Embed Size (px)
Citation preview

1
Hadoop Installation and Running KMeans Clustering
with MapReduce Program on Hadoop
Introduction General issue that I will cover in this document are Hadoop installation (in section 1) and running
KMeans Clustering MapReduce program on Hadoop (section 2).
1 Hadoop Installation I will install Hadoop Single Node Cluster mode in my personal computer using this following
environment .
1. Ubuntu 12.04
2. Java JDK 1.7.0 update 21
3. Hadoop 1.2.1 (stable)
1.1 Prerequisites Before installing Hadoop, the following point must be done first before installing Hadoop in our
system
1. Sun JDK /Open JDK
I use Sun JDK from oracle instead of Open JDK, the resource package can be downloaded from here :
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
2. Hadoop installer packages
In this report, I will use Hadoop version 1.2.1 (stable). The resource package can be downloaded
from her : http://archive.apache.org/dist/hadoop/core/hadoop-1.2.1/
1.1.1 Configuring Java
In my computer, I have several installed java version, they are Java 7 and java 6. For running Hadoop
program, I need to configure which version I will use. I decide to use the newer version (java version
1.7 update 21) so the following are step by step for configuring latest java version.
1. Configure java
$ sudo update-alternatives --config java There are 2 choices for the alternative java (providing /usr/bin/java). Selection Path Priority Status ------------------------------------------------------------ 0 /usr/lib/jvm/jdk1.6.0_45/bin/java 1 auto mode 1 /usr/lib/jvm/jdk1.6.0_45/bin/java 1 manual mode * 2 /usr/lib/jvm/jdk1.7.0_21/bin/java 1 manual mode Press enter to keep the current choice[*], or type selection number: 2

2
2. configure javac
$ sudo update-alternatives --config javac There are 2 choices for the alternative javac (providing /usr/bin/javac). Selection Path Priority Status ------------------------------------------------------------ 0 /usr/lib/jvm/jdk1.6.0_45/bin/javac 1 auto mode 1 /usr/lib/jvm/jdk1.6.0_45/bin/javac 1 manual mode * 2 /usr/lib/jvm/jdk1.7.0_21/bin/javac 1 manual mode Press enter to keep the current choice[*], or type selection number: 2
3. configure javaws
$ sudo update-alternatives --config javaws There are 2 choices for the alternative javaws (providing /usr/bin/javaws). Selection Path Priority Status ------------------------------------------------------------ 0 /usr/lib/jvm/jdk1.6.0_45/bin/javaws 1 auto mode 1 /usr/lib/jvm/jdk1.6.0_45/bin/javaws 1 manual mode * 2 /usr/lib/jvm/jdk1.7.0_21/bin/javaws 1 manual mode Press enter to keep the current choice[*], or type selection number: 2
4. check the configuration
To make sure the latest java, javac, and javaws successfully configure, I use this following command tid@dbubuntu:~$ java -version java version "1.7.0_21" Java(TM) SE Runtime Environment (build 1.7.0_21-b11) Java HotSpot(TM) 64-Bit Server VM (build 23.21-b01, mixed mode)
1.1.2 Hadoop installer
After downloading Hadoop installer package, then we need to extract the installer package into the
desire directory. I downloaded Hadoop installer and locate in the ~/Download directory.
For extracting Hadoop installer package in the local directory, I use the following command
$ tar -xzfv hadoop-1.2.1.tar.gz
1.2 System configuration In this section I will explain step-by step how to setup and preparing the system for Hadoop single
node cluster in my local compute. The system configuration consists of network configuration for
setup the hosts name, move Hadoop extracted package into desire folder, enabling ssh, and adding
and changing folder permission.
1.2.1 Network configuration
In the hadoop network configuration, all of the machines should have alias instead of IP address. To
configure network aliases, we can edit /etc/hosts on machine that will we use for Hadoop
master and slave. In my case, since I am using single node, the configuration can be done by these
step
1. Open file /etc/hosts as sudoers,

3
$ sudo nano /etc/hosts
2. I add the following lines, inside the curly branch is my IP Address,
127.0.0.1 localhost
164.125.50.127 localhost
Note :
For configuring the local computer into pseudo distributed mode, the following configuration for
/etc/hosts is used
# /etc/hosts (for Hadoop Master and Slave) 192.168.0.1 master 192.168.0.2 slave
1.2.2 User configuration
For security issue, we better to create special user for Hadoop in each machine, however, since I am
working in local computer, I use existing user. The following command is for adding new user and
group
$ sudo addgroup hadoop $ sudo adduser --ingroup hadoop hduser
1.2.3 Configuring SSH
Hadoop requires SSH access to manage its nodes. In this configuration, I also configure SSH access to
localhost for hduser that I already made in the previous section and local existing user.
1. For generating ssh key for hduser, we can use the following command
$ su - hduser Password: hduser@dbubuntu:~$ ssh-keygen -t rsa -P "" Generating public/private rsa key pair. Enter file in which to save the key (/home/hduser/.ssh/id_rsa): /home/hduser/.ssh/id_rsa already exists. Overwrite (y/n)? y Your identification has been saved in /home/hduser/.ssh/id_rsa. Your public key has been saved in /home/hduser/.ssh/id_rsa.pub. The key fingerprint is: b8:68:c1:4b:d1:fe:4b:40:2c:1c:b4:37:db:5f:76:ee hduser@dbubuntu The key's randomart image is: +--[ RSA 2048]----+ | .o | | . = | | = * | | . * = | | + = S o . | | . + + . o o | | + . o . . | | . . . . | | . E | +-----------------+ hduser@dbubuntu:~$

