Embed Size (px)
Citation preview

Preservation, Publishing, and People: a SEAD View
Beth PlaleDirector, Data To Insight Center
Indiana UniversityIU Scholarworks

Publishable results of computationally‐based science rarely takes form of single data file or homogeneous collection.
More often bundle: primary results, metadata describing the generated data, software used, configuration parameters used
with the software, input data sources, ….
We call these bundles Research Objects
Bechhofer, S., Buchan, I., De Roure, D., Missier, P., Ainsworth, J., Bhagat, J., … & Goble, C. (2011). Why linked data is not enough for scientists. Future Generation Computer Systems, 29(2), 599–611.

Data lifecycle• Research occurs over months to years. Praveen Kumar study of Mississippi River Basin flood of late April, early May 2011.
• Arrange funding, define objectives (2011) • Data gathering: sample flood plain at designated locations, take pictures, obtain satellite data, contract with independent organization to fly over the area with Lidar
• Data cleaning and analysis• Publish 2‐3 papers (2014)• Decide what data to package for publishing alongside publications• Publish the datasets• Each published package we call a Research Object

Publish‐reuse window
•We focus on one window in time in lifecycle of research data : starts when researcher is ready to make data publically available … through to its first case of use by unrelated party (reuse).
“publish‐reuse window”•Why this window?• Repository services have to be self‐documenting to achieve reproducibility. I derive new object from object in SEAD VA, I revise object in SEAD VA – these are different actions, by different people, with different implications.
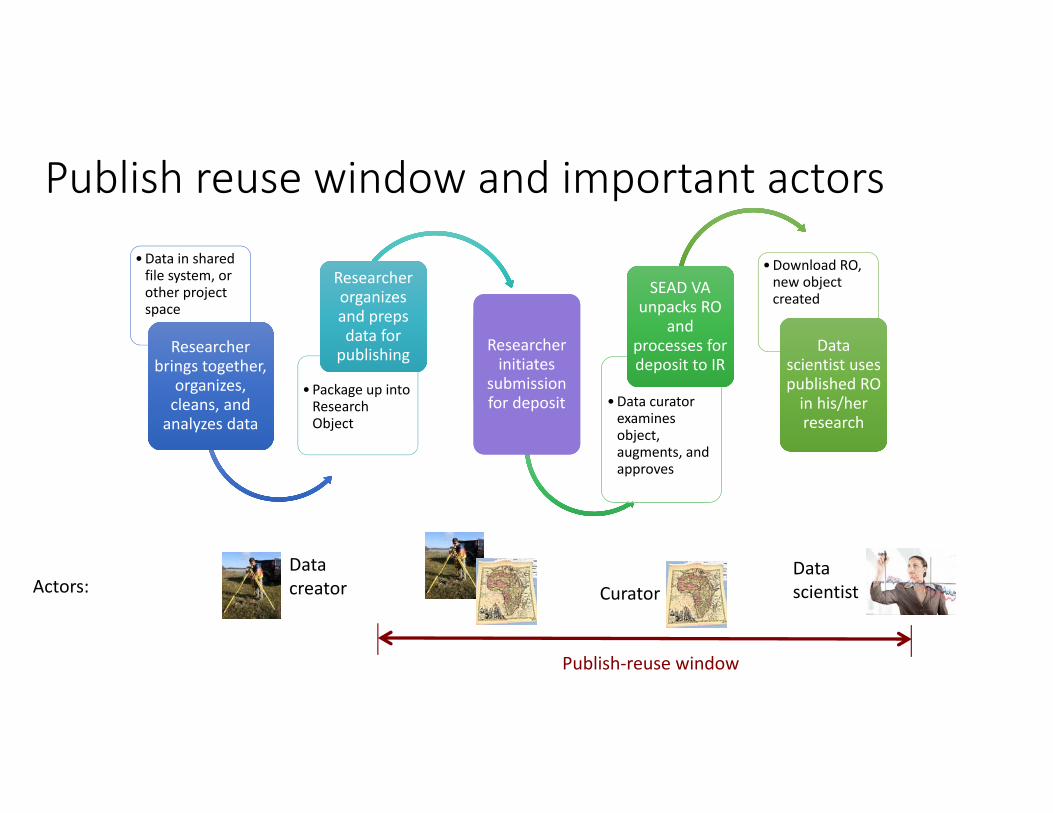
Publish reuse window and important actors•Data in shared file system, or other project space
Researcher brings together,
organizes, cleans, and analyzes data
Researcher brings together,
organizes, cleans, and analyzes data
•Package up into Research Object
Researcher organizes and preps data for publishing
Researcher organizes and preps data for publishing Researcher
initiates submission for deposit
Researcher initiates
submission for deposit •Data curator
examines object, augments, and approves
SEAD VA unpacks RO
and processes for deposit to IR
SEAD VA unpacks RO
and processes for deposit to IR
•Download RO, new object created
Data scientist uses published RO in his/her research
Data scientist uses published RO in his/her research
Publish‐reuse window
Actors:Data creator Curator
Data scientist

Research Object: what the RO is
• The Research object (RO) is an aggregation of resources that can be transferred, produced, and consumed by common services across organizational boundaries. The RO encapsulates digital knowledge and provides a mechanism for sharing and discovering re‐usable research.
• ROs are a bundle of primary results, metadata describing the generated data, software used, configuration parameters used with the software, input data sources, …
• An RO can and will likely have multiple manifestations. • Research object is the publishable object.

Why is Research Object view important?
• Addresses weaknesses in existing solutions: The hierarchical “belongs to” organization of information is extremely inadequate for all but simplest cases.
• Facilitates reproducibility: We can no longer look just at data products: software is critical for reproducibility (even if repeatability is not the goal.)
• Allows for uniform handling: Research object is dropped into a BagIT bag (1 bag = 1 RO). SEAD VA accepts bags of all colors, but all are bags. Lifecycle of ROs tracked in SEAD VA
• Just makes sense: When is the result of a scientific dissertation a uniform collection of files with fixed directory structure? <answer: never>

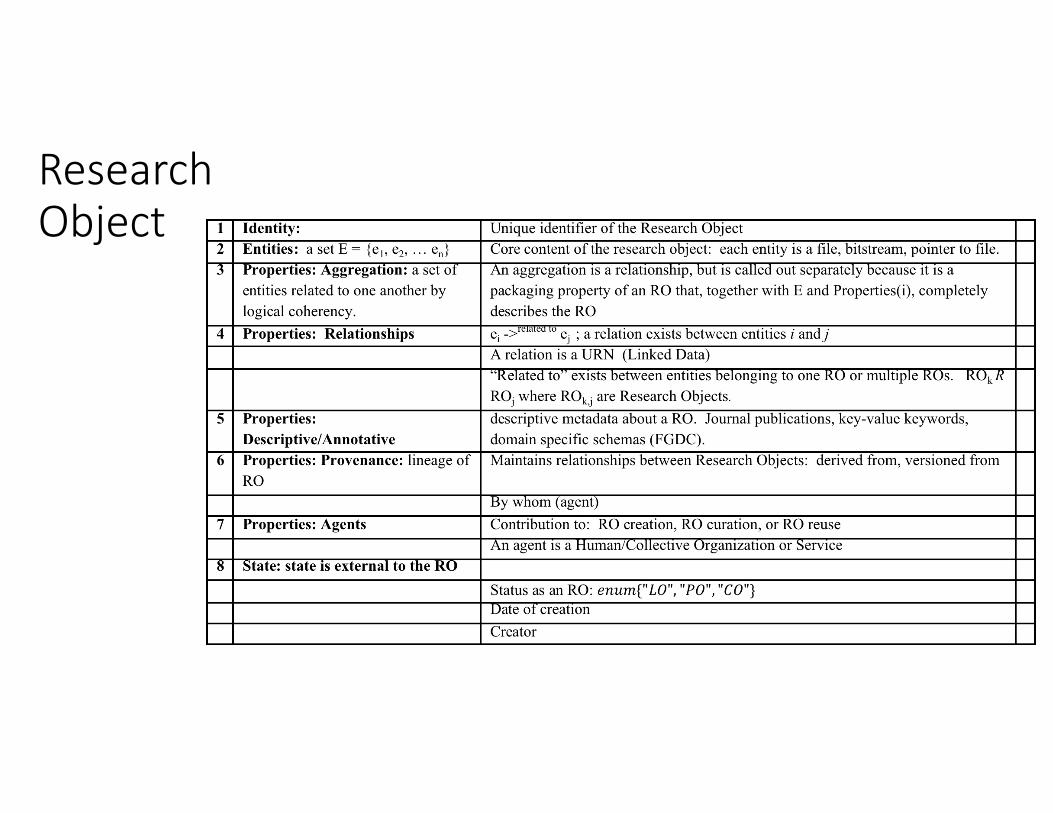
Research Object, Components of
• Identity : unique ID • Entities : core data or software objects themselves• Properties : Aggregation : “belongs to” relationship, used to aggregate within Research Object
• Properties : Relationships : “related to” relationship• Properties: Descriptive/Annotative : metadata• Properties: Provenance : “derived from”, “versioned from” relationship as well as others
• Properties: Agents : data creator (author list), curator, data scientist• State : external to the RO
Research Object

