Embed Size (px)
Citation preview

General Features in Knowledge Tracing Applications to Multiple Subskills, Temporal IRT & Expert Knowledge
* First authors
Yun Huang, University of Pittsburgh* José P. González-Brenes, Pearson* Peter Brusilovsky, University of Pittsburgh

This talk…
• What? Determine student mastery of a skill • How? Novel algorithm called FAST
– Enables features in Knowledge Tracing
• Why? Better and faster student modeling – 25% better AUC, a classification metric – 300 times faster than popular general purpose
student modeling techniques (BNT-SM)

Outline
• Introduction • FAST – Feature-Aware Student Knowledge Tracing • Experimental Setup • Applications
1. Multiple subskills 2. Temporal Item Response Theory 3. Paper exclusive: Expert knowledge
• Execution time • Conclusion

Motivation
• Personalize learning of students – For example, teach students new material as
they learn, so we don’t teach students material they know
• How? Typically with Knowledge Tracing

:
û û ü ü û û ü ü ü
û û ü ü ü
û û ü ü
:

:
:
û û ü ü ü
û û ü ü
Masters a skill or not
• Knowledge Tracing fits a two-state HMM per skill
• Binary latent variables indicate the knowledge of the student of the skill
• Four parameters: 1. Initial Knowledge 2. Learning 3. Guess 4. Slip
Transition
Emission

What’s wrong?
• Only uses performance data (correct or incorrect) • We are now able to capture feature rich data
– MOOCs & intelligent tutoring systems are able to log fine-grained data
– Used a hint, watched video, after hours practice…
• … these features can carry information or intervene on learning

What’s a researcher gotta do?
• Modify Knowledge Tracing algorithm • For example, just on a small-scale
literature survey, we find at least nine different flavors of Knowledge Tracing

So you want to publish in EDM?
1. Think of a feature (e.g., from a MOOC) 2. Modify Knowledge Tracing 3. Write Paper 4. Publish 5. Loop!

Are all of those models sooooo different? • No! we identify three main variants • We call them the “Knowledge Tracing
Family”

Knowledge Tracing Family
No features Emission (guess/slip)
Transition (learning)
Both (guess/slip and
learning)
• Item difficulty (Gowda et al ’11; Pardos et al ’11)
• Student ability (Pardos et al ’10)
• Subskills (Xu et al ’12)
• Help (Sao Pedro et al ’13)
• Student ability (Lee et al ’12; Yudelson et al ’13)
• Item difficulty (Schultz et al ’13)
• Help (Becker et al ’08)
k
y
k
y
f
k
y
f
k
y
f f

• Each model is successful for an ad hoc purpose only – Hard to compare models – Doesn’t help to build a
cognition theory

• Learning scientists have to worry about both features and modeling

• These models are not scalable: – Rely on Bayes Net’s
conditional probability tables – Memory performance grows
exponentially with number of features
– Runtime performance grows exponentially with number of features (with exact inference)

Example:
Mastery p(Correct)
False (1) 0.10 (guess)
True (2) 0.85 (1-slip)
20+1 parameters!
Emission probabilities with no features:

Example: Emission probabilities with 1 binary feature:
Mastery Hint p(Correct)
False False (1) 0.06
True False (2) 0.75
False True (3) 0.25
True True (4) 0.99
21+1 parameters!

Example: Emission probabilities with 10 binary features: Mastery F1 … F10 p(Correct)
False False False False (1) 0.06
… …
True True True True (2048) 0.90
210+1 parameters!

Outline
• Introduction • FAST – Feature-Aware Student Knowledge Tracing • Experimental Setup • Applications
– Multiple subskills – Temporal IRT
• Execution time • Conclusion

Something old… k
y
f f • Uses the most general model
in the Knowledge Tracing Family
• Parameterizes learning and emission (guess+slip) probabilities

Something new… k
y
f f • Instead of using inefficient
conditional probability tables, we use logistic regression [Berg-Kirkpatrick et al’10 ]
• Exponential complexity -> linear complexity

Example:
# of features # of pararameters in KTF # of parameters in FAST
0 2 2
1 4 3
10 2048 12
25 67,108,864 27
25 features are not that many, and yet they can become intractable with Knowledge Tracing Family

Something blue? k
y
f f • Not a lot of changes to
implement prediction • Training requires quite a bit of
changes – We use a recent modification of
the Expectation-Maximization algorithm proposed for Computational Linguistics problems [Berg-Kirkpatrick et al’10 ]

(A parenthesis)
• Jose’s corollary: Each equation in a presentation would send to sleep half the audience
• Equations are in the paper!
“Each equaMon I include in the book
would halve the sales”

