Embed Size (px)
Citation preview

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Pavan Pothukuchi, Principal Product Manager, AWS
Chris Liu, Data Infrastructure Engineer, Coursera
July 13, 2016
Getting Started with
Amazon Redshift

Agenda
• Introduction
• Benefits
• Use cases
• Redshift @ Coursera
• Q&A
AnalyzeStore
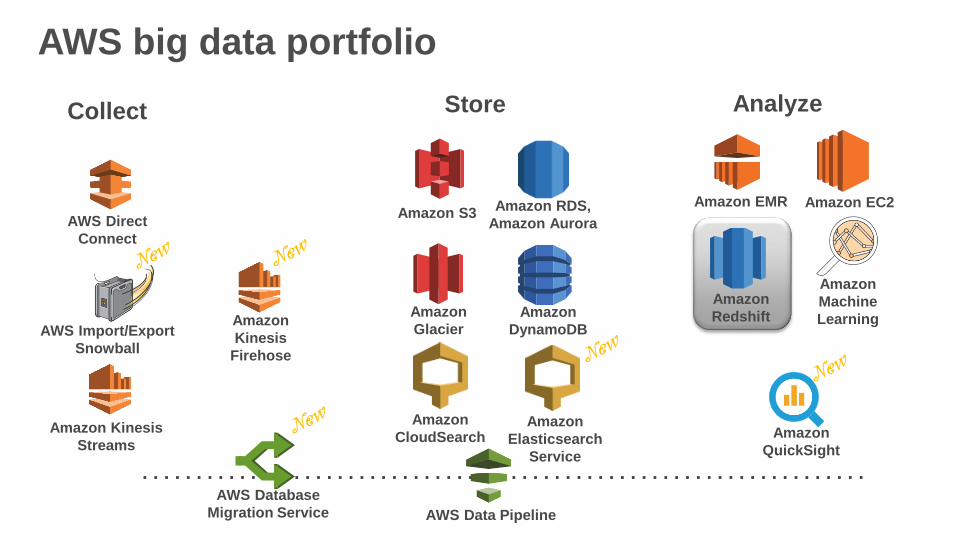
Amazon
Glacier
Amazon S3
Amazon
DynamoDB
Amazon RDS,
Amazon Aurora
AWS big data portfolio
AWS Data Pipeline
Amazon
CloudSearch
Amazon EMR Amazon EC2
Amazon
Redshift
Amazon
Machine
Learning
Amazon
Elasticsearch
Service
AWS Database
Migration Service
Amazon
QuickSight
Amazon
Kinesis
Firehose
AWS Import/Export
Snowball
AWS Direct
Connect
Collect
Amazon Kinesis
Streams

Relational data warehouse
Massively parallel; petabyte scale
Fully managed
HDD and SSD platforms
$1,000/TB/year; starts at $0.25/hour
Amazon
Redshift
a lot faster
a lot simpler
a lot cheaper
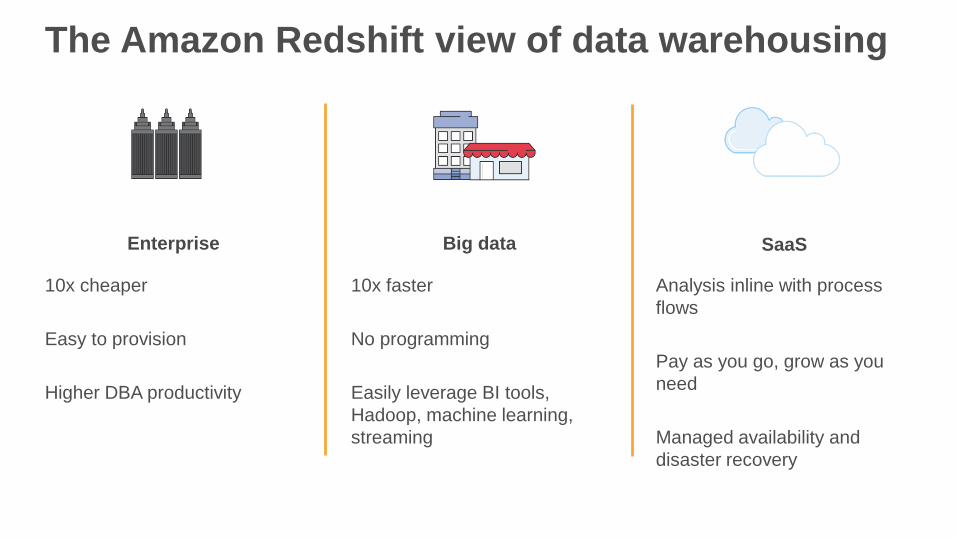
The Amazon Redshift view of data warehousing
10x cheaper
Easy to provision
Higher DBA productivity
10x faster
No programming
Easily leverage BI tools,
Hadoop, machine learning,
streaming
Analysis inline with process
flows
Pay as you go, grow as you
need
Managed availability and
disaster recovery
Enterprise Big data SaaS
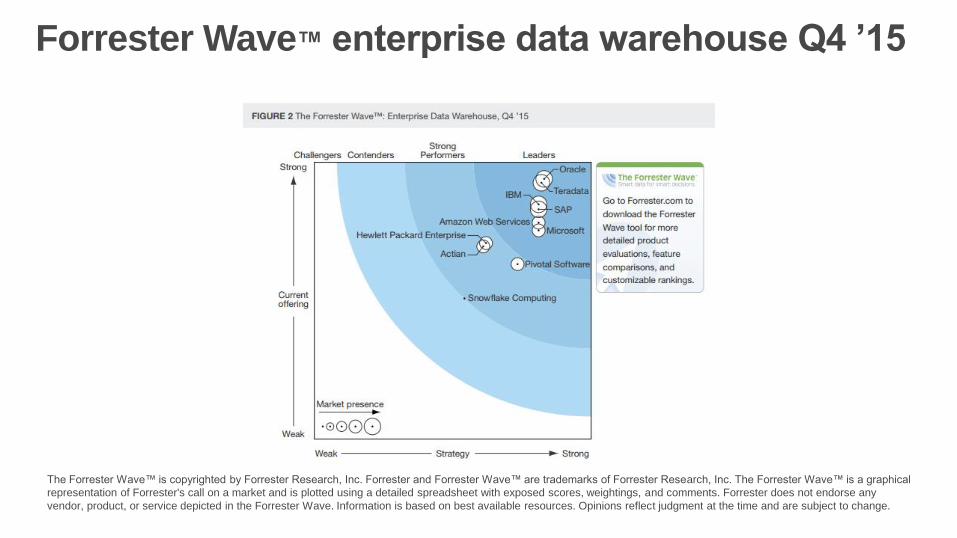
The Forrester Wave™ is copyrighted by Forrester Research, Inc. Forrester and Forrester Wave™ are trademarks of Forrester Research, Inc. The Forrester Wave™ is a graphical
representation of Forrester's call on a market and is plotted using a detailed spreadsheet with exposed scores, weightings, and comments. Forrester does not endorse any
vendor, product, or service depicted in the Forrester Wave. Information is based on best available resources. Opinions reflect judgment at the time and are subject to change.
Forrester Wave™ enterprise data warehouse Q4 ’15

