Embed Size (px)
Citation preview

Pointingthe Unknown Words
1
ACL 2016
Pointing the Unknown Words
Caglar Gulcehre
Universite de MontrealSungjin Ahn
Universite de MontrealRamesh Nallapati
IBM T.J. Watson Research
Bowen Zhou
IBM T.J. Watson ResearchYoshua Bengio
Universite de MontrealCIFAR Senior Fellow
Abstract
The problem of rare and unknown wordsis an important issue that can potentiallyeffect the performance of many NLP sys-tems, including both the traditional count-based and the deep learning models. Wepropose a novel way to deal with the rareand unseen words for the neural networkmodels using attention. Our model usestwo softmax layers in order to predict thenext word in conditional language mod-els: one predicts the location of a wordin the source sentence, and the other pre-dicts a word in the shortlist vocabulary. Ateach time-step, the decision of which soft-max layer to use choose adaptively madeby an MLP which is conditioned on thecontext. We motivate our work from a psy-chological evidence that humans naturallyhave a tendency to point towards objects inthe context or the environment when thename of an object is not known. We ob-serve improvements on two tasks, neuralmachine translation on the Europarl En-glish to French parallel corpora and textsummarization on the Gigaword datasetusing our proposed model.
1 Introduction
Words are the basic input/output units in most ofthe NLP systems, and thus the ability to cover alarge number of words is a key to building a ro-bust NLP system. However, considering that (i)the number of all words in a language includingnamed entities is very large and that (ii) languageitself is an evolving system (people create newwords), this can be a challenging problem.
A common approach followed by the recentneural network based NLP systems is to use a
softmax output layer where each of the output di-mension corresponds to a word in a predefinedword-shortlist. Because computing high dimen-sional softmax is computationally expensive, inpractice the shortlist is limited to have only top-K most frequent words in the training corpus. Allother words are then replaced by a special word,called the unknown word (UNK).
The shortlist approach has two fundamentalproblems. The first problem, which is known asthe rare word problem, is that some of the wordsin the shortlist occur less frequently in the train-ing set and thus are difficult to learn a good repre-sentation, resulting in poor performance. Second,it is obvious that we can lose some important in-formation by mapping different words to a singledummy token UNK. Even if we have a very largeshortlist including all unique words in the trainingset, it does not necessarily improve the test perfor-mance, because there still exists a chance to see anunknown word at test time. This is known as theunknown word problem. In addition, increasingthe shortlist size mostly leads to increasing rarewords due to Zipf’s Law.
These two problems can be particularly criticalin language understanding tasks such as factoidquestion answering (Bordes et al., 2015) where thewords that we are interested in are often named en-tities which are usually unknown or rare words.
In a similar situation, where we have a limitedinformation on how to call an object of interest, itseems that humans (and also some primates) havean efficient behavioral mechanism of drawing at-tention to the object: pointing (Matthews et al.,2012). Pointing makes it possible to deliver in-formation and to associate context to a particularobject without knowing how to call it. In partic-ular, human infants use pointing as a fundamentalcommunication tool (Tomasello et al., 2007).
In this paper, inspired by the pointing behav-
arX
iv:1
603.
0814
8v3
[cs.C
L] 2
1 A
ug 2
016
Pointing the Unknown Words
Caglar Gulcehre
Universite de MontrealSungjin Ahn
Universite de MontrealRamesh Nallapati
IBM T.J. Watson Research
Bowen Zhou
IBM T.J. Watson ResearchYoshua Bengio
Universite de MontrealCIFAR Senior Fellow
Abstract
The problem of rare and unknown wordsis an important issue that can potentiallyeffect the performance of many NLP sys-tems, including both the traditional count-based and the deep learning models. Wepropose a novel way to deal with the rareand unseen words for the neural networkmodels using attention. Our model usestwo softmax layers in order to predict thenext word in conditional language mod-els: one predicts the location of a wordin the source sentence, and the other pre-dicts a word in the shortlist vocabulary. Ateach time-step, the decision of which soft-max layer to use choose adaptively madeby an MLP which is conditioned on thecontext. We motivate our work from a psy-chological evidence that humans naturallyhave a tendency to point towards objects inthe context or the environment when thename of an object is not known. We ob-serve improvements on two tasks, neuralmachine translation on the Europarl En-glish to French parallel corpora and textsummarization on the Gigaword datasetusing our proposed model.
1 Introduction
Words are the basic input/output units in most ofthe NLP systems, and thus the ability to cover alarge number of words is a key to building a ro-bust NLP system. However, considering that (i)the number of all words in a language includingnamed entities is very large and that (ii) languageitself is an evolving system (people create newwords), this can be a challenging problem.
A common approach followed by the recentneural network based NLP systems is to use a
softmax output layer where each of the output di-mension corresponds to a word in a predefinedword-shortlist. Because computing high dimen-sional softmax is computationally expensive, inpractice the shortlist is limited to have only top-K most frequent words in the training corpus. Allother words are then replaced by a special word,called the unknown word (UNK).
The shortlist approach has two fundamentalproblems. The first problem, which is known asthe rare word problem, is that some of the wordsin the shortlist occur less frequently in the train-ing set and thus are difficult to learn a good repre-sentation, resulting in poor performance. Second,it is obvious that we can lose some important in-formation by mapping different words to a singledummy token UNK. Even if we have a very largeshortlist including all unique words in the trainingset, it does not necessarily improve the test perfor-mance, because there still exists a chance to see anunknown word at test time. This is known as theunknown word problem. In addition, increasingthe shortlist size mostly leads to increasing rarewords due to Zipf’s Law.
These two problems can be particularly criticalin language understanding tasks such as factoidquestion answering (Bordes et al., 2015) where thewords that we are interested in are often named en-tities which are usually unknown or rare words.
In a similar situation, where we have a limitedinformation on how to call an object of interest, itseems that humans (and also some primates) havean efficient behavioral mechanism of drawing at-tention to the object: pointing (Matthews et al.,2012). Pointing makes it possible to deliver in-formation and to associate context to a particularobject without knowing how to call it. In partic-ular, human infants use pointing as a fundamentalcommunication tool (Tomasello et al., 2007).
In this paper, inspired by the pointing behav-
arX
iv:1
603.
0814
8v3
[cs.C
L] 2
1 A
ug 2
016

2
ior of humans and recent advances in the atten-tion mechanism (Bahdanau et al., 2014) and thepointer networks (Vinyals et al., 2015), we pro-pose a novel method to deal with the rare or un-known word problem. The basic idea is that wecan see in many NLP problems as a task of predict-ing target text given context text, where some ofthe target words appear in the context as well. Weobserve that in this case we can make the modellearn to point a word in the context and copy it tothe target text, as well as when to point. For exam-ple, in machine translation, we can see the sourcesentence as the context, and the target sentence aswhat we need to predict. In Figure 1, we showan example depiction of how words can be copiedfrom source to target in machine translation. Al-though the source and target languages are differ-ent, many of the words such as named entities areusually represented by the same characters in bothlanguages, making it possible to copy. Similarly,in text summarization, it is natural to use somewords in the original text in the summarized textas well.
Specifically, to predict a target word at eachtimestep, our model first determines the source ofthe word generation, that is, on whether to takeone from a predefined shortlist or to copy one fromthe context. For the former, we apply the typicalsoftmax operation, and for the latter, we use theattention mechanism to obtain the pointing soft-max probability over the context words and pickthe one of high probability. The model learns thisdecision so as to use the pointing only when thecontext includes a word that can be copied to thetarget. This way, our model can predict even thewords which are not in the shortlist, as long asit appears in the context. Although some of thewords still need to be labeled as UNK, i.e., if it isneither in the shortlist nor in the context, in ex-periments we show that this learning when and
where to point improves the performance in ma-chine translation and text summarization.
The rest of the paper is organized as follows. Inthe next section, we review the related works in-cluding pointer networks and previous approachesto the rare/unknown problem. In Section 3, wereview the neural machine translation with atten-tion mechanism which is the baseline in our ex-periments. Then, in Section 4, we propose ourmethod dealing with the rare/unknown word prob-lem, called the Pointer Softmax (PS). The exper-
Guillaume et Cesar ont une voiture bleue a Lausanne.
Guillaume and Cesar have a blue car in Lausanne.Copy Copy Copy
French:
English:
Figure 1: An example of how copying can happenfor machine translation. Common words that ap-pear both in source and the target can directly becopied from input to source. The rest of the un-known in the target can be copied from the inputafter being translated with a dictionary.
imental results are provided in the Section 5 andwe conclude our work in Section 6.
2 Related Work
The attention-based pointing mechanism is intro-duced first in the pointer networks (Vinyals et al.,2015). In the pointer networks, the output space ofthe target sequence is constrained to be the obser-vations in the input sequence (not the input space).Instead of having a fixed dimension softmax out-put layer, softmax outputs of varying dimension isdynamically computed for each input sequence insuch a way to maximize the attention probabilityof the target input. However, its applicability israther limited because, unlike our model, there isno option to choose whether to point or not; it al-ways points. In this sense, we can see the pointernetworks as a special case of our model where wealways choose to point a context word.
Several approaches have been proposed towardssolving the rare words/unknown words problem,which can be broadly divided into three categories.The first category of the approaches focuses onimproving the computation speed of the softmaxoutput so that it can maintain a very large vocabu-lary. Because this only increases the shortlist size,it helps to mitigate the unknown word problem,but still suffers from the rare word problem. Thehierarchical softmax (Morin and Bengio, 2005),importance sampling (Bengio and Senecal, 2008;Jean et al., 2014), and the noise contrastive esti-mation (Gutmann and Hyvarinen, 2012; Mnih andKavukcuoglu, 2013) methods are in the class.
The second category, where our proposedmethod also belongs to, uses information from thecontext. Notable works are (Luong et al., 2015)and (Hermann et al., 2015). In particular, ap-plying to machine translation task, (Luong et al.,2015) learns to point some words in source sen-tence and copy it to the target sentence, similarly

•
•
•
• V
• •
���
killed a man yesterday . [eos]!
John killed a man yesterday . !
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
pt w Whp
Whp(w) bhp(w) softmax
Whp bhp
pt(w) = softmax(Whp(w)ht + bhp(w)) (18)
Whp
d′e
d′e = Wdyde + bdy (19)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (20)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp Whp(w)
bhp(w) softmax Z
Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
!man �
a �
a ���
man !�
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp Whp(w)
bhp(w) softmax Z
Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp ∈ RV×N V
N Whp(w) bhp(w)
softmax Z Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp ∈ RV×N V
N Whp(w) bhp(w)
softmax Z Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp ∈ RV×N V
N Whp(w) bhp(w)
softmax Z Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp ∈ RV×N V
N Whp(w) bhp(w)
softmax Z Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp Whp(w)
bhp(w) softmax Z
Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
3

•
•
•
• V
• •
���
killed a man yesterday . [eos]!
John killed a man yesterday . !
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
pt w Whp
Whp(w) bhp(w) softmax
Whp bhp
pt(w) = softmax(Whp(w)ht + bhp(w)) (18)
Whp
d′e
d′e = Wdyde + bdy (19)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (20)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp Whp(w)
bhp(w) softmax Z
Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
!man �
a �
a ���
man !�
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp Whp(w)
bhp(w) softmax Z
Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp ∈ RV×N V
N Whp(w) bhp(w)
softmax Z Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp ∈ RV×N V
N Whp(w) bhp(w)
softmax Z Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp ∈ RV×N V
N Whp(w) bhp(w)
softmax Z Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp ∈ RV×N V
N Whp(w) bhp(w)
softmax Z Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
• V T
•
•
•Pointer Softmax
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp ∈ RV×N V
N Whp(w) bhp(w)
softmax Z Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
T
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp Whp(w)
bhp(w) softmax Z
Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp Whp(w)
bhp(w) softmax Z
Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
・
4