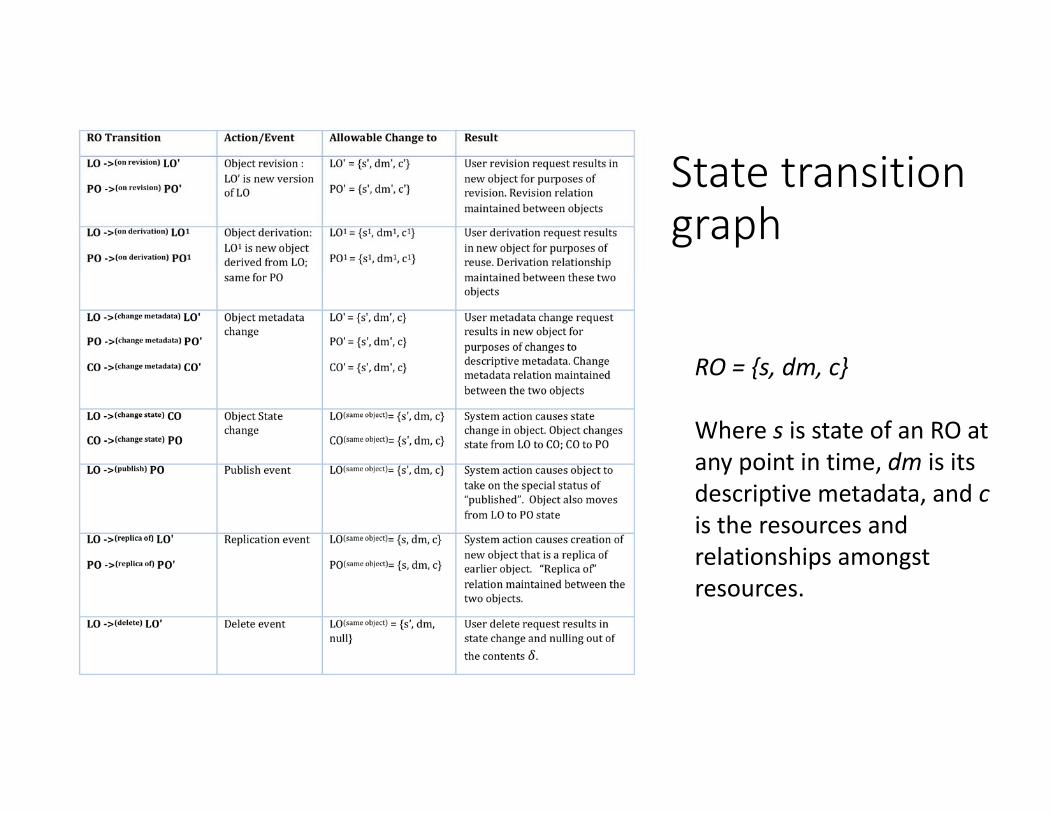
Research Object State TransitionAn RO in one of three states: LO, PO, and CO as follows:
• Live object (LO) – a work in progress. Data creator assembling content for publication
• Curation object (CO) – an object after creator signaled intention to publish. Curator works on the curation object; changes are selective.
• Publication object (PO) ‐ a final version ready to be disseminated widely. Published Objects (PO’s) are mutable under certain conditions only.
RO described by model:
RO = {s, dm, c}Where s is state of an RO at any point in time, dm is its descriptive metadata, and cis the entities (core content) and relationships amongst entities
RO = {s, dm, c}
Where s is state of an RO at any point in time, dm is its descriptive metadata, and cis the resources and relationships amongst resources.
State transition graph
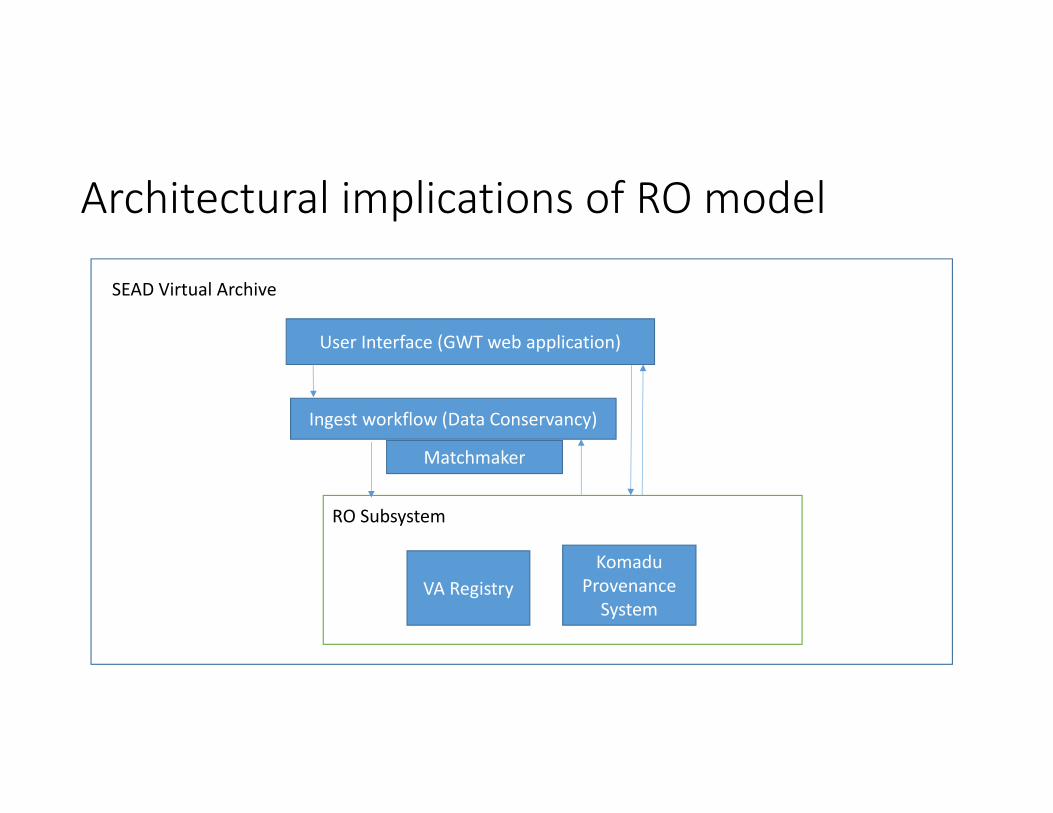
Architectural implications of RO model
SEAD Virtual Archive
User Interface (GWT web application)
Ingest workflow (Data Conservancy)
KomaduProvenance System
VA Registry
RO Subsystem
Matchmaker
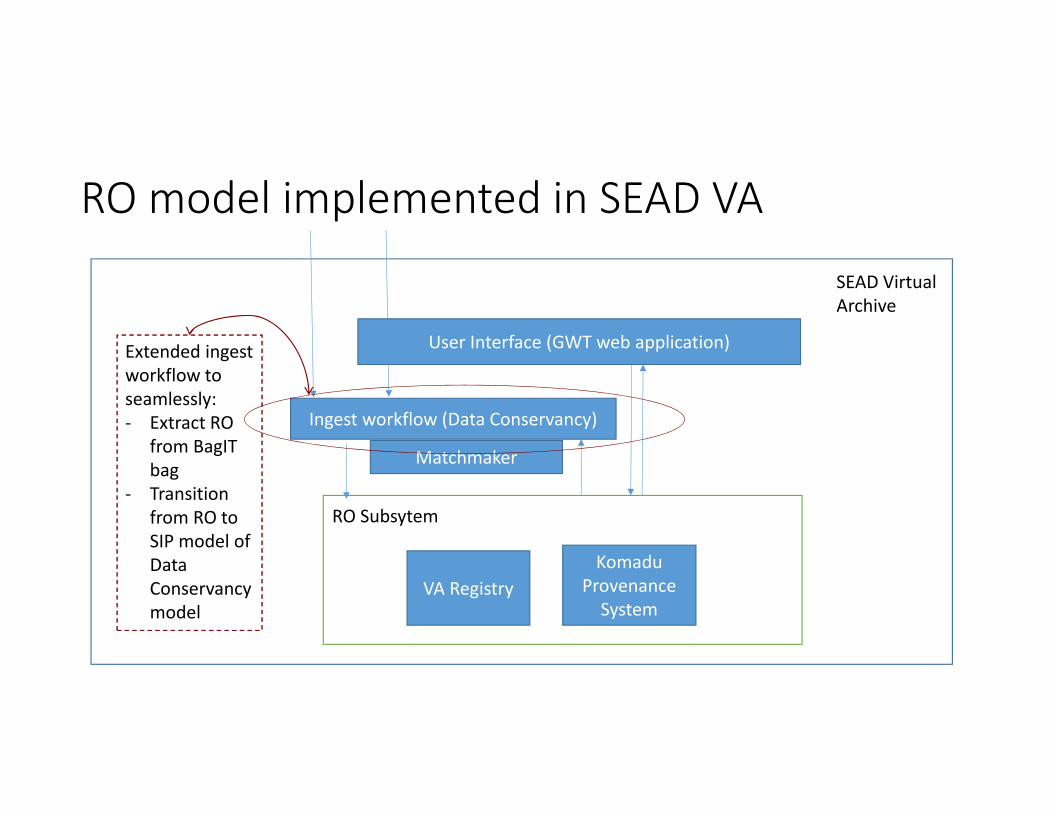
RO model implemented in SEAD VA
SEAD Virtual Archive
Ingest workflow (Data Conservancy)
KomaduProvenance System
VA Registry
RO Subsytem
Matchmaker
Extended ingest workflow to seamlessly: ‐ Extract RO
from BagITbag
‐ Transition from RO to SIP model of Data Conservancy model
User Interface (GWT web application)
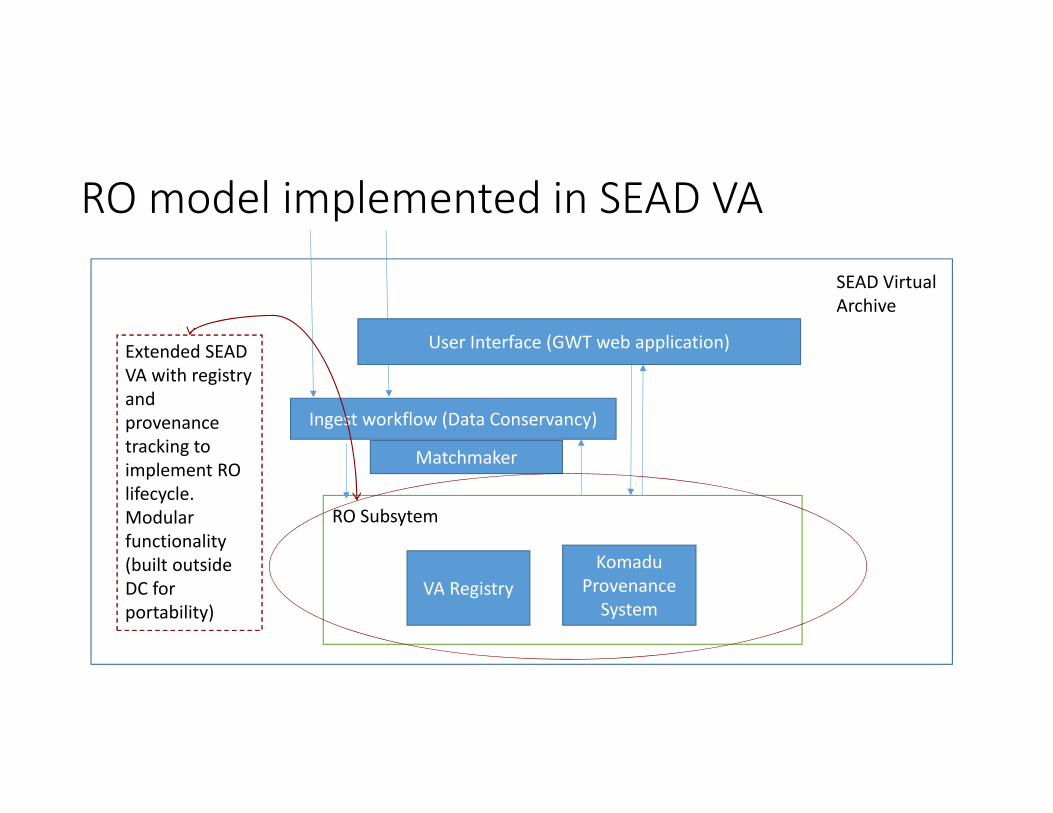
RO model implemented in SEAD VA
SEAD Virtual Archive
Ingest workflow (Data Conservancy)
KomaduProvenance System
VA Registry
RO Subsytem
Matchmaker
Extended SEAD VA with registry and provenance tracking to implement RO lifecycle. Modular functionality (built outside DC for portability)
User Interface (GWT web application)

People: Data Creator, Curator, and Data Scientist

Each of Data Creator, Curator, and Data Scientist are related to one another, and their relationship is through the Research Objects that they create, work on, and use.
This relationship information exists in form of provenance in SEAD VA. Future work is to capture these nuanced relationships in the SEAD Research Network as well.

And onto … SEAD VA Workshop Agenda and Resources
http://bit.ly/sead‐va‐workshop063014

Data Creator in SEAD VAInna Kouper

OverviewThe Data Creator collects data and, once done with a study, gathers materials that support the study and submits them for publication and preservation in institutional repositories.
Example: A dissertation that is based• images from USGS• spreadsheets with numbers and calculations• computing scripts• videos of experiments
In VA a data creator can:• Upload research objects (ROs)• Preview, review and download ROs• Check status of ROs in queue to IR

