Embed Size (px)
Citation preview

Architecting for a Scalable Enterprise

© 2015 C24 Technologies
2
PROBLEMS DON’T CHANGE, THEY JUST GET BIGGER
I’ve been working for 30 years now and I just see the same problems over and over again - History repeating itself
It’s true we have some new ones but they’re just reincarnations of the old ones
You could argue that IoT, social media & eCommerce are all new (since I started anyway) but the problems are the same…
Massive volumes of dataIt needs parsing, filtering, sorting, analysing, alerts, triggers, reporting, compliance… Same ol’ same ol’

© 2015 C24 Technologies
3
30-ISH YEARS AGO
I can remember in 1987 we re-wrote a trading system in Objective-CIn those days there was a “war” between Objective-C and C++History tells us C++ won but it wasn’t a clear victory as Apple shows us today
Anyway, one of the problems we had was loading in all of the exchange rates as the system started upWe used 80386s (the latest 32 bit CPU)The big machines had 1MB (yes 1 mega bytes) of RAMWAN was a 2400 baud modem (2.4k bits ber second)Network was 1MB token-ring (40k/sec on a good day)20MB hard-disk on the top machines (80ms access time)
© 2015 C24 Technologies
4
SOUND FAMILIAR?
Hundreds of currency pairs (USD/GBP) - remember pre-Euro so more currenciesA dozen forward rates (spot, 1 week, 1 month etc.)Several changes per second (coming down the modem @ 2400 baud)
These are some of the problems we faced…
When the machines started up in the morning ittook along time to get the current snap-shot to the trader’s machinesEach new rate (GBP/USD=1.68750) took a long time to update on the clients machines, something do to the new Object Oriented model we’d usedQuerying the data was slowStoring and querying the historic data presented serious issues

© 2015 C24 Technologies
5
HARDWARE TO THE RESCUE!
You could do in a few seconds on an iPhone what took a day to do in those days but that’s thanks to the hardware changes
NOT THE SOFTWARE
The problems and architecture remain the same, we just have a lot more data because we’re now globalWe want every trade quoted on every exchange in every country on every trader’s desk in every office in every countryCompetition has just meant that as soon as one bank does it, you have to do better otherwise you lose the deals and go bankrupt

© 2015 C24 Technologies
6
IT’S NOT JUST THE CPU
Networks speeds20 years ago we used wired modems 38k (bits) wasgood, we now expect mobile networks to give us 50+MB,that’s >1000X
ScreensMy laptop (2 years old) is 2880x1800 and “full colour”, 20 years ago 1024x768 in 16 colours was good but the real change is 3D & OpenGL etc.Low res 3D pie charts needed a maths co-processor to display them in under a second today we expect realistic 3D in real-time on full resolutionToday’s graphics cards are computers within computers
MemoryWe used to have to page 1MB of RAM in and out (memory banks), today we have 16GB or RAM in a laptop and 128GB of SSD on a keyring