•
5
Published as a conference paper at ICLR 2015
The decoder is often trained to predict the next word y
t
0 given the context vector c and all thepreviously predicted words {y1, · · · , yt0�1}. In other words, the decoder defines a probability overthe translation y by decomposing the joint probability into the ordered conditionals:
p(y) =
TY
t=1
p(y
t
| {y1, · · · , yt�1} , c), (2)
where y =
�y1, · · · , yT
y
�. With an RNN, each conditional probability is modeled as
p(y
t
| {y1, · · · , yt�1} , c) = g(y
t�1, st, c), (3)
where g is a nonlinear, potentially multi-layered, function that outputs the probability of yt
, and s
t
isthe hidden state of the RNN. It should be noted that other architectures such as a hybrid of an RNNand a de-convolutional neural network can be used (Kalchbrenner and Blunsom, 2013).
3 LEARNING TO ALIGN AND TRANSLATE
In this section, we propose a novel architecture for neural machine translation. The new architectureconsists of a bidirectional RNN as an encoder (Sec. 3.2) and a decoder that emulates searchingthrough a source sentence during decoding a translation (Sec. 3.1).
3.1 DECODER: GENERAL DESCRIPTION
x1 x2 x3 xT
+αt,1αt,2 αt,3
αt,T
h1 h2 h3 hT
h1 h2 h3 hT
st-1 s t
Figure 1: The graphical illus-tration of the proposed modeltrying to generate the t-th tar-get word y
t
given a sourcesentence (x1, x2, . . . , xT
).
In a new model architecture, we define each conditional probabilityin Eq. (2) as:
p(y
i
|y1, . . . , yi�1,x) = g(y
i�1, si, ci), (4)
where s
i
is an RNN hidden state for time i, computed by
s
i
= f(s
i�1, yi�1, ci).
It should be noted that unlike the existing encoder–decoder ap-proach (see Eq. (2)), here the probability is conditioned on a distinctcontext vector c
i
for each target word y
i
.
The context vector c
i
depends on a sequence of annotations(h1, · · · , hT
x
) to which an encoder maps the input sentence. Eachannotation h
i
contains information about the whole input sequencewith a strong focus on the parts surrounding the i-th word of theinput sequence. We explain in detail how the annotations are com-puted in the next section.
The context vector ci
is, then, computed as a weighted sum of theseannotations h
i
:
c
i
=
T
xX
j=1
↵
ij
h
j
. (5)
The weight ↵ij
of each annotation h
j
is computed by
↵
ij
=
exp (e
ij
)
PT
x
k=1 exp (eik), (6)
wheree
ij
= a(s
i�1, hj
)
is an alignment model which scores how well the inputs around position j and the output at positioni match. The score is based on the RNN hidden state s
i�1 (just before emitting y
i
, Eq. (4)) and thej-th annotation h
j
of the input sentence.
We parametrize the alignment model a as a feedforward neural network which is jointly trained withall the other components of the proposed system. Note that unlike in traditional machine translation,
3
Published as a conference paper at ICLR 2015
The decoder is often trained to predict the next word y
t
0 given the context vector c and all thepreviously predicted words {y1, · · · , yt0�1}. In other words, the decoder defines a probability overthe translation y by decomposing the joint probability into the ordered conditionals:
p(y) =
TY
t=1
p(y
t
| {y1, · · · , yt�1} , c), (2)
where y =
�y1, · · · , yT
y
�. With an RNN, each conditional probability is modeled as
p(y
t
| {y1, · · · , yt�1} , c) = g(y
t�1, st, c), (3)
where g is a nonlinear, potentially multi-layered, function that outputs the probability of yt
, and s
t
isthe hidden state of the RNN. It should be noted that other architectures such as a hybrid of an RNNand a de-convolutional neural network can be used (Kalchbrenner and Blunsom, 2013).
3 LEARNING TO ALIGN AND TRANSLATE
In this section, we propose a novel architecture for neural machine translation. The new architectureconsists of a bidirectional RNN as an encoder (Sec. 3.2) and a decoder that emulates searchingthrough a source sentence during decoding a translation (Sec. 3.1).
3.1 DECODER: GENERAL DESCRIPTION
Figure 1: The graphical illus-tration of the proposed modeltrying to generate the t-th tar-get word y
t
given a sourcesentence (x1, x2, . . . , xT
).
In a new model architecture, we define each conditional probabilityin Eq. (2) as:
p(y
i
|y1, . . . , yi�1,x) = g(y
i�1, si, ci), (4)
where s
i
is an RNN hidden state for time i, computed by
s
i
= f(s
i�1, yi�1, ci).
It should be noted that unlike the existing encoder–decoder ap-proach (see Eq. (2)), here the probability is conditioned on a distinctcontext vector c
i
for each target word y
i
.
The context vector c
i
depends on a sequence of annotations(h1, · · · , hT
x
) to which an encoder maps the input sentence. Eachannotation h
i
contains information about the whole input sequencewith a strong focus on the parts surrounding the i-th word of theinput sequence. We explain in detail how the annotations are com-puted in the next section.
The context vector ci
is, then, computed as a weighted sum of theseannotations h
i
:
c
i
=
T
xX
j=1
↵
ij
h
j
. (5)
The weight ↵ij
of each annotation h
j
is computed by
↵
ij
=
exp (e
ij
)
PT
x
k=1 exp (eik), (6)
wheree
ij
= a(s
i�1, hj
)
is an alignment model which scores how well the inputs around position j and the output at positioni match. The score is based on the RNN hidden state s
i�1 (just before emitting y
i
, Eq. (4)) and thej-th annotation h
j
of the input sentence.
We parametrize the alignment model a as a feedforward neural network which is jointly trained withall the other components of the proposed system. Note that unlike in traditional machine translation,
3
Published as a conference paper at ICLR 2015
The decoder is often trained to predict the next word y
t
0 given the context vector c and all thepreviously predicted words {y1, · · · , yt0�1}. In other words, the decoder defines a probability overthe translation y by decomposing the joint probability into the ordered conditionals:
p(y) =
TY
t=1
p(y
t
| {y1, · · · , yt�1} , c), (2)
where y =
�y1, · · · , yT
y
�. With an RNN, each conditional probability is modeled as
p(y
t
| {y1, · · · , yt�1} , c) = g(y
t�1, st, c), (3)
where g is a nonlinear, potentially multi-layered, function that outputs the probability of yt
, and s
t
isthe hidden state of the RNN. It should be noted that other architectures such as a hybrid of an RNNand a de-convolutional neural network can be used (Kalchbrenner and Blunsom, 2013).
3 LEARNING TO ALIGN AND TRANSLATE
In this section, we propose a novel architecture for neural machine translation. The new architectureconsists of a bidirectional RNN as an encoder (Sec. 3.2) and a decoder that emulates searchingthrough a source sentence during decoding a translation (Sec. 3.1).
3.1 DECODER: GENERAL DESCRIPTION
Figure 1: The graphical illus-tration of the proposed modeltrying to generate the t-th tar-get word y
t
given a sourcesentence (x1, x2, . . . , xT
).
In a new model architecture, we define each conditional probabilityin Eq. (2) as:
p(y
i
|y1, . . . , yi�1,x) = g(y
i�1, si, ci), (4)
where s
i
is an RNN hidden state for time i, computed by
s
i
= f(s
i�1, yi�1, ci).
It should be noted that unlike the existing encoder–decoder ap-proach (see Eq. (2)), here the probability is conditioned on a distinctcontext vector c
i
for each target word y
i
.
The context vector c
i
depends on a sequence of annotations(h1, · · · , hT
x
) to which an encoder maps the input sentence. Eachannotation h
i
contains information about the whole input sequencewith a strong focus on the parts surrounding the i-th word of theinput sequence. We explain in detail how the annotations are com-puted in the next section.
The context vector ci
is, then, computed as a weighted sum of theseannotations h
i
:
c
i
=
T
xX
j=1
↵
ij
h
j
. (5)
The weight ↵ij
of each annotation h
j
is computed by
↵
ij
=
exp (e
ij
)
PT
x
k=1 exp (eik), (6)
wheree
ij
= a(s
i�1, hj
)
is an alignment model which scores how well the inputs around position j and the output at positioni match. The score is based on the RNN hidden state s
i�1 (just before emitting y
i
, Eq. (4)) and thej-th annotation h
j
of the input sentence.
We parametrize the alignment model a as a feedforward neural network which is jointly trained withall the other components of the proposed system. Note that unlike in traditional machine translation,
3
Published as a conference paper at ICLR 2015
The decoder is often trained to predict the next word y
t
0 given the context vector c and all thepreviously predicted words {y1, · · · , yt0�1}. In other words, the decoder defines a probability overthe translation y by decomposing the joint probability into the ordered conditionals:
p(y) =
TY
t=1
p(y
t
| {y1, · · · , yt�1} , c), (2)
where y =
�y1, · · · , yT
y
�. With an RNN, each conditional probability is modeled as
p(y
t
| {y1, · · · , yt�1} , c) = g(y
t�1, st, c), (3)
where g is a nonlinear, potentially multi-layered, function that outputs the probability of yt
, and s
t
isthe hidden state of the RNN. It should be noted that other architectures such as a hybrid of an RNNand a de-convolutional neural network can be used (Kalchbrenner and Blunsom, 2013).
3 LEARNING TO ALIGN AND TRANSLATE
In this section, we propose a novel architecture for neural machine translation. The new architectureconsists of a bidirectional RNN as an encoder (Sec. 3.2) and a decoder that emulates searchingthrough a source sentence during decoding a translation (Sec. 3.1).
3.1 DECODER: GENERAL DESCRIPTION
Figure 1: The graphical illus-tration of the proposed modeltrying to generate the t-th tar-get word y
t
given a sourcesentence (x1, x2, . . . , xT
).
In a new model architecture, we define each conditional probabilityin Eq. (2) as:
p(y
i
|y1, . . . , yi�1,x) = g(y
i�1, si, ci), (4)
where s
i
is an RNN hidden state for time i, computed by
s
i
= f(s
i�1, yi�1, ci).
It should be noted that unlike the existing encoder–decoder ap-proach (see Eq. (2)), here the probability is conditioned on a distinctcontext vector c
i
for each target word y
i
.
The context vector c
i
depends on a sequence of annotations(h1, · · · , hT
x
) to which an encoder maps the input sentence. Eachannotation h
i
contains information about the whole input sequencewith a strong focus on the parts surrounding the i-th word of theinput sequence. We explain in detail how the annotations are com-puted in the next section.
The context vector ci
is, then, computed as a weighted sum of theseannotations h
i
:
c
i
=
T
xX
j=1
↵
ij
h
j
. (5)
The weight ↵ij
of each annotation h
j
is computed by
↵
ij
=
exp (e
ij
)
PT
x
k=1 exp (eik), (6)
wheree
ij
= a(s
i�1, hj
)
is an alignment model which scores how well the inputs around position j and the output at positioni match. The score is based on the RNN hidden state s
i�1 (just before emitting y
i
, Eq. (4)) and thej-th annotation h
j
of the input sentence.
We parametrize the alignment model a as a feedforward neural network which is jointly trained withall the other components of the proposed system. Note that unlike in traditional machine translation,
3
Published as a conference paper at ICLR 2015
The decoder is often trained to predict the next word y
t
0 given the context vector c and all thepreviously predicted words {y1, · · · , yt0�1}. In other words, the decoder defines a probability overthe translation y by decomposing the joint probability into the ordered conditionals:
p(y) =
TY
t=1
p(y
t
| {y1, · · · , yt�1} , c), (2)
where y =
�y1, · · · , yT
y
�. With an RNN, each conditional probability is modeled as
p(y
t
| {y1, · · · , yt�1} , c) = g(y
t�1, st, c), (3)
where g is a nonlinear, potentially multi-layered, function that outputs the probability of yt
, and s
t
isthe hidden state of the RNN. It should be noted that other architectures such as a hybrid of an RNNand a de-convolutional neural network can be used (Kalchbrenner and Blunsom, 2013).
3 LEARNING TO ALIGN AND TRANSLATE
In this section, we propose a novel architecture for neural machine translation. The new architectureconsists of a bidirectional RNN as an encoder (Sec. 3.2) and a decoder that emulates searchingthrough a source sentence during decoding a translation (Sec. 3.1).
3.1 DECODER: GENERAL DESCRIPTION
Figure 1: The graphical illus-tration of the proposed modeltrying to generate the t-th tar-get word y
t
given a sourcesentence (x1, x2, . . . , xT
).
In a new model architecture, we define each conditional probabilityin Eq. (2) as:
p(y
i
|y1, . . . , yi�1,x) = g(y
i�1, si, ci), (4)
where s
i
is an RNN hidden state for time i, computed by
s
i
= f(s
i�1, yi�1, ci).
It should be noted that unlike the existing encoder–decoder ap-proach (see Eq. (2)), here the probability is conditioned on a distinctcontext vector c
i
for each target word y
i
.
The context vector c
i
depends on a sequence of annotations(h1, · · · , hT
x
) to which an encoder maps the input sentence. Eachannotation h
i
contains information about the whole input sequencewith a strong focus on the parts surrounding the i-th word of theinput sequence. We explain in detail how the annotations are com-puted in the next section.
The context vector ci
is, then, computed as a weighted sum of theseannotations h
i
:
c
i
=
T
xX
j=1
↵
ij
h
j
. (5)
The weight ↵ij
of each annotation h
j
is computed by
↵
ij
=
exp (e
ij
)
PT
x
k=1 exp (eik), (6)
wheree
ij
= a(s
i�1, hj
)
is an alignment model which scores how well the inputs around position j and the output at positioni match. The score is based on the RNN hidden state s
i�1 (just before emitting y
i
, Eq. (4)) and thej-th annotation h
j
of the input sentence.
We parametrize the alignment model a as a feedforward neural network which is jointly trained withall the other components of the proposed system. Note that unlike in traditional machine translation,
3
to our method. However, it does not use atten-tion mechanism, and by having fixed sized soft-max output over the relative pointing range (e.g.,-7, . . . , -1, 0, 1, . . . , 7), their model (the Posi-tional All model) has a limitation in applying tomore general problems such as summarization andquestion answering, where, unlike machine trans-lation, the length of the context and the pointinglocations in the context can vary dramatically. Inquestion answering setting, (Hermann et al., 2015)have used placeholders on named entities in thecontext. However, the placeholder id is directlypredicted in the softmax output rather than predict-ing its location in the context.
The third category of the approaches changesthe unit of input/output itself from words to asmaller resolution such as characters (Graves,2013) or bytecodes (Sennrich et al., 2015; Gillicket al., 2015). Although this approach has themain advantage that it could suffer less from therare/unknown word problem, the training usuallybecomes much harder because the length of se-quences significantly increases.
Simultaneously to our work, (Gu et al., 2016)and (Cheng and Lapata, 2016) proposed modelsthat learn to copy from source to target and bothpapers analyzed their models on summarizationtasks.
3 Neural Machine Translation Model
with Attention
As the baseline neural machine translation sys-tem, we use the model proposed by (Bahdanau etal., 2014) that learns to (soft-)align and translatejointly. We refer this model as NMT.
The encoder of the NMT is a bidirectionalRNN (Schuster and Paliwal, 1997). The forwardRNN reads input sequence x = (x1, . . . , x
T
)
in left-to-right direction, resulting in a sequenceof hidden states (
�!h 1, . . . ,
�!h
T
). The backwardRNN reads x in the reversed direction and outputs(
�h 1, . . . ,
�h
T
). We then concatenate the hiddenstates of forward and backward RNNs at each timestep and obtain a sequence of annotation vectors(h1, . . . ,h
T
) where h
j
=
h�!h
j
|| �h
j
i. Here, ||
denotes the concatenation operator. Thus, each an-notation vector h
j
encodes information about thej-th word with respect to all the other surroundingwords in both directions.
In the decoder, we usually use gated recur-rent unit (GRU) (Cho et al., 2014; Chung et al.,
2014). Specifically, at each time-step t, the soft-alignment mechanism first computes the relevanceweight e
tj
which determines the contribution ofannotation vector h
j
to the t-th target word. Weuse a non-linear mapping f (e.g., MLP) whichtakes h
j
, the previous decoder’s hidden state s
t�1
and the previous output yt�1 as input:
e
tj
= f(s
t�1,hj
, y
t�1).
The outputs etj
are then normalized as follows:
l
tj
=
exp(etj
)
PT
k=1 exp(etk
)
. (1)
We call ltj
as the relevance score, or the align-ment weight, of the j-th annotation vector.
The relevance scores are used to get the context
vector c
t
of the t-th target word in the translation:
c
t
=
TX
j=1
l
tj
h
j
,
The hidden state of the decoder st
is computedbased on the previous hidden state s
t�1, the con-text vector c
t
and the output word of the previoustime-step y
t�1:
s
t
= f
r
(s
t�1, yt�1, ct), (2)
where f
r
is GRU.We use a deep output layer (Pascanu et al.,
2013) to compute the conditional distribution overwords:
p(y
t
= a|y<t
,x) /
exp
⇣
a
(Wo
,bo
)fo(st, yt�1, ct)
⌘,
(3)
where W is a learned weight matrix and b is abias of the output layer. f
o
is a single-layer feed-forward neural network. (W
o
,bo
)(·) is a functionthat performs an affine transformation on its input.And the superscript a in a indicates the a-th col-umn vector of .