KT uses Expectation-Maximization
Conditional Probability
Table Lookup
Latent Mastery
E-Step:Forward-Backward algorithm
M-Step: Maximum Likelihood
“Conditional Probability
Table” Lookup
Latent Mastery
Logistic regression
weights
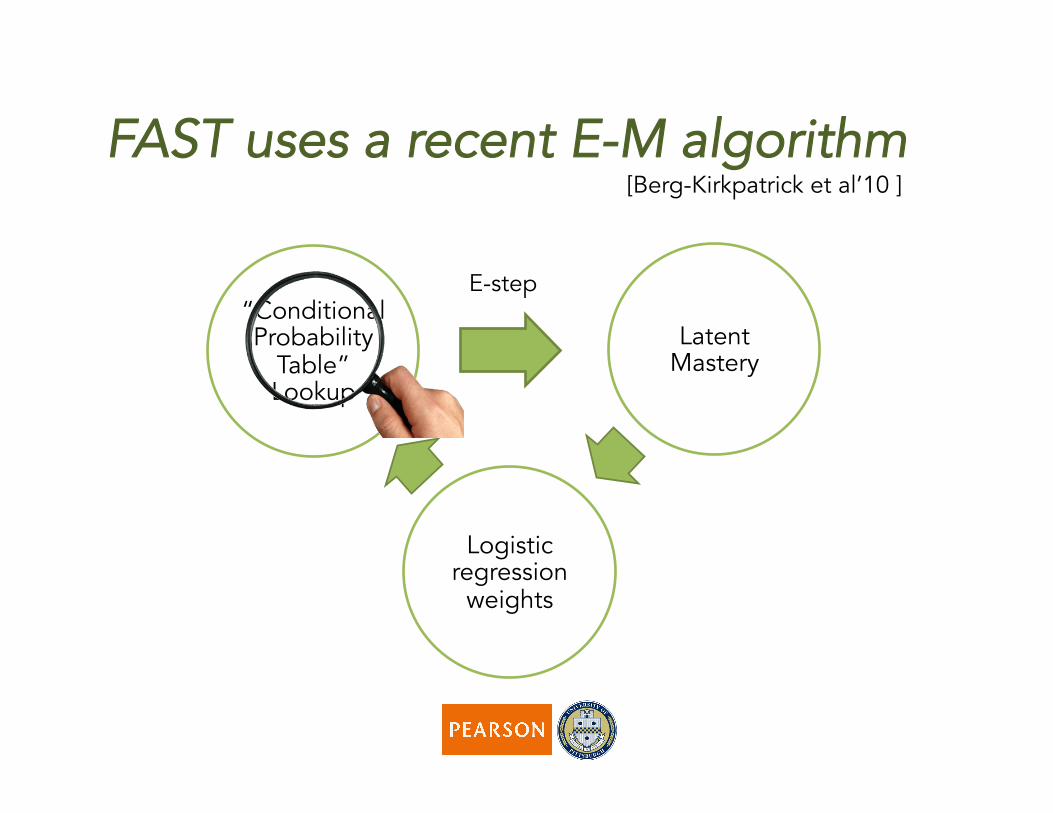
FAST uses a recent E-M algorithm [Berg-Kirkpatrick et al’10 ]
E-step
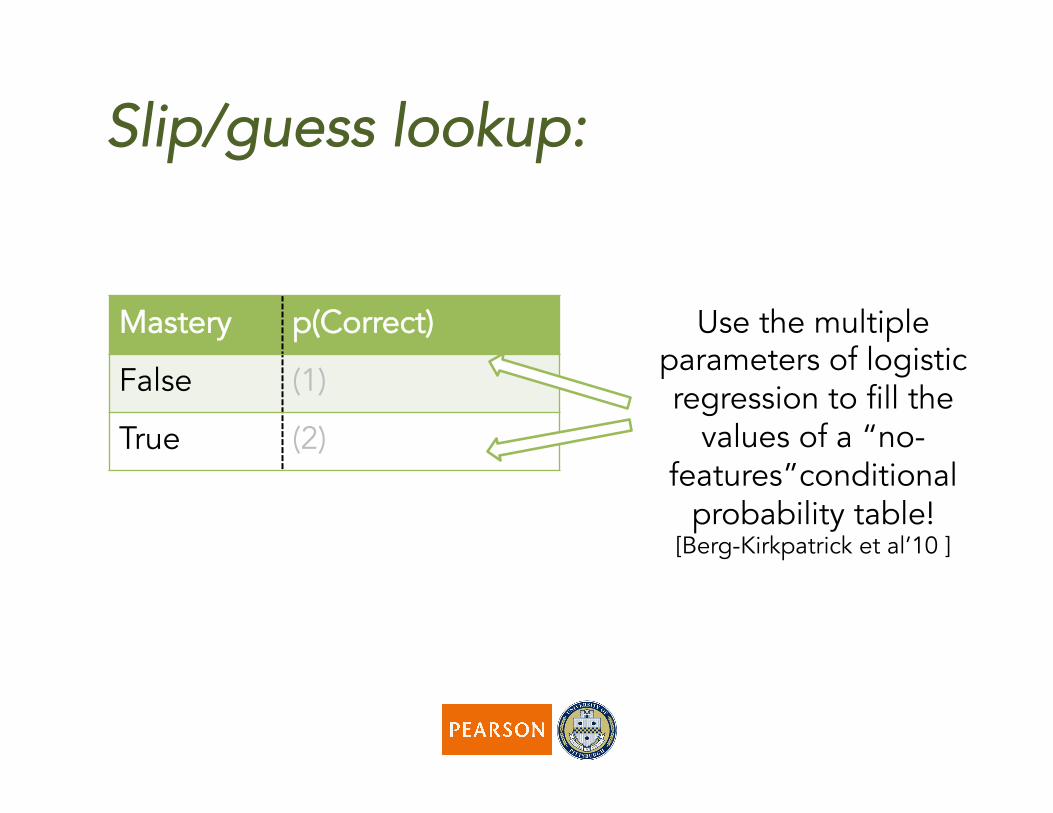
Slip/guess lookup:
Mastery p(Correct)
False (1)
True (2)
Use the multiple parameters of logistic regression to fill the
values of a “no-features”conditional
probability table! [Berg-Kirkpatrick et al’10 ]

