Embed Size (px)
Citation preview

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Rick McFarland, Chief Data Scientist, Hearst Corporation
Adi Krishnan, Principal Product Manager, AWS
April 2016
Getting Started with
Amazon Kinesis

What to expect from this session
Amazon Kinesis: Getting started with streaming data on AWS
• Streaming scenarios
• Amazon Kinesis Streams overview
• Amazon Kinesis Firehose overview
• Firehose experience for Amazon S3 and Amazon Redshift
• The Life of a Click: How Hearst Publishing Manages Clickstream Analytics
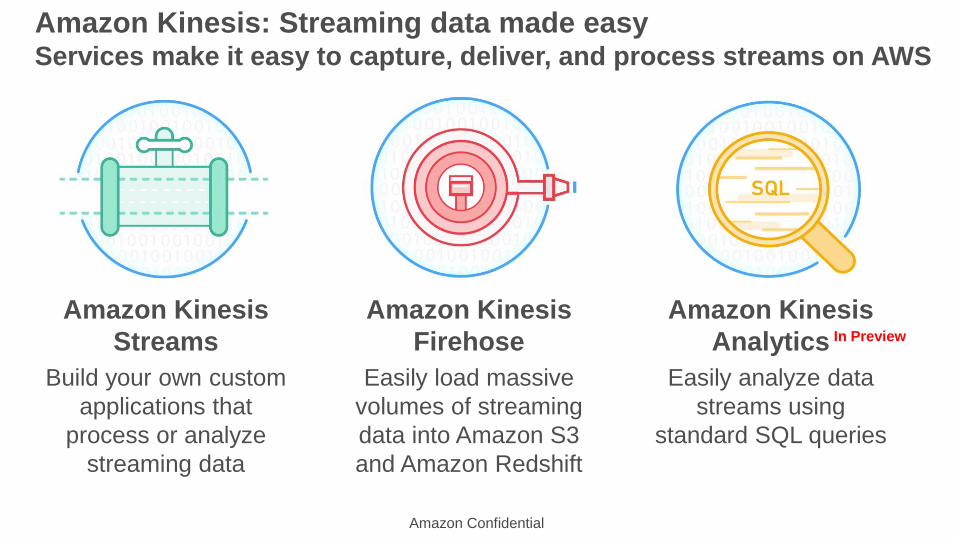
Amazon Kinesis
Streams
Build your own custom
applications that
process or analyze
streaming data
Amazon Kinesis
Firehose
Easily load massive
volumes of streaming
data into Amazon S3
and Amazon Redshift
Amazon Kinesis
Analytics
Easily analyze data
streams using
standard SQL queries
Amazon Kinesis: Streaming data made easyServices make it easy to capture, deliver, and process streams on AWS
Amazon Confidential
In Preview
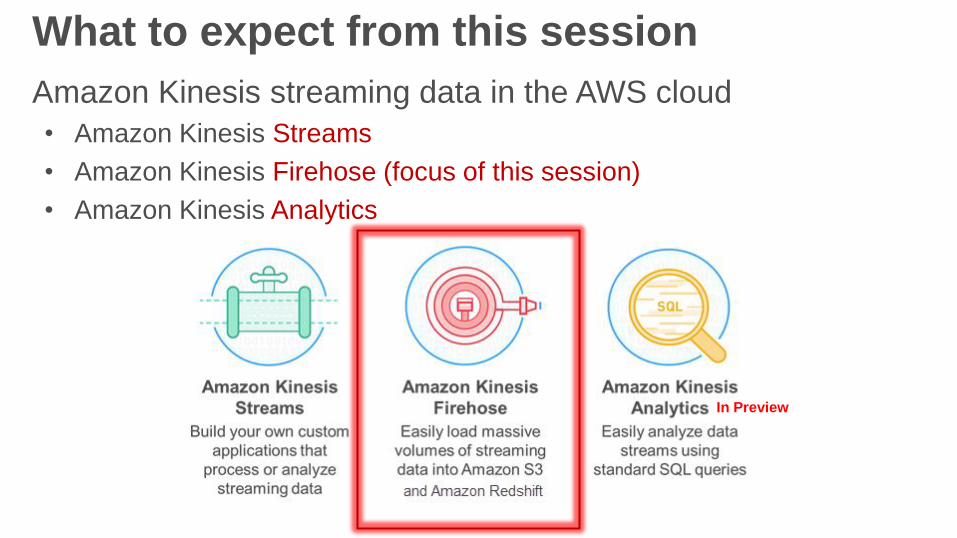
What to expect from this session
Amazon Kinesis streaming data in the AWS cloud
• Amazon Kinesis Streams
• Amazon Kinesis Firehose (focus of this session)
• Amazon Kinesis Analytics
In Preview