Selected Amazon Redshift customers
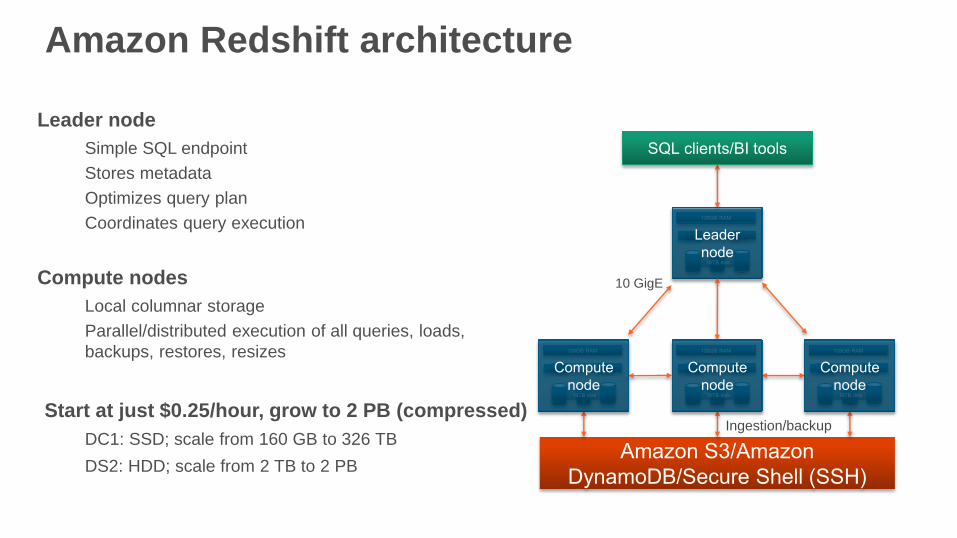
Amazon Redshift architecture
Leader node
Simple SQL endpoint
Stores metadata
Optimizes query plan
Coordinates query execution
Compute nodes
Local columnar storage
Parallel/distributed execution of all queries, loads,
backups, restores, resizes
Start at just $0.25/hour, grow to 2 PB (compressed)
DC1: SSD; scale from 160 GB to 326 TB
DS2: HDD; scale from 2 TB to 2 PB
Ingestion/backup
Backup
Restore
JDBC/ODBC
10 GigE
(HPC)

Benefit #1: Amazon Redshift is fast
Dramatically less I/O
Column storage
Data compression
Zone maps
Direct-attached storage
Large data block sizes
analyze compression listing;
Table | Column | Encoding
---------+----------------+----------
listing | listid | delta
listing | sellerid | delta32k
listing | eventid | delta32k
listing | dateid | bytedict
listing | numtickets | bytedict
listing | priceperticket | delta32k
listing | totalprice | mostly32
listing | listtime | raw
10 | 13 | 14 | 26 |…
… | 100 | 245 | 324
375 | 393 | 417…
… 512 | 549 | 623
637 | 712 | 809 …
… | 834 | 921 | 959
10
324
375
623
637
959
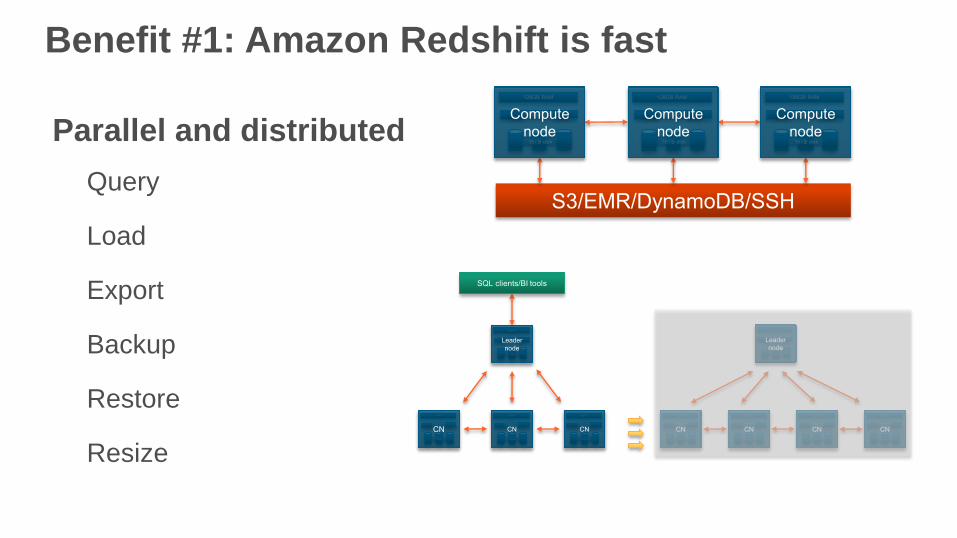
Benefit #1: Amazon Redshift is fast
Parallel and distributed
Query
Load
Export
Backup
Restore
Resize
Benefit #1: Amazon Redshift is fast
Hardware optimized for I/O intensive workloads, 4 GB/sec/node
Enhanced networking, over 1 million packets/sec/node
Choice of storage type, instance size
Regular cadence of autopatched improvements

Benefit #1: Amazon Redshift is fast
New dense storage (HDD) instance type (Jun 2015)
Improved memory 2x, compute 2x, disk throughput 1.5x
Cost: Same as our prior generation!
Performance improvement: 50%
Enhanced I/O and commit improvements (Jan 2016)
Performance improvement: 35%
Memory allocation improvements (May 2016)
Performance improvement: 60%