Background : SEAD Services
• SEAD Research Network• Project Spaces• Packaging and Mapping
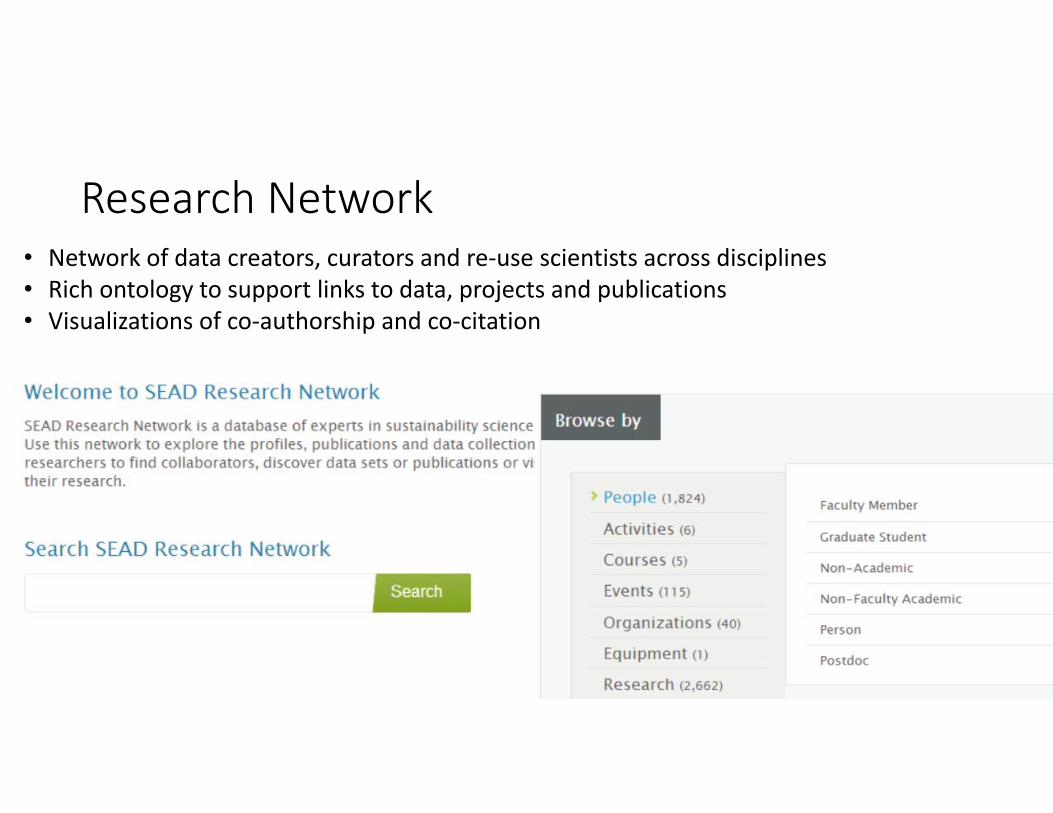
Research Network• Network of data creators, curators and re‐use scientists across disciplines• Rich ontology to support links to data, projects and publications• Visualizations of co‐authorship and co‐citation
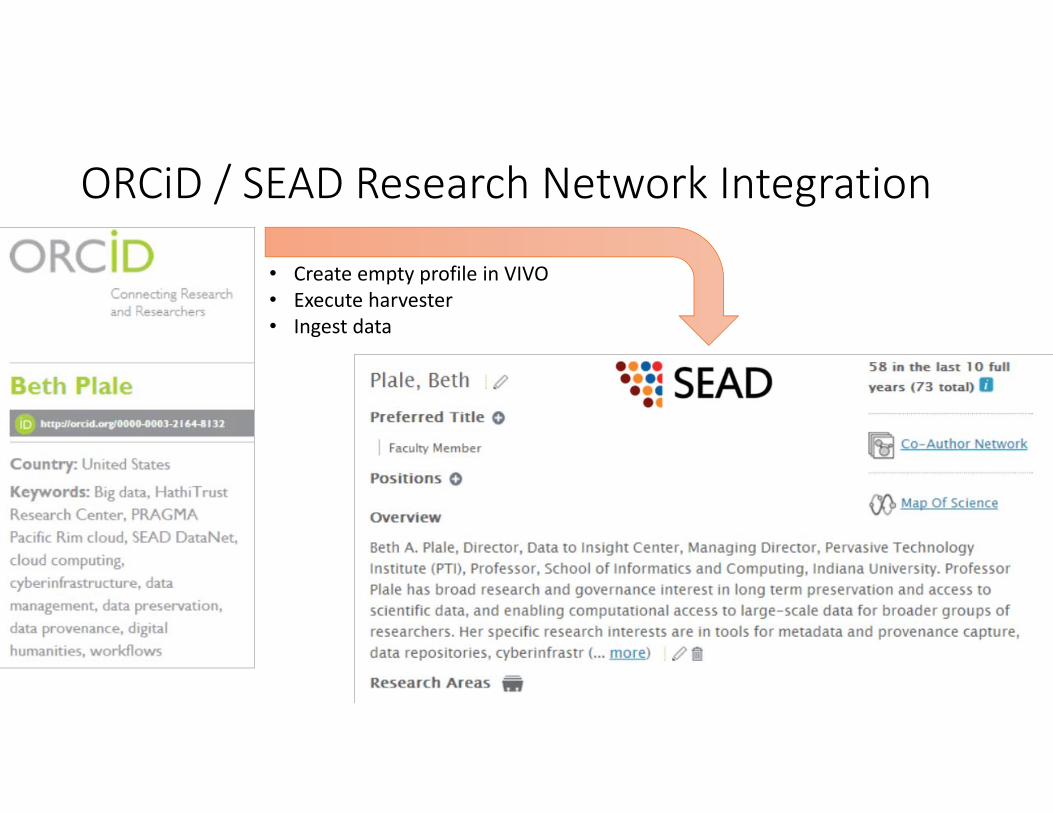
ORCiD / SEAD Research Network Integration
• Create empty profile in VIVO• Execute harvester• Ingest data

Project Spaces
• 15 project spaces (incl. an open demo space and an internal testing space)
• Thousands of collections in active curation• Once a collection is marked for publication, it can be ingested into Virtual Archive
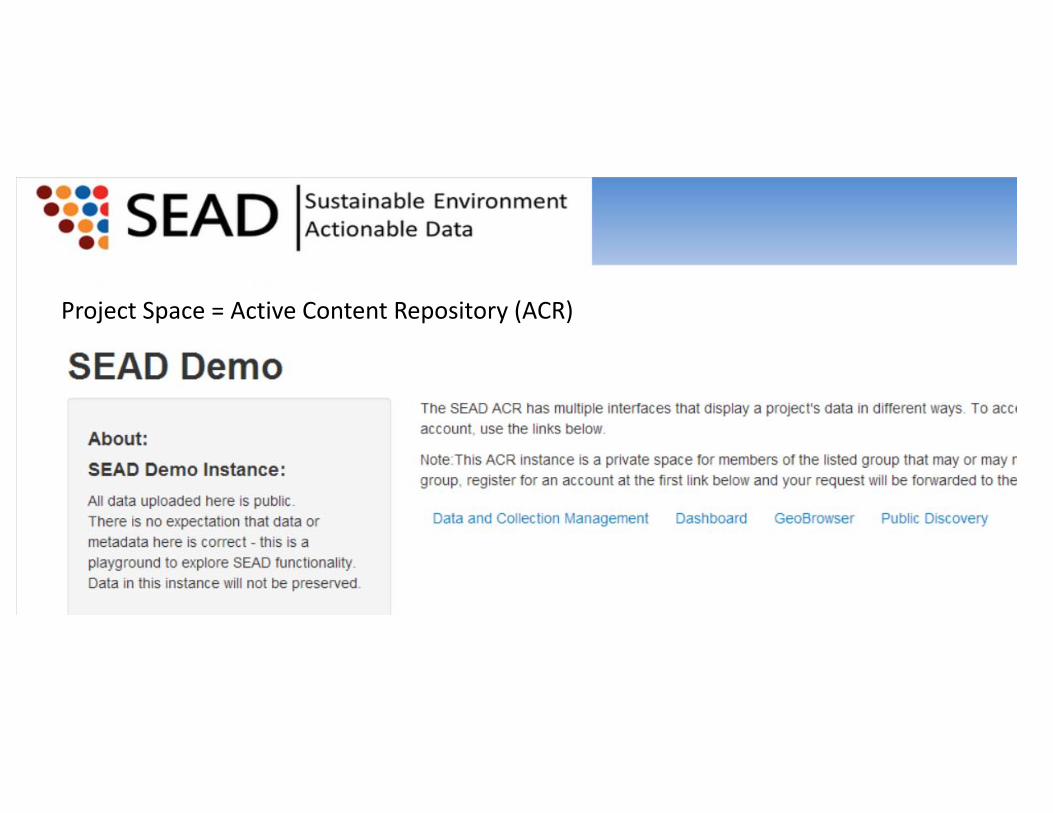
Project Space = Active Content Repository (ACR)
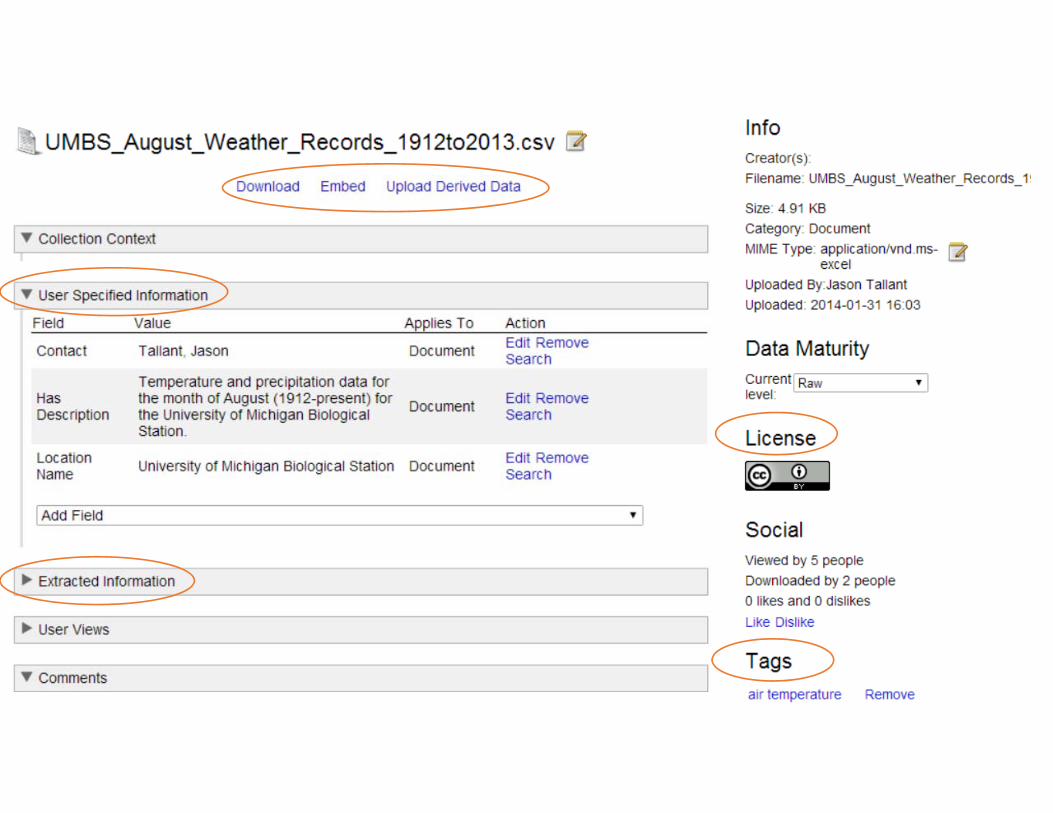

Packaging and Mapping (BagIT / ORE)
• BagIt format• standardized “envelopes” (bags)• no requirements for “knowing” internal semantics• 3 elements: a bag declaration (bag.txt), a manifest file (manifest‐<algorithm>.txt, folder with content (data)
• Tools available for bagging• SEAD BagIt service• LOC Bagger tool (http://sourceforge.net/projects/loc‐xferutils/files/loc‐bagger/2.1.2/)

Resource Maps• OAI/ORE standard
• Exposes rich content• Captures semantic of relationships among RO items• Identifies aggregations
• SEAD VA OAI/ORE relationship classes: • Aggregation• Description• Authorship• Copyright / rights• Modification• Derivation• Citation• Processing (calculation, computation, etc.)
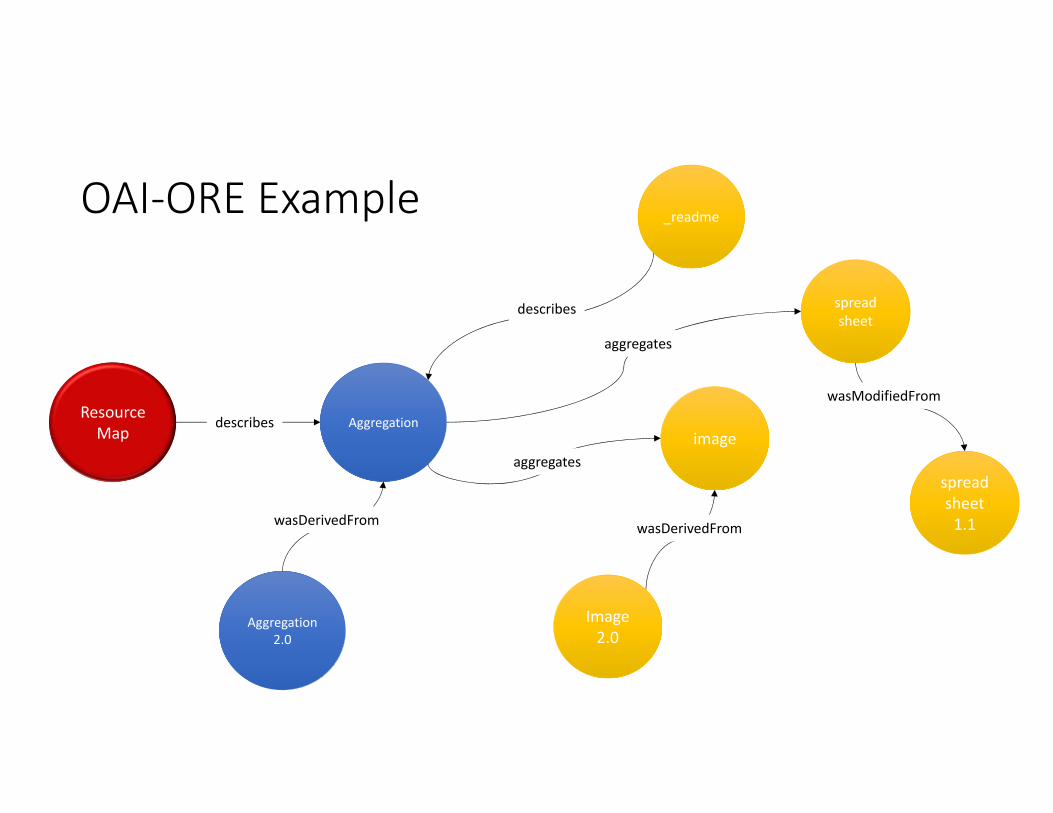
OAI‐ORE Example
Resource Map
Aggregation
_readme
spreadsheet
image
Image 2.0
spreadsheet 1.1
describes
aggregates
describes
wasDerivedFrom
wasModifiedFrom
aggregates
Aggregation2.0
wasDerivedFrom

