Embed Size (px)
Citation preview

1

Hadoop is a framework for running applications on large clusters built of
commodity hardware. The Hadoop framework transparently provides applications
both reliability and data motion. Hadoop implements a computational paradigm
named Map/Reduce, where the application is divided into many small fragments
of work, each of which may be executed or reexecuted on any node in the cluster.
In addition, it provides a distributed file system (HDFS) that stores data on the
compute nodes, providing very high aggregate bandwidth across the cluster. Both
Map/Reduce and the distributed file system are designed so that node failures are
automatically handled by the framework.
ABSTRACT
2

Problem Statement:
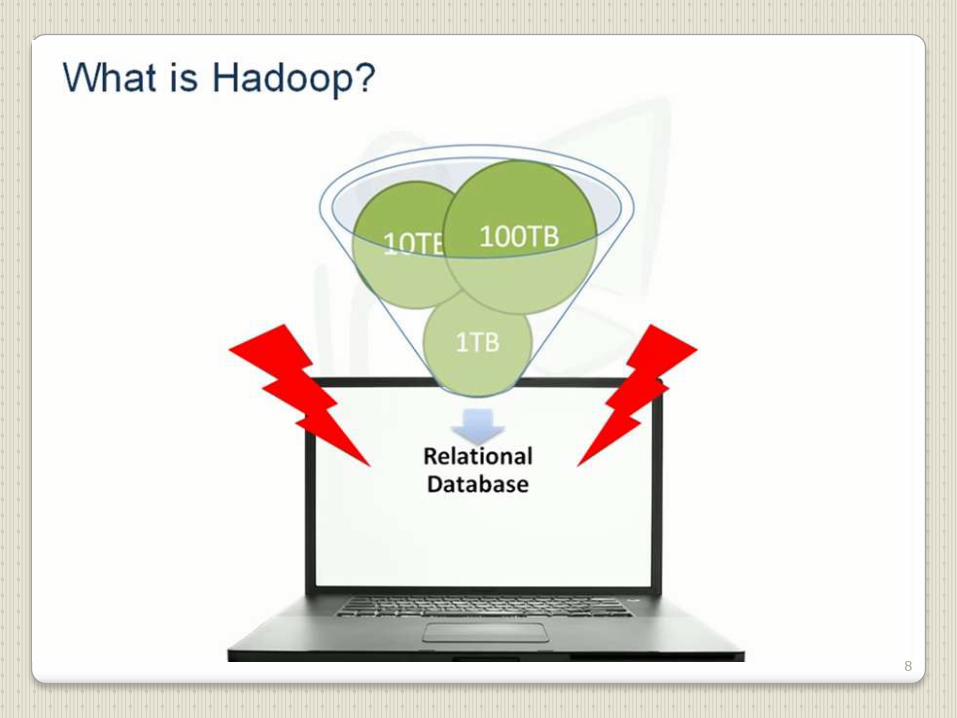
The amount total digital data in the world has exploded in recent years.
This has happened primarily due to information (or data) generated by various
enterprises all over the globe. In 2006, the universal data was estimated to be 0.18
zettabytes in 2006, and is forecasting a tenfold growth by 2011 to 1.8 zettabytes.
The problem is that while the storage capacities of hard drives have
increased massively over the years, access speeds—the rate at which data can be
read from drives have not kept up. One typical drive from 1990 could store 1370
MB of data and had a transfer speed of 4.4 MB/s, so we could read all the data
from a full drive in around 300 seconds. In 2010, 1 Tb drives are the standard
hard disk size, but the transfer speed is around 100 MB/s, so it takes more than
two and a half hours to read all the data off the disk.3

Solution Proposed:
Parallelisation:
A very obvious solution to solving this problem is parallelisation. The
input data is usually large and the computations have to be distributed across
hundreds or thousands of machines in order to finish in a reasonable amount of
time. Reading 1 Tb from a single hard drive may take a long time, but on
parallelizing this over 100 different machines can solve the problem in 2 minutes.
Apache Hadoop is a framework for running applications on large cluster built of
commodity hardware. The Hadoop framework transparently provides applications
both reliability and data motion.
It solves the problem of Hardware Failure through replication.
Redundant copies of the data are kept by the system so that in the event of failure,
there is another copy available. (Hadoop Distributed File System)
The second problem is solved by a simple programming model-
MapReduce. This programming paradigm abstracts the problem from data
read/write to computation over a series of keys. Even though HDFS and
MapReduce are the most significant features of Hadoop. 4
5
6

7
8
9

10

Who Uses Hadoop?
11

12

13
14

Data Everywhere
15

16

17

Examples of Hadoop in action
•In the Telecommunication industry
•In the Media
•In the Technology Industry
18

19

20

21
22

23
24

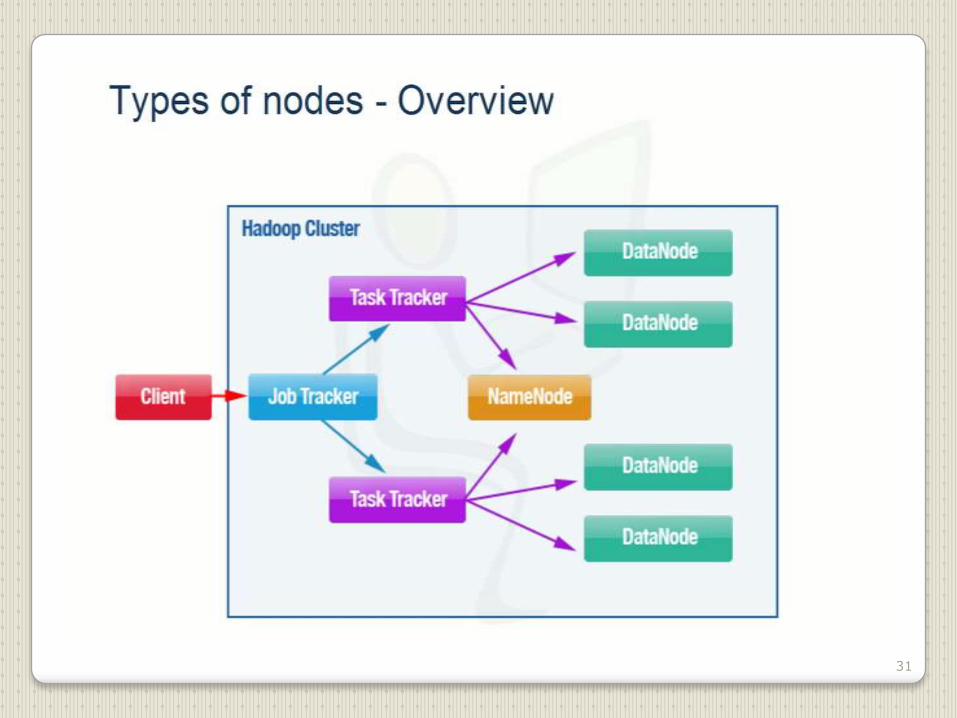
Hadoop Architecture
•Two Main Components :
-Distributed File System
-MapReduce Engine
25

