Embed Size (px)
Citation preview

TAIPEI|SEP.21-22,2016
Min Sun, Sept. 21, 2016
LEARNING FROM DASHCAM VIDEOS

2
AGENDA
• AnticipateAccident- Chanetal.ACCV’16oral
• ExtractingDrivingBehavior- Changetal.ECCV’16workshop

3
Using Dashcam Videos to Anticipate Accidents
詹富翔Fu-Hsiang Chan
NTHU EE
向 宇Yu Xiang
Stanford CS
陳玉亭Yu-Ting Chen
NTHU EE
孫 民Min Sun
NTHU EE
VSLab

4
MOTIVATIONVSLab
Google’s self-driving car is involved in 12 minor accidents mostly caused by other human drivers.
Using dashcam videos to anticipate corner cases (e.g., accient).
Google self-driving car project monthly report (2015)

5
DASHCAM ACCIDENT DATASET

6
POPULATION AND MOTOR VEHICLES DENSITY
Taiwan USA Japan Korea German UK
Area(km2) 36.2 9,831.5 377.9 99.9 357.1 243.6
PopulationDensity(No./km2) 641 32 337 490 229 255
MotorbikeDensity(No./km2) 614 26 232 165 155 140
VehiclesDensity(No./km2) 195 25 199 147 144 135
資料來源:中華民國環境保護統計年報101年表8-1
VSLab

7
MORE COMPLEX ENVIRONMENTJapan Taiwan
VS
VSLab
Japan Taiwan
8
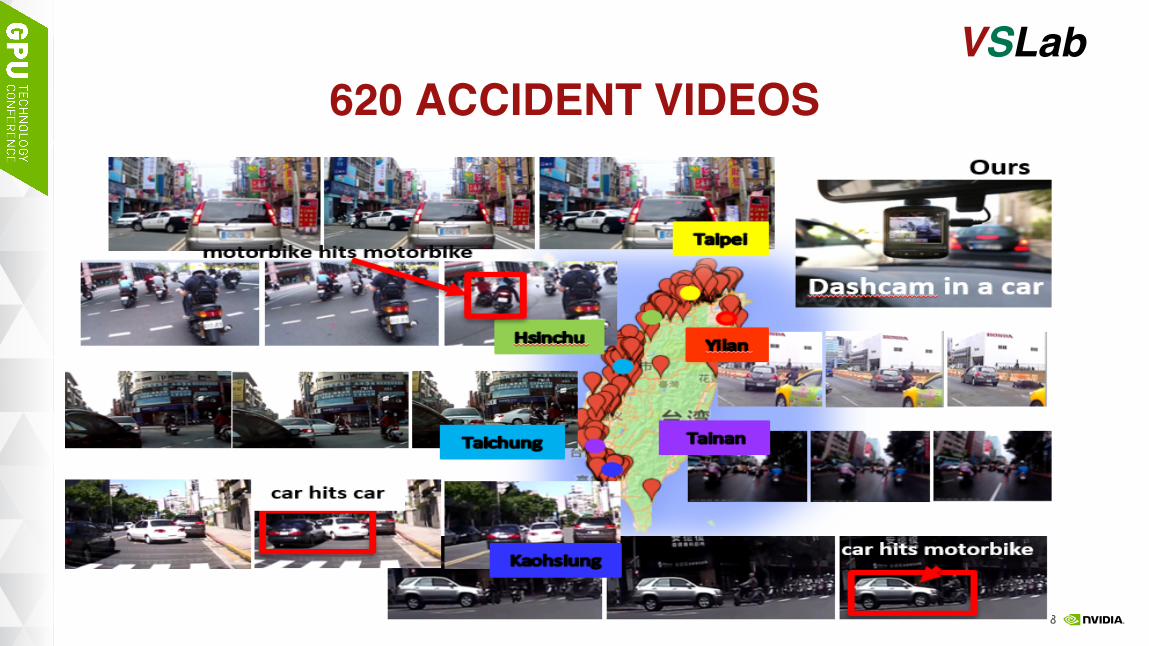
620 ACCIDENT VIDEOSVSLab

9
ACCIDENT TYPES OF 620 VIDEOSVSLab
BikehitsCar
42.6%CarhitsCar
19.7%
BikehitsBike15.6%
Others22%

10
Our MethodVSLabPerson
Bike Motorbike
Car

11
AppearanceVSLab

12
Faster-RCNN (Detection)
S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015
VSLab
Car
CarPerson
Person Person
MotorbikeMotorbike
Motorbike
Car

13
MotionVSLab

14
VSLab
Heng Wang and Cordelia Schmid, “Action recognition with improved trajectories,” in ICCV, 2013
Improved Dense Trajectory (IDT)