The whole model, including both the encoderand the decoder, is jointly trained to maximize the(conditional) log-likelihood of target sequencesgiven input sequences, where the training corpusis a set of (x
n
,y
n
)’s. Figure 2 illustrates the ar-chitecture of the NMT.
Published as a conference paper at ICLR 2015
The decoder is often trained to predict the next word y
t
0 given the context vector c and all thepreviously predicted words {y1, · · · , yt0�1}. In other words, the decoder defines a probability overthe translation y by decomposing the joint probability into the ordered conditionals:
p(y) =
TY
t=1
p(y
t
| {y1, · · · , yt�1} , c), (2)
where y =
�y1, · · · , yT
y
�. With an RNN, each conditional probability is modeled as
p(y
t
| {y1, · · · , yt�1} , c) = g(y
t�1, st, c), (3)
where g is a nonlinear, potentially multi-layered, function that outputs the probability of yt
, and s
t
isthe hidden state of the RNN. It should be noted that other architectures such as a hybrid of an RNNand a de-convolutional neural network can be used (Kalchbrenner and Blunsom, 2013).
3 LEARNING TO ALIGN AND TRANSLATE
In this section, we propose a novel architecture for neural machine translation. The new architectureconsists of a bidirectional RNN as an encoder (Sec. 3.2) and a decoder that emulates searchingthrough a source sentence during decoding a translation (Sec. 3.1).
3.1 DECODER: GENERAL DESCRIPTION
Figure 1: The graphical illus-tration of the proposed modeltrying to generate the t-th tar-get word y
t
given a sourcesentence (x1, x2, . . . , xT
).
In a new model architecture, we define each conditional probabilityin Eq. (2) as:
p(y
i
|y1, . . . , yi�1,x) = g(y
i�1, si, ci), (4)
where s
i
is an RNN hidden state for time i, computed by
s
i
= f(s
i�1, yi�1, ci).
It should be noted that unlike the existing encoder–decoder ap-proach (see Eq. (2)), here the probability is conditioned on a distinctcontext vector c
i
for each target word y
i
.
The context vector c
i
depends on a sequence of annotations(h1, · · · , hT
x
) to which an encoder maps the input sentence. Eachannotation h
i
contains information about the whole input sequencewith a strong focus on the parts surrounding the i-th word of theinput sequence. We explain in detail how the annotations are com-puted in the next section.
The context vector ci
is, then, computed as a weighted sum of theseannotations h
i
:
c
i
=
T
xX
j=1
↵
ij
h
j
. (5)
The weight ↵ij
of each annotation h
j
is computed by
↵
ij
=
exp (e
ij
)
PT
x
k=1 exp (eik), (6)
wheree
ij
= a(s
i�1, hj
)
is an alignment model which scores how well the inputs around position j and the output at positioni match. The score is based on the RNN hidden state s
i�1 (just before emitting y
i
, Eq. (4)) and thej-th annotation h
j
of the input sentence.
We parametrize the alignment model a as a feedforward neural network which is jointly trained withall the other components of the proposed system. Note that unlike in traditional machine translation,
3
(t=i)
[Bahdanau+15]
Publ
ished
asa
conf
eren
cepa
pera
tICL
R20
15
The
deco
der
isof
ten
train
edto
pred
ictt
hene
xtw
ordy
t
0gi
ven
the
cont
extv
ecto
rc
and
allt
hepr
evio
usly
pred
icte
dw
ords
{y1,···,
y
t
0 �1}.
Inot
herw
ords
,the
deco
derd
efine
sapr
obab
ility
over
the
trans
latio
ny
byde
com
posin
gth
ejo
intp
roba
bilit
yin
toth
eor
dere
dco
nditi
onal
s:
p(y)=
T Y
t=1
p(y
t
|{y
1,···,
y
t�1},
c),
(2)
whe
rey=
� y
1,···,
y
T
y
� .With
anRN
N,e
ach
cond
ition
alpr
obab
ility
ism
odel
edas
p(y
t
|{y
1,···,
y
t�1},
c)=
g(y
t�1,s
t
,c),
(3)
whe
reg
isan
onlin
ear,
pote
ntia
llym
ulti-
laye
red,
func
tion
that
outp
utst
hepr
obab
ility
ofy
t
,and
s
t
isth
ehi
dden
state
ofth
eRN
N.I
tsho
uld
beno
ted
that
othe
rarc
hite
ctur
essu
chas
ahy
brid
ofan
RNN
and
ade
-con
volu
tiona
lneu
raln
etw
ork
can
beus
ed(K
alch
bren
nera
ndBl
unso
m,2
013)
.
3LE
AR
NIN
GTO
ALI
GN
AN
DTR
AN
SLAT
E
Inth
isse
ctio
n,w
epro
pose
anov
elar
chite
ctur
efor
neur
alm
achi
netra
nsla
tion.
Then
ewar
chite
ctur
eco
nsist
sof
abi
dire
ctio
nalR
NN
asan
enco
der
(Sec
.3.2
)an
da
deco
der
that
emul
ates
sear
chin
gth
roug
ha
sour
cese
nten
cedu
ring
deco
ding
atra
nsla
tion
(Sec
.3.1
).
3.1
DEC
OD
ER:G
ENER
AL
DES
CR
IPTI
ON
s t
Figu
re1:
Theg
raph
ical
illus
-tra
tion
ofth
epr
opos
edm
odel
tryin
gto
gene
rate
thet-th
tar-
get
wor
dy
t
give
na
sour
cese
nten
ce(x
1,x
2,...,x
T
).
Ina
new
mod
elar
chite
ctur
e,w
ede
fine
each
cond
ition
alpr
obab
ility
inEq
.(2)
as:
p(y
i
|y1,...,y
i�1,x)=
g(y
i�1,s
i
,c
i
),
(4)
whe
res
i
isan
RNN
hidd
ensta
tefo
rtim
ei,c
ompu
ted
by
s
i
=f(s
i�1,y
i�1,c
i
).
Itsh
ould
beno
ted
that
unlik
eth
eex
istin
gen
code
r–de
code
rap
-pr
oach
(see
Eq.(
2)),
here
thep
roba
bilit
yis
cond
ition
edon
adist
inct
cont
extv
ecto
rci
fore
ach
targ
etw
ordy
i
.
The
cont
ext
vect
orc
i
depe
nds
ona
sequ
ence
ofan
nota
tions
(h
1,···,
h
T
x
)to
whi
chan
enco
derm
apst
hein
puts
ente
nce.
Each
anno
tatio
nh
i
cont
ains
info
rmat
ion
abou
tthe
who
lein
puts
eque
nce
with
astr
ong
focu
son
the
parts
surro
undi
ngth
ei-th
wor
dof
the
inpu
tseq
uenc
e.W
eex
plai
nin
deta
ilho
wth
ean
nota
tions
are
com
-pu
ted
inth
ene
xtse
ctio
n.
Thec
onte
xtve
ctor
c
i
is,th
en,c
ompu
ted
asaw
eigh
ted
sum
ofth
ese
anno
tatio
nsh
i
:
c
i
=
T
x
X j=1
↵
ij
h
j
.(5
)
The
wei
ght↵
ij
ofea
chan
nota
tionh
j
isco
mpu
ted
by
↵
ij
=
exp(e
ij
)
PT
x
k=1exp(e
ik
)
,(6
)
whe
ree
ij
=a(s
i�1,h
j
)
isan
alig
nmen
tmod
elw
hich
scor
esho
ww
ellt
hein
puts
arou
ndpo
sitio
nj
and
the
outp
utat
posit
ion
im
atch
.The
scor
eis
base
don
the
RNN
hidd
ensta
tes
i�1
(just
befo
reem
ittin
gy
i
,Eq.
(4))
and
the
j-th
anno
tatio
nh
j
ofth
ein
puts
ente
nce.
Wep
aram
etriz
ethe
alig
nmen
tmod
ela
asaf
eedf
orw
ard
neur
alne
twor
kw
hich
isjo
intly
train
edw
ithal
lthe
othe
rcom
pone
ntso
fthe
prop
osed
syste
m.N
otet
hatu
nlik
ein
tradi
tiona
lmac
hine
trans
latio
n,
3
Publ
ishe
das
aco
nfer
ence
pape
ratI
CLR
2015
The
deco
der
isof
ten
train
edto
pred
ict
the
next
wor
dy
t
0gi
ven
the
cont
ext
vect
orc
and
all
the
prev
ious
lypr
edic
ted
wor
ds{y
1,···,
y
t
0 �1}.
Inot
herw
ords
,the
deco
derd
efine
sa
prob
abili
tyov
erth
etra
nsla
tiony
byde
com
posi
ngth
ejo
intp
roba
bilit
yin
toth
eor
dere
dco
nditi
onal
s:
p(y)=
T Y
t=1
p(y
t
|{y
1,···,
y
t�1},
c),
(2)
whe
rey=
� y
1,···,
y
T
y
� .With
anR
NN
,eac
hco
nditi
onal
prob
abili
tyis
mod
eled
as
p(y
t
|{y
1,···,
y
t�1},
c)=
g(y
t�1,s
t
,c),
(3)
whe
reg
isa
nonl
inea
r,po
tent
ially
mul
ti-la
yere
d,fu
nctio
nth
atou
tput
sthe
prob
abili
tyof
y
t
,and
s
t
isth
ehi
dden
stat
eof
the
RN
N.I
tsho
uld
beno
ted
that
othe
rarc
hite
ctur
essu
chas
ahy
brid
ofan
RN
Nan
da
de-c
onvo
lutio
naln
eura
lnet
wor
kca
nbe
used
(Kal
chbr
enne
rand
Blu
nsom
,201
3).
3L
EA
RN
ING
TO
AL
IGN
AN
DT
RA
NSL
AT
E
Inth
isse
ctio
n,w
epr
opos
ea
nove
larc
hite
ctur
efo
rneu
ralm
achi
netra
nsla
tion.
The
new
arch
itect
ure
cons
ists
ofa
bidi
rect
iona
lR
NN
asan
enco
der
(Sec
.3.2
)an
da
deco
der
that
emul
ates
sear
chin
gth
roug
ha
sour
cese
nten
cedu
ring
deco
ding
atra
nsla
tion
(Sec
.3.1
).
3.1
DE
CO
DE
R:
GE
NE
RA
LD
ESC
RIP
TIO
N
st
Figu
re1:
The
grap
hica
lillu
s-tra
tion
ofth
epr
opos
edm
odel
tryin
gto
gene
rate
thet-th
tar-
get
wor
dy
t
give
na
sour
cese
nten
ce(x
1,x
2,...,x
T
).
Ina
new
mod
elar
chite
ctur
e,w
ede
fine
each
cond
ition
alpr
obab
ility
inEq
.(2)
as:
p(y
i
|y1,...,y
i�1,x)=
g(y
i�1,s
i
,c
i
),
(4)
whe
res
i
isan
RN
Nhi
dden
stat
efo
rtim
ei,c
ompu
ted
by
s
i
=f(s
i�1,y
i�1,c
i
).
Itsh
ould
beno
ted
that
unlik
eth
eex
istin
gen
code
r–de
code
rap
-pr
oach
(see
Eq.(
2)),
here
the
prob
abili
tyis
cond
ition
edon
adi
stin
ctco
ntex
tvec
torc
i
fore
ach
targ
etw
ordy
i
.
The
cont
ext
vect
orc
i
depe
nds
ona
sequ
ence
ofan
nota
tions
(h
1,···,
h
T
x
)to
whi
chan
enco
derm
aps
the
inpu
tsen
tenc
e.Ea
chan
nota
tionh
i
cont
ains
info
rmat
ion
abou
tthe
who
lein
puts
eque
nce
with
ast
rong
focu
son
the
parts
surr
ound
ing
thei-th
wor
dof
the
inpu
tseq
uenc
e.W
eex
plai
nin
deta
ilho
wth
ean
nota
tions
are
com
-pu
ted
inth
ene
xtse
ctio
n.
The
cont
extv
ecto
rci
is,t
hen,
com
pute
das
aw
eigh
ted
sum
ofth
ese
anno
tatio
nsh
i
:
c
i
=
T
x
X j=1
↵
ij
h
j
.(5
)
The
wei
ght↵
ij
ofea
chan
nota
tionh
j
isco
mpu
ted
by
↵
ij
=
exp(e
ij
)
PT
x
k=1exp(e
ik
)
,(6
)
whe
ree
ij
=a(s
i�1,h
j
)
isan
alig
nmen
tmod
elw
hich
scor
esho
ww
ellt
hein
puts
arou
ndpo
sitio
nj
and
the
outp
utat
posi
tion
im
atch
.The
scor
eis
base
don
the
RN
Nhi
dden
stat
es
i�1
(just
befo
reem
ittin
gy
i
,Eq.
(4))
and
the
j-th
anno
tatio
nh
j
ofth
ein
puts
ente
nce.
We
para
met
rize
the
alig
nmen
tmod
ela
asa
feed
forw
ard
neur
alne
twor
kw
hich
isjo
intly
train
edw
ithal
lthe
othe
rcom
pone
ntso
fthe
prop
osed
syst
em.N
ote
that
unlik
ein
tradi
tiona
lmac
hine
trans
latio
n,
3
Publ
ished
asa
conf
eren
cepa
pera
tICL
R20
15
The
deco
der
isof
ten
train
edto
pred
ictt
hene
xtw
ordy
t
0gi
ven
the
cont
extv
ecto
rc
and
allt
hepr
evio
usly
pred
icte
dw
ords
{y1,···,
y
t
0 �1}.
Inot
herw
ords
,the
deco
derd
efine
sapr
obab
ility
over
the
trans
latio
ny
byde
com
posin
gth
ejo
intp
roba
bilit
yin
toth
eor
dere
dco
nditi
onal
s:
p(y)=
T Y
t=1
p(y
t
|{y
1,···,
y
t�1},
c),
(2)
whe
rey=
� y
1,···,
y
T
y
� .With
anRN
N,e
ach
cond
ition
alpr
obab
ility
ism
odel
edas
p(y
t
|{y
1,···,
y
t�1},
c)=
g(y
t�1,s
t
,c),
(3)
whe
reg
isan
onlin
ear,
pote
ntia
llym
ulti-
laye
red,
func
tion
that
outp
utst
hepr
obab
ility
ofy
t
,and
s
t
isth
ehi
dden
state
ofth
eRN
N.I
tsho
uld
beno
ted
that
othe
rarc
hite
ctur
essu
chas
ahy
brid
ofan
RNN
and
ade
-con
volu
tiona
lneu
raln
etw
ork
can
beus
ed(K
alch
bren
nera
ndBl
unso
m,2
013)
.
3LE
AR
NIN
GTO
ALI
GN
AN
DTR
AN
SLAT
E
Inth
isse
ctio
n,w
epro
pose
anov
elar
chite
ctur
efor
neur
alm
achi
netra
nsla
tion.
Then
ewar
chite
ctur
eco
nsist
sof
abi
dire
ctio
nalR
NN
asan
enco
der
(Sec
.3.2
)an
da
deco
der
that
emul
ates
sear
chin
gth
roug
ha
sour
cese
nten
cedu
ring
deco
ding
atra
nsla
tion
(Sec
.3.1
).
3.1
DEC
OD
ER:G
ENER
AL
DES
CR
IPTI
ON
s t
Figu
re1:
Theg
raph
ical
illus
-tra
tion
ofth
epr
opos
edm
odel
tryin
gto
gene
rate
thet-th
tar-
get
wor
dy
t
give
na
sour
cese
nten
ce(x
1,x
2,...,x
T
).
Ina
new
mod
elar
chite
ctur
e,w
ede
fine
each
cond
ition
alpr
obab
ility
inEq
.(2)
as:
p(y
i
|y1,...,y
i�1,x)=
g(y
i�1,s
i
,c
i
),
(4)
whe
res
i
isan
RNN
hidd
ensta
tefo
rtim
ei,c
ompu
ted
by
s
i
=f(s
i�1,y
i�1,c
i
).
Itsh
ould
beno
ted
that
unlik
eth
eex
istin
gen
code
r–de
code
rap
-pr
oach
(see
Eq.(
2)),
here
thep
roba
bilit
yis
cond
ition
edon
adist
inct
cont
extv
ecto
rci
fore
ach
targ
etw
ordy
i
.
The
cont
ext
vect
orc
i
depe
nds
ona
sequ
ence
ofan
nota
tions
(h
1,···,
h
T
x
)to
whi
chan
enco
derm
apst
hein
puts
ente
nce.
Each
anno
tatio
nh
i
cont
ains
info
rmat
ion
abou
tthe
who
lein
puts
eque
nce
with
astr
ong
focu
son
the
parts
surro
undi
ngth
ei-th
wor
dof
the
inpu
tseq
uenc
e.W
eex
plai
nin
deta
ilho
wth
ean
nota
tions
are
com
-pu
ted
inth
ene
xtse
ctio
n.
Thec
onte
xtve
ctor
c
i
is,th
en,c
ompu
ted
asaw
eigh
ted
sum
ofth
ese
anno
tatio
nsh
i
:
c
i
=
T
x
X j=1
↵
ij
h
j
.(5
)
The
wei
ght↵
ij
ofea
chan
nota
tionh
j
isco
mpu
ted
by
↵
ij
=
exp(e
ij
)
PT
x
k=1exp(e
ik
)
,(6
)
whe
ree
ij
=a(s
i�1,h
j
)
isan
alig
nmen
tmod
elw
hich
scor
esho
ww
ellt
hein
puts
arou
ndpo
sitio
nj
and
the
outp
utat
posit
ion
im
atch
.The
scor
eis
base
don
the
RNN
hidd
ensta
tes
i�1
(just
befo
reem
ittin
gy
i
,Eq.
(4))
and
the
j-th
anno
tatio
nh
j
ofth
ein
puts
ente
nce.
Wep
aram
etriz
ethe
alig
nmen
tmod
ela
asaf
eedf
orw
ard
neur
alne
twor
kw
hich
isjo
intly
train
edw
ithal
lthe
othe
rcom
pone
ntso
fthe
prop
osed
syste
m.N
otet
hatu
nlik
ein
tradi
tiona
lmac
hine
trans
latio
n,
3
Publ
ishe
das
aco
nfer
ence
pape
ratI
CLR
2015
The
deco
der
isof
ten
train
edto
pred
ict
the
next
wor
dy
t
0gi
ven
the
cont
ext
vect
orc
and
all
the
prev
ious
lypr
edic
ted
wor
ds{y
1,···,
y
t
0 �1}.
Inot
herw
ords
,the
deco
derd
efine
sa
prob
abili
tyov
erth
etra
nsla
tiony
byde
com
posi
ngth
ejo
intp
roba
bilit
yin
toth
eor
dere
dco
nditi
onal
s:
p(y)=
T Y
t=1
p(y
t
|{y
1,···,
y
t�1},
c),
(2)
whe
rey=
� y
1,···,
y
T
y
� .With
anR
NN
,eac
hco
nditi
onal
prob
abili
tyis
mod
eled
as
p(y
t
|{y
1,···,
y
t�1},
c)=
g(y
t�1,s
t
,c),
(3)
whe
reg
isa
nonl
inea
r,po
tent
ially
mul
ti-la
yere
d,fu
nctio
nth
atou
tput
sthe
prob
abili
tyof
y
t
,and
s
t
isth
ehi
dden
stat
eof
the
RN
N.I
tsho
uld
beno
ted
that
othe
rarc
hite
ctur
essu
chas
ahy
brid
ofan
RN
Nan
da
de-c
onvo
lutio
naln
eura
lnet
wor
kca
nbe
used
(Kal
chbr
enne
rand
Blu
nsom
,201
3).
3L
EA
RN
ING
TO
AL
IGN
AN
DT
RA
NSL
AT
E
Inth
isse
ctio
n,w
epr
opos
ea
nove
larc
hite
ctur
efo
rneu
ralm
achi
netra
nsla
tion.
The
new
arch
itect
ure
cons
ists
ofa
bidi
rect
iona
lR
NN
asan
enco
der
(Sec
.3.2
)an
da
deco
der
that
emul
ates
sear
chin
gth
roug
ha
sour
cese
nten
cedu
ring
deco
ding
atra
nsla
tion
(Sec
.3.1
).
3.1
DE
CO
DE
R:
GE
NE
RA
LD
ESC
RIP
TIO
N
st
Figu
re1:
The
grap
hica
lillu
s-tra
tion
ofth
epr
opos
edm
odel
tryin
gto
gene
rate
thet-th
tar-
get
wor
dy
t
give
na
sour
cese
nten
ce(x
1,x
2,...,x
T
).
Ina
new
mod
elar
chite
ctur
e,w
ede
fine
each
cond
ition
alpr
obab
ility
inEq
.(2)
as:
p(y
i
|y1,...,y
i�1,x)=
g(y
i�1,s
i
,c
i
),
(4)
whe
res
i
isan
RN
Nhi
dden
stat
efo
rtim
ei,c
ompu
ted
by
s
i
=f(s
i�1,y
i�1,c
i
).
Itsh
ould
beno
ted
that
unlik
eth
eex
istin
gen
code
r–de
code
rap
-pr
oach
(see
Eq.(
2)),
here
the
prob
abili
tyis
cond
ition
edon
adi
stin
ctco
ntex
tvec
torc
i
fore
ach
targ
etw
ordy
i
.
The
cont
ext
vect
orc
i
depe
nds
ona
sequ
ence
ofan
nota
tions
(h
1,···,
h
T
x
)to
whi
chan
enco
derm
aps
the
inpu
tsen
tenc
e.Ea
chan
nota
tionh
i
cont
ains
info
rmat
ion
abou
tthe
who
lein
puts
eque
nce
with
ast
rong
focu
son
the
parts
surr
ound
ing
thei-th
wor
dof
the
inpu
tseq
uenc
e.W
eex
plai
nin
deta
ilho
wth
ean
nota
tions
are
com
-pu
ted
inth
ene
xtse
ctio
n.
The
cont
extv
ecto
rci
is,t
hen,
com
pute
das
aw
eigh
ted
sum
ofth
ese
anno
tatio
nsh
i
:
c
i
=
T
x
X j=1
↵
ij
h
j
.(5
)
The
wei
ght↵
ij
ofea
chan
nota
tionh
j
isco
mpu
ted
by
↵
ij
=
exp(e
ij
)
PT
x
k=1exp(e
ik
)
,(6
)
whe
ree
ij
=a(s
i�1,h
j
)
isan
alig
nmen
tmod
elw
hich
scor
esho
ww
ellt
hein
puts
arou
ndpo
sitio
nj
and
the
outp
utat
posi
tion
im
atch
.The
scor
eis
base
don
the
RN
Nhi
dden
stat
es
i�1
(just
befo
reem
ittin
gy
i
,Eq.
(4))
and
the
j-th
anno
tatio
nh
j
ofth
ein
puts
ente
nce.
We
para
met
rize
the
alig
nmen
tmod
ela
asa
feed
forw
ard
neur
alne
twor
kw
hich
isjo
intly
train
edw
ithal
lthe
othe
rcom
pone
ntso
fthe
prop
osed
syst
em.N
ote
that
unlik
ein
tradi
tiona
lmac
hine
trans
latio
n,
3
Published as a conference paper at ICLR 2015
The decoder is often trained to predict the next word y
t
0 given the context vector c and all thepreviously predicted words {y1, · · · , yt0�1}. In other words, the decoder defines a probability overthe translation y by decomposing the joint probability into the ordered conditionals:
p(y) =
TY
t=1
p(y
t
| {y1, · · · , yt�1} , c), (2)
where y =
�y1, · · · , yT
y
�. With an RNN, each conditional probability is modeled as
p(y
t
| {y1, · · · , yt�1} , c) = g(y
t�1, st, c), (3)
where g is a nonlinear, potentially multi-layered, function that outputs the probability of yt
, and s
t
isthe hidden state of the RNN. It should be noted that other architectures such as a hybrid of an RNNand a de-convolutional neural network can be used (Kalchbrenner and Blunsom, 2013).
3 LEARNING TO ALIGN AND TRANSLATE
In this section, we propose a novel architecture for neural machine translation. The new architectureconsists of a bidirectional RNN as an encoder (Sec. 3.2) and a decoder that emulates searchingthrough a source sentence during decoding a translation (Sec. 3.1).
3.1 DECODER: GENERAL DESCRIPTION
yt-1
Figure 1: The graphical illus-tration of the proposed modeltrying to generate the t-th tar-get word y
t
given a sourcesentence (x1, x2, . . . , xT
).
In a new model architecture, we define each conditional probabilityin Eq. (2) as:
p(y
i
|y1, . . . , yi�1,x) = g(y
i�1, si, ci), (4)
where s
i
is an RNN hidden state for time i, computed by
s
i
= f(s
i�1, yi�1, ci).
It should be noted that unlike the existing encoder–decoder ap-proach (see Eq. (2)), here the probability is conditioned on a distinctcontext vector c
i
for each target word y
i
.
The context vector c
i
depends on a sequence of annotations(h1, · · · , hT
x
) to which an encoder maps the input sentence. Eachannotation h
i
contains information about the whole input sequencewith a strong focus on the parts surrounding the i-th word of theinput sequence. We explain in detail how the annotations are com-puted in the next section.
The context vector ci
is, then, computed as a weighted sum of theseannotations h
i
:
c
i
=
T
xX
j=1
↵
ij
h
j
. (5)
The weight ↵ij
of each annotation h
j
is computed by
↵
ij
=
exp (e
ij
)
PT
x
k=1 exp (eik), (6)
wheree
ij
= a(s
i�1, hj
)
is an alignment model which scores how well the inputs around position j and the output at positioni match. The score is based on the RNN hidden state s
i�1 (just before emitting y
i
, Eq. (4)) and thej-th annotation h
j
of the input sentence.
We parametrize the alignment model a as a feedforward neural network which is jointly trained withall the other components of the proposed system. Note that unlike in traditional machine translation,
3
ptpt-1
c.f. http://www.slideshare.net/yutakikuchi927/deep-learning-nlp-attention