4
2. Enable ssh access for local machine with newly created key
cat /home/hduser/.ssh/id_rsa.pub >>
/home/hduser/.ssh/authorized_keys
Note :
Since I use local existing user, I do the above step 2 times, also for user tid
1.2.4 Extracting Hadoop installer
I copy the Hadoop Installer package from ~/Download directory into desire folder. In this case I use
/usr/local to locate hadoop installer package.
1. Command for moving extracted Hadoop into
$ cp ~/Downloads/Hadoop-1.2.1 /usr/local/
$ cd /usr/local
2. in order to make hadoop easy to access and handling some update version of Hadoop, I create
symbolic link of hadoop-1.2.1 into hadoop directory
$ ln -s hadoop-1.2.1 hadoop
3. change folder permission of hadoop, so it will accessible by user tid
$ sudo chown -R tid:hadoop hadoop
1.3 Hadoop Configuration After sucessfully configuring the network, folder, and other configuration, in this part, I will explain
step by step hadoop configuration for each machine. Since I locate my hadoop inside
/usr/local/hadoop so it will be the active directory, and all of the hadoop configurations are
located in conf directory.
1.3.1 conf/masters
Since in this configuration for single node, the content of masters file by default should be like this
Localhost
Note : For multi node cluster we can add the master alias’s name regarding the network setup and
configuration in section 1.2.1
1.3.2 conf/slaves
Same as masters file, the default setup for slaves should be like this
Localhost
Note : for multi node cluster, we can add the master and slave alias(considering network
configuration in section 1.2.1), for example the slaves file might look like this
slave1
slave2
slave3

5
1.3.3 conf/core-site.xml
For core site configuration I specify the location in directory /tmp/Hadoop/app. In this file, I give
the configuration of core site of cluster. Firstly, the file look like this following
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> </configuration>
then I change the configuration to look like this
<configuration>
<property> <name>hadoop.tmp.dir</name> <value>/tmp/hadoop/app</value> <description>A base for other temporary directories.</description> </property>
<property> <name>fs.default.name</name> <value>hdfs://localhost:54310</value> <description>The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.</description> </property>
</configuration>
1.3.4 Conf/mapred-site.xml
I change the mapred-site.xml , that it look like this following
<configuration>
<!-- In: conf/mapred-site.xml -->
<property>
<name>mapred.job.tracker</name>
<value>localhost:54311</value>
<description>
The host and port that
the MapReduce job tracker runs
at. If "local", then jobs are run
in-process as a single map
and reduce task.
</description>
</property>
</configuration>

6
1.3.5 hdfs-site.xml
For hdfs-site, for single cluster, I specify the number of replication only 1, if we have several
machine we can add the number of replication.
<configuration> <property> <name>dfs.replication</name> <value>1</value> <description>Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time. </description> </property> </configuration>
1.3.6 Formatting HDFS via Namenode
Before starting the cluster, we should format the Hadoop File System. It can be formatted once or
more, however formatting the namenode means clear all of the data, so we need to be careful
otherwise we can lose our data
tid@dbubuntu:~$ /usr/local/hadoop/bin/hadoop namenode -format
1.4 Running Hadoop After setting all needed configuration, finally we can start our Hadoop. For running Hadoop daemon,
there are several alternatives,
1.4.1 Starting all daemon at once
For starting all of the service in Hadoop, I use this following command
tid@dbubuntu:/usr/local/hadoop$ bin/start-all.sh
Then, checking whether all of daemons already running using the following command
tid@dbubuntu:/usr/local/hadoop$ jps
1.4.2 Stopping all daemon
For stopping all daemon, we can use the following command
tid@dbubuntu:/usr/local/hadoop$ bin/stop-all.sh

7
2 Hadoop MapReduce Program (KMeans Clustering in Map
Reduce) In this part I will explain how I can run map reduce program regarding reference from Thomas’s blog
for KMeans Clustering in MapReduce (http://codingwiththomas.blogspot.kr/2011/05/k-means-
clustering-with-mapreduce.html ) with some modification
2.1 Eclipse IDE Setup There are several ways for setting up the IDE environment so we can easily create MapReduce
Program in Eclipse. For ease development and setup, I am using Eclipse plugin from self build plugin
by creating jar from Hadoop library. The following are step-by-step setting up eclipse IDE
Step 1: copy the pre-build eclipse plugin for Hadoop in directory plugins of Eclipse
Figure 1 Eclipse hadoop plugin inside plugins directory of eclipse
Step 2 : restart Eclipse, then in the perspective part, we will see other perspective in the right
corner, and choose MapReduce Perspective
Figure 2 MapReduce perspective in eclipse IDE
Step 3: Add the server in the map reduce panel.
In my case, because my server is located in the local machine, named as localhost, the detail will
looks like the following

8
Figure 3 Configuration for adding Hadoop Location
After adding the server, in the right side, along with project explorer, we will see the HDFS file
explorer, and right now Eclipse is ready to use for developing MapReduce Application
Figure 4 HDFS Directory explorer
2.2 Source Code Preparation In this part, I will describe how to prepare the project, package, and class for KMeans Clustering
MapReduce program.
Create new project
1. First, we need to create new MapReduce project, by clicking new project in the upper left
corner of eclipse, and after the following
window pup up, choose MapReduce
project
Figure 5 Choosing MapReduce project

9
2. Fill the project name, and check the reference location of Hadoop. By default, if we are using
eclipse plugin for Hadoop, the folder will be directed to our Hadoop installation folder , then
click “Finish”
Create Package and Class
For KMeans Clustering MapReduce program, based on Thomas’s references, we need to create two
package, one package for clustering model, consists of Model class for Vector, Distance Measure,
and define the ClusterCenter (Vector.java, DistanceMeasurer.java, and ClusterCenter.java) and the
other is package for Main, Mapper, and Reducer Class (KMeans
1. com.clustering.model package Model Class (Vector.java)
Model Class : Vector.java
package com.clustering.model;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.Arrays;
import org.apache.hadoop.io.WritableComparable;
public class Vector implements WritableComparable<Vector>{
private double[] vector;
public Vector(){
super();
}
public Vector(Vector v){
super();
int l= v.vector.length;
this.vector= new double[l];
System.arraycopy(v.vector, 0,this.vector, 0, l);