OAI/ORE Map Example<rdf:RDF…<rdf:Description rdf:about=URI> <!‐‐ data item‐‐>
<ore:isAggregatedBy>ID</ore:isAggregatedBy><dcterms:identifier rdf:datatype=URI>ID</dcterms:identifier><dcterms:title rdf:datatype=URI>Vortex_Mining.xlsx</dcterms:title><dcterms:source rdf:datatype=URI>test_bag/data/Vortex_Mining.xlsx</dcterms:source>
<!‐‐ A related resource from which the described resource is derived. ‐‐></rdf:Description>…..</rdf:RDF>

Demo / Hands on[Data creator role]

Download Test Research Objects
Or go to https://iu.box.com/sead‐va‐test‐bags
Register / Sign In• Go to http://seadva‐test.d2i.indiana.edu:5672/sead‐access/• Click LOG IN and fill your login information (or click SignUp below)
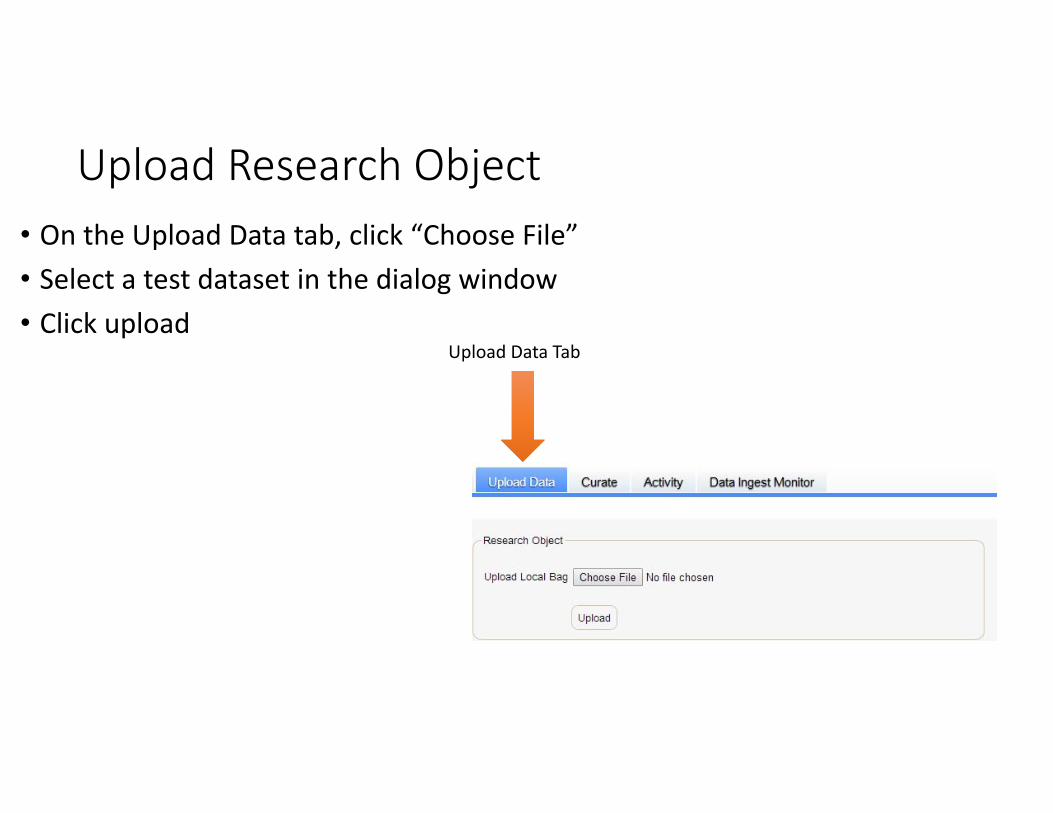
Upload Research Object• On the Upload Data tab, click “Choose File”• Select a test dataset in the dialog window• Click upload
Upload Data Tab
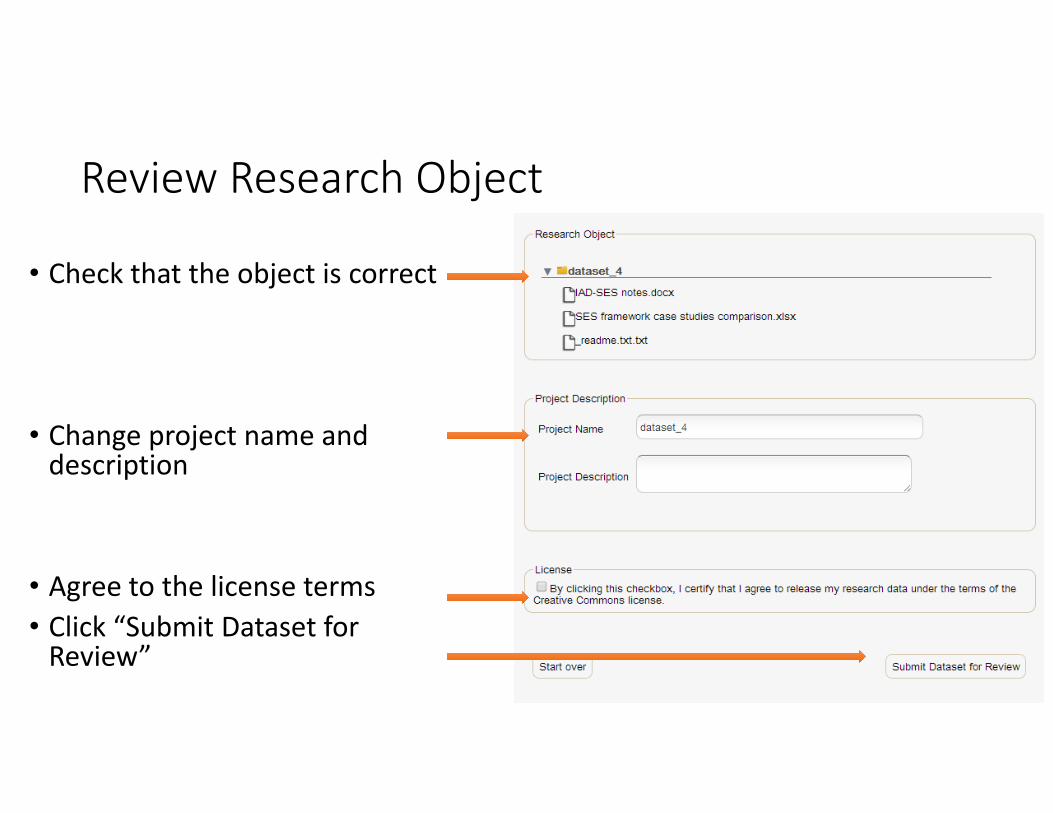
Review Research Object
• Check that the object is correct
• Change project name and description
• Agree to the license terms• Click “Submit Dataset for Review”

Status and Success Messages
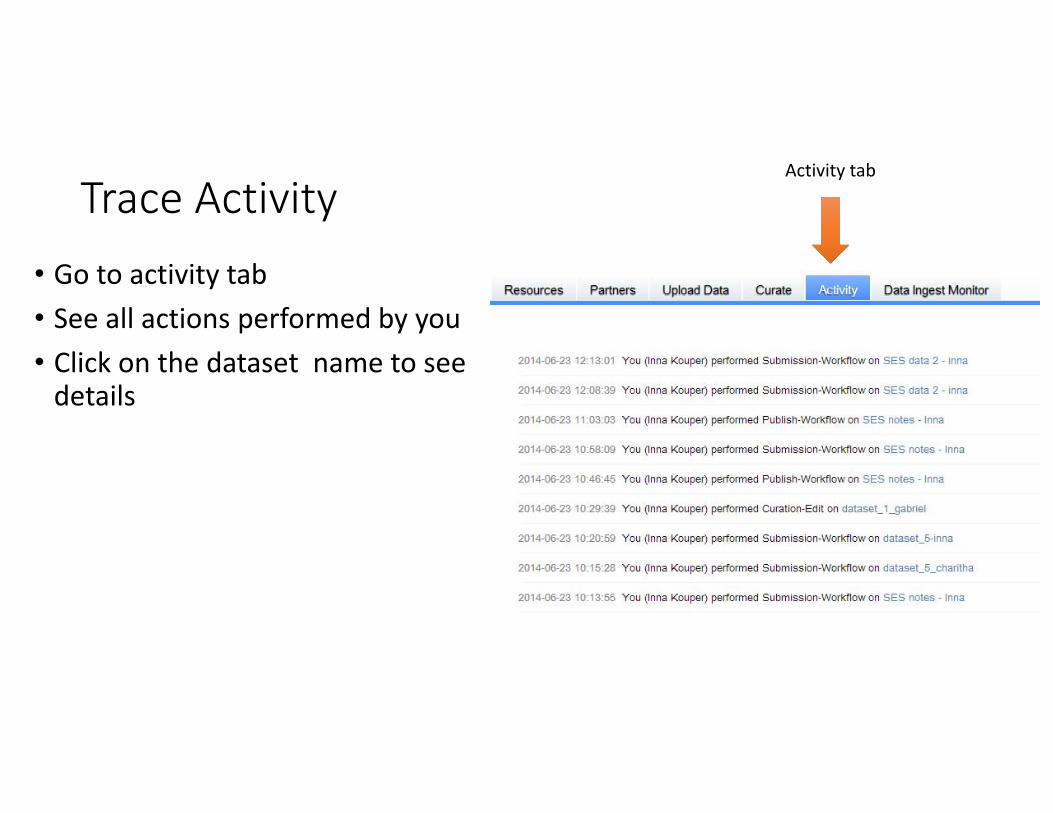
Trace Activity• Go to activity tab• See all actions performed by you• Click on the dataset name to see details
Activity tab

View Research Object Details
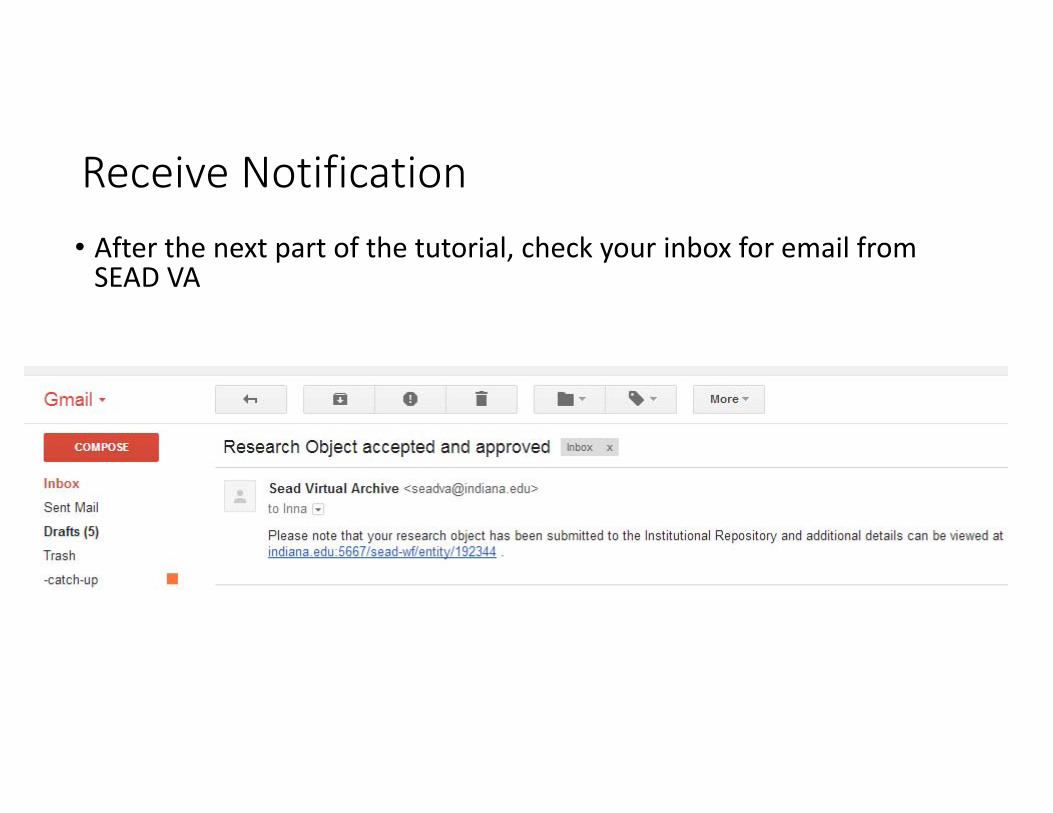
Receive Notification• After the next part of the tutorial, check your inbox for email from SEAD VA