26

27

28

29

30
31
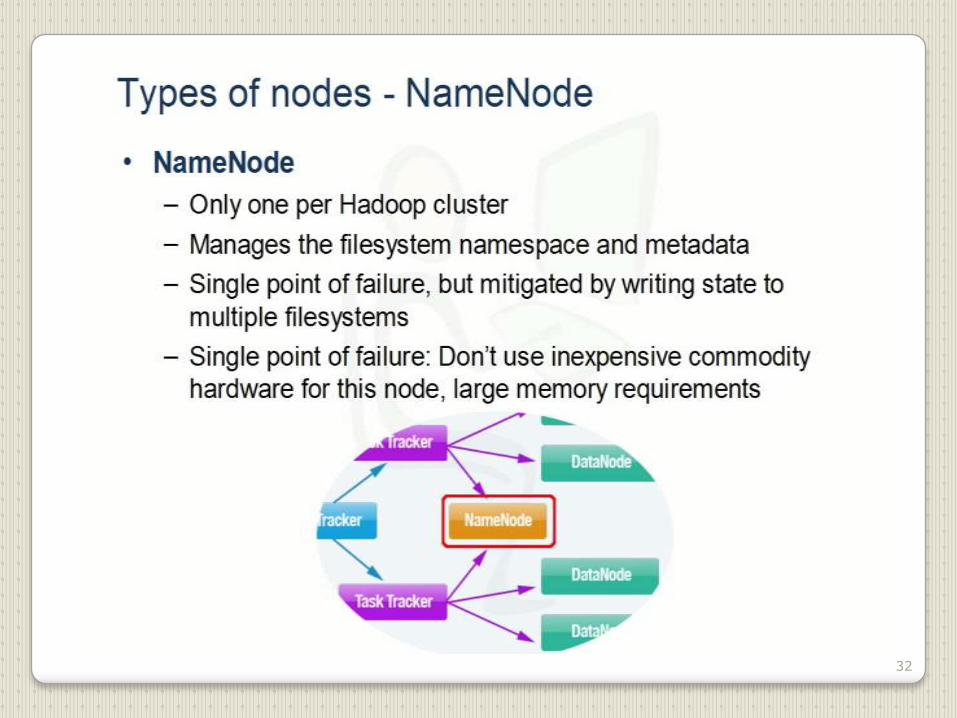
32
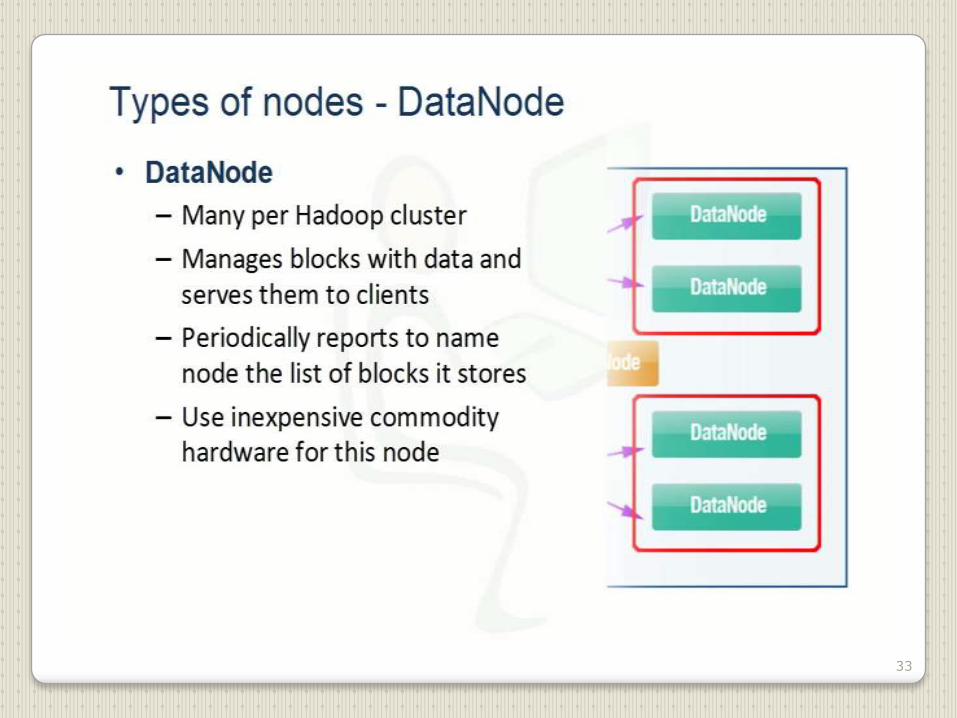
33
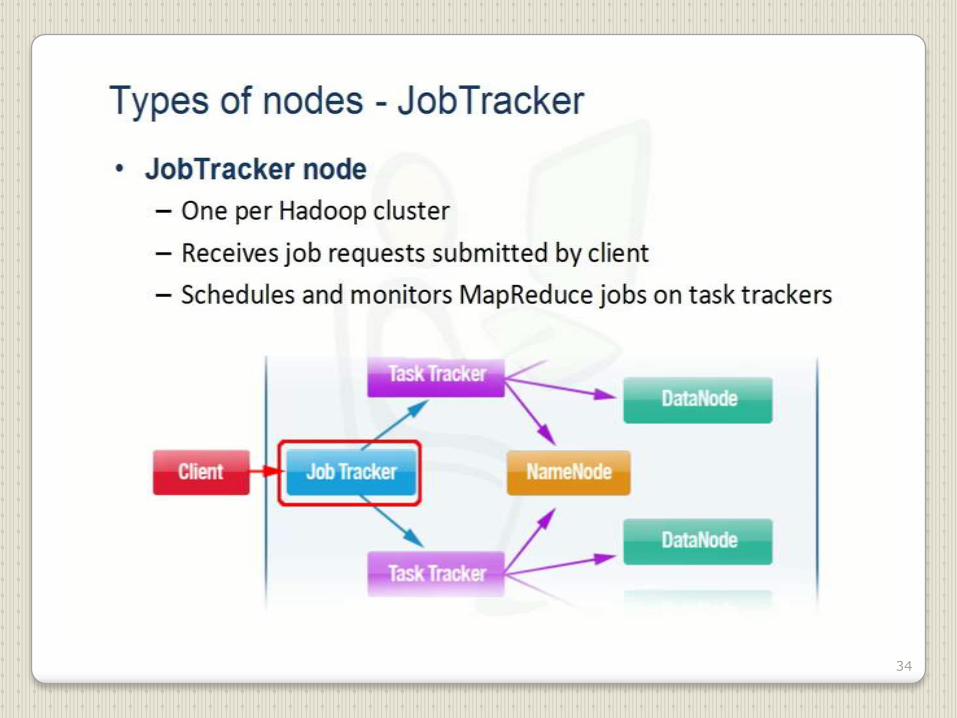
34
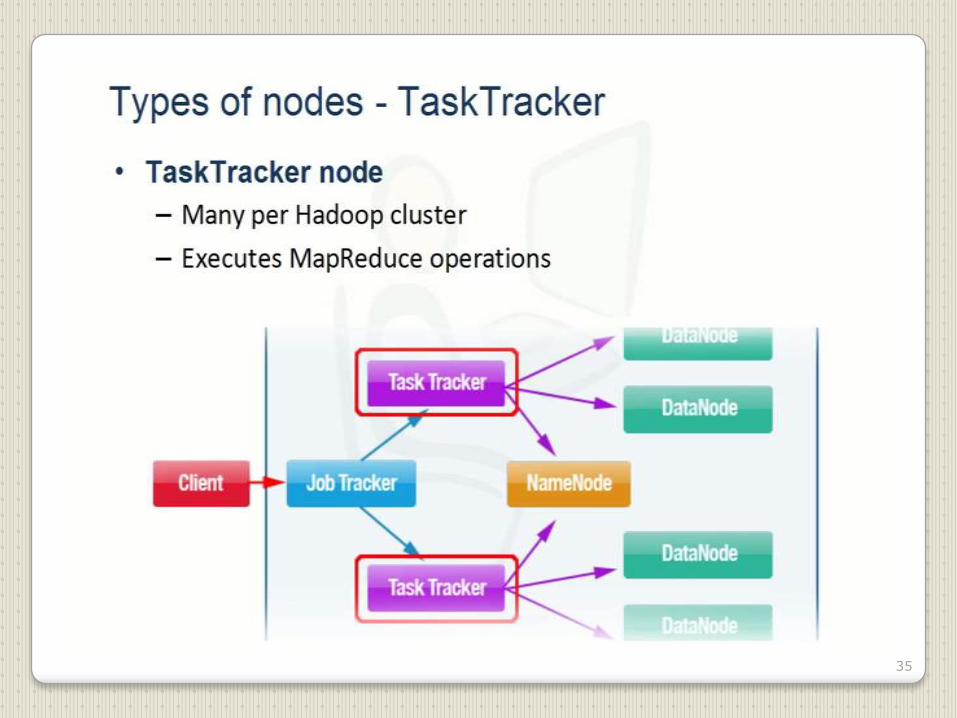
