Embed Size (px)
Citation preview

Dmitri Chtchourov,
MANTL Data Pla6orm, Microservices and BigData Services
Innova?on Architect, CIS CTO Group

Agenda
Problem & Opportunity
What do we want to do?
What is in it for us?
How does it work?
What have we done so far?
Anatomy of a Service
Reference Architectures and real use cases
PuMng it all together

Problem & Opportunity
Rapid innova?on in compu?ng and applica?on development services No single service is op.mal for all solu.ons Customers want to run mul.ple services in a single cluster and run mul.ple clusters in Intercloud environment
...to maximize u,liza,on ...to share data between services …Complex/BigData and Microservices together

Technologies matrix* Service Product Cloud/Virtualiza?on CIS/AWS/Metacloud/UCS… Provisioning Open Stack/Terraform Automa?on Ansible Clustering & Resource Management Mesos, Marathon, Docker Load Balancing Avi Networks ETL & Data Shaping StreamSets Log Data Gathering Logstash Metrics Gathering CollectD, Avi Networks Messaging KaUa, Solace Data Storing (Batch) HDFS Data Storing (OLTP/Real-‐?me) Cassandra Data Storing (Indexing) Elas?c search Data Processing Apache Spark Visualiza?on Zoomdata *Subset example

Cloud Management
Data Collect
Data Storage
Data Processing
Visualisa.on
Technologies stack

Datacenter and solution today
VM7 or
BM7
VM8 or
BM8
VM4 or
BM4
VM5 or
BM5
VM6 or
BM6
VM1 or
BM1
Visualization Service
Data Ingestion Service
Analytics Service
• Configuration and management of 3 separate clusters • Resources stay idle if service is not active • Need to move data between clusters for each service
VM2 or
BM2
VM3 or
BM3
VM1 or
BM1
VM2 or
BM2
VM3 or
BM3

What do we want to do?
Data Inges?on Service
Analy?cs Service
Visualiza?on Service
….to maximize u,liza,on ...to share data between services
Shared cluster Mul.ple clusters

Shared Cluster
CIS/AWS/Metapod/UCS…
VM1 or
BM1
VM2 or
BM2
VM3 or
BM3
VM4 or
BM4
VM5 or
BM5

What is in it for us?
Maximize u.liza.on Deliver more services with smaller footprint
Shared clusters for all services
Easier deployment and management with unified service plaCorm
Shared data between services Faster and more compe..ve services and solu.ons
Combine paradigms for flexibility and func.onality
Run complex services and microservices in the single environment

How does this work?
Mesos Slave
Spark Task Executor
Mesos Executor
Mesos Slave
Docker Executor
Docker Executor
Mesos Master
Task #1 Task #2 ./python XYZ java -‐jar XYZ.jar ./xyz
Mesos Master Mesos Master
Spark Service Scheduler Marathon Service Scheduler Zookeeper quorum

How does this work? Mesos provides fine grained resource isola+on
Mesos Slave Process
Spark Task Executor
Mesos Executor
Task #1 Task #2 ./python XYZ
Compute Node
Executor Container (cgroups)

How does this work? Mesos provides scalability
Mesos Slave Process
Spark Task Executor
Task #1 Task #2 ./ruby XYZ
Compute Node
Python executor finished, more available resources more Spark
Container (cgroups)
Task #3 Task #4

How does this work? Mesos has no single point of failure
Mesos Master Mesos Master Mesos Master
VM1 or
BM1
VM2 or
BM2
VM3 or
BM3
VM4 or
BM4
VM5 or
BM5
Services keep running if VM fails!

How does this work? Master node can failover
Mesos Master Mesos Master Mesos Master
VM1 or
BM1
VM2 or
BM2
VM3 or
BM3
VM4 or
BM4
VM5 or
BM5
Services keep running if Mesos Master fails!