© 2015 C24 Technologies
7
RAW POWER
Apollo 11’s guidance computer had just 2kof memory and 32k of read-only storageBut it got it to the moon - and back!Most of the time :-)The backup was a slide rule
Today you can compress a full 1080pmovie into about 1GB and watch it on yourmobile phone
Why then do we have problems getting XML into memory?
© 2015 C24 Technologies
8
50 YEARS ON AND MOORE’S LAW IS STILL WITH US
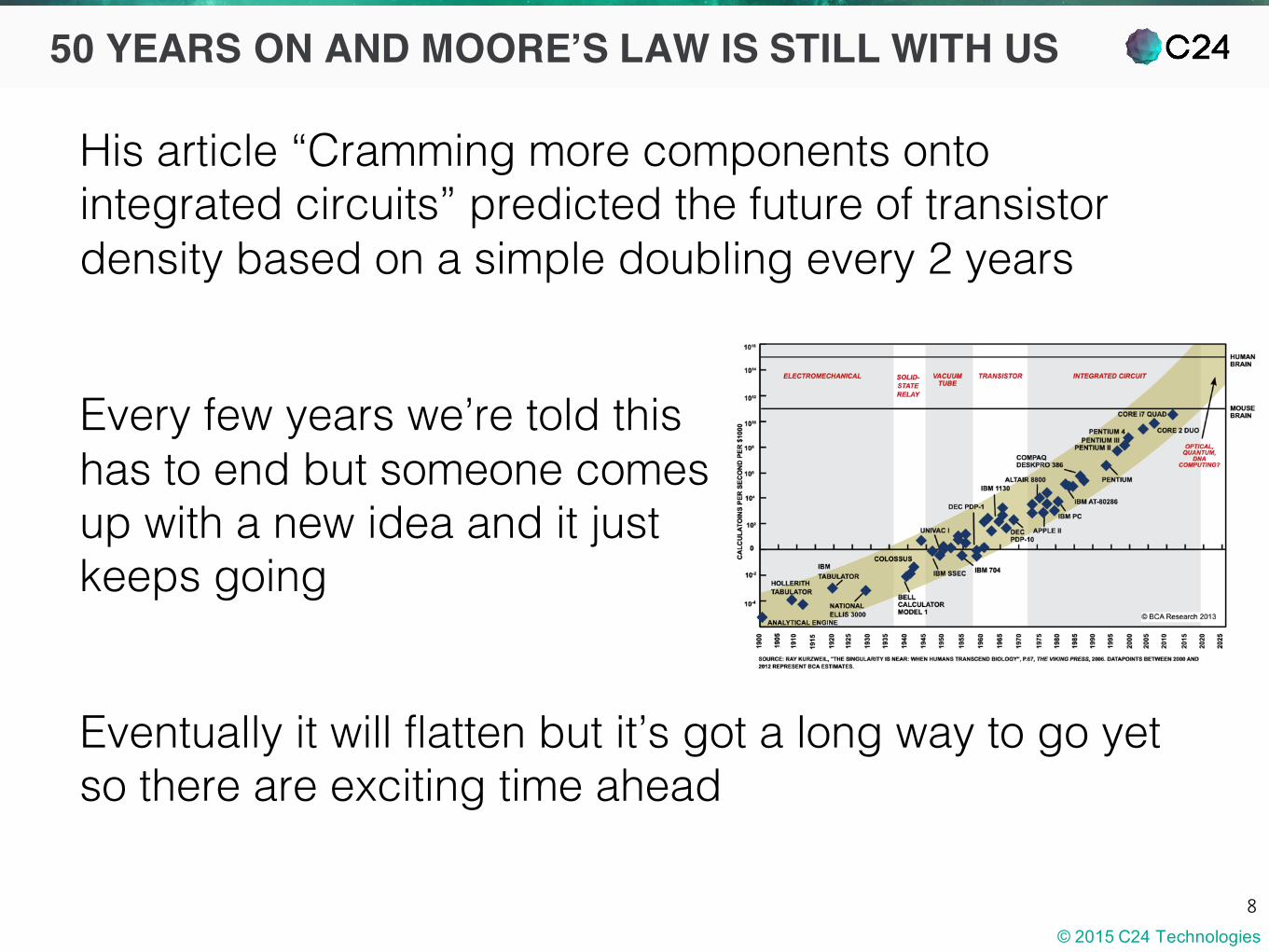
His article “Cramming more components onto integrated circuits” predicted the future of transistor density based on a simple doubling every 2 years
Every few years we’re told thishas to end but someone comesup with a new idea and it justkeeps going
Eventually it will flatten but it’s got a long way to go yet so there are exciting time ahead