Benefit #2: Amazon Redshift is inexpensive
Ds2 (HDD)Price per hour for
DW1.XL single node
Effective annual
price per TB compressed
On demand $ 0.850 $ 3,725
1-year reservation $ 0.500 $ 2,190
3-year reservation $ 0.228 $ 999
Dc1 (SSD)Price per hour for
DW2.L single node
Effective annual
price per TB compressed
On demand $ 0.250 $ 13,690
1-year reservation $ 0.161 $ 8,795
3-year reservation $ 0.100 $ 5,500
Pricing is simple
Number of nodes x price/hour
No charge for leader node
No upfront costs
Pay as you go
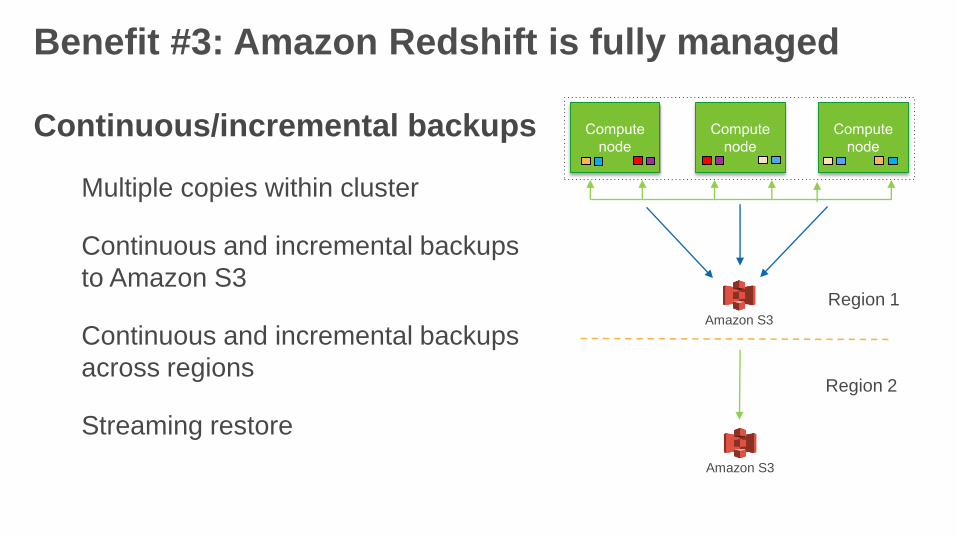
Benefit #3: Amazon Redshift is fully managed
Continuous/incremental backups
Multiple copies within cluster
Continuous and incremental backups
to Amazon S3
Continuous and incremental backups
across regions
Streaming restore
Amazon S3
Amazon S3
Region 1
Region 2
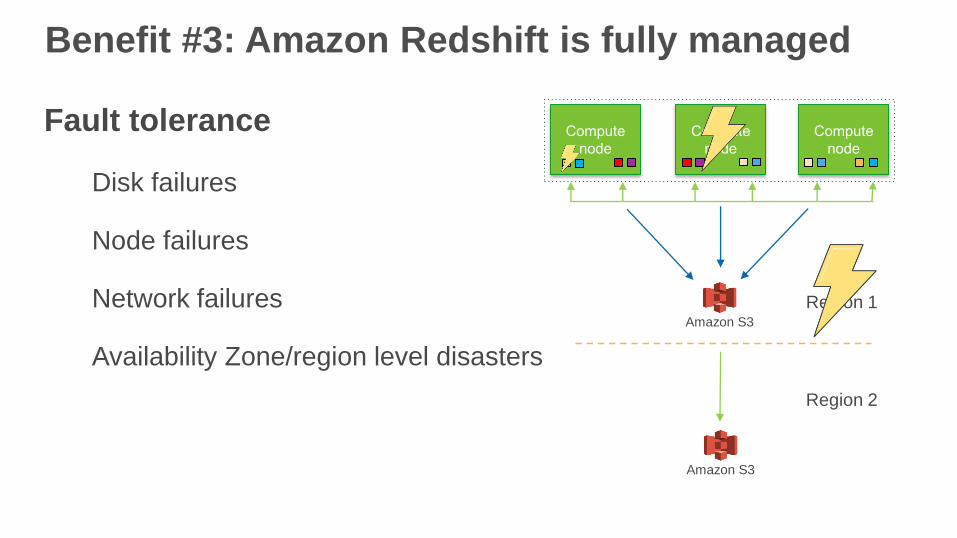
Benefit #3: Amazon Redshift is fully managed
Amazon S3
Amazon S3
Region 1
Region 2
Fault tolerance
Disk failures
Node failures
Network failures
Availability Zone/region level disasters
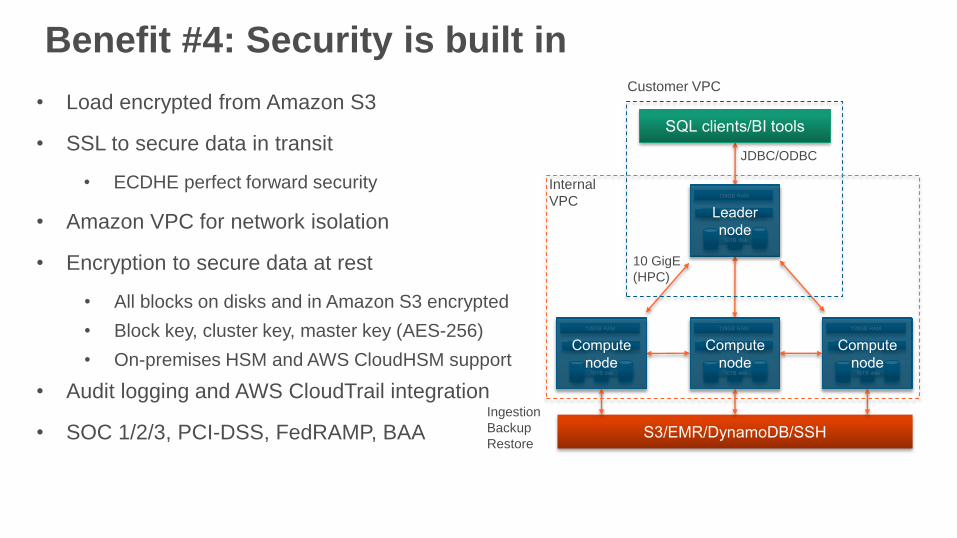
Benefit #4: Security is built in
• Load encrypted from Amazon S3
• SSL to secure data in transit
• ECDHE perfect forward security
• Amazon VPC for network isolation
• Encryption to secure data at rest
• All blocks on disks and in Amazon S3 encrypted
• Block key, cluster key, master key (AES-256)
• On-premises HSM and AWS CloudHSM support
• Audit logging and AWS CloudTrail integration
• SOC 1/2/3, PCI-DSS, FedRAMP, BAA
10 GigE
(HPC)
Ingestion
Backup
Restore
Customer VPC
Internal
VPC
JDBC/ODBC
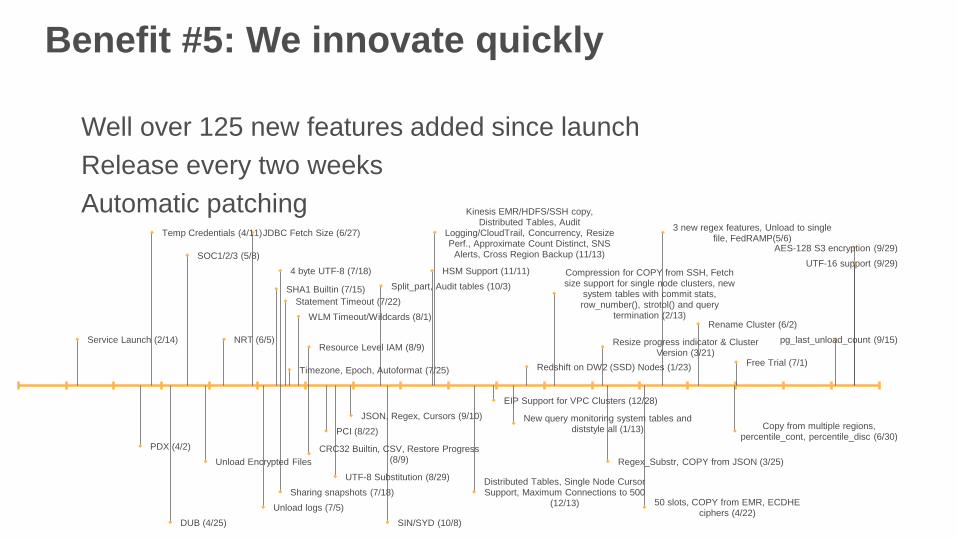
Benefit #5: We innovate quickly
Well over 125 new features added since launch
Release every two weeks
Automatic patching
Service Launch (2/14)
PDX (4/2)
Temp Credentials (4/11)
DUB (4/25)
SOC1/2/3 (5/8)
Unload Encrypted Files
NRT (6/5)
JDBC Fetch Size (6/27)
Unload logs (7/5)
SHA1 Builtin (7/15)
4 byte UTF-8 (7/18)
Sharing snapshots (7/18)
Statement Timeout (7/22)
Timezone, Epoch, Autoformat (7/25)
WLM Timeout/Wildcards (8/1)
CRC32 Builtin, CSV, Restore Progress (8/9)
Resource Level IAM (8/9)
PCI (8/22)
UTF-8 Substitution (8/29)
JSON, Regex, Cursors (9/10)
Split_part, Audit tables (10/3)
SIN/SYD (10/8)
HSM Support (11/11)
Kinesis EMR/HDFS/SSH copy, Distributed Tables, Audit
Logging/CloudTrail, Concurrency, Resize Perf., Approximate Count Distinct, SNS
Alerts, Cross Region Backup (11/13)
Distributed Tables, Single Node Cursor Support, Maximum Connections to 500
(12/13)
EIP Support for VPC Clusters (12/28)
New query monitoring system tables and diststyle all (1/13)
Redshift on DW2 (SSD) Nodes (1/23)
Compression for COPY from SSH, Fetch size support for single node clusters, new
system tables with commit stats, row_number(), strotol() and query
termination (2/13)
Resize progress indicator & Cluster Version (3/21)
Regex_Substr, COPY from JSON (3/25)
50 slots, COPY from EMR, ECDHE ciphers (4/22)
3 new regex features, Unload to single file, FedRAMP(5/6)
Rename Cluster (6/2)
Copy from multiple regions, percentile_cont, percentile_disc (6/30)
Free Trial (7/1)
pg_last_unload_count (9/15)
AES-128 S3 encryption (9/29)
UTF-16 support (9/29)