How does this work? Slave process can failover
Tasks keep running if Mesos Slave Process fails!
Mesos Slave Process
Spark Task Executor
Task #1 Task #2 ./ruby XYZ
Compute Node
Task #3 Task #4

How does this work? Can deploy in many environments Get orchestrated by Openstack, Ansible (scripts), Cloudbreak
True Hybrid Cloud deployment: CIS, AWS, UCS, vSphere, other
CIS/ CIS/AWS/Metpod/vSphere/UCS…
Terraform
REST API REST API
Scripted provisioning
Direct provisioning
Policy, Auto-‐scaling
VM1 or
BM1
VM2 or
BM2
VM3 or
BM3
VM4 or
BM4
VM5 or
BM5

How does this work? Microservices managed and scaled separately Microservices managed by Mesos in a single platform
Microservices architecture for Mesos frameworks and other components
CIS/AWS/Metacloud/vSphere/UCS… Terraform
Spark Executor
N Spark
Executor 1 Spark
Scheduler Kafka
Broker N Kafka
Broker 1 Kafka
Scheduler Docker Docker
Traefik Microservices …
REST API REST API
Scripted provisioning
Direct provisioning
Policy, Auto-scaling
VM1 or
BM1
VM2 or
BM2
VM3 or
BM3
VM4 or
BM4
VM5 or
BM5

What have we done so far? Working with partners on adop.ng and co-‐developing services
Partners Co-‐development Partners

Anatomy of the service/framework Riak is Basho Technologies distributed highly available database Op?mized Mul?-‐Datacenter opera?on We are working together with Basho Labs on developing and tes?ng their Mesos Service version of the product
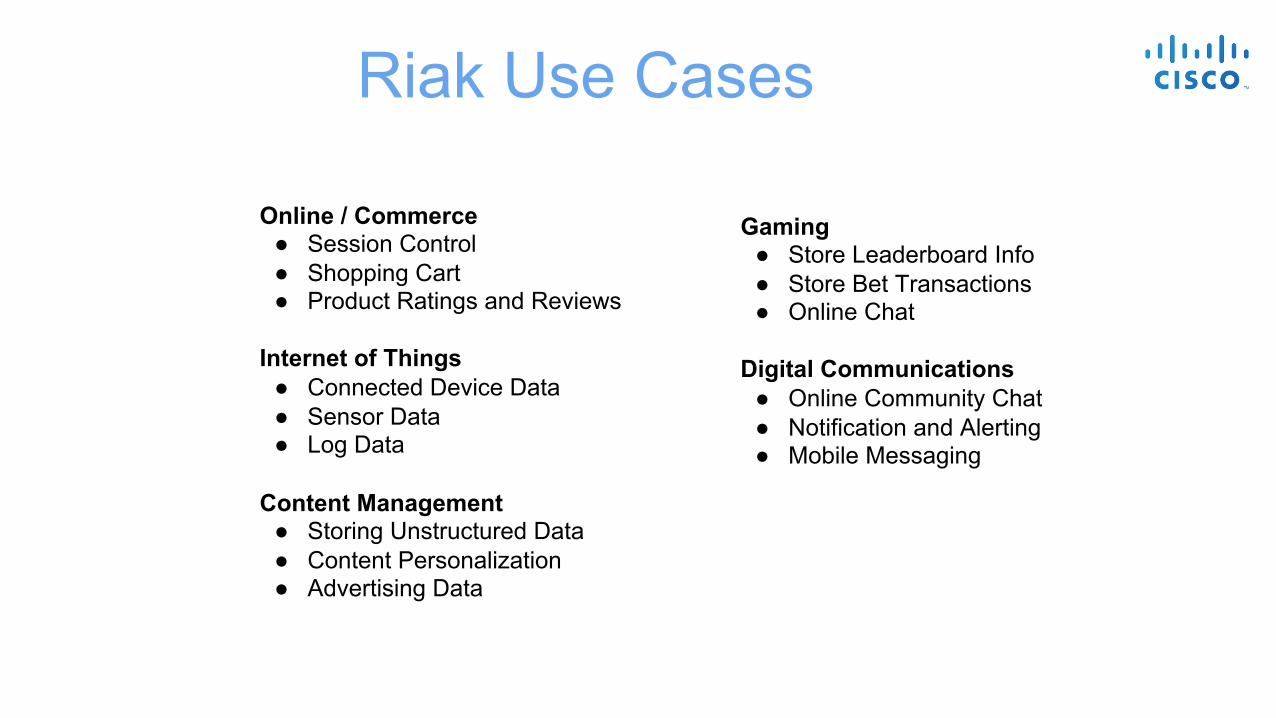
Riak Use Cases
Online / Commerce ● Session Control ● Shopping Cart ● Product Ratings and Reviews
Internet of Things ● Connected Device Data ● Sensor Data ● Log Data
Content Management ● Storing Unstructured Data ● Content Personalization ● Advertising Data
Gaming ● Store Leaderboard Info ● Store Bet Transactions ● Online Chat
Digital Communications ● Online Community Chat ● Notification and Alerting ● Mobile Messaging