© 2015 C24 Technologies
9
SOFTWARE IS SLOWING US DOWN
Programmers are lazy, I’m one, I gave all my demos to someoneelse to write while I write these slides (thanks Iain)We’ve added layer upon layer of abstraction to hide thecomplexity and hardware - Good but it slows things down
We simplified programming with drag-n-dropnow even kindergarten kids can program
Twenty years ago Java was introduced to theworld, it took away all the problems we hadwith memory management and hardware architecturesIt was cool then and I think it’s still cool now but it doeshave a lot of issues, many of which we can work around

© 2015 C24 Technologies
10
MY SLIDE FROM 2012
Today my optimisation target is Java itself

© 2015 C24 Technologies
11
JAVA IS VERBOSE AND SLOW
OK, don’t get offended, Java is a great language and small applications are often as fast as C/C++, the JIT compiler is seriously powerful
BUT
For data high volume processing, distributed computing and analytics Java performance sucks
BUT
It is still the best we have so we just need to improve the way it works

© 2015 C24 Technologies
12
GARBAGE COLLECTION
Programmers make mistakes, in the days of C/C++ it crashed or hung the machine today it just kills the hangs or crashes the JVM
Memory management was supposed to help but you can bring your entire machine to a grinding halt with ease…Concatenating Strings in a loopAdding to a collection and forgetting to clear itProcessing too much data
The JVM and Garbage Collection doesn’t fix your bad programming it just limits the damage is can causeThis comes at a cost too

© 2015 C24 Technologies
13
SERIALISATION
Java Serialisation sucks - full stop!
It’s so bad there are over 2 dozen open source frameworks to replace it
Almost all of the In-Memory Data Grids (IMDGs) have alternatives to native serialisation
A serialised Java object is usually larger in size than its XML equivalent
Even the process of serialisation and de-serialisation is slow, extremely slowWe’ll come back to this later

© 2015 C24 Technologies
14
ANALYTICS & BIG DATA
There are essentially 4 optionsDo it in memory on one machine - fast but limited sizeDo it off disk on one machine - slow due to disk I/O and limited CPUUse distributed memory - faster but not linearly faster than one machineUse distributed disk - fast due to more CPU but limited by disk I/O
If we could somehow improve GC, network serialisation and disk I/O we could vastly improve on the latency (time for results) and throughput (complexity of results)
Heard of Hadoop and Spark?

© 2015 C24 Technologies
15
HADOOP
To run a Hadoop query…First understand the data you’re analysing so that you can extract itWrite some code to extract, transform and load the data into HBase/HDFSThis can take days or weeks to codeAnd can take hours or days to run
Now fire up Hadoop to get your answer - more time because it’s on disk and distributed - It’s SLOW
Make one small change and you’re back to square oneQuery to result can take weeks

© 2015 C24 Technologies
16
SPARK
Spark is faster because it runs in memory but it still has the overhead of Java Serialisation for distribution
There are two modes, cached and un-cachedAs the name would suggest un-cached is off disk so we’re back to serialisation costs again
Spark can use Kryo to improve serialisation, this is good but means writing code and it’s not practical for complex data models
Spark is an improvement on Hadoop but still limited by Java

© 2015 C24 Technologies
17
LET’S PARK BIG DATA FOR NOW…
We’ll come back to Spark later…

© 2015 C24 Technologies
18
IN THE MORE RECENT PAST…
At JAX Finance earlier this year I introduced the idea of using binary instead of classic Java objects
This is really bringing the skills we used 20 years ago in C and C++ back into the Java world
As long as your getter() returns the Object you expected why should you care if it was stored in binary or as a Java object?This is after all the beauty of abstraction
Let’s just see what this does again…