35
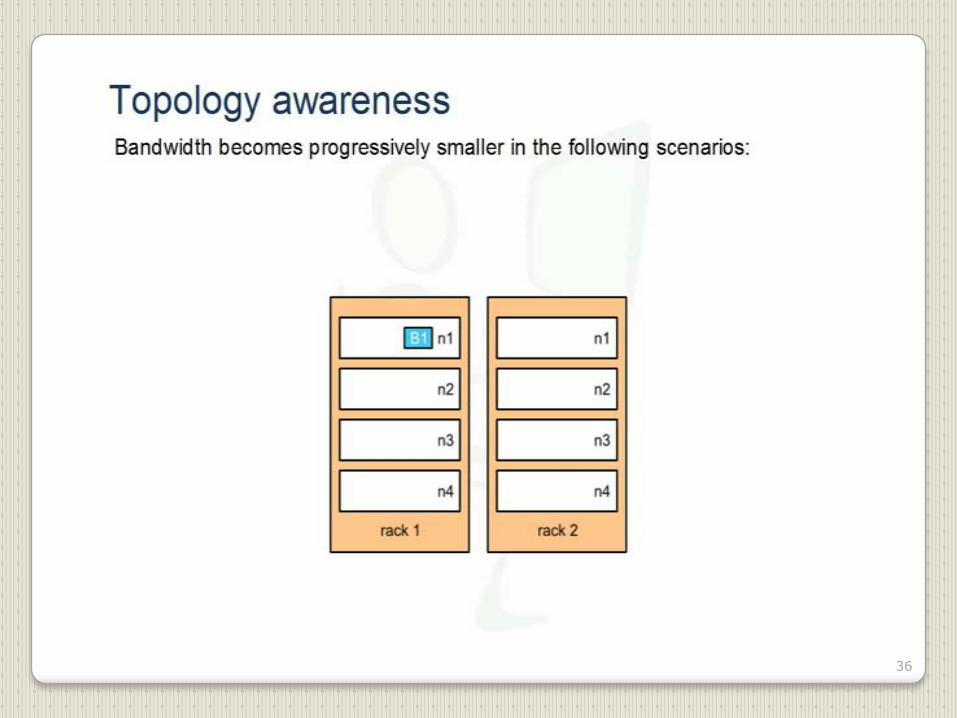
36
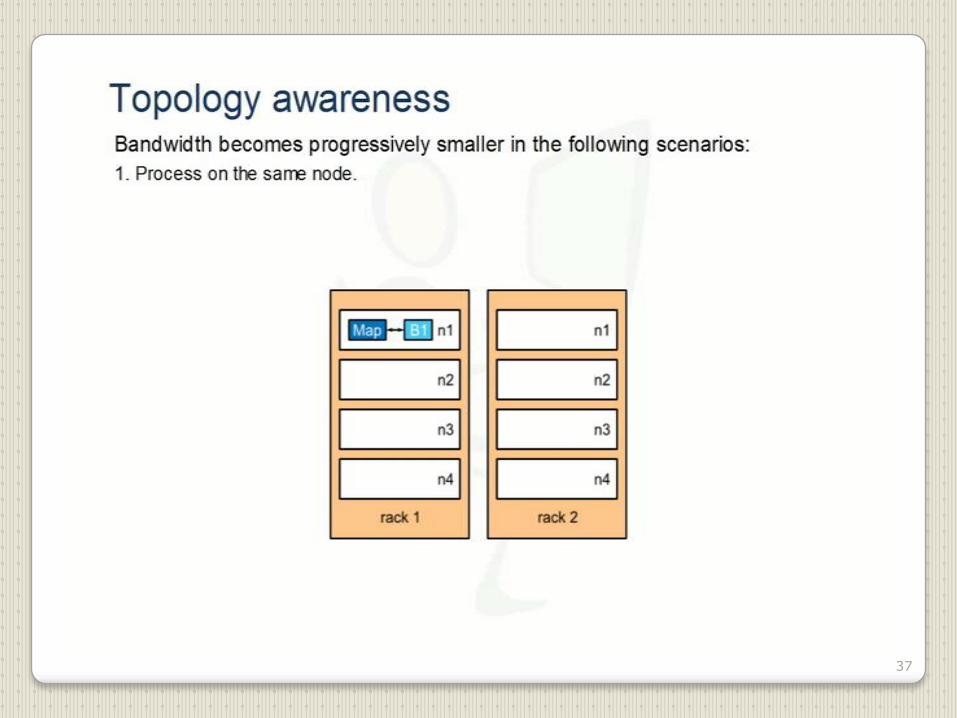
37
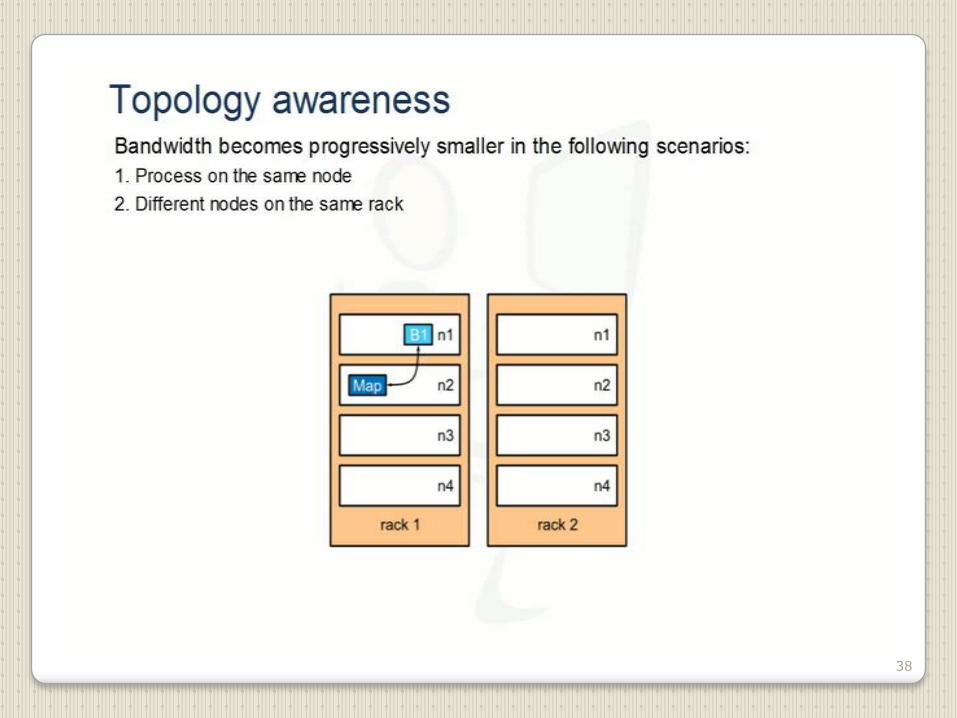
38
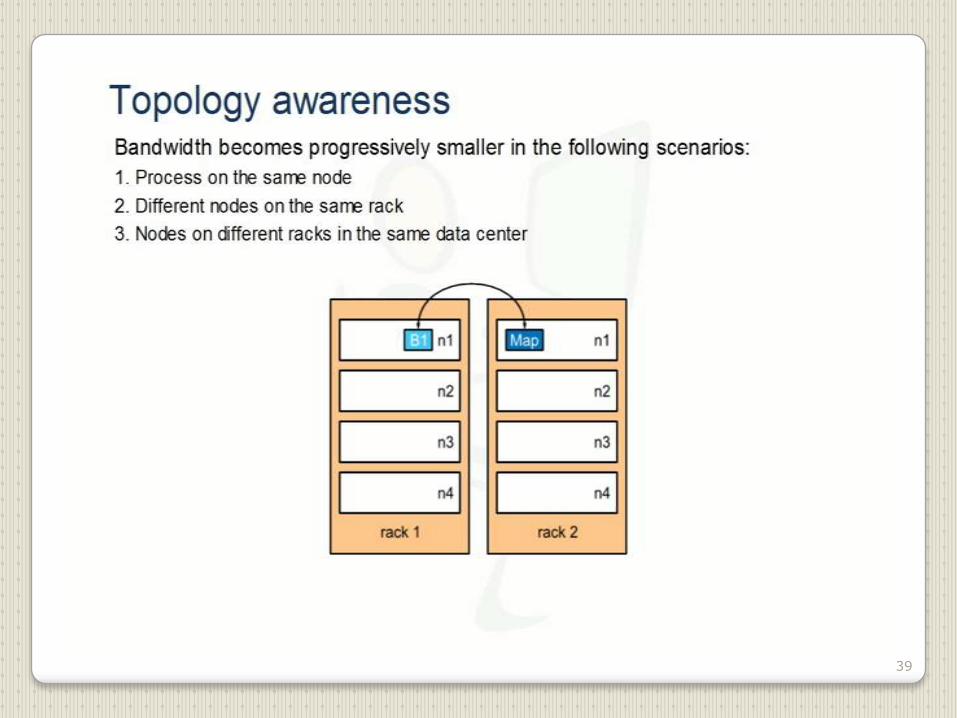
39