Development phases Phase 0: Package applica?on in Docker container to deploy on Mesos Phase 1: Convert applica?on to Microservices Architecture to deploy as Mesos applica?on with mul?ple components Phase 2: Create an intelligent scalable Mesos service based on the applica?on
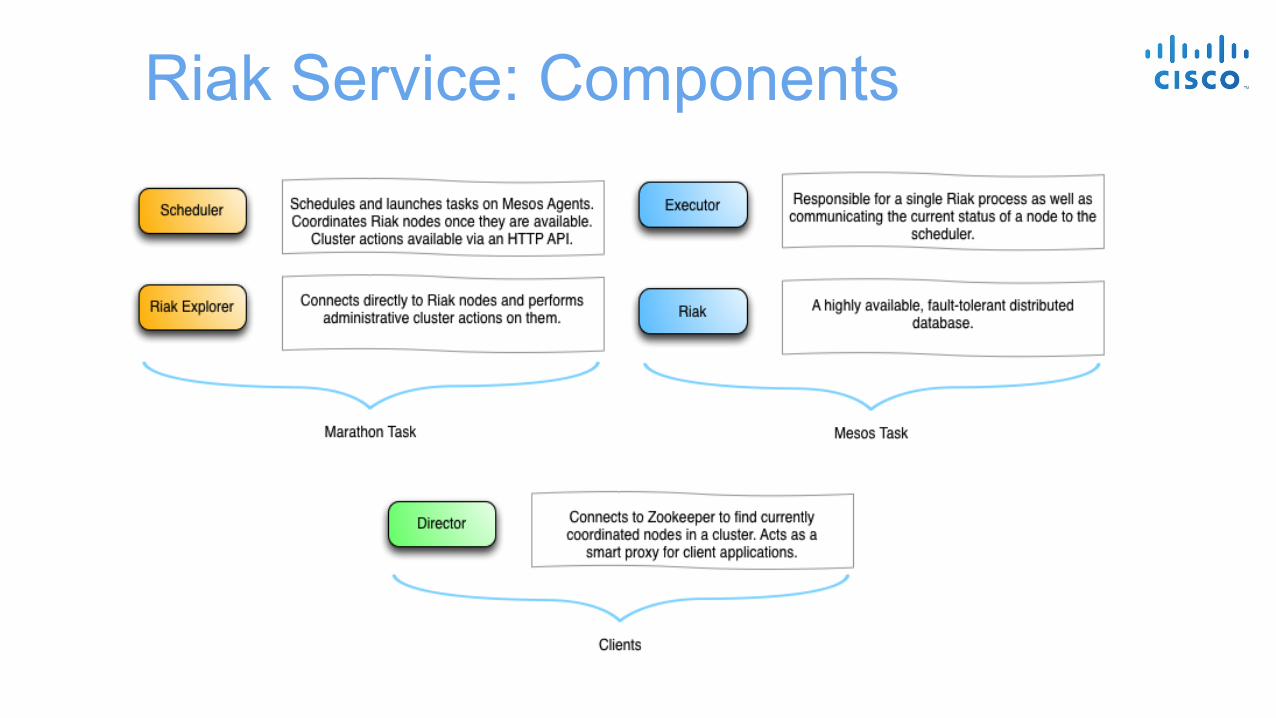
Riak Service: Components