© 2015 C24 Technologies
19
SAME API, JUST BINARY
Classic getter and setter vs. binary implementationIdentical API
© 2015 C24 Technologies
20
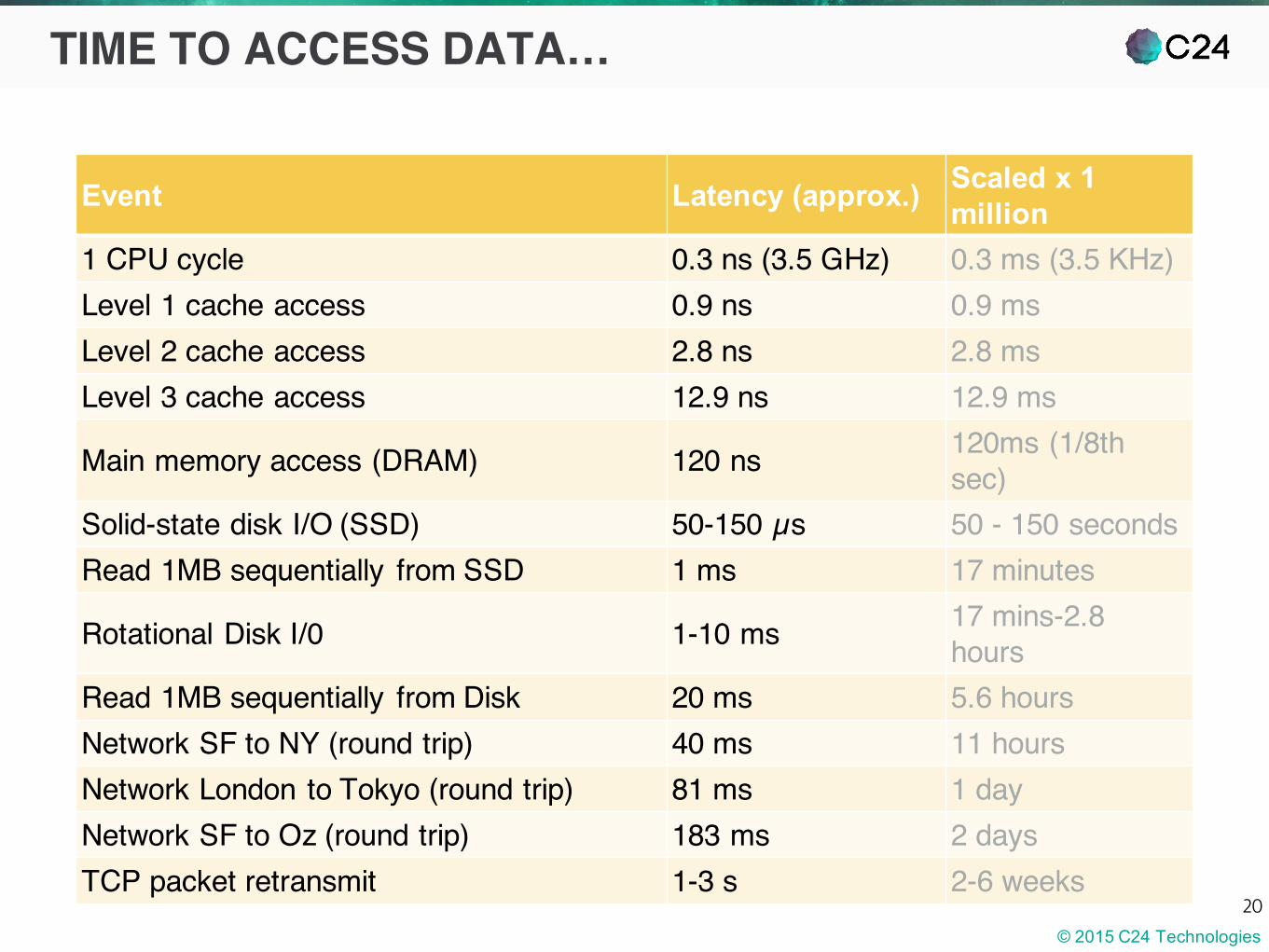
TIME TO ACCESS DATA…
I scaled by 1 million times simply because that’s roughly the ratio between an modern airplane and the speed of light
Event Latency (approx.) Scaled x 1 million
1 CPU cycle 0.3 ns (3.5 GHz) 0.3 ms (3.5 KHz)Level 1 cache access 0.9 ns 0.9 msLevel 2 cache access 2.8 ns 2.8 msLevel 3 cache access 12.9 ns 12.9 ms
Main memory access (DRAM) 120 ns 120ms (1/8th sec)
