Embed Size (px)
Citation preview

Ensuring Performance in a Fast-Paced Environment
Martin Spier Performance Engineering @ Netflix
@spiermar [email protected]
Performance & Capacity 2014 by CMG

Martin Spier ● Performance Engineer @ Netflix ● Previously @ Expedia and Dell ● Performance
o Architecture, Tuning and Profiling o Testing and Frameworks o Tool Development
● Blog @ http://overloaded.io ● Twitter @spiermar

● World's leading Internet television network ● ⅓ of all traffic heading into American homes at
peak hours ● > 50 million members ● > 40 countries ● > 1 billion hours of TV shows and movies per
month ● > 100s different client devices

Agenda ● How Netflix Works
o Culture, Development Model, High-level Architecture, Platform
● Ensuring Performance o Auto-Scaling, Squeeze Tests, Simian Army, Hystrix,
Redundancy, Canary Analysis, Performance Test Framework, Large Scale Tests

● Culture deck* is TRUE o 9M+ views
● Minimal process ● Context over control ● Root access to everything ● No approvals required ● Only Senior Engineers
Freedom and Responsibility
* http://www.slideshare.net/reed2001/culture-1798664

Independent Development Teams ● Highly aligned, loosely coupled ● Free to define release cycles ● Free to choose use any methodology ● But it’s an agile environment ● And there is a “paved road”

Development Agility ● Continuous innovation cycle ● Shorter development cycles ● Automate everything! ● Self-service deployments ● A/B Tests ● Failure cost close to zero ● Lower time to market ● Innovation > Risk
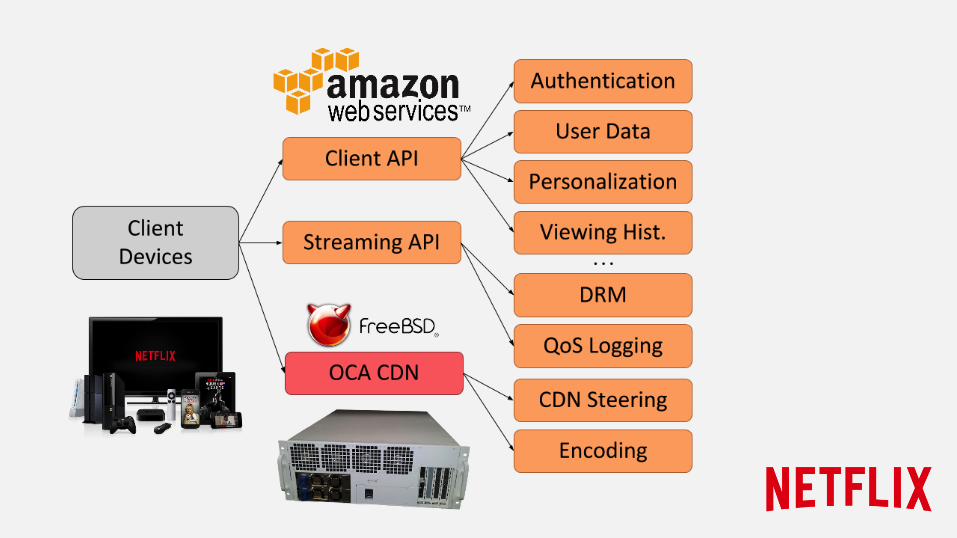

