Embed Size (px)
Citation preview

Angelo Corsaro, PhD Chief Technology Officer
Classical Distributed Algorithms with DDS

Cop
yrig
ht P
rism
Tech
, 201
5
The Data Distribution Service (DDS) provides a very useful foundation for building highly dynamic, reconfigurable, dependable and high performance systems
However, in building distributed systems with DDS one is often faced with two kind of problems:
- How can distributed coordination problems be solved with DDS? e.g. distributed mutual exclusion, consensus, etc
- How can higher order primitives and abstractions be supported over DDS? e.g. fault-tolerant distributed queues, total-order multicast, etc.
In this presentation we will look at how DDS can be used to implement some of the classical Distributed Algorithm that solve these problems
Context

DDS Abstractions and Properties

Copyrig
ht 2013, PrismTech – A
ll Rights Reserved.
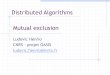
Data Distribution Service (DDS)
‣ DDS provides a Global Data Space abstraction that allows applications to autonomously, anonymously, securely and efficiently share data
‣ DDS’ Global Data Space is fully distributed, highly efficient and scalable
DDS Global Data Space
...
Data Writer
Data Writer
Data Writer
Data Reader
Data Reader
Data Reader
Data Reader
Data Writer
TopicAQoS
TopicBQoS
TopicCQoS
TopicDQoS
Copyrig
ht 2013, PrismTech – A
ll Rights Reserved.
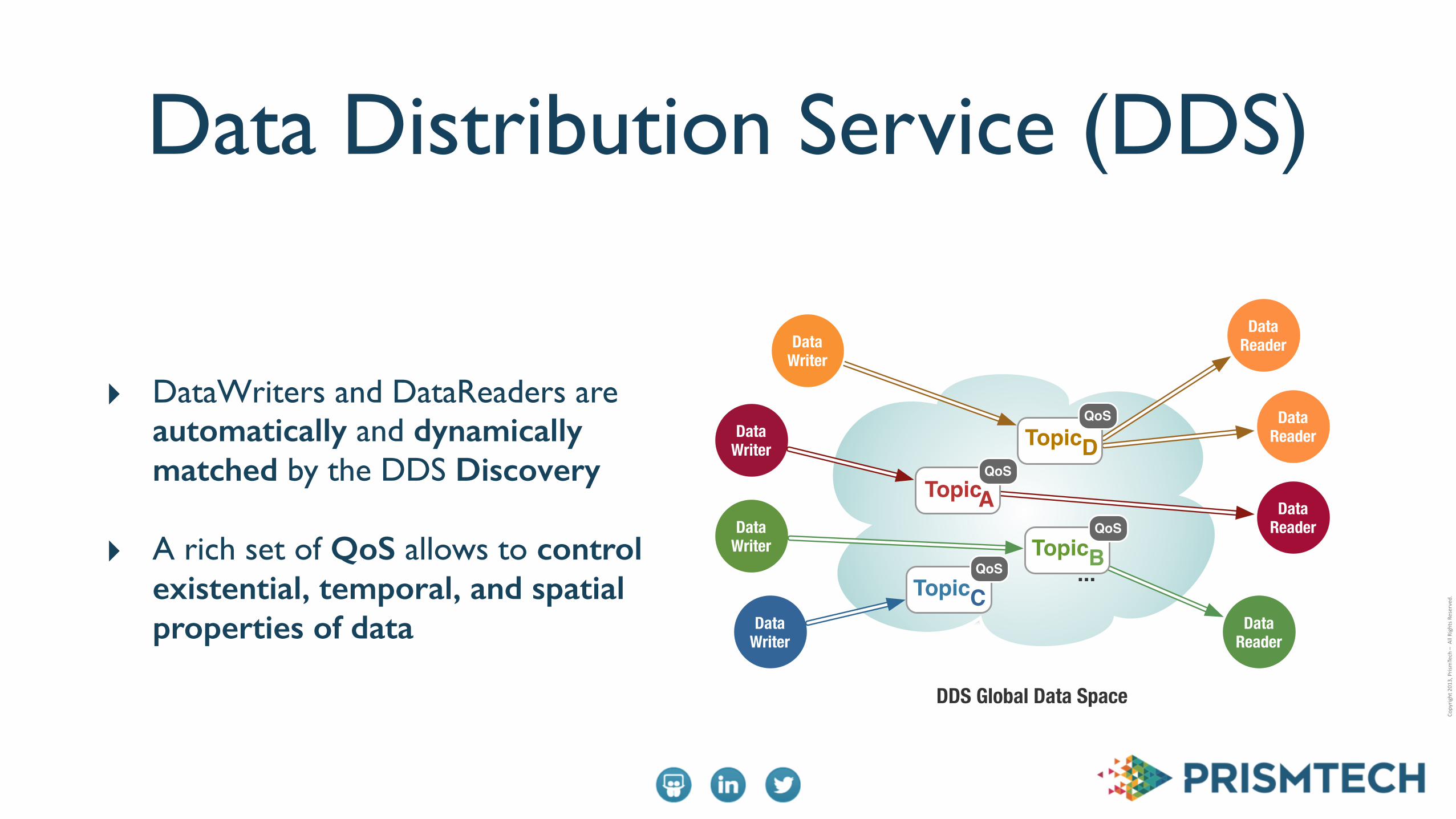
Data Distribution Service (DDS)
‣ DataWriters and DataReaders are automatically and dynamically matched by the DDS Discovery
‣ A rich set of QoS allows to control existential, temporal, and spatial properties of data
DDS Global Data Space
...
Data Writer
Data Writer
Data Writer
Data Reader
Data Reader
Data Reader
Data Reader
Data Writer
TopicAQoS
TopicBQoS
TopicCQoS
TopicDQoS
Copyrig
ht 2013, PrismTech – A
ll Rights Reserved.
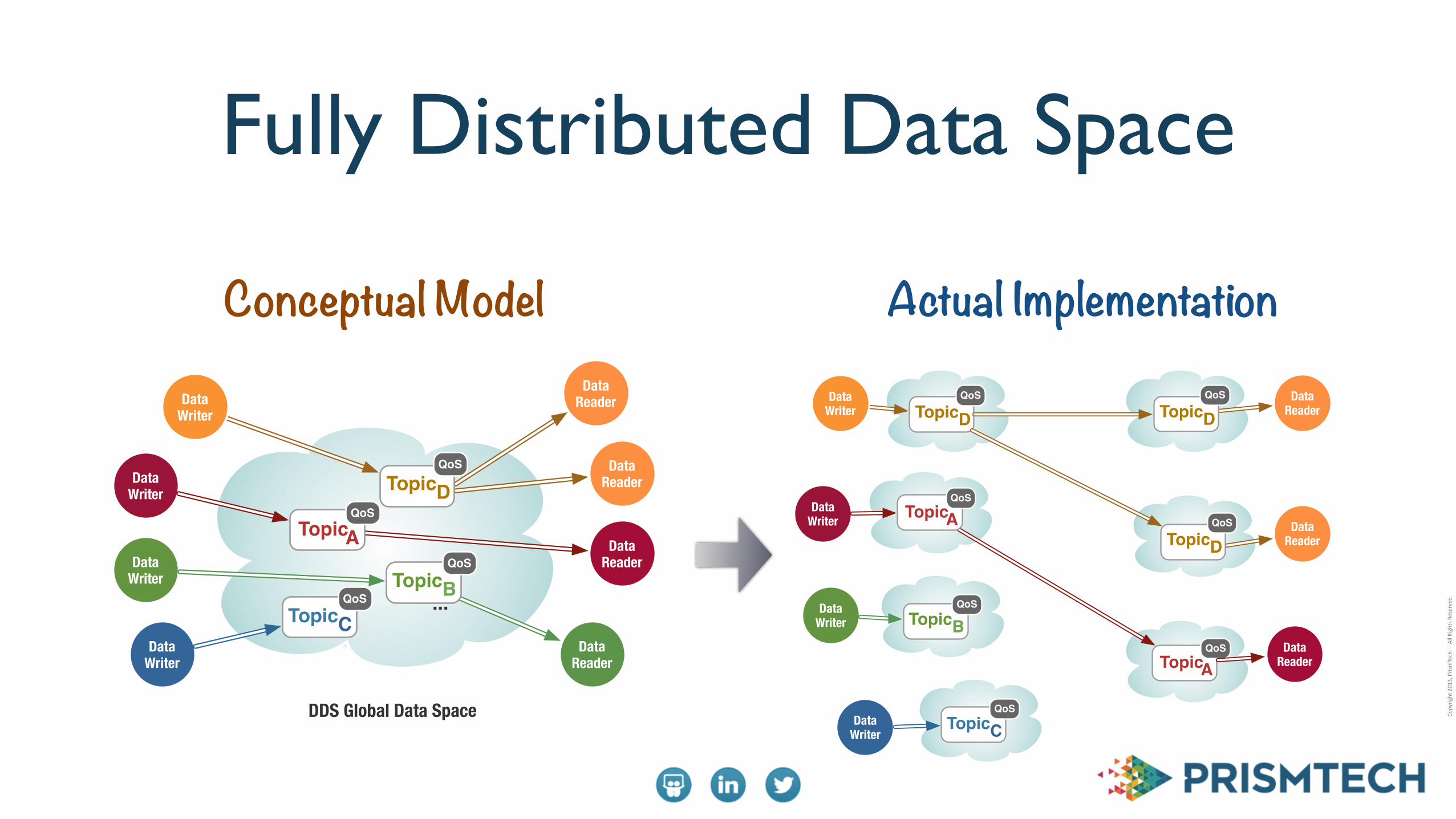
Fully Distributed Data Space
Conceptual Model Actual Implementation
Data Writer
Data Writer
Data Writer
Data Reader
Data Reader
Data Reader
Data Writer
TopicAQoS
TopicBQoS
TopicCQoS
TopicDQoS
TopicDQoS
TopicDQoS
TopicAQoS
DDS Global Data Space
...
Data Writer
Data Writer
Data Writer
Data Reader
Data Reader
Data Reader
Data Reader
Data Writer
TopicAQoS
TopicBQoS
TopicCQoS
TopicDQoS
Copyrig
ht 2013, PrismTech – A
ll Rights Reserved.
Data Writer
Data Writer
Data Writer
Data Reader
Data Reader
Data Reader
Data Writer
TopicAQoS
TopicBQoS
TopicCQoS
TopicDQoS
TopicDQoS
TopicDQoS
TopicAQoS
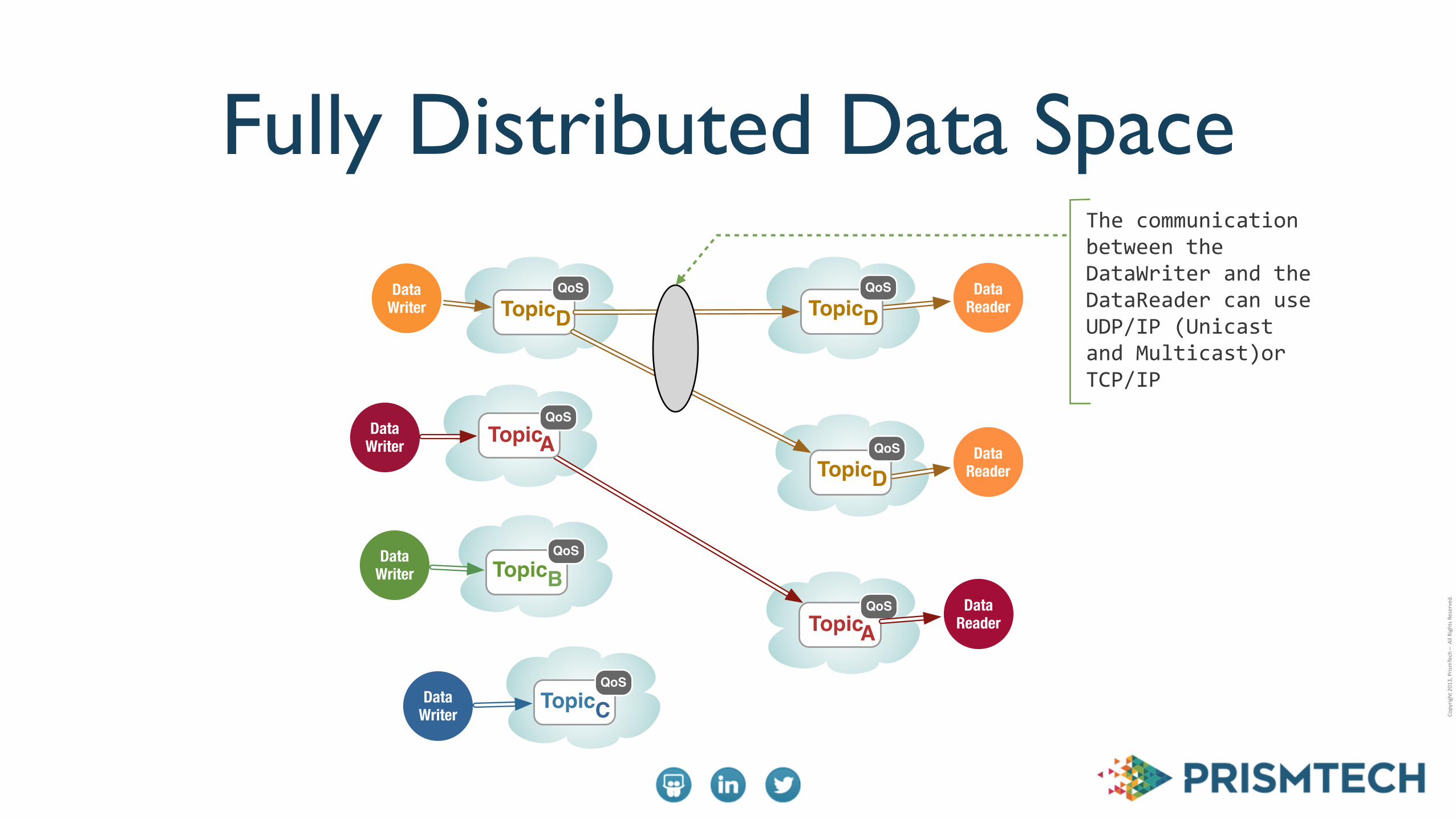
Fully Distributed Data SpaceThe communication between the DataWriter and the DataReader can use UDP/IP (Unicast and Multicast)or TCP/IP
Cop
yrig
ht P
rism
Tech
, 201
4
Vortex supports the definition of Data Models.
These data models allow to naturally represent physical and virtual entities characterising the application domain
Vortex types are extensible and evolvable, thus allowing incremental updates and upgrades
Data Centricity