Benefit #6: Amazon Redshift is powerful
• Approximate functions
• User-defined functions
• Machine learning
• Data science

Benefit #7: Amazon Redshift has a large ecosystem
Data integration Systems integratorsBusiness intelligence
Benefit #8: Service-oriented architecture
Amazon
DynamoDB
Amazon EMR
Amazon S3
Amazon EC2/SSH
Amazon RDS/
Amazon Aurora
Amazon
Redshift
Amazon Kinesis
Amazon ML
AWS Data Pipeline
Amazon
CloudSearch
Amazon
Mobile
Analytics
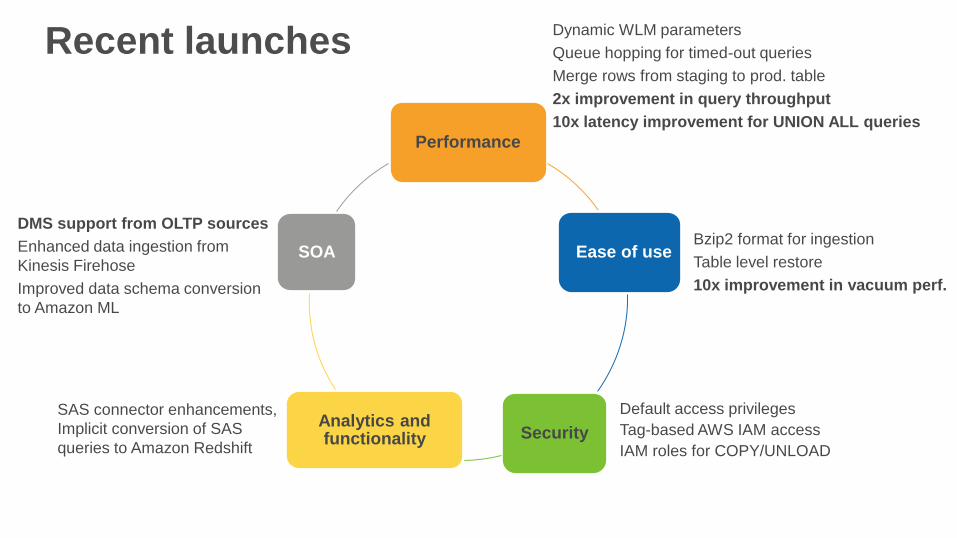
Performance
Ease of use
SecurityAnalytics and functionality
SOA
Recent launchesDynamic WLM parameters
Queue hopping for timed-out queries
Merge rows from staging to prod. table
2x improvement in query throughput
10x latency improvement for UNION ALL queries
Bzip2 format for ingestion
Table level restore
10x improvement in vacuum perf.
Default access privileges
Tag-based AWS IAM access
IAM roles for COPY/UNLOAD
SAS connector enhancements,
Implicit conversion of SAS
queries to Amazon Redshift
DMS support from OLTP sources
Enhanced data ingestion from
Kinesis Firehose
Improved data schema conversion
to Amazon ML