Curator in SEAD VAKavitha Chandrasekar

Overview
The Curator works on Research Objects created and submitted by Data Creators: reviews submission, modifies metadata, and takes action to move submission to their Institutional Repository
In VA curator can:• Select Item for review from curation queue• Enhance Metadata• Deposit to Institutional Repository

“Under the Hood”IR Recommendation and IR Description

Automatic IR Recommendation (SEAD VA Matchmaker)• Matches RO’s to compatible Institutional Repository• Recommends best Institutional Repository match for RO• Facilitates transfer and deposit of heterogeneous ROs
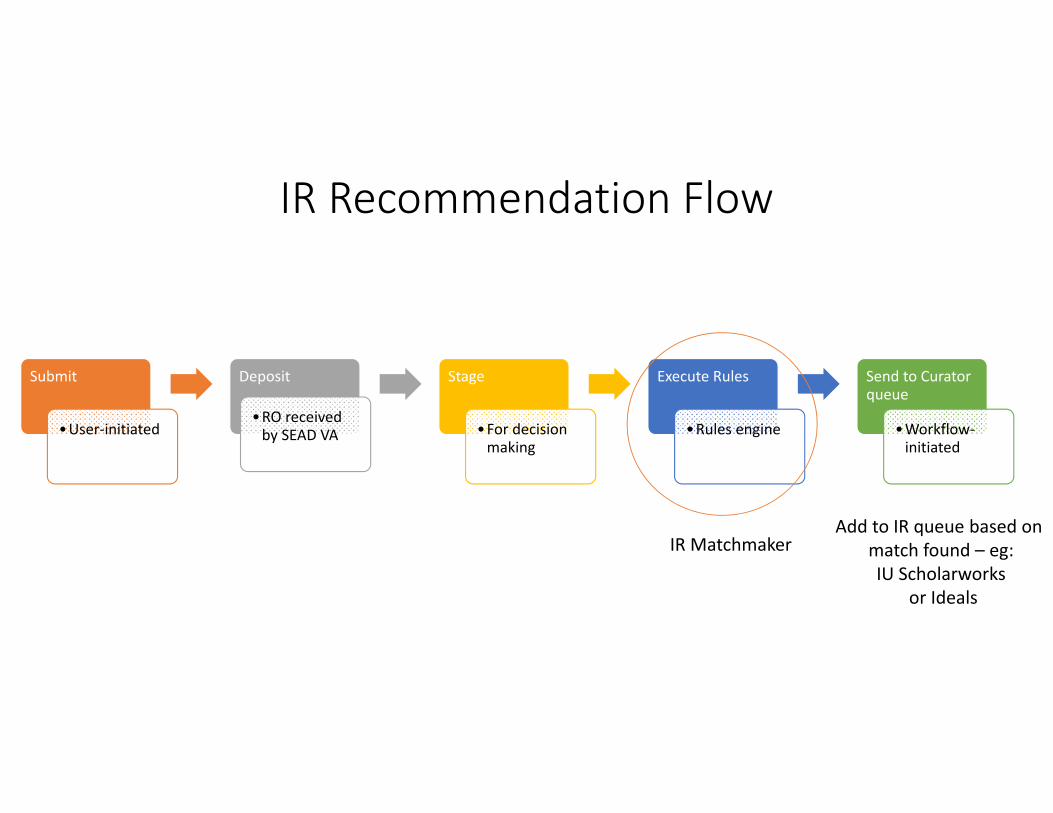
IR Recommendation Flow
Submit
•User‐initiated
Deposit
•RO received by SEAD VA
Stage
•For decision making
Execute Rules
•Rules engine
Send to Curator queue
•Workflow‐initiated
IR MatchmakerAdd to IR queue based on
match found – eg:IU Scholarworks
or Ideals

IR – SEAD VA “contract”: the Service Level Agreement• Service Level Agreement (SLA) is a contract of sorts between SEAD VA and an Institutional Repository. It captures• Repository requirements and privileges• Repository services
• The IR Recommendation system uses excerpts from IR’s SLA to identify compatible pairs of datasets and repositories during RO deposit.

Service Level Agreement‐ Requirements and Privileges (summary)• RO properties – Requirements
• Data contributor Institutional Affiliation • Scientific Domain• Data Organization (e.g.: BagIt or SWORD)• Size• Versioning• Minimal Metadata• Licensing (eg: open, embargoed)
• Repository privileges• Repository is free to re‐distribute the RO received from SEAD VA, except in case of embargo.
• Repository can migrate RO into other formats and re‐distribute migrate ROs.• Repository curators can annotate data collections to comply with standards or upgrades in our policies.

SLA – Repository Service Guarantees
• Long‐term preservation• Format Migration• Archival support• Embargo• Access • DOI generation• Technical guarantees:
• Limited Downtime• Data Ingest Time• Backup• Integrity checks

Excerpt from from SLA for IU Scholarworks
• Institutional Affiliation• At least one author, at the time of deposit, belongs to the same institution as our repository.
• RO Size• 150 MB for items uploaded directly to IUScholarWorks, 10 GB total• 5 TB for items hosted on the SDA
• Versioning• Only final PO is accepted, subsequent versions will substitute the version of record.
• Scientific Domain – Curator review might be needed• ROs are associated with research in the domains of ANY (identify specific domains or put “sustainability science” for a broader match)

The IR Recommender use of an SLA
• IR Recommender implements an IR’s SLA as a set of executable rules in the Matchmaker. The rules are executed with a rules engine called “Drools”• Rules can be added on the fly, meaning new IR can be added just by specifying a SLA. • Incorporate modifications in SLA to rules at runtime
• Clean mapping of SLA terms to Drools Drools rules

Mapping SLA to Drools rulesrule "IU Scholaworks Affiliation rule”
dialect "mvel”salience 20
whenSeadDeliverableUnit( title != null ) //Per IU SLA collection should have titleSeadDeliverableUnit($contributors:dataContributors )eval( $contributors.size>0 ) //Creators should not be empty per IU SLA$seadPerson: SeadPerson( idType == "vivo" && getEmail(id)=="Indiana University") from $contributors;$seadDu : SeadDeliverableUnit(sizeBytes < 10000000000 ) //Total collection size less than10 GB approximatelySeadDeliverableUnit(fileNo < 1000 ) //Total file count less than 1000SeadDeliverableUnit( "CC" in (rights) ) //Open access data
thenaddRepository("iu", 2); //Adding IU repository to the queue of matched repositories with priority 2
end
Rule declaration
Condition
Execution
Affiliated data contributor found

Demo / Hands On[Curator role]
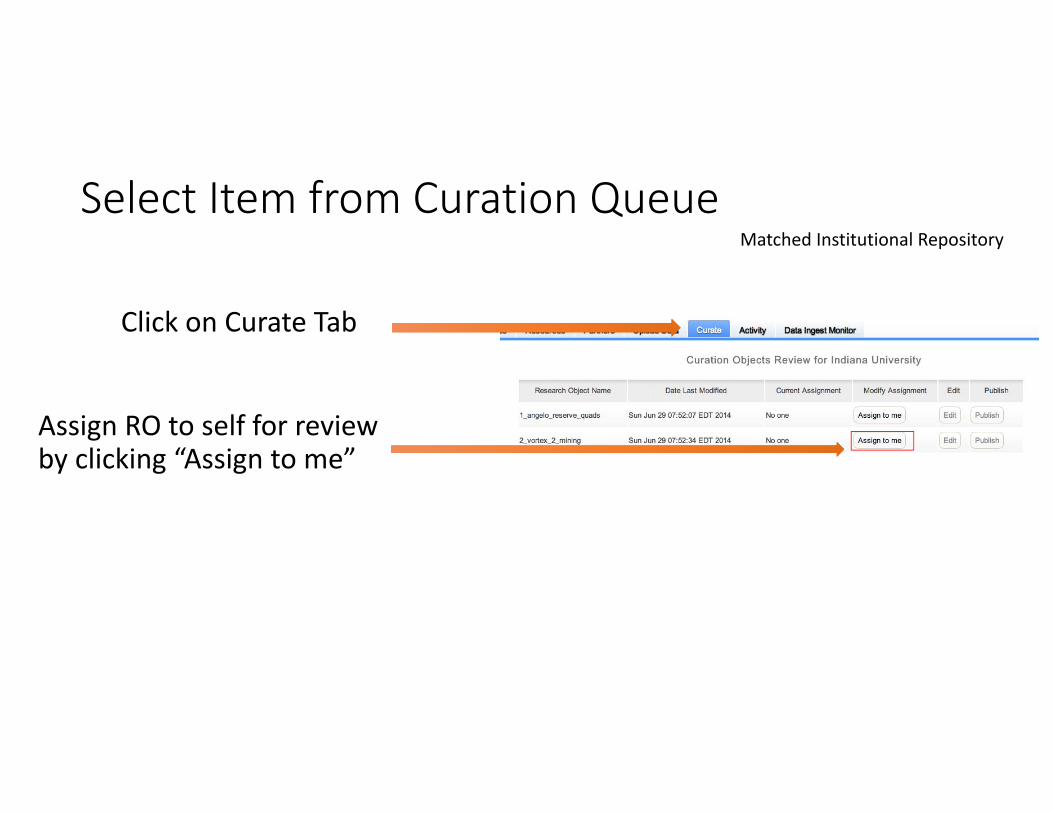
Select Item from Curation QueueMatched Institutional Repository
Click on Curate Tab
Assign RO to self for review by clicking “Assign to me”
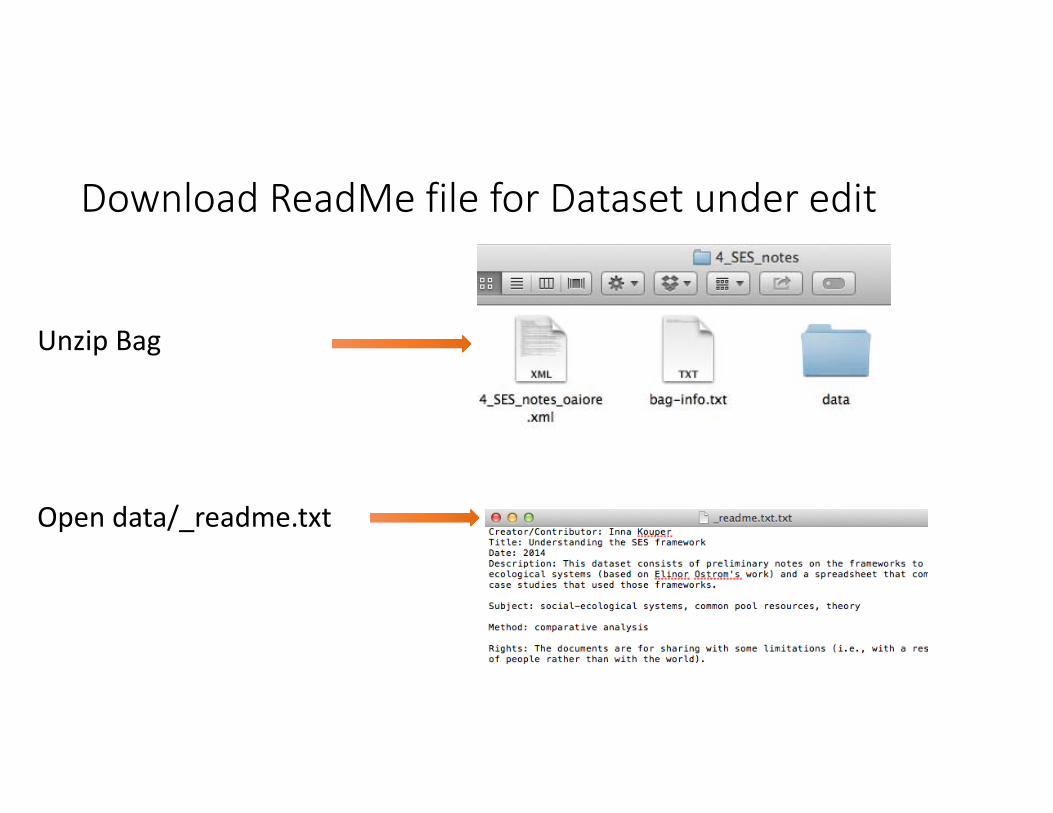
Download ReadMe file for Dataset under edit
Unzip Bag
Open data/_readme.txt