Riak Service: Architecture

Riak Service: Persistence

Riak Service: Operational Simplicity

Riak Service: Highly Scalable E-‐commerce Applica.on with Varying Traffic

Anatomy of the service/framework Zoomdata is distributed highly available large scale visualiza?on pla6orm Op?mized very big data set micro-‐query analy?cs We are working together with Zoomdata on developing and tes?ng their Mesos Service version of the product

Zoomdata Service: Components

Zoomdata Service: Mesos + Kubernetes
Mesos Slave
Mesos Master
Mesos Slave Mesos Slave
Zoomdata web app
Mongodb Spark Worker
Spark Executor
Spark Executor
Proxy (haproxy, nginx)
Kubernetes Mongo Service/RC
Kubernetes Spark-‐Proxy Service/RC
Spark-‐Proxy
Zoomdata web app
Zoomdata web app
Kubernetes Framework
Kubernetes Zoomdata Scheduler Service/RC
Zoomdata Scheduler
ProxyGen Script
User
● Every component (Zoomdata App, MongoDB, Spark-‐Proxy, Scheduler) must be started in independent K8s Pod and there must be exactly one MongoDB, Spark-‐Proxy and Scheduler Pods meanwhile Zoomdata App can be scaled with help Kubernetes Replica?on Controller.
● There must be defined Kubernetes Service for MongoDB, Spark-‐Proxy, Scheduler as they will be used in Zoomdata’s App Pod. Every docker container will have env variables for every present Service injected automa?cally.

Anatomy of the service/framework
StreamSets is an open source con?nuous big data ingest infrastructure Accelerates ?me to analysis with unprecedented transparency and processing to data in mo?on.
Cluster deployments
JVM, Docker, Spark Streaming on Mesos
Con?nuous Opera?ons to Minimize down?me

Advantages of Streamsets
Adaptable Data flow -‐ Design and execute intent-‐driven data flows in a graphical
IDE
Instream Sani?za?on -‐ transform and process the data on the fly
Intelligent Monitoring -‐ Get early warnings, detect anomalies and take ac?on
Link origins to des?na?ons with in-stream data preparation

Streamsets Data Pipeline
MESOS
Streamsets Data Collector (SDC) Architecture Cluster Streaming mode Data Collector runs as an applica?on within Spark Streaming, Spark Streaming runs on Mesos cluster manager to process data from a KaUa cluster. The Data Collector uses a cluster manager and a cluster applica?on to spawn workers as needed. Cluster Batch Mode : Data Collector processes all available data from HDFS and then stops the pipeline. MapReduce generate addi?onal worker nodes as needed. Standalone mode Single Data Collector process runs the pipeline. A pipeline runs in standalone mode by default.

MANTL Data Platform Overview A modern, baneries included pla6orm for rapidly deploying globally distributed services. Mantl’s goal is to provide a fully func?onal, instrumented, and portable container based PaaS for your business at the push of a bunon
1) Easy deployment and configura?on on different
pla6orms
2) High availability and self-‐healing
3) Mul?-‐datacenter support
4) Linear scalability
5) Smart resource management
6) Wide range of supported frameworks

MANTL nodes
Consul for service discovery Mesos cluster manager Marathon for cluster management Docker container run?me Zookeeper for configura?on management
Docker containers Any Mesos-‐based workloads
Traefik for proxying external traffic into services running in the cluster

Security & Opera.on
Frameworks
PlaCorm Support
Mantl Components
Core Components
➢ Data Storage -‐ Riak, Cassandra, HDFS ➢ Data processing -‐ Spark ➢ Security -‐ Vault
➢ Data inges?on – KaYa ➢ Metrics collec?on -‐ Collectd ➢ Logs forwarding -‐ Logstash
➢ Provisioning -‐ Terraform, Ansible ➢ Cluster management – Mesos, Marathon ➢ Service discovery and configura?on management -‐ Consul, Zookeeper,
Traefik ➢ Container run?me -‐ Docker
➢ Cisco Cloud Services, Cisco MetaCloud ➢ Amazon Web Services ➢ Google Compute Engine
➢ Openstack ➢ DigitalOcean ➢ Bare Metal
➢ Autoscaling and high availability ➢ Applica?on load balancer ➢ Applica?on dynamic firewall
➢ Manage Linux user accounts ➢ Authen?ca?on and authoriza?on
for Consul, Mesos, Marathon

Long Running Services
Big Data Processing
Batch Scheduling
Supported Mesos Frameworks
Data Storage
Mesos makes it easy to develop distributed systems by providing high-‐level building blocks.

