Embed Size (px)
Citation preview

/ 103
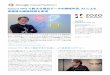
Hive on Sparkを活用した高速データ分析
ビッグデータ部加嵜長門
2016年2月8日
Hadoop / Spark Conference Japan 2016

/ 103
自己紹介
•加嵜長門
• 2014年4月~ DMM.comラボ• Hadoop基盤構築
• Spark MLlib, GraphXを用いたレコメンド開発
•好きな言語• SQL
• Cypher
2

/ 103
DMM.com の事例 –システム概要
3
Recommend API
Search API
Data API
Actuation
Transforming
Message Queue Consumer
ETL
Processing
Storage
行動ログ
Recommend
Products
Marketing
• 機械学習• 統計分析• グラフ分析
サービス情報

/ 103
DMM.com の事例 –課題
• 1年前の課題
• Hive が遅い• クエリのデバッグ
• クエリの修正・実行→ 休憩→ 結果を確認
• クエリの修正・実行→ MTG へ→ 結果を確認
• クエリの修正・実行→ 帰宅→ 翌日結果を確認
• …
• 定期バッチ• サービスの追加とともに実行時間が肥大化
4

/ 103
DMM.com の事例 – Hive の高速化を目指す
• Hive• Hive on MapReduce
• Hive on Spark
• Hive on Tez
• Spark• Shark
• SparkSQL
• DataFrame
• Impala
• Drill
• Presto
• …
5
• SQL on Hadoop の選択肢

/ 103
DMM.com の事例 – Hive の高速化を目指す
•「高速」とは?
6

/ 103
DMM.com の事例 – Hive の高速化を目指す
•「高速」とは?• 低レイテンシ
7

/ 103
DMM.com の事例 – Hive の高速化を目指す
•「高速」とは?• 低レイテンシ
• 高スループット
8

/ 103
DMM.com の事例 – Hive の高速化を目指す
•「高速」とは?• 低レイテンシ
• 高スループット
• 導入コスト
• 開発コスト
• 学習コスト
9

/ 103
DMM.com の事例 – Hive on Spark の導入
• Hive on Spark とは• https://issues.apache.org/jira/browse/HIVE-7292
• Hive の実行エンジンに、MapReduce ではなく Spark を使用• Hive テーブルを RDD として扱う
• 用途的には Hive on Tezと競合する
• Spark – RDD のメリット• 繰り返し処理に強い
10

/ 103
DMM.com の事例 – Hive on Spark の導入
• 2015年8月26日~• Hive on Spark 検証開始
• 2015年9月11日~• プロダクション環境に導入• Hive on MR + Spark の運用を、Hive on Spark + Spark の運用に変更
• 処理の高速化• リソース管理の一元化
• 現在まで特に問題なく稼働中
• 導入~運用までのコストが低い• Hive クエリと Spark 運用の知識があれば、他に学習することはほとんどない
11

/ 103
DMM.com の事例 – Hive on Spark のメリット
• 3時間以上かかっていた Hive バッチ処理が1時間まで短縮• ジョブ数が多くなるクエリほど効果が高い傾向
• Hive クエリの書き換えが不要• パラメタ一つの変更で高速化できる
12
-- Hive on SparkSET hive.execution.engine=spark;
37% 19%

/ 103
Hive on Spark を活用した高速データ分析
• レイテンシ• 数秒~数分
• スループット• Spark と同等
• 導入コスト• Spark が導入されていれば一瞬(ただし experimental)
• 開発コスト• HiveQL互換 (SQL:2003相当)
• 学習コスト• 新しい概念は特にない
13

/ 103
Hive on Spark –導入手順の紹介
• CDHを使う• Configuring Hive on Spark
http://www.cloudera.com/documentation/enterprise/latest/topics/admin_hos_config.html
• Apacheコミュニティ版を使う• Hive on Spark: Getting Started
https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started
14
■ Important: Hive on Spark is included in CDH 5.4 and higher but is not currently supported nor recommended for production use.

/ 103
Hive on Spark –導入手順の紹介
• CDHを使う• Hive > 設定 > Enable Hive on Spark (Unsupported) にチェック
• 3クリック!(Hive, YARN, Sparkが設定済であれば)
15

/ 103
Hive on Spark –導入手順の紹介
•クエリ実行時に engine パラメタを設定
16
-- Hive on SparkSET hive.execution.engine=spark;
-- Hive on MapReduceSET hive.execution.engine=mr;
-- Hive on TezSET hive.execution.engine=tez;
※参考

/ 103
Hive on Spark –実行例
• Beeline
17
# sudo -u hdfs beeline ¥> --verbose=true ¥> -u jdbc:hive2:// ¥> --hiveconf hive.execution.engine=spark
issuing: !connect jdbc:hive2:// '' ''scan complete in 2msConnecting to jdbc:hive2://Connected to: Apache Hive (version x.x.x)Driver: Hive JDBC (version x.x.x)Transaction isolation: TRANSACTION_REPEATABLE_READBeeline version x.x.x by Apache Hive
0: jdbc:hive2://>

/ 103
Hive on Spark –実行例
• Hue
18

/ 103
Hive on Spark –実行例
• Hue から実行した場合の注意点(調査中)• 実行ユーザごとに ApplicationMasterが残り続ける
• 動的アロケーションで Executor をデコミッションさせてあげるほうが良い(後述)
19

/ 103
Hive on Spark –パフォーマンスチューニング
•初期設定ではあまりパフォーマンスは期待できない• デフォルトで割り当てられるリソースが少ない
•ジョブ自体が失敗することも多い
20
ERROR cluster.YarnScheduler: Lost executor 1ERROR cluster.YarnScheduler: Lost executor 2
FAILED: SemanticException Failed to get a spark session: org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create spark client.