••
α
6
Published as a conference paper at ICLR 2015
The decoder is often trained to predict the next word y
t
0 given the context vector c and all thepreviously predicted words {y1, · · · , yt0�1}. In other words, the decoder defines a probability overthe translation y by decomposing the joint probability into the ordered conditionals:
p(y) =
TY
t=1
p(y
t
| {y1, · · · , yt�1} , c), (2)
where y =
�y1, · · · , yT
y
�. With an RNN, each conditional probability is modeled as
p(y
t
| {y1, · · · , yt�1} , c) = g(y
t�1, st, c), (3)
where g is a nonlinear, potentially multi-layered, function that outputs the probability of yt
, and s
t
isthe hidden state of the RNN. It should be noted that other architectures such as a hybrid of an RNNand a de-convolutional neural network can be used (Kalchbrenner and Blunsom, 2013).
3 LEARNING TO ALIGN AND TRANSLATE
In this section, we propose a novel architecture for neural machine translation. The new architectureconsists of a bidirectional RNN as an encoder (Sec. 3.2) and a decoder that emulates searchingthrough a source sentence during decoding a translation (Sec. 3.1).
3.1 DECODER: GENERAL DESCRIPTION
x1 x2 x3 xT
+αt,1αt,2 αt,3
αt,T
h1 h2 h3 hT
h1 h2 h3 hT
st-1 s t
Figure 1: The graphical illus-tration of the proposed modeltrying to generate the t-th tar-get word y
t
given a sourcesentence (x1, x2, . . . , xT
).
In a new model architecture, we define each conditional probabilityin Eq. (2) as:
p(y
i
|y1, . . . , yi�1,x) = g(y
i�1, si, ci), (4)
where s
i
is an RNN hidden state for time i, computed by
s
i
= f(s
i�1, yi�1, ci).
It should be noted that unlike the existing encoder–decoder ap-proach (see Eq. (2)), here the probability is conditioned on a distinctcontext vector c
i
for each target word y
i
.
The context vector c
i
depends on a sequence of annotations(h1, · · · , hT
x
) to which an encoder maps the input sentence. Eachannotation h
i
contains information about the whole input sequencewith a strong focus on the parts surrounding the i-th word of theinput sequence. We explain in detail how the annotations are com-puted in the next section.
The context vector ci
is, then, computed as a weighted sum of theseannotations h
i
:
c
i
=
T
xX
j=1
↵
ij
h
j
. (5)
The weight ↵ij
of each annotation h
j
is computed by
↵
ij
=
exp (e
ij
)
PT
x
k=1 exp (eik), (6)
wheree
ij
= a(s
i�1, hj
)
is an alignment model which scores how well the inputs around position j and the output at positioni match. The score is based on the RNN hidden state s
i�1 (just before emitting y
i
, Eq. (4)) and thej-th annotation h
j
of the input sentence.
We parametrize the alignment model a as a feedforward neural network which is jointly trained withall the other components of the proposed system. Note that unlike in traditional machine translation,
3
Published as a conference paper at ICLR 2015
The decoder is often trained to predict the next word y
t
0 given the context vector c and all thepreviously predicted words {y1, · · · , yt0�1}. In other words, the decoder defines a probability overthe translation y by decomposing the joint probability into the ordered conditionals:
p(y) =
TY
t=1
p(y
t
| {y1, · · · , yt�1} , c), (2)
where y =
�y1, · · · , yT
y
�. With an RNN, each conditional probability is modeled as
p(y
t
| {y1, · · · , yt�1} , c) = g(y
t�1, st, c), (3)
where g is a nonlinear, potentially multi-layered, function that outputs the probability of yt
, and s
t
isthe hidden state of the RNN. It should be noted that other architectures such as a hybrid of an RNNand a de-convolutional neural network can be used (Kalchbrenner and Blunsom, 2013).
3 LEARNING TO ALIGN AND TRANSLATE
In this section, we propose a novel architecture for neural machine translation. The new architectureconsists of a bidirectional RNN as an encoder (Sec. 3.2) and a decoder that emulates searchingthrough a source sentence during decoding a translation (Sec. 3.1).
3.1 DECODER: GENERAL DESCRIPTION
Figure 1: The graphical illus-tration of the proposed modeltrying to generate the t-th tar-get word y
t
given a sourcesentence (x1, x2, . . . , xT
).
In a new model architecture, we define each conditional probabilityin Eq. (2) as:
p(y
i
|y1, . . . , yi�1,x) = g(y
i�1, si, ci), (4)
where s
i
is an RNN hidden state for time i, computed by
s
i
= f(s
i�1, yi�1, ci).
It should be noted that unlike the existing encoder–decoder ap-proach (see Eq. (2)), here the probability is conditioned on a distinctcontext vector c
i
for each target word y
i
.
The context vector c
i
depends on a sequence of annotations(h1, · · · , hT
x
) to which an encoder maps the input sentence. Eachannotation h
i
contains information about the whole input sequencewith a strong focus on the parts surrounding the i-th word of theinput sequence. We explain in detail how the annotations are com-puted in the next section.
The context vector ci
is, then, computed as a weighted sum of theseannotations h
i
:
c
i
=
T
xX
j=1
↵
ij
h
j
. (5)
The weight ↵ij
of each annotation h
j
is computed by
↵
ij
=
exp (e
ij
)
PT
x
k=1 exp (eik), (6)
wheree
ij
= a(s
i�1, hj
)
is an alignment model which scores how well the inputs around position j and the output at positioni match. The score is based on the RNN hidden state s
i�1 (just before emitting y
i
, Eq. (4)) and thej-th annotation h
j
of the input sentence.
We parametrize the alignment model a as a feedforward neural network which is jointly trained withall the other components of the proposed system. Note that unlike in traditional machine translation,
3
Published as a conference paper at ICLR 2015
The decoder is often trained to predict the next word y
t
0 given the context vector c and all thepreviously predicted words {y1, · · · , yt0�1}. In other words, the decoder defines a probability overthe translation y by decomposing the joint probability into the ordered conditionals:
p(y) =
TY
t=1
p(y
t
| {y1, · · · , yt�1} , c), (2)
where y =
�y1, · · · , yT
y
�. With an RNN, each conditional probability is modeled as
p(y
t
| {y1, · · · , yt�1} , c) = g(y
t�1, st, c), (3)
where g is a nonlinear, potentially multi-layered, function that outputs the probability of yt
, and s
t
isthe hidden state of the RNN. It should be noted that other architectures such as a hybrid of an RNNand a de-convolutional neural network can be used (Kalchbrenner and Blunsom, 2013).
3 LEARNING TO ALIGN AND TRANSLATE
In this section, we propose a novel architecture for neural machine translation. The new architectureconsists of a bidirectional RNN as an encoder (Sec. 3.2) and a decoder that emulates searchingthrough a source sentence during decoding a translation (Sec. 3.1).
3.1 DECODER: GENERAL DESCRIPTION
Figure 1: The graphical illus-tration of the proposed modeltrying to generate the t-th tar-get word y
t
given a sourcesentence (x1, x2, . . . , xT
).
In a new model architecture, we define each conditional probabilityin Eq. (2) as:
p(y
i
|y1, . . . , yi�1,x) = g(y
i�1, si, ci), (4)
where s
i
is an RNN hidden state for time i, computed by
s
i
= f(s
i�1, yi�1, ci).
It should be noted that unlike the existing encoder–decoder ap-proach (see Eq. (2)), here the probability is conditioned on a distinctcontext vector c
i
for each target word y
i
.
The context vector c
i
depends on a sequence of annotations(h1, · · · , hT
x
) to which an encoder maps the input sentence. Eachannotation h
i
contains information about the whole input sequencewith a strong focus on the parts surrounding the i-th word of theinput sequence. We explain in detail how the annotations are com-puted in the next section.
The context vector ci
is, then, computed as a weighted sum of theseannotations h
i
:
c
i
=
T
xX
j=1
↵
ij
h
j
. (5)
The weight ↵ij
of each annotation h
j
is computed by
↵
ij
=
exp (e
ij
)
PT
x
k=1 exp (eik), (6)
wheree
ij
= a(s
i�1, hj
)
is an alignment model which scores how well the inputs around position j and the output at positioni match. The score is based on the RNN hidden state s
i�1 (just before emitting y
i
, Eq. (4)) and thej-th annotation h
j
of the input sentence.
We parametrize the alignment model a as a feedforward neural network which is jointly trained withall the other components of the proposed system. Note that unlike in traditional machine translation,
3
Published as a conference paper at ICLR 2015
The decoder is often trained to predict the next word y
t
0 given the context vector c and all thepreviously predicted words {y1, · · · , yt0�1}. In other words, the decoder defines a probability overthe translation y by decomposing the joint probability into the ordered conditionals:
p(y) =
TY
t=1
p(y
t
| {y1, · · · , yt�1} , c), (2)
where y =
�y1, · · · , yT
y
�. With an RNN, each conditional probability is modeled as
p(y
t
| {y1, · · · , yt�1} , c) = g(y
t�1, st, c), (3)
where g is a nonlinear, potentially multi-layered, function that outputs the probability of yt
, and s
t
isthe hidden state of the RNN. It should be noted that other architectures such as a hybrid of an RNNand a de-convolutional neural network can be used (Kalchbrenner and Blunsom, 2013).
3 LEARNING TO ALIGN AND TRANSLATE
In this section, we propose a novel architecture for neural machine translation. The new architectureconsists of a bidirectional RNN as an encoder (Sec. 3.2) and a decoder that emulates searchingthrough a source sentence during decoding a translation (Sec. 3.1).
3.1 DECODER: GENERAL DESCRIPTION
Figure 1: The graphical illus-tration of the proposed modeltrying to generate the t-th tar-get word y
t
given a sourcesentence (x1, x2, . . . , xT
).
In a new model architecture, we define each conditional probabilityin Eq. (2) as:
p(y
i
|y1, . . . , yi�1,x) = g(y
i�1, si, ci), (4)
where s
i
is an RNN hidden state for time i, computed by
s
i
= f(s
i�1, yi�1, ci).
It should be noted that unlike the existing encoder–decoder ap-proach (see Eq. (2)), here the probability is conditioned on a distinctcontext vector c
i
for each target word y
i
.
The context vector c
i
depends on a sequence of annotations(h1, · · · , hT
x
) to which an encoder maps the input sentence. Eachannotation h
i
contains information about the whole input sequencewith a strong focus on the parts surrounding the i-th word of theinput sequence. We explain in detail how the annotations are com-puted in the next section.
The context vector ci
is, then, computed as a weighted sum of theseannotations h
i
:
c
i
=
T
xX
j=1
↵
ij
h
j
. (5)
The weight ↵ij
of each annotation h
j
is computed by
↵
ij
=
exp (e
ij
)
PT
x
k=1 exp (eik), (6)
wheree
ij
= a(s
i�1, hj
)
is an alignment model which scores how well the inputs around position j and the output at positioni match. The score is based on the RNN hidden state s
i�1 (just before emitting y
i
, Eq. (4)) and thej-th annotation h
j
of the input sentence.
We parametrize the alignment model a as a feedforward neural network which is jointly trained withall the other components of the proposed system. Note that unlike in traditional machine translation,
3
Published as a conference paper at ICLR 2015
The decoder is often trained to predict the next word y
t
0 given the context vector c and all thepreviously predicted words {y1, · · · , yt0�1}. In other words, the decoder defines a probability overthe translation y by decomposing the joint probability into the ordered conditionals:
p(y) =
TY
t=1
p(y
t
| {y1, · · · , yt�1} , c), (2)
where y =
�y1, · · · , yT
y
�. With an RNN, each conditional probability is modeled as
p(y
t
| {y1, · · · , yt�1} , c) = g(y
t�1, st, c), (3)
where g is a nonlinear, potentially multi-layered, function that outputs the probability of yt
, and s
t
isthe hidden state of the RNN. It should be noted that other architectures such as a hybrid of an RNNand a de-convolutional neural network can be used (Kalchbrenner and Blunsom, 2013).
3 LEARNING TO ALIGN AND TRANSLATE
In this section, we propose a novel architecture for neural machine translation. The new architectureconsists of a bidirectional RNN as an encoder (Sec. 3.2) and a decoder that emulates searchingthrough a source sentence during decoding a translation (Sec. 3.1).
3.1 DECODER: GENERAL DESCRIPTION
Figure 1: The graphical illus-tration of the proposed modeltrying to generate the t-th tar-get word y
t
given a sourcesentence (x1, x2, . . . , xT
).
In a new model architecture, we define each conditional probabilityin Eq. (2) as:
p(y
i
|y1, . . . , yi�1,x) = g(y
i�1, si, ci), (4)
where s
i
is an RNN hidden state for time i, computed by
s
i
= f(s
i�1, yi�1, ci).
It should be noted that unlike the existing encoder–decoder ap-proach (see Eq. (2)), here the probability is conditioned on a distinctcontext vector c
i
for each target word y
i
.
The context vector c
i
depends on a sequence of annotations(h1, · · · , hT
x
) to which an encoder maps the input sentence. Eachannotation h
i
contains information about the whole input sequencewith a strong focus on the parts surrounding the i-th word of theinput sequence. We explain in detail how the annotations are com-puted in the next section.
The context vector ci
is, then, computed as a weighted sum of theseannotations h
i
:
c
i
=
T
xX
j=1
↵
ij
h
j
. (5)
The weight ↵ij
of each annotation h
j
is computed by
↵
ij
=
exp (e
ij
)
PT
x
k=1 exp (eik), (6)
wheree
ij
= a(s
i�1, hj
)
is an alignment model which scores how well the inputs around position j and the output at positioni match. The score is based on the RNN hidden state s
i�1 (just before emitting y
i
, Eq. (4)) and thej-th annotation h
j
of the input sentence.
We parametrize the alignment model a as a feedforward neural network which is jointly trained withall the other components of the proposed system. Note that unlike in traditional machine translation,
3
to our method. However, it does not use atten-tion mechanism, and by having fixed sized soft-max output over the relative pointing range (e.g.,-7, . . . , -1, 0, 1, . . . , 7), their model (the Posi-tional All model) has a limitation in applying tomore general problems such as summarization andquestion answering, where, unlike machine trans-lation, the length of the context and the pointinglocations in the context can vary dramatically. Inquestion answering setting, (Hermann et al., 2015)have used placeholders on named entities in thecontext. However, the placeholder id is directlypredicted in the softmax output rather than predict-ing its location in the context.
The third category of the approaches changesthe unit of input/output itself from words to asmaller resolution such as characters (Graves,2013) or bytecodes (Sennrich et al., 2015; Gillicket al., 2015). Although this approach has themain advantage that it could suffer less from therare/unknown word problem, the training usuallybecomes much harder because the length of se-quences significantly increases.
Simultaneously to our work, (Gu et al., 2016)and (Cheng and Lapata, 2016) proposed modelsthat learn to copy from source to target and bothpapers analyzed their models on summarizationtasks.
3 Neural Machine Translation Model
with Attention
As the baseline neural machine translation sys-tem, we use the model proposed by (Bahdanau etal., 2014) that learns to (soft-)align and translatejointly. We refer this model as NMT.
The encoder of the NMT is a bidirectionalRNN (Schuster and Paliwal, 1997). The forwardRNN reads input sequence x = (x1, . . . , x
T
)
in left-to-right direction, resulting in a sequenceof hidden states (
�!h 1, . . . ,
�!h
T
). The backwardRNN reads x in the reversed direction and outputs(
�h 1, . . . ,
�h
T
). We then concatenate the hiddenstates of forward and backward RNNs at each timestep and obtain a sequence of annotation vectors(h1, . . . ,h
T
) where h
j
=
h�!h
j
|| �h
j
i. Here, ||
denotes the concatenation operator. Thus, each an-notation vector h
j
encodes information about thej-th word with respect to all the other surroundingwords in both directions.
In the decoder, we usually use gated recur-rent unit (GRU) (Cho et al., 2014; Chung et al.,
2014). Specifically, at each time-step t, the soft-alignment mechanism first computes the relevanceweight e
tj
which determines the contribution ofannotation vector h
j
to the t-th target word. Weuse a non-linear mapping f (e.g., MLP) whichtakes h
j
, the previous decoder’s hidden state s
t�1
and the previous output yt�1 as input:
e
tj
= f(s
t�1,hj
, y
t�1).
The outputs etj
are then normalized as follows:
l
tj
=
exp(etj
)
PT
k=1 exp(etk
)
. (1)
We call ltj
as the relevance score, or the align-ment weight, of the j-th annotation vector.
The relevance scores are used to get the context
vector c
t
of the t-th target word in the translation:
c
t
=
TX
j=1
l
tj
h
j
,
The hidden state of the decoder st
is computedbased on the previous hidden state s
t�1, the con-text vector c
t
and the output word of the previoustime-step y
t�1:
s
t
= f
r
(s
t�1, yt�1, ct), (2)
where f
r
is GRU.We use a deep output layer (Pascanu et al.,
2013) to compute the conditional distribution overwords:
p(y
t
= a|y<t
,x) /
exp
⇣
a
(Wo
,bo
)fo(st, yt�1, ct)
⌘,
(3)
where W is a learned weight matrix and b is abias of the output layer. f
o
is a single-layer feed-forward neural network. (W
o
,bo
)(·) is a functionthat performs an affine transformation on its input.And the superscript a in a indicates the a-th col-umn vector of .
The whole model, including both the encoderand the decoder, is jointly trained to maximize the(conditional) log-likelihood of target sequencesgiven input sequences, where the training corpusis a set of (x
n
,y
n
)’s. Figure 2 illustrates the ar-chitecture of the NMT.
(t=i)
Publ
ished
asa
conf
eren
cepa
pera
tICL
R20
15
The
deco
der
isof
ten
train
edto
pred
ictt
hene
xtw
ordy
t
0gi
ven
the
cont
extv
ecto
rc
and
allt
hepr
evio
usly
pred
icte
dw
ords
{y1,···,
y
t
0 �1}.
Inot
herw
ords
,the
deco
derd
efine
sapr
obab
ility
over
the
trans
latio
ny
byde
com
posin
gth
ejo
intp
roba
bilit
yin
toth
eor
dere
dco
nditi
onal
s:
p(y)=
T Y
t=1
p(y
t
|{y
1,···,
y
t�1},
c),
(2)
whe
rey=
� y
1,···,
y
T
y
� .With
anRN
N,e
ach
cond
ition
alpr
obab
ility
ism
odel
edas
p(y
t
|{y
1,···,
y
t�1},
c)=
g(y
t�1,s
t
,c),
(3)
whe
reg
isan
onlin
ear,
pote
ntia
llym
ulti-
laye
red,
func
tion
that
outp
utst
hepr
obab
ility
ofy
t
,and
s
t
isth
ehi
dden
state
ofth
eRN
N.I
tsho
uld
beno
ted
that
othe
rarc
hite
ctur
essu
chas
ahy
brid
ofan
RNN
and
ade
-con
volu
tiona
lneu
raln
etw
ork
can
beus
ed(K
alch
bren
nera
ndBl
unso
m,2
013)
.
3LE
AR
NIN
GTO
ALI
GN
AN
DTR
AN
SLAT
E
Inth
isse
ctio
n,w
epro
pose
anov
elar
chite
ctur
efor
neur
alm
achi
netra
nsla
tion.
Then
ewar
chite
ctur
eco
nsist
sof
abi
dire
ctio
nalR
NN
asan
enco
der
(Sec
.3.2
)an
da
deco
der
that
emul
ates
sear
chin
gth
roug
ha
sour
cese
nten
cedu
ring
deco
ding
atra
nsla
tion
(Sec
.3.1
).
3.1
DEC
OD
ER:G
ENER
AL
DES
CR
IPTI
ON
s t
Figu
re1:
Theg
raph
ical
illus
-tra
tion
ofth
epr
opos
edm
odel
tryin
gto
gene
rate
thet-th
tar-
get
wor
dy
t
give
na
sour
cese
nten
ce(x
1,x
2,...,x
T
).
Ina
new
mod
elar
chite
ctur
e,w
ede
fine
each
cond
ition
alpr
obab
ility
inEq
.(2)
as:
p(y
i
|y1,...,y
i�1,x)=
g(y
i�1,s
i
,c
i
),
(4)
whe
res
i
isan
RNN
hidd
ensta
tefo
rtim
ei,c
ompu
ted
by
s
i
=f(s
i�1,y
i�1,c
i
).
Itsh
ould
beno
ted
that
unlik
eth
eex
istin
gen
code
r–de
code
rap
-pr
oach
(see
Eq.(
2)),
here
thep
roba
bilit
yis
cond
ition
edon
adist
inct
cont
extv
ecto
rci
fore
ach
targ
etw
ordy
i
.
The
cont
ext
vect
orc
i
depe
nds
ona
sequ
ence
ofan
nota
tions
(h
1,···,
h
T
x
)to
whi
chan
enco
derm
apst
hein
puts
ente
nce.
Each
anno
tatio
nh
i
cont
ains
info
rmat
ion
abou
tthe
who
lein
puts
eque
nce
with
astr
ong
focu
son
the
parts
surro
undi
ngth
ei-th
wor
dof
the
inpu
tseq
uenc
e.W
eex
plai
nin
deta
ilho
wth
ean
nota
tions
are
com
-pu
ted
inth
ene
xtse
ctio
n.
Thec
onte
xtve
ctor
c
i
is,th
en,c
ompu
ted
asaw
eigh
ted
sum
ofth
ese
anno
tatio
nsh
i
:
c
i
=
T
x
X j=1
↵
ij
h
j
.(5
)
The
wei
ght↵
ij
ofea
chan
nota
tionh
j
isco
mpu
ted
by
↵
ij
=
exp(e
ij
)
PT
x
k=1exp(e
ik
)
,(6
)
whe
ree
ij
=a(s
i�1,h
j
)
isan
alig
nmen
tmod
elw
hich
scor
esho
ww
ellt
hein
puts
arou
ndpo
sitio
nj
and
the
outp
utat
posit
ion
im
atch
.The
scor
eis
base
don
the
RNN
hidd
ensta
tes
i�1
(just
befo
reem
ittin
gy
i
,Eq.
(4))
and
the
j-th
anno
tatio
nh
j
ofth
ein
puts
ente
nce.
Wep
aram
etriz
ethe
alig
nmen
tmod
ela
asaf
eedf
orw
ard
neur
alne
twor
kw
hich
isjo
intly
train
edw
ithal
lthe
othe
rcom
pone
ntso
fthe
prop
osed
syste
m.N
otet
hatu
nlik
ein
tradi
tiona
lmac
hine
trans
latio
n,
3
Publ
ishe
das
aco
nfer
ence
pape
ratI
CLR
2015
The
deco
der
isof
ten
train
edto
pred
ict
the
next
wor
dy
t
0gi
ven
the
cont
ext
vect
orc
and
all
the
prev
ious
lypr
edic
ted
wor
ds{y
1,···,
y
t
0 �1}.
Inot
herw
ords
,the
deco
derd
efine
sa
prob
abili
tyov
erth
etra
nsla
tiony
byde
com
posi
ngth
ejo
intp
roba
bilit
yin
toth
eor
dere
dco
nditi
onal
s:
p(y)=
T Y
t=1
p(y
t
|{y
1,···,
y
t�1},
c),
(2)
whe
rey=
� y
1,···,
y
T
y
� .With
anR
NN
,eac
hco
nditi
onal
prob
abili
tyis
mod
eled
as
p(y
t
|{y
1,···,
y
t�1},
c)=
g(y
t�1,s
t
,c),
(3)
whe
reg
isa
nonl
inea
r,po
tent
ially
mul
ti-la
yere
d,fu
nctio
nth
atou
tput
sthe
prob
abili
tyof
y
t
,and
s
t
isth
ehi
dden
stat
eof
the
RN
N.I
tsho
uld
beno
ted
that
othe
rarc
hite
ctur
essu
chas
ahy
brid
ofan
RN
Nan
da
de-c
onvo
lutio
naln
eura
lnet
wor
kca
nbe
used
(Kal
chbr
enne
rand
Blu
nsom
,201
3).
3L
EA
RN
ING
TO
AL
IGN
AN
DT
RA
NSL
AT
E
Inth
isse
ctio
n,w
epr
opos
ea
nove
larc
hite
ctur
efo
rneu
ralm
achi
netra
nsla
tion.
The
new
arch
itect
ure
cons
ists
ofa
bidi
rect
iona
lR
NN
asan
enco
der
(Sec
.3.2
)an
da
deco
der
that
emul
ates
sear
chin
gth
roug
ha
sour
cese
nten
cedu
ring
deco
ding
atra
nsla
tion
(Sec
.3.1
).
3.1
DE
CO
DE
R:
GE
NE
RA
LD
ESC
RIP
TIO
N
st
Figu
re1:
The
grap
hica
lillu
s-tra
tion
ofth
epr
opos
edm
odel
tryin
gto
gene
rate
thet-th
tar-
get
wor
dy
t
give
na
sour
cese
nten
ce(x
1,x
2,...,x
T
).
Ina
new
mod
elar
chite
ctur
e,w
ede
fine
each
cond
ition
alpr
obab
ility
inEq
.(2)
as:
p(y
i
|y1,...,y
i�1,x)=
g(y
i�1,s
i
,c
i
),
(4)
whe
res
i
isan
RN
Nhi
dden
stat
efo
rtim
ei,c
ompu
ted
by
s
i
=f(s
i�1,y
i�1,c
i
).
Itsh
ould
beno
ted
that
unlik
eth
eex
istin
gen
code
r–de
code
rap
-pr
oach
(see
Eq.(
2)),
here
the
prob
abili
tyis
cond
ition
edon
adi
stin
ctco
ntex
tvec
torc
i
fore
ach
targ
etw
ordy
i
.
The
cont
ext
vect
orc
i
depe
nds
ona
sequ
ence
ofan
nota
tions
(h
1,···,
h
T
x
)to
whi
chan
enco
derm
aps
the
inpu
tsen
tenc
e.Ea
chan
nota
tionh
i
cont
ains
info
rmat
ion
abou
tthe
who
lein
puts
eque
nce
with
ast
rong
focu
son
the
parts
surr
ound
ing
thei-th
wor
dof
the
inpu
tseq
uenc
e.W
eex
plai
nin
deta
ilho
wth
ean
nota
tions
are
com
-pu
ted
inth
ene
xtse
ctio
n.
The
cont
extv
ecto
rci
is,t
hen,
com
pute
das
aw
eigh
ted
sum
ofth
ese
anno
tatio
nsh
i
:
c
i
=
T
x
X j=1
↵
ij
h
j
.(5
)
The
wei
ght↵
ij
ofea
chan
nota
tionh
j
isco
mpu
ted
by
↵
ij
=
exp(e
ij
)
PT
x
k=1exp(e
ik
)
,(6
)
whe
ree
ij
=a(s
i�1,h
j
)
isan
alig
nmen
tmod
elw
hich
scor
esho
ww
ellt
hein
puts
arou
ndpo
sitio
nj
and
the
outp
utat
posi
tion
im
atch
.The
scor
eis
base
don
the
RN
Nhi
dden
stat
es
i�1
(just
befo
reem
ittin
gy
i
,Eq.
(4))
and
the
j-th
anno
tatio
nh
j
ofth
ein
puts
ente
nce.
We
para
met
rize
the
alig
nmen
tmod
ela
asa
feed
forw
ard
neur
alne
twor
kw
hich
isjo
intly
train
edw
ithal
lthe
othe
rcom
pone
ntso
fthe
prop
osed
syst
em.N
ote
that
unlik
ein
tradi
tiona
lmac
hine
trans
latio
n,
3
Publ
ished
asa
conf
eren
cepa
pera
tICL
R20
15
The
deco
der
isof
ten
train
edto
pred
ictt
hene
xtw
ordy
t
0gi
ven
the
cont
extv
ecto
rc
and
allt
hepr
evio
usly
pred
icte
dw
ords
{y1,···,
y
t
0 �1}.
Inot
herw
ords
,the
deco
derd
efine
sapr
obab
ility
over
the
trans
latio
ny
byde
com
posin
gth
ejo
intp
roba
bilit
yin
toth
eor
dere
dco
nditi
onal
s:
p(y)=
T Y
t=1
p(y
t
|{y
1,···,
y
t�1},
c),
(2)
whe
rey=
� y
1,···,
y
T
y
� .With
anRN
N,e
ach
cond
ition
alpr
obab
ility
ism
odel
edas
p(y
t
|{y
1,···,
y
t�1},
c)=
g(y
t�1,s
t
,c),
(3)
whe
reg
isan
onlin
ear,
pote
ntia
llym
ulti-
laye
red,
func
tion
that
outp
utst
hepr
obab
ility
ofy
t
,and
s
t
isth
ehi
dden
state
ofth
eRN
N.I
tsho
uld
beno
ted
that
othe
rarc
hite
ctur
essu
chas
ahy
brid
ofan
RNN
and
ade
-con
volu
tiona
lneu
raln
etw
ork
can
beus
ed(K
alch
bren
nera
ndBl
unso
m,2
013)
.
3LE
AR
NIN
GTO
ALI
GN
AN
DTR
AN
SLAT
E
Inth
isse
ctio
n,w
epro
pose
anov
elar
chite
ctur
efor
neur
alm
achi
netra
nsla
tion.
Then
ewar
chite
ctur
eco
nsist
sof
abi
dire
ctio
nalR
NN
asan
enco
der
(Sec
.3.2
)an
da
deco
der
that
emul
ates
sear
chin
gth
roug
ha
sour
cese
nten
cedu
ring
deco
ding
atra
nsla
tion
(Sec
.3.1
).
3.1
DEC
OD
ER:G
ENER
AL
DES
CR
IPTI
ON
s t
Figu
re1:
Theg
raph
ical
illus
-tra
tion
ofth
epr
opos
edm
odel
tryin
gto
gene
rate
thet-th
tar-
get
wor
dy
t
give
na
sour
cese
nten
ce(x
1,x
2,...,x
T
).
Ina
new
mod
elar
chite
ctur
e,w
ede
fine
each
cond
ition
alpr
obab
ility
inEq
.(2)
as:
p(y
i
|y1,...,y
i�1,x)=
g(y
i�1,s
i
,c
i
),
(4)
whe
res
i
isan
RNN
hidd
ensta
tefo
rtim
ei,c
ompu
ted
by
s
i
=f(s
i�1,y
i�1,c
i
).
Itsh
ould
beno
ted
that
unlik
eth
eex
istin
gen
code
r–de
code
rap
-pr
oach
(see
Eq.(
2)),
here
thep
roba
bilit
yis
cond
ition
edon
adist
inct
cont
extv
ecto
rci
fore
ach
targ
etw
ordy
i
.
The
cont
ext
vect
orc
i
depe
nds
ona
sequ
ence
ofan
nota
tions
(h
1,···,
h
T
x
)to
whi
chan
enco
derm
apst
hein
puts
ente
nce.
Each
anno
tatio
nh
i
cont
ains
info
rmat
ion
abou
tthe
who
lein
puts
eque
nce
with
astr
ong
focu
son
the
parts
surro
undi
ngth
ei-th
wor
dof
the
inpu
tseq
uenc
e.W
eex
plai
nin
deta
ilho
wth
ean
nota
tions
are
com
-pu
ted
inth
ene
xtse
ctio
n.
Thec
onte
xtve
ctor
c
i
is,th
en,c
ompu
ted
asaw
eigh
ted
sum
ofth
ese
anno
tatio
nsh
i
:
c
i
=
T
x
X j=1
↵
ij
h
j
.(5
)
The
wei
ght↵
ij
ofea
chan
nota
tionh
j
isco
mpu
ted
by
↵
ij
=
exp(e
ij
)
PT
x
k=1exp(e
ik
)
,(6
)
whe
ree
ij
=a(s
i�1,h
j
)
isan
alig
nmen
tmod
elw
hich
scor
esho
ww
ellt
hein
puts
arou
ndpo
sitio
nj
and
the
outp
utat
posit
ion
im
atch
.The
scor
eis
base
don
the
RNN
hidd
ensta
tes
i�1
(just
befo
reem
ittin
gy
i
,Eq.
(4))
and
the
j-th
anno
tatio
nh
j
ofth
ein
puts
ente
nce.
Wep
aram
etriz
ethe
alig
nmen
tmod
ela
asaf
eedf
orw
ard
neur
alne
twor
kw
hich
isjo
intly
train
edw
ithal
lthe
othe
rcom
pone
ntso
fthe
prop
osed
syste
m.N
otet
hatu
nlik
ein
tradi
tiona
lmac
hine
trans
latio
n,
3
Publ
ishe
das
aco
nfer
ence
pape
ratI
CLR
2015
The
deco
der
isof
ten
train
edto
pred
ict
the
next
wor
dy
t
0gi
ven
the
cont
ext
vect
orc
and
all
the
prev
ious
lypr
edic
ted
wor
ds{y
1,···,
y
t
0 �1}.
Inot
herw
ords
,the
deco
derd
efine
sa
prob
abili
tyov
erth
etra
nsla
tiony
byde
com
posi
ngth
ejo
intp
roba
bilit
yin
toth
eor
dere
dco
nditi
onal
s:
p(y)=
T Y
t=1
p(y
t
|{y
1,···,
y
t�1},
c),
(2)
whe
rey=
� y
1,···,
y
T
y
� .With
anR
NN
,eac
hco
nditi
onal
prob
abili
tyis
mod
eled
as
p(y
t
|{y
1,···,
y
t�1},
c)=
g(y
t�1,s
t
,c),
(3)
whe
reg
isa
nonl
inea
r,po
tent
ially
mul
ti-la
yere
d,fu
nctio
nth
atou
tput
sthe
prob
abili
tyof
y
t
,and
s
t
isth
ehi
dden
stat
eof
the
RN
N.I
tsho
uld
beno
ted
that
othe
rarc
hite
ctur
essu
chas
ahy
brid
ofan
RN
Nan
da
de-c
onvo
lutio
naln
eura
lnet
wor
kca
nbe
used
(Kal
chbr
enne
rand
Blu
nsom
,201
3).
3L
EA
RN
ING
TO
AL
IGN
AN
DT
RA
NSL
AT
E
Inth
isse
ctio
n,w
epr
opos
ea
nove
larc
hite
ctur
efo
rneu
ralm
achi
netra
nsla
tion.
The
new
arch
itect
ure
cons
ists
ofa
bidi
rect
iona
lR
NN
asan
enco
der
(Sec
.3.2
)an
da
deco
der
that
emul
ates
sear
chin
gth
roug
ha
sour
cese
nten
cedu
ring
deco
ding
atra
nsla
tion
(Sec
.3.1
).
3.1
DE
CO
DE
R:
GE
NE
RA
LD
ESC
RIP
TIO
N
st
Figu
re1:
The
grap
hica
lillu
s-tra
tion
ofth
epr
opos
edm
odel
tryin
gto
gene
rate
thet-th
tar-
get
wor
dy
t
give
na
sour
cese
nten
ce(x
1,x
2,...,x
T
).
Ina
new
mod
elar
chite
ctur
e,w
ede
fine
each
cond
ition
alpr
obab
ility
inEq
.(2)
as:
p(y
i
|y1,...,y
i�1,x)=
g(y
i�1,s
i
,c
i
),
(4)
whe
res
i
isan
RN
Nhi
dden
stat
efo
rtim
ei,c
ompu
ted
by
s
i
=f(s
i�1,y
i�1,c
i
).
Itsh
ould
beno
ted
that
unlik
eth
eex
istin
gen
code
r–de
code
rap
-pr
oach
(see
Eq.(
2)),
here
the
prob
abili
tyis
cond
ition
edon
adi
stin
ctco
ntex
tvec
torc
i
fore
ach
targ
etw
ordy
i
.
The
cont
ext
vect
orc
i
depe
nds
ona
sequ
ence
ofan
nota
tions
(h
1,···,
h
T
x
)to
whi
chan
enco
derm
aps
the
inpu
tsen
tenc
e.Ea
chan
nota
tionh
i
cont
ains
info
rmat
ion
abou
tthe
who
lein
puts
eque
nce
with
ast
rong
focu
son
the
parts
surr
ound
ing
thei-th
wor
dof
the
inpu
tseq
uenc
e.W
eex
plai
nin
deta
ilho
wth
ean
nota
tions
are
com
-pu
ted
inth
ene
xtse
ctio
n.
The
cont
extv
ecto
rci
is,t
hen,
com
pute
das
aw
eigh
ted
sum
ofth
ese
anno
tatio
nsh
i
:
c
i
=
T
x
X j=1
↵
ij
h
j
.(5
)
The
wei
ght↵
ij
ofea
chan
nota
tionh
j
isco
mpu
ted
by
↵
ij
=
exp(e
ij
)
PT
x
k=1exp(e
ik
)
,(6
)
whe
ree
ij
=a(s
i�1,h
j
)
isan
alig
nmen
tmod
elw
hich
scor
esho
ww
ellt
hein
puts
arou
ndpo
sitio
nj
and
the
outp
utat
posi
tion
im
atch
.The
scor
eis
base
don
the
RN
Nhi
dden
stat
es
i�1
(just
befo
reem
ittin
gy
i
,Eq.
(4))
and
the
j-th
anno
tatio
nh
j
ofth
ein
puts
ente
nce.
We
para
met
rize
the
alig
nmen
tmod
ela
asa
feed
forw
ard
neur
alne
twor
kw
hich
isjo
intly
train
edw
ithal
lthe
othe
rcom
pone
ntso
fthe
prop
osed
syst
em.N
ote
that
unlik
ein
tradi
tiona
lmac
hine
trans
latio
n,
3
Published as a conference paper at ICLR 2015
The decoder is often trained to predict the next word y
t
0 given the context vector c and all thepreviously predicted words {y1, · · · , yt0�1}. In other words, the decoder defines a probability overthe translation y by decomposing the joint probability into the ordered conditionals:
p(y) =
TY
t=1
p(y
t
| {y1, · · · , yt�1} , c), (2)
where y =
�y1, · · · , yT
y
�. With an RNN, each conditional probability is modeled as
p(y
t
| {y1, · · · , yt�1} , c) = g(y
t�1, st, c), (3)
where g is a nonlinear, potentially multi-layered, function that outputs the probability of yt
, and s
t
isthe hidden state of the RNN. It should be noted that other architectures such as a hybrid of an RNNand a de-convolutional neural network can be used (Kalchbrenner and Blunsom, 2013).
3 LEARNING TO ALIGN AND TRANSLATE
In this section, we propose a novel architecture for neural machine translation. The new architectureconsists of a bidirectional RNN as an encoder (Sec. 3.2) and a decoder that emulates searchingthrough a source sentence during decoding a translation (Sec. 3.1).
3.1 DECODER: GENERAL DESCRIPTION
yt-1
Figure 1: The graphical illus-tration of the proposed modeltrying to generate the t-th tar-get word y
t
given a sourcesentence (x1, x2, . . . , xT
).
In a new model architecture, we define each conditional probabilityin Eq. (2) as:
p(y
i
|y1, . . . , yi�1,x) = g(y
i�1, si, ci), (4)
where s
i
is an RNN hidden state for time i, computed by
s
i
= f(s
i�1, yi�1, ci).
It should be noted that unlike the existing encoder–decoder ap-proach (see Eq. (2)), here the probability is conditioned on a distinctcontext vector c
i
for each target word y
i
.
The context vector c
i
depends on a sequence of annotations(h1, · · · , hT
x
) to which an encoder maps the input sentence. Eachannotation h
i
contains information about the whole input sequencewith a strong focus on the parts surrounding the i-th word of theinput sequence. We explain in detail how the annotations are com-puted in the next section.
The context vector ci
is, then, computed as a weighted sum of theseannotations h
i
:
c
i
=
T
xX
j=1
↵
ij
h
j
. (5)
The weight ↵ij
of each annotation h
j
is computed by
↵
ij
=
exp (e
ij
)
PT
x
k=1 exp (eik), (6)
wheree
ij
= a(s
i�1, hj
)
is an alignment model which scores how well the inputs around position j and the output at positioni match. The score is based on the RNN hidden state s
i�1 (just before emitting y
i
, Eq. (4)) and thej-th annotation h
j
of the input sentence.
We parametrize the alignment model a as a feedforward neural network which is jointly trained withall the other components of the proposed system. Note that unlike in traditional machine translation,
3
ptpt-1