ANALYTICS PLATFORM MANAGEMENT
Data Inges?on • KaUa, Streamsets configurators Data Storage
Riak, Cassandra, HDFS Model DevOps Machine learning
MLLib, Spark Model Deployment • Model loading, versioning
Cluster Management & Scheduling
Cluster manager Mesos
Cluster Management long running service
Marathon Service Discovery
Consul Distributed Virtual network
Calico ETCD
ADVANCED ANALYTICS APPS
Analy?cs Accelerators as Apps • Forecas?ng, NLP, op?miza?on, enrichment etc.
SPECIALIZED ADVANCED ANALYTICS MODELS
Consul?ng Services Design, Build, Deploy Maintain, Manage Performance
DASHBOARDS
ZoomData Tableau, Qlik, Spo6ire, Excel/BI Cubes …
BUSINESS APPS
Custom ZoomData Visualiza?ons (D3) Custom Applica?ons Customer System Integra?on
CUSTOMIZAT
ION &
MAN
AGED
SER
VICE
S
CISCO INTERCLOUD
Customization MANTL Data Platform

Sample Architecture for Batch Data Processing
Cassandra
Elastic Search
Spark
Spark Mllib Riak
Kibana Dashboard
Visualisation Storage
Stream Sets
I/P in multiple formats Text, logs and json from various storage source.
Spark application process data and store to elastic search or Cassandra or Riak storage for visualization else it stores in HDFS
Machine learning algorithm for data science application
Zoomdata Data
Discovery
D3 Web
Application
HDFS
StreamSets Data Collector runs as an application in Spark Streaming to pull data from origin to spark
CSV, Tab delimited etc.
LOG file
JSON
TEXT

Sample Architecture for Data Streaming
Kafka
Cassandra
Elastic Search
Spark
Spark Mllib
Riak
Kibana Dashboard
Visualisation Storage
Stream Sets
Streaming network from different sources
Kafka is used for collecting streaming data and data is consumed through consumer API by Streamset for further processing.
Spark application process data and store to elastic search or Cassandra or Riak storage.
Machine learning algorithm for data science application
Zoomdata Data
Discovery
D3 Web
Application

Use Case 1 - Shipped Analytics
Collect log metric from cluster to analyze and drive Alert/Recommend engine • Alert Engine - produces alert messages on a basis of some conditions.
• Trend Engine - produces trend messages related to data aggregation. • Policy Engine – derives from Alert and Trend Engines produces policy
messages which contain recommendations.

Use Case 1 - Shipped Analytics Architecture
Central Cluster
Probe
Probe
Probe

DataCollector
DataCollector
DataCollector
node
node
node
node
node
Use Case 1 - Shipped Analytics Data Flow

• Iden?fy the top technology trends by analyzing public data and open source projects
• Use machine learning to process a wide range of public data available on the world wide web and iden?fy high poten?al emerging technologies
• Publish results to a web-‐based dashboards and refresh results regularly
Use case 2 - Emerging Top technology using Public data

Use Case 2 - Analysis Through Public data

Use Case 2 - Dataflow
APIs
RSS feeds
Scraping
Numeric Network Data
Text data (ar?cles, blogs)
Staging tables
Interac.ve D3 Dashboards
Websites
Data Sources D a t a Extractors
Data Storage Data Processing Machine Learning Visualization
Below we used the framework to execute the project in CIS Data Platform

Lambda Reference Architecture
Monitoring / Analy?cs Cluster (local, Texas-‐3)
Global Monitoring / Analy?cs Cluster (global, Texas-‐1)
Monitoring / Analy?cs Cluster (local, Ams. -‐1 )
Monitoring / Analy?cs Cluster (local, Lon.-‐1)
Local components and deployment is the same as global, just smaller Real-‐.me and batch processing (Lambda), anomaly detec.on, visualiza.on
SSL
KaUa
SSL
SSL
MQTT