10
}
public Vector(double x, double y){
super();
this.vector = new double []{x,y};
}
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
int size = in.readInt();
vector = new double[size];
for(int i=0;i<size;i++)
vector[i]=in.readDouble();
}
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeInt(vector.length);
for(int i=0;i<vector.length;i++)
out.writeDouble(vector[i]);
}
@Override
public int compareTo(Vector o) {
// TODO Auto-generated method stub
boolean equals = true;
for (int i=0;i<vector.length;i++){
if (vector[i] != o.vector[i]) {
equals = false;
break;
}
}
if(equals)
return 0;
else
return 1;
}
public double[] getVector(){
return vector;
}
public void setVector(double[]vector){
this.vector=vector;
}
public String toString(){
return "Vector [vector=" + Arrays.toString(vector) + "]";
}
}
2. Distance Measurement Class
Distance Measurement class : DistanceMeasurer.java
package com.clustering.model;

11
public class DistanceMeasurer {
public static final double measureDistance(ClusterCenter center,
Vector v) {
double sum = 0;
int length = v.getVector().length;
for (int i = 0; i < length; i++) {
sum += Math.abs(center.getCenter().getVector()[i]
- v.getVector()[i]);
}
return sum;
}
}
3. ClusterCenter
Cluster Center definition : ClusterCenter.java
package com.clustering.model;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class ClusterCenter implements WritableComparable<ClusterCenter> {
private Vector center;
public ClusterCenter() {
super();
this.center = null;
}
public ClusterCenter(ClusterCenter center) {
super();
this.center = new Vector(center.center);
}
public ClusterCenter(Vector center) {
super();
this.center = center;
}
public boolean converged(ClusterCenter c) {
return compareTo(c) == 0 ? false : true;
}
@Override
public void write(DataOutput out) throws IOException {
center.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
this.center = new Vector();
center.readFields(in);
}

12
@Override
public int compareTo(ClusterCenter o) {
return center.compareTo(o.getCenter());
}
/**
* @return the center
*/
public Vector getCenter() {
return center;
}
@Override
public String toString() {
return "ClusterCenter [center=" + center + "]";
}
}
After configuring the class model, the next one is MapReduce Classes, which consist of Mapper,
Reducer, and finally the Main class
1. Mapper class
Mapper class : KMeansMapper.java
package com.clustering.mapreduce;
import java.io.IOException;
import java.util.LinkedList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.mapreduce.Mapper;
import com.clustering.model.ClusterCenter;
import com.clustering.model.DistanceMeasurer;
import com.clustering.model.Vector;
public class KMeansMapper extends
Mapper<ClusterCenter, Vector, ClusterCenter, Vector>{
List<ClusterCenter> centers = new LinkedList<ClusterCenter>();
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
super.setup(context);
Configuration conf = context.getConfiguration();
Path centroids = new Path(conf.get("centroid.path"));
FileSystem fs = FileSystem.get(conf);
SequenceFile.Reader reader = new SequenceFile.Reader(fs,
centroids,
conf);

13
ClusterCenter key = new ClusterCenter();
IntWritable value = new IntWritable();
while (reader.next(key, value)) {
centers.add(new ClusterCenter(key));
}
reader.close();
}
@Override
protected void map(ClusterCenter key, Vector value, Context context)
throws IOException, InterruptedException {
ClusterCenter nearest = null;
double nearestDistance = Double.MAX_VALUE;
for (ClusterCenter c : centers) {
double dist = DistanceMeasurer.measureDistance(c,
value);
if (nearest == null) {
nearest = c;
nearestDistance = dist;
} else {
if (nearestDistance > dist) {
nearest = c;
nearestDistance = dist;
}
}
}
context.write(nearest, value);
}
}
2. Reducer class
Reducer class : KMeansReducer.java
package com.clustering.mapreduce;
import java.io.IOException;
import java.util.LinkedList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.mapreduce.Reducer;
import com.clustering.model.ClusterCenter;
import com.clustering.model.Vector;
public class KMeansReducer extends
Reducer<ClusterCenter, Vector, ClusterCenter, Vector>{
public static enum Counter{
CONVERGED
}
List<ClusterCenter> centers = new LinkedList<ClusterCenter>();

14
protected void reduce(ClusterCenter key, Iterable<Vector> values,
Context context) throws IOException,
InterruptedException{
Vector newCenter = new Vector();
List<Vector> vectorList = new LinkedList<Vector>();
int vectorSize = key.getCenter().getVector().length;
newCenter.setVector(new double[vectorSize]);
for(Vector value :values){
vectorList.add(new Vector(value));
for(int i=0;i<value.getVector().length;i++){
newCenter.getVector()[i]+=value.getVector()[i];
}
}
for(int i=0;i<newCenter.getVector().length;i++){
newCenter.getVector()[i] =
newCenter.getVector()[i]/vectorList.size();
}
ClusterCenter center = new ClusterCenter(newCenter);
centers.add(center);
for(Vector vector:vectorList){
context.write(center, vector);
}
if(center.converged(key))
context.getCounter(Counter.CONVERGED).increment(1);
}
protected void cleanup(Context context) throws
IOException,InterruptedException{
super.cleanup(context);
Configuration conf = context.getConfiguration();
Path outPath = new Path(conf.get("centroid.path"));
FileSystem fs = FileSystem.get(conf);
fs.delete(outPath,true);
final SequenceFile.Writer out = SequenceFile.createWriter(fs,
context.getConfiguration(),
outPath, ClusterCenter.class, IntWritable.class);
final IntWritable value = new IntWritable(0);
for(ClusterCenter center:centers){
out.append(center, value);
}
out.close();
}
}