Use cases
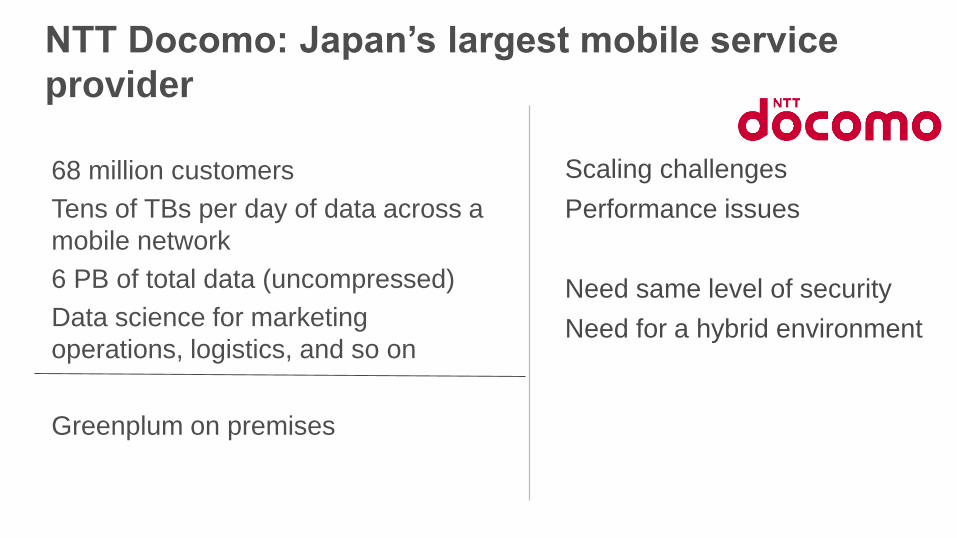
NTT Docomo: Japan’s largest mobile service
provider
68 million customers
Tens of TBs per day of data across a
mobile network
6 PB of total data (uncompressed)
Data science for marketing
operations, logistics, and so on
Greenplum on premises
Scaling challenges
Performance issues
Need same level of security
Need for a hybrid environment
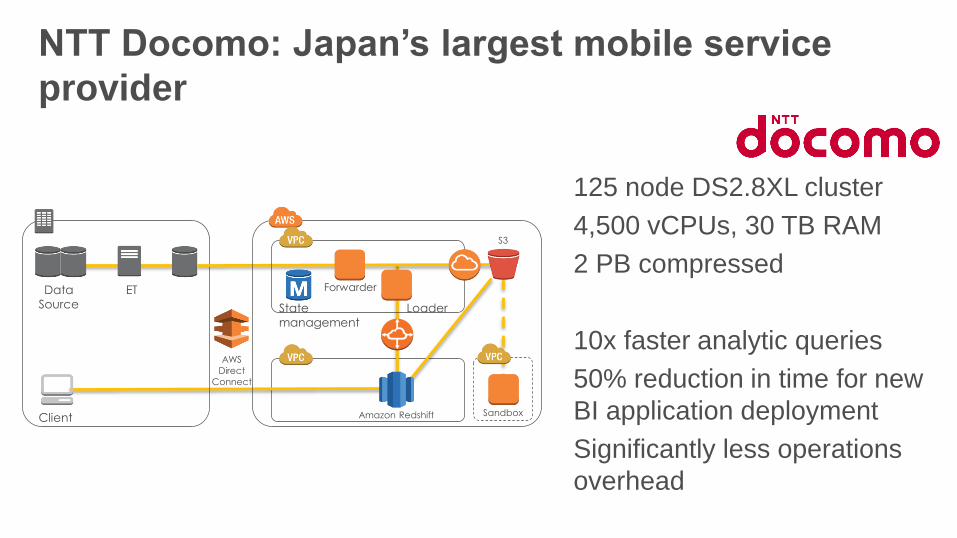
NTT Docomo: Japan’s largest mobile service
provider
125 node DS2.8XL cluster
4,500 vCPUs, 30 TB RAM
2 PB compressed
10x faster analytic queries
50% reduction in time for new
BI application deployment
Significantly less operations
overhead
Data
Source
ET
AWS
Direct
Connect
Client
Forwarder
LoaderState
management
SandboxAmazon Redshift
S3
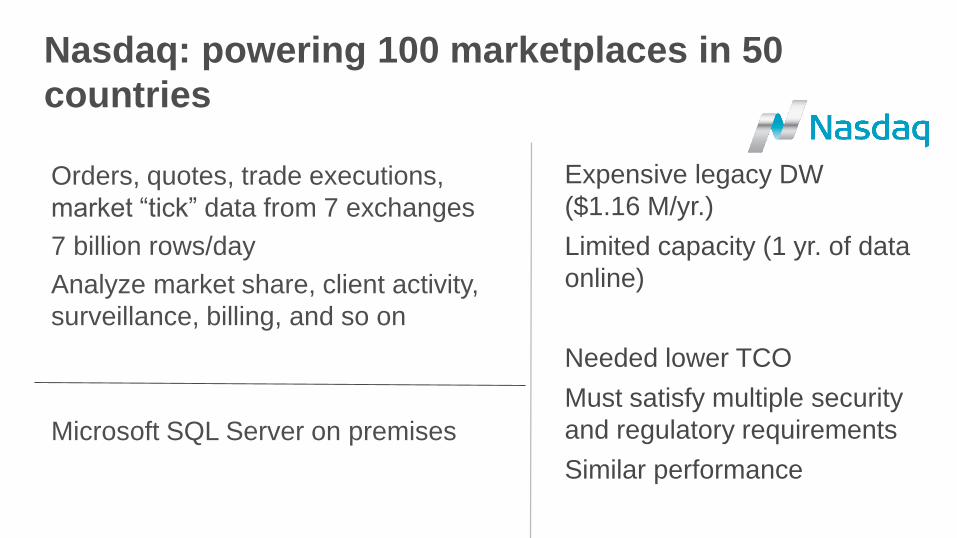
Nasdaq: powering 100 marketplaces in 50
countries
Orders, quotes, trade executions,
market “tick” data from 7 exchanges
7 billion rows/day
Analyze market share, client activity,
surveillance, billing, and so on
Microsoft SQL Server on premises
Expensive legacy DW
($1.16 M/yr.)
Limited capacity (1 yr. of data
online)
Needed lower TCO
Must satisfy multiple security
and regulatory requirements
Similar performance
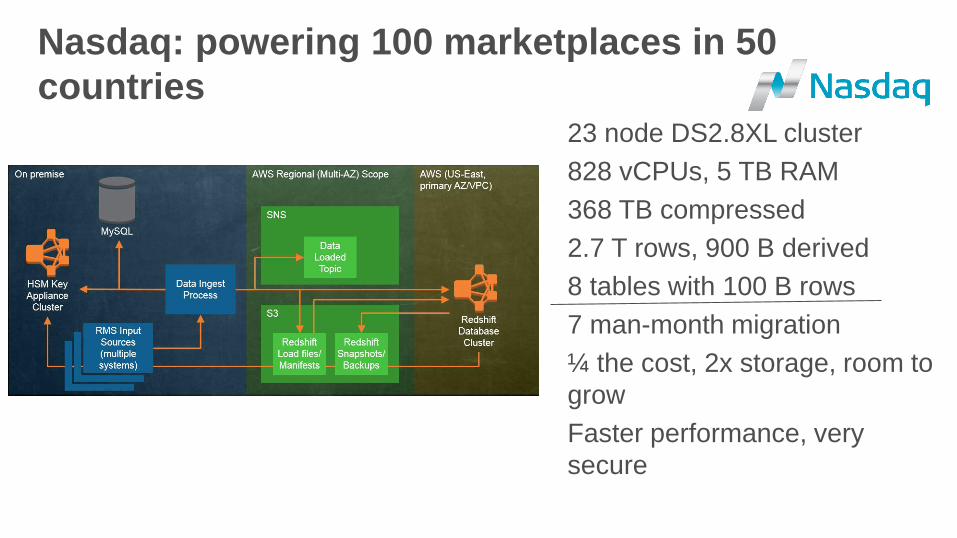
23 node DS2.8XL cluster
828 vCPUs, 5 TB RAM
368 TB compressed
2.7 T rows, 900 B derived
8 tables with 100 B rows
7 man-month migration
¼ the cost, 2x storage, room to
grow
Faster performance, very
secure
Nasdaq: powering 100 marketplaces in 50
countries