“Conditional Probability
Table” Lookup
Latent Mastery
Logistic regression
weights
FAST uses a recent E-M algorithm [Berg-Kirkpatrick et al’10 ]
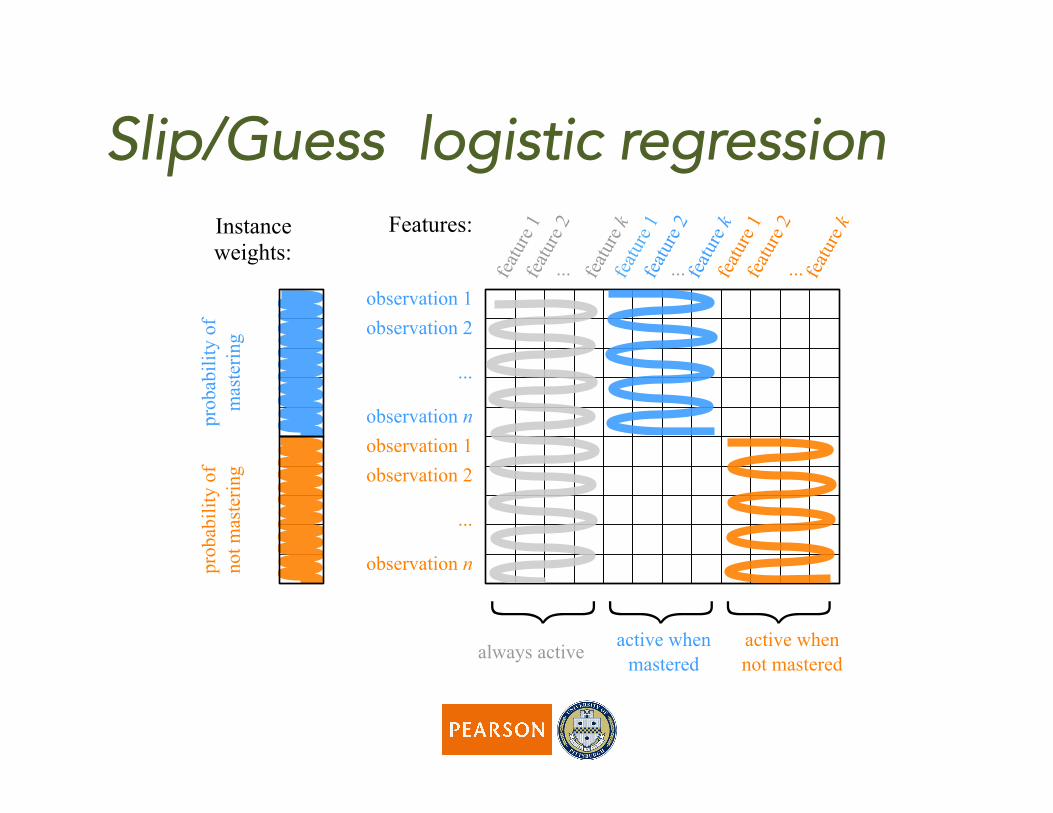
observation 1observation 2
observation n
...
featu
re 1
featu
re 2
featu
re k
featu
re 1
featu
re 2
featu
re k
featu
re 1
featu
re 2
featu
re k
... ... ...
observation 1observation 2
observation n
...
{ { {active when
masteredactive when not masteredalways active
Features:Instance weights:
prob
abili
ty o
f no
t mas
terin
gpr
obab
ility
of
mas
terin
g
Slip/Guess logistic regression