Solid-state disk I/O (SSD) 50-150 µs 50 - 150 secondsRead 1MB sequentially from SSD 1 ms 17 minutes
Rotational Disk I/0 1-10 ms 17 mins-2.8 hours
Read 1MB sequentially from Disk 20 ms 5.6 hoursNetwork SF to NY (round trip) 40 ms 11 hoursNetwork London to Tokyo (round trip) 81 ms 1 dayNetwork SF to Oz (round trip) 183 ms 2 daysTCP packet retransmit 1-3 s 2-6 weeks
© 2015 C24 Technologies
21
COMPARING…
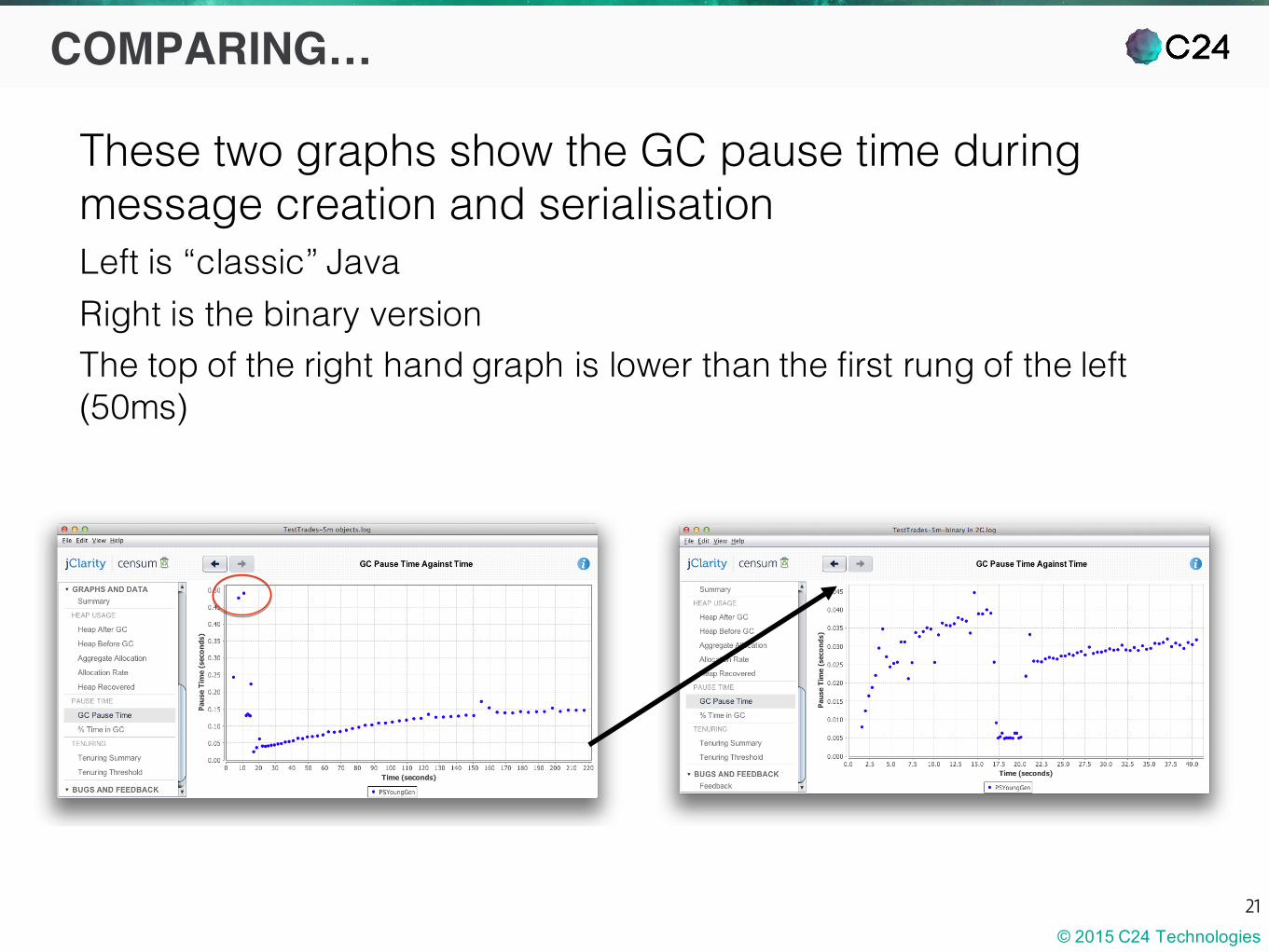
These two graphs show the GC pause time during message creation and serialisationLeft is “classic” JavaRight is the binary versionThe top of the right hand graph is lower than the first rung of the left (50ms)