15
3. Main class
Main class : KMeansClusteringJob.java
package com.clustering.mapreduce;
import java.io.IOException;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import com.clustering.model.ClusterCenter;
import com.clustering.model.Vector;
public class KMeansClusteringJob {
private static final Log LOG =
LogFactory.getLog(KMeansClusteringJob.class);
public static void main(String[] args) throws IOException,
InterruptedException, ClassNotFoundException {
int iteration = 1;
Configuration conf = new Configuration();
conf.set("num.iteration", iteration + "");
Path in = new Path("files/clustering/import/data");
Path center = new
Path("files/clustering/import/center/cen.seq");
conf.set("centroid.path", center.toString());
Path out = new Path("files/clustering/depth_1");
Job job = new Job(conf);
job.setJobName("KMeans Clustering");
job.setMapperClass(KMeansMapper.class);
job.setReducerClass(KMeansReducer.class);
job.setJarByClass(KMeansMapper.class);
SequenceFileInputFormat.addInputPath(job, in);
FileSystem fs = FileSystem.get(conf);
if (fs.exists(out))
fs.delete(out, true);
if (fs.exists(center))
fs.delete(out, true);
if (fs.exists(in))
fs.delete(out, true);
final SequenceFile.Writer centerWriter =
SequenceFile.createWriter(fs,
conf, center, ClusterCenter.class,
IntWritable.class);

16
final IntWritable value = new IntWritable(0);
centerWriter.append(new ClusterCenter(new Vector(1, 1)),
value);
centerWriter.append(new ClusterCenter(new Vector(5, 5)),
value);
centerWriter.close();
final SequenceFile.Writer dataWriter =
SequenceFile.createWriter(fs,
conf, in, ClusterCenter.class,
Vector.class);
dataWriter
.append(new ClusterCenter(new Vector(0,
0)), new Vector(1, 2));
dataWriter.append(new ClusterCenter(new Vector(0, 0)),
new Vector(16, 3));
dataWriter
.append(new ClusterCenter(new Vector(0,
0)), new Vector(3, 3));
dataWriter
.append(new ClusterCenter(new Vector(0,
0)), new Vector(2, 2));
dataWriter
.append(new ClusterCenter(new Vector(0,
0)), new Vector(2, 3));
dataWriter.append(new ClusterCenter(new Vector(0, 0)),
new Vector(25, 1));
dataWriter
.append(new ClusterCenter(new Vector(0,
0)), new Vector(7, 6));
dataWriter
.append(new ClusterCenter(new Vector(0,
0)), new Vector(6, 5));
dataWriter.append(new ClusterCenter(new Vector(0, 0)), new
Vector(-1,
-23));
dataWriter.close();
SequenceFileOutputFormat.setOutputPath(job, out);
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
job.setOutputKeyClass(ClusterCenter.class);
job.setOutputValueClass(Vector.class);
job.waitForCompletion(true);
long counter = job.getCounters()
.findCounter(KMeansReducer.Counter.CONVERGED).getValue();
iteration++;
while (counter > 0) {
conf = new Configuration();
conf.set("centroid.path", center.toString());
conf.set("num.iteration", iteration + "");
job = new Job(conf);
job.setJobName("KMeans Clustering " + iteration);
job.setMapperClass(KMeansMapper.class);
job.setReducerClass(KMeansReducer.class);
job.setJarByClass(KMeansMapper.class);
Input
vector
K-Center
vector

17
in = new Path("files/clustering/depth_" +
(iteration - 1) + "/");
out = new Path("files/clustering/depth_" +
iteration);
SequenceFileInputFormat.addInputPath(job, in);
if (fs.exists(out))
fs.delete(out, true);
SequenceFileOutputFormat.setOutputPath(job, out);
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
job.setOutputKeyClass(ClusterCenter.class);
job.setOutputValueClass(Vector.class);
job.waitForCompletion(true);
iteration++;
counter = job.getCounters()
.findCounter(KMeansReducer.Counter.CONVERGED).getValue();
}
Path result = new Path("files/clustering/depth_" +
(iteration - 1) + "/");
FileStatus[] stati = fs.listStatus(result);
for (FileStatus status : stati) {
if (!status.isDir() &&
!status.getPath().toString().contains("/_")) {
Path path = status.getPath();
LOG.info("FOUND " + path.toString());
SequenceFile.Reader reader = new
SequenceFile.Reader(fs, path,
conf);
ClusterCenter key = new ClusterCenter();
Vector v = new Vector();
while (reader.next(key, v)) {
LOG.info(key + " / " + v);
}
reader.close();
}
}
}
}

