Embed Size (px)
Citation preview
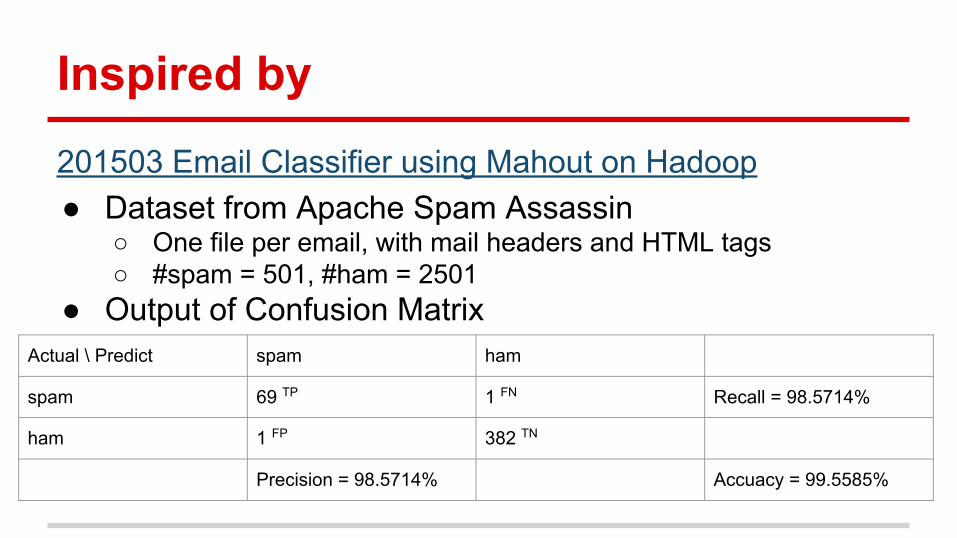
Inspired by201503 Email Classifier using Mahout on Hadoop● Dataset from Apache Spam Assassin
○ One file per email, with mail headers and HTML tags○ #spam = 501, #ham = 2501
● Output of Confusion Matrix
Actual \ Predict spam ham
spam 69 TP 1 FN Recall = 98.5714%
ham 1 FP 382 TN
Precision = 98.5714% Accuacy = 99.5585%

Using Decision Tree (1)def spam2Feature(sc: SparkContext, inpath:String, features:Int, lable:Double) = { val tf = new HashingTF(numFeatures = features) val dataRaw: RDD[(String, String)] = sc. wholeTextFiles(inpath) val dataLabeled: RDD[LabeledPoint] = tf. transform( dataRaw.map { case (file, text) => text. split(" ").toList } ).map{ features => LabeledPoint(lable, features) } dataLabeled}val spampath = "file:///home/leo/spam/20030228.spam"val hampath = "file:///home/leo/spam/20030228.easyham"val labeledSpam = spam2Feature(sc, spampath, 100, 1.0D)val labeledHam = spam2Feature(sc, hampath, 100, 0.0D)labeledSpam.cache();labeledHam.cache()
val Array(dataTrain, dataCV, dataTest) = (labeledSpam.union(labeledHam)).randomSplit(Array(0.8, 0.1, 0.1))
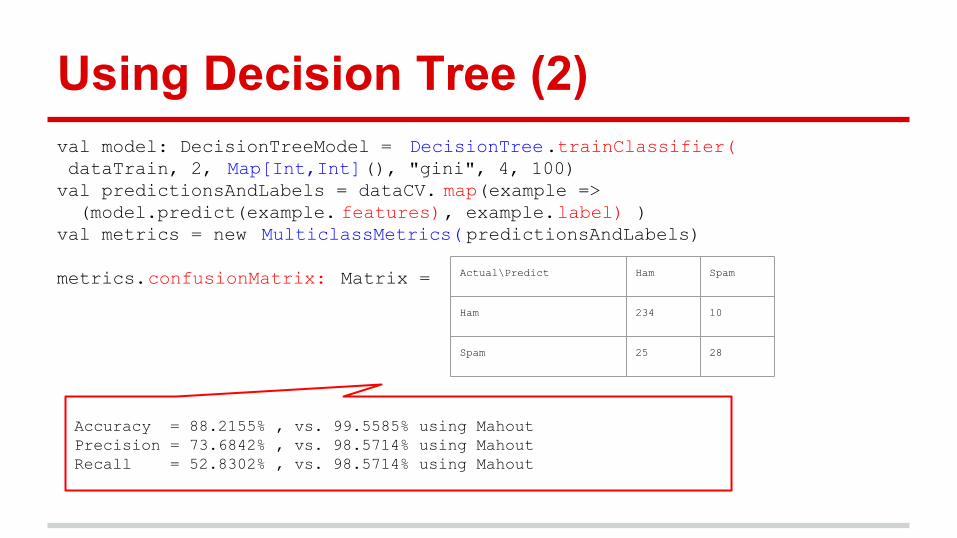
Using Decision Tree (2)val model: DecisionTreeModel = DecisionTree.trainClassifier( dataTrain, 2, Map[Int,Int](), "gini", 4, 100)val predictionsAndLabels = dataCV. map(example => (model.predict(example. features), example.label) )val metrics = new MulticlassMetrics( predictionsAndLabels)
metrics.confusionMatrix: Matrix = Actual\Predict Ham Spam
Ham 234 10
Spam 25 28
Accuracy = 88.2155% , vs. 99.5585% using Mahout Precision = 73.6842% , vs. 98.5714% using MahoutRecall = 52.8302% , vs. 98.5714% using Mahout

Tuning Hyperparameters (1)val evaluations = ( for { impurity <- Array("gini", "entropy") depth <- Array(10, 20, 30) bins <- Array(40, 300)} yield { val model = DecisionTree.trainClassifier(dataTrain , 2, Map[Int,Int](), impurity, depth, bins) val predictionsAndLabels = dataCV. map(example => (model.predict(example.features), example. label) ) val metrics = new BinaryClassificationMetrics( predictionsAndLabels) (model, (impurity, depth, bins), metrics)}).sortBy{ case (model, (impurity, depth, bins), metrics) => metrics.areaUnderROC }.reverse

Tuning Hyperparameters (2)evaluations.map{ case (model, (impurity, depth, bins), metrics) => val cnfmatrix = metrics. scoreAndLabels.map{ sl => sl match { case (1.0, 1.0) => Array(1, 0, 0, 0) // TP case (0.0, 1.0) => Array(0, 1, 0, 0) // FN case (0.0, 0.0) => Array(0, 0, 1, 0) // TN case (1.0, 0.0) => Array(0, 0, 0, 1) // FP }}.reduce{ (ary1, ary2) => Array( ary1(0)+ary2(0), ary1(1)+ary2(1), ary1(2)+ary2(2), ary1(3)+ary2(3)) } val accuracy = (cnfmatrix(0)+cnfmatrix(2)) / (cnfmatrix. sum).toDouble s"impurity=${impurity}, depth=${depth}, bins=${bins}), AUC=${metrics.areaUnderROC}, accuracy=${accuracy}"}.foreach(println)
impurity=entropy, depth=30, bins=40), AUC=0.852341, accuracy=0.916376impurity=entropy, depth=20, bins=40), AUC=0.852341, accuracy=0.916376impurity=entropy, depth=10, bins=40), AUC=0.852341, accuracy=0.916376impurity=entropy, depth=10, bins=300), AUC=0.831933, accuracy=0.909408impurity=gini, depth=20, bins=300), AUC=0.831933, accuracy=0.909408






