•
•
•
• V
• •
���
killed a man yesterday . [eos]!
John killed a man yesterday . !
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
pt w Whp
Whp(w) bhp(w) softmax
Whp bhp
pt(w) = softmax(Whp(w)ht + bhp(w)) (18)
Whp
d′e
d′e = Wdyde + bdy (19)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (20)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp Whp(w)
bhp(w) softmax Z
Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
!man �
a �
a ���
man !�
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp Whp(w)
bhp(w) softmax Z
Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp ∈ RV×N V
N Whp(w) bhp(w)
softmax Z Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp ∈ RV×N V
N Whp(w) bhp(w)
softmax Z Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp ∈ RV×N V
N Whp(w) bhp(w)
softmax Z Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp ∈ RV×N V
N Whp(w) bhp(w)
softmax Z Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
• V T
•
•
•
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp ∈ RV×N V
N Whp(w) bhp(w)
softmax Z Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
T
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp Whp(w)
bhp(w) softmax Z
Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
6
RNN t wt
pt
pt = softmax(Whpht + bhp) (16)
ht =−−−→RNN t′≺t(xwt′ ) (17)
softmax(s)i =exp(si)!
sj∈s exp(sj)(18)
(19)
softmax(s)i N s i
exp
exp
pt w Whp Whp(w)
bhp(w) softmax Z
Whp bhp
pt(w) =Whp(w)Tht + bhp(w)
Z(20)
Z ="
w′
Whp(w′)Tht + bhp(w
′) (21)
Whp
d′e
d′e = Wdyde + bdy (22)
bhp(w)
bhpe
xwt′ xwt′
d′′e = Wdxde + bdx (23)
20
・
7
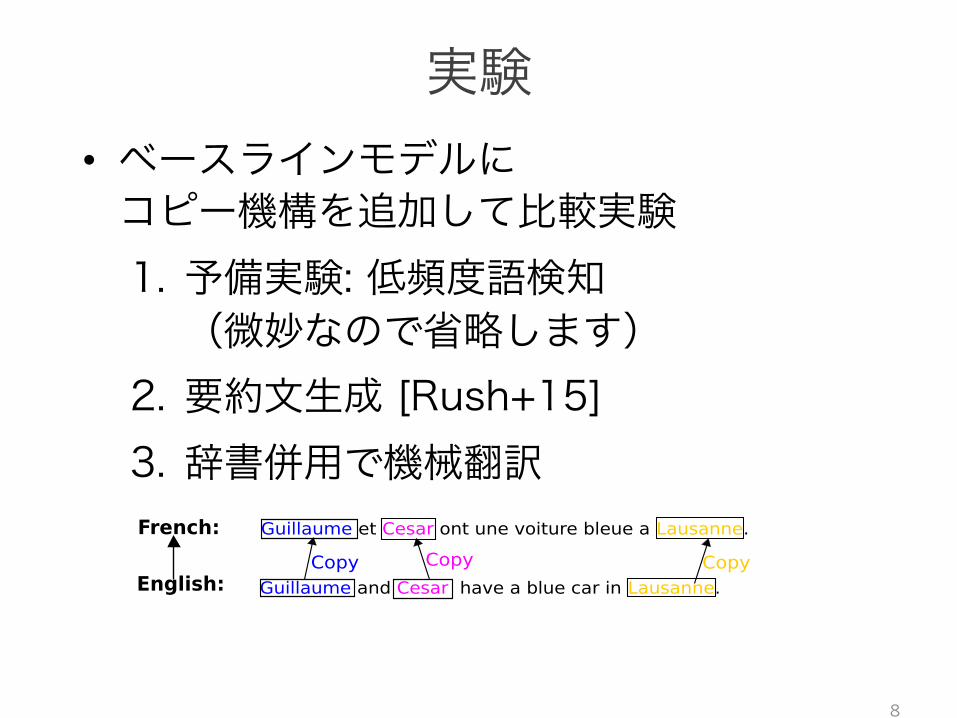
•
8
ior of humans and recent advances in the atten-tion mechanism (Bahdanau et al., 2014) and thepointer networks (Vinyals et al., 2015), we pro-pose a novel method to deal with the rare or un-known word problem. The basic idea is that wecan see in many NLP problems as a task of predict-ing target text given context text, where some ofthe target words appear in the context as well. Weobserve that in this case we can make the modellearn to point a word in the context and copy it tothe target text, as well as when to point. For exam-ple, in machine translation, we can see the sourcesentence as the context, and the target sentence aswhat we need to predict. In Figure 1, we showan example depiction of how words can be copiedfrom source to target in machine translation. Al-though the source and target languages are differ-ent, many of the words such as named entities areusually represented by the same characters in bothlanguages, making it possible to copy. Similarly,in text summarization, it is natural to use somewords in the original text in the summarized textas well.
Specifically, to predict a target word at eachtimestep, our model first determines the source ofthe word generation, that is, on whether to takeone from a predefined shortlist or to copy one fromthe context. For the former, we apply the typicalsoftmax operation, and for the latter, we use theattention mechanism to obtain the pointing soft-max probability over the context words and pickthe one of high probability. The model learns thisdecision so as to use the pointing only when thecontext includes a word that can be copied to thetarget. This way, our model can predict even thewords which are not in the shortlist, as long asit appears in the context. Although some of thewords still need to be labeled as UNK, i.e., if it isneither in the shortlist nor in the context, in ex-periments we show that this learning when and
where to point improves the performance in ma-chine translation and text summarization.
The rest of the paper is organized as follows. Inthe next section, we review the related works in-cluding pointer networks and previous approachesto the rare/unknown problem. In Section 3, wereview the neural machine translation with atten-tion mechanism which is the baseline in our ex-periments. Then, in Section 4, we propose ourmethod dealing with the rare/unknown word prob-lem, called the Pointer Softmax (PS). The exper-
Guillaume et Cesar ont une voiture bleue a Lausanne.
Guillaume and Cesar have a blue car in Lausanne.Copy Copy Copy
French:
English:
Figure 1: An example of how copying can happenfor machine translation. Common words that ap-pear both in source and the target can directly becopied from input to source. The rest of the un-known in the target can be copied from the inputafter being translated with a dictionary.
imental results are provided in the Section 5 andwe conclude our work in Section 6.
2 Related Work
The attention-based pointing mechanism is intro-duced first in the pointer networks (Vinyals et al.,2015). In the pointer networks, the output space ofthe target sequence is constrained to be the obser-vations in the input sequence (not the input space).Instead of having a fixed dimension softmax out-put layer, softmax outputs of varying dimension isdynamically computed for each input sequence insuch a way to maximize the attention probabilityof the target input. However, its applicability israther limited because, unlike our model, there isno option to choose whether to point or not; it al-ways points. In this sense, we can see the pointernetworks as a special case of our model where wealways choose to point a context word.
Several approaches have been proposed towardssolving the rare words/unknown words problem,which can be broadly divided into three categories.The first category of the approaches focuses onimproving the computation speed of the softmaxoutput so that it can maintain a very large vocabu-lary. Because this only increases the shortlist size,it helps to mitigate the unknown word problem,but still suffers from the rare word problem. Thehierarchical softmax (Morin and Bengio, 2005),importance sampling (Bengio and Senecal, 2008;Jean et al., 2014), and the noise contrastive esti-mation (Gutmann and Hyvarinen, 2012; Mnih andKavukcuoglu, 2013) methods are in the class.
The second category, where our proposedmethod also belongs to, uses information from thecontext. Notable works are (Luong et al., 2015)and (Hermann et al., 2015). In particular, ap-plying to machine translation task, (Luong et al.,2015) learns to point some words in source sen-tence and copy it to the target sentence, similarly