18
Final project listing will look like this
Figure 6 File Listing for KMeansMapReduce Program
2.3 Run the program Unlike the wordcount program that we have to prepare the input files, in KMeansClustering
program the input is defined inside the KMeansClusteringJob class.
For running KMeansClustering job, since we are already configure the eclipse, we can run the
program natively inside Eclipse, So by pointing out the Main class (KMeansClusteringJob.java) we can
run the project as Hadoop Application
Figure 7 Run Project as hadoop application
The Input (to be defined in KMeansClusteringJob class)
Vector [vector=[16.0, 3.0]] Vector [vector=[7.0, 6.0]] Vector [vector=[6.0, 5.0]] Vector [vector=[25.0, 1.0]] Vector [vector=[1.0, 2.0]] Vector [vector=[3.0, 3.0]] Vector [vector=[2.0, 2.0]] Vector [vector=[2.0, 3.0]] Vector [vector=[-1.0, -23.0]]
Output from Thomas’s Blog :
ClusterCenter [center=Vector [vector=[13.5, 3.75]]] / Vector [vector=[16.0, 3.0]] ClusterCenter [center=Vector [vector=[13.5, 3.75]]] / Vector [vector=[7.0, 6.0]] ClusterCenter [center=Vector [vector=[13.5, 3.75]]] / Vector [vector=[6.0, 5.0]] ClusterCenter [center=Vector [vector=[13.5, 3.75]]] / Vector [vector=[25.0, 1.0]] ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[1.0, 2.0]] ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[3.0, 3.0]] ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[2.0, 2.0]] ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[2.0, 3.0]]
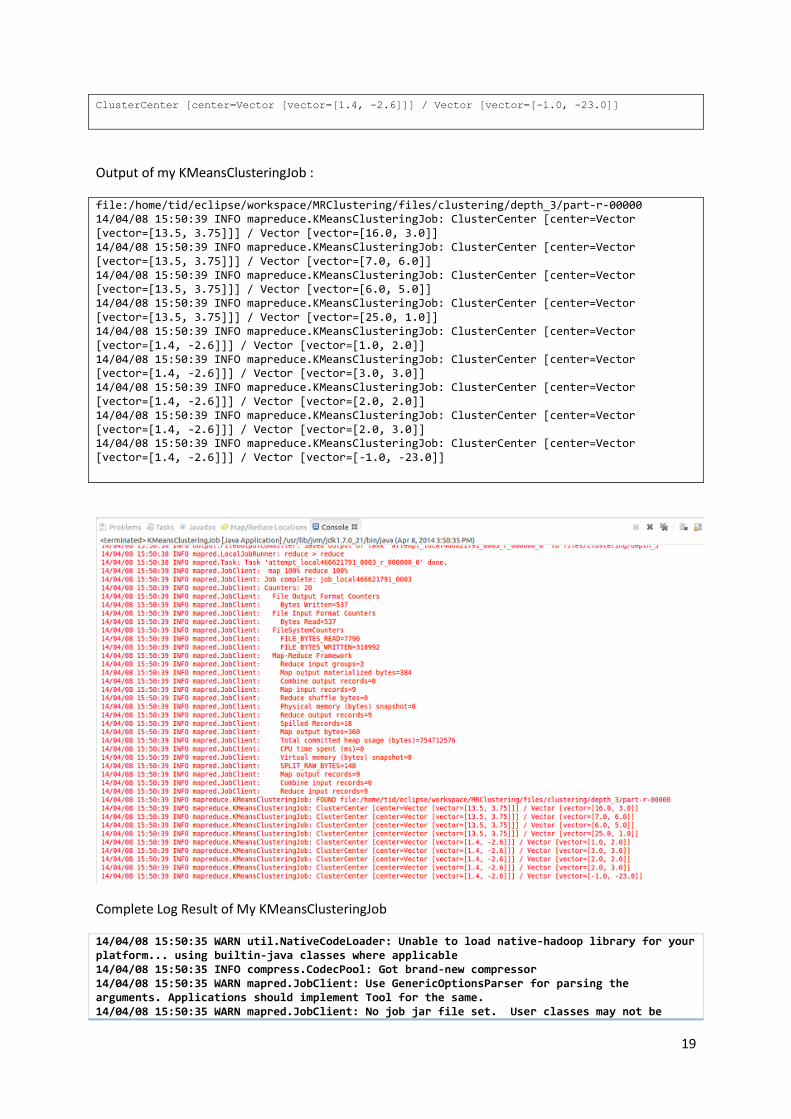
19
ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[-1.0, -23.0]]
Output of my KMeansClusteringJob :
file:/home/tid/eclipse/workspace/MRClustering/files/clustering/depth_3/part-r-00000 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[13.5, 3.75]]] / Vector [vector=[16.0, 3.0]] 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[13.5, 3.75]]] / Vector [vector=[7.0, 6.0]] 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[13.5, 3.75]]] / Vector [vector=[6.0, 5.0]] 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[13.5, 3.75]]] / Vector [vector=[25.0, 1.0]] 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[1.0, 2.0]] 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[3.0, 3.0]] 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[2.0, 2.0]] 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[2.0, 3.0]] 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[-1.0, -23.0]]
Complete Log Result of My KMeansClusteringJob
14/04/08 15:50:35 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 14/04/08 15:50:35 INFO compress.CodecPool: Got brand-new compressor 14/04/08 15:50:35 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 14/04/08 15:50:35 WARN mapred.JobClient: No job jar file set. User classes may not be