Amazon Redshift @
Chris Liu – Data Infrastructure Engineer
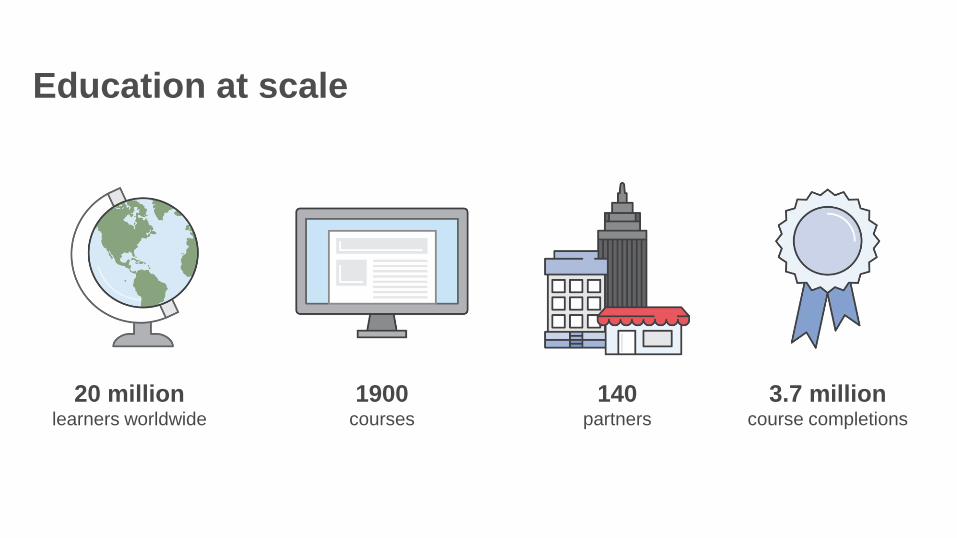
Education at scale
140partners
3.7 millioncourse completions
20 millionlearners worldwide
1900courses

Takeaways
• Simplicity
• Scalability
• Flexibility
• Extensibility

Outline
• Moving from no data warehouse to the Amazon
Redshift ecosystem• No warehouse: m2.2xlarge read replica – 4 CPUs, 32 GB RAM on Amazon RDS
• First Amazon Redshift cluster: 1 ds1.xl node – 2 CPU, 16 GB RAM

Outline
• Moving from no data warehouse to the Amazon
Redshift ecosystem• No warehouse: m2.2xlarge read replica – 4 CPUs, 32 GB RAM on Amazon RDS
• First Amazon Redshift cluster: 1 ds1.xl node – 2 CPU, 16 GB RAM
• The Amazon Redshift ecosystem at Coursera• Current day: 9 dc1.8xl nodes – 288 CPUs, 2.4 TB RAM

Outline
• Moving from no data warehouse to the Amazon
Redshift ecosystem• No warehouse: m2.2xlarge read replica – 4 CPUs, 32 GB RAM on Amazon RDS
• First Amazon Redshift cluster: 1 ds1.xl node – 2 CPU, 16 GB RAM
• The Amazon Redshift ecosystem at Coursera• Current day: 9 dc1.8xl nodes – 288 CPUs, 2.4 TB RAM
• Learnings from 3 years on Amazon Redshift• Lessons in communication, surprises, reflections

Starting point
• Querying production read replica
• Makeshift libraries providing thin abstraction layer• 45 minutes to provide aggregate metrics over all classes running on Coursera =(

Starting point
• Querying production read replica
• Makeshift libraries providing thin abstraction layer• 45 minutes to provide aggregate metrics over all classes running on Coursera =(

Move in progress
• Risk-free deployment• "Let's try it out"
• Few clicks to deploy cluster, connect to cluster, resize

Move in progress
• Risk-free deployment• "Let's try it out"
• Few clicks to deploy cluster, connect to cluster, resize
• AWS ecosystem integration• COPY from S3/EMR/SSH
• Unload to S3
• UNLOAD(COPY(data)) == COPY(UNLOAD(data)) == data

Move in progress
• Risk-free deployment• "Let's try it out"
• Few clicks to deploy cluster, connect to cluster, resize
• AWS ecosystem integration• COPY from S3/EMR/SSH
• Unload to S3
• UNLOAD(COPY(data)) == COPY(UNLOAD(data)) == data
• Minimal administration• In aggregate, less than 1 full-time employee for administration
• Automation and tooling for monitoring usage and performance
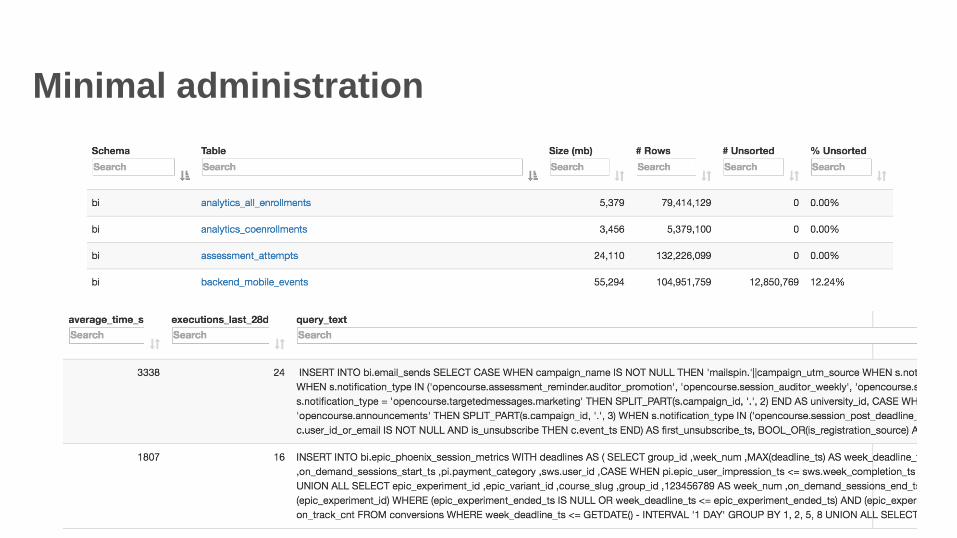
Minimal administration

