Embed Size (px)
Citation preview

Lightweight NLP
for Social Media Applications
Bruce Smith
Lithium Technologies, Inc.
SXSW 2012
March 13, 2012
@btsmith
#nlp #sxsw

What Can You
Learn in this
Session?
Lightweight NLP
for Social Media Applications
Are You
in the
Right Session?
2

@btsmith #nlp
▪ This session is not about
Natural Law Party
Neuro-linguistic Programming
No Light Perception (total blindness)
Nonlinear Programming
NLP = Natural Language Processing
3

@btsmith #nlp
▪ I will talk about “n-grams” several times
▪ Wikipedia has pages for 3 different kinds of “engram” • Neuropsychology
• Scientology
• 2009 album by Finnish black metal band Beherit
▪ Wikipedia has pages for 3 different kinds of “enneagram” • Nine-sided star polygon
• Enneagram of Personality
• Fourth Way Enneagram
N-Grams ≠ Engrams, Enneagrams, etc
4

@btsmith #nlp
▪ developing a social media application?
▪ looking for ways to make your application better?
▪ interested in a quick introduction to NLP or text analytics?
Are you…
5

@btsmith #nlp
▪ how you can use NLP tools in your social media app?
▪ if you need a Ph.D. to use NLP tools?
▪ where to find free NLP tools?
▪ where to learn more?
Do you want to know…
6

@btsmith #nlp
▪ the role of machine learning in NLP?
▪ the difference between training and production?
▪ what a training corpus is and where to find one?
Do you want to understand…
7

@btsmith #nlp
▪ Computers are powerful and cheap!
▪ There‟s a lot of very good, free software!
▪ There‟s an enormous amount of very good, free text data!
▪ Don’t be afraid of non-English content! • Unicode is your friend
• just remember „utf-8‟
This is a Great Time to Start Using NLP!
8

Lightweight NLP
for Social Media Applications
Very Simple NLP
with
Very Little Math
9

@btsmith #nlp
▪ document • newspaper article, novel, patent, scientific paper
• blog post, comment, status update, tweet
▪ corpus • collection of documents
• plural is “corpora”
▪ treebank • annotated corpus
• words are annotated with parts of speech
• sentences are annotated with parse trees
Document, Corpus, Treebank
10

@btsmith #nlp
Penn Treebank‟s Parts of Speech
11
CC Coordinating conjunction
CD Cardinal number
DT Determiner
IN Preposition or
subordinating conjunction
… …
JJ Adjective
JJR Adjective, comparative
JJS Adjective, superlative
… …
NN Noun, singular or mass
NNS Noun, plural
NNP Proper noun, singular
… …
POS Possessive ending
PRP Personal pronoun
PRP$ Possessive pronoun
… …
VB Verb, base form
VBD Verb, past tense
VBG Verb, gerund
or present participle
… …
WP Wh-pronoun
WP$ Possessive wh-pronoun
… …

@btsmith #nlp
Phrase Structure Grammars & Parse Trees
12
S Sentence
NP Noun Phrase
VP Verb Phrase
PP Prepositional Phrase
… …
Phrases (non-terminals)
S → NP VP
…
NP → NN
NP → JJ NN
…
VP → V NP
….
Grammar
NNP Proper noun, singular
NNS Noun, plural
VBZ Verb, 3rd person
singular present
… …
POS (terminals)
S
NP
VP
NNP
Bruce
VBZ
likes
NNS
dogs
NP
Parse Tree

@btsmith #nlp
▪ contiguous subsequence of n items • in order and with no gaps
• words
• characters
▪ n-grams have special names when n is small • unigram n=1
• bigram n=2
• trigram n=3
N-Grams
13

@btsmith #nlp
Lightweight NLP for Social Media Applications
▪ Unigrams for this session‟s title
Character N-Grams
14
l
i
g
h
t
w
e
i
g
h
t
n
l
p
f
o
r
s
o
c
i
a
l
m
e
d
i
a
a
p
p
l
i
c
a
t
i
o
n
s