20
found. See JobConf(Class) or JobConf#setJar(String). 14/04/08 15:50:35 INFO input.FileInputFormat: Total input paths to process : 1 14/04/08 15:50:35 INFO mapred.JobClient: Running job: job_local1343624176_0001 14/04/08 15:50:35 INFO mapred.LocalJobRunner: Waiting for map tasks 14/04/08 15:50:35 INFO mapred.LocalJobRunner: Starting task: attempt_local1343624176_0001_m_000000_0 14/04/08 15:50:36 INFO util.ProcessTree: setsid exited with exit code 0 14/04/08 15:50:36 INFO mapred.Task: Using ResourceCalculatorPlugin : org.apache.hadoop.util.LinuxResourceCalculatorPlugin@24bec229 14/04/08 15:50:36 INFO mapred.MapTask: Processing split: file:/home/tid/eclipse/workspace/MRClustering/files/clustering/import/data:0+558 14/04/08 15:50:36 INFO mapred.MapTask: io.sort.mb = 100 14/04/08 15:50:36 INFO mapred.MapTask: data buffer = 79691776/99614720 14/04/08 15:50:36 INFO mapred.MapTask: record buffer = 262144/327680 14/04/08 15:50:36 INFO compress.CodecPool: Got brand-new decompressor 14/04/08 15:50:36 INFO compress.CodecPool: Got brand-new decompressor 14/04/08 15:50:36 INFO mapred.MapTask: Starting flush of map output 14/04/08 15:50:36 INFO mapred.MapTask: Finished spill 0 14/04/08 15:50:36 INFO mapred.Task: Task:attempt_local1343624176_0001_m_000000_0 is done. And is in the process of commiting 14/04/08 15:50:36 INFO mapred.LocalJobRunner: 14/04/08 15:50:36 INFO mapred.Task: Task 'attempt_local1343624176_0001_m_000000_0' done. 14/04/08 15:50:36 INFO mapred.LocalJobRunner: Finishing task: attempt_local1343624176_0001_m_000000_0 14/04/08 15:50:36 INFO mapred.LocalJobRunner: Map task executor complete. 14/04/08 15:50:36 INFO mapred.Task: Using ResourceCalculatorPlugin : org.apache.hadoop.util.LinuxResourceCalculatorPlugin@7b4b3d0e 14/04/08 15:50:36 INFO mapred.LocalJobRunner: 14/04/08 15:50:36 INFO mapred.Merger: Merging 1 sorted segments 14/04/08 15:50:36 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 380 bytes 14/04/08 15:50:36 INFO mapred.LocalJobRunner: 14/04/08 15:50:36 INFO mapred.Task: Task:attempt_local1343624176_0001_r_000000_0 is done. And is in the process of commiting 14/04/08 15:50:36 INFO mapred.LocalJobRunner: 14/04/08 15:50:36 INFO mapred.Task: Task attempt_local1343624176_0001_r_000000_0 is allowed to commit now 14/04/08 15:50:36 INFO output.FileOutputCommitter: Saved output of task 'attempt_local1343624176_0001_r_000000_0' to files/clustering/depth_1 14/04/08 15:50:36 INFO mapred.LocalJobRunner: reduce > reduce 14/04/08 15:50:36 INFO mapred.Task: Task 'attempt_local1343624176_0001_r_000000_0' done. 14/04/08 15:50:36 INFO mapred.JobClient: map 100% reduce 100% 14/04/08 15:50:36 INFO mapred.JobClient: Job complete: job_local1343624176_0001 14/04/08 15:50:36 INFO mapred.JobClient: Counters: 21 14/04/08 15:50:36 INFO mapred.JobClient: File Output Format Counters 14/04/08 15:50:36 INFO mapred.JobClient: Bytes Written=537 14/04/08 15:50:36 INFO mapred.JobClient: File Input Format Counters 14/04/08 15:50:36 INFO mapred.JobClient: Bytes Read=574 14/04/08 15:50:36 INFO mapred.JobClient: FileSystemCounters 14/04/08 15:50:36 INFO mapred.JobClient: FILE_BYTES_READ=2380 14/04/08 15:50:36 INFO mapred.JobClient: FILE_BYTES_WRITTEN=106876 14/04/08 15:50:36 INFO mapred.JobClient: com.clustering.mapreduce.KMeansReducer$Counter 14/04/08 15:50:36 INFO mapred.JobClient: CONVERGED=2 14/04/08 15:50:36 INFO mapred.JobClient: Map-Reduce Framework 14/04/08 15:50:36 INFO mapred.JobClient: Reduce input groups=2 14/04/08 15:50:36 INFO mapred.JobClient: Map output materialized bytes=384 14/04/08 15:50:36 INFO mapred.JobClient: Combine output records=0 14/04/08 15:50:36 INFO mapred.JobClient: Map input records=9 14/04/08 15:50:36 INFO mapred.JobClient: Reduce shuffle bytes=0 14/04/08 15:50:36 INFO mapred.JobClient: Physical memory (bytes) snapshot=0 14/04/08 15:50:36 INFO mapred.JobClient: Reduce output records=9 14/04/08 15:50:36 INFO mapred.JobClient: Spilled Records=18 14/04/08 15:50:36 INFO mapred.JobClient: Map output bytes=360 14/04/08 15:50:36 INFO mapred.JobClient: Total committed heap usage (bytes)=355991552 14/04/08 15:50:36 INFO mapred.JobClient: CPU time spent (ms)=0 14/04/08 15:50:36 INFO mapred.JobClient: Virtual memory (bytes) snapshot=0