Cop
yrig
ht P
rism
Tech
, 201
4
A Topic defines a domain-wide information’s class
A Topic is defined by means of a (name, type, qos) tuple, where
• name: identifies the topic within the domain
• type: is the programming language type associated with the topic. Types are extensible and evolvable
• qos: is a collection of policies that express the non-functional properties of this topic, e.g. reliability, persistence, etc.
Topic
TopicTypeName
QoS
struct TemperatureSensor { @key long sid; float temp; float hum; }
Cop
yrig
ht P
rism
Tech
, 201
5
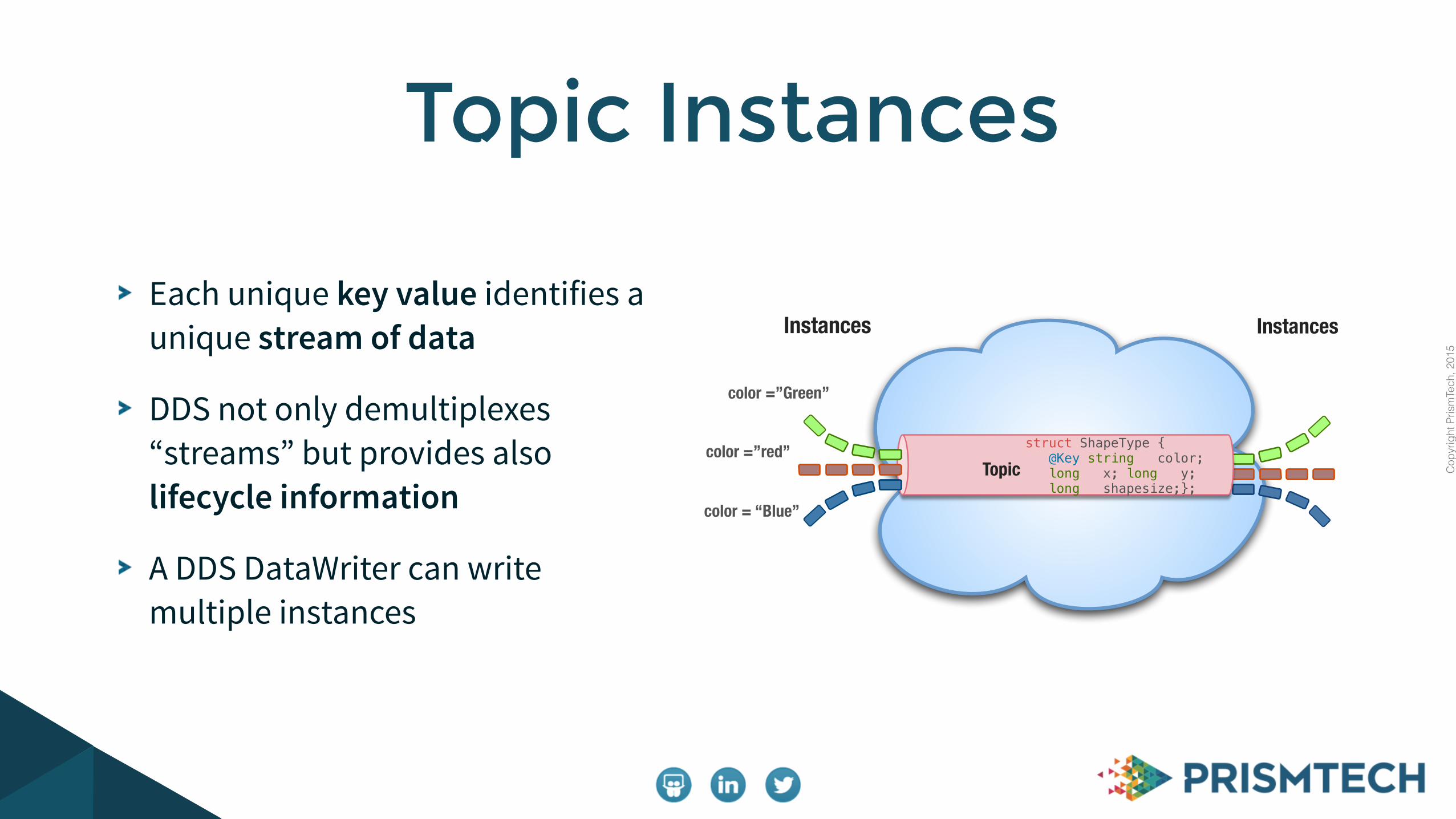
Each unique key value identifies a unique stream of data
DDS not only demultiplexes “streams” but provides also lifecycle information
A DDS DataWriter can write multiple instances
Topic Instances
Topic
InstancesInstances
color =”Green”
color =”red”
color = “Blue”
struct ShapeType { @Key string color; long x; long y; long shapesize;};
Cop
yrig
ht P
rism
Tech
, 201
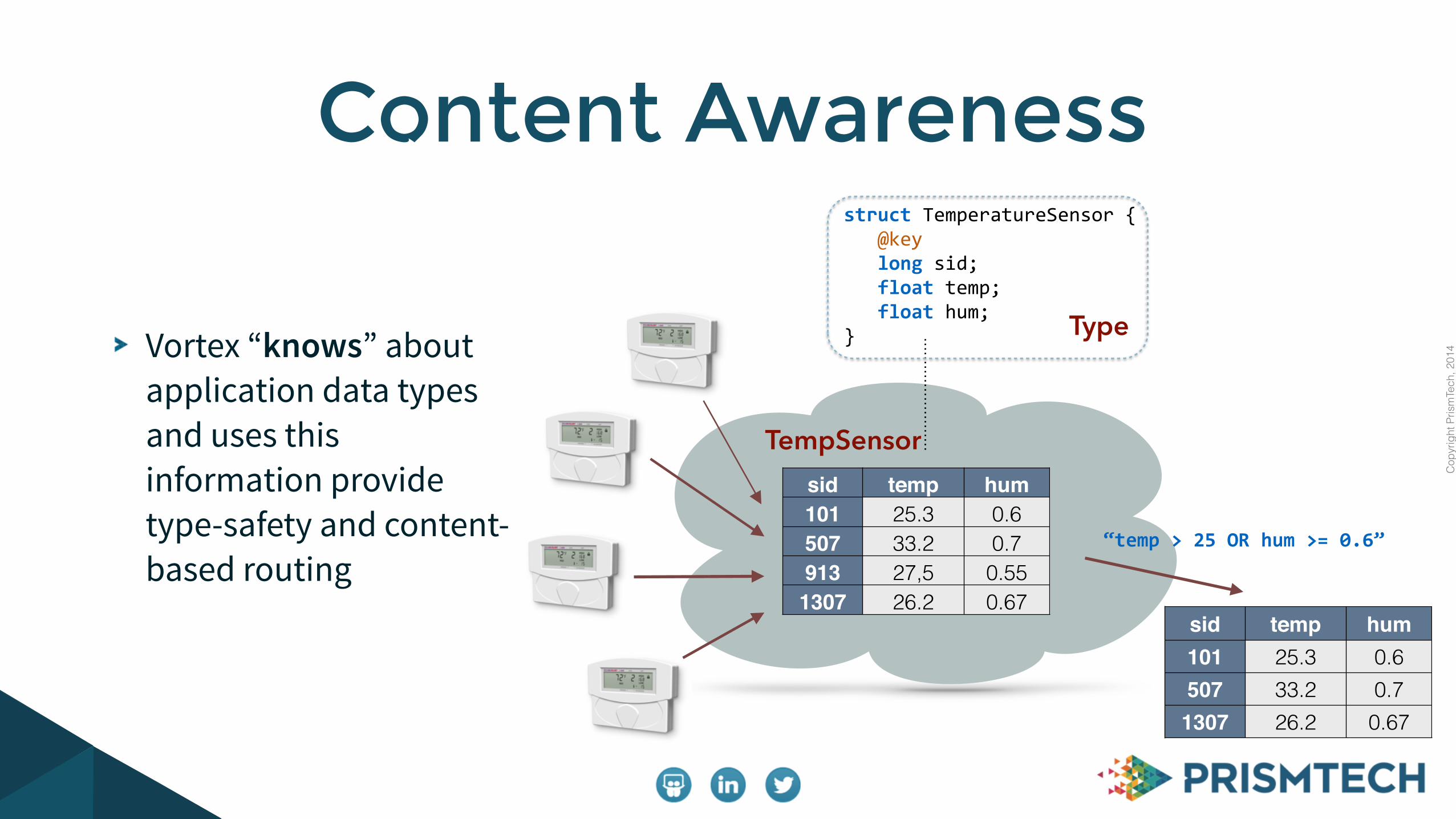
4Vortex “knows” about application data types and uses this information provide type-safety and content-based routing
Content Awarenessstruct TemperatureSensor { @key long sid; float temp; float hum; }
sid temp hum101 25.3 0.6507 33.2 0.7913 27,5 0.551307 26.2 0.67
“temp > 25 OR hum >= 0.6”
sid temp hum101 25.3 0.6507 33.2 0.71307 26.2 0.67
Type
TempSensor
Cop
yrig
ht P
rism
Tech
, 201
4
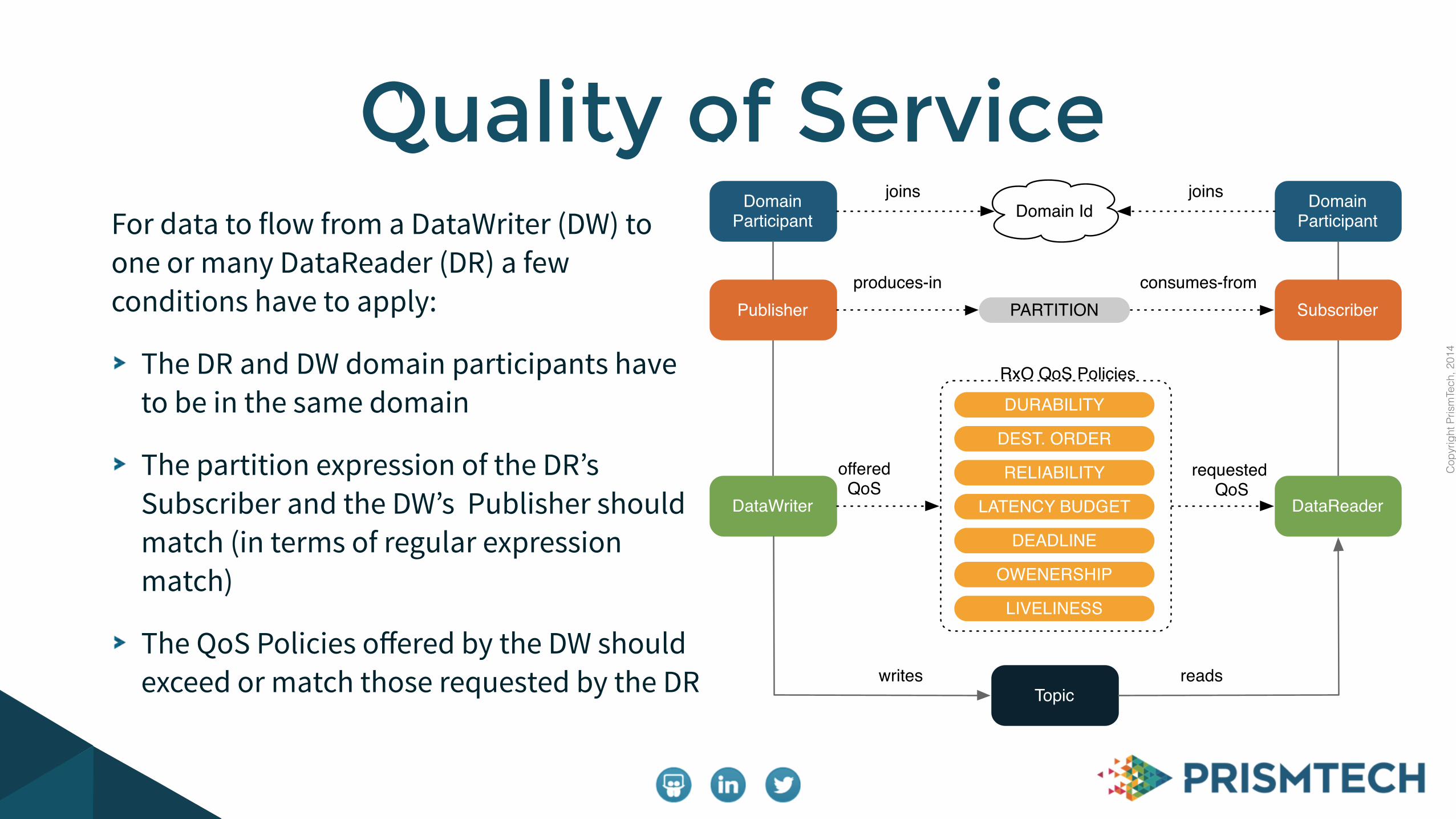
For data to flow from a DataWriter (DW) to one or many DataReader (DR) a few conditions have to apply:
The DR and DW domain participants have to be in the same domain
The partition expression of the DR’s Subscriber and the DW’s Publisher should match (in terms of regular expression match)
The QoS Policies offered by the DW should exceed or match those requested by the DR
Quality of ServiceDomain
Participant
DURABILITY
OWENERSHIP
DEADLINE
LATENCY BUDGET
LIVELINESS
RELIABILITY
DEST. ORDER
Publisher
DataWriter
PARTITION
DataReader
Subscriber
DomainParticipant
offered QoS
Topicwrites reads
Domain Idjoins joins
produces-in consumes-from
RxO QoS Policies
requested QoS
Cop
yrig
ht P
rism
Tech
, 201
5
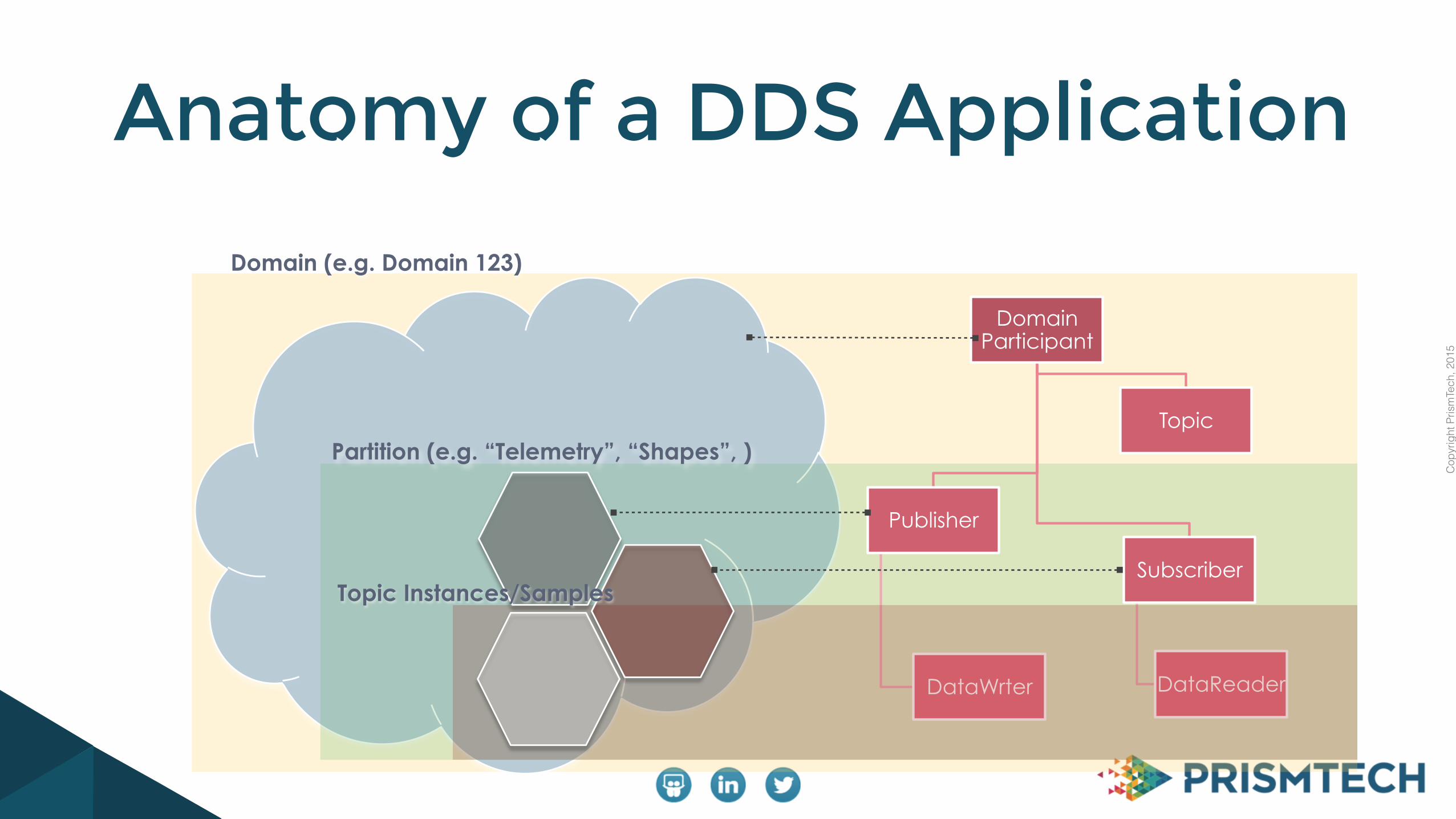
Anatomy of a DDS Application
Domain (e.g. Domain 123)
Domain Participant
Topic
Publisher
DataWrter
Subscriber
DataReader
Partition (e.g. “Telemetry”, “Shapes”, )
Topic Instances/Samples