observation 1observation 2
observation n
...
featu
re 1
featu
re 2
featu
re k
featu
re 1
featu
re 2
featu
re k
featu
re 1
featu
re 2
featu
re k
... ... ...
observation 1observation 2
observation n
...
{ { {active when
masteredactive when not masteredalways active
Features:Instance weights:
prob
abili
ty o
f no
t mas
terin
gpr
obab
ility
of
mas
terin
g
Slip/Guess logistic regression
When FAST uses only intercept terms as features for the two levels of mastery, it is equivalent to Knowledge Tracing!

Outline
• Introduction • FAST – Feature-Aware Student Knowledge Tracing • Experimental Setup • Examples
– Multiple subskills – Temporal IRT – Expert knowledge
• Conclusion

Collected from QuizJET, a tutor for learning Java programming.
March 28, 2014 31
Each question is generated from a template, and students can try multiple attempts
Students give values for a variable or the output
Java code
Tutoring System

March 28, 2014 32
Data
• Smaller dataset: – ~21,000 observations – First attempt: ~7,000 observations – 110 students
• Unbalanced: 70% correct • 95 question templates • “Hierarchical” cognitive model:
19 skills, 99 subskills
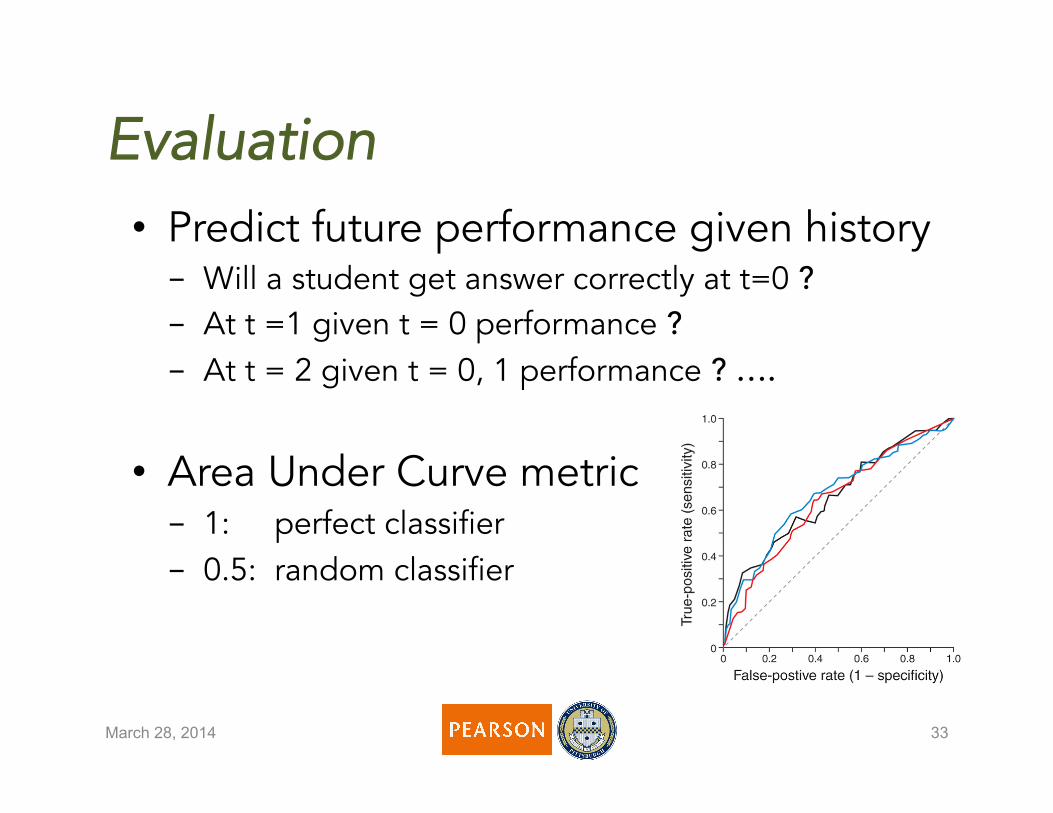
• Predict future performance given history - Will a student get answer correctly at t=0 ? - At t =1 given t = 0 performance ? - At t = 2 given t = 0, 1 performance ? ….
• Area Under Curve metric - 1: perfect classifier - 0.5: random classifier
March 28, 2014 33
Evaluation