21
14/04/08 15:50:36 INFO mapred.JobClient: SPLIT_RAW_BYTES=139 14/04/08 15:50:36 INFO mapred.JobClient: Map output records=9 14/04/08 15:50:36 INFO mapred.JobClient: Combine input records=0 14/04/08 15:50:36 INFO mapred.JobClient: Reduce input records=9 14/04/08 15:50:36 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 14/04/08 15:50:36 WARN mapred.JobClient: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String). 14/04/08 15:50:36 INFO input.FileInputFormat: Total input paths to process : 1 14/04/08 15:50:37 INFO mapred.JobClient: Running job: job_local1426850290_0002 14/04/08 15:50:37 INFO mapred.LocalJobRunner: Waiting for map tasks 14/04/08 15:50:37 INFO mapred.LocalJobRunner: Starting task: attempt_local1426850290_0002_m_000000_0 14/04/08 15:50:37 INFO mapred.Task: Using ResourceCalculatorPlugin : org.apache.hadoop.util.LinuxResourceCalculatorPlugin@26adcd34 14/04/08 15:50:37 INFO mapred.MapTask: Processing split: file:/home/tid/eclipse/workspace/MRClustering/files/clustering/depth_1/part-r-00000:0+521 14/04/08 15:50:37 INFO mapred.MapTask: io.sort.mb = 100 14/04/08 15:50:37 INFO mapred.MapTask: data buffer = 79691776/99614720 14/04/08 15:50:37 INFO mapred.MapTask: record buffer = 262144/327680 14/04/08 15:50:37 INFO mapred.MapTask: Starting flush of map output 14/04/08 15:50:37 INFO mapred.MapTask: Finished spill 0 14/04/08 15:50:37 INFO mapred.Task: Task:attempt_local1426850290_0002_m_000000_0 is done. And is in the process of commiting 14/04/08 15:50:37 INFO mapred.LocalJobRunner: 14/04/08 15:50:37 INFO mapred.Task: Task 'attempt_local1426850290_0002_m_000000_0' done. 14/04/08 15:50:37 INFO mapred.LocalJobRunner: Finishing task: attempt_local1426850290_0002_m_000000_0 14/04/08 15:50:37 INFO mapred.LocalJobRunner: Map task executor complete. 14/04/08 15:50:37 INFO mapred.Task: Using ResourceCalculatorPlugin : org.apache.hadoop.util.LinuxResourceCalculatorPlugin@3740f768 14/04/08 15:50:37 INFO mapred.LocalJobRunner: 14/04/08 15:50:37 INFO mapred.Merger: Merging 1 sorted segments 14/04/08 15:50:37 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 380 bytes 14/04/08 15:50:37 INFO mapred.LocalJobRunner: 14/04/08 15:50:37 INFO mapred.Task: Task:attempt_local1426850290_0002_r_000000_0 is done. And is in the process of commiting 14/04/08 15:50:37 INFO mapred.LocalJobRunner: 14/04/08 15:50:37 INFO mapred.Task: Task attempt_local1426850290_0002_r_000000_0 is allowed to commit now 14/04/08 15:50:37 INFO output.FileOutputCommitter: Saved output of task 'attempt_local1426850290_0002_r_000000_0' to files/clustering/depth_2 14/04/08 15:50:37 INFO mapred.LocalJobRunner: reduce > reduce 14/04/08 15:50:37 INFO mapred.Task: Task 'attempt_local1426850290_0002_r_000000_0' done. 14/04/08 15:50:38 INFO mapred.JobClient: map 100% reduce 100% 14/04/08 15:50:38 INFO mapred.JobClient: Job complete: job_local1426850290_0002 14/04/08 15:50:38 INFO mapred.JobClient: Counters: 21 14/04/08 15:50:38 INFO mapred.JobClient: File Output Format Counters 14/04/08 15:50:38 INFO mapred.JobClient: Bytes Written=537 14/04/08 15:50:38 INFO mapred.JobClient: File Input Format Counters 14/04/08 15:50:38 INFO mapred.JobClient: Bytes Read=537 14/04/08 15:50:38 INFO mapred.JobClient: FileSystemCounters 14/04/08 15:50:38 INFO mapred.JobClient: FILE_BYTES_READ=5088 14/04/08 15:50:38 INFO mapred.JobClient: FILE_BYTES_WRITTEN=212938 14/04/08 15:50:38 INFO mapred.JobClient: com.clustering.mapreduce.KMeansReducer$Counter 14/04/08 15:50:38 INFO mapred.JobClient: CONVERGED=2 14/04/08 15:50:38 INFO mapred.JobClient: Map-Reduce Framework 14/04/08 15:50:38 INFO mapred.JobClient: Reduce input groups=2 14/04/08 15:50:38 INFO mapred.JobClient: Map output materialized bytes=384 14/04/08 15:50:38 INFO mapred.JobClient: Combine output records=0 14/04/08 15:50:38 INFO mapred.JobClient: Map input records=9 14/04/08 15:50:38 INFO mapred.JobClient: Reduce shuffle bytes=0 14/04/08 15:50:38 INFO mapred.JobClient: Physical memory (bytes) snapshot=0 14/04/08 15:50:38 INFO mapred.JobClient: Reduce output records=9 14/04/08 15:50:38 INFO mapred.JobClient: Spilled Records=18