Scenarios Accelerated Ingest-
Transform-Load
Continual Metrics
Generation
Responsive Data
Analysis
Data Types IT logs, applications logs, social media / clickstreams, sensor or device data, market data
Ad/ Marketing
Tech
Publisher, bidder data
aggregation
Advertising metrics like
coverage, yield, conversion
Analytics on user
engagement with ads,
optimized bid / buy engines
IoT Sensor, device telemetry
data ingestion
IT operational metrics
dashboards
Sensor operational
intelligence, alerts, and
notifications
Gaming Online customer engagement
data aggregation
Consumer engagement
metrics for level success,
transition rates, CTR
Clickstream analytics,
leaderboard generation,
player-skill match engines
Consumer
Engagement
Online customer engagement
data aggregation
Consumer engagement
metrics like page views,
CTR
Clickstream analytics,
recommendation engines
Streaming data scenarios across segments
1 23

Amazon Kinesis: Streaming data done the AWS wayMakes it easy to capture, deliver, and process real-time data streams
Pay as you go, no upfront costs
Elastically scalable
Right services for your specific use cases
Real-time latencies
Easy to provision, deploy, and manage
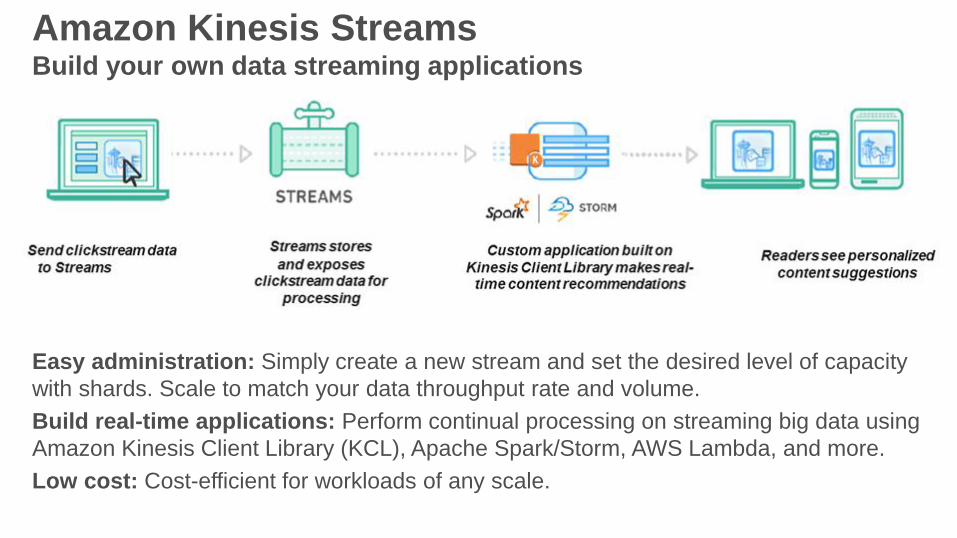
Amazon Kinesis StreamsBuild your own data streaming applications
Easy administration: Simply create a new stream and set the desired level of capacity
with shards. Scale to match your data throughput rate and volume.
Build real-time applications: Perform continual processing on streaming big data using
Amazon Kinesis Client Library (KCL), Apache Spark/Storm, AWS Lambda, and more.
Low cost: Cost-efficient for workloads of any scale.

Sending and reading data from Streams
AWS SDK
LOG4J
Flume
Fluentd
Get* APIs
Kinesis Client Library
+
Connector Library
Apache
Storm
Amazon Elastic
MapReduce
Sending Consuming
AWS Mobile
SDK
Kinesis
Producer
Library
AWS Lambda
Apache
Spark

Real-time streaming data ingestion
Custom-built
streaming
applications
Inexpensive: $0.014 per 1,000,000 PUT payload units
Amazon Kinesis StreamsManaged service for real-time processing

We listened to our customers…

Amazon Kinesis Streams select new features…
Kinesis Producer Library
PutRecords API, 500 records or 5 MB payload
Kinesis Client Library in Python, Node.JS, Ruby…
Server-side time stamps
Increased individual max record payload 50 KB to 1 MB
Reduced end-to-end propagation delay
Extended stream retention from 24 hours to 7 days