Cop
yrig
ht P
rism
Tech
, 201
5
We can think of a DataWriter and its matching DataReaders as connected by a logical typed communication channel
The properties of this channel are controlled by means of QoS Policies
At the two extreme this logical communication channel can be:
- Best-Effort/Reliable Last n-values Channel
- Best-Effort/Reliable FIFO Channel
Channel Properties
DR
DR
DR
TopicDW

Cop
yrig
ht P
rism
Tech
, 201
5
The last n-values channel is useful when modelling distributed state
When n=1 then the last value channel provides a way of modelling an eventually consistent distributed state
This abstraction is very useful if what matters is the current value of a given topic instance
The Qos Policies that give a Last n-value Channel are:
- RELIABILITY = RELIABLE
- HISTORY = KEEP_LAST(n)
- DURABILITY = TRANSIENT | PERSISTENT [in most cases]
Last n-values Channel
DR
DR
DR
TopicDW

Cop
yrig
ht P
rism
Tech
, 201
5
The FIFO Channel is useful when we care about every single sample that was produced for a given topic -- as opposed to the “last value”
This abstraction is very useful when writing distributing algorithm over DDS
Depending on Qos Policies, DDS provides:
- Best-Effort/Reliable FIFO Channel
- FT-Reliable FIFO Channel (using an OpenSplice-specific extension)
The Qos Policies that give a FIFO Channel are:
- RELIABILITY = RELIABLE
- HISTORY = KEEP_ALL
FIFO Channel
DR
DR
DR
TopicDW
Cop
yrig
ht P
rism
Tech
, 201
5
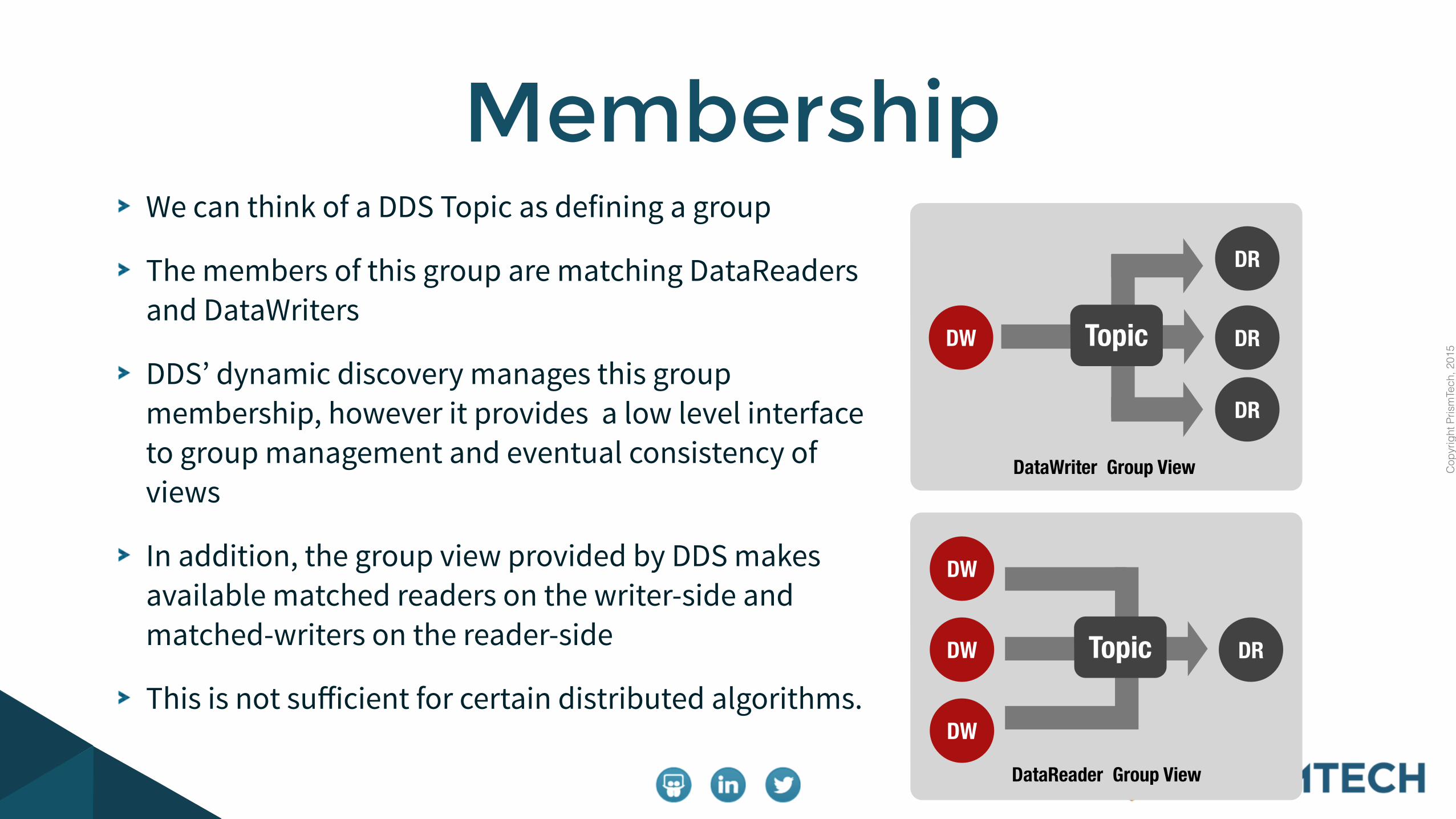
We can think of a DDS Topic as defining a group
The members of this group are matching DataReaders and DataWriters
DDS’ dynamic discovery manages this group membership, however it provides a low level interface to group management and eventual consistency of views
In addition, the group view provided by DDS makes available matched readers on the writer-side and matched-writers on the reader-side
This is not sufficient for certain distributed algorithms.
Membership
DR
DR
DR
TopicDW
DataWriter Group View
DW
DW DRTopic
DW
DataReader Group View