•
•
•
•
9

•
10
Table 4: Generated summaries from NMT with PS. Boldface words are the words copied from the source.Source #1 china ’s tang gonghong set a world record with a clean and
jerk lift of ### kilograms to win the women ’s over-## kilogramweightlifting title at the asian games on tuesday .
Target #1 china ’s tang <unk>,sets world weightlifting recordNMT+PS #1 china ’s tang gonghong wins women ’s weightlifting weightlift-
ing title at asian gamesSource #2 owing to criticism , nbc said on wednesday that it was ending
a three-month-old experiment that would have brought the firstliquor advertisements onto national broadcast network television.
Target #2 advertising : nbc retreats from liquor commercialsNMT+PS #2 nbc says it is ending a three-month-old experimentSource #3 a senior trade union official here wednesday called on ghana ’s
government to be “ mindful of the plight ” of the ordinary peoplein the country in its decisions on tax increases .
Target #3 tuc official,on behalf of ordinary ghanaiansNMT+PS #3 ghana ’s government urged to be mindful of the plight
vocabulary, we first check if the same word y
t
ap-pears in the source sentence. If it is not, we thencheck if a translated version of the word exists inthe source sentence by using a look-up table be-tween the source and the target language. If theword is in the source sentence, we then use the lo-cation of the word in the source as the target. Oth-erwise we check if one of the English senses fromthe cross-language dictionary of the French wordis in the source. If it is in the source sentence, thenwe use the location of that word as our translation.Otherwise we just use the argmax of l
t
as the tar-get.
For switching network d
t
, we observed that us-ing a two-layered MLP with noisy-tanh activation(Gulcehre et al., 2016) function with residual con-nection from the lower layer (He et al., 2015) ac-tivation function to the upper hidden layers im-proves the BLEU score about 1 points over thed
t
using ReLU activation function. We initializedthe biases of the last sigmoid layer of d
t
to �1
such that if dt
becomes more biased toward choos-ing the shortlist vocabulary at the beginning of thetraining. We renormalize the gradients if the normof the gradients exceed 1 (Pascanu et al., 2012).
Table 5: Europarl Dataset (EN-FR)BLEU-4
NMT 20.19NMT + PS 23.76
In Table 5, we provided the result of NMT withpointer softmax and we observe about 3.6 BLEUscore improvement over our baseline.
Figure 4: A comparison of the validation learning-curves of the same NMT model trained withpointer softmax and the regular softmax layer. Ascan be seen from the figures, the model trainedwith pointer softmax converges faster than the reg-ular softmax layer. Switching network for pointersoftmax in this Figure uses ReLU activation func-tion.
In Figure 4, we show the validation curvesof the NMT model with attention and the NMTmodel with shortlist-softmax layer. Pointer soft-max converges faster in terms of number of mini-batch updates and achieves a lower validationnegative-log-likelihood (NLL) (63.91) after 200kupdates over the Europarl dataset than the NMT
Table 4: Generated summaries from NMT with PS. Boldface words are the words copied from the source.Source #1 china ’s tang gonghong set a world record with a clean and
jerk lift of ### kilograms to win the women ’s over-## kilogramweightlifting title at the asian games on tuesday .
Target #1 china ’s tang <unk>,sets world weightlifting recordNMT+PS #1 china ’s tang gonghong wins women ’s weightlifting weightlift-
ing title at asian gamesSource #2 owing to criticism , nbc said on wednesday that it was ending
a three-month-old experiment that would have brought the firstliquor advertisements onto national broadcast network television.
Target #2 advertising : nbc retreats from liquor commercialsNMT+PS #2 nbc says it is ending a three-month-old experimentSource #3 a senior trade union official here wednesday called on ghana ’s
government to be “ mindful of the plight ” of the ordinary peoplein the country in its decisions on tax increases .
Target #3 tuc official,on behalf of ordinary ghanaiansNMT+PS #3 ghana ’s government urged to be mindful of the plight
vocabulary, we first check if the same word y
t
ap-pears in the source sentence. If it is not, we thencheck if a translated version of the word exists inthe source sentence by using a look-up table be-tween the source and the target language. If theword is in the source sentence, we then use the lo-cation of the word in the source as the target. Oth-erwise we check if one of the English senses fromthe cross-language dictionary of the French wordis in the source. If it is in the source sentence, thenwe use the location of that word as our translation.Otherwise we just use the argmax of l
t
as the tar-get.
For switching network d
t
, we observed that us-ing a two-layered MLP with noisy-tanh activation(Gulcehre et al., 2016) function with residual con-nection from the lower layer (He et al., 2015) ac-tivation function to the upper hidden layers im-proves the BLEU score about 1 points over thed
t
using ReLU activation function. We initializedthe biases of the last sigmoid layer of d
t
to �1
such that if dt
becomes more biased toward choos-ing the shortlist vocabulary at the beginning of thetraining. We renormalize the gradients if the normof the gradients exceed 1 (Pascanu et al., 2012).
Table 5: Europarl Dataset (EN-FR)BLEU-4
NMT 20.19NMT + PS 23.76
In Table 5, we provided the result of NMT withpointer softmax and we observe about 3.6 BLEUscore improvement over our baseline.
Figure 4: A comparison of the validation learning-curves of the same NMT model trained withpointer softmax and the regular softmax layer. Ascan be seen from the figures, the model trainedwith pointer softmax converges faster than the reg-ular softmax layer. Switching network for pointersoftmax in this Figure uses ReLU activation func-tion.
In Figure 4, we show the validation curvesof the NMT model with attention and the NMTmodel with shortlist-softmax layer. Pointer soft-max converges faster in terms of number of mini-batch updates and achieves a lower validationnegative-log-likelihood (NLL) (63.91) after 200kupdates over the Europarl dataset than the NMT
<v1> ’s <v2> <v3> set a world record with a clean and jerk lift of ### kilograms to win the women ’s over-## kilogram weightlifting title at the asian games on tuesday .<v1> ’s <v2> <v3>,sets world weightlifting record

••
•
•
•••
11

• gonghonh <unk>
•
•
12
For evaluation, we use full-length Rouge F1 us-ing the official evaluation tool 2. In their work, theauthors of (Bahdanau et al., 2014) use full-lengthRouge Recall on this corpus, since the maximumlength of limited-length version of Rouge recallof 75 bytes (intended for DUC data) is alreadylong for Gigaword summaries. However, sincefull-length Recall can unfairly reward longer sum-maries, we also use full-length F1 in our experi-ments for a fair comparison between our models,independent of the summary length.
The experimental results comparing the PointerSoftmax with NMT model are displayed in Ta-ble 1 for the UNK pointers data and in Table 2for the entity pointers data. As our experimentsshow, pointer softmax improves over the baselineNMT on both UNK data and entities data. Ourhope was that the improvement would be largerfor the entities data since the incidence of point-ers was much greater. However, it turns out thisis not the case, and we suspect the main reasonis anonymization of entities which removed data-sparsity by converting all entities to integer-idsthat are shared across all documents. We believethat on de-anonymized data, our model could helpmore, since the issue of data-sparsity is more acutein this case.
Table 1: Results on Gigaword Corpus when point-ers are used for UNKs in the training data, usingRouge-F1 as the evaluation metric.
Rouge-1 Rouge-2 Rouge-LNMT + lvt 34.87 16.54 32.27NMT + lvt + PS 35.19 16.66 32.51
Table 2: Results on anonymized Gigaword Corpuswhen pointers are used for entities, using Rouge-F1 as the evaluation metric.
Rouge-1 Rouge-2 Rouge-LNMT + lvt 34.89 16.78 32.37NMT + lvt + PS 35.11 16.76 32.55
In Table 3, we provide the results for summa-rization on Gigaword corpus in terms of recall asalso similar comparison is done by (Rush et al.,2015). We observe improvements on all the scoreswith the addition of pointer softmax. Let us note
2http://www.berouge.com/Pages/default.
aspx
Table 3: Results on Gigaword Corpus for model-ing UNK’s with pointers in terms of recall.
Rouge-1 Rouge-2 Rouge-LNMT + lvt 36.45 17.41 33.90NMT + lvt + PS 37.29 17.75 34.70
that, since the test set of (Rush et al., 2015) is notpublicly available, we sample 2000 texts with theirsummaries without replacement from the valida-tion set and used those examples as our test set.
In Table 4 we present a few system gener-ated summaries from the Pointer Softmax modeltrained on the UNK pointers data. From those ex-amples, it is apparent that the model has learned toaccurately point to the source positions wheneverit needs to generate rare words in the summary.
5.3 Neural Machine Translation
In our neural machine translation (NMT) experi-ments, we train NMT models with attention overthe Europarl corpus (Bahdanau et al., 2014) overthe sequences of length up to 50 for English toFrench translation. 3. All models are trained withearly-stopping which is done based on the negativelog-likelihood (NLL) on the development set. Ourevaluations to report the performance of our mod-els are done on newstest2011 by using BLUEscore. 4
We use 30, 000 tokens for both the source andthe target language shortlist vocabularies (1 of thetoken is still reserved for the unknown words).The whole corpus contains 134, 831 unique En-glish words and 153, 083 unique French words.We have created a word-level dictionary fromFrench to English which contains translation of15,953 words that are neither in shortlist vocab-ulary nor dictionary of common words for boththe source and the target. There are about 49, 490words shared between English and French parallelcorpora of Europarl.
During the training, in order to decide whetherto pick a word from the source sentence using at-tention/pointers or to predict the word from theshort-list vocabulary, we use the following sim-ple heuristic. If the word is not in the short-list
3In our experiments, we use an existing code, pro-vided in https://github.com/kyunghyuncho/
dl4mt-material, and on the original model we onlychanged the last softmax layer for our experiments
4We compute the BLEU score using the multi-blue.perlscript from Moses on tokenized sentence pairs.
Table 4: Generated summaries from NMT with PS. Boldface words are the words copied from the source.Source #1 china ’s tang gonghong set a world record with a clean and
jerk lift of ### kilograms to win the women ’s over-## kilogramweightlifting title at the asian games on tuesday .
Target #1 china ’s tang <unk>,sets world weightlifting recordNMT+PS #1 china ’s tang gonghong wins women ’s weightlifting weightlift-
ing title at asian gamesSource #2 owing to criticism , nbc said on wednesday that it was ending
a three-month-old experiment that would have brought the firstliquor advertisements onto national broadcast network television.
Target #2 advertising : nbc retreats from liquor commercialsNMT+PS #2 nbc says it is ending a three-month-old experimentSource #3 a senior trade union official here wednesday called on ghana ’s
government to be “ mindful of the plight ” of the ordinary peoplein the country in its decisions on tax increases .
Target #3 tuc official,on behalf of ordinary ghanaiansNMT+PS #3 ghana ’s government urged to be mindful of the plight
vocabulary, we first check if the same word y
t
ap-pears in the source sentence. If it is not, we thencheck if a translated version of the word exists inthe source sentence by using a look-up table be-tween the source and the target language. If theword is in the source sentence, we then use the lo-cation of the word in the source as the target. Oth-erwise we check if one of the English senses fromthe cross-language dictionary of the French wordis in the source. If it is in the source sentence, thenwe use the location of that word as our translation.Otherwise we just use the argmax of l
t
as the tar-get.
For switching network d
t
, we observed that us-ing a two-layered MLP with noisy-tanh activation(Gulcehre et al., 2016) function with residual con-nection from the lower layer (He et al., 2015) ac-tivation function to the upper hidden layers im-proves the BLEU score about 1 points over thed
t
using ReLU activation function. We initializedthe biases of the last sigmoid layer of d
t
to �1
such that if dt
becomes more biased toward choos-ing the shortlist vocabulary at the beginning of thetraining. We renormalize the gradients if the normof the gradients exceed 1 (Pascanu et al., 2012).
Table 5: Europarl Dataset (EN-FR)BLEU-4
NMT 20.19NMT + PS 23.76
In Table 5, we provided the result of NMT withpointer softmax and we observe about 3.6 BLEUscore improvement over our baseline.
Figure 4: A comparison of the validation learning-curves of the same NMT model trained withpointer softmax and the regular softmax layer. Ascan be seen from the figures, the model trainedwith pointer softmax converges faster than the reg-ular softmax layer. Switching network for pointersoftmax in this Figure uses ReLU activation func-tion.
In Figure 4, we show the validation curvesof the NMT model with attention and the NMTmodel with shortlist-softmax layer. Pointer soft-max converges faster in terms of number of mini-batch updates and achieves a lower validationnegative-log-likelihood (NLL) (63.91) after 200kupdates over the Europarl dataset than the NMT

••
13
For evaluation, we use full-length Rouge F1 us-ing the official evaluation tool 2. In their work, theauthors of (Bahdanau et al., 2014) use full-lengthRouge Recall on this corpus, since the maximumlength of limited-length version of Rouge recallof 75 bytes (intended for DUC data) is alreadylong for Gigaword summaries. However, sincefull-length Recall can unfairly reward longer sum-maries, we also use full-length F1 in our experi-ments for a fair comparison between our models,independent of the summary length.
The experimental results comparing the PointerSoftmax with NMT model are displayed in Ta-ble 1 for the UNK pointers data and in Table 2for the entity pointers data. As our experimentsshow, pointer softmax improves over the baselineNMT on both UNK data and entities data. Ourhope was that the improvement would be largerfor the entities data since the incidence of point-ers was much greater. However, it turns out thisis not the case, and we suspect the main reasonis anonymization of entities which removed data-sparsity by converting all entities to integer-idsthat are shared across all documents. We believethat on de-anonymized data, our model could helpmore, since the issue of data-sparsity is more acutein this case.
Table 1: Results on Gigaword Corpus when point-ers are used for UNKs in the training data, usingRouge-F1 as the evaluation metric.
Rouge-1 Rouge-2 Rouge-LNMT + lvt 34.87 16.54 32.27NMT + lvt + PS 35.19 16.66 32.51
Table 2: Results on anonymized Gigaword Corpuswhen pointers are used for entities, using Rouge-F1 as the evaluation metric.
Rouge-1 Rouge-2 Rouge-LNMT + lvt 34.89 16.78 32.37NMT + lvt + PS 35.11 16.76 32.55
In Table 3, we provide the results for summa-rization on Gigaword corpus in terms of recall asalso similar comparison is done by (Rush et al.,2015). We observe improvements on all the scoreswith the addition of pointer softmax. Let us note
2http://www.berouge.com/Pages/default.
aspx
Table 3: Results on Gigaword Corpus for model-ing UNK’s with pointers in terms of recall.
Rouge-1 Rouge-2 Rouge-LNMT + lvt 36.45 17.41 33.90NMT + lvt + PS 37.29 17.75 34.70
that, since the test set of (Rush et al., 2015) is notpublicly available, we sample 2000 texts with theirsummaries without replacement from the valida-tion set and used those examples as our test set.
In Table 4 we present a few system gener-ated summaries from the Pointer Softmax modeltrained on the UNK pointers data. From those ex-amples, it is apparent that the model has learned toaccurately point to the source positions wheneverit needs to generate rare words in the summary.
5.3 Neural Machine Translation
In our neural machine translation (NMT) experi-ments, we train NMT models with attention overthe Europarl corpus (Bahdanau et al., 2014) overthe sequences of length up to 50 for English toFrench translation. 3. All models are trained withearly-stopping which is done based on the negativelog-likelihood (NLL) on the development set. Ourevaluations to report the performance of our mod-els are done on newstest2011 by using BLUEscore. 4
We use 30, 000 tokens for both the source andthe target language shortlist vocabularies (1 of thetoken is still reserved for the unknown words).The whole corpus contains 134, 831 unique En-glish words and 153, 083 unique French words.We have created a word-level dictionary fromFrench to English which contains translation of15,953 words that are neither in shortlist vocab-ulary nor dictionary of common words for boththe source and the target. There are about 49, 490words shared between English and French parallelcorpora of Europarl.
During the training, in order to decide whetherto pick a word from the source sentence using at-tention/pointers or to predict the word from theshort-list vocabulary, we use the following sim-ple heuristic. If the word is not in the short-list
3In our experiments, we use an existing code, pro-vided in https://github.com/kyunghyuncho/
dl4mt-material, and on the original model we onlychanged the last softmax layer for our experiments
4We compute the BLEU score using the multi-blue.perlscript from Moses on tokenized sentence pairs.
Table 4: Generated summaries from NMT with PS. Boldface words are the words copied from the source.Source #1 china ’s tang gonghong set a world record with a clean and
jerk lift of ### kilograms to win the women ’s over-## kilogramweightlifting title at the asian games on tuesday .
Target #1 china ’s tang <unk>,sets world weightlifting recordNMT+PS #1 china ’s tang gonghong wins women ’s weightlifting weightlift-
ing title at asian gamesSource #2 owing to criticism , nbc said on wednesday that it was ending
a three-month-old experiment that would have brought the firstliquor advertisements onto national broadcast network television.
Target #2 advertising : nbc retreats from liquor commercialsNMT+PS #2 nbc says it is ending a three-month-old experimentSource #3 a senior trade union official here wednesday called on ghana ’s
government to be “ mindful of the plight ” of the ordinary peoplein the country in its decisions on tax increases .
Target #3 tuc official,on behalf of ordinary ghanaiansNMT+PS #3 ghana ’s government urged to be mindful of the plight
vocabulary, we first check if the same word y
t
ap-pears in the source sentence. If it is not, we thencheck if a translated version of the word exists inthe source sentence by using a look-up table be-tween the source and the target language. If theword is in the source sentence, we then use the lo-cation of the word in the source as the target. Oth-erwise we check if one of the English senses fromthe cross-language dictionary of the French wordis in the source. If it is in the source sentence, thenwe use the location of that word as our translation.Otherwise we just use the argmax of l
t
as the tar-get.
For switching network d
t
, we observed that us-ing a two-layered MLP with noisy-tanh activation(Gulcehre et al., 2016) function with residual con-nection from the lower layer (He et al., 2015) ac-tivation function to the upper hidden layers im-proves the BLEU score about 1 points over thed
t
using ReLU activation function. We initializedthe biases of the last sigmoid layer of d
t
to �1
such that if dt
becomes more biased toward choos-ing the shortlist vocabulary at the beginning of thetraining. We renormalize the gradients if the normof the gradients exceed 1 (Pascanu et al., 2012).
Table 5: Europarl Dataset (EN-FR)BLEU-4
NMT 20.19NMT + PS 23.76
In Table 5, we provided the result of NMT withpointer softmax and we observe about 3.6 BLEUscore improvement over our baseline.
Figure 4: A comparison of the validation learning-curves of the same NMT model trained withpointer softmax and the regular softmax layer. Ascan be seen from the figures, the model trainedwith pointer softmax converges faster than the reg-ular softmax layer. Switching network for pointersoftmax in this Figure uses ReLU activation func-tion.
In Figure 4, we show the validation curvesof the NMT model with attention and the NMTmodel with shortlist-softmax layer. Pointer soft-max converges faster in terms of number of mini-batch updates and achieves a lower validationnegative-log-likelihood (NLL) (63.91) after 200kupdates over the Europarl dataset than the NMT
<v1> ’s <v2> <v3> set a world record with a clean and jerk lift of ### kilograms to win the women ’s over-## kilogram weightlifting title at the asian games on tuesday .<v1> ’s <v2> <v3>,sets world weightlifting record

••
••
•
•
•14
ior of humans and recent advances in the atten-tion mechanism (Bahdanau et al., 2014) and thepointer networks (Vinyals et al., 2015), we pro-pose a novel method to deal with the rare or un-known word problem. The basic idea is that wecan see in many NLP problems as a task of predict-ing target text given context text, where some ofthe target words appear in the context as well. Weobserve that in this case we can make the modellearn to point a word in the context and copy it tothe target text, as well as when to point. For exam-ple, in machine translation, we can see the sourcesentence as the context, and the target sentence aswhat we need to predict. In Figure 1, we showan example depiction of how words can be copiedfrom source to target in machine translation. Al-though the source and target languages are differ-ent, many of the words such as named entities areusually represented by the same characters in bothlanguages, making it possible to copy. Similarly,in text summarization, it is natural to use somewords in the original text in the summarized textas well.
Specifically, to predict a target word at eachtimestep, our model first determines the source ofthe word generation, that is, on whether to takeone from a predefined shortlist or to copy one fromthe context. For the former, we apply the typicalsoftmax operation, and for the latter, we use theattention mechanism to obtain the pointing soft-max probability over the context words and pickthe one of high probability. The model learns thisdecision so as to use the pointing only when thecontext includes a word that can be copied to thetarget. This way, our model can predict even thewords which are not in the shortlist, as long asit appears in the context. Although some of thewords still need to be labeled as UNK, i.e., if it isneither in the shortlist nor in the context, in ex-periments we show that this learning when and
where to point improves the performance in ma-chine translation and text summarization.
The rest of the paper is organized as follows. Inthe next section, we review the related works in-cluding pointer networks and previous approachesto the rare/unknown problem. In Section 3, wereview the neural machine translation with atten-tion mechanism which is the baseline in our ex-periments. Then, in Section 4, we propose ourmethod dealing with the rare/unknown word prob-lem, called the Pointer Softmax (PS). The exper-
Guillaume et Cesar ont une voiture bleue a Lausanne.
Guillaume and Cesar have a blue car in Lausanne.Copy Copy Copy
French:
English:
Figure 1: An example of how copying can happenfor machine translation. Common words that ap-pear both in source and the target can directly becopied from input to source. The rest of the un-known in the target can be copied from the inputafter being translated with a dictionary.
imental results are provided in the Section 5 andwe conclude our work in Section 6.
2 Related Work
The attention-based pointing mechanism is intro-duced first in the pointer networks (Vinyals et al.,2015). In the pointer networks, the output space ofthe target sequence is constrained to be the obser-vations in the input sequence (not the input space).Instead of having a fixed dimension softmax out-put layer, softmax outputs of varying dimension isdynamically computed for each input sequence insuch a way to maximize the attention probabilityof the target input. However, its applicability israther limited because, unlike our model, there isno option to choose whether to point or not; it al-ways points. In this sense, we can see the pointernetworks as a special case of our model where wealways choose to point a context word.
Several approaches have been proposed towardssolving the rare words/unknown words problem,which can be broadly divided into three categories.The first category of the approaches focuses onimproving the computation speed of the softmaxoutput so that it can maintain a very large vocabu-lary. Because this only increases the shortlist size,it helps to mitigate the unknown word problem,but still suffers from the rare word problem. Thehierarchical softmax (Morin and Bengio, 2005),importance sampling (Bengio and Senecal, 2008;Jean et al., 2014), and the noise contrastive esti-mation (Gutmann and Hyvarinen, 2012; Mnih andKavukcuoglu, 2013) methods are in the class.
The second category, where our proposedmethod also belongs to, uses information from thecontext. Notable works are (Luong et al., 2015)and (Hermann et al., 2015). In particular, ap-plying to machine translation task, (Luong et al.,2015) learns to point some words in source sen-tence and copy it to the target sentence, similarly

