Embed Size (px)
Citation preview

Indian PUG 2015
11th April
Kumar Rajeev Rastogi
Prasanna
Optimizer Hint

KUMAR RAJEEV RASTOGI
Senior Technical Leader at Huawei Technology for almost 7 years
Have worked to develop various features on PostgreSQL (for internal
projects) as well as on In-House DB.
Active PostgreSQL community members, have contributed many patches.
Holds around 10 patents in my name in various DB technologies.
This is my second talk in Indian PUG, first one was last year.
Prior to this, worked at Aricent Technology for 3 years.
Blog - rajeevrastogi.blogspot.in
LinkedIn - http://in.linkedin.com/in/kumarrajeevrastogi
Who am I?

Introduction
Why Optimizer Hint
Query Hint
Statistics Hint
Data Hint
Drawback
Reference
Agenda
Introduction
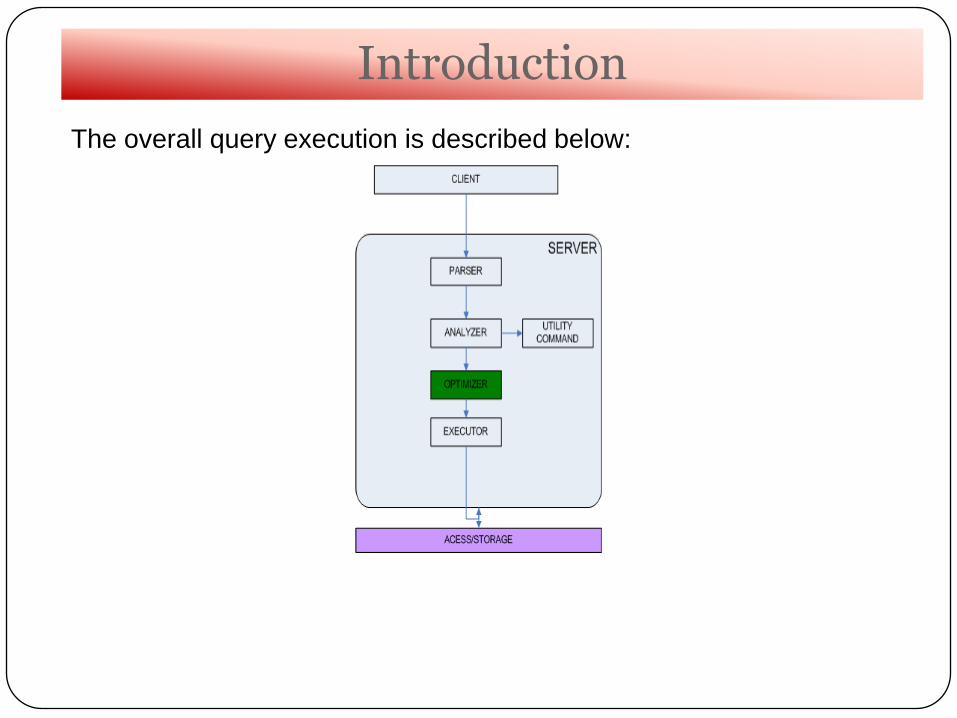
The overall query execution is described below:

Introduction Contd…
1. Parser: Parses the query submitted by the client to do the
syntactical validation. Output of this step is “parsed tree”.
2. Analyzer: It validates the parsed tree semantically.
3. Utility Commands: All of the DDL and other utility commands then
gets executed by this sub-module.
4. Optimizer: This is almost like brain of complete SQL execution
engine. It find the best possible plan for its execution.
5. Executor: The output from optimizer is “Plan Tree”, which then gets
converted to Execution Tree, where each node of the tree denotes
the kind of operation it has to do like IndexScan, SeqScan, Agg,
Join etc. Then each node gets executed to yield the final result.