Cop
yrig
ht P
rism
Tech
, 201
5
DDS provides built-in mechanism for detection of DataWriter faults through the LivelinessChangedStatus
A writer is considered as having lost its liveliness if it has failed to assert it within its lease period
Fault-Detection
DW
DW DRTopic
DW
DataReader Group View

System Model

Cop
yrig
ht P
rism
Tech
, 201
5
Partially Synchronous
- After a Global Stabilisation Time (GST) communication latencies are bounded, yet the bound is unknown
Non-Byzantine Fail/Recovery
- Process can fail and restart but don’t perform malicious actions
System Model

Cop
yrig
ht P
rism
Tech
, 201
5
The algorithms that will be showed next are implemented on OpenSplice using the Moliere Scala API
All algorithms are available as part of the Open Source project dada
Programming Environment
! DDS-based Advanced Distributed Algorithms Toolkit
!Open Source !github.com/kydos/dada

Higher Level Abstractions

Cop
yrig
ht P
rism
Tech
, 201
5
A Group Management abstraction should provide the ability to join/leave a group, provide the current view and detect failures of group members
Ideally group management should also provide the ability to elect leaders
A Group Member should represent a process
Group Managementabstract class Group { // Join/Leave API def join(mid: Int) def leave(mid: Int)
// Group View API def size: Int def view: List[Int] def waitForViewSize(n: Int) def waitForViewSize(n: Int, timeout: Int)
// Leader Election API def leader: Option[Int] def proposeLeader(mid: Int, lid: Int)
// Reactions handling Group Events val reactions: Reactions}
case class MemberJoin(val mid: Int)case class MemberLeave(val mid: Int)case class MemberFailure(mid:Int)case class EpochChange(epoch: Long)case class NewLeader(mid: Option[Int])

Cop
yrig
ht P
rism
Tech
, 201
5
To implement the Group abstraction with support for Leader Election it is sufficient to rely on the following topic types:
Topic Types
enum TMemberStatus { JOINED, LEFT, FAILED, SUSPECTED};
struct TMemberInfo { long mid; // member-id TMemberStatus status;};#pragma keylist TMemberInfo mid
struct TEventualLeaderVote { long long epoch; long mid; long lid; // voted leader-id};#pragma keylist TEventualLeaderVote mid

Cop
yrig
ht P
rism
Tech
, 201
5
Group Management The TMemberInfo topic is used to advertise presence and manage the members state transitions
Leader Election The TEventualLeaderVote topic is used to cast votes for leader election
This leads us to: Topic(name = MemberInfo, type = TMemberInfo, QoS = {Reliability.Reliable, History.KeepLast(1), Durability.TransientLocal}) Topic(name = EventualLeaderVote, type = TEventualLeaderVote, QoS = {Reliability.Reliable, History.KeepLast(1), Durability.TransientLocal}
Topics
Cop
yrig
ht P
rism
Tech
, 201
5
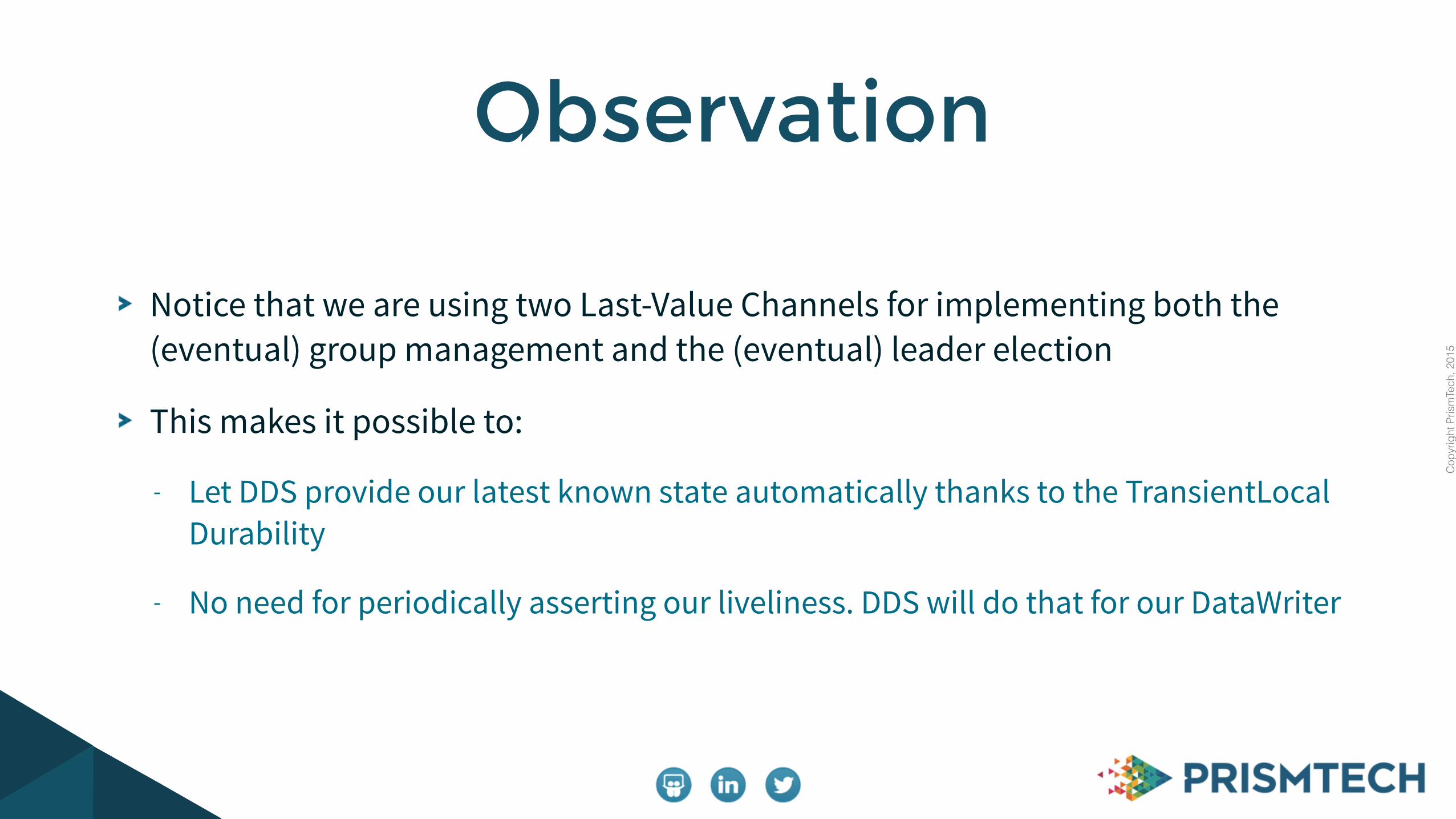
Notice that we are using two Last-Value Channels for implementing both the (eventual) group management and the (eventual) leader election
This makes it possible to:
- Let DDS provide our latest known state automatically thanks to the TransientLocal Durability
- No need for periodically asserting our liveliness. DDS will do that for our DataWriter
Observation

Cop
yrig
ht P
rism
Tech
, 201
5
At the beginning of each epoch the leader is None Each new epoch a leader election algorithm is run
Leader Election
M1
M2
M0
crashjoin
join
join
epoch = 0 epoch = 1 epoch = 2 epoch = 3
Leader: None => M1 Leader: None => M1 Leader: None => M0 Leader: None => M0
Cop
yrig
ht P
rism
Tech
, 201
5
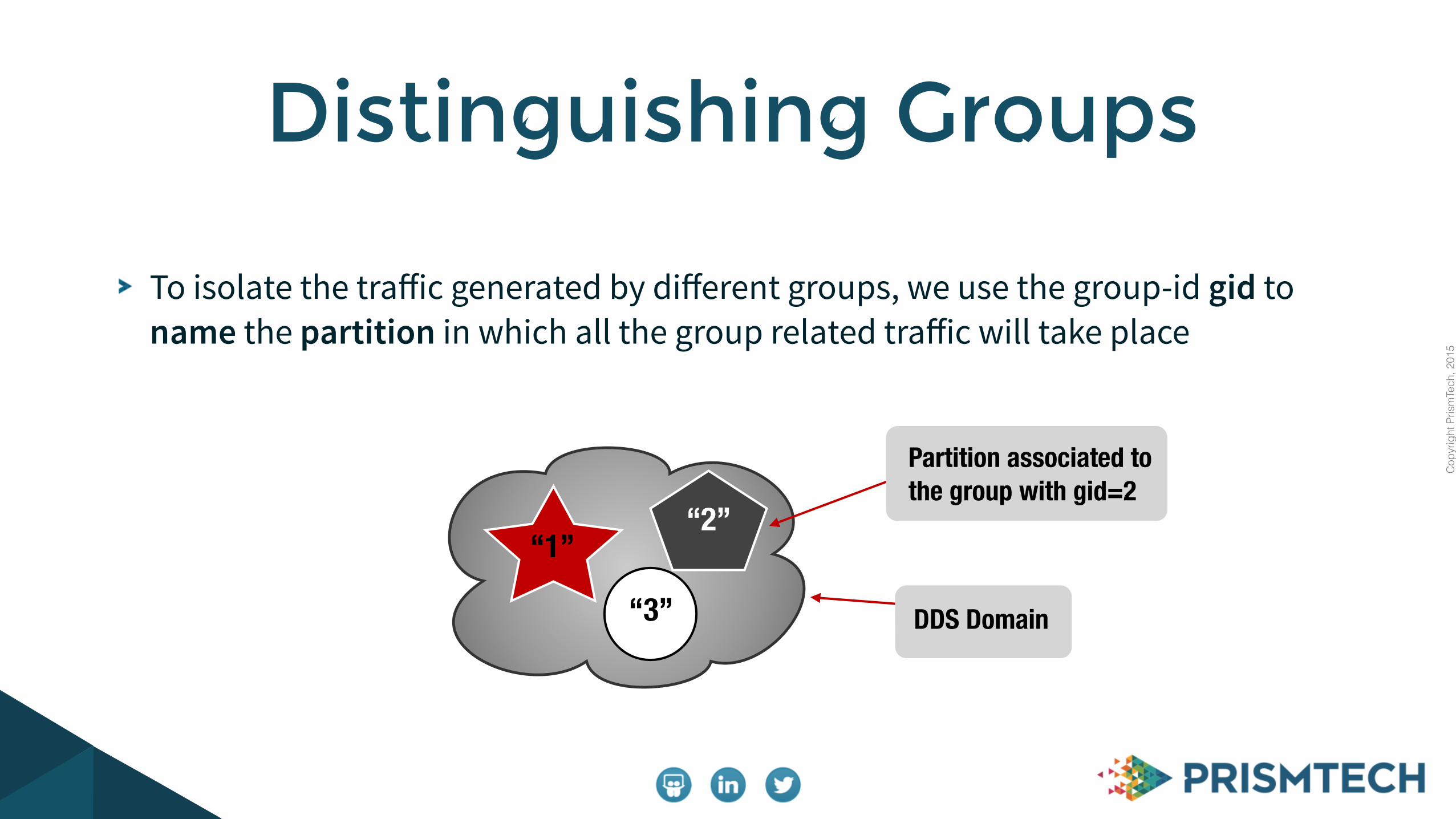
To isolate the traffic generated by different groups, we use the group-id gid to name the partition in which all the group related traffic will take place
Distinguishing Groups
“1”“2”
“3” DDS Domain
Partition associated to the group with gid=2