Amazon Kinesis Firehose
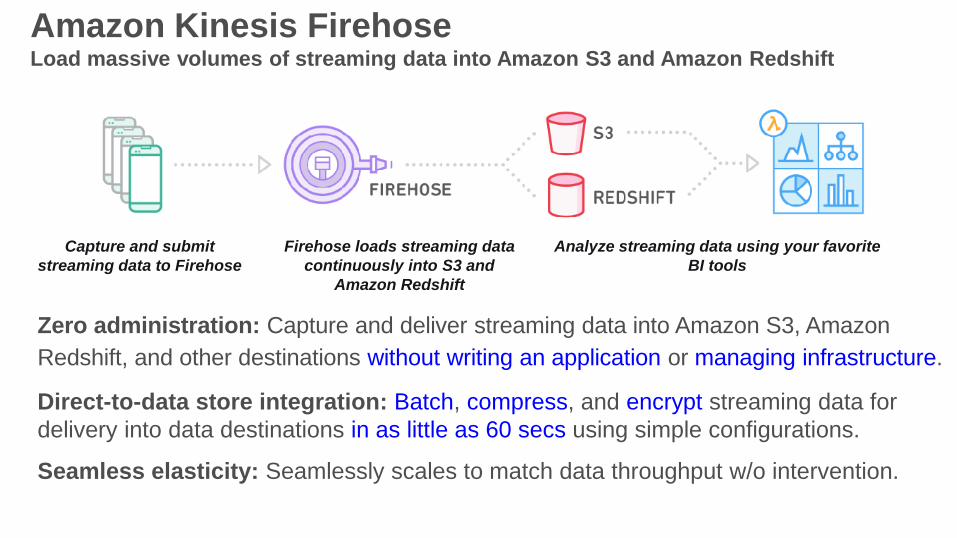
Amazon Kinesis FirehoseLoad massive volumes of streaming data into Amazon S3 and Amazon Redshift
Zero administration: Capture and deliver streaming data into Amazon S3, Amazon
Redshift, and other destinations without writing an application or managing infrastructure.
Direct-to-data store integration: Batch, compress, and encrypt streaming data for
delivery into data destinations in as little as 60 secs using simple configurations.
Seamless elasticity: Seamlessly scales to match data throughput w/o intervention.
Capture and submit
streaming data to Firehose
Firehose loads streaming data
continuously into S3 and
Amazon Redshift
Analyze streaming data using your favorite
BI tools

AWS Platform SDKs Mobile SDKs Kinesis Agent AWS IoT
Amazon S3 Amazon Redshift
• Send data from IT infra, mobile devices, sensors
• Integrated with AWS SDK, agents, and AWS IoT
• Fully managed service to capture streaming
data
• Elastic w/o resource provisioning
• Pay-as-you-go: 3.5 cents / GB transferred
• Batch, compress, and encrypt data before loads
• Loads data into Amazon Redshift tables by using
the COPY command
Amazon Kinesis Firehose
Capture IT and app logs, device and sensor data, and more Enable near-real time analytics using existing tools
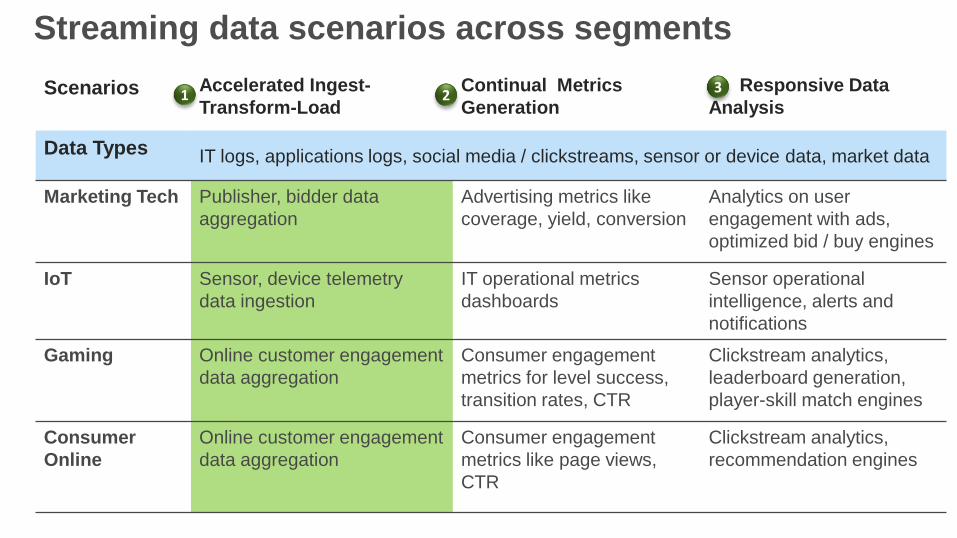
Scenarios Accelerated Ingest-
Transform-Load
Continual Metrics
Generation
Responsive Data
Analysis
Data Types IT logs, applications logs, social media / clickstreams, sensor or device data, market data
Marketing Tech Publisher, bidder data
aggregation
Advertising metrics like
coverage, yield, conversion
Analytics on user
engagement with ads,
optimized bid / buy engines
IoT Sensor, device telemetry
data ingestion
IT operational metrics
dashboards
Sensor operational
intelligence, alerts and
notifications
Gaming Online customer engagement
data aggregation
Consumer engagement
metrics for level success,
transition rates, CTR
Clickstream analytics,
leaderboard generation,
player-skill match engines
Consumer
Online
Online customer engagement
data aggregation
Consumer engagement
metrics like page views,
CTR
Clickstream analytics,
recommendation engines
Streaming data scenarios across segments
1 23