Architecture ● Scalable and Resilient ● Micro-services ● Stateless ● Assume Failure ● Backwards Compatible ● Service Discovery
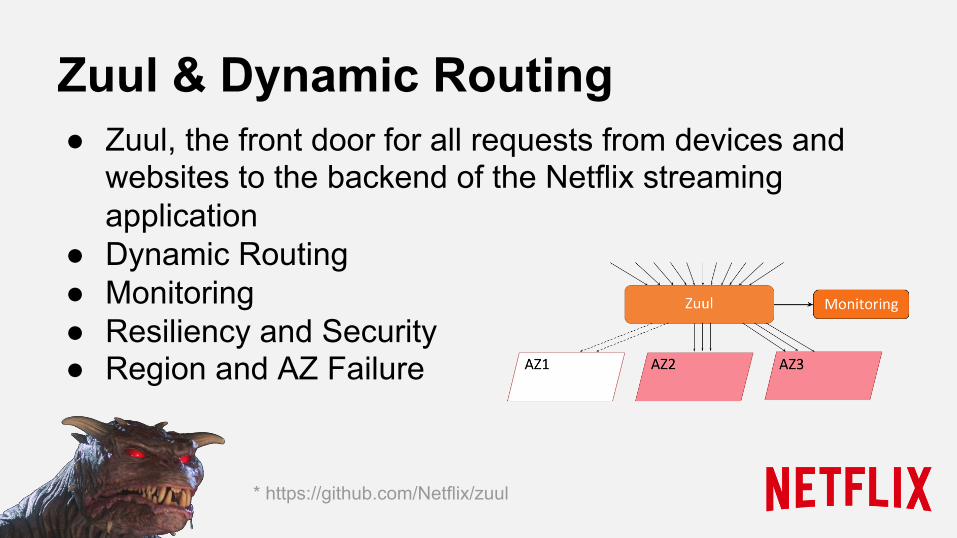
Zuul & Dynamic Routing ● Zuul, the front door for all requests from devices and
websites to the backend of the Netflix streaming application
● Dynamic Routing ● Monitoring ● Resiliency and Security ● Region and AZ Failure
* https://github.com/Netflix/zuul

Cloud ● Amazon’s AWS ● Multi-region Active/Active ● Ephemeral Instances ● Auto-Scaling ● Netflix OSS (https://github.com/Netflix)

Performance Engineering ● Not a part of any development team ● Not a shared service ● Through consultation improve and maintain the
performance and reliability ● Provide self-service performance analysis utilities ● Disseminate performance best practices ● And we’re hiring!

What about Performance?
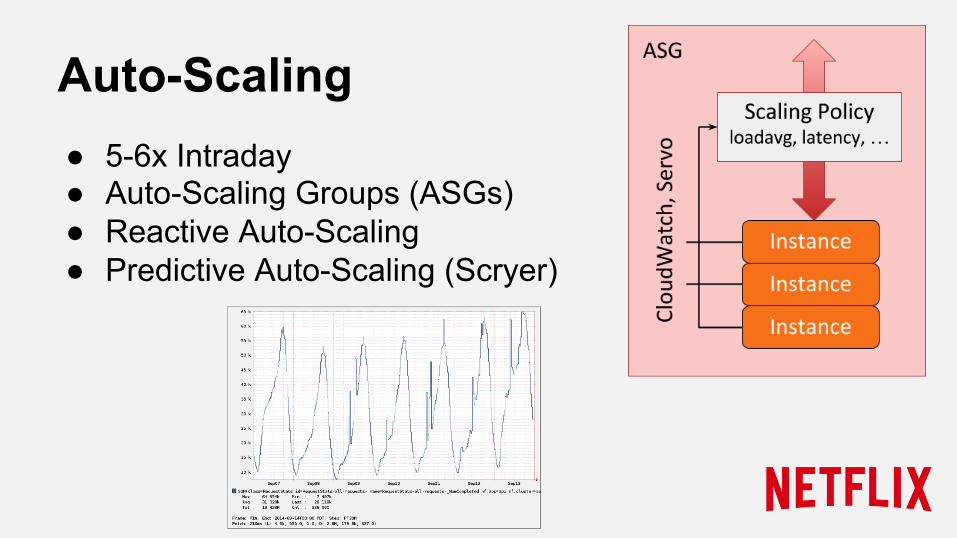
● 5-6x Intraday ● Auto-Scaling Groups (ASGs) ● Reactive Auto-Scaling ● Predictive Auto-Scaling (Scryer)
Auto-Scaling