@btsmith #nlp
Lightweight NLP for Social Media Applications
▪ Bigrams for this session‟s title
Character N-Grams
15
li
ig
gh
ht
tw
we
ei
ig
gh
ht
tn
nl
lp
pf
fo
or
rs
so
oc
ci
ia
al
lm
me
ed
di
ia
aa
ap
pp
pl
li
ic
ca
at
ti
io
on
ns

@btsmith #nlp
Lightweight NLP for Social Media Applications
▪ Trigrams for this session‟s title
Character N-Grams
16
lig
igh
ght
htw
twe
wei
eig
igh
ght
htn
tnl
nlp
lpf
pfo
for
ors
rso
soc
oci
cia
ial
alm
lme
med
edi
dia
iaa
aap
app
ppl
pli
lic
ica
cat
ati
tio
ion
ons

@btsmith #nlp
▪ N-grams are interesting when we look at frequencies
Character N-Gram Frequencies
17
i – 6
a – 4
l – 4
o – 3
p – 3
…
gh – 2
ht – 2
ia – 2
ig – 2
li – 2
…
ght – 2
igh – 2
aap – 1
alm – 1
aap – 1
…
Lightweight NLP for Social Media Applications

@btsmith #nlp
▪ Word n-grams from Pride and Prejudice (using NLTK)
Word N-Gram Frequencies
18
to – 4116
the – 4105
of – 3572
and – 3491
her – 2551
a – 2092
…
to be – 436
of the – 430
in the – 359
it was – 280
of her – 276
to the – 242
…
i am sure – 72
as soon as – 59
in the world – 57
i do not – 46
could not be – 42
she could not – 39
…

@btsmith #nlp
▪ Word n-grams from Pride and Prejudice
with no stopword unigrams
N-Gram Frequencies
19
elinor – 685
could – 578
marianne – 566
mrs – 530
would – 515
said – 397
…
to be – 436
of the – 430
in the – 359
it was – 280
of her – 276
to the – 242
…
i am sure – 72
as soon as – 59
in the world – 57
i do not – 46
could not be – 42
she could not – 39
…
@btsmith #nlp
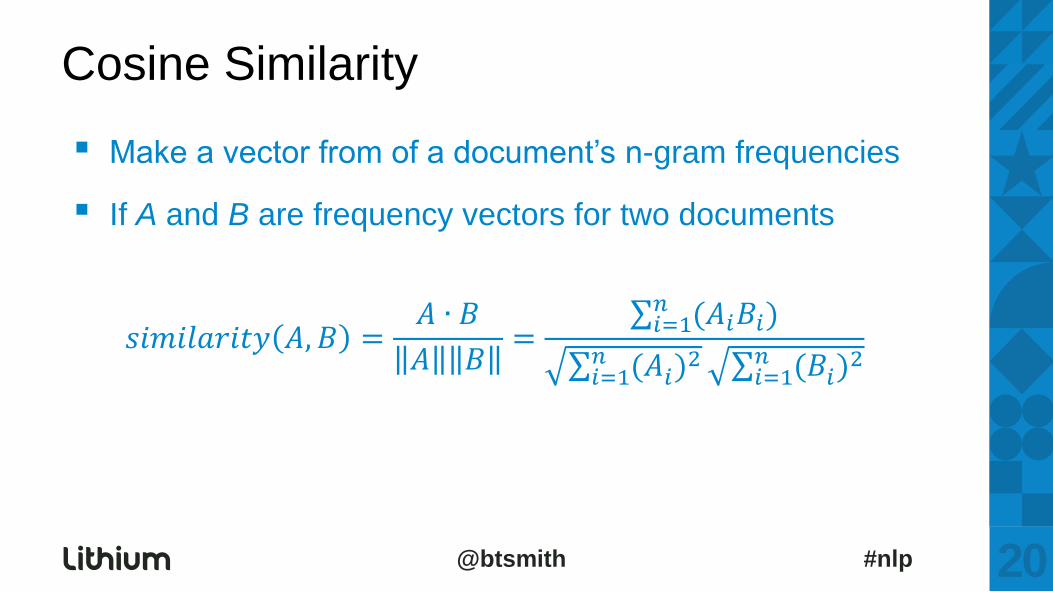
▪ Make a vector from of a document‟s n-gram frequencies
▪ If A and B are frequency vectors for two documents
𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦 𝐴, 𝐵 =𝐴 ∙ 𝐵
𝐴 𝐵=
(𝐴𝑖𝐵𝑖𝑛𝑖=1 )
(𝐴𝑖)2𝑛
𝑖=1 (𝐵𝑖)2𝑛
𝑖=1
Cosine Similarity
20