/ 103
Hive on Spark –パフォーマンスチューニング
•ボトルネックとなる箇所の特定
•コンテナのリソースを調整
•パーティション数(タスク数)を調整
•その他の項目を調整
21
ほとんど Spark の話

/ 103
Hive on Spark –パフォーマンスチューニング
•ボトルネックとなる箇所の特定
•コンテナのリソースを調整
•パーティション数(タスク数)を調整
•その他の項目を調整
22

/ 103
Hive on Spark –ボトルネックとなる箇所の特定
•主に以下の3パターン• コンソール出力
• Spark UI
• EXPLAIN句の出力
23

/ 103
Hive on Spark –ボトルネックとなる箇所の特定
•コンソール出力• 見方は後述
24

/ 103
Hive on Spark –ボトルネックとなる箇所の特定
• Spark UI• Spark ユーザには見慣れたページ
25

/ 103
Hive on Spark –ボトルネックとなる箇所の特定
• EXPLAIN句の出力• Hive と同様に実行計画を確認できる
26
EXPLAIN SELECT … ;

/ 103
Hive on Spark –ボトルネックとなる箇所の特定
•コンソール出力(再)• Spark Job の実行過程が表示される
27

/ 103
【補足】Spark の基礎
• RDD, Partition
28
Partition 1
Partition 2
Partition 3
RDD 1

/ 103
【補足】Spark の基礎
•処理の流れ
29
Partition 1
Partition 2
Partition 3
RDD 1
Partition 1
Partition 2
Partition 3
RDD 2

/ 103
【補足】Spark の基礎
•処理の流れ
30
Partition 1
Partition 2
Partition 3
RDD 1
Partition 1
Partition 2
Partition 3
RDD 2
Partition 1
Partition 2
Partition 3
RDD 3

/ 103
【補足】Spark の基礎
•シャッフル処理
31
Partition 1
Partition 2
Partition 3
RDD 1
Partition 1
Partition 2
Partition 3
RDD 2
Partition 1
Partition 2
Partition 3
RDD 3
Partition 1
Partition 2
RDD 4

/ 103
【補足】Spark の基礎
•シャッフル処理
32
Partition 1
Partition 2
Partition 3
RDD 1
Partition 1
Partition 2
Partition 3
RDD 2
Partition 1
Partition 2
Partition 3
RDD 3
Partition 1
Partition 2
RDD 4
Partition 1
Partition 2
RDD 5

/ 103
【補足】Spark の基礎
• Stage
33
Partition 1
Partition 2
Partition 3
RDD 1
Partition 1
Partition 2
Partition 3
RDD 2
Partition 1
Partition 2
Partition 3
RDD 3
Partition 1
Partition 2
RDD 4
Partition 1
Partition 2
RDD 5
Stage 1 Stage 2

/ 103
【補足】Spark の基礎
• Task
34
Partition 1
Partition 2
Partition 3
RDD 1
Partition 1
Partition 2
Partition 3
RDD 2
Partition 1
Partition 2
Partition 3
RDD 3
Partition 1
Partition 2
RDD 4
Partition 1
Partition 2
RDD 5
Stage 1 Stage 2
Task 1
Task 3
Task 1
Task 2
Task 2

/ 103
【補足】Spark の基礎
• Job
35
Job
Stage 1 Stage 2
Partition 1
Partition 2
Partition 3
RDD 1
Partition 1
Partition 2
Partition 3
RDD 2
Partition 1
Partition 2
Partition 3
RDD 3
Task 1
Task 2
Task 3
Partition 1
Partition 2
RDD 4
Partition 1
Partition 2
RDD 5
Task 1
Task 2

/ 103
【補足】Spark の基礎
•コンソール出力の見方
36
Job
Stage 1 Stage 2
Task 1
Task 2
Task 3
Task 1
Task 2
Task 3
Task 4
Task 5
Task 4
Stage-1_0: 0/5 Stage-2_0: 0/4
Job Progress Format
ステージ名
リトライ回数 タスク数

/ 103
【補足】Spark の基礎
• Driver, Executor
37
Job
Stage 1 Stage 2
Task 1
Task 2
Task 3
Task 1
Task 2
Task 3
Task 4
Driver
Executor 1
executor memory
core 1 core 2
Executor 2
executor memory
core 1 core 2Task 5
Task 4
Stage-1_0: 0/5 Stage-2_0: 0/4
Job Progress Format

/ 103
【補足】Spark の基礎
•タスクスケジューリング
38
Job
Stage 1 Stage 2
Driver
Executor 1
executor memory
core 1 core 2
Executor 2
executor memory
core 1 core 2
Task 1 Task 2
Task 3
Task 1
Task 2
Task 3
Task 4Task 5
Task 4
Stage-1_0: 0(+4)/5 Stage-2_0: 0/4
Task 1
Task 2
Task 3
Task 4
Job Progress Format
実行中タスク数

/ 103
【補足】Spark の基礎
•タスクスケジューリング
39
Job
Stage 1 Stage 2
Driver
Executor 1
executor memory
core 1 core 2
Executor 2
executor memory
core 1 core 2
Task 3
Task 1
Task 2
Task 3
Task 4Task 5
Task 4
Stage-1_0: 2(+2)/5 Stage-2_0: 0/4
Task 1
Task 2
Task 3
Task 4
Job Progress Format
完了タスク数

/ 103
【補足】Spark の基礎
•タスクスケジューリング
40
Job
Stage 1 Stage 2
Driver
Executor 1
executor memory
core 1 core 2
Executor 2
executor memory
core 1 core 2
Task 3
Task 1
Task 2
Task 3
Task 4
Task 5
Task 4
Stage-1_0: 2(+3)/5 Stage-2_0: 0/4
Task 5
Task 1
Task 2
Task 3
Task 4
Job Progress Format

/ 103
【補足】Spark の基礎
•タスクスケジューリング
41
Job
Stage 1 Stage 2
Driver
Executor 1
executor memory
core 1 core 2
Executor 2
executor memory
core 1 core 2
Task 1
Task 2
Task 3
Task 5
Task 4
Stage-1_0: 4(+1)/5 Stage-2_0: 0/4
Task 5
Task 1
Task 2
Task 3
Task 4
Job Progress Format

/ 103
【補足】Spark の基礎
•タスクスケジューリング
42
Job
Stage 1 Stage 2
Driver
Executor 1
executor memory
core 1 core 2
Executor 2
executor memory
core 1 core 2
Task 1
Task 2
Task 3
Task 4
Stage-1_0: 5/5 Stage-2_0: 0/4
Task 5
Task 1
Task 2
Task 3
Task 4
Job Progress Format