Enhance Metadata
Click on ‘Edit’ button

View Research Object in Edit mode
To edit, click on entities in the bottom pane
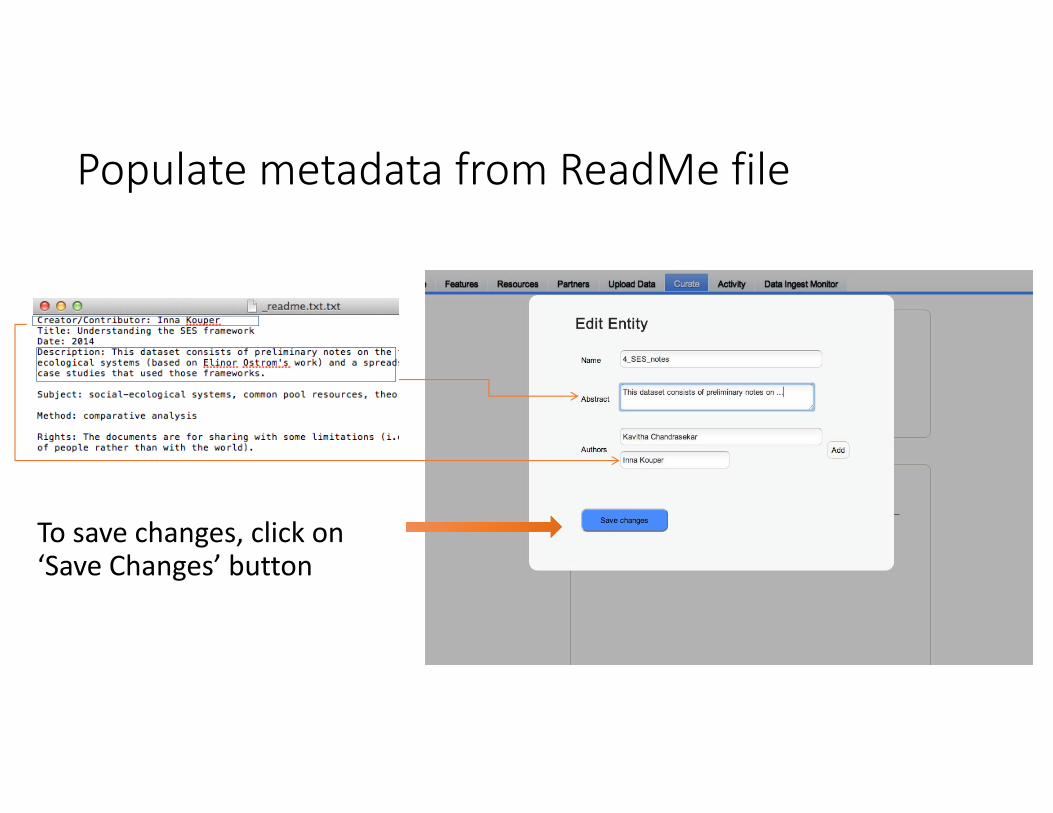
Populate metadata from ReadMe file
To save changes, click on ‘Save Changes’ button
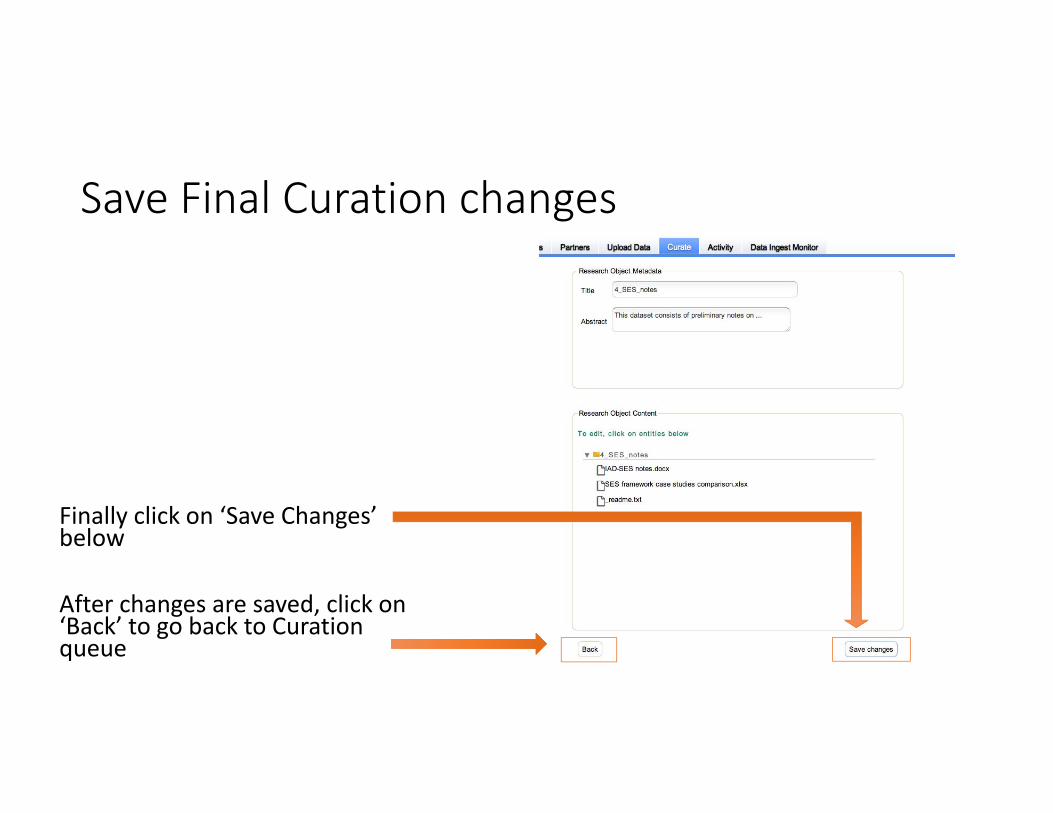
Save Final Curation changes
Finally click on ‘Save Changes’ below
After changes are saved, click on ‘Back’ to go back to Curation queue

Approve and Publish to Institutional Repository
Publish

Trace Activity
• Go to activity tab• See all actions performed by you• Click on the Research Object name to see details
Activity tab
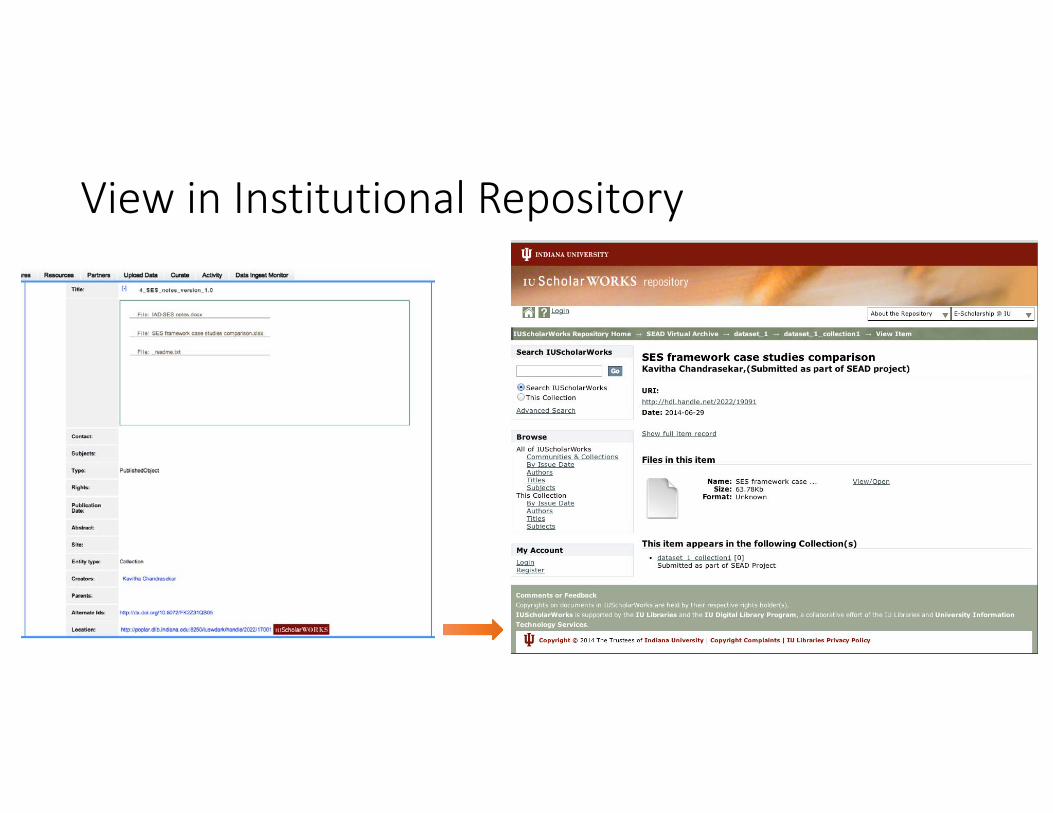
View in Institutional Repository

Data Reuse Scientist in SEAD VAIsuru Suriarachchi

Overview: The Data Scientist Data Scientist uses research objects that were created by someone elsefor his/her purposes and creates new research objects by modifyingexisting objects.Super Simple Example: Putting images in given RO 3 into a singlepresentation and creating a new RO
Data scientist can:• Search• Download (bags)• Modify• Re‐upload

“Under the Hood”Provenance, Component Interaction

Provenance
• What is Provenance? • Provenance is information about entities, activities, and people involved in producing a piece of data or thing, which can be used to form assessments about its quality, reliability or trustworthiness
• Also called “Lineage” or “Pedigree”• Advantages of provenance for preservation
• Derive ownership• Asses quality and trustworthiness• Reproducibility• Validation• Failure Tracing
Not used in Preservation Provenance

Provenance in Repositories
• The provenance important here is provenance of a Research Object • Why important?
• For the data scientists in “Search”• To check ownership of RO• To asses quality and trustworthiness of RO
• For the Curators • To check curation history
• Provenance role in “Publish ‐ Reuse window”• Published Object (PO) Provenance• Curation Object (CO) Provenance

Provenance Capture in SEAD VA
• Uses Komadu provenance system• Captures activity in real time, assembles new activity into internal representation as provenance graphs
• W3C PROV spec compliant
• Terminology• Activity : Some Processing Event in SEAD VA• Entity : A Research Object (in CO or PO state)• Agent : Data Creator, Curator, Data Scientist
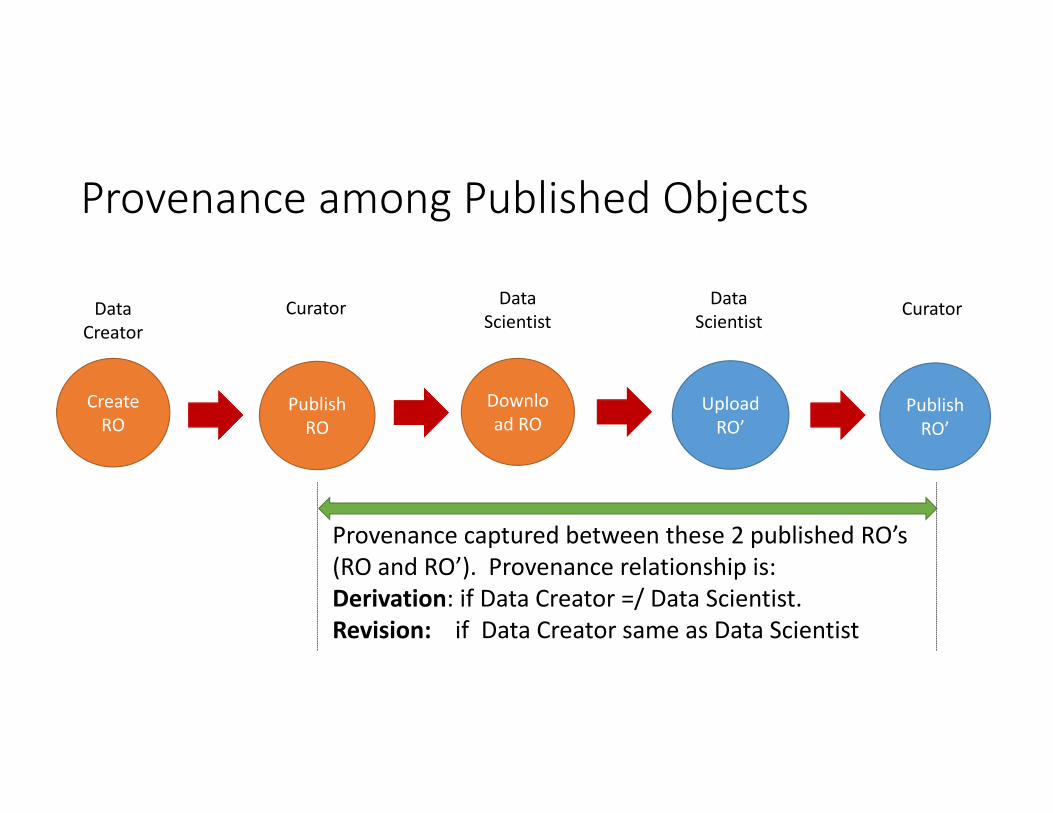
Provenance among Published Objects
Create RO
Publish RO
Download RO
Upload RO’
Publish RO’
DataCreator
Curator Data Scientist
CuratorData Scientist
Provenance captured between these 2 published RO’s (RO and RO’). Provenance relationship is:Derivation: if Data Creator =/ Data Scientist. Revision: if Data Creator same as Data Scientist