Amazon Kinesis Firehose
Customer Experience

1. Delivery stream: The underlying entity of Firehose. Use Firehose by
creating a delivery stream to a specified destination and send data to it.
• You do not have to create a stream or provision shards.
• You do not have to specify partition keys.
2. Records: The data producer sends data blobs as large as 1,000 KB to a
delivery stream. That data blob is called a record.
3. Data Producers: Producers send records to a delivery stream. For
example, a web server that sends log data to a delivery stream is a data
producer.
Amazon Kinesis Firehose Three simple concepts

Amazon Kinesis Firehose console experience Unified console experience for Firehose and Streams

Amazon Kinesis Firehose console (S3) Create fully managed resources for delivery without building an app

Amazon Kinesis Firehose console (S3) Configure data delivery options simply using the console

Amazon Kinesis Firehose console (Amazon Redshift)Configure data delivery to Amazon Redshift simply using the console

Amazon Kinesis agent
Software agent makes submitting data to Firehose easy
• Monitors files and sends new data records to your delivery stream
• Handles file rotation, check pointing, and retry upon failures
• Preprocessing capabilities such as format conversion and log parsing
• Delivers all data in a reliable, timely, and simple manner
• Emits Amazon CloudWatch metrics to help you better monitor and
troubleshoot the streaming process
• Supported on Amazon Linux AMI with version 2015.09 or later, or Red Hat
Enterprise Linux version 7 or later; install on Linux-based server
environments such as web servers, front ends, log servers, and more
• Also enabled for Streams

Amazon Kinesis Firehose pricingSimple, pay-as-you-go, and no up-front costs
Dimension Value
Per 1 GB of data ingested $0.035

Amazon Kinesis Firehose or Amazon Kinesis Streams?

Amazon Kinesis Streams is a service for workloads that requires
custom processing, per incoming record, with sub-1-second
processing latency, and a choice of stream processing frameworks.
Amazon Kinesis Firehose is a service for workloads that require
zero administration, ability to use existing analytics tools based
on S3 or Amazon Redshift, and a data latency of 60 seconds or
higher.

Amazon Kinesis Analytics
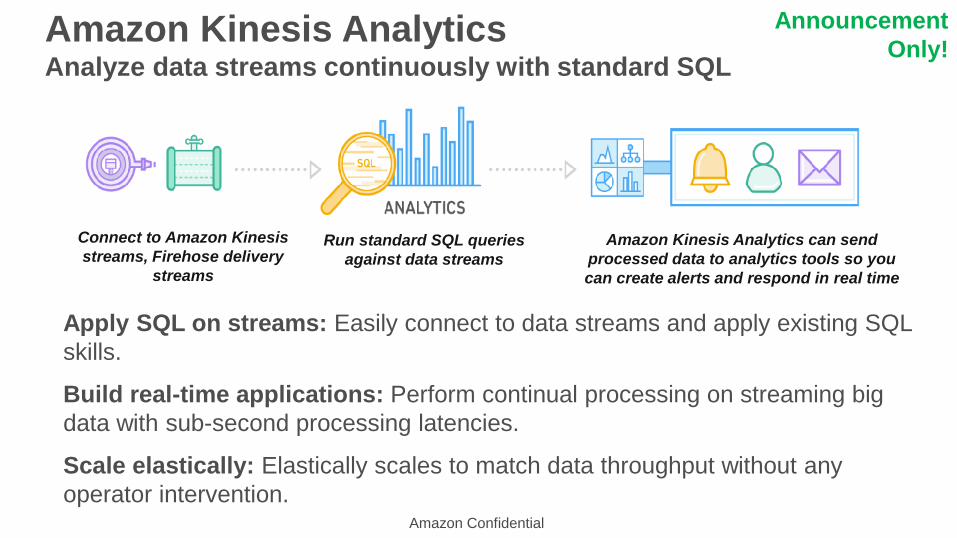
Amazon Kinesis AnalyticsAnalyze data streams continuously with standard SQL
Apply SQL on streams: Easily connect to data streams and apply existing SQL
skills.
Build real-time applications: Perform continual processing on streaming big
data with sub-second processing latencies.
Scale elastically: Elastically scales to match data throughput without any
operator intervention.
Announcement
Only!
Amazon Confidential
Connect to Amazon Kinesis
streams, Firehose delivery
streams
Run standard SQL queries
against data streams
Amazon Kinesis Analytics can send
processed data to analytics tools so you
can create alerts and respond in real time

The Life of a ClickHow Hearst Publishing Manages Clickstream AnalyticsRick McFarland April 2016
?
Clickstream Data
Building a Data Pipeline
Lessons Learned
Questions &Answers
Agenda

The Evolution of“Chasing the Customer”
PastNear Past
Now!
Survey Websites Every Electronic Device
100–1000 Responses 1 MM–1 BN Trillions
1 Week Daily Seconds
Survey Data Clickstream Data “Lifestream” Data
Collection
Volume
Speed
Description “Thoughtstream” Data?
When will it stop?
Nanobots?
Won’t matter!
Future?