/ 103
【補足】Spark の基礎
•タスクスケジューリング
43
Job
Stage 1 Stage 2
Driver
Executor 1
executor memory
core 1 core 2
Executor 2
executor memory
core 1 core 2
Task 1 Task 2
Task 3 Task 4
Stage-1_0: 5/5 Stage-2_0: 0(+4)/4
Task 5
Task 1
Task 2
Task 3
Task 4
Task 1
Task 2
Task 3
Task 4
Job Progress Format

/ 103
【補足】Spark の基礎
•タスクスケジューリング
44
Job
Stage 1 Stage 2
Driver
Executor 1
executor memory
core 1 core 2
Executor 2
executor memory
core 1 core 2
Task 2
Task 4
Stage-1_0: 5/5 Stage-2_0: 2(+2)/4
Task 1
Task 2
Task 3
Task 4
Task 5
Task 1
Task 2
Task 3
Task 4
Job Progress Format

/ 103
【補足】Spark の基礎
•タスクスケジューリング
45
Job
Stage 1 Stage 2
Driver
Executor 1
executor memory
core 1 core 2
Executor 2
executor memory
core 1 core 2
Task 1
Task 2
Task 3
Task 4
Task 5
Task 1
Task 2
Task 3
Task 4
Stage-1_0: 5/5 Stage-2_0: 4/4
Job Progress Format

/ 103
【補足】Spark の基礎
• Spark UI• どのタスクでどのくらい時間がかかったか詳細に確認できる
46

/ 103
Hive on Spark –パフォーマンスチューニング
•ボトルネックとなる箇所の特定
•コンテナのリソースを調整
•パーティション数(タスク数)を調整
•その他の項目を調整
47

/ 103
Hive on Spark –コンテナのリソースを調整
•主な項目• Driver, Executor メモリを調整
• Driver, Executor コア数を調整
• Executor 数を調整• 静的に指定
• 動的アロケーションを使用
48
Driver
Executor 1
executor memory
core 1 core 2
Executor 2
executor memory
core 1 core 2

/ 103
Hive on Spark –コンテナのリソースを調整
•主な項目• Driver, Executor メモリを調整
• Driver, Executor コア数を調整
• Executor 数を調整• 静的に指定
• 動的アロケーションを使用
49
Driver
Executor 1
executor memory
core 1 core 2
Executor 2
executor memory
core 1 core 2
メモリを増やして1度
に処理できるデータ量を増やす
コア数を増やして1度
に処理できるタスク数を増やす
インスタンス数を増やして1度に処理でき
るタスク数とデータ量を増やす

/ 103
Hive on Spark –コンテナのリソースを調整
•静的にリソースを割り当てる
50
パラメタ名 デフォルト値 推奨値
spark.driver.memory 1g 4g
spark.driver.cores 1 1
spark.yarn.driver.memoryOverhead driverMemory * 0.10,with minimum of 384 (MB)
driverMemory * 0.10
spark.executor.memory 1g 10g~
spark.yarn.executor.memoryOverhead executorMemory * 0.10,with minimum of 384 (MB)
executorMemory * 0.25
spark.executor.cores 1 (YARN mode) (環境依存) 2~
spark.executor.instances 2 (環境依存) 2~
http://spark.apache.org/docs/1.6.0/running-on-yarn.htmlhttp://spark.apache.org/docs/1.6.0/configuration.htmlhttps://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started

/ 103
Hive on Spark –コンテナのリソースを調整
•メモリ設定詳細• ~ Spark 1.5
51
パラメタ名 デフォルト値 推奨値
spark.storage.memoryFraction 0.6 0.2
spark.shuffle.memoryFraction 0.2 0.6
spark.storage.unrollFraction 0.2 0.2
http://spark.apache.org/docs/1.6.0/configuration.html
http://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-2/

/ 103
Hive on Spark –コンテナのリソースを調整
•メモリ設定詳細• Spark 1.6 ~
52
パラメタ名 デフォルト値 推奨値
spark.memory.fraction 0.75 未検証
spark.memory.storageFraction 0.5 未検証
spark.memory.offHeap.enabled true 未検証
spark.memory.offHeap.size 0 未検証
http://spark.apache.org/docs/1.6.0/configuration.html

/ 103
Hive on Spark –コンテナのリソースを調整
•動的アロケーション• 処理量に応じて Executor 数を動的に決定する
• Executor 当たりの CPU やメモリ量は別途指定したほうがよい
53
パラメタ名 デフォルト値 推奨値
spark.dynamicAllocation.enabled false true
spark.shuffle.service.enabled false true
spark.dynamicAllocation.maxExecutors infinity (環境依存)
spark.dynamicAllocation.minExecutors 0 0 (idle時にデコミッションさせたい場合)
spark.dynamicAllocation.initialExecutors spark.dynamicAllocation.minExecutors
(環境依存) minExecutorsが0の場合、増やしてあげると初動が早い
spark.executor.instances 使用不可
http://spark.apache.org/docs/latest/job-scheduling.html#dynamic-resource-allocationhttp://spark.apache.org/docs/1.6.0/configuration.html

/ 103
Hive on Spark –パフォーマンスチューニング
•ボトルネックとなる箇所の特定
•コンテナのリソースを調整
•パーティション数(タスク数)を調整
•その他の項目を調整
54

/ 103
Hive on Spark –パーティション数(タスク数)を調整
• Executor を増やしても失敗する例• 1 タスクあたりの処理が大きすぎる
55
Job
Stage 1
Task 1
Task 2
Task 3

/ 103
Hive on Spark –パーティション数(タスク数)を調整
• Executor を増やしても失敗する例• 1 タスクあたりの処理が大きすぎる
• タスク数を増やして、1 タスクあたりの処理を分割する
56
Job
Stage 1
Task 1
Task 2
Task 3
Job
Stage 1
Task 1 Task 2
Task 3 Task 4
Task 5 Task 6
Task 7 Task 8
Task 9 Task 10
Task 11 Task 12