Cop
yrig
ht P
rism
Tech
, 201
5Events provide notification of group membership changes
These events are handled by registering partial functions with the Group reactions
Example object GroupMember { def main(args: Array[String]) { if (args.length < 2) { println("USAGE: GroupMember <gid> <mid>") sys.exit(1) } val gid = args(0).toInt val mid = args(1).toInt
val group = Group(gid)
group.join(mid)
val printGroupView = () => { print("Group["+ gid +"] = { ") group.view foreach(m => print(m + " ")) println("}")}
group listen { case MemberFailure(mid) => { println("Member "+ mid + " Failed.") printGroupView() } case MemberJoin(mid) => { println("Member "+ mid + " Joined") printGroupView() } case MemberLeave(mid) => { println("Member "+ mid +" Left") printGroupView() } } }}
[1/2]

Cop
yrig
ht P
rism
Tech
, 201
5
An eventual leader election algorithm can be implemented by simply casting a vote each time there is an group epoch change
A Group Epoch change takes place each time there is a change on the group view
The leader is eventually elected only if a majority of the process currently on the view agree
Otherwise the group leader is set to “None”
Example[2/2]
object EventualLeaderElection { def main(args: Array[String]) { if (args.length < 2) { println("USAGE: GroupMember <gid> <mid>") sys.exit(1) } val gid = args(0).toInt val mid = args(1).toInt
val group = Group(gid)
group.join(mid)
group listen { case EpochChange(e) => { val lid = group.view.min group.proposeLeader(mid, lid) } case NewLeader(l) =>
println(">> NewLeader = "+ l) } }}

Distributed Mutex

Cop
yrig
ht P
rism
Tech
, 201
5
A relatively simple Distributed Mutex Algorithm was proposed by Leslie Lamport as an example application of Lamport’s Logical Clocks
The basic protocol (with Agrawala optimization) works as follows (sketched):
- When a process needs to enter a critical section sends a MUTEX request by tagging it with its current logical clock
- The process obtains the Mutex only when he has received ACKs from all the other process in the group
- When process receives a Mutex requests he sends an ACK only if he has not an outstanding Mutex request timestamped with a smaller logical clock
Lamport’s Distributed Mutex

Cop
yrig
ht P
rism
Tech
, 201
5
A base class defines the Mutex Protocol
The Mutex companion uses dependency injection to decide which concrete mutex implementation to use
Mutex Abstraction
abstract class Mutex { def acquire()
def release()
}

Cop
yrig
ht P
rism
Tech
, 201
5
The mutual exclusion algorithm requires essentially:
- FIFO communication channels between group members
- Logical Clocks
- MutexRequest and MutexAck Messages
These needs, have now to be translated in terms of topic types, topics, readers/writers and QoS Settings
Foundation Abstractions

Cop
yrig
ht P
rism
Tech
, 201
5
For implementing the Mutual Exclusion Algorithm it is sufficient to define the following topic types:
Topic Types
struct TLogicalClock { long ts; long mid;};#pragma keylist LogicalClock mid
struct TAck { long amid; // acknowledged member-id LogicalClock ts;};#pragma keylist TAck ts.mid

Cop
yrig
ht P
rism
Tech
, 201
5
We need essentially two topics: One topic for representing the Mutex Requests, and Another topic for representing Acks
This leads us to: Topic(name = MutexRequest, type = TLogicalClock, QoS = {Reliability.Reliable, History.KeepAll}) Topic(name = MutexAck, type = TAck, QoS = {Reliability.Reliable, History.KeepAll})
Topics

Cop
yrig
ht P
rism
Tech
, 201
5
All the algorithms presented were implemented using DDS and Scala
The resulting library has been baptized “dada” (DDS Advanced Distributed Algorithms) and is available under LGPL-v3
Show me the Code!

Cop
yrig
ht P
rism
Tech
, 201
5
The LCMutex is one of the possible Mutex protocol, implementing the Agrawala variation of the classical Lamport’s Algorithm
LCMutex
class LCMutex(val mid: Int, val gid: Int, val n: Int)(implicit val logger: Logger) extends Mutex {
private var group = Group(gid) private var ts = LogicalClock(0, mid) private var receivedAcks = new AtomicLong(0)
private var pendingRequests = new SynchronizedPriorityQueue[LogicalClock]() private var myRequest = LogicalClock.Infinite
private val reqDW = DataWriter[TLogicalClock](LCMutex.groupPublisher(gid), LCMutex.mutexRequestTopic, LCMutex.dwQos)
private val reqDR = DataReader[TLogicalClock](LCMutex.groupSubscriber(gid), LCMutex.mutexRequestTopic, LCMutex.drQos)
private val ackDW = DataWriter[TAck](LCMutex.groupPublisher(gid), LCMutex.mutexAckTopic, LCMutex.dwQos)
private val ackDR = DataReader[TAck](LCMutex.groupSubscriber(gid), LCMutex.mutexAckTopic, LCMutex.drQos)
private val ackSemaphore = new Semaphore(0)

Cop
yrig
ht P
rism
Tech
, 201
5
LCMutex.acquire
def acquire() { ts = ts.inc() myRequest = ts reqDW write myRequest ackSemaphore.acquire() }
Notice that as the LCMutex is single-threaded we can’t issue concurrent acquire.

Cop
yrig
ht P
rism
Tech
, 201
5
LCMutex.release
Notice that as the LCMutex is single-threaded we can’t issue a new request before we release.
def release() { myRequest = LogicalClock.Infinite (pendingRequests dequeueAll) foreach { req => ts = ts inc() ackDW write new TAck(req.id, ts) } }

Cop
yrig
ht P
rism
Tech
, 201
5
LCMutex.onACKackDR listen { case DataAvailable(dr) => { // Count only the ACK for us val acks = ((ackDR take) filter (_.amid == mid)) val k = acks.length
if (k > 0) { // Set the local clock to the max (tsi, tsj) + 1 synchronized { val maxTs = math.max(ts.ts, (acks map (_.ts.ts)).max) + 1 ts = LogicalClock(maxTs, ts.id) } val ra = receivedAcks.addAndGet(k) val groupSize = group.size // If received sufficient many ACKs we can enter our Mutex! if (ra == groupSize - 1) { receivedAcks.set(0) ackSemaphore.release() } } } }

Cop
yrig
ht P
rism
Tech
, 201
5
LCMutex.onReqreqDR.reactions += { case DataAvailable(dr) => { val requests = (reqDR take) filterNot (_.mid == mid)
if (requests.isEmpty == false ) { synchronized { val maxTs = math.max((requests map (_.ts)).max, ts.ts) + 1 ts = LogicalClock(maxTs, ts.id) } requests foreach (r => { if (r < myRequest) { ts = ts inc() val ack = new TAck(r.mid, ts) ackDW ! ack None } else { (pendingRequests find (_ == r)).getOrElse({ pendingRequests.enqueue(r) r}) } }) } } }

