Increasing Your Prospects: Cassandra in Online Advertising
Let 'em know: #cassandra12
A little about what we do
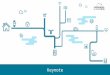
Impressions look like
A High Level look at RTB
4.M6d bids on impression. If we in we display an ad.
3.Exchanges serve as auction houses for the impressions.
1.Browsers visit Publishers and create impressions.2.Publishers
sell impressions via Exchanges.
Key Cassandra features
Horizontal scalabilityMore nodes more storage
More nodes more throughput
Cassandra is a high availability solution
Almost all changes can be made at run time
Rolling updates
Survives node failures
One configuration file
Key storage model features
Type Validation give us creature comforts
Help prevent insertion of bad dataColumns named 'age' should be
a number
Make data easier to read and write for end users
Encourage/Enforce storage in terse formatStore 478 as 478 not
478
Rows do not need to have fixed columns
Writes do not read
Optimal for set/get/slice operations
Things I have learned on the presentation circuit
Gratuitous use of Meme Generator (tx Nathan)
Gratuitous buzzwords for maximum tweet-ability Big Data
Real Time analytics
Cloud
Web scale
Make prolific statements that contradict current software trends
(tx Dean)
Attempted Prolific Statement: Transactions and locking are
highly overrated
Signal De-duplication and
frequency capping
Solution must be web-scalebillions of users
one->thousands of events per user
Solution must record events
Do not store the same event N times a minuteControl data
growthSpiders, nagios, pathological cases
Small statistical difference in signalAn action 10 times a day
vs 1 time a minute
What this would look like
'?' Solution with transactions
and locking
Likely need scalable redundant lock layerBuilt in locks are not
free
Lots of code
Lots of sockets
Likely need to read to writeResults in more nodes or caching
layer for disk io
Remember with Cassandra...
Rows have one to many columns
Column is composed of { name, value, timstamp }If two columns
have the same name > timestamp wins
Memtables absorb overwrites
Writes are fastSorted structure in memory
Commit log to disk
Log-structured storage prunes old values and deletes
No reads on write path
Cassandr'ified solution
Consistent Hashing distributes data
Random Partitioner rows keys are MD5 to locate nodeResults in
even distribution of rows across nodes
Limits/Removes hot spots
Big Data is not so big when you have N nodes attack it
* Wife asked me if diagram above was a flag. Pledge your
allegiance to the United Nodes of Big Data
Memtables absorb overwrites
Memtables give de-duplication for freeLarge memtable has larger
chance of absorbing a write
This solves our original requirement:Do not store the same event
N-times per interval
Worst-case data written to disk N-times and compacted away
Automatically de-duplicate on read with last-update-wins
rule
Casandra & stream processing as an alternative to ETL
ETL (Extract,Transform,Load) is a useful paradigm
Batch process can be obtuseProcesses with long startup
Little support for Appends, inserts, updates
Throughput issues for small files
Difficult for small windows of time
Overhead from MapReduce
Sample scenario breakdown of state, city, and count
City, State, count(1) in ETL system
Several phases / copies
Storing the entire log to build/rebuild aggregation
Difficult to do on small intervals
Needs scheduling, needs log push system
City, State, count(1) stream system
Could use Cassandra's counter feature directly
Added Apache Kafka layerDecouples producers and consumers
Allows message replay
Allows backlog and recover from failures (never happens btw)
Near real time
An application to search logs
In 2008 this article sold me on map reduce
Take logs from all servers
Put them into hadoop
Generate lucene indexes
Load into sharded SOLR cluster on interval
Pseudo diagram of solution
Process to get files from servers into hadoop
MapReduce process to build indexes
Embedded SOLR on Hadoop Datanodes
* Go here for real story:
http://www.slideshare.net/schubertzhang/case-study-how-rackspace-query-terabytes-of-data-2400928
But now its the future!
Every component or layer of an architecture is another thing
document and manage
DataStax has built SOLR into Cassandra
Applications can write to solr/cassandra directly
Applications can read solr/cassandra directly
Ah ha! moment
Determined the rackspace log application could be done with
simple pieces
Someone called it Taco Bell Programming'The more I write code
and design systems, the more I understand that many times, you can
achieve the desired functionality simply with clever
reconfigurations of the basic Unix tool set. After all,
functionality is an asset, but code is a liability.