40
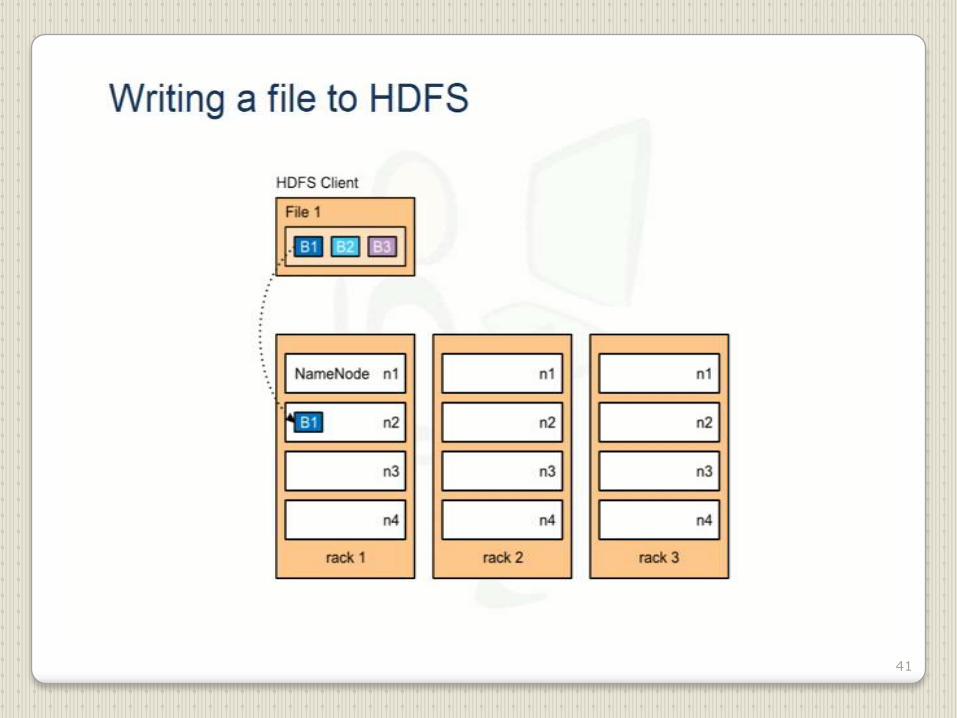
41
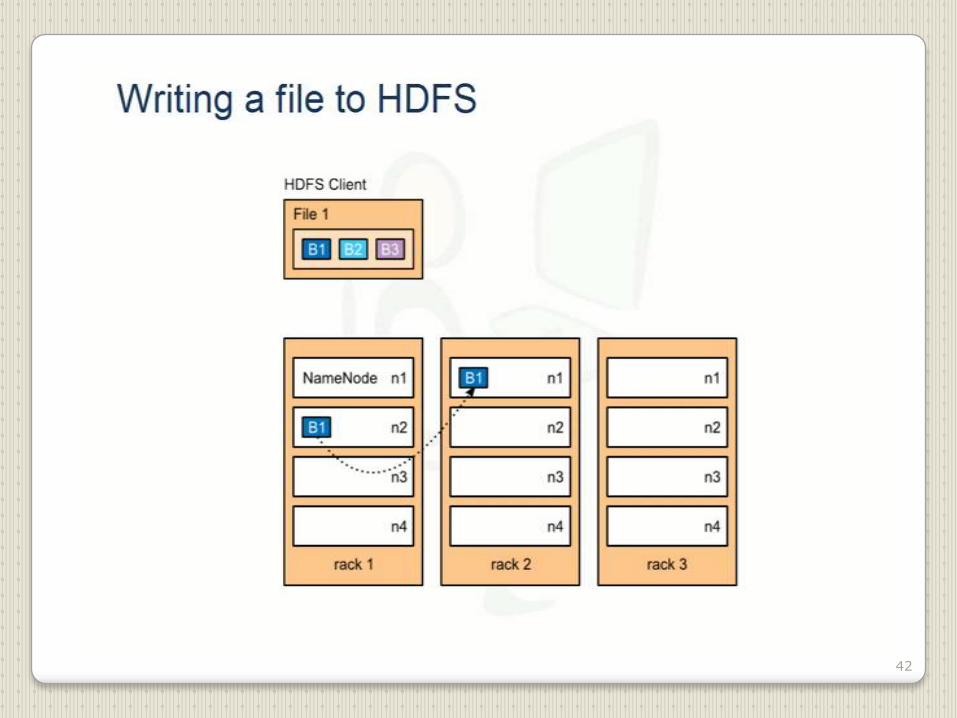
42
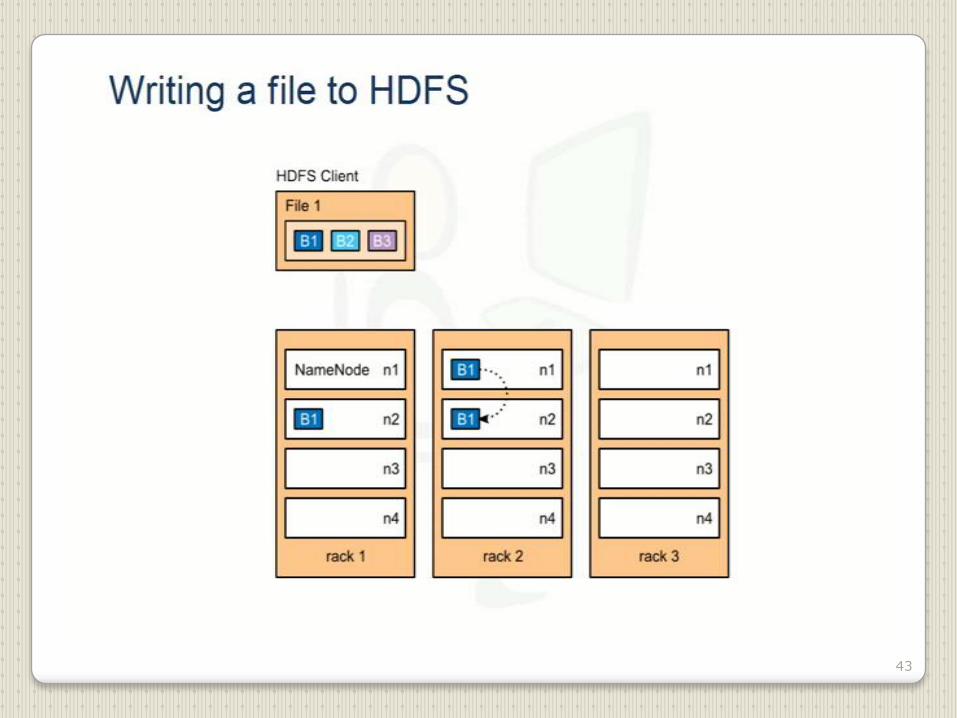
43
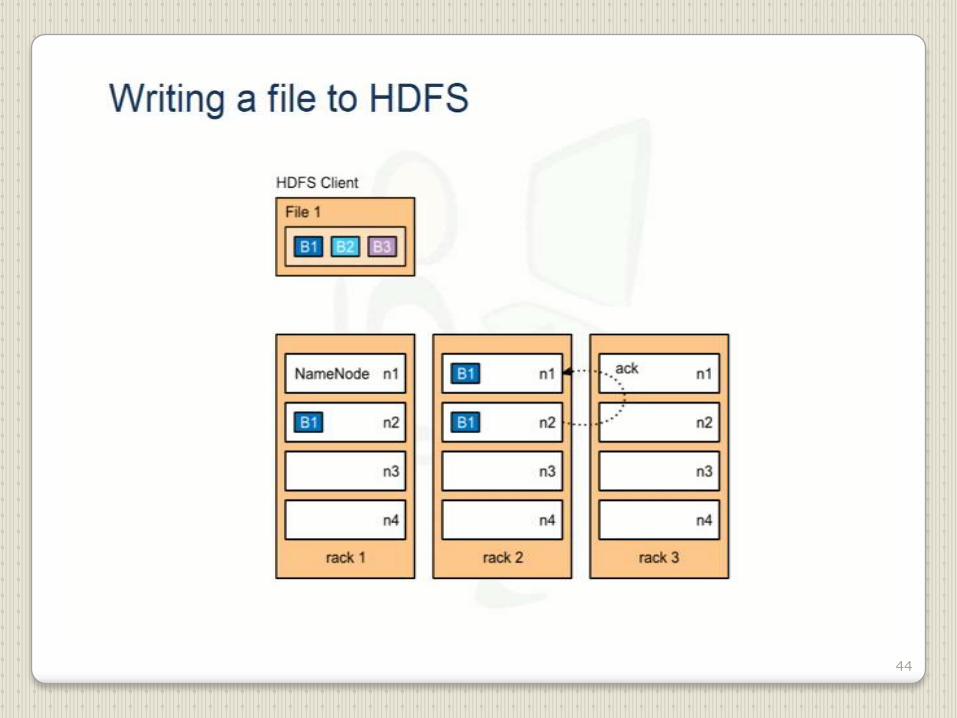
44
45
46
47