Squeeze Tests ● Stress Test, with Production Load ● Steering Production Traffic ● Understand the Upper Limits of Capacity ● Adjust Auto-Scaling Policies ● Automated Squeeze Tests
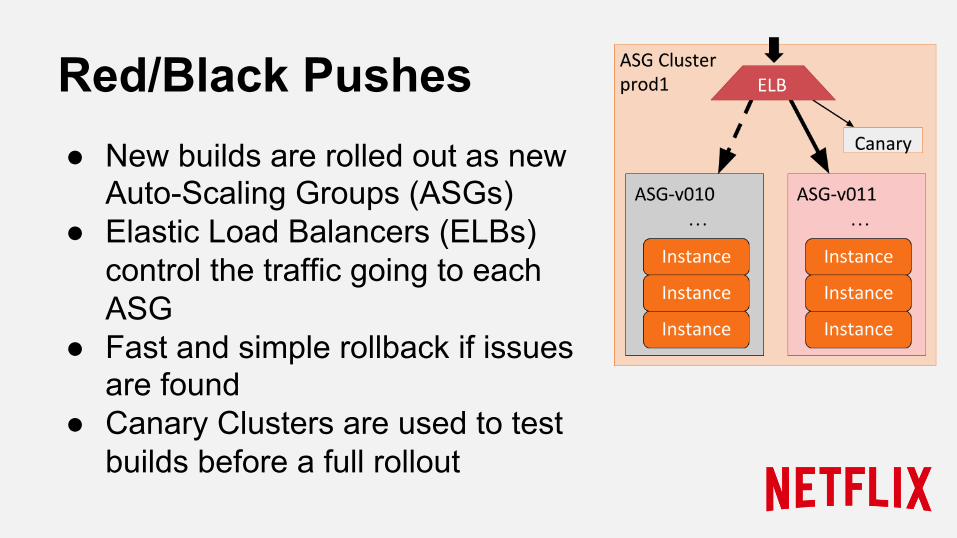
Red/Black Pushes ● New builds are rolled out as new
Auto-Scaling Groups (ASGs) ● Elastic Load Balancers (ELBs)
control the traffic going to each ASG
● Fast and simple rollback if issues are found
● Canary Clusters are used to test builds before a full rollout

Monitoring: Atlas ● Humongous, 1.2 billion distinct time
series ● Integrated to all systems, production
and test ● 1 minute resolution, quick roll ups ● 12-month persistence ● API and querying UI ● System and Application Level ● Servo (github.com/Netflix/servo) ● Custom dashboards

Vector ● 1 second Resolution ● No Persistence ● Leverages Performance Co-
Pilot (PCP) ● System-level Metrics ● Java Metrics (parfait) ● ElasticSearch, Cassandra ● Flame Graphs (Brendan Gregg)
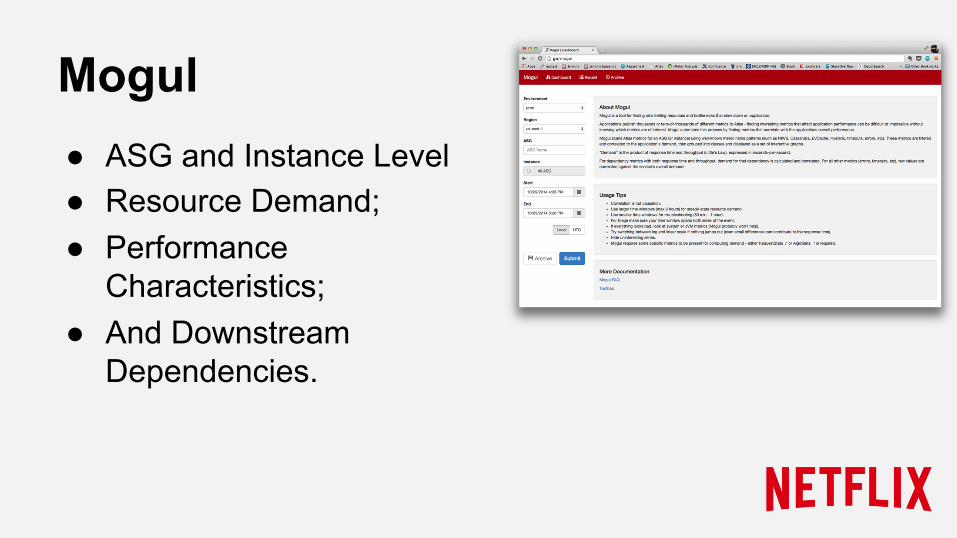
Mogul ● ASG and Instance Level ● Resource Demand; ● Performance
Characteristics; ● And Downstream
Dependencies.

Slalom ● Cluster Level ● High-level Demand Flow ● Cross-application Request
Tracing ● Downstream and Upstream
Demand

Canary Release
“Canary release is a technique to reduce the risk of introducing a new software version in
production by slowly rolling out the change to a small subset of users before rolling it out to the entire infrastructure and making it available to
everybody.”

Automatic Canary Analysis (ACA)
Exactly what the name implies. An automated way of analyzing a canary release.