© 2015 C24 Technologies
22
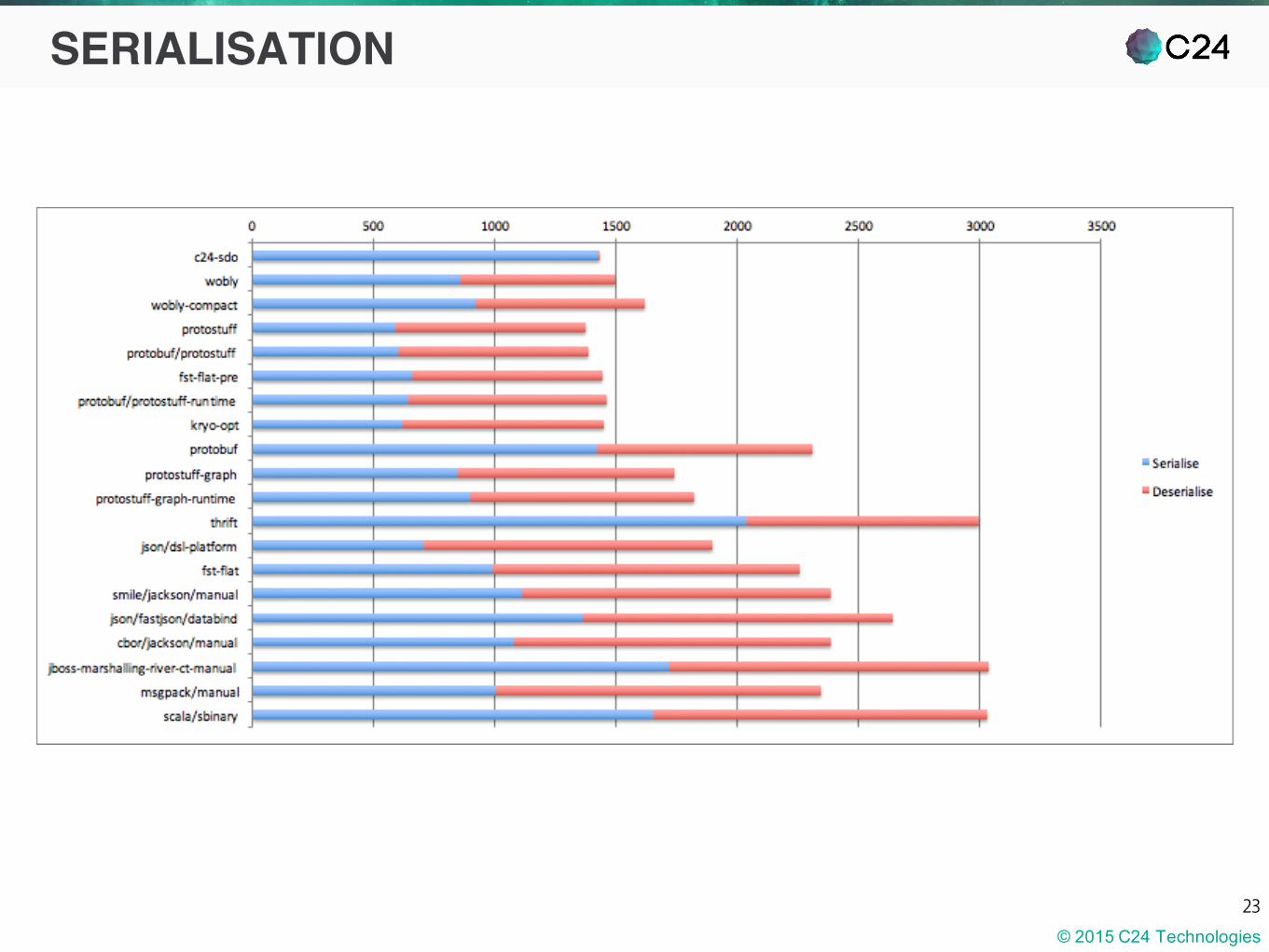
SERIALISATION
Serialisation was compared (by a client) to several dozen serialisation frameworks
The test framework can be found here:
https://github.com/eishay/jvm-serializers/
Preon was either at the top or within 5%of the top
However the use-case was verysimple, SDOs work better with morecomplex models
© 2015 C24 Technologies
23
SERIALISATION
Serialisation was compared (by a client) to several dozen serialisation frameworks
The test framework can be found here:
https://github.com/eishay/jvm-serializers/
C24 is either at the top or within 5%of the top
However the use-case was verysimple, SDOs work better with morecomplex models