MANTL Data Platform in Practice: putting it all together
Working on advanced enabling technology – Mesos, K8S, Orchestra?on Working on developing individual components – dev & co-‐dev: Zoomdata, Riak, Streamsets, etc. PuMng together reference architectures and real solu?ons to test and further develop the technology Provide innova?on and advanced services to customers Pla6orm to develop and deliver Microservices and Data applica?ons

Q/A

Next steps Con?nue partnerships and co-‐devlopment efforts with industry leaders to deliver innova?on Con?nue applying new developed technology to real use cases and PoC with customers and partners Con?nue working closely with A&E and Product teams on produc?za?on roadmap Work with A&E team closely on priori?za?on of our R&D ac?vi?es to stay closely aligned

Anatomy of the service/framework
Elas?csearch is a highly scalable open-‐source full-‐text search and analy?cs engine Allows to store, search, and analyse big volumes of data quickly and in near real ?me Underlying technology in applica?on to Op?mize complex search in Big data We are working together with Elas?c developing and tes?ng their UTILIZING Mesos cluster to run Elas?csearch

Elas?csearch on Mesos Cluster
Elas?c framework scheduler
Marathon framework scheduler
Chronos framework scheduler
Zookeper
Chronos Executor Marathon Executor HA Proxy node
Step 1: Mesos Cluster with Marathon & Chronos running Step 2:Elas?c framework installa?on on MESOS Master with a configured # of mesos slaves to be launched Step 3: Deploys the ES executore in MESOS slaves Step 4: ES nodes discovery and Zookeper pugin in ES nodes Step 5 Using plugin nodes find each other and search is op?mized at cluster level
Elas?csearch executor & Zookeper pugin

MANTL Architecture – Datacenters Control nodes manage the cluster and resource nodes. Containers automa?cally register themselves into DNS so that other services can locate them.
Once WAN joining is configured, each cluster can locate services in other data centres via DNS or Consul API
Single Datacentre Mul?ple Datacentre

Client Client Client
RPC over DNSmask
RPC over DNSmask
LAN gossip over DNSmask
Server Server (Leader) Server
replication replication
Lead forwarding
Internet
Server Server (Leader) Server
replication replication
Lead forwarding
Datacenter 1
Datacenter 2
Remote DC forwarding
WAN gossip
TCP&UDP
Consul
➢ Service discovery
➢ Client health-checking
➢ Key-value store for
configurations
➢ Multi-datacenter support

Mesos features
Mesos makes it easy to develop distributed systems by providing high-‐level building blocks.
➢ Scalability
➢ Fault-tolerance and self-healing
➢ Resource isolation
➢ Fine Grained resource elasticity