/ 103
Hive on Spark –パーティション数(タスク数)を調整
•主に以下の 2 パターン• タスク数を固定値で指定する
• 1 タスク当たりのデータサイズを指定する
57
パラメタ名 デフォルト値 推奨値
mapreduce.job.reduces 1 (クエリ依存) 10~
hive.exec.reducers.bytes.per.reducer 256,000,000 (256MB) (クエリ依存)デフォルトより小さめが良いかも
https://cwiki.apache.org/confluence/display/Hive/Configuration+Propertieshttps://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml

/ 103
Hive on Spark –パフォーマンスチューニング
•ボトルネックとなる箇所の特定
•コンテナのリソースを調整
•パーティション数(タスク数)を調整
•その他の項目を調整
58

/ 103
Hive on Spark –その他のチューニング項目
•シリアライザ• Spark はディスク/ネットワークの I/O 時に RDD をシリアライズする
• Hive on Spark で主に効くのはシャッフル処理のネットワーク I/O
• デフォルトの JavaSerializer より高速な KryoSerializer推奨
59
パラメタ名 デフォルト値 推奨値
spark.serializer org.apache.spark.serializer. JavaSerializer
org.apache.spark.serializer.KryoSerializer

/ 103
Hive on Spark –その他のチューニング項目
•コネクションタイムアウト• Spark Client の生成に時間がかかり、タイムアウトする場合がある
• 環境に応じてタイムアウトを伸ばす
60
パラメタ名 デフォルト値 推奨値
hive.spark.client.connect.timeout 1000 (ms) (環境依存)デフォルトより長めが良い
hive.spark.client.server.connect.timeout 90000 (ms) (環境依存)

/ 103
Hive on Spark –その他のチューニング項目
•圧縮• シャッフル時のネットワーク I/O が気になる→ 中間データを圧縮
• ファイル出力時のディスク I/O が気になる→ 出力データを圧縮
• 圧縮コーデック• Gzipが高速
• BZip2 は圧縮率と Splittableな特性
• その他 Snappy, LZO, LZ4 …
61
パラメタ名 デフォルト値 推奨値
hive.exec.compress.intermediate false (クエリ依存) false / true
hive.exec.compress.output false (クエリ依存) false / true
mapred.output.compression.codec • org.apache.hadoop.io.compress.GzipCodec• org.apache.hadoop.io.compress.BZip2Codec• …

/ 103
Hive on Spark –その他のチューニング項目
•ファイルのマージ• Hive on Spark と Hive on MR ではマージ関連のデフォルト値が異なる
• Hive on Spark ではデフォルトで出力ファイルのマージが効かない
• 細かいファイルが大量に出力され、パフォーマンスの低下を招く場合がある
• ただし、安易にマージを有効化すると、Executor のメモリ量によってはシャッフル時に OutOfMemoryを引き起こす
• マージするファイルサイズも適切に設定したほうがよい
62
パラメタ名 デフォルト値 推奨値
hive.merge.mapfiles true
hive.merge.mapredfiles false
hive.merge.sparkfiles false (クエリ依存)基本的に true
hive.merge.size.per.task 256000000 (クエリ依存)デフォルトより小さめが良いかも
hive.merge.smallfiles.avgsize 16000000 (クエリ依存)

/ 103
Hive on Spark –その他のチューニング項目
•「圧縮 ×ファイルのマージ」の落とし穴
• Hive のファイル圧縮と STORE の種類とマージの関係http://dayafterneet.blogspot.jp/2012/07/hivestore.html
• hive.mergeにおける STORE と圧縮の問題とワークアラウンドhttp://chopl.in/post/2012/11/15/merge-files-problem-in-hive/
• 圧縮とファイルのマージを同時に実現したい場合• 出力形式を TextFileにすると、マージが効かなくなる
63

/ 103
Hive on Spark –その他のチューニング項目
•「圧縮 ×ファイルのマージ」の落とし穴• ファイルのマージは出力結果に対して行われる
• つまり、マージ処理の前に圧縮が行われる
• TextFileのように、ファイル全体が圧縮される場合→ 圧縮ファイルのマージはできない
64
TextFile
圧縮
マージできない

/ 103
SequenceFileSequenceFile
Hive on Spark –その他のチューニング項目
•「圧縮 ×ファイルのマージ」の落とし穴• ファイルのマージは出力結果に対して行われる
• つまり、マージ処理の前に圧縮が行われる
• SequenceFile, RCFile等のように、ファイルの中身が圧縮される場合→ SequenceFile, RCFile自体のマージはできる
65
圧縮
マージできる
SequenceFile
SequenceFile SequenceFile

/ 103
Hive on Spark –まとめ
•導入~運用までのコストが低い• Hive と Spark の経験があれば、他に学習することはほとんどない
•パラメタ一つで高速化• DMM.com の事例では、バッチ処理時間を約3分の1まで短縮
• 必要であれば MapReduce に簡単に切り替えられる
66

/ 103
【補足】 Hive で役に立つ SQL 構文
• WITH句
• CASE式
• LATERAL句 ×テーブル関数
• WINDOW関数
• TABLESAMPLE
67

/ 103
【補足】 Hive で役に立つ SQL 構文
• WITH句
• CASE式
• LATERAL句 ×テーブル関数
• WINDOW関数
• TABLESAMPLE
68

/ 103
【補足】WITH句の活用
•共通表式WITH句• SQL99 で定義
•ジョブ数が多いクエリほど Hive on Spark が効果的• サブクエリのネストが深くなりがち
• WITH でフラット化
• クエリの一部を実行することも容易になる
69

/ 103
【補足】WITH句の活用
•ネストしたクエリは読みにくい(WITH句を使わない場合)
70
http://www.slideshare.net/MarkusWinand/modern-sql
--▽最後の処理SELECT a1, a2, b2, c1, c2FROM (--▽ 2番目の処理
SELECT a1, a2, b2FROM a
JOIN (--▽最初の処理SELECT b1, b2 FROM b
) AS d ON (a.a1 = d.b1)) AS e
JOIN (--▽ 3番目の処理
SELECT c1, c2 FROM c) AS f ON (e.a2 = f.c1);