15
ANTICIPATING ACCIDENTS MODELVSLab

16
ANTICIPATING ACCIDENTS MODELVSLab
• Recurrent neural network

17
• Spatial attention modelzx
ANTICIPATING ACCIDENTS MODELVSLab
Time = t
RN
NR
NN
RN
NTime = t+1
Time = t+2
Weighted sum
Weighted sum
Weighted sum
Attention
Attention

18
ANTICIPATING ACCIDENTS MODELVSLab
• Exponential loss
Time
Ashesh Jain, Hema S. Koppula, Bharad Raghavan, Shane Soh, and Ashutosh Saxena, “Car that knows before you do: Anticipating maneuvers via learning temporal driving models,” in ICCV, 2015.

19
ANTICIPATING ACCIDENTS MODELVSLab
• Recurrent Neural Network
• Spatial Attention Model
• Exponential Loss

20
EXPERIENCESVSLab
Positiveexamples
Negativeexamples
Total
Trainingset 455 829 1284Testingset 165 301 466Total 620 1130 1750
• Positive : Negative ≒ 2:3• Training : Testing ≒ 3:1
Negative example Positive example

21
mAP
[1][2]
Finetune Faster-RCNNVSLab
• Training set: KITTI dataset + 58 additional videos
• Testing set: 165 positive examples of testing set
29%
35%27%
15%
35%
28%
[1] M. Everingham et al.“The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results,” 2007.[2] T.-Y. Lin et al. “Microsoft COCO: Com- ´ mon Objects in Context,” in ECCV, 2014.
Generalphotos StreetView photos

22
ANTICIPATING ACCIDENTS RESULTSVSLab
Appearance
Motion
Recurrent Neural Network
Single-frame Classifier (SFC)
Frame baseAverage attentionConcatenate the framewith the average attentionWeighted-summing frame with attention on objectConcatenating frame with attention on object
FrameT
SFC
VGG or IDT
Output
FrameT+1
SFC
VGG or IDT
Output
RNN RNN
attention
Only Attention on object

23
ANTICIPATING ACCIDENTS RESULTSVSLab
Achieve the best 74.35% mAP
Appearance
Motion

24
ANTICIPATING ACCIDENTS RESULTOur method anticipates accidents about 2 seconds before they occurwith 80% recall and 56.14% precision.
VSLab
56.14% ≒2

25
VSLabTypical Examples

26
Boxattentionhigh
low
Focusontheboxweight>0.4
frame
Prob
ability
Threshold
Accident!
Warning
VSLabTypical Examples

27
Boxattentionhigh
low
Focusontheboxweight>0.4
frame
Prob
ability
Threshold
Accident!
Warning
VSLabTypical Examples

28
Boxattentionhigh
low
Focusontheboxweight>0.4
frame
Prob
ability
Threshold
Accident!
Warning
VSLabTypical Examples

29
RELATED WORKVSLab
B. Frohlich, M. Enzweiler, and U. Franke, “Will this car change the lane? - turn signal recognition in the frequency domain,” in Intelligent Vehicles Symposium (IV), 2014.
A. Doshi, B. Morris, and M. Trivedi, “On-road prediction of driver’s intent with multimodal sensory cues,” IEEE Pervasive Computing, vol. 10, no. 3, pp. 22–34, 2011.

30
RELATED WORKVSLab
Ashesh Jain, Avi Singh, Hema S Koppula, Shane Soh, and Ashutosh Saxena, “Recurrent neural networks for driver activity anticipation via sensory-fusion architecture,” in ICRA, 2016.
Ashesh Jain, Hema S. Koppula, Bharad Raghavan, Shane Soh, and Ashutosh Saxena, “Car that knows before you do: Anticipating maneuvers via learning temporal driving models,” in ICCV, 2015.

31
AGENDA
• AnticipateAccident- Chanetal.ACCV’16oral
• ExtractingDrivingBehavior- Changetal.ECCV’16workshop

32
Extracting Driving Behavior: Global Metric Localization
from Dashcam Videos in the Wild
孫 民Min Sun
NTHU EE
陳煥宗Hwann-Tzong Chen
NTHU CS
張劭平
NTHU EE
簡瑞霆
NTHU CS
王福恩
NTHU EE
楊尚達
NTHU EE

33

34
SfM
GlobalMetricReconstruction
Image-levelMatching
Patch-levelMatching
3DAlignment
Top 3 similar images
The most similar images
Dashframe
Streetview Output

35
DEMO

36
AGENDA
• AnticipateAccident- Chanetal.ACCV’16oral
• ExtractingDrivingBehavior- Changetal.ECCV’16workshop
http://aliensunmin.github.io/VSLab

TAIPEI|SEP.21-22,2016
THANK YOU





