@btsmith #nlp
▪ Create word N-gram frequency vectors • with unigrams, bigrams, trigrams
• Moby Dick
• Pride and Prejudice
▪ Compute their cosine similarity
0.534
▪ More interesting with a larger set of documents…
Cosine Similarity
21

@btsmith #nlp
▪ In the past, NLP was more about
grammars and logic and parsing
▪ Today, NLP is more about
statistics and machine learning
▪ Why? • computers are much more powerful
• there are enormous amounts of very good, free data
NLP and Machine Learning
22

@btsmith #nlp
▪ Think of machine learning as
programming by analyzing sample data
▪ Example • Use the Penn Treebank as sample data
• Build a program that labels words with parts-of-speech
NLP and Machine Learning
23

@btsmith #nlp
▪ Training • depends on sample data, your training corpus
• there are very good, free machine learning tools
• sometimes training is slow
• experiment with different techniques (perceptron, SVM, etc)
• test, test, test…
▪ Production • uses models generated during training
• typically very fast
NLP and Machine Learning
24

Lightweight NLP
for Social Media Applications
Lightweight NLP
Techniques
25

@btsmith #nlp
▪ Language Identification
▪ Sentence Breaking
▪ Stemming
▪ Part-of-Speech Tagging
Lightweight NLP Techniques
26

@btsmith #nlp
You might try looking at
▪ character sets (e.g. Unicode character blocks)
▪ words in language-specific dictionaries
▪ character n-gram frequencies and cosine similarity
Language Identification
27

@btsmith #nlp
▪ Character n-gram frequencies for English
Language Identification
28
e 12.6%
t 9.1%
a 8.0%
o 7.6%
i 6.9%
n 6.9%
s 6.3%
h 6.2%
…
th 3.9%
he 3.7%
in 2.3%
er 2.2%
an 2.1%
re 1.7%
nd 1.6%
on 1.4%
…
the 3.5%
and 1.6%
ing 1.1%
her 0.8%
hat 0.7%
his 0.6%
tha 0.6%
ere 0.6%
…
From Cryptograms.org, derived from English documents at Project Gutenberg

@btsmith #nlp
▪ tika.apache.org
▪ models for
▪ trainable with sample data
da Danish
de German
et Estonian
el Greek
en English
es Spanish
fi Finnish
fr French
is Icelandic
it Italian
nl Dutch
no Norwegian
pl Polish
pt Portuguese
ro Romanian
ru Russian
sv Swedish
th Thai
uk Ukrainian
…
Language Identification with Tika
29

@btsmith #nlp
Where can you find samples of…
30
▪ French?
▪ German?
▪ Russian?
▪ Japanese?
▪ Arabic?
▪ Cherokee?