48

49

50

51

52

53

54

55

56

57

58

59

60

61
62
63
64
65
66
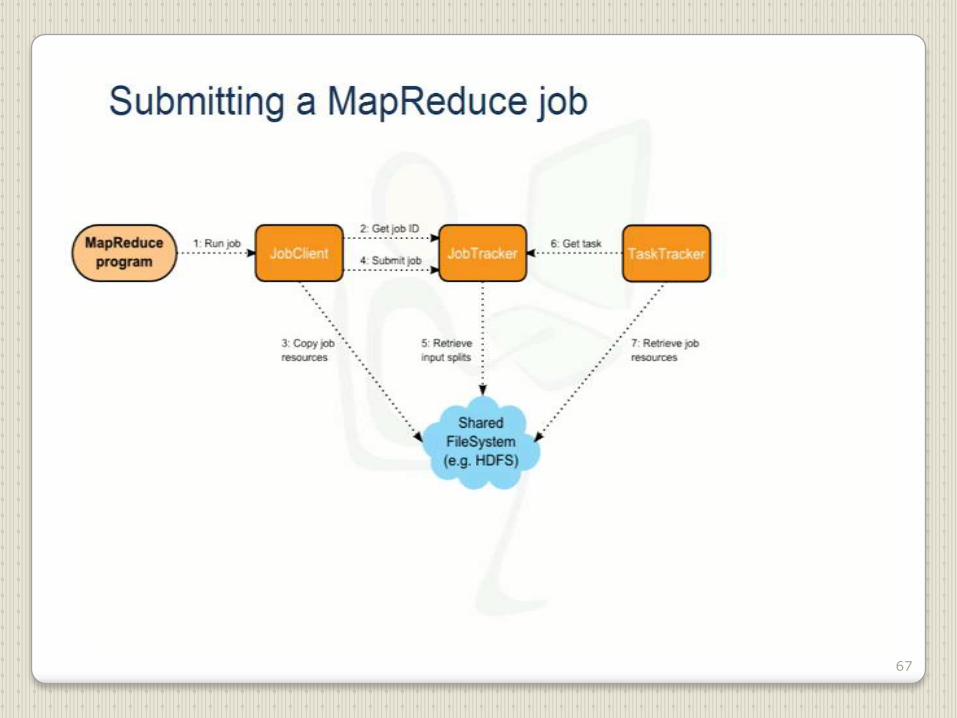
67
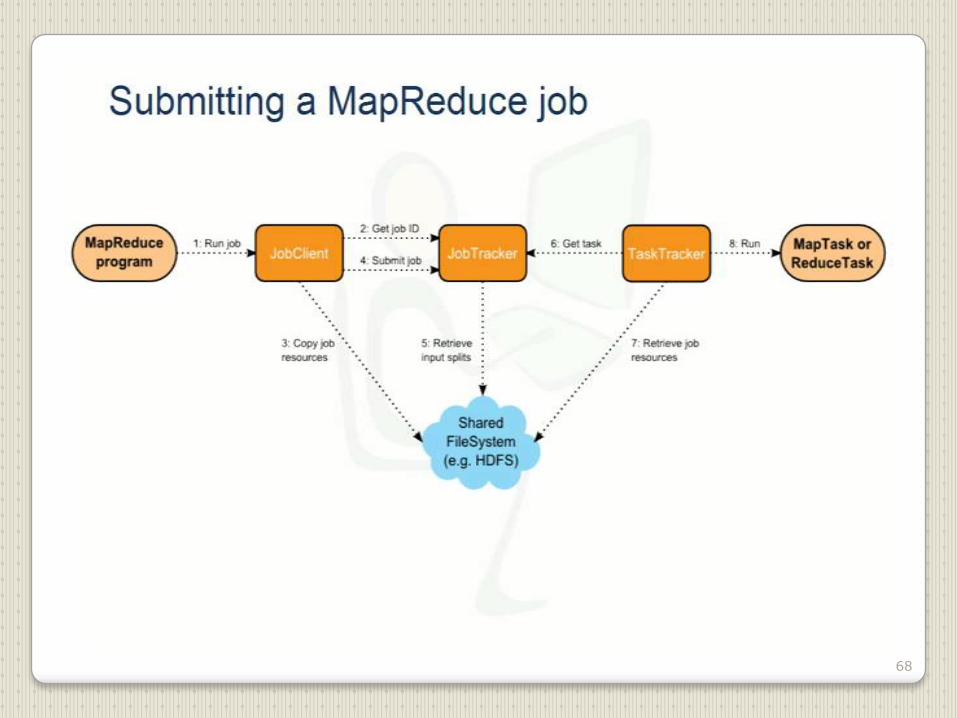
68

