Embed Size (px)
Citation preview

Ensuring QoS in Multi-‐tenant Hadoop EnvironmentsEliminate contention and guarantee SLAs
Sean SuchterCEO & Co-‐founder, Pepperdata

©2016 Pepperdata
4 QoS use cases
1. Queue vs. queue (scheduler QoS)
2. HBase vs. ad hoc
3. ETL vs. ad hoc (MapReduce vs. MapReduce)
4. Spikes in swapping

©2016 Pepperdata
Situation 1: Queue vs. Queue
©2016 Pepperdata
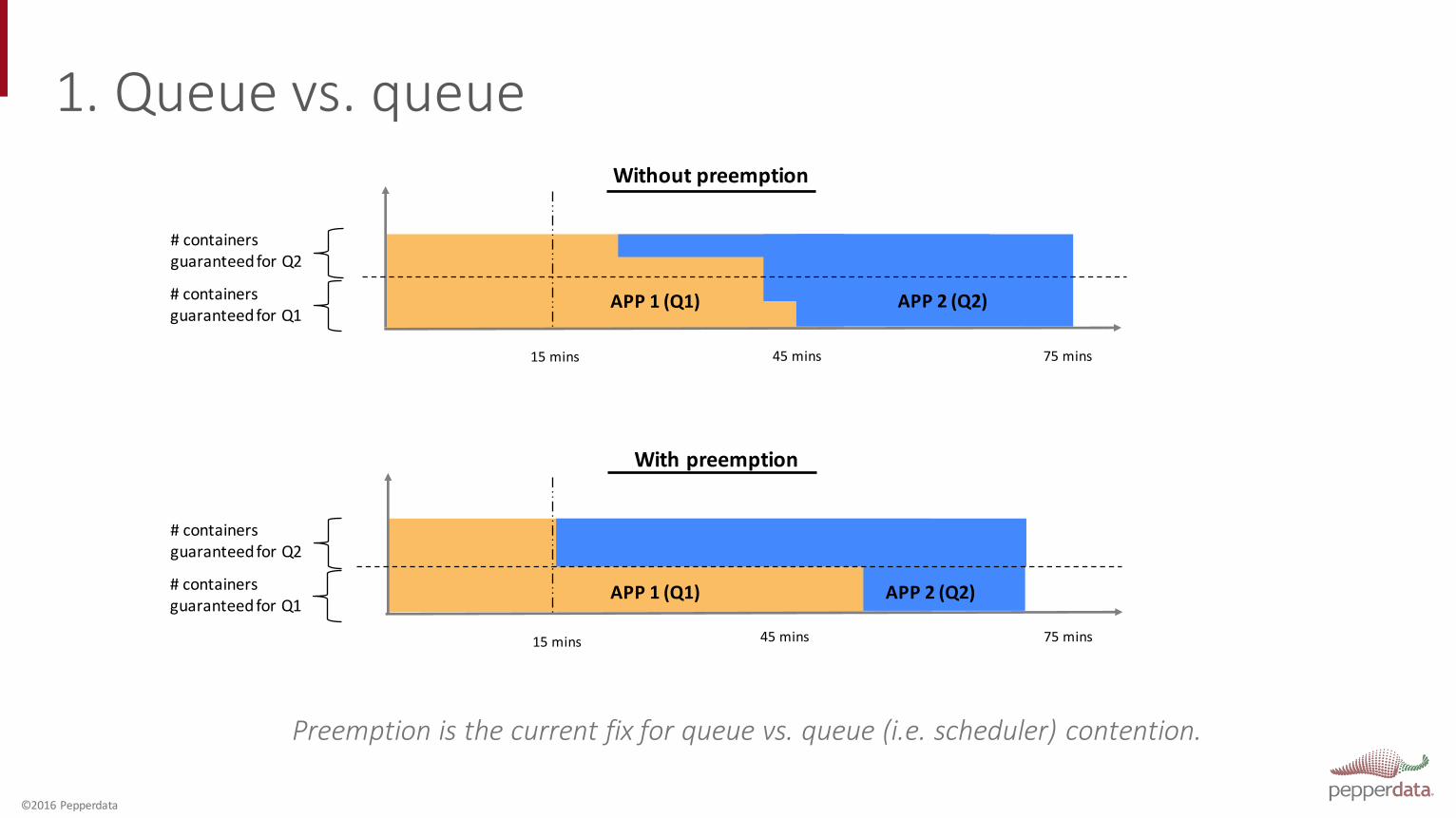
1. Queue vs. queue
Preemption is the current fix for queue vs. queue (i.e. scheduler) contention.