Outline
• Introduction • FAST – Feature-Aware Student Knowledge Tracing • Experimental Setup • Applications
– Multiple subskills – Temporal IRT – Expert knowledge
• Execution time • Conclusion

Multiple subskills
• Experts annotated items (question) with a single skill and multiple subskills

Multiple subskills & KnowledgeTracing • Original Knowledge Tracing can not
model multiple subskills • Most Knowledge Tracing variants assume
equal importance of subskills during training (and then adjust it during testing)
• State of the art method, LR-DBN [Xu and
Mostow ’11] assigns importance in both training and testing

FAST can handle multiple subskills
• Parameterize learning • Parameterize slip and guess
• Features: binary variables that indicate presence of subskills

FAST vs Knowledge Tracing: Slip parameters of subskills
• Conventional Knowledge assumes that all subskills have the same difficulty (red line)
• FAST can identify different difficulty between subskills
• Does it matter?
subskills within a skill:
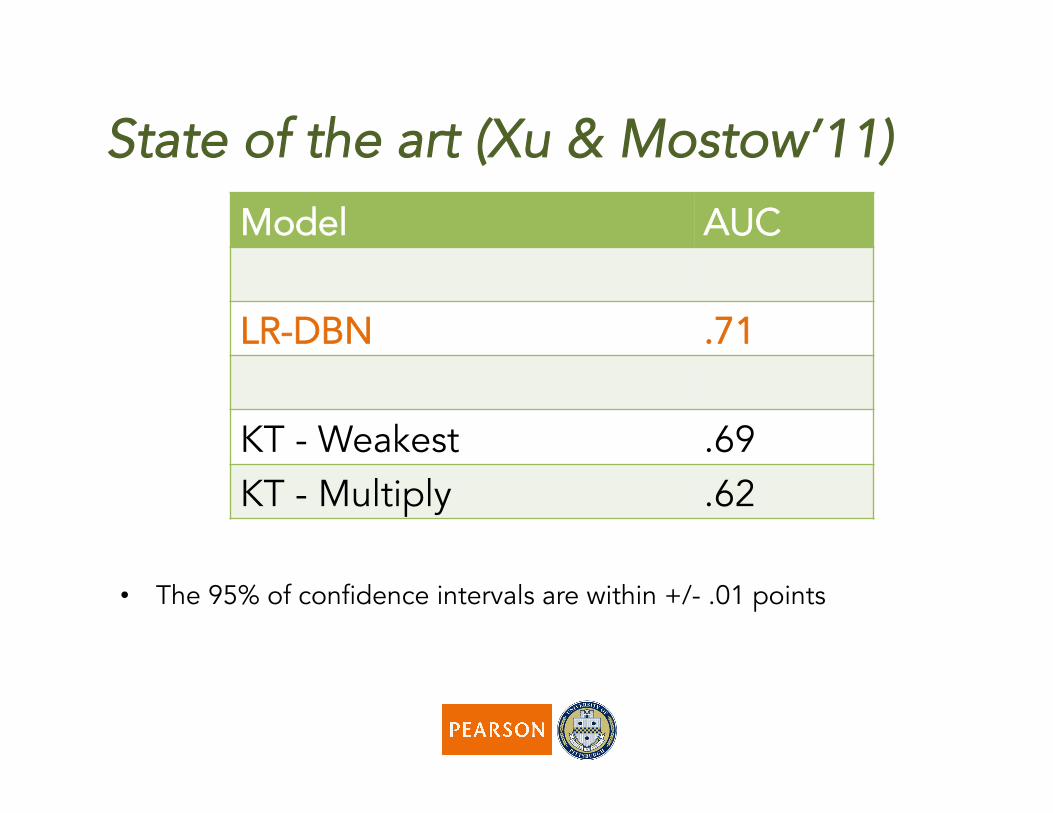
State of the art (Xu & Mostow’11)
• The 95% of confidence intervals are within +/- .01 points
Model AUC
LR-DBN .71
KT - Weakest .69 KT - Multiply .62
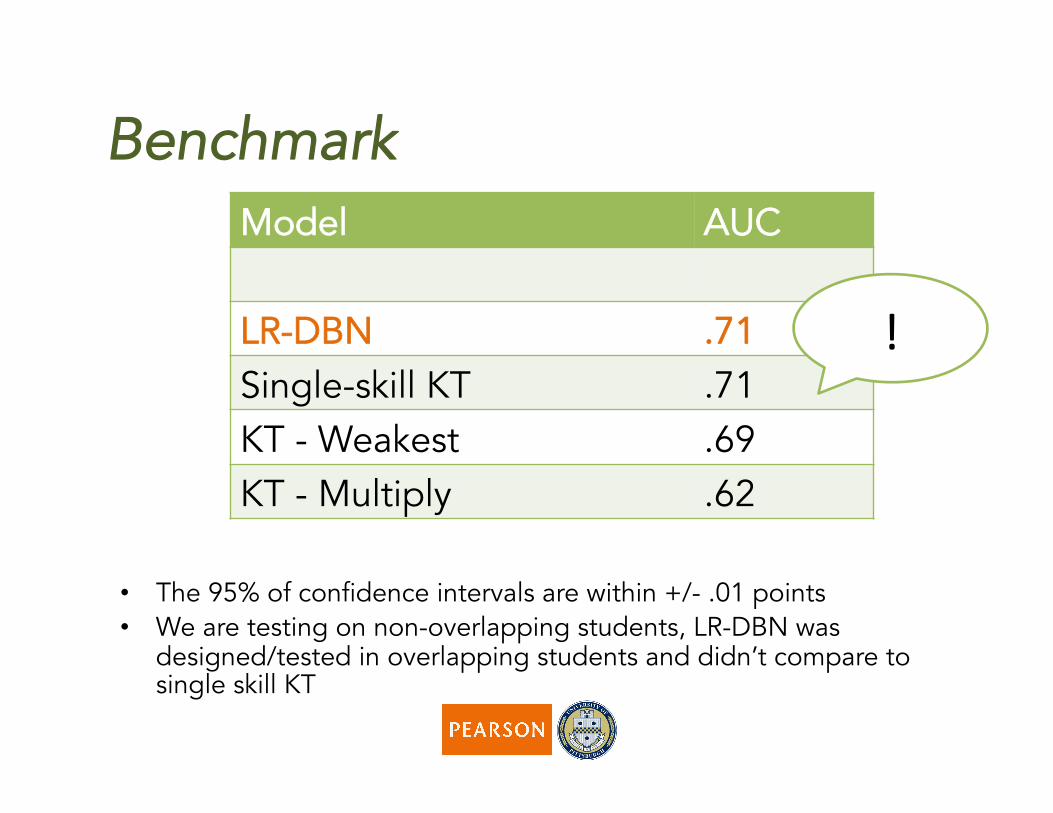
Benchmark Model AUC
LR-DBN .71 Single-skill KT .71 KT - Weakest .69 KT - Multiply .62
• The 95% of confidence intervals are within +/- .01 points • We are testing on non-overlapping students, LR-DBN was
designed/tested in overlapping students and didn’t compare to single skill KT
!