Optimizer Zoomed In
It takes the validated query tree from analyzer, looks for the all the
possible plan and then selects the best plan for execution. There are
multiple possible plan because there are several different methods of
doing the same operation, some of them are:
a. Two scan algorithms (index scan, sequential scan)
b. Three core join algorithms (nested loops, hash join, merge join)
c. Join Order
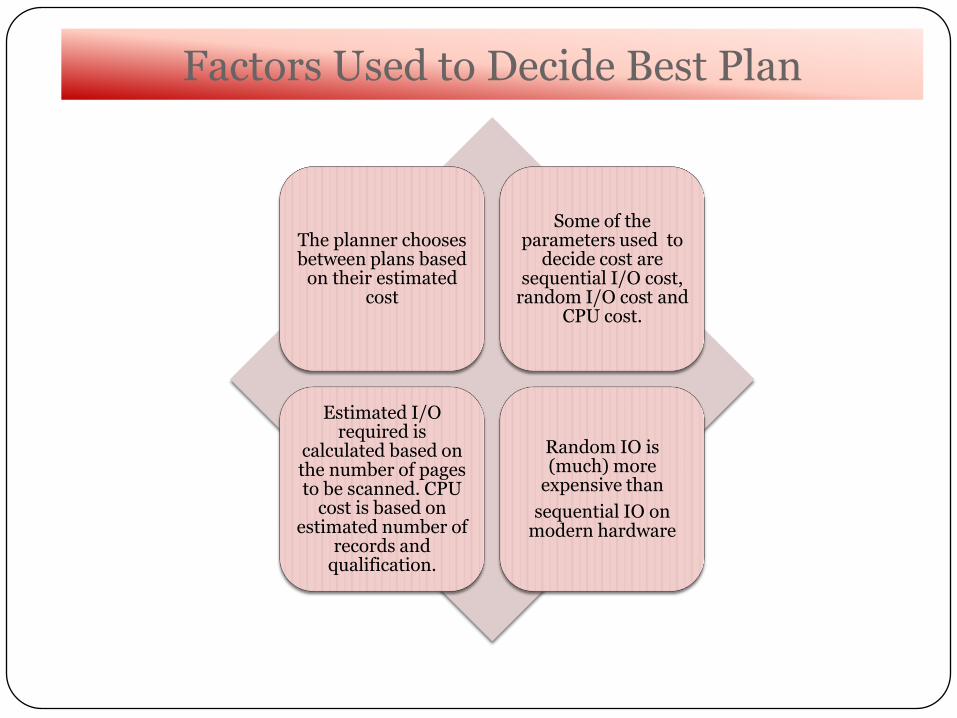
Factors Used to Decide Best Plan
The planner chooses between plans based
on their estimated cost
Some of the parameters used to
decide cost are sequential I/O cost,
random I/O cost and CPU cost.
Estimated I/O required is
calculated based on the number of pages to be scanned. CPU
cost is based on estimated number of
records and qualification.
Random IO is (much) more
expensive than
sequential IO on modern hardware

Optimizer Accuracy
It is believed that Optimizer makes best effort to produce the best
plan for execution using the parameters mentioned and actually in
majority of cases it is being accurate to give the correct and optimal
plan for execution.
“Why Optimizer Hint”?

Why Optimizer Hint
What is Optimizer Hint:
As the name suggest, it is a Hint to optimizer to change the
resultant plan as per the hint. As it is just hint, so resultant plan may
or may not be as per the hint given.
Why Optimizer Hint:
As a DBA you might know information about your data but theoptimizer may not know, in this case DBA should be able to instructthe optimizer to choose a certain query execution plan based onsome criteria.

Why Optimizer Hint: Scenario-1
Consider for a query, the possible plans for joining two tables weremerge join and nested loop join but based on the total costestimation merge join were selected as winner plan. Now considerscenario where we might require getting the first row result at theearliest, then in that case the plan with smallest start-up cost will bemore useful although total cost for this plan is more.

Why Optimizer Hint: Scenario-2
Consider the following query
SELECT * FROM TBL1, TBL3, TBL2 WHERE ….
Now lets us say the selectivity for each tables are as below:
TBL1: 0.5
TBL2: 0.5
TBL3: 0.3
Since currently planner does not maintain the selectivity for jointables or columns, then in order to check selectivity for join tables, itsimply multiply the selectivity of individual tables. So now in ourexample case, selectivity will be as below:
TBL1, TBL2: 0.5*0.5 = 0.25
TBL1, TBL3: 0.5*0.3 = 0.15
But DBA knows that the selectivity of join of TBL1 AND TBL2 is notcorrect as it will result in maximum of one record where as selectivityof join of TBL1 and TBL3 is correct.

Hint Types
1. Query Hints
2. Statistics Hints
3. Data Hints

Query Hint
This kind of hints force optimizer to choose desired plan on specific
relation or join of relations. E.g. DBA can specify to select
Sequence scan path for scanning a relation.
Index scan path for scanning a relation.
Merge join path for joining two relations.
Order to evaluate join of relations.

Query Hint Contd…
Following are ways to provide query hint for a particular query
Hints along with query in a commented format with syntax as:
SELECT/UPDATE/DELETE/INSERT /*hint*/ ………………;
Some DB provide it as separate command instead of embedding
into query.
Sometime it is also given as property along with table name in
query.

Query Hint By Other DBs
Many databases are using query hint as optimization hint, some of
them are:
1. Oracle
2. Sybase
3. MySQL
4. EnterpriseDB PostgreSQL Plus
5. Recently we have also implemented query hint in Huawei for
internal Database.