Without preemption
With preemption
15 mins
15 mins
45 mins
45 mins
75 mins
75 mins
APP 1 (Q1) APP 2 (Q2)
APP 1 (Q1) APP 2 (Q2)
# containers guaranteed for Q2
# containers guaranteed for Q1
# containers guaranteed for Q2
# containers guaranteed for Q1

©2016 Pepperdata
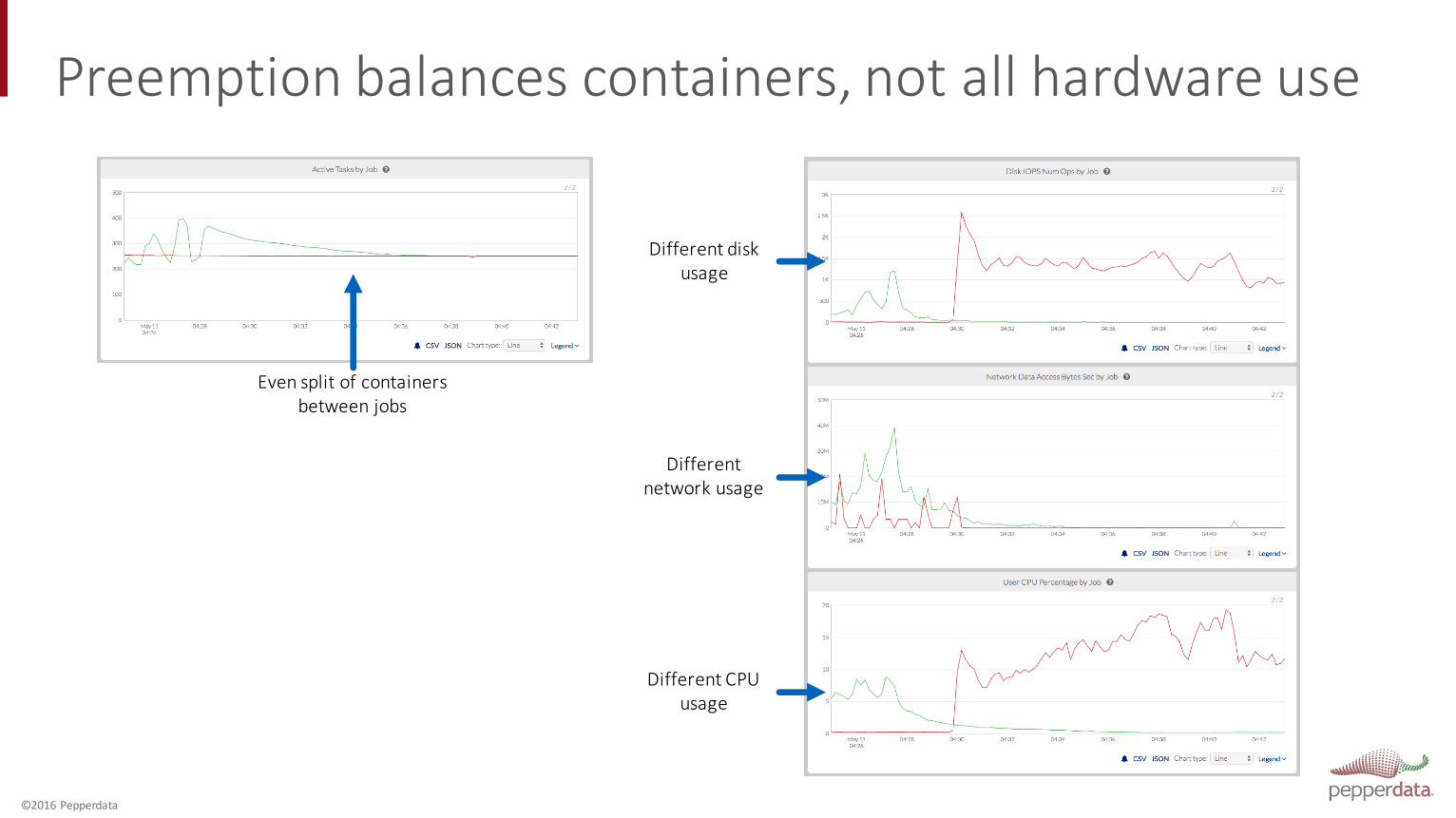
Preemption balances container/task counts, but…
• Preemption requires killing containers to start new ones• Wastes work
• Preemption only balances containers among queues• Does not balance disk I/O, network, etc.