A Clickstream is the real-time transmission, collection, and processing of the actions visitors make on websites…and now across all devices!
Action Data
Scrolling or mouse movement
Event Data
Highlighting text, listening to audio, playing video
Geospatial Data
Lat/Lon, GPS, movement, proximity
Sensor Data
Pulse, gait, body temperature

Premium and Global ScaleThe Power of Hearst
Magazines20 U.S. titles & nearly 300 international titles
Newspapers15 daily & 34 weekly titles
Broadcasting30 television & 2 radio stations
Business MediaOperates more than 20 business-to businesses with
significant holdings in the auto, electronic, medical and financial industriesWhat this means for our data
Hearst has over 250 websites, which results in 100 GB of data per day and over 20 billion pageviews per year.

Hearst Data Services aims to ensure that all combined data assets are leveraged across the corporation
Unify Hearst’s data streams
Development of big data analytics
platform
Promote enterprise-wide product development

Hearst Data Services in Action
Product initiative led by all editors at Hearst
Buzzing@Hearst

Demo: Buzzing@Hearst

The Business Value ofBuzzing@HearstReal-time reactions Instant feedback on articles from our audiences
Promoting popular content cross-channelIncremental resyndication of popular articles across properties(e.g., trending newspaper articles can be adopted by magazines)
Authentic influenceInform Hearst editors to write articles that are more relevant to our audiences
Understanding engagementInform both editors what channels are our audiences leveraging to read Hearst articles
INCREMENTAL REVENUE
25% more page views
15% more visitors

Engineering Requirements ofBuzzing@Hearst
Throughput goalTransport data from all 250+ Hearst properties worldwide
Latency goalClick-to-tool in under 5 min.
Agile interface Easily add new data fields into clickstream
Unique metricsRequirements defined by Data Science team (e.g., standard deviations, regressions, etc.)
Reporting windowData reporting window ranges from 1 hour to 1 week
Front-end developmentDeveloped “from scratch”, so data exposed through API must support development team’s unique requirements

Engineering Requirements ofBuzzing@Hearst
Operational ConsistencyMost importantly, operation of the existing sites cannot be affected

Where We StartedA Static Clickstream Across Hearst
Users on Hearst properties
Corporate data center
Netezza data warehouse
Clickstream Once per day
~30 GB per day containing basic
web log data (e.g., referrer, URL, user agent, cookie, etc.)
Used for ad hoc SQL-based
reporting and analytics

A Look at the 4 Phases ofHearst’s Data Pipeline
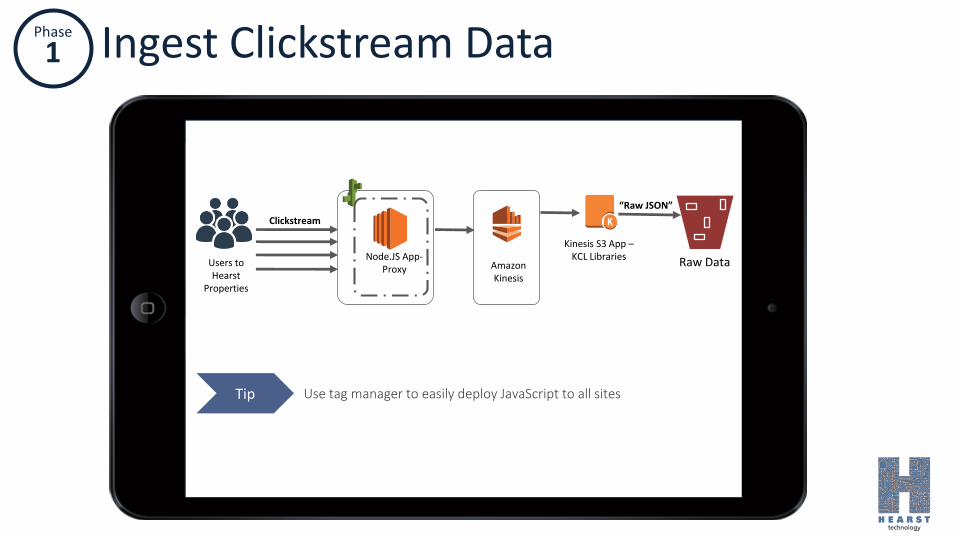
Ingest Clickstream Data
Amazon Kinesis
Node.JS App-Proxy
Kinesis S3 App –KCL Libraries
Users to Hearst
Properties
Clickstream
“Raw JSON”
Raw Data
Tip Use tag manager to easily deploy JavaScript to all sites
Phase
1