/ 103
【補足】WITH句の活用
•ネストしたクエリは読みにくい(WITH句を使わない場合)
71
http://www.slideshare.net/MarkusWinand/modern-sql
--▽最後の処理SELECT a1, a2, b2, c1, c2FROM (--▽ 2番目の処理
SELECT a1, a2, b2FROM a
JOIN (--▽最初の処理SELECT b1, b2 FROM b
) AS d ON (a.a1 = d.b1)) AS e
JOIN (--▽ 3番目の処理
SELECT c1, c2 FROM c) AS f ON (e.a2 = f.c1);

/ 103
【補足】WITH句の活用
•ネストしたクエリは読みにくい(WITH句を使わない場合)
72
http://www.slideshare.net/MarkusWinand/modern-sql
--▽最後の処理SELECT a1, a2, b2, c1, c2FROM (--▽ 2番目の処理
SELECT a1, a2, b2FROM a
JOIN (--▽最初の処理SELECT b1, b2 FROM b
) AS d ON (a.a1 = d.b1)) AS e
JOIN (--▽ 3番目の処理
SELECT c1, c2 FROM c) AS f ON (e.a2 = f.c1);

/ 103
【補足】WITH句の活用
•ネストしたクエリは読みにくい(WITH句を使わない場合)
73
http://www.slideshare.net/MarkusWinand/modern-sql
--▽最後の処理SELECT a1, a2, b2, c1, c2FROM (--▽ 2番目の処理
SELECT a1, a2, b2FROM a
JOIN (--▽最初の処理SELECT b1, b2 FROM b
) AS d ON (a.a1 = d.b1)) AS e
JOIN (--▽ 3番目の処理
SELECT c1, c2 FROM c) AS f ON (e.a2 = f.c1);

/ 103
【補足】WITH句の活用
•ネストしたクエリは読みにくい(WITH句を使わない場合)
74
http://www.slideshare.net/MarkusWinand/modern-sql
--▽最後の処理SELECT a1, a2, b2, c1, c2FROM (--▽ 2番目の処理
SELECT a1, a2, b2FROM a
JOIN (--▽最初の処理SELECT b1, b2 FROM b
) AS d ON (a.a1 = d.b1)) AS e
JOIN (--▽ 3番目の処理
SELECT c1, c2 FROM c) AS f ON (e.a2 = f.c1);

/ 103
【補足】WITH句の活用
• WITH句を使って書き換え
75
--▽最後の処理SELECT a1, a2, b2, c1, c2FROM (--▽ 2番目の処理
SELECT a1, a2, b2FROM a
JOIN (--▽最初の処理SELECT b1, b2 FROM b
) AS d ON (a.a1 = d.b1)) AS e
JOIN (--▽ 3番目の処理
SELECT c1, c2 FROM c) AS f ON (e.a2 = f.c1);
http://www.slideshare.net/MarkusWinand/modern-sql
WITH--▽最初の処理d AS ( SELECT b1, b2 FROM b ),--▽ 2番目の処理e AS (
SELECT a1, a2, b2FROM a JOIN d ON (a.a1 = d.b1)
),--▽ 3番目の処理f AS ( SELECT c1, c2 FROM c )--▽最後の処理SELECT a1, a2, b2, c1, c2FROM eJOIN f ON (e.a2 = f.c1);

/ 103
【補足】WITH句の活用
• WITH句を使って書き換え
76
--▽最後の処理SELECT a1, a2, b2, c1, c2FROM (--▽ 2番目の処理
SELECT a1, a2, b2FROM a
JOIN (--▽最初の処理SELECT b1, b2 FROM b
) AS d ON (a.a1 = d.b1)) AS e
JOIN (--▽ 3番目の処理
SELECT c1, c2 FROM c) AS f ON (e.a2 = f.c1);
http://www.slideshare.net/MarkusWinand/modern-sql
WITH--▽最初の処理d AS ( SELECT b1, b2 FROM b ),--▽ 2番目の処理e AS (
SELECT a1, a2, b2FROM a JOIN d ON (a.a1 = d.b1)
),--▽ 3番目の処理f AS ( SELECT c1, c2 FROM c )--▽最後の処理SELECT a1, a2, b2, c1, c2FROM eJOIN f ON (e.a2 = f.c1);

/ 103
【補足】WITH句の活用
• WITH句を使って書き換え
77
--▽最後の処理SELECT a1, a2, b2, c1, c2FROM (--▽ 2番目の処理
SELECT a1, a2, b2FROM a
JOIN (--▽最初の処理SELECT b1, b2 FROM b
) AS d ON (a.a1 = d.b1)) AS e
JOIN (--▽ 3番目の処理
SELECT c1, c2 FROM c) AS f ON (e.a2 = f.c1);
http://www.slideshare.net/MarkusWinand/modern-sql
WITH--▽最初の処理d AS ( SELECT b1, b2 FROM b ),--▽ 2番目の処理e AS (
SELECT a1, a2, b2FROM a JOIN d ON (a.a1 = d.b1)
),--▽ 3番目の処理f AS ( SELECT c1, c2 FROM c )--▽最後の処理SELECT a1, a2, b2, c1, c2FROM eJOIN f ON (e.a2 = f.c1);

/ 103
【補足】WITH句の活用
• WITH句を使って書き換え
78
--▽最後の処理SELECT a1, a2, b2, c1, c2FROM (--▽ 2番目の処理
SELECT a1, a2, b2FROM a
JOIN (--▽最初の処理SELECT b1, b2 FROM b
) AS d ON (a.a1 = d.b1)) AS e
JOIN (--▽ 3番目の処理
SELECT c1, c2 FROM c) AS f ON (e.a2 = f.c1);
http://www.slideshare.net/MarkusWinand/modern-sql
WITH--▽最初の処理d AS ( SELECT b1, b2 FROM b ),--▽ 2番目の処理e AS (
SELECT a1, a2, b2FROM a JOIN d ON (a.a1 = d.b1)
),--▽ 3番目の処理f AS ( SELECT c1, c2 FROM c )--▽最後の処理SELECT a1, a2, b2, c1, c2FROM eJOIN f ON (e.a2 = f.c1);