@btsmith #nlp
▪ Also known as • sentence boundary disambiguation
• sentence detection
▪ You could just look for punctuation, but… • what about abbreviations?
• what about numbers?
• what about domain names like lithium.com, etc?
• what about names like Yahoo!, etc?
Sentence Breaking
31

@btsmith #nlp
▪ opennlp.apache.org
▪ models for
da Danish nl Dutch
de German pt Portuguese
en English se Swedish
▪ trainable with new sample data
Sentence Breaking with OpenNLP
32

@btsmith #nlp
▪ Reducing a word to a stem or base form
▪ Porter Stemmer is a popular stemmer for English
▪ Examples
lightweight → lightweight
natural → natur
language → languag
processing → process
Stemming
33

@btsmith #nlp
▪ A few examples from Pride and Prejudice (using NLTK)
Stemming
34
affect affect affectation affected affecting affection affections affects
amus amuse amused amusement amusements amusing
close close closed closely closing grate grate grateful gratefully

@btsmith #nlp
▪ tartarus.org
▪ stemmers for
de German nl Dutch
en English no Norwegian
es Spanish pt Portuguese
fi Finnish ru Russian
fr French se Swedish
it Italian …
Stemming with Snowball
35

@btsmith #nlp
▪ Part of Speech frequently abbreviated POS
▪ Not every language has the same parts of speech
▪ Even for one language,
not everyone agrees on the parts of speech
▪ Example: Penn Treebank POS tags for English
Part-of-Speech Tagging
36

@btsmith #nlp
lightweight nlp for social
media applications
lightweight NN
nlp NN
for IN
social JJ
media NNS
applications NNS
nlp is easier than you thought
nlp NN
is VBZ
easier JJR
than IN
you PRP
thought VBD
Part-of-Speech Tagging
37

@btsmith #nlp
▪ opennlp.apache.org
▪ two kinds of models for each of
de German pt Portuguese
en English se Swedish
nl Dutch
▪ trainable with new sample data
Part-of-Speech Tagging with OpenNLP
38

Lightweight NLP
for Social Media Applications
Lightweight NLP
in
Applications
39

@btsmith #nlp
▪ Language Identification
▪ Sentence Breaking for Summaries
▪ Stemming for Word Counts
▪ POS Tagging for Document Categorization
▪ Lithium SMM Quotes
Lightweight NLP in Applications
40

@btsmith #nlp
Lithium SMM (Social Media Monitoring)
41

@btsmith #nlp
▪ Language ID is never perfect,
especially with social media!
• short documents
• ambiguity
• mixed languages
• nonsense
• and… lots of very strange stuff
Language Identification
42

@btsmith #nlp
What language is this?
43
______________$$$$______________
____________$$$$$$$$____________
___________$$$$$$$$$$___________
___________$$$$$$$$$$___________
_____________$$$$$$_____________
_____________$$$$$$_____________
_____________$$$$$$_____________
____$$$$_____$$$$$$_____$$$$____
___$$$$$_____$$$$$$_____$$$$$___
_$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$_
_$$$$$$$$$$$.СРБИЈА.$$$$$$$$$$$_
___$$$$$$$$$$$$$$$$$$$$$$$$$$___
____$$$$_____$$$$$$_____$$$$____
_____________$$$$$$_____________
_____________$$$$$$_____________
_____________$$$$$$_____________
_____________$$$$$$_____________
_____________$$$$$$_____________
_____________$$$$$$_____________
_____________$$$$$$_____________
_____________$$$$$$_____________
___________$$$$$$$$$$___________
___________$$$$$$$$$$___________
____________$$$$$$$$____________
______________$$$$______________