Distributed Queue

Cop
yrig
ht P
rism
Tech
, 201
5
A distributed queue conceptually provides the ability of enqueueing and dequeueing elements
Depending on the invariants that are guaranteed the distributed queue implementation can be more or less efficient
In what follows we’ll focus on a relaxed form of distributed queue, called Eventual Queue, which while providing a relaxed yet very useful semantics is amenable to high performance implementations
Distributed Queue Abstraction
Cop
yrig
ht P
rism
Tech
, 201
5
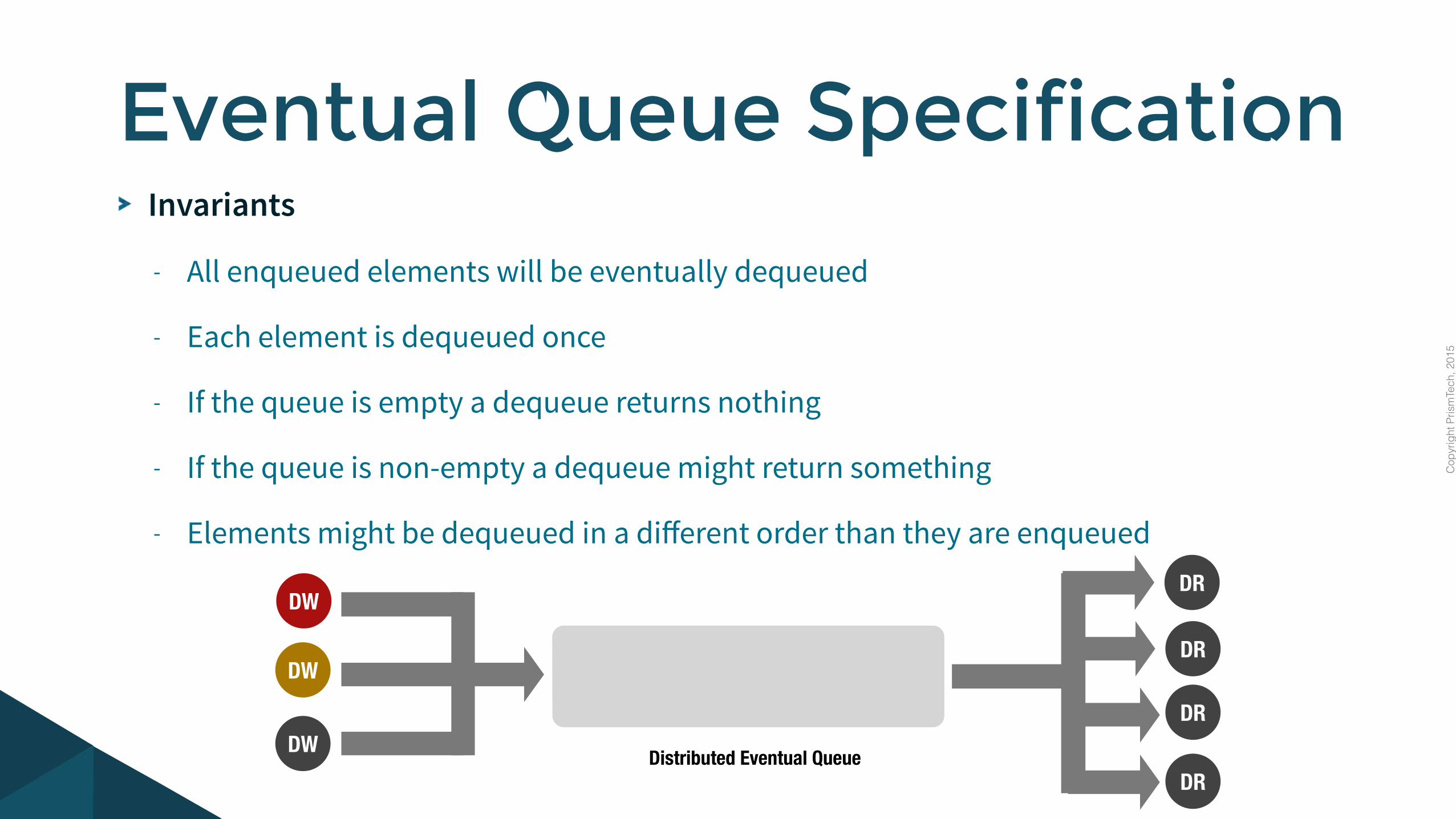
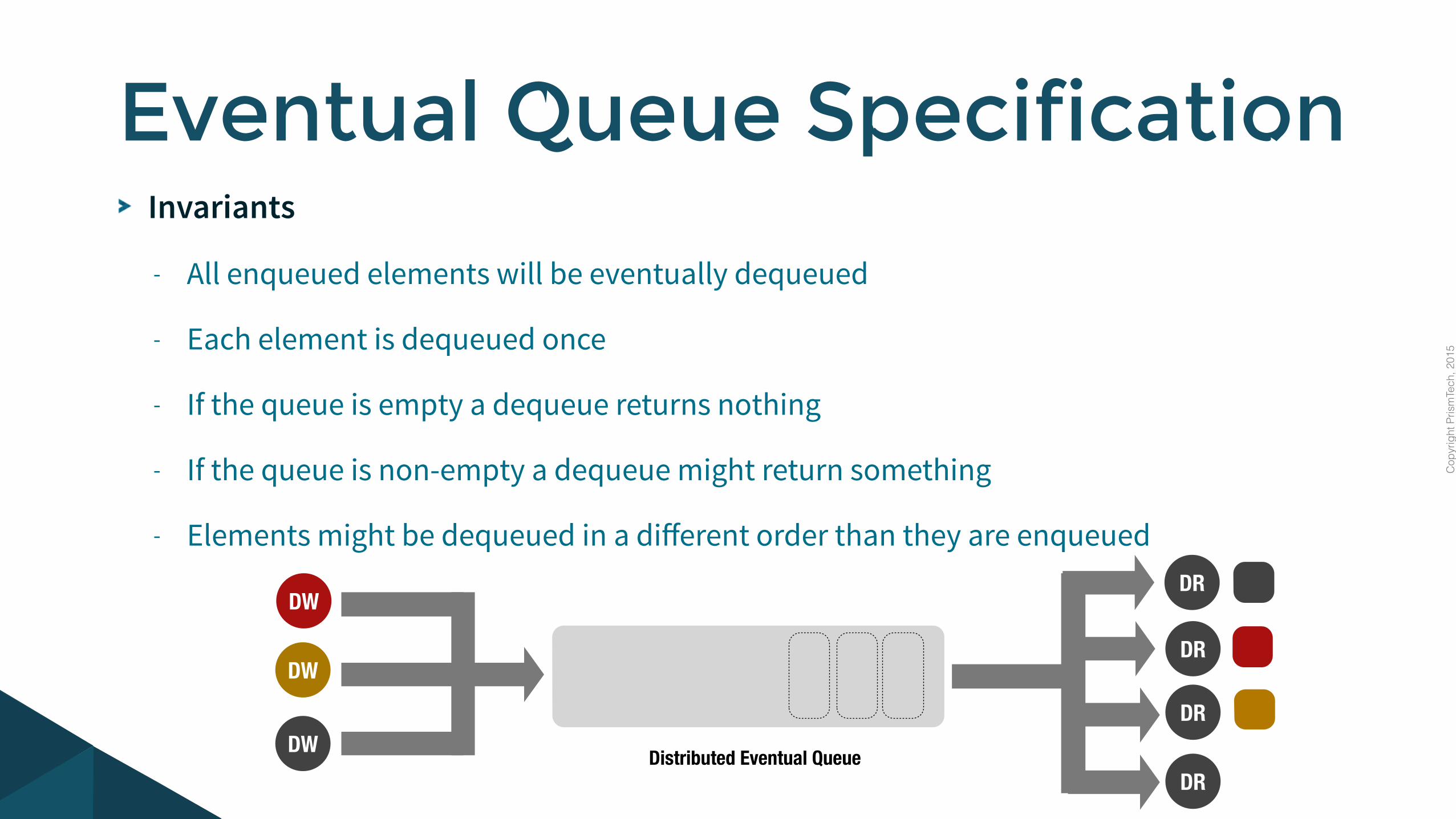
Invariants
- All enqueued elements will be eventually dequeued
- Each element is dequeued once
- If the queue is empty a dequeue returns nothing
- If the queue is non-empty a dequeue might return something
- Elements might be dequeued in a different order than they are enqueued
Eventual Queue Specification
DR
DR
DR
DW
DW
DW
DRDistributed Eventual Queue
Cop
yrig
ht P
rism
Tech
, 201
5
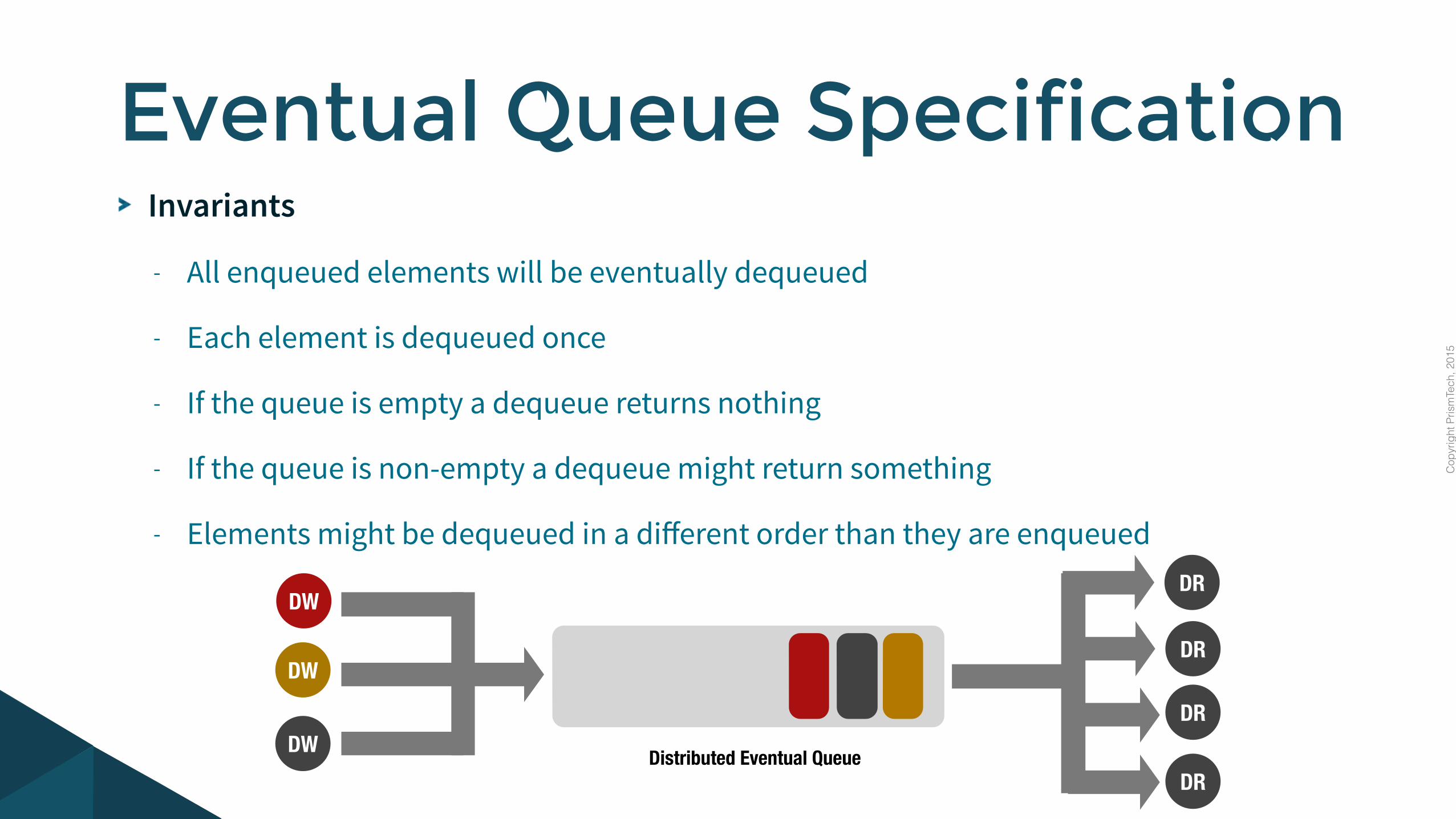
Invariants
- All enqueued elements will be eventually dequeued
- Each element is dequeued once
- If the queue is empty a dequeue returns nothing
- If the queue is non-empty a dequeue might return something
- Elements might be dequeued in a different order than they are enqueued
Eventual Queue Specification
DR
DR
DR
DW
DW
DW
DRDistributed Eventual Queue
Cop
yrig
ht P
rism
Tech
, 201
5
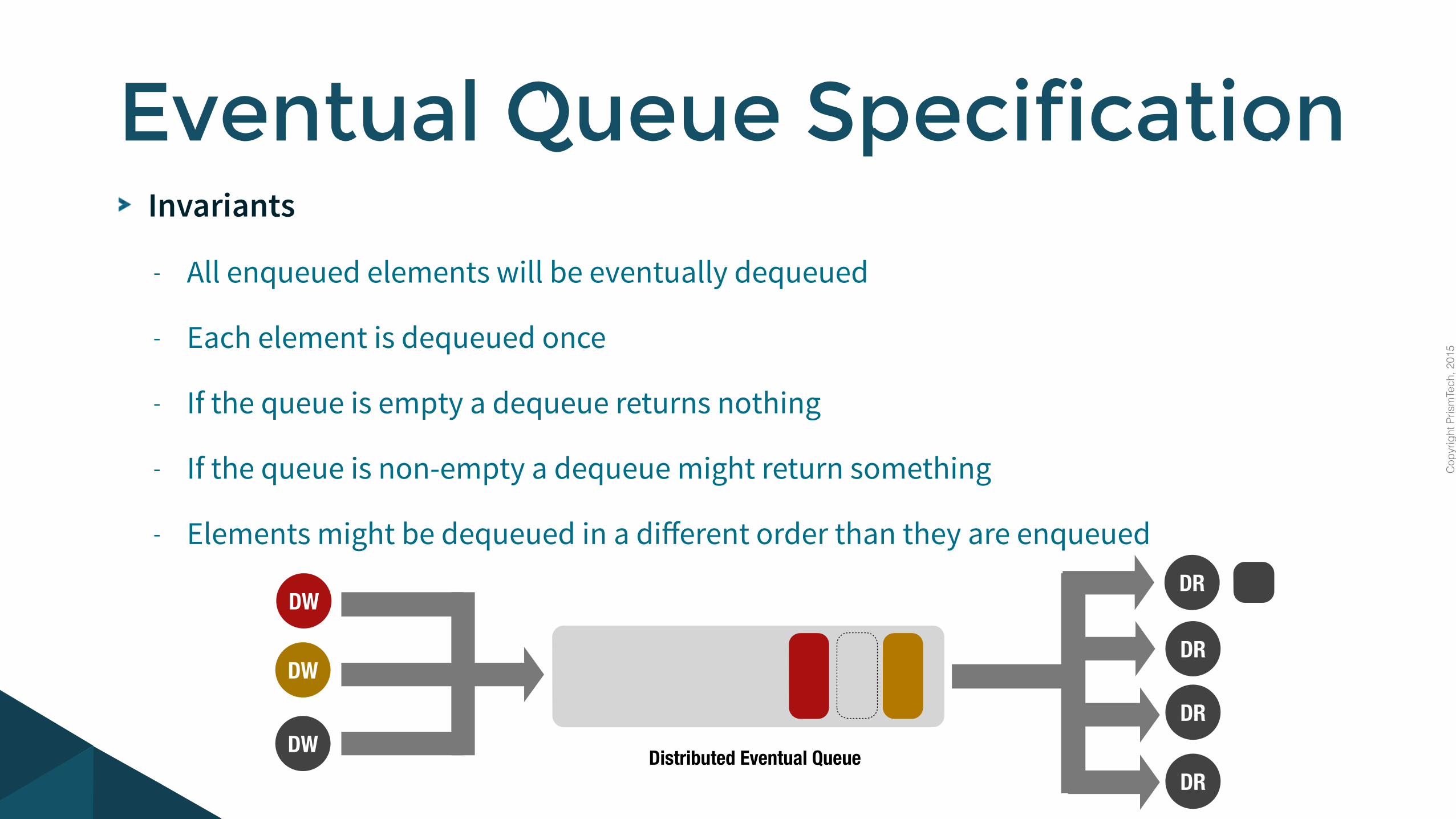
Invariants
- All enqueued elements will be eventually dequeued
- Each element is dequeued once
- If the queue is empty a dequeue returns nothing
- If the queue is non-empty a dequeue might return something
- Elements might be dequeued in a different order than they are enqueued
Eventual Queue Specification
DR
DR
DR
DW
DW
DW
DRDistributed Eventual Queue
Cop
yrig
ht P
rism
Tech
, 201
5
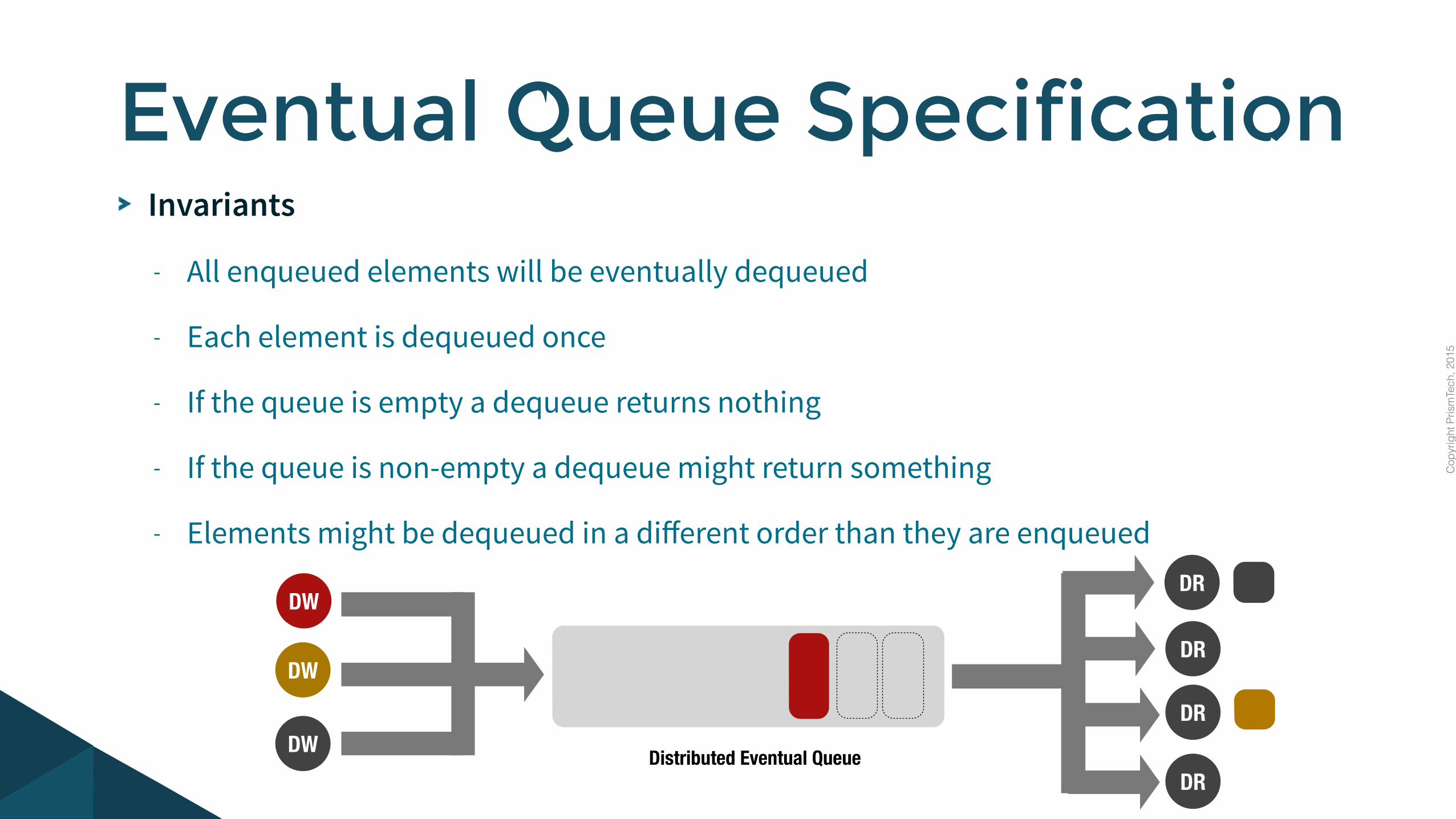
Invariants
- All enqueued elements will be eventually dequeued
- Each element is dequeued once
- If the queue is empty a dequeue returns nothing
- If the queue is non-empty a dequeue might return something
- Elements might be dequeued in a different order than they are enqueued
Eventual Queue Specification
DR
DR
DR
DW
DW
DW
DRDistributed Eventual Queue
Cop
yrig
ht P
rism
Tech
, 201
5
Invariants
- All enqueued elements will be eventually dequeued
- Each element is dequeued once
- If the queue is empty a dequeue returns nothing
- If the queue is non-empty a dequeue might return something
- Elements might be dequeued in a different order than they are enqueued
Eventual Queue Specification
DR
DR
DR
DW
DW
DW
Distributed Eventual QueueDR