Mesos architecture

Mesos setup for developing application
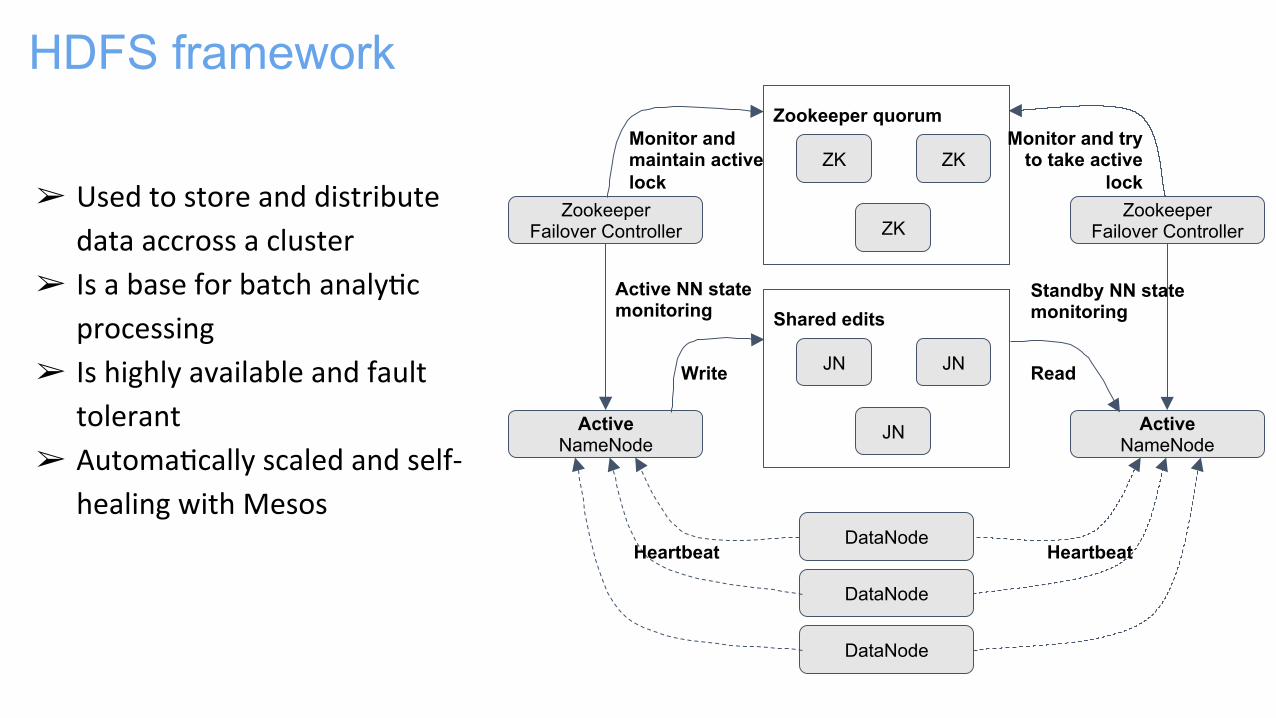
ZK
ZK
ZK
Zookeeper quorum
JN
JN
JN
Shared edits
DataNode
DataNode
Active NameNode
Zookeeper Failover Controller
Active NameNode
Zookeeper Failover Controller
DataNode
Heartbeat Heartbeat
Write Read
Active NN state monitoring
Standby NN state monitoring
Monitor and maintain active lock
Monitor and try to take active
lock ➢ Used to store and distribute
data accross a cluster ➢ Is a base for batch analy?c
processing ➢ Is highly available and fault
tolerant ➢ Automa?cally scaled and self-‐
healing with Mesos
HDFS framework

* hnps://github.com/datastax/spark-‐cassandra-‐connector
Mesos Framework for Spark and Cassandra

* Smart broker.id assignment * Preservation of broker placement * Rolling restarts * Easy cluster scale-up
Mesos framework for Kafka

Ø Fault tolerant job scheduler Ø handles dependencies and ISO8601 based
schedules Ø Flexible Job Scheduling Ø Supports arbitrarily long dependency chain Ø supports the defini?on of jobs triggered by
the comple?on of other jobs
Mesos framework for Chronos

How MANTL Data Platform for business application • Cisco Data Platform can be used to build custom applications or
service for various analysis and Data analytics initiative. • Companies can streamline Data ingestion, process,
manipulate , analyse and visualize data all in single Infrastructure

Yali Load Testing Framework Yali
Elas?csearch
KaUa
Cassandra
HDFS
Plugins
Kafka
Cassandra
HDFS
Storage
Elasticsearch
Generate data to load test storage

Elasticsearch Plugin Testing Results
Job Host config
Elas.csearch config
Execu.on threads
Batches Records/batch/thread
Average response from ES, s
Records/s Record size, b
Records generated * 10^6
Execu.on .me, min
Win7, 4 cpu, 16 ram
Cluster: CentOs 6.7, Elas?csearch 2.1.1, VPN network, 2 master(4 cpu, 16 ram), 15 worker nodes(8 cpu, 32 ram)
12 60 50000 78 6804 280 36 84
Local: CentOs 6.4, Elas?csearch 2.1.1, VMware virtual network, single node (2 Core cpu, 8 Gb ram)
4 60 10000 1,6 14768 280 2,4 2,5
Records





