Query Hint By Oracle: Example
Some of the hint used by Oracle in query are:
1. /*+ FULL(tbl)*/ Hint to optimizer to choose sequence scan for table
„tbl‟;
2. /*+ORDERED */ Hint to optimizer to choose the same join ordering as the table names are given in FROM clause.
3. /*+ USE_NL(tbl1 tbl2) */ Hint to optimizer to choose the nested loop join between tables ‘tbl1’ and ‘tbl2’;

Query Hint By Sybase: Example
Some of the hint used by Sybase in query are:
1. set forceplan [on|off] Hint to optimizer to choose the same joinordering as the table names are given in FROM clause, if it is on.
2. We can specify the index to use for a query using the (indexindex_name) clause in select, update, and delete statements

Query Hint By MySQL: Example
Some of the hint used by MySQL in query are:
1. /*! STRAIGHT_JOIN */ This hint tells optimizer to join the tables in theorder that they are specified in the FROM clause. (MySQL hint is similarto oracle except it uses ‘!’ instead of ‘+’.
2. USE {INDEX|KEY} (index_list)] Provide hints to give the optimizerinformation about how to choose indexes during query processing

Query Hint By EDB: Example
Hint used in EDB are similar to used in Oracle:
1. /*+ FULL(tbl)*/ Hint to optimizer to choose sequence scan for table
„tbl‟;
2. /*+ORDERED */ Hint to optimizer to choose the same join ordering
as the table names are given in FROM clause.
3. /*+ USE_NL(tbl1 tbl2) */ Hint to optimizer to choose the nested
loop join between tables „tbl1‟ and „tbl2‟;

Does PostgreSQL has query Hint?
NO (or indirectly YES)
PostgreSQL does not support hint directly but there are many GUCconfiguration parameter, using which we can force to disable particularplan (Notice here that we can configure to disable a particular planunlike other DB, where Hint provided to choose a particular plan).
e.g.
enable_indexscan to off: Forces optimizer to skip index scan
enable_mergejoin to off: Forces optimizer to skip merge join
Also this setting is session-wise not query-wise.
Similar to hint, this setting can also be ignored if not possible to processe.g. even if we make enable_seqscan to off still it can select sequencescan to scan a table if there is no index on that particular table.
These setting are very useful for a developer or DBA working ontuning the planner or their application respectively.

Statistics Hint
Statistics Hint is used to provide any kind of possible statistics
related to query, which can be used by optimizer to yield the even
better plan compare to what it would have done otherwise.
Since most of the databases stores statistics for a particular column
or relation but doesn‟t store statistics related to join of column or
relation. Rather these databases just multiply the statistics of
individual column/relation to get the statistics of join, which may not
be always correct.
So for such case statistics based hints can be used to
provides direct statistics of join of relation or columns.

Statistics Hint: Example
Lets say there is query as
SELECT * FROM EMPLOYEE WHERE GRADE>5 AND SALARY > 10000;
If we calculate independent stats for a and b.
suppose sel(GRADE) = .2 and sel(SALARY) = .2;
then sel (GRADE and SALARY) =
sel(GRADE) * sel (SALARY) = .04.
In all practical cases if we see, these two components will be highly be dependent i.e. first column satisfy, 2nd column will also satisfy. Then in that case sel (GRADE and SALARY) should be .2 not .04. But current optimizer will be incorrect in this case and may give wrong plan.

Statistics Hint: Example Contd…
The query with statistics hint will look like:
SELECT /*+ SEL (GRADE and SALARY) AS 0.2* FROM EMPLOYEE WHERE GRADE>5 AND SALARY > 10000;

Data Hint
This kind of hints provides the information about the relationship/
dependency among relations or column to influence the plan instead
of directly hinting to provide desired plan or direct selectivity value.
Optimizer can consider dependency information to derive the
actual selectivity.

Data Hint: Example
Lets say there is a query as
SELECT * FROM TBL WHERE ID1 = 5 AND ID2=NULL;
SELECT * FROM TBL WHERE ID1 = 5 AND ID2!=NULL;
Now here if we specify that the dependency as
“If TBL.ID1 = 5 then TBL.ID2 is NULL”
then the optimizer will always consider this dependency pattern and
accordingly combined statistics for these two columns can be
choosen.

Drawback
1. Required periodic maintenance to verify that hint supplied is still giving positive result
2. Interference with upgrades: today's helpful hints become anti-performance after an upgrade.
3. Encouraging bad DBA habits slap a hint on instead of figuring out the real issue.
Reference
http://docs.oracle.com/cd/B19306_01/server.102/b14211/hintsref.htm
http://manuals.sybase.com/onlinebooks/group-as/asg1250e/ptallbk/@Generic__BookTextView/32117