@btsmith #nlp
What language is this?
44
ღೋ ´¯`•.¸,¤°`°¤,¸.•´¯`•.¸,¤Ƹ ̵̡Ӝ ̵̨̄Ʒ´¯`•.ღೋ ´¯`•. ╱▔▌ ╔═╗╔═╗╔═╗╔═╗╔═╗░╔═╗╔╗╔═╗╔═╗╔═╗╔╗╔╗─╔═╗─ ╱▔▔▔▔╲ ╱▌ ║█║║═╣║═╣║╠╝║═╣░║▌║╚╝║█║║█║║█║║║║║─║═╣ ╱◑▓░▓░░ ▌ ║╔╝║═╣╠═║║╠╗║═╣░║▌║──║╦║║╔╝║═╣║║║╚╗║═╣ ╲░░░░░╱╲▌ ╚╝─╚═╝╚═╝╚═╝╚═╝░╚═╝──╚╩╝╚╝─╚╩╝╚╝╚═╝╚═╝─ ▔▔╲▌▔
@btsmith #nlp
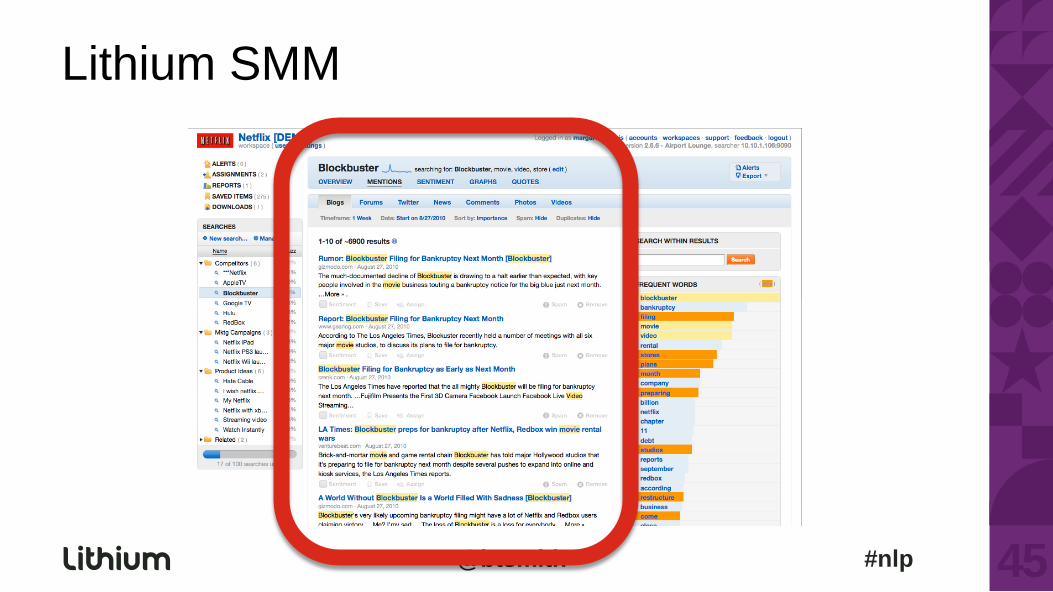
Lithium SMM
45

@btsmith #nlp
▪ Summary does not replace the document
▪ Summary lets you decide if the document is interesting
▪ Summaries are sentences selected from the document • contain the search terms
• not too short, not too long, etc
• truncated only if necessary
Sentence Breaking for Summaries
46
@btsmith #nlp
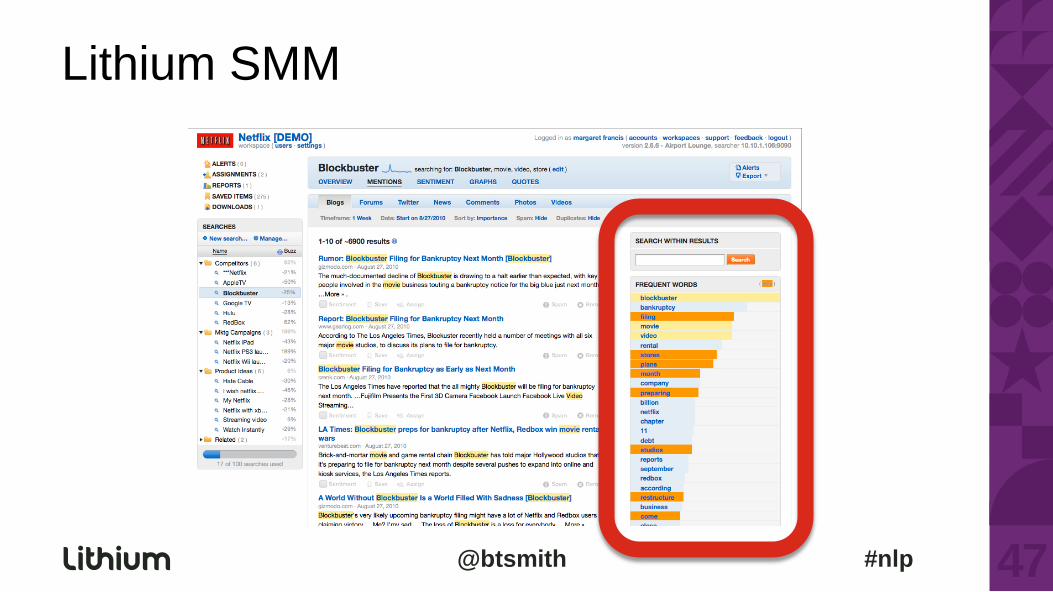
Lithium SMM
47