Phase
1 Summary
Making it easyUse JSON formatting for payloads so more fields can be easily added without impacting downstream processing
Making it smoothHTTP call requires minimal code introduced to the actual site implementations
Making it flexibleMust be able to meet rollout and growing demand. AWS Elastic Beanstalk can be scaled, and Amazon Kinesis stream can be re-sharded
Making it durableAmazon S3 provides high durability storage for raw data
Once a reliable, scalable onboarding platform is in place, we can focus on ETL
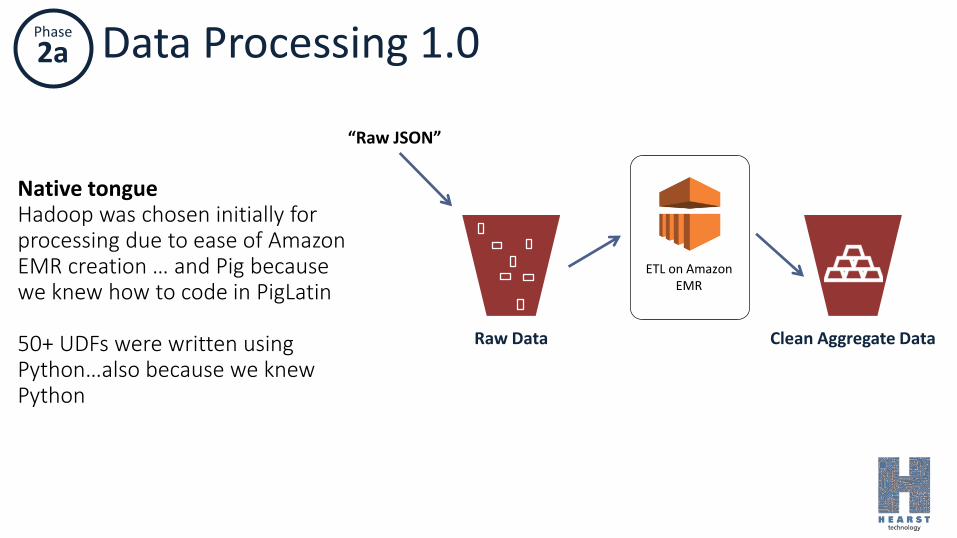
Phase
2a Data Processing 1.0
ETL on Amazon EMR
Clean Aggregate DataRaw Data
“Raw JSON”
Native tongueHadoop was chosen initially for processing due to ease of Amazon EMR creation … and Pig because we knew how to code in PigLatin
50+ UDFs were written using Python…also because we knew Python
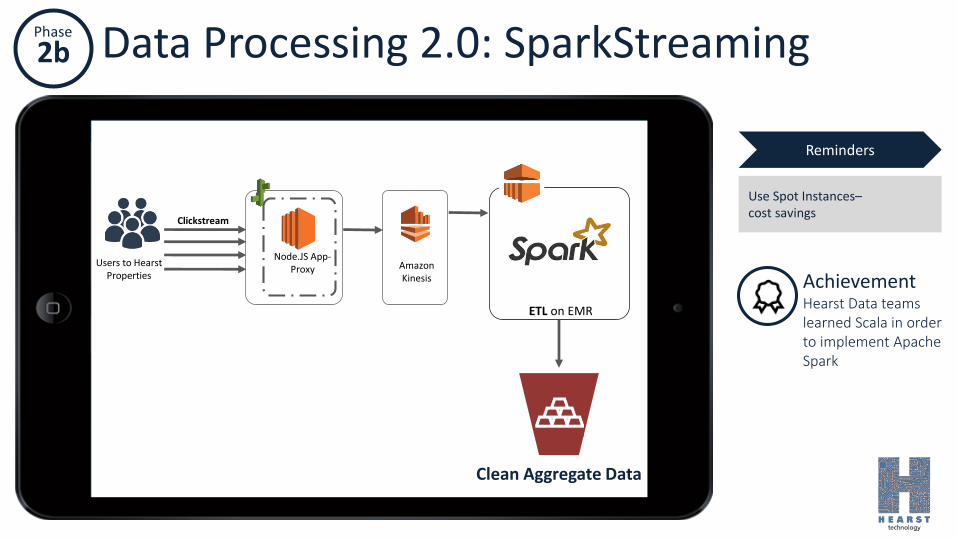
Phase
2b Data Processing 2.0: SparkStreaming
Amazon Kinesis
Node.JS App-Proxy
Users to Hearst Properties
Clickstream
ETL on EMR
Clean Aggregate Data
Use Spot Instances–cost savings
Reminders
AchievementHearst Data teams learned Scala in order to implement Apache Spark
Phase
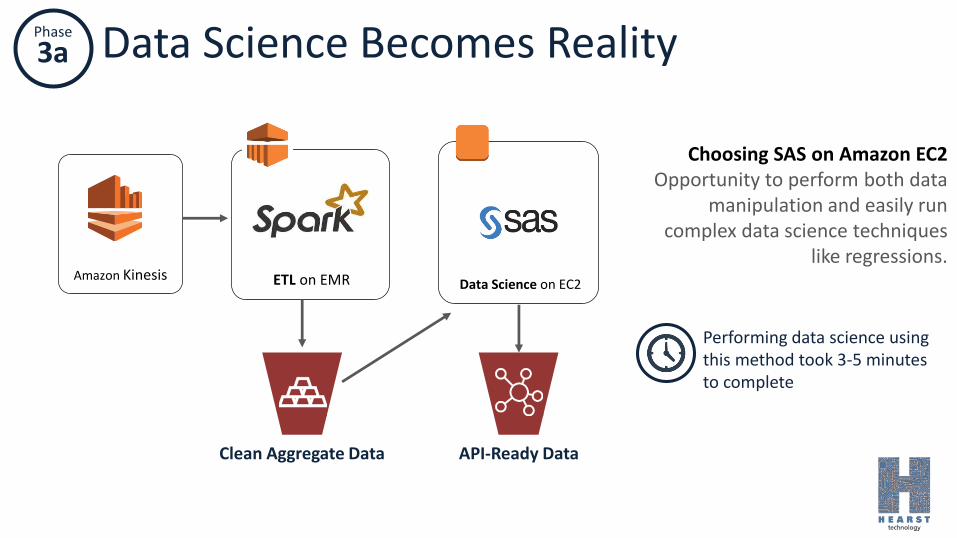