Benchmark Model AUC
LR-DBN .71 Single-skill KT .71 KT - Weakest .69 KT - Multiply .62
• The 95% of confidence intervals are within +/- .01 points • We are testing on non-overlapping students, LR-DBN was
designed/tested in overlapping students and didn’t compare to single skill KT
!
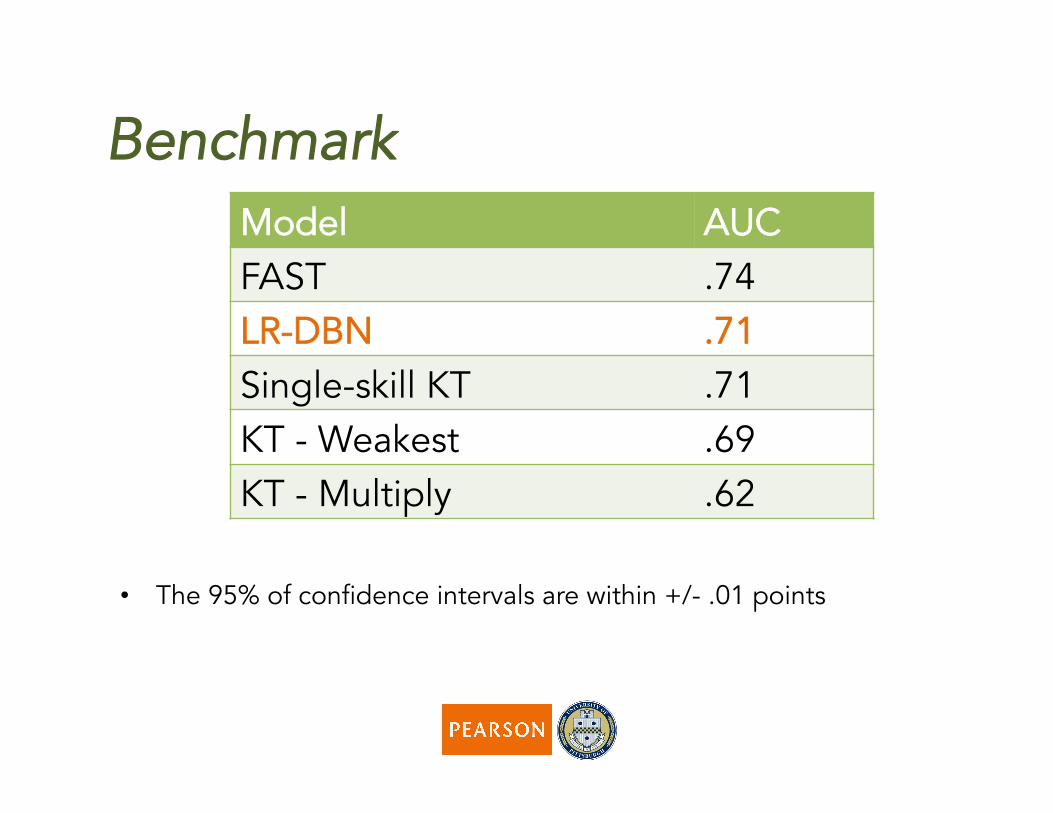
Benchmark
• The 95% of confidence intervals are within +/- .01 points
Model AUC FAST .74 LR-DBN .71 Single-skill KT .71 KT - Weakest .69 KT - Multiply .62