©2016 Pepperdata
Preemption balances containers, not all hardware use
Different disk usage
Even split of containers between jobs
Different network usage
Different CPU usage

©2016 Pepperdata
Situation 2: HBase vs. Ad Hoc
©2016 Pepperdata
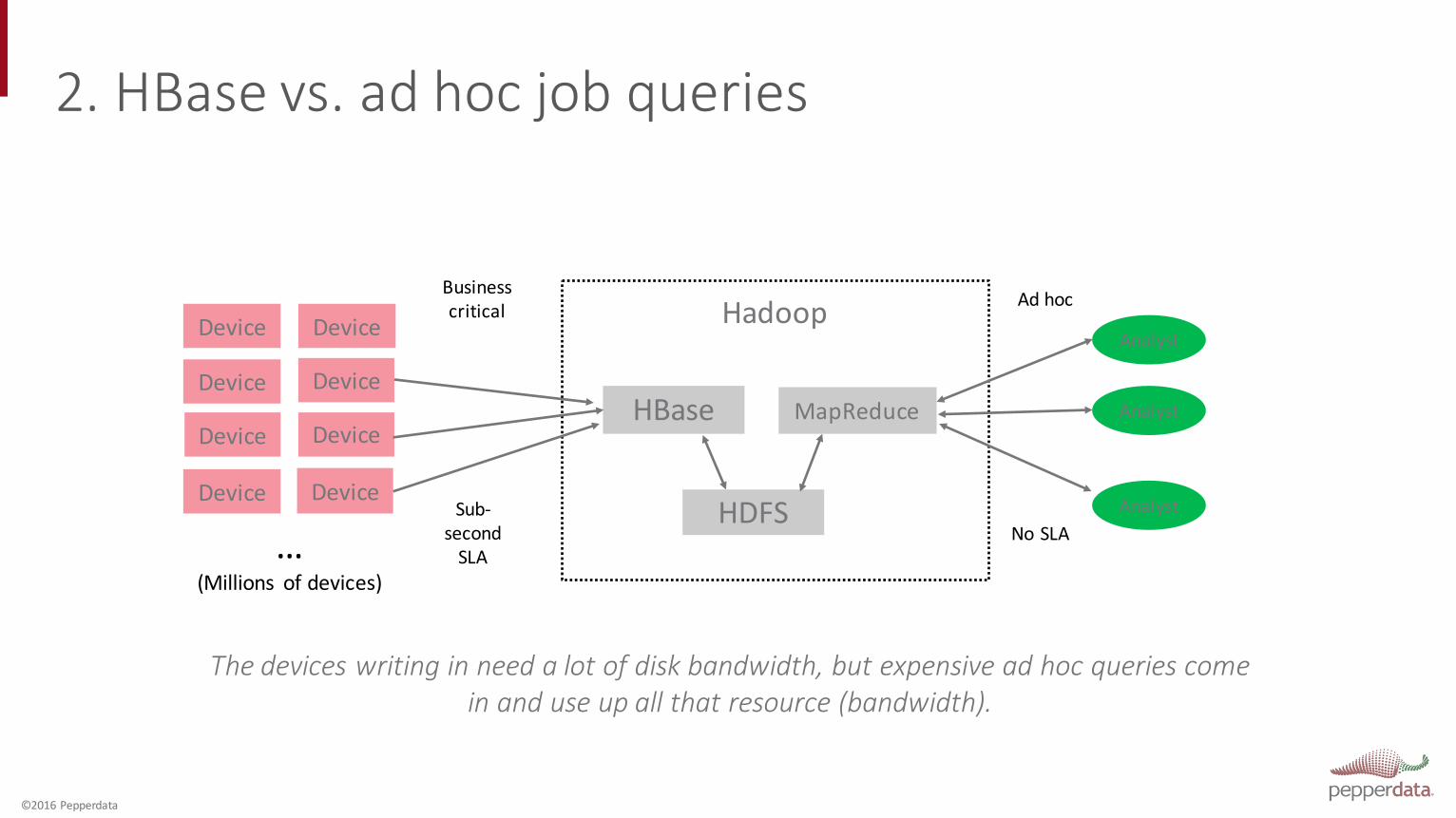
2. HBase vs. ad hoc job queries
Device
HBase
Analyst
MapReduce
Sub-‐second SLA
Hadoop
HDFS
Ad hoc
Device
Device