3a Data Science Becomes Reality
Data Science on EC2Amazon Kinesis ETL on EMR
Clean Aggregate Data API-Ready Data
Choosing SAS on Amazon EC2Opportunity to perform both data
manipulation and easily run complex data science techniques
like regressions.
Performing data science using this method took 3-5 minutes to complete
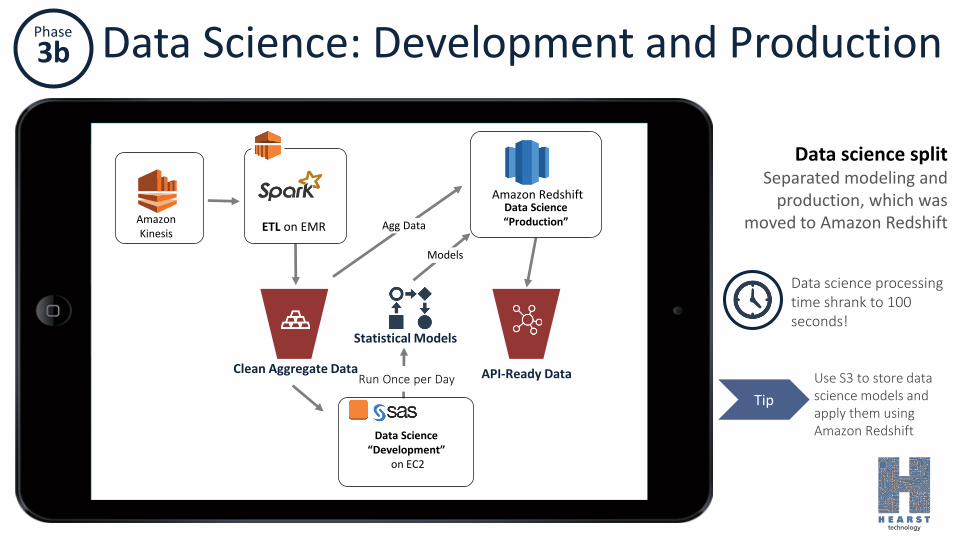
Phase
3b Data Science: Development and Production
Amazon Kinesis
Data Science“Production”
Amazon Redshift
ETL on EMR
Data Science “Development”
on EC2
Run Once per Day
Models
Agg Data
Clean Aggregate Data API-Ready Data
Statistical Models
Tip
Use S3 to store data science models and apply them using Amazon Redshift
Data science splitSeparated modeling and
production, which was moved to Amazon Redshift
Data science processing time shrank to 100 seconds!
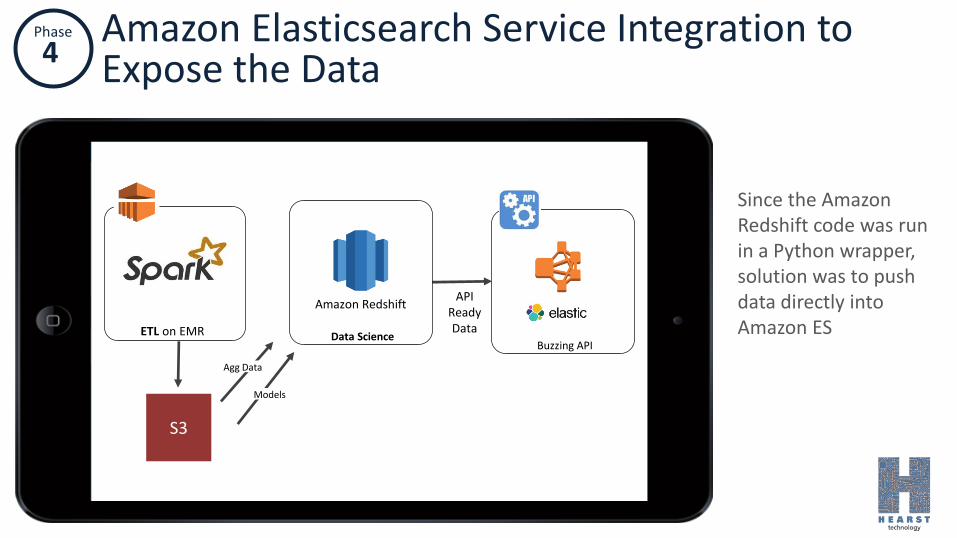
Phase
4Amazon Elasticsearch Service Integration to Expose the Data
Since the Amazon Redshift code was run in a Python wrapper, solution was to push data directly into Amazon ES
Buzzing API
APIReadyData
Data Science
Amazon Redshift
ETL on EMR
Models
Agg Data
S3
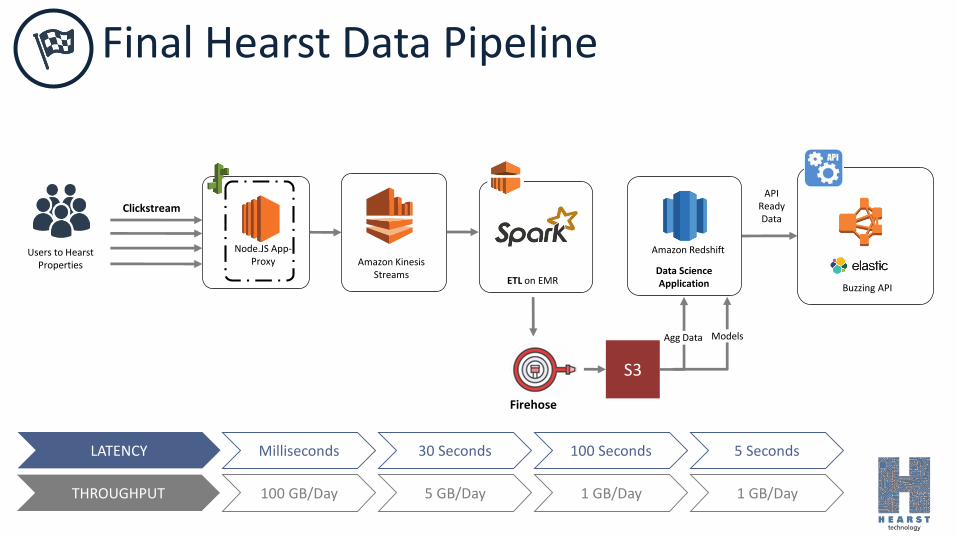
Buzzing API
APIReadyData
Amazon KinesisStreams