Outline
• Introduction • FAST – Feature-Aware Student Knowledge Tracing • Experimental Setup • Applications
– Multiple subskills – Temporal IRT
• Execution time • Conclusion

Two paradigms: (50 years of research in 1 slide) • Knowledge Tracing
– Allows learning – Every item = same difficulty – Every student = same ability
• Item Response Theory – NO learning – Models items difficulties – Models student abilities

Can FAST help merging the paradigms?

Item Response Theory
• The simplest of its forms, it’s the Rasch model
• The Rasch can be formulated in many ways: – Typically using latent variables – Logistic regression
• a feature per student • a feature per item • We end up with a lot of features! – Good thing we
are using FAST ;-)
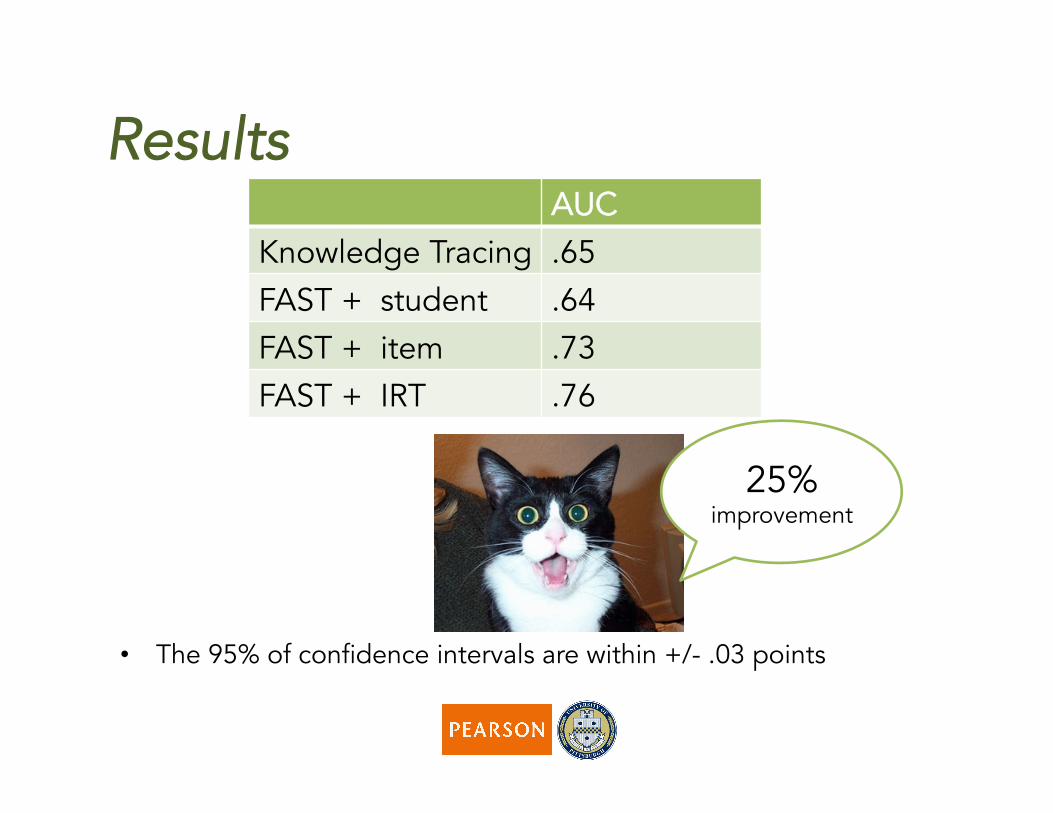
Results AUC
Knowledge Tracing .65
FAST + student .64 FAST + item .73 FAST + IRT .76
• The 95% of confidence intervals are within +/- .03 points
25% improvement