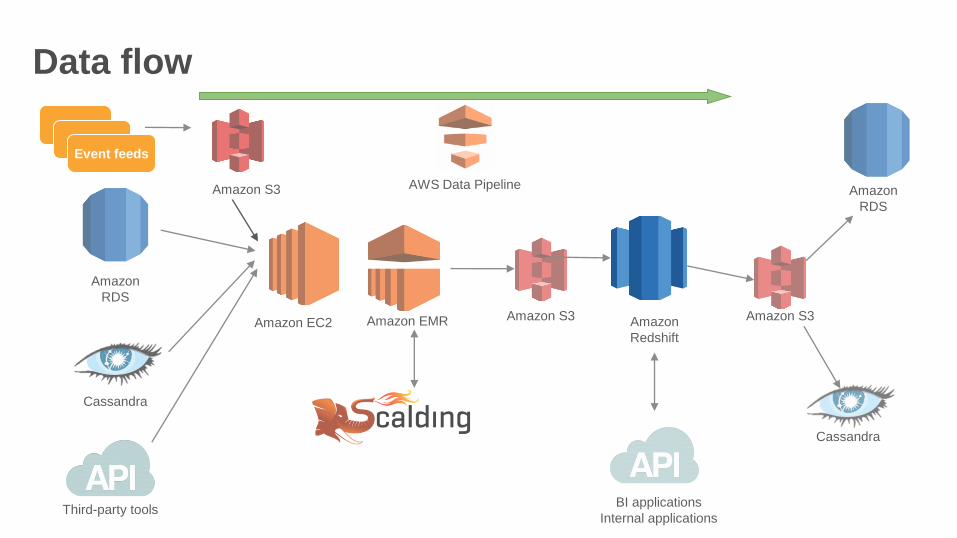
Amazon Redshift ecosystem at Coursera
• Data flow in and out of Amazon Redshift
• Business insights and reporting
• Deriving value from data
• Democratizing data access

Amazon Redshift ecosystem at Coursera
• Data flow in and out of Amazon Redshift
• Business insights and reporting
• Deriving value from data
• Democratizing data access
Amazon
Redshift
Amazon
RDS
Amazon EMR Amazon S3
Event feeds
Amazon EC2
Amazon
RDS
Amazon S3
BI applications
Internal applicationsThird-party tools
Cassandra
Cassandra
AWS Data Pipeline
Data flow
Amazon S3

Amazon Redshift ecosystem at Coursera
• Data flow in and out of Amazon Redshift
• Business insights and reporting
• Data products
• Democratizing data access

• Provide directional insights and aggregate metrics
• Aggregate metrics over all classes on Coursera: < 5 seconds
• Goal: Insight at the speed of thought
• Results1: 0.8s median, 28s p95, 120s p99
• Companywide goal tracking
• Scheduled reports to internal and external stakeholders
• Crucial part of data informed culture
1 Results for ad hoc queries ran in the last 90 days
Business insights and reporting

Amazon Redshift ecosystem at Coursera
• Data flow in and out of Amazon Redshift
• Business insights and reporting
• Data products
• Democratizing data access

• AB experimentation
• 300 M impression table joined with 1.8 B events table in 12 minutes.
• Recommendations model
• Amazon Redshift for relational transformation
• Unload to S3 for model training
• Providing university partners with analytical dashboard
and research exports
Data Products

Amazon Redshift ecosystem at Coursera
• Data flow in and out of Amazon Redshift
• Business insights and reporting
• Data products
• Democratizing data access
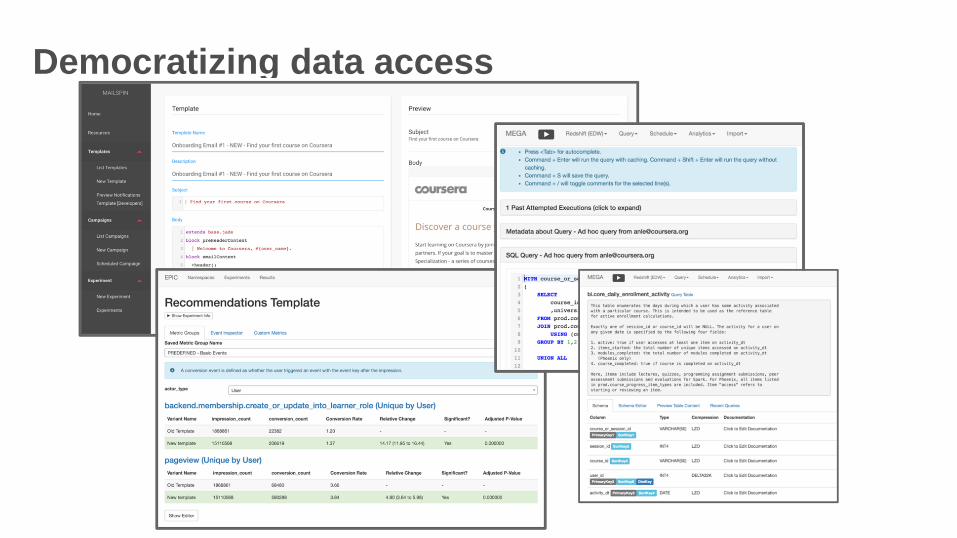
Democratizing data access
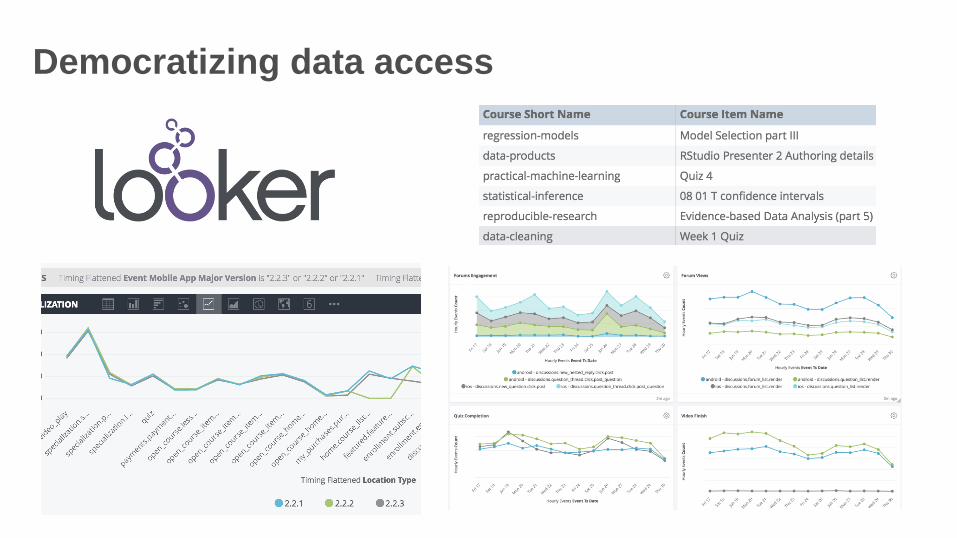
Democratizing data access