@btsmith #nlp
▪ Most common words in the results for your query • excludes stopwords
▪ Trending words were previously not common
▪ Click on a frequent word to search within results
▪ Should we count… • words?
• stems?
Frequent Words and Stemming
48

@btsmith #nlp
▪ We use POS Tagging in Lithium SMM Quotes • along with other things
• not such a “lightweight” application
▪ POS also useful for document categorization • POS-based features
• machine learning
POS Tagging
49

@btsmith #nlp
▪ Author Gender Automatic Categorization of Author Gender via N-Gram Analysis, Jonathan Doyle and Vlado Keselj. In The 6th Symposium on Natural Language Processing, SNLP'2005, Chiang Rai, Thailand, December 2005.
▪ Opinion Spam Finding Deceptive Opinion Spam by Any Stretch of the Imagination, Myle Ott, Yejin Choi, Claire Cardie and Jeffrey T. Hancock, The 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, Oregon, USA, June 19-24, 2011.
POS Tags and Document Categorization
50

@btsmith #nlp
▪ Quotes • Select interesting sentences from social media documents
• Classify them as love, hate, comparison, warning, etc.
▪ Quotes depends on • language identification
• sentence breaking
• POS tagging
• parsing
• specialized dictionaries
Lithium SMM Quotes
51

@btsmith #nlp
Lithium SMM Quotes
52

Lightweight NLP
for Social Media Applications
Resources
53

@btsmith #nlp
▪ Corpus linguistics
▪ Cosine similarity
▪ Function word
▪ Language identification
▪ Machine learning
▪ N-gram
▪ Natural language processing
▪ Part-of-speech tagging
▪ Sentence boundary disambiguation
▪ Stemming
▪ Stop words
▪ Text mining
▪ Treebank
Wikipedia
54

@btsmith #nlp
▪ NLTK • Natural Language Toolkit
• Python library for NLP
• nltk.org
▪ OpenNLP • machine-learning based NLP tools
• Java library for NLP
• opennlp.apache.org
▪ Snowball • ANSI C and Java stemmers
• snowball.tartarus.org
▪ Tika • Java toolkit for extracting metadata
and text from documents
• includes language identification
• tika.apache.org
Software
55

@btsmith #nlp
▪ Natural Language Processing with Python
Steven Bird, Ewan Klein & Edward Loper
O‟Reilly, 2009
▪ Foundations of Statistical Natural Language Processing
Chris Manning & Hinrich Schütze
MIT Press, 1999
Books
56

@btsmith #nlp
▪ Association for Computational Linguistics
http://www.aclweb.org
▪ Remember that‟s aclweb.org
acl.org is the Association of Christian Librarians
Organization
57

@btsmith #nlp
▪ Bruce Smith
@btsmith
▪ People at SXSW wearing Lithium‟s Nation Builder T-shirts
Contact Info
58





