© 2015 C24 Technologies
24
SDOS & IMDGS
Performance and memory gain can be very significantThe following demonstrates different storage capacity of XML, standard Java vs binary for storing XML (in this case FpML and ISO-20022)The IMDG in this specific case is Coherence but others are similar

© 2015 C24 Technologies
25
BINARY WITH SPARK
Compare the red (cached memory) and there’s no difference but compare cached diskSince binary serialisation to/from disk is almost cost-free we see almost no degradation from disk to memoryUsing binary with diskis about 20 times fasterthan the best alternativeand less than half thespeed of cachedmemoryUsing binary on disk with Spark offers the volumes of Hadoop and performance of Spark

© 2015 C24 Technologies
26
SO MUCH TO TALK ABOUT, SO LITTLE TIME :-(
Spring, Groovy, C#, Go, Scala, Clojure, SwiftMicroServices, Docker, CloudFoundryESBs, SOA, JEEDatabases, RDBMS and NoSQLIn-Memory Data Grids (IMDGs)CloudIoTPaaS / SaaS / IaaS / YaSaaSVirtualisation

© 2015 C24 Technologies
27
SPRING BOOT
Spring Boot is becoming the de facto framework for Java-based applications
With very little else a Spring Boot application can be deployed on a local machine, onto a server, a data centre (private cloud) or the cloud (a data centre where you don’t know the addrsss)
Unless you’re going enterprise scale with configurable workflow, high availability, automated scalability then it’s difficult to justify MicroServices
Given the option we use Spring Boot with our clients and they seem to get hooked on the simplicity and power

© 2015 C24 Technologies
28
MICROSERVICES
There are two types of MicroService or two main “needs”To be able to package the entire application and deploy it in one goTo be able to manage deployment and life-cycle of large scale systems
The Java Virtual Machine with Spring Boot and Maven (cough splutter) goes a long way to providing all the functionality of the first need
At enterprise scale then we need more than a packaged application - Cloud Foundry / BlueMix etc.This is usually in the realm of the Dev Ops guys (and gals) not the Java/Spring programmerIn a perfect world programmers need an abstraction from MicroServices implementations, Spring Boot goes a long way to providing this

© 2015 C24 Technologies
29
TIME IS SHORT…
… but hopefully time for a few questions…
@jtdavies

THANK YOU!
@jtdavies





