69
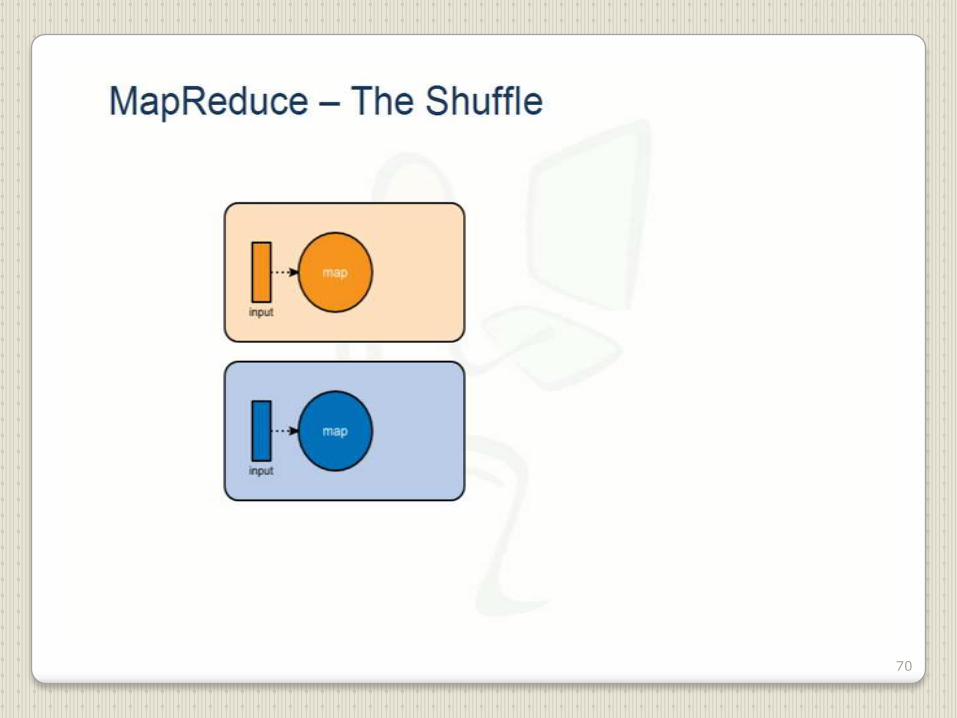
70
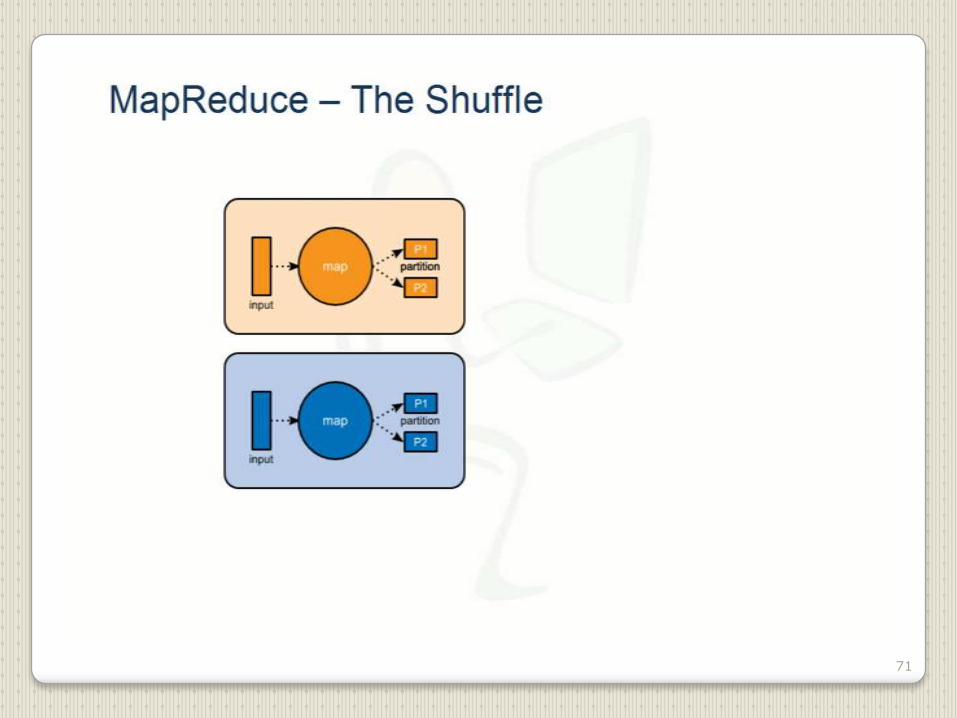
71
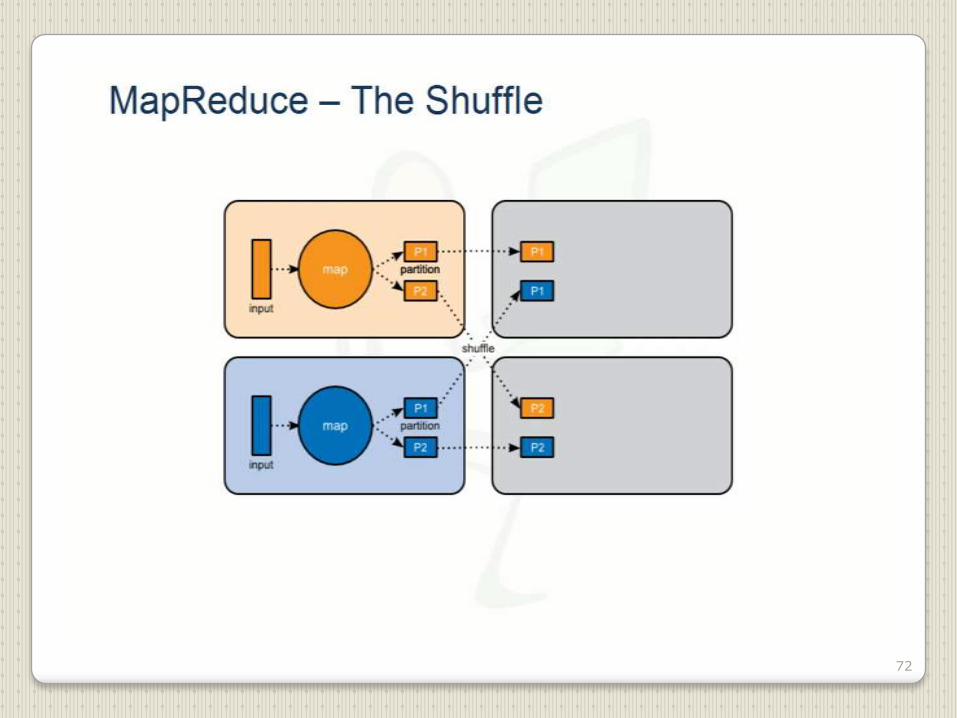
72
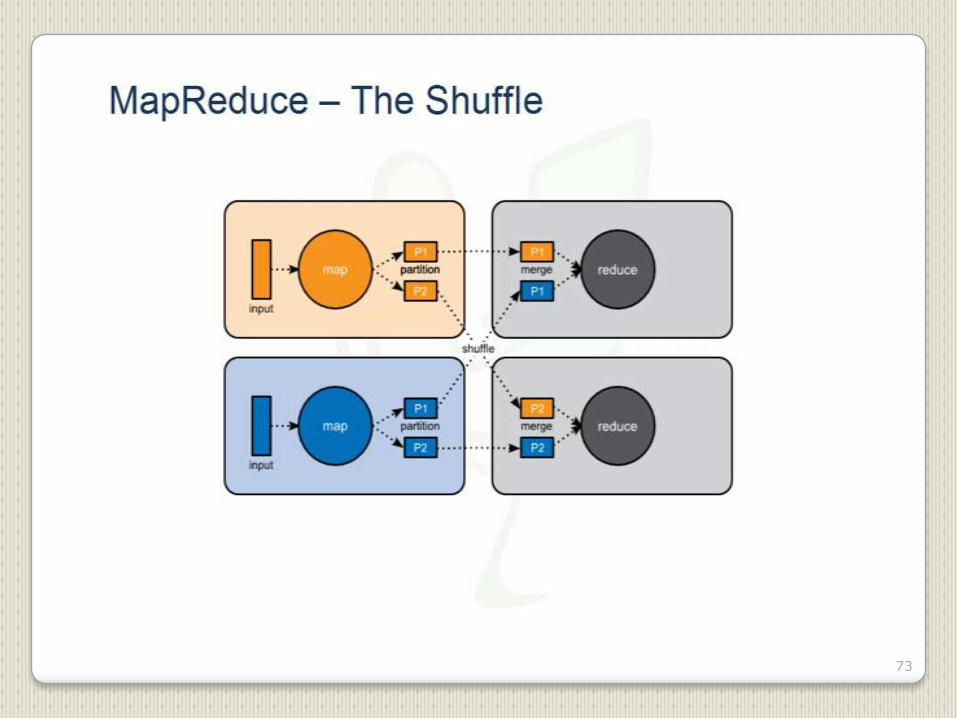
73