ACA: Use Case ● You are a service owner and have finished
implementing a new feature into your application. ● You want to determine if the new build, v1.1, is
performing analogous to the existing build. ● The new build is deployed automatically to a canary
cluster ● A small percentage of production traffic is steered to the
canary cluster ● After a short period of time, canary analysis
is triggered

Automated Canary Analysis ● For a given set of metrics, ACA will compare
samples from baseline and canary; ● Determine if they are analogous; ● Identify any metrics that deviate from the
baseline; ● And generate a score that indicates the overall
similarity of the canary.

Automated Canary Analysis ● The score will be associated
with a Go/No-Go decision; ● And the new build will be
rolled out (or not) to the rest of the production environment.
● No workload definitions ● No synthetic load

When is it appropriate?
What about pre-production Performance
Testing?

Not always!
Sometimes it doesn't make sense to run performance tests.

Remember the short release cycles?
With the short time span between production builds,
pre-production tests don’t warn us much sooner. (And there’s ACA)

When it brings value. Not just because is part of a process.
So when?

When? Use Cases ● New Services ● Large Code Refactoring ● Architecture Changes ● Workload Changes ● Proof of Concept ● Initial Cluster Sizing ● Instance Type Migration

Use Cases, cont. ● Troubleshooting ● Tuning ● Teams that release less frequently
o Intermediary Builds ● Base Components (Paved Road)
o Amazon Cloud Images (AMIs) o Platform o Common Libraries

Who? ● Push “tests” to development teams ● Development understands the product, they
developed It ● Performance Engineering knows the tools
and techniques (so we help!) ● Easier to scale the effort!

How? Environment ● Free to create any environment configuration ● Integration stack ● Full production-like or scaled-down environment ● Hybrid model
o Performance + integration stack ● Production testing
How? Test Framework ● Built around JMeter

How? Test Framework
● Runs on Amazon’s EC2 ● Leverages Jenkins for orchestration

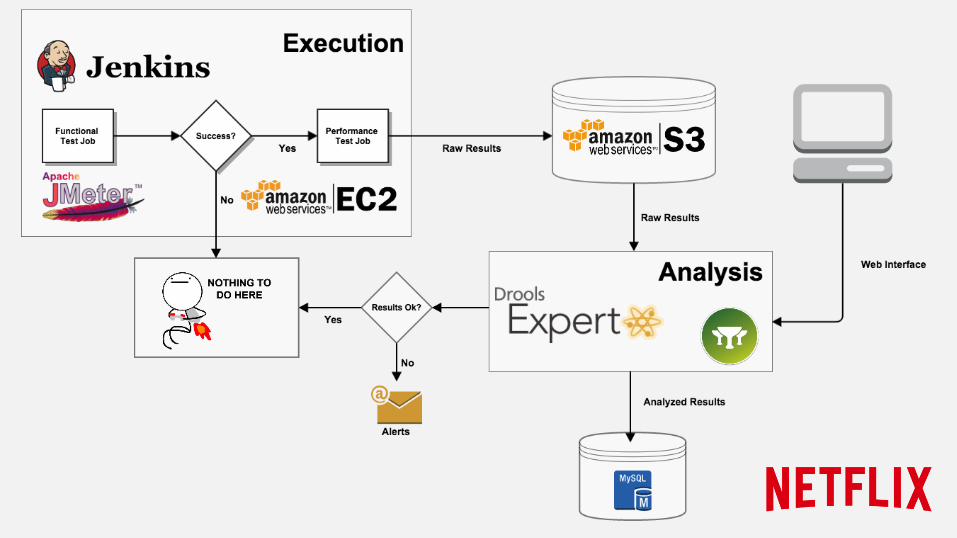
How? Analysis
● In-house developed web analysis tool and API ● Results persisted on Amazon’s S3 and RDS

How? Analysis
● Automated analysis built-in (thresholds) ● Customized alerts ● Interface with monitoring tools

Large Scale Tests ● > 100k req/s ● > 100 of load generators ● High Throughput Components
o In-Memory Caches ● Component scaling ● Full production tests

Large Scale Tests: Problems ● Your test client is likely the first bottleneck ● Components are (often) not designed to
scale o Great performance per node; o But they don’t scale horizontally. o Controller, data feeder, load generator*, result
collection, result analysis, monitoring
* often the exception