Device
Device
Device
Device
Device
Business critical
Analyst
AnalystNo SLA…
(Millions of devices)
The devices writing in need a lot of disk bandwidth, but expensive ad hoc queries come in and use up all that resource (bandwidth).

©2016 Pepperdata
What might you try….
Scale out HBase Use HBase online snapshots
Have separate HBase cluster
Physically separate HBase and MapReduce
©2016 Pepperdata
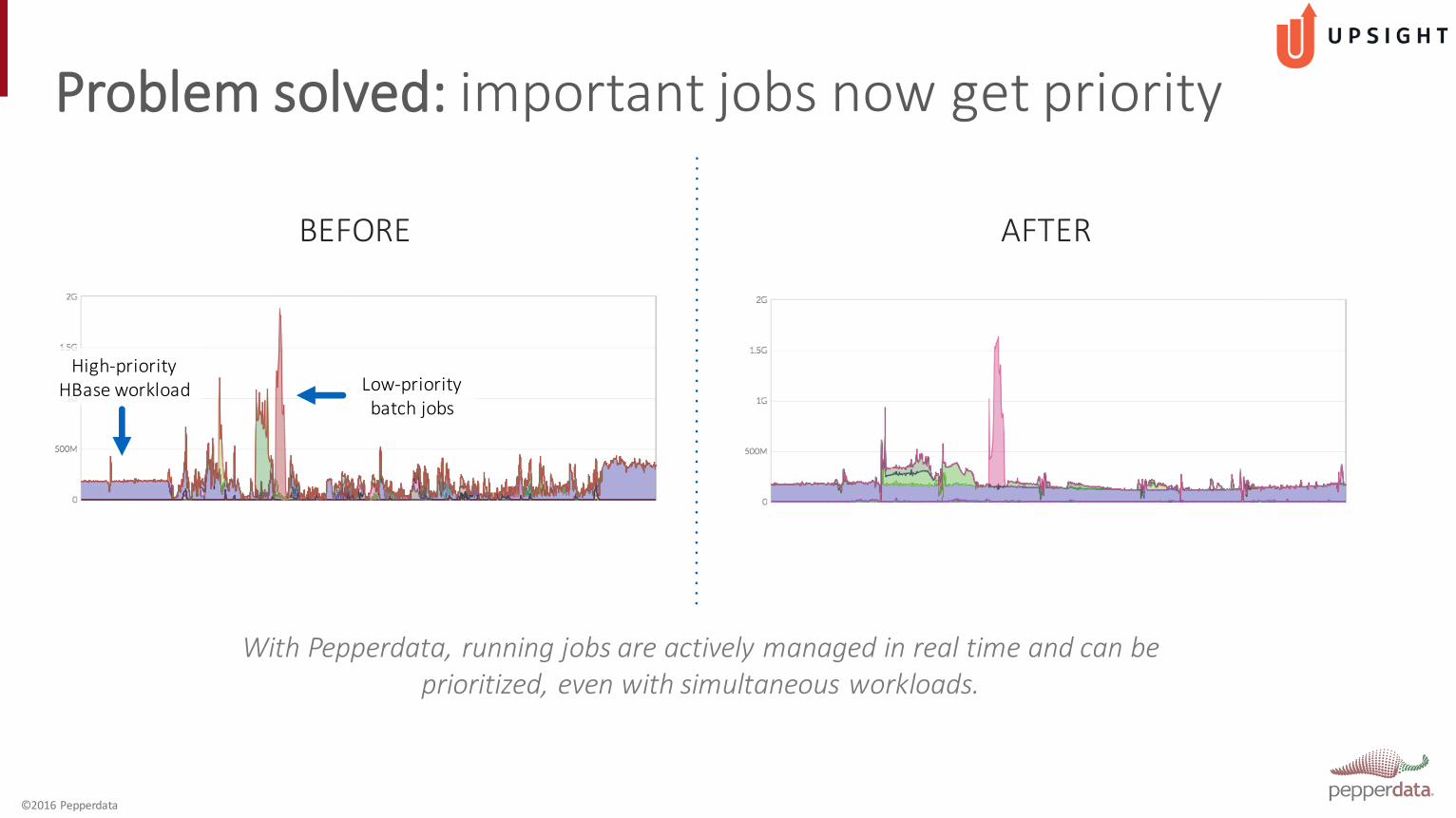
With Pepperdata, running jobs are actively managed in real time and can be prioritized, even with simultaneous workloads.
Low-‐priority batch jobs
High-‐priority HBase workload
BEFORE AFTER
Problem solved: important jobs now get priority

©2016 Pepperdata
Situation 3: ETL vs. Ad Hoc

©2016 Pepperdata
3. ETL vs. ad hoc (aka MapReduce vs. MapReduce)