••
••
15
Table 4: Generated summaries from NMT with PS. Boldface words are the words copied from the source.Source #1 china ’s tang gonghong set a world record with a clean and
jerk lift of ### kilograms to win the women ’s over-## kilogramweightlifting title at the asian games on tuesday .
Target #1 china ’s tang <unk>,sets world weightlifting recordNMT+PS #1 china ’s tang gonghong wins women ’s weightlifting weightlift-
ing title at asian gamesSource #2 owing to criticism , nbc said on wednesday that it was ending
a three-month-old experiment that would have brought the firstliquor advertisements onto national broadcast network television.
Target #2 advertising : nbc retreats from liquor commercialsNMT+PS #2 nbc says it is ending a three-month-old experimentSource #3 a senior trade union official here wednesday called on ghana ’s
government to be “ mindful of the plight ” of the ordinary peoplein the country in its decisions on tax increases .
Target #3 tuc official,on behalf of ordinary ghanaiansNMT+PS #3 ghana ’s government urged to be mindful of the plight
vocabulary, we first check if the same word y
t
ap-pears in the source sentence. If it is not, we thencheck if a translated version of the word exists inthe source sentence by using a look-up table be-tween the source and the target language. If theword is in the source sentence, we then use the lo-cation of the word in the source as the target. Oth-erwise we check if one of the English senses fromthe cross-language dictionary of the French wordis in the source. If it is in the source sentence, thenwe use the location of that word as our translation.Otherwise we just use the argmax of l
t
as the tar-get.
For switching network d
t
, we observed that us-ing a two-layered MLP with noisy-tanh activation(Gulcehre et al., 2016) function with residual con-nection from the lower layer (He et al., 2015) ac-tivation function to the upper hidden layers im-proves the BLEU score about 1 points over thed
t
using ReLU activation function. We initializedthe biases of the last sigmoid layer of d
t
to �1
such that if dt
becomes more biased toward choos-ing the shortlist vocabulary at the beginning of thetraining. We renormalize the gradients if the normof the gradients exceed 1 (Pascanu et al., 2012).
Table 5: Europarl Dataset (EN-FR)BLEU-4
NMT 20.19NMT + PS 23.76
In Table 5, we provided the result of NMT withpointer softmax and we observe about 3.6 BLEUscore improvement over our baseline.
Figure 4: A comparison of the validation learning-curves of the same NMT model trained withpointer softmax and the regular softmax layer. Ascan be seen from the figures, the model trainedwith pointer softmax converges faster than the reg-ular softmax layer. Switching network for pointersoftmax in this Figure uses ReLU activation func-tion.
In Figure 4, we show the validation curvesof the NMT model with attention and the NMTmodel with shortlist-softmax layer. Pointer soft-max converges faster in terms of number of mini-batch updates and achieves a lower validationnegative-log-likelihood (NLL) (63.91) after 200kupdates over the Europarl dataset than the NMT
Table 4: Generated summaries from NMT with PS. Boldface words are the words copied from the source.Source #1 china ’s tang gonghong set a world record with a clean and
jerk lift of ### kilograms to win the women ’s over-## kilogramweightlifting title at the asian games on tuesday .
Target #1 china ’s tang <unk>,sets world weightlifting recordNMT+PS #1 china ’s tang gonghong wins women ’s weightlifting weightlift-
ing title at asian gamesSource #2 owing to criticism , nbc said on wednesday that it was ending
a three-month-old experiment that would have brought the firstliquor advertisements onto national broadcast network television.
Target #2 advertising : nbc retreats from liquor commercialsNMT+PS #2 nbc says it is ending a three-month-old experimentSource #3 a senior trade union official here wednesday called on ghana ’s
government to be “ mindful of the plight ” of the ordinary peoplein the country in its decisions on tax increases .
Target #3 tuc official,on behalf of ordinary ghanaiansNMT+PS #3 ghana ’s government urged to be mindful of the plight
vocabulary, we first check if the same word y
t
ap-pears in the source sentence. If it is not, we thencheck if a translated version of the word exists inthe source sentence by using a look-up table be-tween the source and the target language. If theword is in the source sentence, we then use the lo-cation of the word in the source as the target. Oth-erwise we check if one of the English senses fromthe cross-language dictionary of the French wordis in the source. If it is in the source sentence, thenwe use the location of that word as our translation.Otherwise we just use the argmax of l
t
as the tar-get.
For switching network d
t
, we observed that us-ing a two-layered MLP with noisy-tanh activation(Gulcehre et al., 2016) function with residual con-nection from the lower layer (He et al., 2015) ac-tivation function to the upper hidden layers im-proves the BLEU score about 1 points over thed
t
using ReLU activation function. We initializedthe biases of the last sigmoid layer of d
t
to �1
such that if dt
becomes more biased toward choos-ing the shortlist vocabulary at the beginning of thetraining. We renormalize the gradients if the normof the gradients exceed 1 (Pascanu et al., 2012).
Table 5: Europarl Dataset (EN-FR)BLEU-4
NMT 20.19NMT + PS 23.76
In Table 5, we provided the result of NMT withpointer softmax and we observe about 3.6 BLEUscore improvement over our baseline.
Figure 4: A comparison of the validation learning-curves of the same NMT model trained withpointer softmax and the regular softmax layer. Ascan be seen from the figures, the model trainedwith pointer softmax converges faster than the reg-ular softmax layer. Switching network for pointersoftmax in this Figure uses ReLU activation func-tion.
In Figure 4, we show the validation curvesof the NMT model with attention and the NMTmodel with shortlist-softmax layer. Pointer soft-max converges faster in terms of number of mini-batch updates and achieves a lower validationnegative-log-likelihood (NLL) (63.91) after 200kupdates over the Europarl dataset than the NMT

•
•
•
16
h2 hTh1 …st ct
ywt
yt-1
Vocabulary softmax
Attention distribution (lt)
Source Sequence
x2 xTx1 …BiRNN
Target Sequence
st-1
Figure 2: A depiction of neural machine transla-tion architecture with attention. At each timestep,the model generates the attention distribution l
t
.We use l
t
and the encoder’s hidden states to obtainthe context c
t
. The decoder uses c
t
to predict avector of probabilities for the words w
t
by usingvocabulary softmax.
4 The Pointer Softmax
In this section, we introduce our method, called asthe pointer softmax (PS), to deal with the rare andunknown words. The pointer softmax can be anapplicable approach to many NLP tasks, becauseit resolves the limitations about unknown wordsfor neural networks. It can be used in parallel withother existing techniques such as the large vocabu-lary trick (Jean et al., 2014). Our model learns twokey abilities jointly to make the pointing mech-anism applicable in more general settings: (i) topredict whether it is required to use the pointingor not at each time step and (ii) to point any lo-cation of the context sequence whose length canvary widely over examples. Note that the pointernetworks (Vinyals et al., 2015) are in lack of theability (i), and the ability (ii) is not achieved in themodels by (Luong et al., 2015).
To achieve this, our model uses two softmaxoutput layers, the shortlist softmax and the loca-
tion softmax. The shortlist softmax is the sameas the typical softmax output layer where eachdimension corresponds a word in the predefinedword shortlist. The location softmax is a pointernetwork where each of the output dimension cor-responds to the location of a word in the contextsequence. Thus, the output dimension of the loca-tion softmax varies according to the length of thegiven context sequence.
At each time-step, if the model decides to usethe shortlist softmax, we generate a word w
t
fromthe shortlist. Otherwise, if it is expected that thecontext sequence contains a word which needs to
be generated at the time step, we obtain the loca-tion of the context word l
t
from the location soft-max. The key to making this possible is decid-ing when to use the shortlist softmax or the lo-cation softmax at each time step. In order to ac-complish this, we introduce a switching networkto the model. The switching network, which isa multilayer perceptron in our experiments, takesthe representation of the context sequence (similarto the input annotation in NMT) and the previoushidden state of the output RNN as its input. It out-puts a binary variable z
t
which indicates whetherto use the shortlist softmax (when z
t
= 1) or thelocation softmax (when z
t
= 0). Note that if theword that is expected to be generated at each time-step is neither in the shortlist nor in the context se-quence, the switching network selects the shortlistsoftmax, and then the shortlist softmax predictsUNK. The details of the pointer softmax model canbe seen in Figure 3 as well.
h2 hTh1 …st ct
zt yltyw
t
yt-1
Vocabulary softmax
Pointer distribution (lt)
Source Sequence
Point & copy
x2 xTx1 …BiRNN
Target Sequence
p 1-p
st-1
Figure 3: A depiction of the Pointer Softmax (PS)architecture. At each timestep, l
t
, ct
and w
t
forthe words over the limited vocabulary (shortlist)is generated. We have an additional switchingvariable z
t
that decides whether to use vocabularyword or to copy a word from the source sequence.
More specifically, our goal is to maximize theprobability of observing the target word sequencey = (y1, y2, . . . , yT
y
) and the word generationsource z = (z1, z2, . . . , zT
y
), given the context se-quence x = (x1, x2, . . . , xT
x
):
p
✓
(y, z|x) =T
yY
t=1
p
✓
(y
t
, z
t
|y<t
, z
<t
,x). (4)
Note that the word observation y
t
can be eithera word w
t
from the shortlist softmax or a loca-tion l
t
from the location softmax, depending onthe switching variable z
t
.Considering this, we can factorize the above