Cop
yrig
ht P
rism
Tech
, 201
5
A Queue can be seen as the composition of two simpler data structure, a Dequeue and an Enqueue
The Enqueue simply allows to add elements
The Enqueue simply allows to get elements
Eventual Queue Abstraction
trait Enqueue[T] { def enqueue(t: T)}
trait Dequeue[T] { def dequeue(): Option[T] def sdequeue(): Option[T] def length: Int def isEmpty: Boolean = length == 0}
trait Queue[T] extends Enqueue[T] with Dequeue[T]

Cop
yrig
ht P
rism
Tech
, 201
5
One approach to implement the eventual queue on DDS is to keep a local queue on each of the consumer and to run a coordination algorithm to enforce the Eventual Queue Invariants
The advantage of this approach is that the latency of the dequeue is minimized and the throughput of enqueues is maximised (we’ll see this latter is really a property of the eventual queue)
The disadvantage, for some use cases, is that the consumer need to store the whole queue locally thus, this solution is applicable for either symmetric environments running on LANs
Eventual Queue on DDS

Cop
yrig
ht P
rism
Tech
, 201
5
All enqueued elements will be eventually dequeued Each element is dequeued once If the queue is empty a dequeue returns nothing If the queue is non-empty a dequeue might return something
- These invariants require that we implement a distributed protocol for ensuring that values are eventually picked up and picked up only once!
Elements might be dequeued in a different order than they are enqueued
Eventual Queue Invariants & DDS

Cop
yrig
ht P
rism
Tech
, 201
5
All enqueued elements will be eventually dequeued If the queue is empty a dequeue returns nothing If the queue is non-empty a dequeue might return something
Elements might be dequeued in a different order than they are enqueued
- This essentially means that we can have different local order for the queue elements on each consumer. Which in turns means that we can distribute enqueued elements by simple DDS writes!
- The implication of this is that the enqueue operation is going to be as efficient as a DDS write
- Finally, to ensure eventual consistency in presence of writer faults we’ll take advantage of OpenSplice’s FT-Reliability!
Eventual Queue Invariants & DDS

Cop
yrig
ht P
rism
Tech
, 201
5
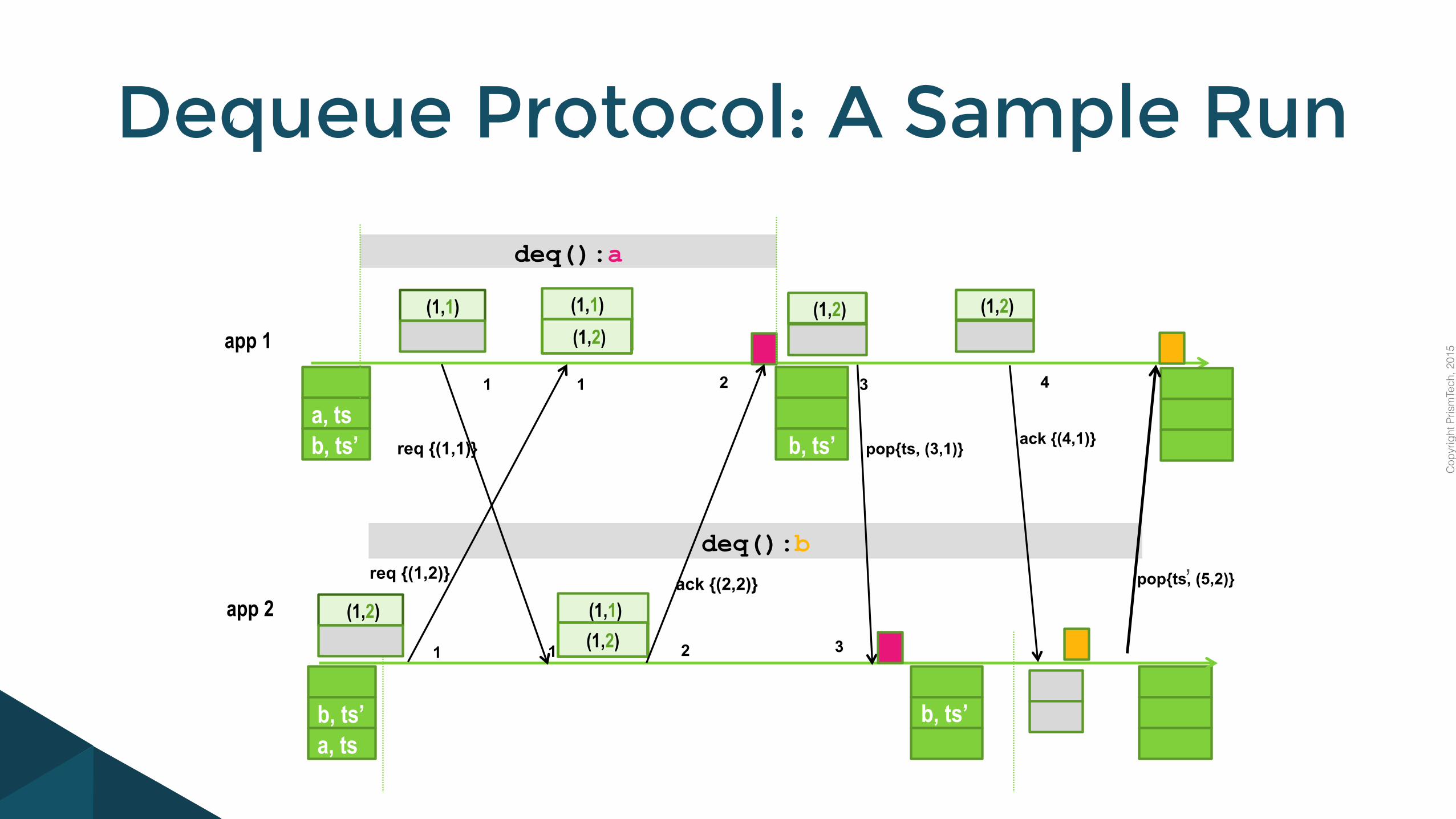
A possible Dequeue protocol can be derived by the Lamport/Agrawala Distributed Mutual Exclusion Algorithm
The general idea is similar as we want to order dequeues as opposed to access to some critical section, however there are some important details to be sorted out to ensure that we really maintain the eventual queue invariants
Key Issues to Address
- DDS provides eventual consistency thus we might have wildly different local view of the content of the queue (not just its order but the actual elements)
- Once a process has gained the right to dequeue it has to be sure that it can pick an element that nobody else has picked just before. Then he has to ensure that before he allows anybody else to pick a value his choice has to be popped by all other local queues
Dequeue Protocol: General Idea

Cop
yrig
ht P
rism
Tech
, 201
5
To implement the Eventual Queue over DDS we use three different Topic Types
The TQueueCommand represents all the commands used by the protocol (more later on this)
TQueueElement represents a writer time-stamped queue element
Topic Typesstruct TLogicalClock { long long ts; long mid;};
enum TCommandKind { DEQUEUE, ACK, POP};
struct TQueueCommand { TCommandKind kind; long mid; TLogicalClock ts;};#pragma keylist TQueueCommand
typedef sequence<octet> TData;struct TQueueElement { TLogicalClock ts; TData data;};#pragma keylist TQueueElement

Cop
yrig
ht P
rism
Tech
, 201
5To implement the Eventual Queue we need only two topics: One topic for representing the queue elements Another topic for representing all the protocol messages. Notice that the choice of using a single topic for all the protocol messages was carefully made to be able to ensure FIFO ordering between protocol messages
Topics