Disclaimer
• In our dataset, most students answer items in the same order
• Item estimates are biased • Future work: define continuous IRT
difficulty features – It’s easy in FAST ;-)

Outline
• Introduction • FAST – Feature-Aware Student Knowledge Tracing • Experimental Setup • Applications
– Multiple subskills – Temporal IRT
• Execution time • Conclusion

March 28, 2014 50
7,100 11,300 15,500 19,8000
10
20
30
40
50
60
23
28
46
54
0.08 0.10 0.12 0.15
# of observations
exe
cutio
n tim
e (
min
.)
BNT−SM (no feat.)
FAST (no feat.)
FAST is 300x faster than BNT-SM!

LR-DBN vs FAST
• We use the authors’ implementation of LR-DBN
• LR-DBN takes about 250 minutes • FAST only takes about 44 seconds • 15,500 datapoints • This is on an old laptop, no parallelization,
nothing fancy • (details on the paper)

Outline
• Introduction • FAST – Feature-Aware Student Knowledge Tracing • Experimental Setup • Examples
– Multiple subskills – Temporal IRT
• Conclusion
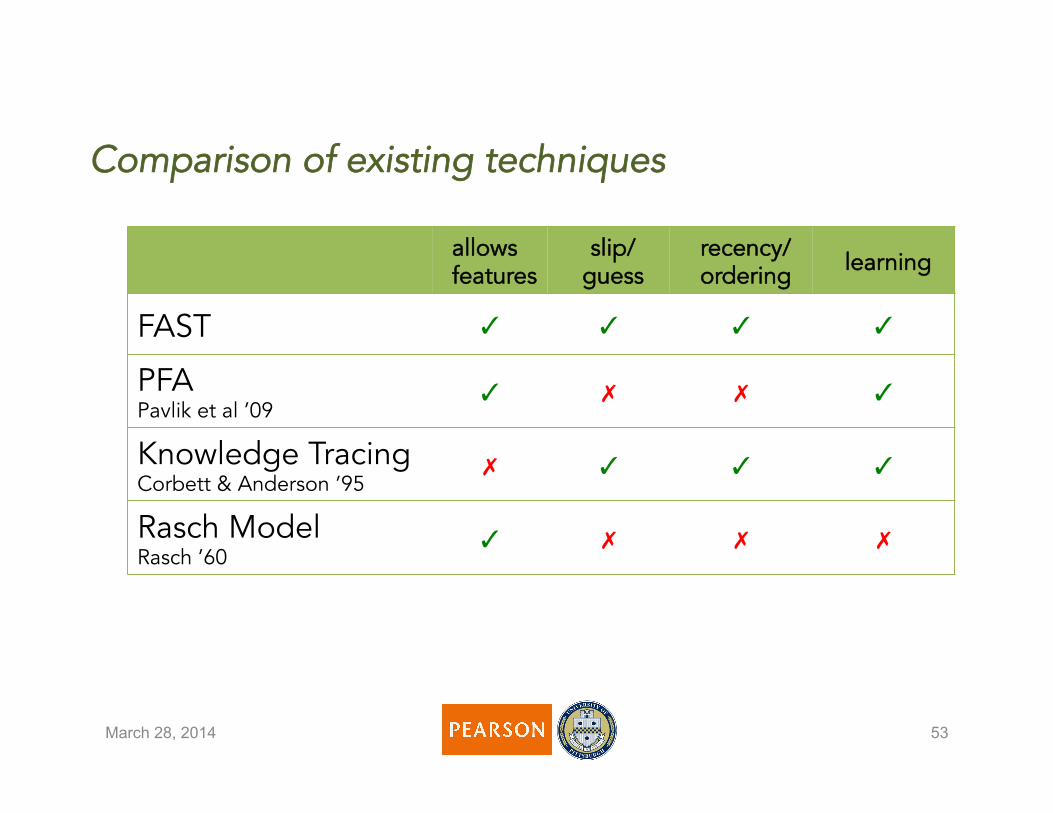
Comparison of existing techniques
March 28, 2014 53
allows features
slip/ guess
recency/ordering learning
FAST ✓ ✓ ✓ ✓
PFA Pavlik et al ’09
✓ ✗ ✗ ✓
Knowledge Tracing Corbett & Anderson ’95
✗ ✓ ✓ ✓
Rasch Model Rasch ’60
✓ ✗ ✗ ✗

• FAST lives by its name • FAST provides high flexibility in utilizing
features, and as our studies show, even with simple features improves significantly over Knowledge Tracing

• The effect of features depends on how smartly they are designed and on the dataset
• I am looking forward for more clever uses of feature engineering for FAST in the community






