22
14/04/08 15:50:38 INFO mapred.JobClient: Map output bytes=360 14/04/08 15:50:38 INFO mapred.JobClient: Total committed heap usage (bytes)=555352064 14/04/08 15:50:38 INFO mapred.JobClient: CPU time spent (ms)=0 14/04/08 15:50:38 INFO mapred.JobClient: Virtual memory (bytes) snapshot=0 14/04/08 15:50:38 INFO mapred.JobClient: SPLIT_RAW_BYTES=148 14/04/08 15:50:38 INFO mapred.JobClient: Map output records=9 14/04/08 15:50:38 INFO mapred.JobClient: Combine input records=0 14/04/08 15:50:38 INFO mapred.JobClient: Reduce input records=9 14/04/08 15:50:38 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 14/04/08 15:50:38 WARN mapred.JobClient: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String). 14/04/08 15:50:38 INFO input.FileInputFormat: Total input paths to process : 1 14/04/08 15:50:38 INFO mapred.JobClient: Running job: job_local466621791_0003 14/04/08 15:50:38 INFO mapred.LocalJobRunner: Waiting for map tasks 14/04/08 15:50:38 INFO mapred.LocalJobRunner: Starting task: attempt_local466621791_0003_m_000000_0 14/04/08 15:50:38 INFO mapred.Task: Using ResourceCalculatorPlugin : org.apache.hadoop.util.LinuxResourceCalculatorPlugin@373fdd1a 14/04/08 15:50:38 INFO mapred.MapTask: Processing split: file:/home/tid/eclipse/workspace/MRClustering/files/clustering/depth_2/part-r-00000:0+521 14/04/08 15:50:38 INFO mapred.MapTask: io.sort.mb = 100 14/04/08 15:50:38 INFO mapred.MapTask: data buffer = 79691776/99614720 14/04/08 15:50:38 INFO mapred.MapTask: record buffer = 262144/327680 14/04/08 15:50:38 INFO mapred.MapTask: Starting flush of map output 14/04/08 15:50:38 INFO mapred.MapTask: Finished spill 0 14/04/08 15:50:38 INFO mapred.Task: Task:attempt_local466621791_0003_m_000000_0 is done. And is in the process of commiting 14/04/08 15:50:38 INFO mapred.LocalJobRunner: 14/04/08 15:50:38 INFO mapred.Task: Task 'attempt_local466621791_0003_m_000000_0' done. 14/04/08 15:50:38 INFO mapred.LocalJobRunner: Finishing task: attempt_local466621791_0003_m_000000_0 14/04/08 15:50:38 INFO mapred.LocalJobRunner: Map task executor complete. 14/04/08 15:50:38 INFO mapred.Task: Using ResourceCalculatorPlugin : org.apache.hadoop.util.LinuxResourceCalculatorPlugin@78d3cdb9 14/04/08 15:50:38 INFO mapred.LocalJobRunner: 14/04/08 15:50:38 INFO mapred.Merger: Merging 1 sorted segments 14/04/08 15:50:38 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 380 bytes 14/04/08 15:50:38 INFO mapred.LocalJobRunner: 14/04/08 15:50:38 INFO mapred.Task: Task:attempt_local466621791_0003_r_000000_0 is done. And is in the process of commiting 14/04/08 15:50:38 INFO mapred.LocalJobRunner: 14/04/08 15:50:38 INFO mapred.Task: Task attempt_local466621791_0003_r_000000_0 is allowed to commit now 14/04/08 15:50:38 INFO output.FileOutputCommitter: Saved output of task 'attempt_local466621791_0003_r_000000_0' to files/clustering/depth_3 14/04/08 15:50:38 INFO mapred.LocalJobRunner: reduce > reduce 14/04/08 15:50:38 INFO mapred.Task: Task 'attempt_local466621791_0003_r_000000_0' done. 14/04/08 15:50:39 INFO mapred.JobClient: map 100% reduce 100% 14/04/08 15:50:39 INFO mapred.JobClient: Job complete: job_local466621791_0003 14/04/08 15:50:39 INFO mapred.JobClient: Counters: 20 14/04/08 15:50:39 INFO mapred.JobClient: File Output Format Counters 14/04/08 15:50:39 INFO mapred.JobClient: Bytes Written=537 14/04/08 15:50:39 INFO mapred.JobClient: File Input Format Counters 14/04/08 15:50:39 INFO mapred.JobClient: Bytes Read=537 14/04/08 15:50:39 INFO mapred.JobClient: FileSystemCounters 14/04/08 15:50:39 INFO mapred.JobClient: FILE_BYTES_READ=7796 14/04/08 15:50:39 INFO mapred.JobClient: FILE_BYTES_WRITTEN=318992 14/04/08 15:50:39 INFO mapred.JobClient: Map-Reduce Framework 14/04/08 15:50:39 INFO mapred.JobClient: Reduce input groups=2 14/04/08 15:50:39 INFO mapred.JobClient: Map output materialized bytes=384 14/04/08 15:50:39 INFO mapred.JobClient: Combine output records=0 14/04/08 15:50:39 INFO mapred.JobClient: Map input records=9 14/04/08 15:50:39 INFO mapred.JobClient: Reduce shuffle bytes=0 14/04/08 15:50:39 INFO mapred.JobClient: Physical memory (bytes) snapshot=0

23
14/04/08 15:50:39 INFO mapred.JobClient: Reduce output records=9 14/04/08 15:50:39 INFO mapred.JobClient: Spilled Records=18 14/04/08 15:50:39 INFO mapred.JobClient: Map output bytes=360 14/04/08 15:50:39 INFO mapred.JobClient: Total committed heap usage (bytes)=754712576 14/04/08 15:50:39 INFO mapred.JobClient: CPU time spent (ms)=0 14/04/08 15:50:39 INFO mapred.JobClient: Virtual memory (bytes) snapshot=0 14/04/08 15:50:39 INFO mapred.JobClient: SPLIT_RAW_BYTES=148 14/04/08 15:50:39 INFO mapred.JobClient: Map output records=9 14/04/08 15:50:39 INFO mapred.JobClient: Combine input records=0 14/04/08 15:50:39 INFO mapred.JobClient: Reduce input records=9 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: FOUND file:/home/tid/eclipse/workspace/MRClustering/files/clustering/depth_3/part-r-00000 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[13.5, 3.75]]] / Vector [vector=[16.0, 3.0]] 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[13.5, 3.75]]] / Vector [vector=[7.0, 6.0]] 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[13.5, 3.75]]] / Vector [vector=[6.0, 5.0]] 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[13.5, 3.75]]] / Vector [vector=[25.0, 1.0]] 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[1.0, 2.0]] 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[3.0, 3.0]] 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[2.0, 2.0]] 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[2.0, 3.0]] 14/04/08 15:50:39 INFO mapreduce.KMeansClusteringJob: ClusterCenter [center=Vector [vector=[1.4, -2.6]]] / Vector [vector=[-1.0, -23.0]]
References
Hadoop Installation on single node cluster - http://www.michael-noll.com/tutorials/running-
hadoop-on-ubuntu-linux-single-node-cluster/
KMeansClustering with MapReduce - http://codingwiththomas.blogspot.kr/2011/05/k-
means-clustering-with-mapreduce.html

![ApproxHadoop: Bringing Approximations to MapReduce Frameworkssantosh.nagarakatte/... · Hadoop. Hadoop is the best-known, publicly available im-plementation of MapReduce [1]. Hadoop](https://img.pdfslide.us/doc/110x75/5f0f6abb7e708231d4440e6d/approxhadoop-bringing-approximations-to-mapreduce-frameworks-santoshnagarakatte.jpg)



