Cassandra is my main taco ingredient
Prolific statement: Design stuff
with less arrows
Less layers/components
Low latency
More layers/components
Batch driven
Solr has wide adoption
Clients for many programming languages
Many hip JQuery Ajax widgets and stuff
Open source Reuters Ajax Solr demo worked seamlessly with
cassandra/solr
Implemented Rackspace like solution with small code
Game Changer: Compression
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 3,000 ns
Send 1K bytes over 1 Gbps network 10,000 ns 0.01 ms
Read 4K randomly from SSD* 150,000 ns 0.15 ms
Read 1 MB sequentially from memory 250,000 ns 0.25 ms
Round trip within same datacenter 500,000 ns 0.5 ms
Read 1 MB sequentially from SSD* 1,000,000 ns 1 ms 4X memory
Disk seek 10,000,000 ns 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from disk 20,000,000 ns 20 ms 80x memory,
20X SSD
Source: https://gist.github.com/2841832
Why compression helps
Compressed data is smaller on disk
If we compress data more fits in RAM and is cached
Rotational disks:Rotational disks have very slow seeks
RAM not used by process with cache disk
Solid State Disks do seek faster then rotationalBut they are
more expensive then rotational
Enabling Compression
Rolling update to Cassandra
update column family my_stuff with
compression_options={sstable_compression:SnappyCompressor,
chunk_length_kb:64};
bin/nodetool -h cdbla120 -p 8585 rebuildsstables my_stuff
68 GB of data shrinks to 36
Compression in action
Disk activity reduced drastically as more/all data fit in
cache
Better performance
Disks that spin less should last longer
Compression lessons
Creates extra CPU usage (but not really much)
Creates more young gen garbage (some)
Anecdotal experimentation with chunk_length_kb64KB is good for
sparse less frequent tables
16KB had same compression ratio and made less garbage
Found 4KB to be less effective then 16KB
This is easy to experiment with
We have reached the point of the presentation where we...
Hate on everything not Cassandra
Cassandra's uptime story
Main cluster in continuous operation since 8/6/11
Doubled physical nodes in the cluster
Upgraded Cassandra twice 0.7.7->0.8.6->1.0.7
Rolling reboot kernel update, 1 for leap second
No maintenance windows
Let's compare Cassandra with other things I use/used
Cassandra vs MySQL master/slave...
MySQLCassandra
ReplicationSingle thread, binlogs, manual recoveryPer
operation
ScalingAdd more nodes, initial sync, setup replication,
configure applicationsBootstrap new Cassandra node, re-balance
off-peak
ConsistencyApplications that care read master, or application
check status of replicationPer operation
BackupMysqldump/LVM snapshotSstabletojson | snapshot
RestoreRe-insert everything/Restore snapshotCopy files into
place
So with mysql...
Replication breaking often requiring manual intervention for
many fixes
Blocking writes for 30 minutes to add a column to a table
Scale up to big iron then...Restart takes 30 minutes to fsck all
disks
Applications needing to be coded with state aware logicWhich
node should I query?
Is replication behind?
Is there some merge table trickery going on?
Cassandra vs Memcache
MemcacheCassandra
ReplicationNone (client managed)Per operation
ScalingNone (client managed)Grow or shrink without bad reads
ConsistencyYes (and really no)Per operation
BackupNo persistencesstabletojson|snapshot
RestoreNo persistenceCache warming
So memcache is...
Not persistent
Not clear on sharding
Not clear on failure modes
Actual experiences with memcacheMemcache client was not sharding
requests evenly. 60 % were going to node 1..
We lost rack with 40% of the memcache nodesSite went to crawl as
DB's were overloaded
took 1 hour to warm up again
Cassandra vs DRBD
DRBDCassandra
Replication1 or 2 nodes per blockPer operation
ScalingNo scaling. Just more availability.Grow or shrink
dynamically
ConsistencySync modes change failure consistency, deadtime
between flip-flopsPer operation
BackupLike a disksstabletojson|snapshot
RestoreLike a diskLike a disk
So DRBD is...
A 30 second to 1 minute fail over/outage
An alert that might wake you upbut hopefully allows you to sleep
again
Handcuffed to linux-ha/keepalived etcMaking it an involved
setup
Making it involved to troubleshoot
Might need a crossover cable or dedicated network
cpu/network intensive with very active disks
Can successfully fail over a data file in an inconsistent
state
Cassandra vs HDFS
HadoopCassandra
ReplicationPer filePer operation
ScalingAdd nodesAdd nodes
ConsistencyVery, to the point getting data in becomes
difficultPer operation
BackupDistcpsstabletojson|snapshot
RestoreDistcpLike a disk
So HDFS...
Comes up with about 4 or 5 reasons a year for master node/ full
cluster restartGrow NameNode heap
Enable jobtracker setting to stop 100,000 task jobs
Enabled/updated trash feature (off by default)
Forced to do a fail over by hardware fault
Random DRBD/Kernel brain fart
Need to update a JVM/kernel eventually
Now finally new versions have HA NameNode
Running jobs lose progress will not automatically restart
Questions?
2012 Media6Degrees. All Rights Reserved. Proprietary and
Confidential
Click to edit the title text formatClick to edit Master title
style
2012 Media6Degrees. All Rights Reserved. Proprietary and
ConfidentialClick to edit the title text formatClick to edit Master
title style
Click to edit the outline text formatSecond Outline LevelThird
Outline LevelFourth Outline LevelFifth Outline LevelSixth Outline
LevelSeventh Outline LevelEighth Outline Level
Ninth Outline LevelClick to edit Master text stylesSecond
levelThird levelFourth level