• Customer example:• Online provider of real estate data
• Hundred nightly jobs that have to run, with hard and fast SLAs
• Pulling from many data sources (batch and streaming) and in real time
• Need to ensure SLAs for business critical jobs
©2016 Pepperdata
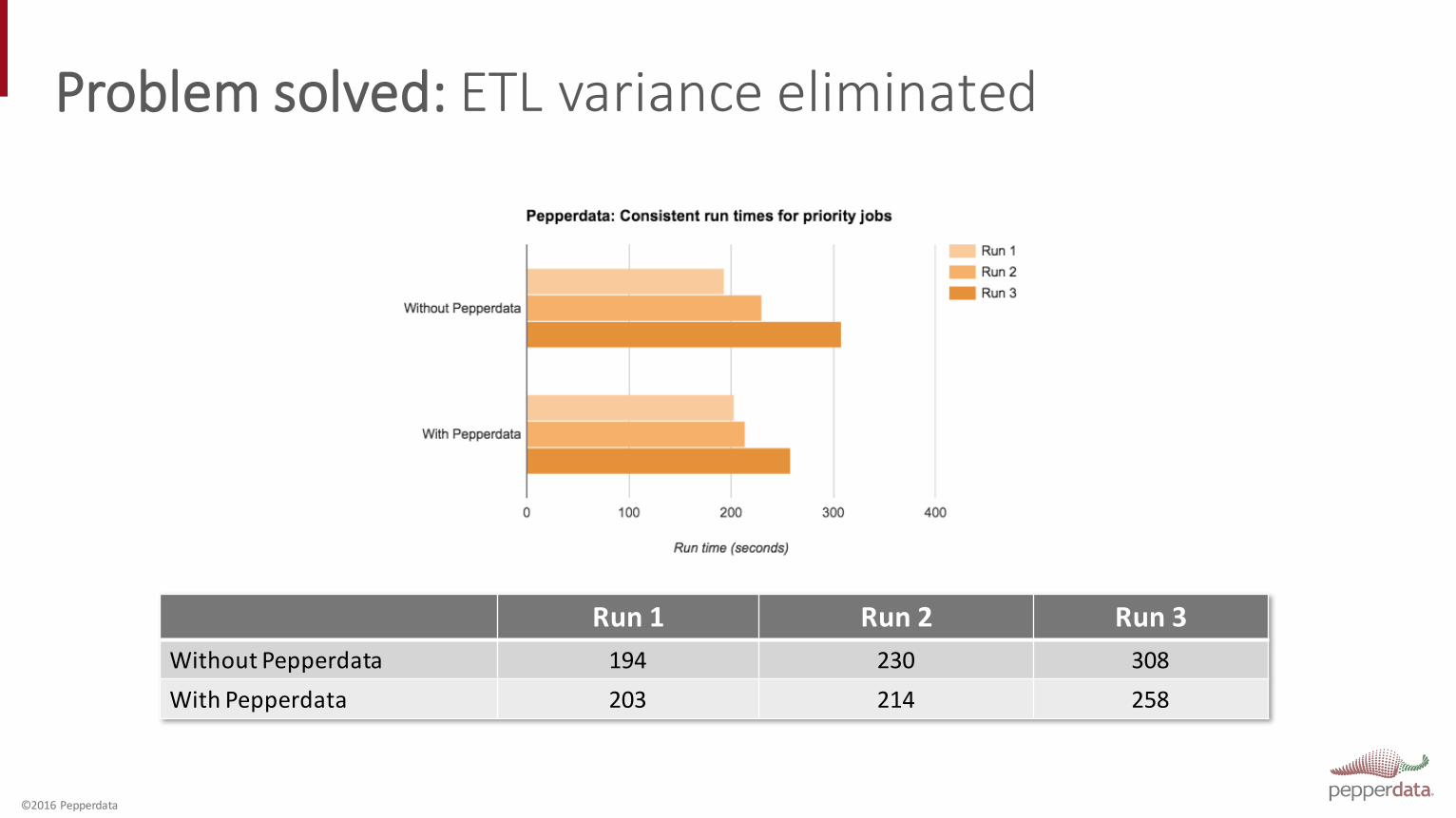
Problem solved: ETL variance eliminated
Run 1 Run 2 Run 3Without Pepperdata 194 230 308With Pepperdata 203 214 258