/ 103
【補足】WITH句の活用
• WITH句を使って書き換え
79
--▽最後の処理SELECT a1, a2, b2, c1, c2FROM (--▽ 2番目の処理
SELECT a1, a2, b2FROM a
JOIN (--▽最初の処理SELECT b1, b2 FROM b
) AS d ON (a.a1 = d.b1)) AS e
JOIN (--▽ 3番目の処理
SELECT c1, c2 FROM c) AS f ON (e.a2 = f.c1);
http://www.slideshare.net/MarkusWinand/modern-sql
WITH--▽最初の処理d AS ( SELECT b1, b2 FROM b ),--▽ 2番目の処理e AS (
SELECT a1, a2, b2FROM a JOIN d ON (a.a1 = d.b1)
),--▽ 3番目の処理f AS ( SELECT c1, c2 FROM c )--▽最後の処理SELECT a1, a2, b2, c1, c2FROM eJOIN f ON (e.a2 = f.c1);

/ 103
【補足】 Hive で役に立つ SQL 構文
• WITH句
• CASE式
• LATERAL句 ×テーブル関数
• WINDOW関数
• TABLESAMPLE
80

/ 103
【補足】 CASE式の活用
• CASE式• SQL92 で定義
•条件に従って値を返す式
• Spark でボトルネックとなりやすい箇所はディスクI/O
•テーブル走査の回数は可能な限り減らしたい• UNION ALL や LEFT OUTER JOIN を CASE式で書き換え
•行持ちのデータを列持ちに変換できる
81

/ 103
【補足】 CASE式の活用
•例:CTR, CVR の集計(CASE式を使わない場合)
82
WITHaction_log AS( SELECT '2016-02-01' AS dt, 'view' AS actionUNION ALL SELECT '2016-02-01' AS dt, 'view' AS actionUNION ALL SELECT '2016-02-01' AS dt, 'view' AS actionUNION ALL SELECT '2016-02-01' AS dt, 'click' AS actionUNION ALL SELECT '2016-02-01' AS dt, 'click' AS actionUNION ALL SELECT '2016-02-01' AS dt, 'purchase' AS actionUNION ALL SELECT '2016-02-02' AS dt, 'view' AS actionUNION ALL SELECT '2016-02-02' AS dt, 'view' AS action
),t1 AS (SELECT dt, action, COUNT(*) AS ct FROM action_log GROUP BY dt, action
)SELECTv.dt, COALESCE(c.ct / v.ct, 0.0) AS ctr, COALESCE(p.ct / c.ct, 0.0) AS cvr
FROM t1 AS vLEFT OUTER JOIN t1 AS c ON v.dt = c.dt AND c.action = 'click'LEFT OUTER JOIN t1 AS p ON v.dt = p.dt AND p.action = 'purchase'
WHERE v.action = 'view';
dt action
2016-02-01 view
2016-02-01 view
2016-02-01 view
2016-02-01 click
2016-02-01 click
2016-02-01 purchase
2016-02-02 view
2016-02-02 view
action_log

/ 103
【補足】 CASE式の活用
•例:CTR, CVR の集計(CASE式を使わない場合)
83
WITHaction_log AS( SELECT '2016-02-01' AS dt, 'view' AS actionUNION ALL SELECT '2016-02-01' AS dt, 'view' AS actionUNION ALL SELECT '2016-02-01' AS dt, 'view' AS actionUNION ALL SELECT '2016-02-01' AS dt, 'click' AS actionUNION ALL SELECT '2016-02-01' AS dt, 'click' AS actionUNION ALL SELECT '2016-02-01' AS dt, 'purchase' AS actionUNION ALL SELECT '2016-02-02' AS dt, 'view' AS actionUNION ALL SELECT '2016-02-02' AS dt, 'view' AS action
),t1 AS (SELECT dt, action, COUNT(*) AS ct FROM action_log GROUP BY dt, action
)SELECTv.dt, COALESCE(c.ct / v.ct, 0.0) AS ctr, COALESCE(p.ct / c.ct, 0.0) AS cvr
FROM t1 AS vLEFT OUTER JOIN t1 AS c ON v.dt = c.dt AND c.action = 'click'LEFT OUTER JOIN t1 AS p ON v.dt = p.dt AND p.action = 'purchase'
WHERE v.action = 'view';
dt action ct
2016-02-01 view 3
2016-02-01 click 2
2016-02-01 purchase 1
2016-02-02 view 2
t1

/ 103
【補足】 CASE式の活用
•例:CTR, CVR の集計(CASE式を使わない場合)
84
WITHaction_log AS( SELECT '2016-02-01' AS dt, 'view' AS actionUNION ALL SELECT '2016-02-01' AS dt, 'view' AS actionUNION ALL SELECT '2016-02-01' AS dt, 'view' AS actionUNION ALL SELECT '2016-02-01' AS dt, 'click' AS actionUNION ALL SELECT '2016-02-01' AS dt, 'click' AS actionUNION ALL SELECT '2016-02-01' AS dt, 'purchase' AS actionUNION ALL SELECT '2016-02-02' AS dt, 'view' AS actionUNION ALL SELECT '2016-02-02' AS dt, 'view' AS action
),t1 AS (SELECT dt, action, COUNT(*) AS ct FROM action_log GROUP BY dt, action
)SELECTv.dt, COALESCE(c.ct / v.ct, 0.0) AS ctr, COALESCE(p.ct / c.ct, 0.0) AS cvr
FROM t1 AS vLEFT OUTER JOIN t1 AS c ON v.dt = c.dt AND c.action = 'click'LEFT OUTER JOIN t1 AS p ON v.dt = p.dt AND p.action = 'purchase'
WHERE v.action = 'view';
dt ctr cvr
2016-02-01 0.666 0.5
2016-02-02 0 0