Node.JS App-Proxy
Clickstream
Data ScienceApplication
Amazon Redshift
ETL on EMR
Users to Hearst Properties
Final Hearst Data Pipeline
LATENCY
THROUGHPUT
Milliseconds 30 Seconds 100 Seconds 5 Seconds
100 GB/Day 5 GB/Day 1 GB/Day 1 GB/Day
Agg Data Models
Firehose
S3

Amazon
Kinesis
Big
Data
Spark
ApacheAmazon
Redshift
Results
API
Turning Data into Diamonds

A Look at OurLessons Learned

A Look at OurLessons Learned
Yesterday
Today
Tomorrow
Amazon Kinesis
Amazon Kinesis
Amazon Kinesis
S3 EMR-Pig
Spark-Scala
PySpark + SparkR
Amazon Redshift
EC2-SASS3
S3
S3EMR to
Amazon ES
Amazon ES
Amazon ES
1 hr
< 5 min
< 2 min
Transport Storage ETL Storage Analysis Storage Exposure Latency

Clickstreams Are the New “Data Currency” of Business
You can actually “do more with
less”
You don’t need a big team : This can all be done with a team of 2-3 FTEs
…Or 1 very rare individual




![Skaffold - storage.googleapis.com · [getting-started getting-started] Hello world! [getting-started getting-started] Hello world! [getting-started getting-started] Hello world! 5](https://img.pdfslide.us/doc/110x75/5ec939f2a76a033f091c5ac7/skaffold-getting-started-getting-started-hello-world-getting-started-getting-started.jpg)