Large Scale Tests: Single Controller ● Single controller, multiple load generators ● Controller also serves as data feeder ● Controller collects all results synchronously ● Controller aggregates monitoring data ● Batch and async might alleviate the problem ● Analysis of large result sets is heavy (think
percentiles)

Large Scale Tests: Distributed Model ● Data Feeding and Load Generation
o No Controller o Independent Load Generators
● Data Collection and Monitoring o Decentralized Monitoring Platform
● Data Analysis o Aggregation at node level o Hive/Pig o ElasticSearch

Takeaways ● Canary analysis ● Testing only when it brings VALUE ● Leveraging cloud for tests ● Automated test analysis ● Pushing execution to development teams ● Open source tools

References ● parfait (https://code.google.com/p/parfait/) ● servo (https://github.com/Netflix/servo) ● hystrix (https://github.com/Netflix/Hystrix) ● culture deck (
http://www.slideshare.net/reed2001/culture-1798664) ● zuul (https://github.com/Netflix/zuul) ● scryer (
http://techblog.netflix.com/2013/11/scryer-netflixs-predictive-auto-scaling.html)

Backup Slides

Simian Army ● Ensures cloud handles failures
through regular testing ● The Monkeys
o Chaos Monkey: Resiliency o Latency: Artificial Delays o Conformity: Best-practices o Janitor: Unused Instances o Doctor: Health checks o Security: Security Violations o Chaos Gorilla: AZ Failure o Chaos Kong: Region Failure

“... is a latency and fault tolerance library designed to
isolate points of access to remote systems ...”
* https://github.com/Netflix/Hystrix
● Stop cascading failures. ● Fallbacks and graceful degradation ● Fail fast and rapid recovery ● Thread and semaphore isolation with
circuit breakers ● Real-time monitoring and
configuration changes

Real-time Analytics Platform (RTA) ● ACA runs on top of RTA ● Compute Engines
o OpenCPU (R) o OpenPY (Python)
● Data Sources o Real-time Monitoring Systems o Big Data Platforms
● Reporting, Scheduling, Persistence

● Deviation => “acceptable” regression ● Small performance regressions might sneak in ● Short release cycle = many releases ● Many releases = cumullative regression
Slow Performance Regression
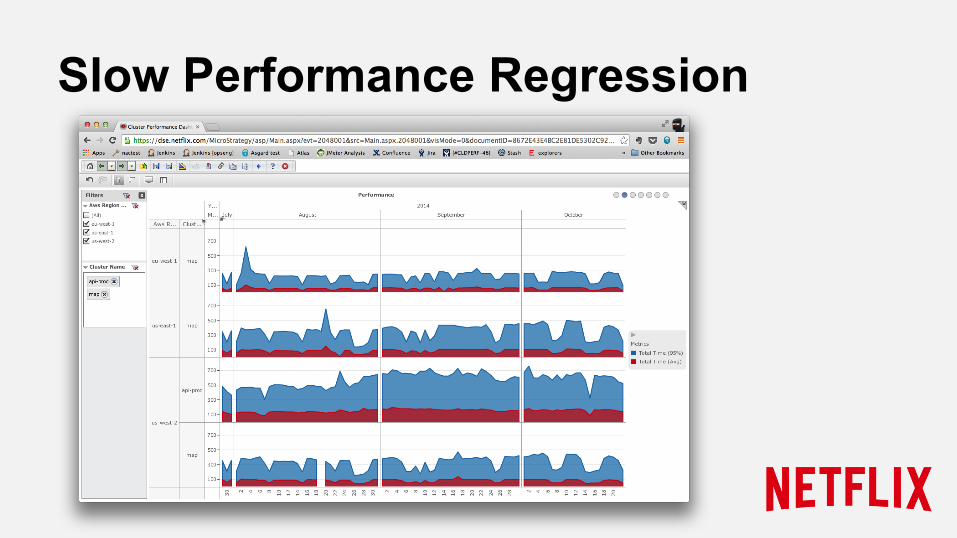
Slow Performance Regression

Testing Lower Level Components ● Base AMIs
o OS (Linux), tools and agents ● Common Application Platform ● Common Libraries ● Reference Application
o Leverages a common architecture (front, middle, data, memcache, jar clients, Hystrix)
o Implements functions that stress specific resources (cpu, service, db)






