/ 103
【補足】 CASE式の活用
•例:CTR, CVR の集計(CASE式を使った場合)
85
t1 AS (SELECT
dt, SUM(CASE action WHEN 'view' THEN 1 END) AS view_ct, SUM(CASE action WHEN 'click' THEN 1 END) AS click_ct, SUM(CASE action WHEN 'purchase' THEN 1 END) AS purchase_ct
FROM action_logGROUP BY dt
)SELECT
dt, COALESCE( click_ct / view_ct, 0.0) AS ctr, COALESCE( purchase_ct / click_ct, 0.0) AS cvr
FROM t1;
dt CASE view CASE click CASE purchase
2016-02-01 1 NULL NULL
2016-02-01 1 NULL NULL
2016-02-01 1 NULL NULL
2016-02-01 NULL 1 NULL
2016-02-01 NULL 1 NULL
2016-02-01 NULL NULL 1
2016-02-02 1 NULL NULL
2016-02-02 1 NULL NULL

/ 103
【補足】 CASE式の活用
•例:CTR, CVR の集計(CASE式を使った場合)
86
t1 AS (SELECT
dt, SUM(CASE action WHEN 'view' THEN 1 END) AS view_ct, SUM(CASE action WHEN 'click' THEN 1 END) AS click_ct, SUM(CASE action WHEN 'purchase' THEN 1 END) AS purchase_ct
FROM action_logGROUP BY dt
)SELECT
dt, COALESCE( click_ct / view_ct, 0.0) AS ctr, COALESCE( purchase_ct / click_ct, 0.0) AS cvr
FROM t1;
dt view_ct click_ct purchase_ct
2016-02-01 3 2 1
2016-02-02 2 NULL NULL
t1

/ 103
【補足】 CASE式の活用
•例:CTR, CVR の集計(CASE式を使った場合)
87
t1 AS (SELECT
dt, SUM(CASE action WHEN 'view' THEN 1 END) AS view_ct, SUM(CASE action WHEN 'click' THEN 1 END) AS click_ct, SUM(CASE action WHEN 'purchase' THEN 1 END) AS purchase_ct
FROM action_logGROUP BY dt
)SELECT
dt, COALESCE( click_ct / view_ct, 0.0) AS ctr, COALESCE( purchase_ct / click_ct, 0.0) AS cvr
FROM t1;
dt ctr cvr
2016-02-01 0.666 0.5
2016-02-02 0 0

/ 103
【補足】 Hive で役に立つ SQL 構文
• WITH句
• CASE式
• LATERAL句 ×テーブル関数
• WINDOW関数
• TABLESAMPLE
88

/ 103
【補足】 LATERAL句 ×テーブル関数の活用
• LATERAL句• SQL99 で定義
• FROM の中で、あるサブクエリやテーブル関数の内側から、外側のリレーションの列を参照する
• NestLoop Join のようなことが実現できる※
• HiveQLでは LATERAL VIEW として実装
•列持ちのデータを行持ちに変換できる
89
※) http://lets.postgresql.jp/documents/technical/lateral/1

/ 103
【補足】 LATERAL句 ×テーブル関数の活用
• explode関数• テーブル (rows) を返す関数
•配列や MAP を行に展開する
90
SELECT ARRAY(1, 2, 3);SELECT EXPLODE(ARRAY(1, 2, 3));
col
1
2
3
SELECT MAP('a', 1, 'b', 2, 'c', 3);SELECT EXPLODE(MAP('a', 1, 'b', 2, 'c', 3));
key Value
a 1
b 2
c 3
_c0
{"a":1,"b":2,"c":3}
_c0
[1,2,3]

/ 103
【補足】 LATERAL句 ×テーブル関数の活用
•ただし、以下のような書き方はできない• explode関数はテーブルを返すため
91
WITHt1 AS (
SELECT'2016-02-08' AS dt
, MAP('CTR', 0.03, 'CVR', 0.01, 'I2C', 0.0003) AS indicators)SELECT
dt, EXPLODE(indicators)
FROM t1;
t1.dt key value
2016-02-08 CTR 0.03
2016-02-08 CVR 0.01
2016-02-08 I2C 0.0003
dt indicators
2016-02-08 {"CTR":0.03,"CVR":0.01,"I2C":3.0E-4}
t1

/ 103
【補足】 LATERAL句 ×テーブル関数の活用
• LATERAL VIEW と組み合わせる• LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)* ※
92
WITHt1 AS (
SELECT'2016-02-08' AS dt
, MAP('CTR', 0.03, 'CVR', 0.01, 'I2C', 0.0003) AS indicators)SELECT
t1.dt, i.key, i.value
FROM t1LATERAL VIEW EXPLODE(indicators) i AS key, value;
t1.dt key value
2016-02-08 CTR 0.03
2016-02-08 CVR 0.01
2016-02-08 I2C 0.0003
dt indicators
2016-02-08 {"CTR":0.03,"CVR":0.01,"I2C":3.0E-4}
t1
※) https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LateralView

/ 103
【補足】 Hive で役に立つ SQL 構文
• WITH句
• CASE式
• LATERAL句 ×テーブル関数
• WINDOW関数
• TABLESAMPLE
93

/ 103
【補足】WINDOW関数の活用
• WINDOW関数(OLAP関数)• SQL:2003 で定義
•コストの高い自己結合を排除
94
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics

/ 103
【補足】WINDOW関数の活用
•例:時系列データの解析
95
WITHaccess_log AS (
SELECT '2016-02-01' AS dt, 'AAA' AS usernameUNION ALL SELECT '2016-02-02' AS dt, 'AAA' AS usernameUNION ALL SELECT '2016-02-03' AS dt, 'AAA' AS usernameUNION ALL SELECT '2016-02-07' AS dt, 'AAA' AS usernameUNION ALL SELECT '2016-02-01' AS dt, 'BBB' AS usernameUNION ALL SELECT '2016-02-03' AS dt, 'BBB' AS usernameUNION ALL SELECT '2016-02-05' AS dt, 'BBB' AS username
)SELECT
dt, username, LAG(dt) OVER(PARTITION BY username ORDER BY dt) AS last_access, DATEDIFF(dt, LAG(dt) OVER(PARTITION BY username ORDER BY dt)) AS access_span, COUNT(1) OVER(PARTITION BY username ORDER BY dt) AS cumulative_access
FROM access_log;
dt username
2016-02-01 AAA
2016-02-02 AAA
2016-02-03 AAA
2016-02-07 AAA
2016-02-01 BBB
2016-02-03 BBB
2016-02-05 BBB