©2016 Pepperdata
Situation 4: Spikes in Swapping
©2016 Pepperdata
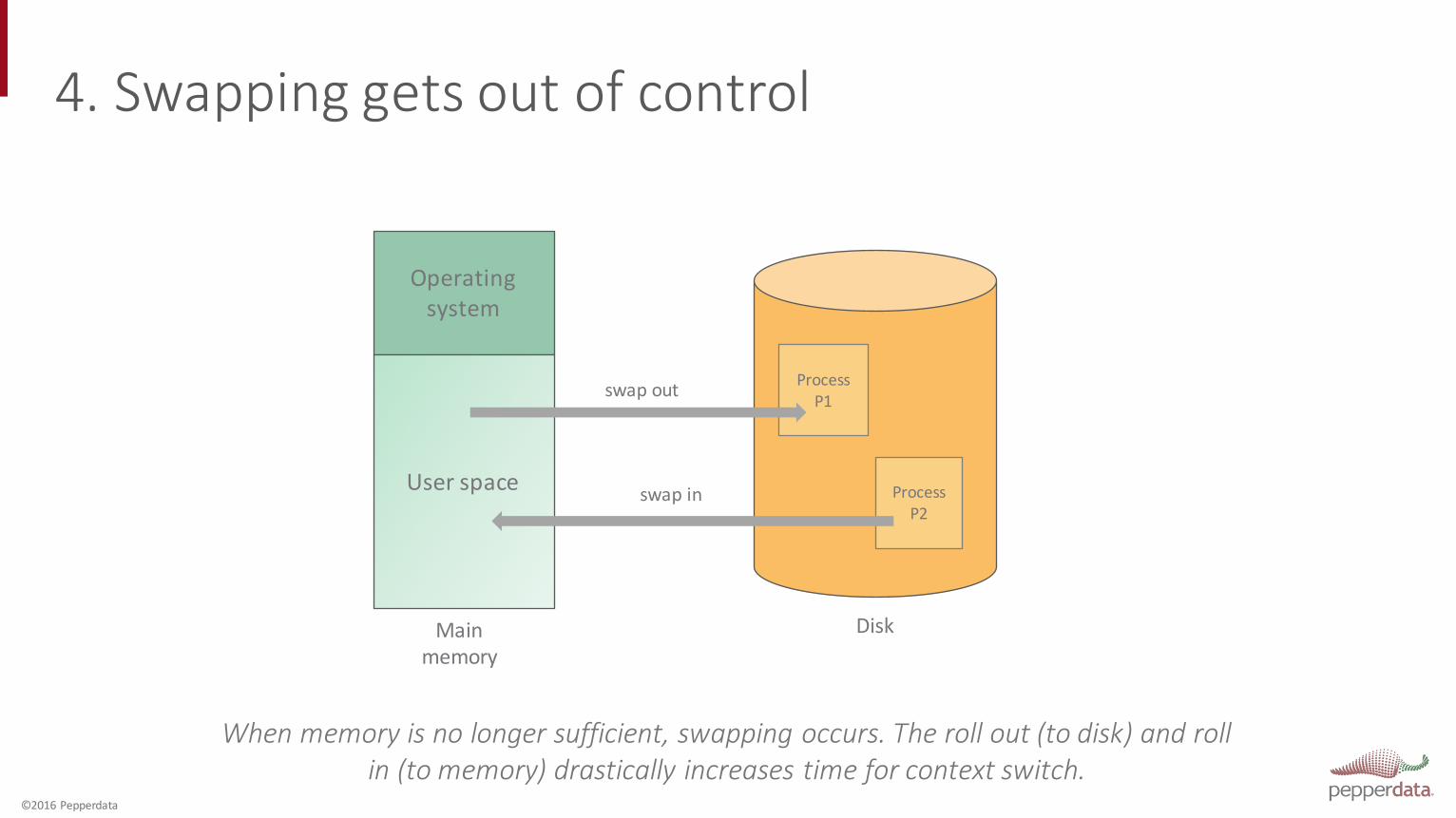
4. Swapping gets out of control
Process P1
Process P2
Disk
Operating system
User space
Mainmemory
swap out
swap in
When memory is no longer sufficient, swapping occurs. The roll out (to disk) and roll in (to memory) drastically increases time for context switch.