Learnings from 3 years on Amazon Redshift
• Thinking in Amazon Redshift
• Communicate to users
• Surprises
• Reflections

Thinking in Amazon Redshift
• Columnar
• SELECT * considered harmful in most cases

Thinking in Amazon Redshift
• Columnar
• SELECT * considered harmful in most cases
• Nodes, slices, blocks
• 1 MB blocks per slice, n slices per node depending on node type

Thinking in Amazon Redshift
• Columnar
• SELECT * considered harmful in most cases
• Nodes, slices, blocks
• 1 MB blocks per slice, n slices per node depending on node type
• Sorting and distribution
• Share nothing massively parallel processing => data is sorted per slice
• Up to 2 orders of magnitude increase in JOIN/GROUP BY for merge join vs hash join
Communicating to users
• Prefer the scientific method over gut feel
• Investigate how many rows were materialized with svl_query_report
• Understand EXPLAIN plan for data distribution, join strategy, predicate order

Communicating to users
• Prefer the scientific method over gut feel
• Investigate how many rows were materialized with svl_query_report
• Understand EXPLAIN plan for data distribution, join strategy, predicate order
• SQL style guide for readability
• Leading commas, capitalized SQL keywords, conventions for handling dates/timestamps,
conventions for table names, mapping tables

Communicating to users
• Prefer the scientific method over gut feel
• Investigate how many rows were materialized with svl_query_report
• Understand EXPLAIN plan for data distribution, join strategy, predicate order
• SQL style guide for readability
• Leading commas, capitalized SQL keywords, conventions for handling dates/timestamps,
conventions for table names, mapping tables
• Use the right tool for the right task
• Amazon Redshift is not for online traffic serving
• Amazon Redshift is not for stream processing

Surprises
• "Fundamental theorem of Redshift at Coursera"
• Most queries involve full table scans
• 9 nodes x 32 slices/node x 1 block/slice x 1 MB/block => at least 288 MB allocated per column
• Store ~75 M integer values and maintain 1 block per slice

Surprises
• "Fundamental theorem of Redshift at Coursera"
• Most queries involve full table scans
• 9 nodes x 32 slices/node x 1 block/slice x 1 MB/block => at least 288 MB allocated per column
• Store ~75 M integer values and maintain 1 block per slice
• Features may behave in unexpected fashions
• Sort key compression
• Primary and foreign keys

Surprises
• "Fundamental theorem of Redshift at Coursera"
• Most queries involve full table scans
• 9 nodes x 32 slices/node x 1 block/slice x 1 MB/block => at least 288 MB allocated per column
• Store ~75 M integer values and maintain 1 block per slice
• Features may behave in unexpected fashions
• Sort key compression
• Primary and foreign keys
• Features may be unexpectedly expensive
• COMMIT – Batch work, monitor with stl_commit_stats
• VACUUM – Prefer TRUNCATE, monitor with stl_vacuum, stl_query
• Your mileage may vary

Reflections
• Simplicity – Relational model, Postgres 8.0 compliant SQL, things just
work. Minimal administration. Minimal tuning.

Reflections
• Simplicity – Relational model, Postgres 8.0 compliant SQL, things just
work. Minimal administration. Minimal tuning.
• Scalability – Scaled cluster up 5 times in the last 3 years as data volume
and usage increased.

Reflections
• Simplicity – Relational model, Postgres 8.0 compliant SQL, things just
work. Minimal administration. Minimal tuning.
• Scalability – Scaled cluster up 5 times in the last 3 years as data volume
and usage increased.
• Flexibility – No strict requirement on data modeling; dusty knobs for
tuning in majority of cases. Handles both heavily normalized data model
and denormalized clickstream data.

Reflections
• Simplicity – Relational model, Postgres 8.0 compliant SQL, things just
work. Minimal administration. Minimal tuning.
• Scalability – Scaled cluster up 5 times in the last 3 years as data volume
and usage increased.
• Flexibility – No strict requirement on data modeling; dusty knobs for
tuning in majority of cases. Handles both heavily normalized data model
and denormalized clickstream data.
• Extensibility – Standard API (JDBC/ODBC/libpq) and integration points.

Resources
Pavan Pothukuchi | [email protected] |
Chris Liu | [email protected] |
Detail pages
• http://aws.amazon.com/redshift
• https://aws.amazon.com/marketplace/redshift/
Best practices
• http://docs.aws.amazon.com/redshift/latest/dg/c_loading-data-best-practices.html
• http://docs.aws.amazon.com/redshift/latest/dg/c_designing-tables-best-practices.html
• http://docs.aws.amazon.com/redshift/latest/dg/c-optimizing-query-performance.html
Related breakout sessions
• Deep Dive on Amazon QuickSight (2:15–3:15 pm)
• Getting Started with Amazon QuickSight (2:15–3:15 pm)
• Database Migration: Simple, Cross-Engine and Cross-Platform Migrations with Minimal Downtime (4:45–5:45 pm)





![Skaffold - storage.googleapis.com · [getting-started getting-started] Hello world! [getting-started getting-started] Hello world! [getting-started getting-started] Hello world! 5](https://img.pdfslide.us/doc/110x75/5ec939f2a76a033f091c5ac7/skaffold-getting-started-getting-started-hello-world-getting-started-getting-started.jpg)