/ 103
【補足】WINDOW関数の活用
•例:時系列データの解析
96
WITHaccess_log AS (
SELECT '2016-02-01' AS dt, 'AAA' AS usernameUNION ALL SELECT '2016-02-02' AS dt, 'AAA' AS usernameUNION ALL SELECT '2016-02-03' AS dt, 'AAA' AS usernameUNION ALL SELECT '2016-02-07' AS dt, 'AAA' AS usernameUNION ALL SELECT '2016-02-01' AS dt, 'BBB' AS usernameUNION ALL SELECT '2016-02-03' AS dt, 'BBB' AS usernameUNION ALL SELECT '2016-02-05' AS dt, 'BBB' AS username
)SELECT
dt, username, LAG(dt) OVER(PARTITION BY username ORDER BY dt) AS last_access, DATEDIFF(dt, LAG(dt) OVER(PARTITION BY username ORDER BY dt)) AS access_span, COUNT(1) OVER(PARTITION BY username ORDER BY dt) AS cumulative_access
FROM access_log;
dt username
last_access
2016-02-01 AAA NULL
2016-02-02 AAA 2016-02-01
2016-02-03 AAA 2016-02-02
2016-02-07 AAA 2016-02-03
2016-02-01 BBB NULL
2016-02-03 BBB 2016-02-01
2016-02-05 BBB 2016-02-03

/ 103
【補足】WINDOW関数の活用
•例:時系列データの解析
97
WITHaccess_log AS (
SELECT '2016-02-01' AS dt, 'AAA' AS usernameUNION ALL SELECT '2016-02-02' AS dt, 'AAA' AS usernameUNION ALL SELECT '2016-02-03' AS dt, 'AAA' AS usernameUNION ALL SELECT '2016-02-07' AS dt, 'AAA' AS usernameUNION ALL SELECT '2016-02-01' AS dt, 'BBB' AS usernameUNION ALL SELECT '2016-02-03' AS dt, 'BBB' AS usernameUNION ALL SELECT '2016-02-05' AS dt, 'BBB' AS username
)SELECT
dt, username, LAG(dt) OVER(PARTITION BY username ORDER BY dt) AS last_access, DATEDIFF(dt, LAG(dt) OVER(PARTITION BY username ORDER BY dt)) AS access_span, COUNT(1) OVER(PARTITION BY username ORDER BY dt) AS cumulative_access
FROM access_log;
dt username
last_access access_span
2016-02-01 AAA NULL NULL
2016-02-02 AAA 2016-02-01 1
2016-02-03 AAA 2016-02-02 1
2016-02-07 AAA 2016-02-03 4
2016-02-01 BBB NULL NULL
2016-02-03 BBB 2016-02-01 2
2016-02-05 BBB 2016-02-03 2

/ 103
【補足】WINDOW関数の活用
•例:時系列データの解析
98
WITHaccess_log AS (
SELECT '2016-02-01' AS dt, 'AAA' AS usernameUNION ALL SELECT '2016-02-02' AS dt, 'AAA' AS usernameUNION ALL SELECT '2016-02-03' AS dt, 'AAA' AS usernameUNION ALL SELECT '2016-02-07' AS dt, 'AAA' AS usernameUNION ALL SELECT '2016-02-01' AS dt, 'BBB' AS usernameUNION ALL SELECT '2016-02-03' AS dt, 'BBB' AS usernameUNION ALL SELECT '2016-02-05' AS dt, 'BBB' AS username
)SELECT
dt, username, LAG(dt) OVER(PARTITION BY username ORDER BY dt) AS last_access, DATEDIFF(dt, LAG(dt) OVER(PARTITION BY username ORDER BY dt)) AS access_span, COUNT(1) OVER(PARTITION BY username ORDER BY dt) AS cumulative_access
FROM access_log;
dt username
last_access access_span
cumulative_acess
2016-02-01 AAA NULL NULL 1
2016-02-02 AAA 2016-02-01 1 2
2016-02-03 AAA 2016-02-02 1 3
2016-02-07 AAA 2016-02-03 4 4
2016-02-01 BBB NULL NULL 1
2016-02-03 BBB 2016-02-01 2 2
2016-02-05 BBB 2016-02-03 2 3

/ 103
【補足】 Hive で役に立つ SQL 構文
• WITH句
• CASE式
• LATERAL句 ×テーブル関数
• WINDOW関数
• TABLESAMPLE
99

/ 103
【補足】 TABLESAMPLE の活用
• TABLESAMPLE• SQL:2003 で定義
•データのサンプリングを行う
•全量データが必要ない場合• 傾向分析等
•少ないデータでクエリを試したい場合
100

/ 103
【補足】 TABLESAMPLE の活用
• BucketedTableの作成• 例:ユーザIDでバケット化
• データの投入• パラメタの設定で自動的にバケット化される
101
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL+BucketedTables
CREATE TABLE access_log_bucketed (user_id BIGINT
, action STRING, product_id STRING
)PARTITIONED BY (dt STRING)CLUSTERED BY (user_id) INTO 256 BUCKETS;
SET hive.enforce.bucketing = true;
FROM access_logINSERT OVERWRITE TABLE access_log_bucketedPARTITION (dt='2016-02-01')SELECT user_id, action, product_idWHERE ds='2016-02-01';

/ 103
【補足】 TABLESAMPLE の活用
• BucketedTableからサンプリング
•ブロックレベルのサンプリング• ※挙動が複雑なのでマニュアル参照
102
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Sampling
SELECT COUNT(1)FROM access_log_bucketedTABLESAMPLE (BUCKET 1 OUT OF 256 ON user_id);
SELECT COUNT(1)FROM access_log_bucketedTABLESAMPLE (BUCKET 1 OUT OF 16 ON user_id);
SELECT COUNT(1)FROM access_log_bucketedTABLESAMPLE (1 PERCENT);
SELECT COUNT(1)FROM access_log_bucketedTABLESAMPLE (10 ROWS);

/ 103
【補足】 Hive で役に立つ SQL 構文
• WITH句
• CASE式
• LATERAL句 ×テーブル関数
• WINDOW関数
• TABLESAMPLE
103