Maintaining Provenance among Published ROs• Two identifiers maintained: DOI and Internal Identifier.•Why two identifiers? • DOI: each RO has a unique DOI. • Internal Identifier: lineage maintained through internal identifier which maintains the relationship between original object and derived object

Provenance among Published Objects• At first publish of RO, a DOI and Internal Identifier are added to oaiore.xml
• At Re‐upload

Provenance among Published ROs
• Provenance relationships captured in Komadu• Entity‐Entity (derivation) : When the second publish is done
• This RO provenance capture continues up to any number of publish:download:re‐upload cycles
• At second publish (RO’), “wasDerivedFrom” element is added in the oaiore.xml referring to the original Internal Identifier

Usage of Published Object Provenance• Data scientist can see lineage graph of her new RO’. This helps her assess the collection and is useful if original object changes (forward provenance).
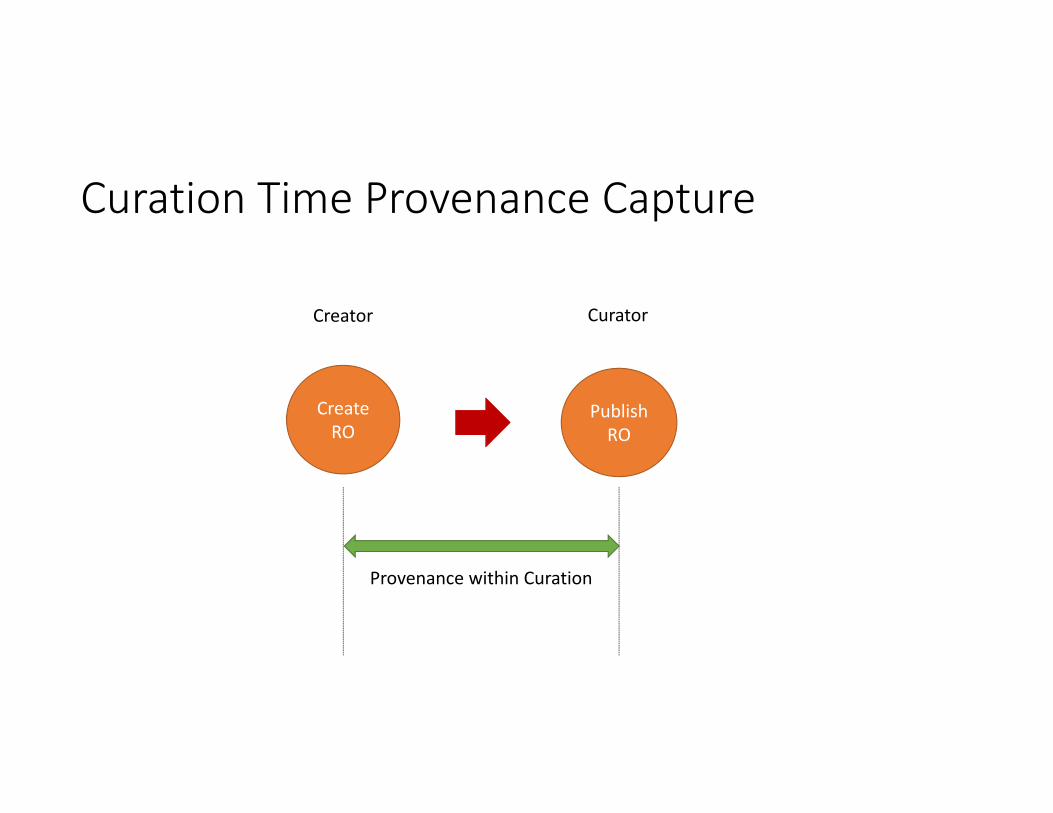
Curation Time Provenance Capture
Create RO
Publish RO
Creator Curator
Provenance within Curation

Curation Time Provenance Capture• Curation Activities
• Curation‐Edit‐Event• Publish‐Event
• Provenance relationships captured in Komadu• Agent‐Activity : When some Agent triggers one of above Activities• Activity‐Entity : When an Activity Generates (Updates) a Research Object
• Example Scenario• Curator X edits metadata on research object Y
• Agent‐Activity relationship (association) between X and Curation‐Edit‐Event• Activity‐Entity relationship (generation) between Curation‐Edit‐Event and Y
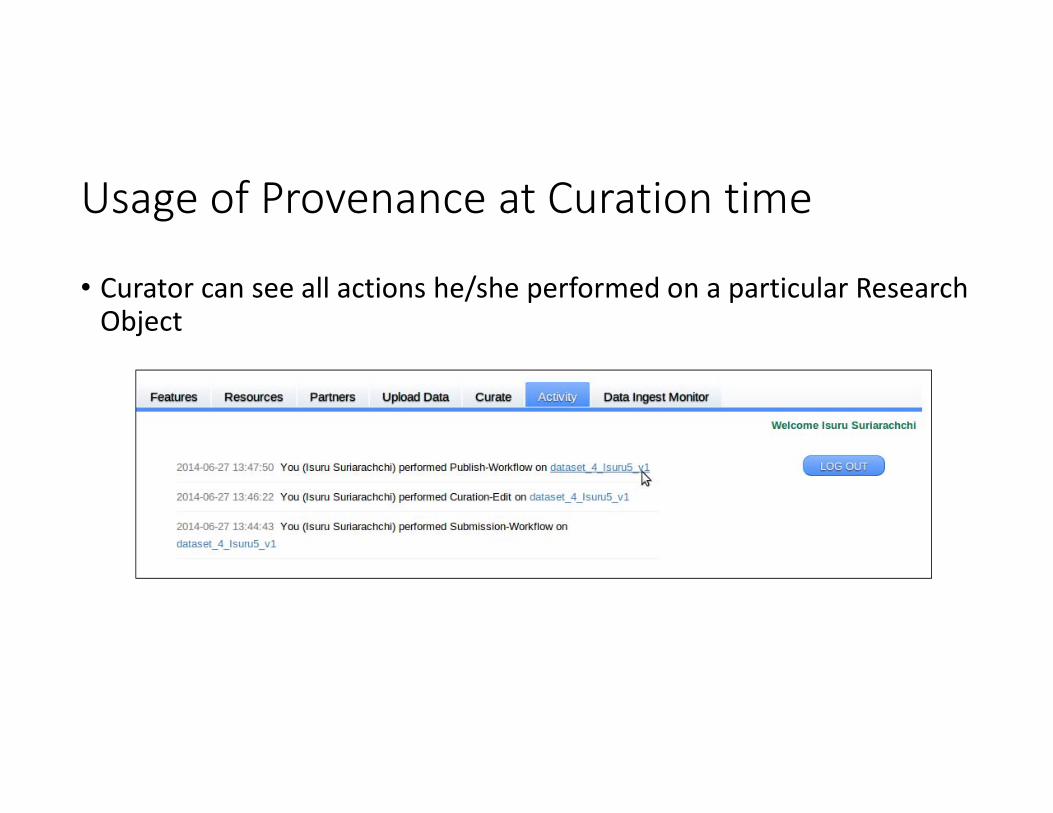
Usage of Provenance at Curation time
• Curator can see all actions he/she performed on a particular Research Object
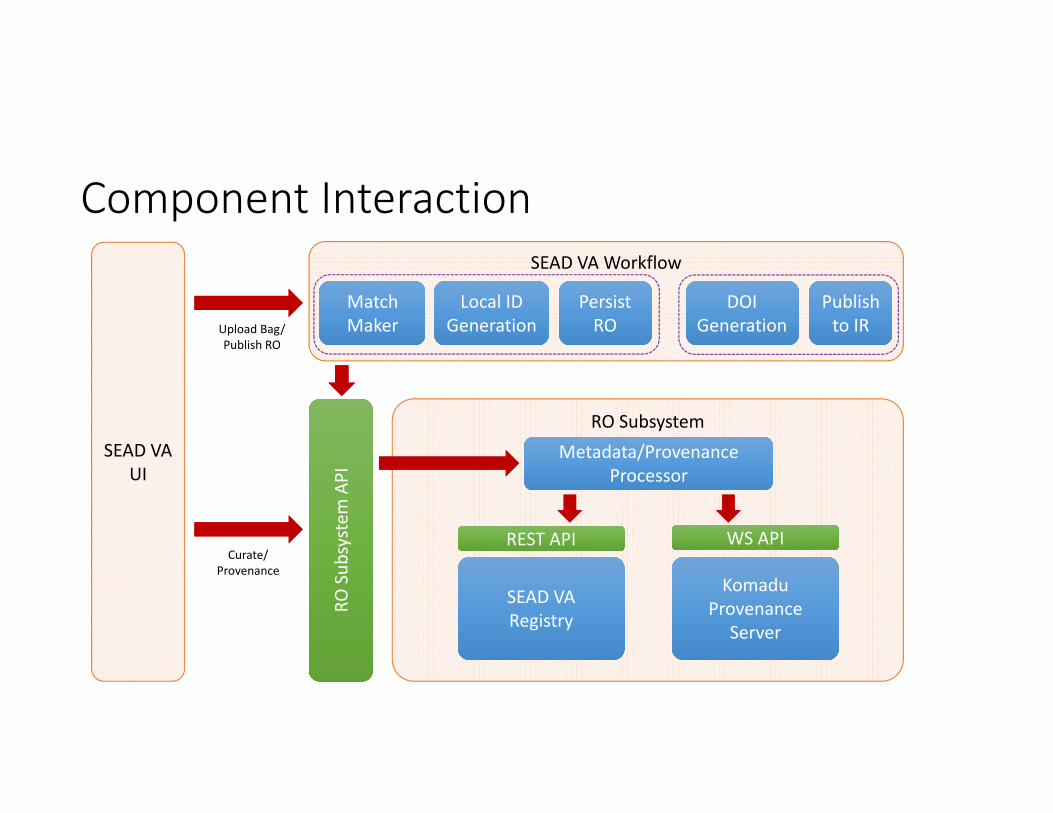
Component InteractionSEAD VA Workflow
Local ID GenerationLocal ID
GenerationPersist RO
Persist RO
DOI Generation
DOI Generation
Publish to IR
Publish to IR
RO Subsystem
RO Sub
system
API
RO Sub
system
API
SEAD VARegistrySEAD VARegistry
KomaduProvenance
Server
KomaduProvenance
Server
Metadata/Provenance Processor
Metadata/Provenance Processor
REST APIREST API WS APIWS API
SEAD VAUI
Upload Bag/Publish RO
Curate/Provenance
MatchMakerMatchMaker