Ø
Ø
Ø
Ø
Ø
Ø
17
Figure 4: A comparison of the validation learning-curves of the same NMT model trained withpointer softmax and the regular softmax layer. Ascan be seen from the figures, the model trainedwith pointer softmax converges faster than the reg-ular softmax layer. Switching network for pointersoftmax in this Figure uses ReLU activation func-tion.
ification over the NMT, our model is able to gen-eralize to the unseen words and can deal with rare-words more efficiently. For the summarizationtask on Gigaword dataset, the pointer softmax wasable to improve the results even when it is usedtogether with the large-vocabulary trick. In thecase of neural machine translation, we observedthat the training with the pointer softmax is alsoimproved the convergence speed of the model aswell. For French to English machine translationon Europarl corpora, we observe that using thepointer softmax can also improve the training con-vergence of the model.
References
[Bahdanau et al.2014] Dzmitry Bahdanau, KyunghyunCho, and Yoshua Bengio. 2014. Neural machinetranslation by jointly learning to align and translate.CoRR, abs/1409.0473.
[Bengio and Senecal2008] Yoshua Bengio and Jean-Sebastien Senecal. 2008. Adaptive importancesampling to accelerate training of a neural proba-bilistic language model. Neural Networks, IEEE
Transactions on, 19(4):713–722.
[Bordes et al.2015] Antoine Bordes, Nicolas Usunier,Sumit Chopra, and Jason Weston. 2015. Large-scale simple question answering with memory net-works. arXiv preprint arXiv:1506.02075.
[Cheng and Lapata2016] Jianpeng Cheng and MirellaLapata. 2016. Neural summarization by ex-
tracting sentences and words. arXiv preprint
arXiv:1603.07252.
[Cho et al.2014] Kyunghyun Cho, BartVan Merrienboer, Caglar Gulcehre, DzmitryBahdanau, Fethi Bougares, Holger Schwenk,and Yoshua Bengio. 2014. Learning phraserepresentations using rnn encoder-decoder forstatistical machine translation. arXiv preprint
arXiv:1406.1078.
[Chung et al.2014] Junyoung Chung, Caglar Gulcehre,KyungHyun Cho, and Yoshua Bengio. 2014. Em-pirical evaluation of gated recurrent neural networkson sequence modeling. CoRR, abs/1412.3555.
[Gillick et al.2015] Dan Gillick, Cliff Brunk, OriolVinyals, and Amarnag Subramanya. 2015. Mul-tilingual language processing from bytes. arXiv
preprint arXiv:1512.00103.
[Graves2013] Alex Graves. 2013. Generating se-quences with recurrent neural networks. arXiv
preprint arXiv:1308.0850.
[Gu et al.2016] Jiatao Gu, Zhengdong Lu, Hang Li,and Victor OK Li. 2016. Incorporating copyingmechanism in sequence-to-sequence learning. arXiv
preprint arXiv:1603.06393.
[Gulcehre et al.2016] Caglar Gulcehre, MarcinMoczulski, Misha Denil, and Yoshua Bengio.2016. Noisy activation functions. arXiv preprint
arXiv:1603.00391.
[Gutmann and Hyvarinen2012] Michael U Gutmannand Aapo Hyvarinen. 2012. Noise-contrastive esti-mation of unnormalized statistical models, with ap-plications to natural image statistics. The Journal of
Machine Learning Research, 13(1):307–361.
[He et al.2015] Kaiming He, Xiangyu Zhang, Shao-qing Ren, and Jian Sun. 2015. Deep resid-ual learning for mage recognition. arXiv preprint
arXiv:1512.03385.
[Hermann et al.2015] Karl Moritz Hermann, TomasKocisky, Edward Grefenstette, Lasse Espeholt, WillKay, Mustafa Suleyman, and Phil Blunsom. 2015.Teaching machines to read and comprehend. In Ad-
vances in Neural Information Processing Systems,pages 1684–1692.
[Jean et al.2014] Sebastien Jean, Kyunghyun Cho,Roland Memisevic, and Yoshua Bengio. 2014. Onusing very large target vocabulary for neural ma-chine translation. arXiv preprint arXiv:1412.2007.
[Kingma and Adam2015] Diederik P Kingma andJimmy Ba Adam. 2015. A method for stochasticoptimization. In International Conference on
Learning Representation.
[Luong et al.2015] Minh-Thang Luong, Ilya Sutskever,Quoc V Le, Oriol Vinyals, and Wojciech Zaremba.2015. Addressing the rare word problem in neuralmachine translation. In Proceedings of ACL.
148
[Matthews et al.2012] Danielle Matthews, TanyaBehne, Elena Lieven, and Michael Tomasello.2012. Origins of the human pointing gesture: atraining study. Developmental science, 15(6):817–829.
[Mnih and Kavukcuoglu2013] Andriy Mnih and KorayKavukcuoglu. 2013. Learning word embeddingsefficiently with noise-contrastive estimation. In Ad-
vances in Neural Information Processing Systems,pages 2265–2273.
[Morin and Bengio2005] Frederic Morin and YoshuaBengio. 2005. Hierarchical probabilistic neural net-work language model. In Aistats, volume 5, pages246–252. Citeseer.
[Pascanu et al.2012] Razvan Pascanu, Tomas Mikolov,and Yoshua Bengio. 2012. On the difficulty oftraining recurrent neural networks. arXiv preprint
arXiv:1211.5063.
[Pascanu et al.2013] Razvan Pascanu, Caglar Gulcehre,Kyunghyun Cho, and Yoshua Bengio. 2013. Howto construct deep recurrent neural networks. arXiv
preprint arXiv:1312.6026.
[Rush et al.2015] Alexander M. Rush, Sumit Chopra,and Jason Weston. 2015. A neural attention modelfor abstractive sentence summarization. CoRR,abs/1509.00685.
[Schuster and Paliwal1997] Mike Schuster andKuldip K Paliwal. 1997. Bidirectional recur-rent neural networks. Signal Processing, IEEE
Transactions on, 45(11):2673–2681.
[Sennrich et al.2015] Rico Sennrich, Barry Haddow,and Alexandra Birch. 2015. Neural machine trans-lation of rare words with subword units. arXiv
preprint arXiv:1508.07909.
[Theano Development Team2016] Theano Develop-ment Team. 2016. Theano: A Python frameworkfor fast computation of mathematical expressions.arXiv e-prints, abs/1605.02688, May.
[Tomasello et al.2007] Michael Tomasello, MalindaCarpenter, and Ulf Liszkowski. 2007. A new look atinfant pointing. Child development, 78(3):705–722.
[Vinyals et al.2015] Oriol Vinyals, Meire Fortunato,and Navdeep Jaitly. 2015. Pointer networks. In Ad-
vances in Neural Information Processing Systems,pages 2674–2682.
[Zeiler2012] Matthew D Zeiler. 2012. Adadelta:an adaptive learning rate method. arXiv preprint
arXiv:1212.5701.
7 Acknowledgments
We would also like to thank the developers ofTheano 5, for developing such a powerful tool
5http://deeplearning.net/software/
theano/
for scientific computing (Theano DevelopmentTeam, 2016). We acknowledge the support ofthe following organizations for research fundingand computing support: NSERC, Samsung, Cal-cul Quebec, Compute Canada, the Canada Re-search Chairs and CIFAR. C. G. thanks for IBMT.J. Watson Research for funding this researchduring his internship between October 2015 andJanuary 2016.
149
Figure 4: A comparison of the validation learning-curves of the same NMT model trained withpointer softmax and the regular softmax layer. Ascan be seen from the figures, the model trainedwith pointer softmax converges faster than the reg-ular softmax layer. Switching network for pointersoftmax in this Figure uses ReLU activation func-tion.
ification over the NMT, our model is able to gen-eralize to the unseen words and can deal with rare-words more efficiently. For the summarizationtask on Gigaword dataset, the pointer softmax wasable to improve the results even when it is usedtogether with the large-vocabulary trick. In thecase of neural machine translation, we observedthat the training with the pointer softmax is alsoimproved the convergence speed of the model aswell. For French to English machine translationon Europarl corpora, we observe that using thepointer softmax can also improve the training con-vergence of the model.
References
[Bahdanau et al.2014] Dzmitry Bahdanau, KyunghyunCho, and Yoshua Bengio. 2014. Neural machinetranslation by jointly learning to align and translate.CoRR, abs/1409.0473.
[Bengio and Senecal2008] Yoshua Bengio and Jean-Sebastien Senecal. 2008. Adaptive importancesampling to accelerate training of a neural proba-bilistic language model. Neural Networks, IEEE
Transactions on, 19(4):713–722.
[Bordes et al.2015] Antoine Bordes, Nicolas Usunier,Sumit Chopra, and Jason Weston. 2015. Large-scale simple question answering with memory net-works. arXiv preprint arXiv:1506.02075.
[Cheng and Lapata2016] Jianpeng Cheng and MirellaLapata. 2016. Neural summarization by ex-
tracting sentences and words. arXiv preprint
arXiv:1603.07252.
[Cho et al.2014] Kyunghyun Cho, BartVan Merrienboer, Caglar Gulcehre, DzmitryBahdanau, Fethi Bougares, Holger Schwenk,and Yoshua Bengio. 2014. Learning phraserepresentations using rnn encoder-decoder forstatistical machine translation. arXiv preprint
arXiv:1406.1078.
[Chung et al.2014] Junyoung Chung, Caglar Gulcehre,KyungHyun Cho, and Yoshua Bengio. 2014. Em-pirical evaluation of gated recurrent neural networkson sequence modeling. CoRR, abs/1412.3555.
[Gillick et al.2015] Dan Gillick, Cliff Brunk, OriolVinyals, and Amarnag Subramanya. 2015. Mul-tilingual language processing from bytes. arXiv
preprint arXiv:1512.00103.
[Graves2013] Alex Graves. 2013. Generating se-quences with recurrent neural networks. arXiv
preprint arXiv:1308.0850.
[Gu et al.2016] Jiatao Gu, Zhengdong Lu, Hang Li,and Victor OK Li. 2016. Incorporating copyingmechanism in sequence-to-sequence learning. arXiv
preprint arXiv:1603.06393.
[Gulcehre et al.2016] Caglar Gulcehre, MarcinMoczulski, Misha Denil, and Yoshua Bengio.2016. Noisy activation functions. arXiv preprint
arXiv:1603.00391.
[Gutmann and Hyvarinen2012] Michael U Gutmannand Aapo Hyvarinen. 2012. Noise-contrastive esti-mation of unnormalized statistical models, with ap-plications to natural image statistics. The Journal of
Machine Learning Research, 13(1):307–361.
[He et al.2015] Kaiming He, Xiangyu Zhang, Shao-qing Ren, and Jian Sun. 2015. Deep resid-ual learning for mage recognition. arXiv preprint
arXiv:1512.03385.
[Hermann et al.2015] Karl Moritz Hermann, TomasKocisky, Edward Grefenstette, Lasse Espeholt, WillKay, Mustafa Suleyman, and Phil Blunsom. 2015.Teaching machines to read and comprehend. In Ad-
vances in Neural Information Processing Systems,pages 1684–1692.
[Jean et al.2014] Sebastien Jean, Kyunghyun Cho,Roland Memisevic, and Yoshua Bengio. 2014. Onusing very large target vocabulary for neural ma-chine translation. arXiv preprint arXiv:1412.2007.
[Kingma and Adam2015] Diederik P Kingma andJimmy Ba Adam. 2015. A method for stochasticoptimization. In International Conference on
Learning Representation.
[Luong et al.2015] Minh-Thang Luong, Ilya Sutskever,Quoc V Le, Oriol Vinyals, and Wojciech Zaremba.2015. Addressing the rare word problem in neuralmachine translation. In Proceedings of ACL.
148
Figure 4: A comparison of the validation learning-curves of the same NMT model trained withpointer softmax and the regular softmax layer. Ascan be seen from the figures, the model trainedwith pointer softmax converges faster than the reg-ular softmax layer. Switching network for pointersoftmax in this Figure uses ReLU activation func-tion.
ification over the NMT, our model is able to gen-eralize to the unseen words and can deal with rare-words more efficiently. For the summarizationtask on Gigaword dataset, the pointer softmax wasable to improve the results even when it is usedtogether with the large-vocabulary trick. In thecase of neural machine translation, we observedthat the training with the pointer softmax is alsoimproved the convergence speed of the model aswell. For French to English machine translationon Europarl corpora, we observe that using thepointer softmax can also improve the training con-vergence of the model.
References
[Bahdanau et al.2014] Dzmitry Bahdanau, KyunghyunCho, and Yoshua Bengio. 2014. Neural machinetranslation by jointly learning to align and translate.CoRR, abs/1409.0473.
[Bengio and Senecal2008] Yoshua Bengio and Jean-Sebastien Senecal. 2008. Adaptive importancesampling to accelerate training of a neural proba-bilistic language model. Neural Networks, IEEE
Transactions on, 19(4):713–722.
[Bordes et al.2015] Antoine Bordes, Nicolas Usunier,Sumit Chopra, and Jason Weston. 2015. Large-scale simple question answering with memory net-works. arXiv preprint arXiv:1506.02075.
[Cheng and Lapata2016] Jianpeng Cheng and MirellaLapata. 2016. Neural summarization by ex-
tracting sentences and words. arXiv preprint
arXiv:1603.07252.
[Cho et al.2014] Kyunghyun Cho, BartVan Merrienboer, Caglar Gulcehre, DzmitryBahdanau, Fethi Bougares, Holger Schwenk,and Yoshua Bengio. 2014. Learning phraserepresentations using rnn encoder-decoder forstatistical machine translation. arXiv preprint
arXiv:1406.1078.
[Chung et al.2014] Junyoung Chung, Caglar Gulcehre,KyungHyun Cho, and Yoshua Bengio. 2014. Em-pirical evaluation of gated recurrent neural networkson sequence modeling. CoRR, abs/1412.3555.
[Gillick et al.2015] Dan Gillick, Cliff Brunk, OriolVinyals, and Amarnag Subramanya. 2015. Mul-tilingual language processing from bytes. arXiv
preprint arXiv:1512.00103.
[Graves2013] Alex Graves. 2013. Generating se-quences with recurrent neural networks. arXiv
preprint arXiv:1308.0850.
[Gu et al.2016] Jiatao Gu, Zhengdong Lu, Hang Li,and Victor OK Li. 2016. Incorporating copyingmechanism in sequence-to-sequence learning. arXiv
preprint arXiv:1603.06393.
[Gulcehre et al.2016] Caglar Gulcehre, MarcinMoczulski, Misha Denil, and Yoshua Bengio.2016. Noisy activation functions. arXiv preprint
arXiv:1603.00391.
[Gutmann and Hyvarinen2012] Michael U Gutmannand Aapo Hyvarinen. 2012. Noise-contrastive esti-mation of unnormalized statistical models, with ap-plications to natural image statistics. The Journal of
Machine Learning Research, 13(1):307–361.
[He et al.2015] Kaiming He, Xiangyu Zhang, Shao-qing Ren, and Jian Sun. 2015. Deep resid-ual learning for mage recognition. arXiv preprint
arXiv:1512.03385.
[Hermann et al.2015] Karl Moritz Hermann, TomasKocisky, Edward Grefenstette, Lasse Espeholt, WillKay, Mustafa Suleyman, and Phil Blunsom. 2015.Teaching machines to read and comprehend. In Ad-
vances in Neural Information Processing Systems,pages 1684–1692.
[Jean et al.2014] Sebastien Jean, Kyunghyun Cho,Roland Memisevic, and Yoshua Bengio. 2014. Onusing very large target vocabulary for neural ma-chine translation. arXiv preprint arXiv:1412.2007.
[Kingma and Adam2015] Diederik P Kingma andJimmy Ba Adam. 2015. A method for stochasticoptimization. In International Conference on
Learning Representation.
[Luong et al.2015] Minh-Thang Luong, Ilya Sutskever,Quoc V Le, Oriol Vinyals, and Wojciech Zaremba.2015. Addressing the rare word problem in neuralmachine translation. In Proceedings of ACL.
148
Figure 4: A comparison of the validation learning-curves of the same NMT model trained withpointer softmax and the regular softmax layer. Ascan be seen from the figures, the model trainedwith pointer softmax converges faster than the reg-ular softmax layer. Switching network for pointersoftmax in this Figure uses ReLU activation func-tion.
ification over the NMT, our model is able to gen-eralize to the unseen words and can deal with rare-words more efficiently. For the summarizationtask on Gigaword dataset, the pointer softmax wasable to improve the results even when it is usedtogether with the large-vocabulary trick. In thecase of neural machine translation, we observedthat the training with the pointer softmax is alsoimproved the convergence speed of the model aswell. For French to English machine translationon Europarl corpora, we observe that using thepointer softmax can also improve the training con-vergence of the model.
References
[Bahdanau et al.2014] Dzmitry Bahdanau, KyunghyunCho, and Yoshua Bengio. 2014. Neural machinetranslation by jointly learning to align and translate.CoRR, abs/1409.0473.
[Bengio and Senecal2008] Yoshua Bengio and Jean-Sebastien Senecal. 2008. Adaptive importancesampling to accelerate training of a neural proba-bilistic language model. Neural Networks, IEEE
Transactions on, 19(4):713–722.
[Bordes et al.2015] Antoine Bordes, Nicolas Usunier,Sumit Chopra, and Jason Weston. 2015. Large-scale simple question answering with memory net-works. arXiv preprint arXiv:1506.02075.
[Cheng and Lapata2016] Jianpeng Cheng and MirellaLapata. 2016. Neural summarization by ex-
tracting sentences and words. arXiv preprint
arXiv:1603.07252.
[Cho et al.2014] Kyunghyun Cho, BartVan Merrienboer, Caglar Gulcehre, DzmitryBahdanau, Fethi Bougares, Holger Schwenk,and Yoshua Bengio. 2014. Learning phraserepresentations using rnn encoder-decoder forstatistical machine translation. arXiv preprint
arXiv:1406.1078.
[Chung et al.2014] Junyoung Chung, Caglar Gulcehre,KyungHyun Cho, and Yoshua Bengio. 2014. Em-pirical evaluation of gated recurrent neural networkson sequence modeling. CoRR, abs/1412.3555.
[Gillick et al.2015] Dan Gillick, Cliff Brunk, OriolVinyals, and Amarnag Subramanya. 2015. Mul-tilingual language processing from bytes. arXiv
preprint arXiv:1512.00103.
[Graves2013] Alex Graves. 2013. Generating se-quences with recurrent neural networks. arXiv
preprint arXiv:1308.0850.
[Gu et al.2016] Jiatao Gu, Zhengdong Lu, Hang Li,and Victor OK Li. 2016. Incorporating copyingmechanism in sequence-to-sequence learning. arXiv
preprint arXiv:1603.06393.
[Gulcehre et al.2016] Caglar Gulcehre, MarcinMoczulski, Misha Denil, and Yoshua Bengio.2016. Noisy activation functions. arXiv preprint
arXiv:1603.00391.
[Gutmann and Hyvarinen2012] Michael U Gutmannand Aapo Hyvarinen. 2012. Noise-contrastive esti-mation of unnormalized statistical models, with ap-plications to natural image statistics. The Journal of
Machine Learning Research, 13(1):307–361.
[He et al.2015] Kaiming He, Xiangyu Zhang, Shao-qing Ren, and Jian Sun. 2015. Deep resid-ual learning for mage recognition. arXiv preprint
arXiv:1512.03385.
[Hermann et al.2015] Karl Moritz Hermann, TomasKocisky, Edward Grefenstette, Lasse Espeholt, WillKay, Mustafa Suleyman, and Phil Blunsom. 2015.Teaching machines to read and comprehend. In Ad-
vances in Neural Information Processing Systems,pages 1684–1692.
[Jean et al.2014] Sebastien Jean, Kyunghyun Cho,Roland Memisevic, and Yoshua Bengio. 2014. Onusing very large target vocabulary for neural ma-chine translation. arXiv preprint arXiv:1412.2007.
[Kingma and Adam2015] Diederik P Kingma andJimmy Ba Adam. 2015. A method for stochasticoptimization. In International Conference on
Learning Representation.
[Luong et al.2015] Minh-Thang Luong, Ilya Sutskever,Quoc V Le, Oriol Vinyals, and Wojciech Zaremba.2015. Addressing the rare word problem in neuralmachine translation. In Proceedings of ACL.
148
[Matthews et al.2012] Danielle Matthews, TanyaBehne, Elena Lieven, and Michael Tomasello.2012. Origins of the human pointing gesture: atraining study. Developmental science, 15(6):817–829.
[Mnih and Kavukcuoglu2013] Andriy Mnih and KorayKavukcuoglu. 2013. Learning word embeddingsefficiently with noise-contrastive estimation. In Ad-
vances in Neural Information Processing Systems,pages 2265–2273.
[Morin and Bengio2005] Frederic Morin and YoshuaBengio. 2005. Hierarchical probabilistic neural net-work language model. In Aistats, volume 5, pages246–252. Citeseer.
[Pascanu et al.2012] Razvan Pascanu, Tomas Mikolov,and Yoshua Bengio. 2012. On the difficulty oftraining recurrent neural networks. arXiv preprint
arXiv:1211.5063.
[Pascanu et al.2013] Razvan Pascanu, Caglar Gulcehre,Kyunghyun Cho, and Yoshua Bengio. 2013. Howto construct deep recurrent neural networks. arXiv
preprint arXiv:1312.6026.
[Rush et al.2015] Alexander M. Rush, Sumit Chopra,and Jason Weston. 2015. A neural attention modelfor abstractive sentence summarization. CoRR,abs/1509.00685.
[Schuster and Paliwal1997] Mike Schuster andKuldip K Paliwal. 1997. Bidirectional recur-rent neural networks. Signal Processing, IEEE
Transactions on, 45(11):2673–2681.
[Sennrich et al.2015] Rico Sennrich, Barry Haddow,and Alexandra Birch. 2015. Neural machine trans-lation of rare words with subword units. arXiv
preprint arXiv:1508.07909.
[Theano Development Team2016] Theano Develop-ment Team. 2016. Theano: A Python frameworkfor fast computation of mathematical expressions.arXiv e-prints, abs/1605.02688, May.
[Tomasello et al.2007] Michael Tomasello, MalindaCarpenter, and Ulf Liszkowski. 2007. A new look atinfant pointing. Child development, 78(3):705–722.
[Vinyals et al.2015] Oriol Vinyals, Meire Fortunato,and Navdeep Jaitly. 2015. Pointer networks. In Ad-
vances in Neural Information Processing Systems,pages 2674–2682.
[Zeiler2012] Matthew D Zeiler. 2012. Adadelta:an adaptive learning rate method. arXiv preprint
arXiv:1212.5701.
7 Acknowledgments
We would also like to thank the developers ofTheano 5, for developing such a powerful tool
5http://deeplearning.net/software/
theano/
for scientific computing (Theano DevelopmentTeam, 2016). We acknowledge the support ofthe following organizations for research fundingand computing support: NSERC, Samsung, Cal-cul Quebec, Compute Canada, the Canada Re-search Chairs and CIFAR. C. G. thanks for IBMT.J. Watson Research for funding this researchduring his internship between October 2015 andJanuary 2016.
149
Figure 4: A comparison of the validation learning-curves of the same NMT model trained withpointer softmax and the regular softmax layer. Ascan be seen from the figures, the model trainedwith pointer softmax converges faster than the reg-ular softmax layer. Switching network for pointersoftmax in this Figure uses ReLU activation func-tion.
ification over the NMT, our model is able to gen-eralize to the unseen words and can deal with rare-words more efficiently. For the summarizationtask on Gigaword dataset, the pointer softmax wasable to improve the results even when it is usedtogether with the large-vocabulary trick. In thecase of neural machine translation, we observedthat the training with the pointer softmax is alsoimproved the convergence speed of the model aswell. For French to English machine translationon Europarl corpora, we observe that using thepointer softmax can also improve the training con-vergence of the model.
References
[Bahdanau et al.2014] Dzmitry Bahdanau, KyunghyunCho, and Yoshua Bengio. 2014. Neural machinetranslation by jointly learning to align and translate.CoRR, abs/1409.0473.
[Bengio and Senecal2008] Yoshua Bengio and Jean-Sebastien Senecal. 2008. Adaptive importancesampling to accelerate training of a neural proba-bilistic language model. Neural Networks, IEEE
Transactions on, 19(4):713–722.
[Bordes et al.2015] Antoine Bordes, Nicolas Usunier,Sumit Chopra, and Jason Weston. 2015. Large-scale simple question answering with memory net-works. arXiv preprint arXiv:1506.02075.
[Cheng and Lapata2016] Jianpeng Cheng and MirellaLapata. 2016. Neural summarization by ex-
tracting sentences and words. arXiv preprint
arXiv:1603.07252.
[Cho et al.2014] Kyunghyun Cho, BartVan Merrienboer, Caglar Gulcehre, DzmitryBahdanau, Fethi Bougares, Holger Schwenk,and Yoshua Bengio. 2014. Learning phraserepresentations using rnn encoder-decoder forstatistical machine translation. arXiv preprint
arXiv:1406.1078.
[Chung et al.2014] Junyoung Chung, Caglar Gulcehre,KyungHyun Cho, and Yoshua Bengio. 2014. Em-pirical evaluation of gated recurrent neural networkson sequence modeling. CoRR, abs/1412.3555.
[Gillick et al.2015] Dan Gillick, Cliff Brunk, OriolVinyals, and Amarnag Subramanya. 2015. Mul-tilingual language processing from bytes. arXiv
preprint arXiv:1512.00103.
[Graves2013] Alex Graves. 2013. Generating se-quences with recurrent neural networks. arXiv
preprint arXiv:1308.0850.
[Gu et al.2016] Jiatao Gu, Zhengdong Lu, Hang Li,and Victor OK Li. 2016. Incorporating copyingmechanism in sequence-to-sequence learning. arXiv
preprint arXiv:1603.06393.
[Gulcehre et al.2016] Caglar Gulcehre, MarcinMoczulski, Misha Denil, and Yoshua Bengio.2016. Noisy activation functions. arXiv preprint
arXiv:1603.00391.
[Gutmann and Hyvarinen2012] Michael U Gutmannand Aapo Hyvarinen. 2012. Noise-contrastive esti-mation of unnormalized statistical models, with ap-plications to natural image statistics. The Journal of
Machine Learning Research, 13(1):307–361.
[He et al.2015] Kaiming He, Xiangyu Zhang, Shao-qing Ren, and Jian Sun. 2015. Deep resid-ual learning for mage recognition. arXiv preprint
arXiv:1512.03385.
[Hermann et al.2015] Karl Moritz Hermann, TomasKocisky, Edward Grefenstette, Lasse Espeholt, WillKay, Mustafa Suleyman, and Phil Blunsom. 2015.Teaching machines to read and comprehend. In Ad-
vances in Neural Information Processing Systems,pages 1684–1692.
[Jean et al.2014] Sebastien Jean, Kyunghyun Cho,Roland Memisevic, and Yoshua Bengio. 2014. Onusing very large target vocabulary for neural ma-chine translation. arXiv preprint arXiv:1412.2007.
[Kingma and Adam2015] Diederik P Kingma andJimmy Ba Adam. 2015. A method for stochasticoptimization. In International Conference on
Learning Representation.
[Luong et al.2015] Minh-Thang Luong, Ilya Sutskever,Quoc V Le, Oriol Vinyals, and Wojciech Zaremba.2015. Addressing the rare word problem in neuralmachine translation. In Proceedings of ACL.
148
ing to align and translate. arXiv preprintarXiv:1409.0473 .
P. J. Barrio, D. G. Goldstein, and J. M. Hofman.2016. Improving the comprehension of num-bers in the news. In Conference on Human Fac-tors in Computing Systems (CHI).
T. Berg-Kirkpatrick, D. Burkett, and D. Klein.2012. An empirical investigation of statisticalsignificance in NLP. In Empirical Methods inNatural Language Processing (EMNLP). pages995–1005.
K. Bollacker, C. Evans, P. Paritosh, T. Sturge, andJ. Taylor. 2008. Freebase: a collaborativelycreated graph database for structuring humanknowledge. In International Conference onManagement of Data (SIGMOD). pages 1247–1250.
S. Bowman, G. Angeli, C. Potts, and C. D. Man-ning. 2015. A large annotated corpus for learn-ing natural language inference. In Empiri-cal Methods in Natural Language Processing(EMNLP).
D. L. Chen and R. J. Mooney. 2008. Learning tosportscast: A test of grounded language acqui-sition. In International Conference on MachineLearning (ICML). pages 128–135.
F. Chevalier, R. Vuillemot, and G. Gali. 2013. Us-ing concrete scales: A practical framework foreffective visual depiction of complex measures.IEEE Transactions on Visualization and Com-puter Graphics 19:2426–2435.
G. Chiacchieri. 2013. Dictionary of numbers.http://www.dictionaryofnumbers.
com/.
A. Fader, S. Soderland, and O. Etzioni. 2011.Identifying relations for open information ex-traction. In Empirical Methods in Natural Lan-guage Processing (EMNLP).
R. Jia and P. Liang. 2016. Data recombinationfor neural semantic parsing. In Association forComputational Linguistics (ACL).
M. G. Jones and A. R. Taylor. 2009. Developinga sense of scale: Looking backward. Journal ofResearch in Science Teaching 46:460–475.
Y. Kim, J. Hullman, and M. Agarwala. 2016. Gen-erating personalized spatial analogies for dis-tances and areas. In Conference on Human Fac-tors in Computing Systems (CHI).
W. Lu and H. T. Ng. 2012. A probabilistic forest-to-string model for language generation fromtyped lambda calculus expressions. In Empir-ical Methods in Natural Language Processing(EMNLP). pages 1611–1622.
M. Luong, H. Pham, and C. D. Manning. 2015.Effective approaches to attention-based neuralmachine translation. In Empirical Methods inNatural Language Processing (EMNLP). pages1412–1421.
T. Mikolov, K. Chen, G. Corrado, and Jeffrey.2013. Efficient estimation of word representa-tions in vector space. arXiv .
J. A. Paulos. 1988. Innumeracy: Mathematicalilliteracy and its consequences. Macmillan.
C. Seife. 2010. Proofiness: How you’re beingfooled by the numbers. Penguin.
I. Sutskever, O. Vinyals, and Q. V. Le. 2014. Se-quence to sequence learning with neural net-works. In Advances in Neural Information Pro-cessing Systems (NIPS). pages 3104–3112.
K. H. Teigen. 2015. Framing of numeric quanti-ties. The Wiley Blackwell Handbook of Judg-ment and Decision Making pages 568–589.
T. R. Tretter, M. G. Jones, and J. Minogue. 2006.Accuracy of scale conceptions in science: Men-tal maneuverings across many orders of spa-tial magnitude. Journal of Research in ScienceTeaching 43:1061–1085.
Y. Wang, J. Berant, and P. Liang. 2015. Buildinga semantic parser overnight. In Association forComputational Linguistics (ACL).
Y. W. Wong and R. J. Mooney. 2007. Generationby inverting a semantic parser that uses statisti-cal machine translation. In Human LanguageTechnology and North American Associationfor Computational Linguistics (HLT/NAACL).pages 172–179.





