©2016 Pepperdata
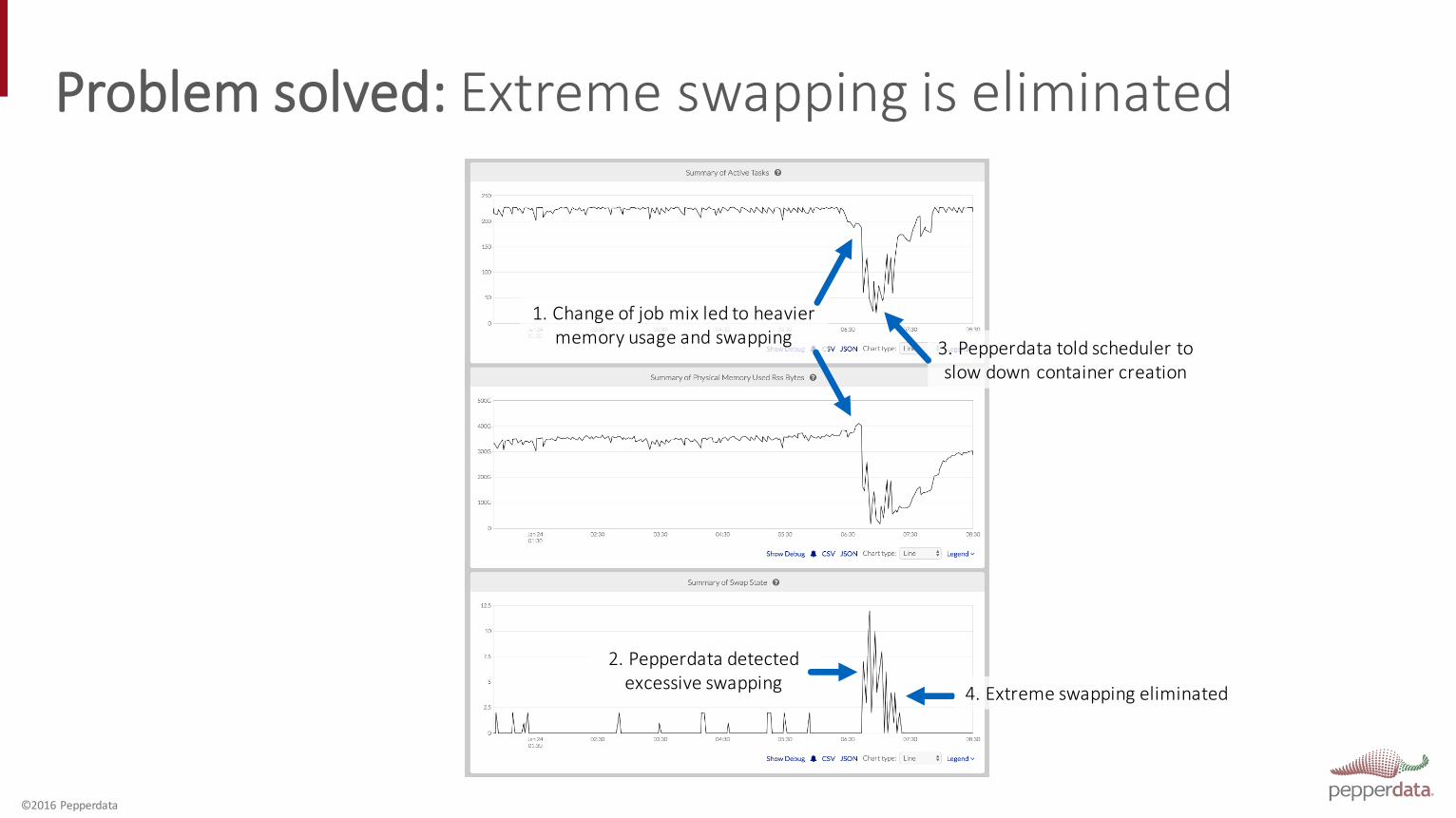
Problem solved: Extreme swapping is eliminated
1. Change of job mix led to heavier memory usage and swapping
2. Pepperdata detected excessive swapping
3. Pepperdata told scheduler to slow down container creation
4. Extreme swapping eliminated

©2016 Pepperdata
Summary
• QoS is imperative to guaranteeing SLAs in multi-‐tenant, multi-‐workload Hadoop environments.
• All size Hadoop deployments need QoS – not just for huge clusters!
• Traditional solutions (i.e. preemption) do not solve real-‐time contention problems or monitor actual hardware utilization.
• To guarantee QoS for Hadoop, you need a real-‐time, dynamic solution that actively reshapes cluster activity.

©2016 Pepperdata
THANK YOU

©2016 Pepperdata
Appendix




