Demo / Hands On[as a data scientist]
Register / Sign In• Go to http://seadva‐test.d2i.indiana.edu:5672/sead‐access/• Click LOG IN and fill your login information (or click SignUp below)
Search for Data
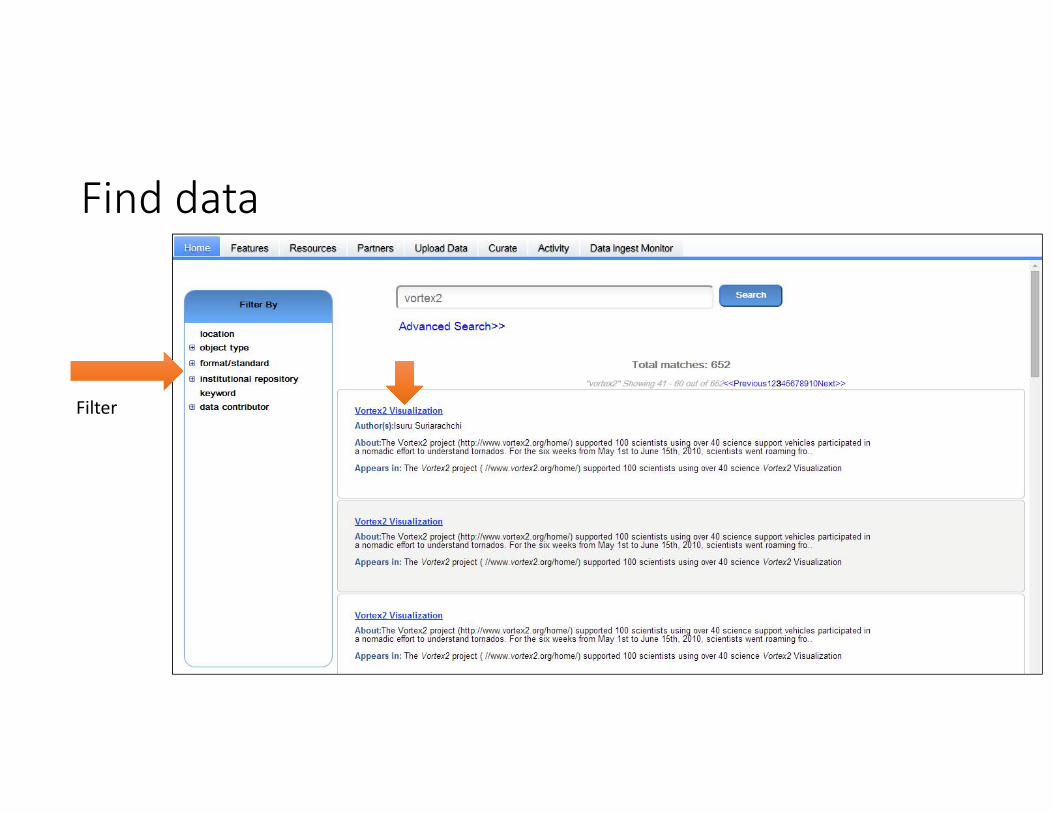
Find data
Filter
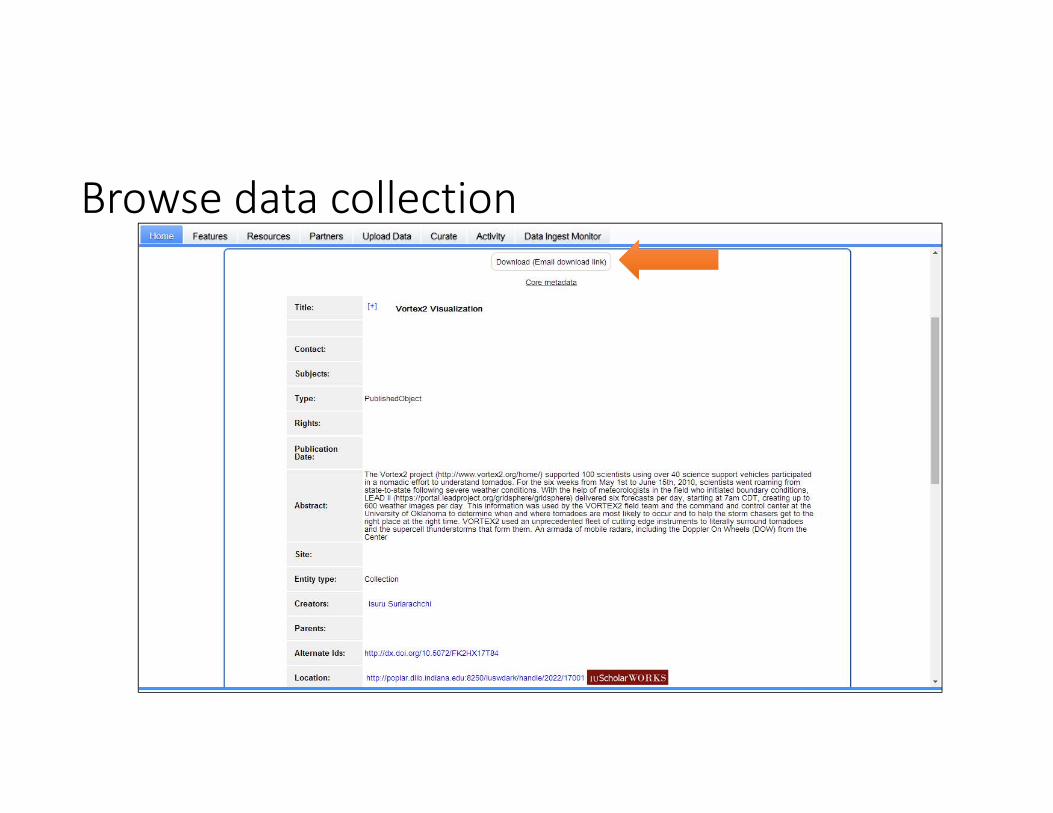
Browse data collection

Request Data Download
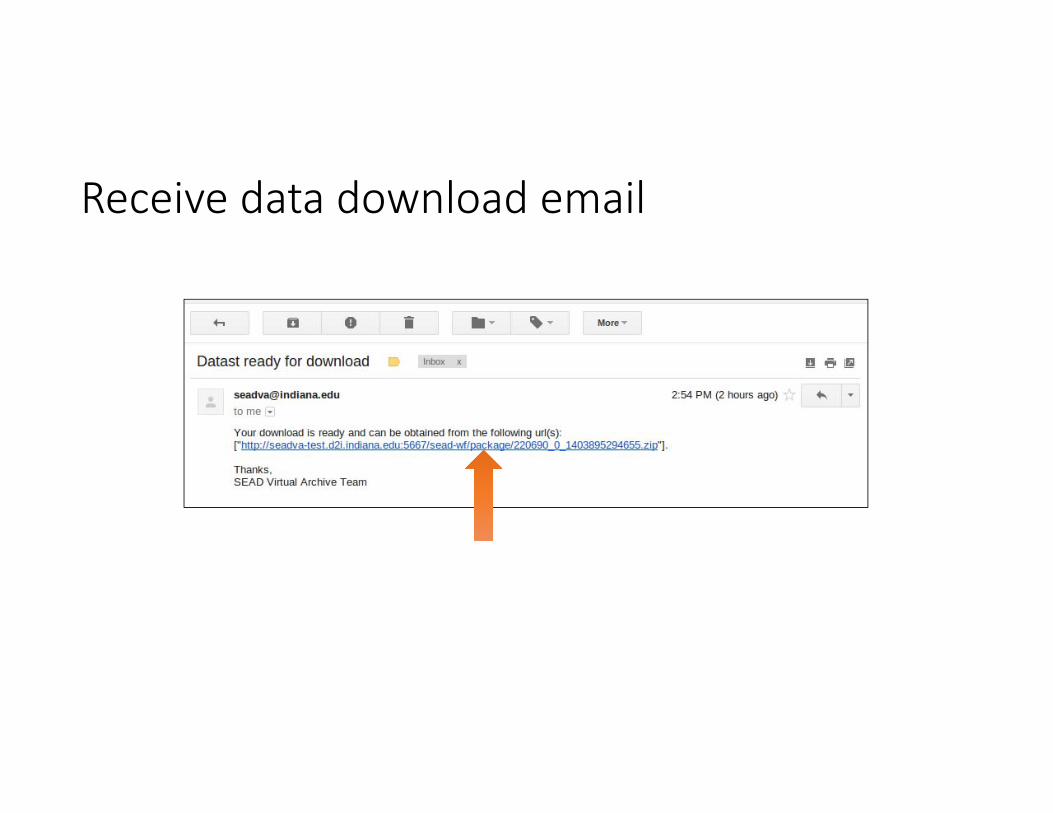
Receive data download email
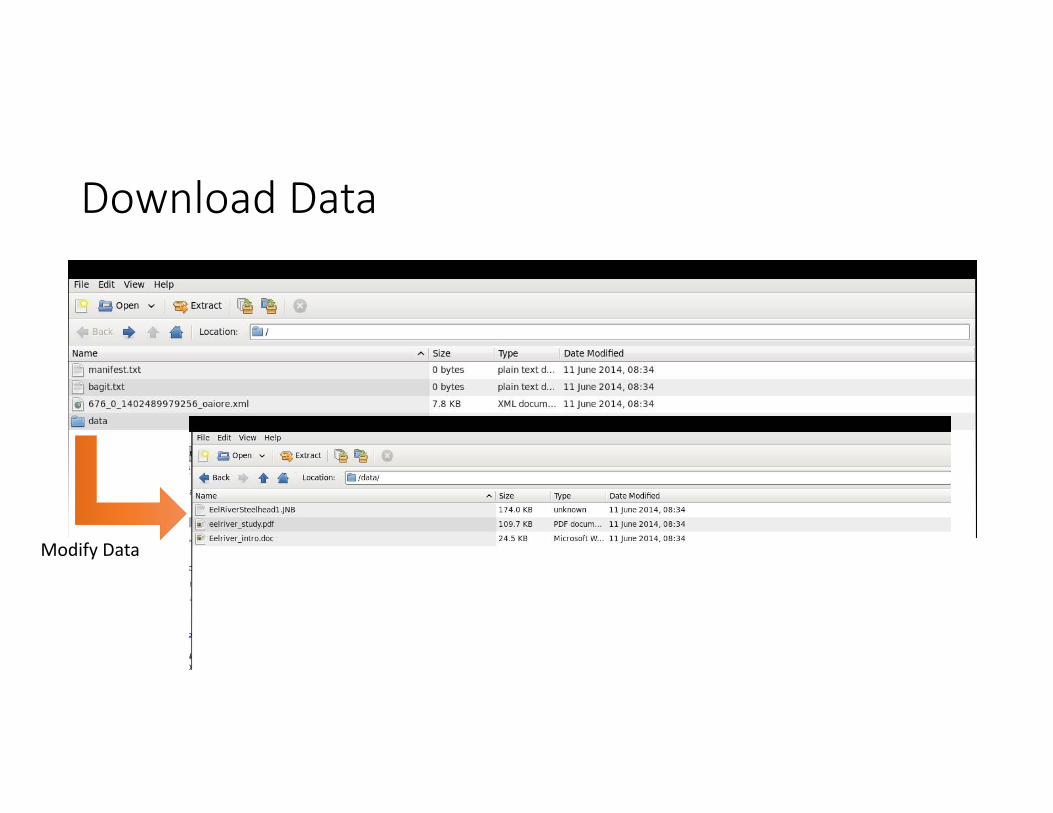
Download Data
Modify Data
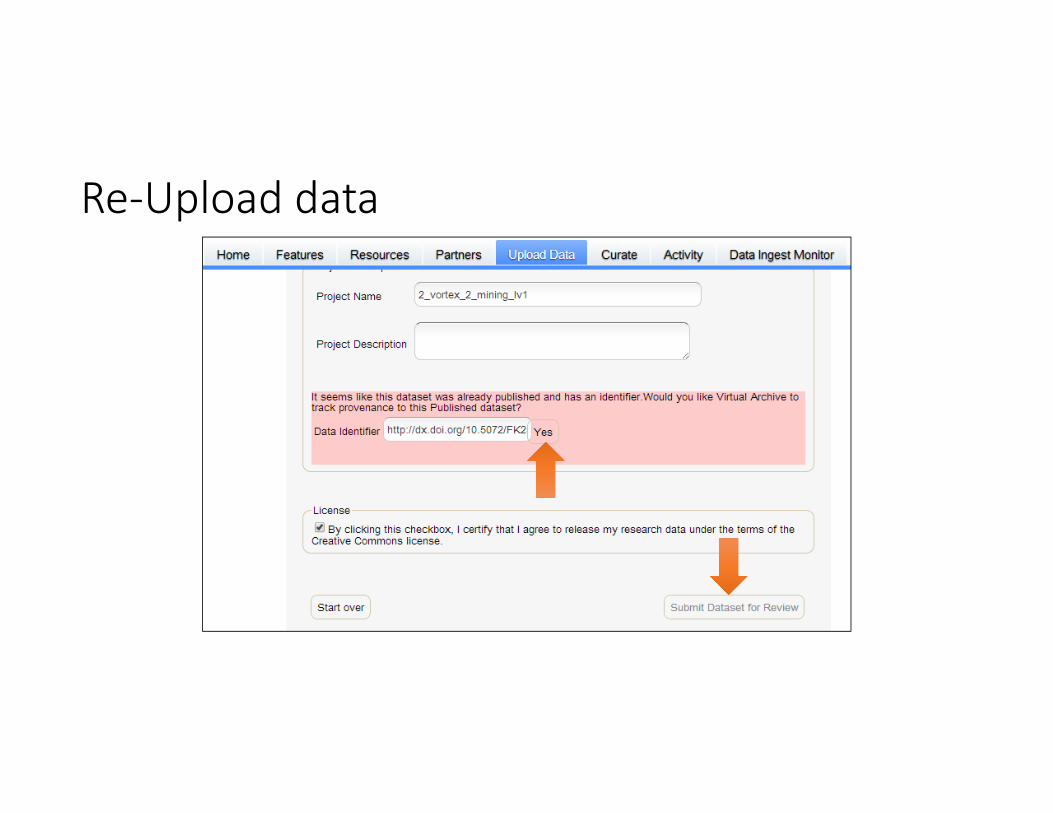
Re‐Upload data

Access Curation Queue

Approve and Publish
Publish

Check Activity
• Go to activity tab• See activities performed (Curation time provenance)
• Click on the Research Object name to see details
Activity tab

Check Provenance Graph
Provenance between 2 published objects (derivation)

Thank You





