74

75

76

77
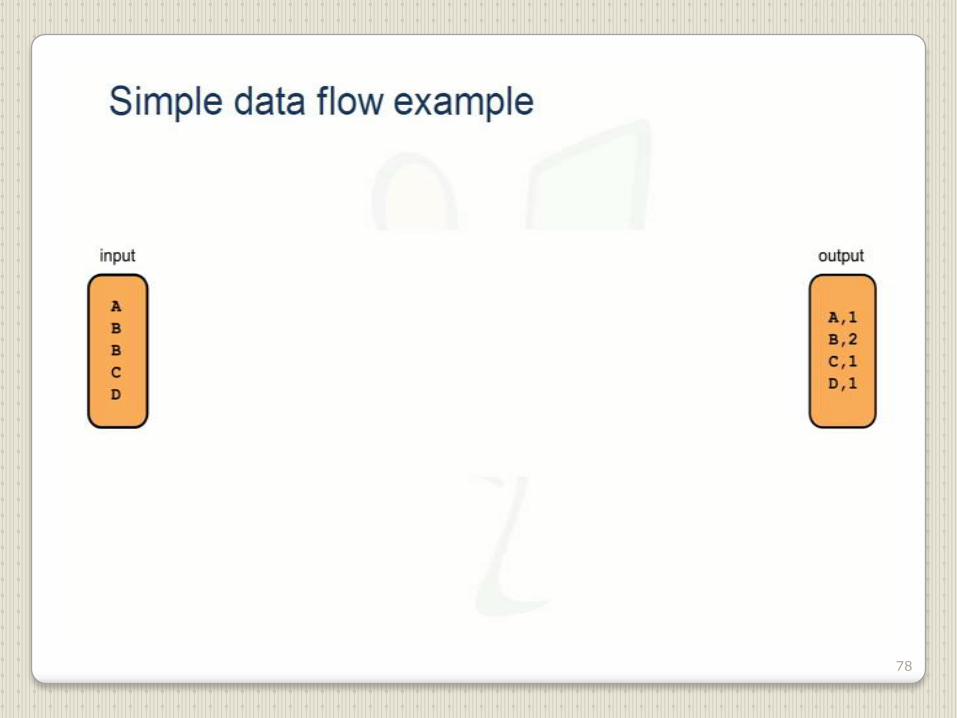
78
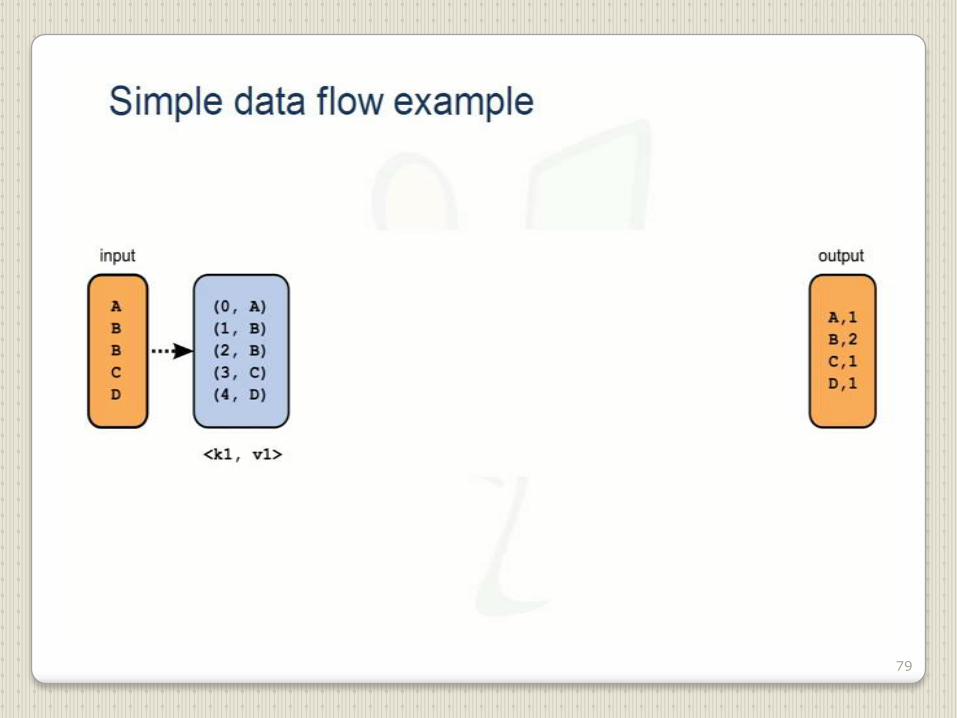
79
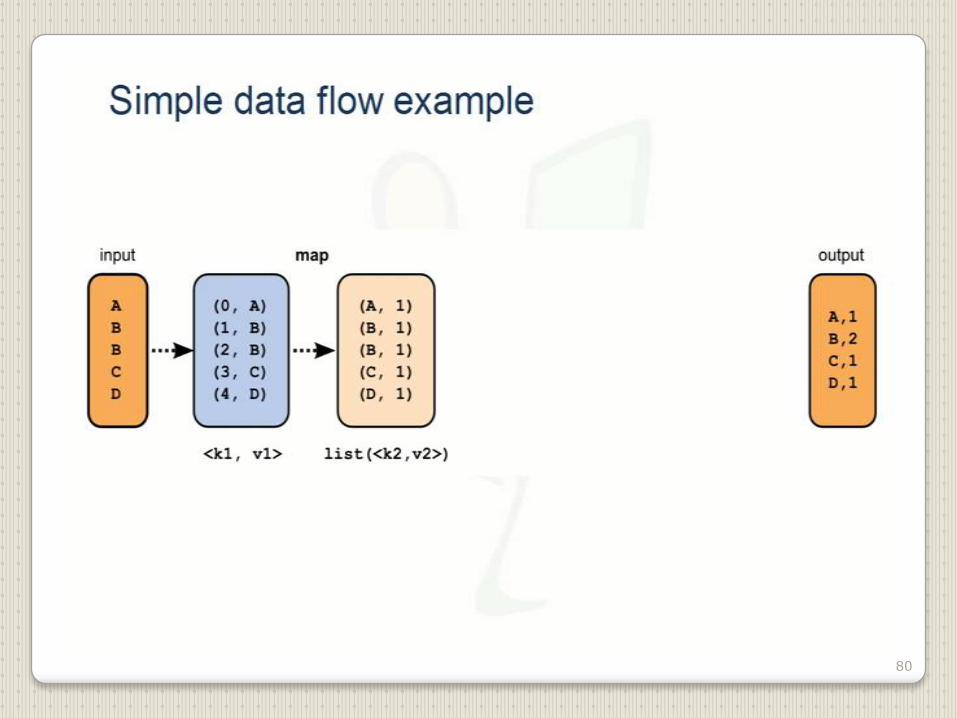
80
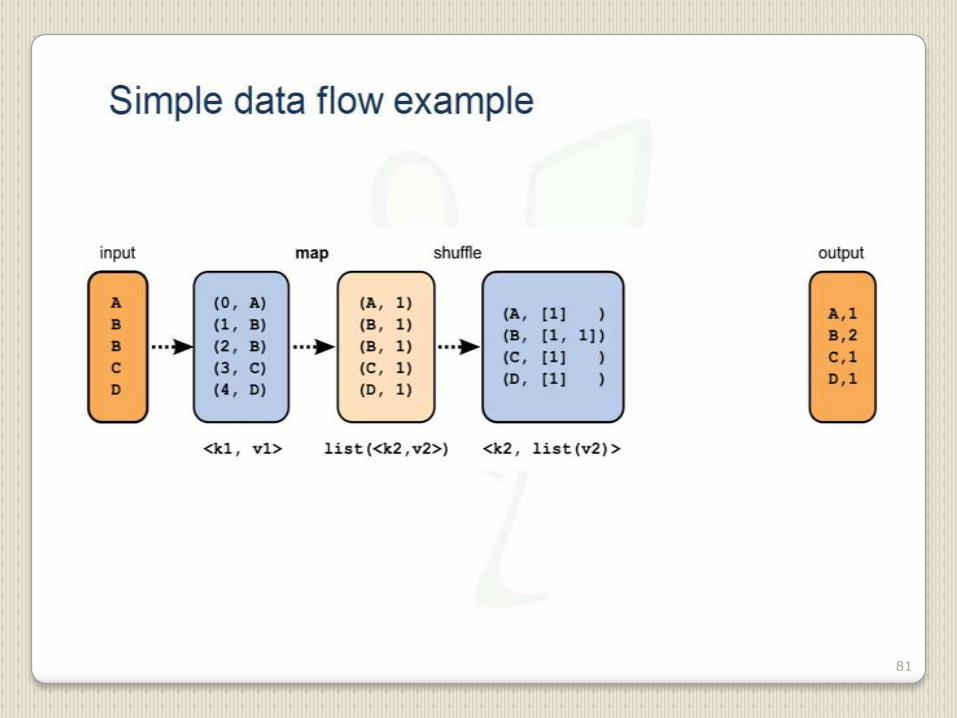
81
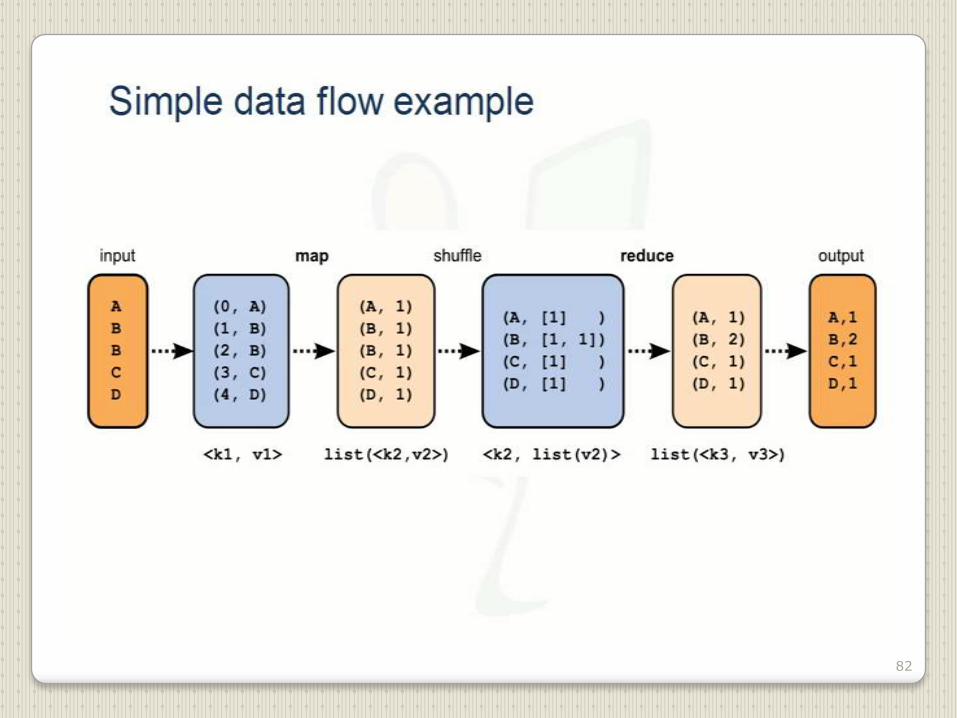
82

83

Hadoop (MapReduce) is one of the very powerful frameworks that enable easy
development on data-intensive application. It objective is help building a
supplication with high scalability with thousands of machines. We can see
Hadoop is very suitable to data-intensive background application and perfect fit to
our project‟s requirements. Apart from running application in parallel, Hadoop
provides some job monitoring features similar to Azure. If any machine crash,
the data could be recovered by other machines, and it will take up the jobs
automatically. When we put Hadoop into cloud, we also see the convenience in
setting up Hadoop. With a few command lines, we can allocate any number of
clusters to run Hadoop, this may save lot of time and effort. We found the
combination of cloud and Hadoop is surely a common way to setup large scale
application with lower cost, but higher elastic property.
Conclusion
84

Resources
http://hadoop.apache.org
http://developer.yahoo.com/hadoop
http://www.cloudera.com/resources
85




