Cop
yrig
ht P
rism
Tech
, 201
5
This leads us to:
Topic(name = QueueElement, type = TQueueElement, QoS = {Reliability.Reliable, History.KeepAll})
Topic(name = QueueCommand, type = TQueueCommand, QoS = {Reliability.Reliable, History.KeepAll})
Topics
Cop
yrig
ht P
rism
Tech
, 201
5
Dequeue Protocol: A Sample Run
deq():a
a, ts b, ts’
app 1 (1,1)
req {(1,2)}
deq():b ack {(2,2)}
(1,1) (1,2)
pop{ts, (3,1)}
req {(1,1)}
1 1 2
1 1 2 3
3
ack {(4,1)}
4
pop{ts, (5,2)}
app 2
b, ts’ a, ts
(1,2) (1,1) (1,2)
b, ts’
b, ts’
(1,2) (1,2)
’

Cop
yrig
ht P
rism
Tech
, 201
5
Example: Producerobject MessageProducer { def main(args: Array[String]) { if (args.length < 4) { println("USAGE:\n\t MessageProducer <mid> <gid> <n> <samples>") sys.exit(1) } val mid = args(0).toInt val gid = args(1).toInt val n = args(2).toInt val samples = args(3).toInt val group = Group(gid) group listen { case MemberJoin(mid) => println("Joined M["+ mid +"]") } group.join(mid) group.waitForViewSize(n)
val queue = Enqueue[String]("CounterQueue", mid, gid)
for (i <- 1 to samples) { val msg = "MSG["+ mid +", "+ i +"]" println(msg) queue.enqueue(msg) // Pace the write so that you can see what's going on Thread.sleep(300) } }}

Cop
yrig
ht P
rism
Tech
, 201
5
Example: Consumerobject MessageConsumer { def main(args: Array[String]) { if (args.length < 4) { println("USAGE:\n\t MessageProducer <mid> <gid> <readers-num> <n>") sys.exit(1) } val mid = args(0).toInt val gid = args(1).toInt val rn = args(2).toInt val n = args(3).toInt val group = Group(gid)
group.reactions += { case MemberJoin(mid) => println("Joined M["+ mid +"]") } group.join(mid) group.waitForViewSize(n)
val queue = Queue[String]("CounterQueue", mid, gid, rn)
val baseSleep = 1000 while (true) { queue.sdequeue() match { case Some(s) => println(Console.MAGENTA_B + s + Console.RESET) case _ => println(Console.MAGENTA_B + "None" + Console.RESET) } val sleepTime = baseSleep + (math.random * baseSleep).toInt Thread.sleep(sleepTime) } }}

Dealing with Faults

Cop
yrig
ht P
rism
Tech
, 201
5The algorithms presented so far can be easily extended to deal with failures by taking advantage of group abstraction presented earlier
The main issue to carefully consider is that if a timing assumption is violated thus leading to falsely suspecting the crash of a process safety of some of those algorithms might be violated!
Fault-Detectors

Paxos

Cop
yrig
ht P
rism
Tech
, 201
5
Paxos is a protocol for state-machine replication proposed by Leslie Lamport in his “The Part-time Parliament”
The Paxos protocol works in under asynchrony -- to be precise, it is safe under asynchrony and has progress under partial synchrony (both are not possible under asynchrony due to FLP) -- and admits a crash/recovery failure mode
Paxos requires some form of stable storage
The theoretical specification of the protocol is very simple and elegant
The practical implementations of the protocol have to fill in many hairy details...
Paxos in Brief

Cop
yrig
ht P
rism
Tech
, 201
5
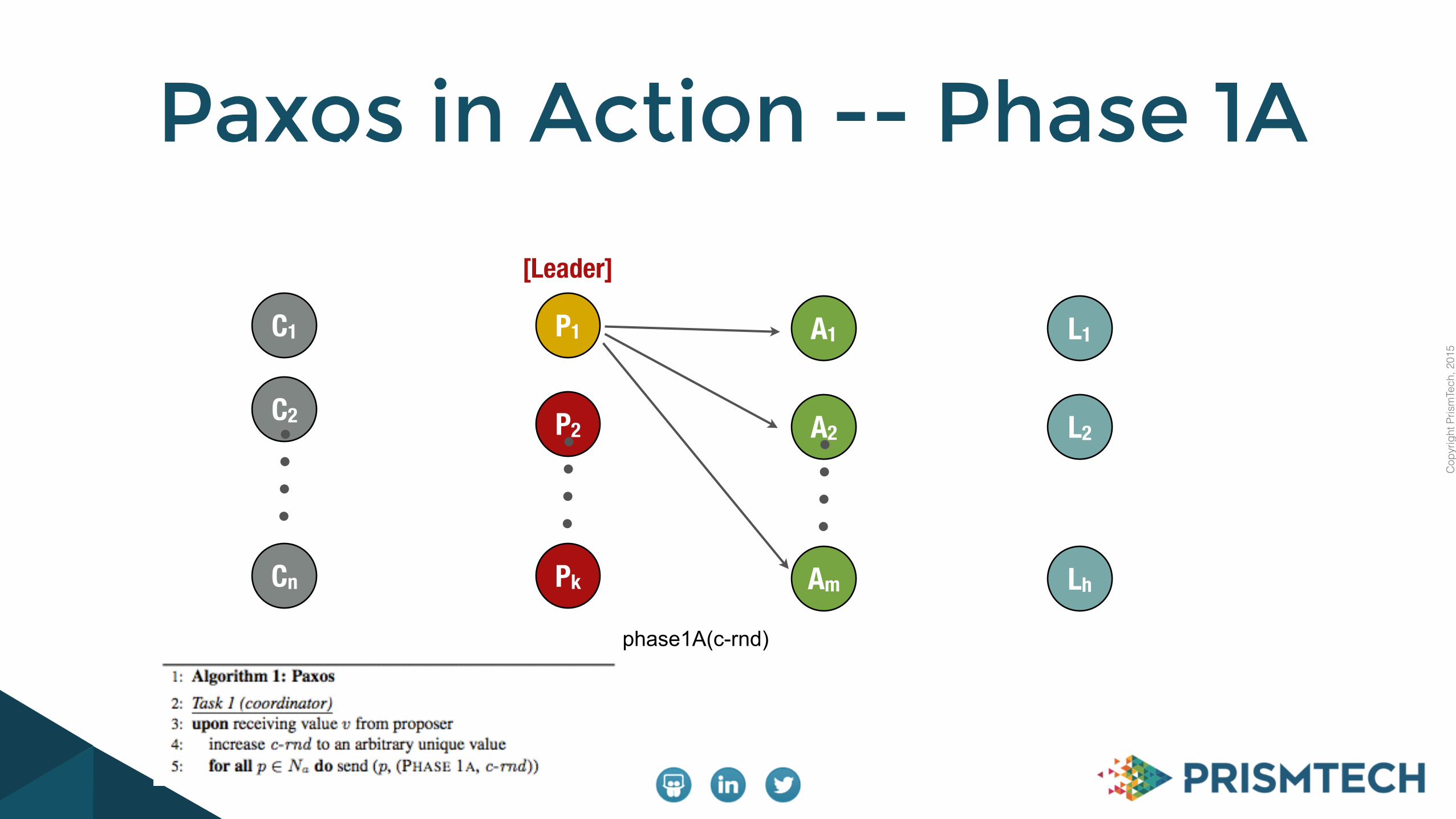
The Paxos protocol considers three different kinds of agents (the same process can play multiple roles):
- Proposers
- Acceptors
- Learners
To make progress the protocol requires that a proposer acts as the leader in issuing proposals to acceptors on behalf of clients
The protocol is safe even if there are multiple leaders, in that case progress might be scarified
- This implies that Paxos can use an eventual leader election algorithm to decide the distinguished proposer
Paxos in Brief

Cop
yrig
ht P
rism
Tech
, 201
5
Paxos Synod Protocol

Cop
yrig
ht P
rism
Tech
, 201
5
Paxos in Action
C1
C2
Cn
P1
P2
Pk
A2
Am
A1
L2
Lh
L1
[Leader]
Cop
yrig
ht P
rism
Tech
, 201
5
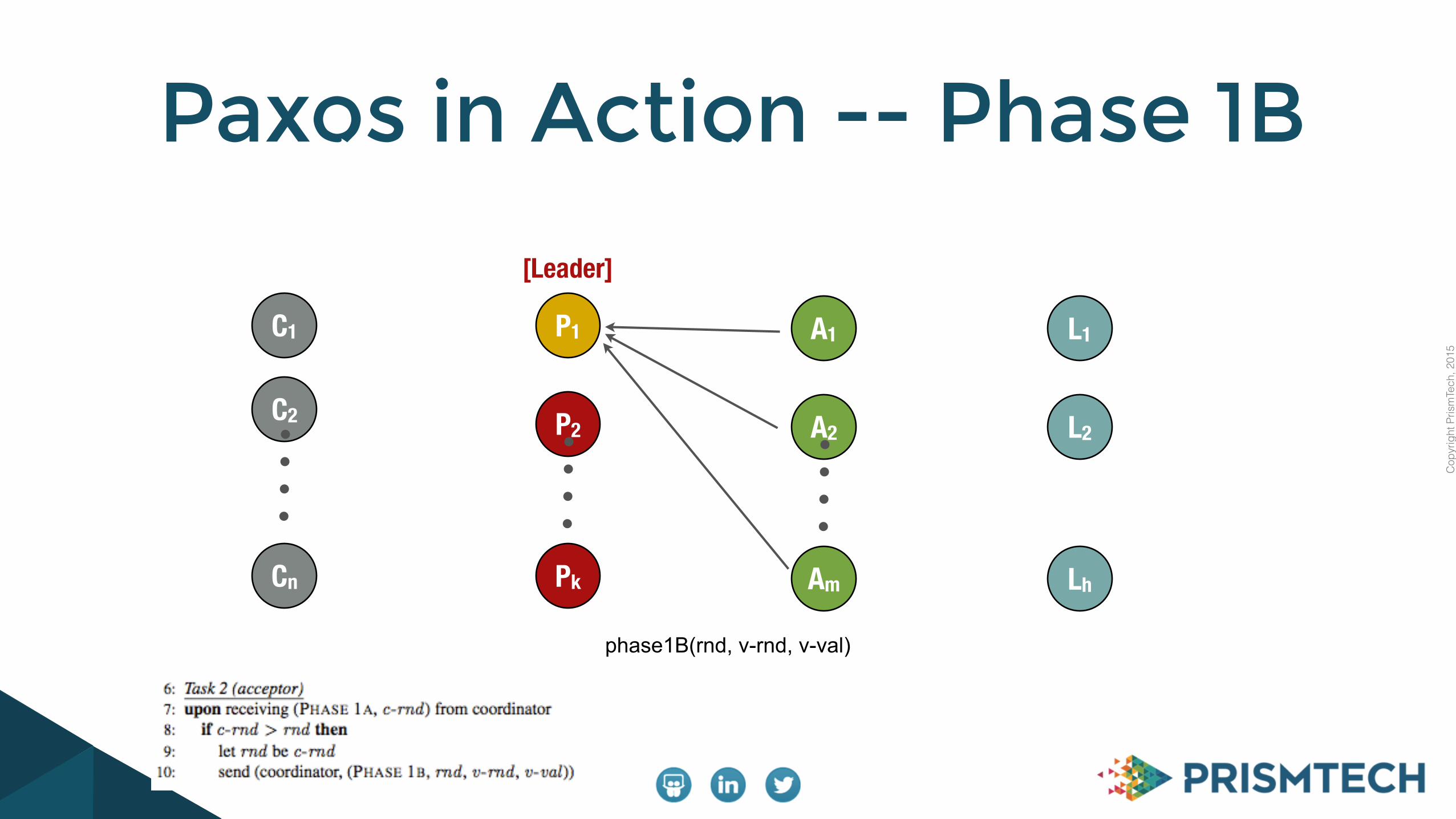
Paxos in Action -- Phase 1A
C1
C2
Cn
P1
P2
Pk
[Leader]
A2
Am
A1
L2
Lh
L1
phase1A(c-rnd)
Cop
yrig
ht P
rism
Tech
, 201
5
Paxos in Action -- Phase 1B
C1
C2
Cn
P1
P2
Pk
[Leader]
A2
Am
A1
L2
Lh
L1
phase1B(rnd, v-rnd, v-val)
Cop
yrig
ht P
rism
Tech
, 201
5
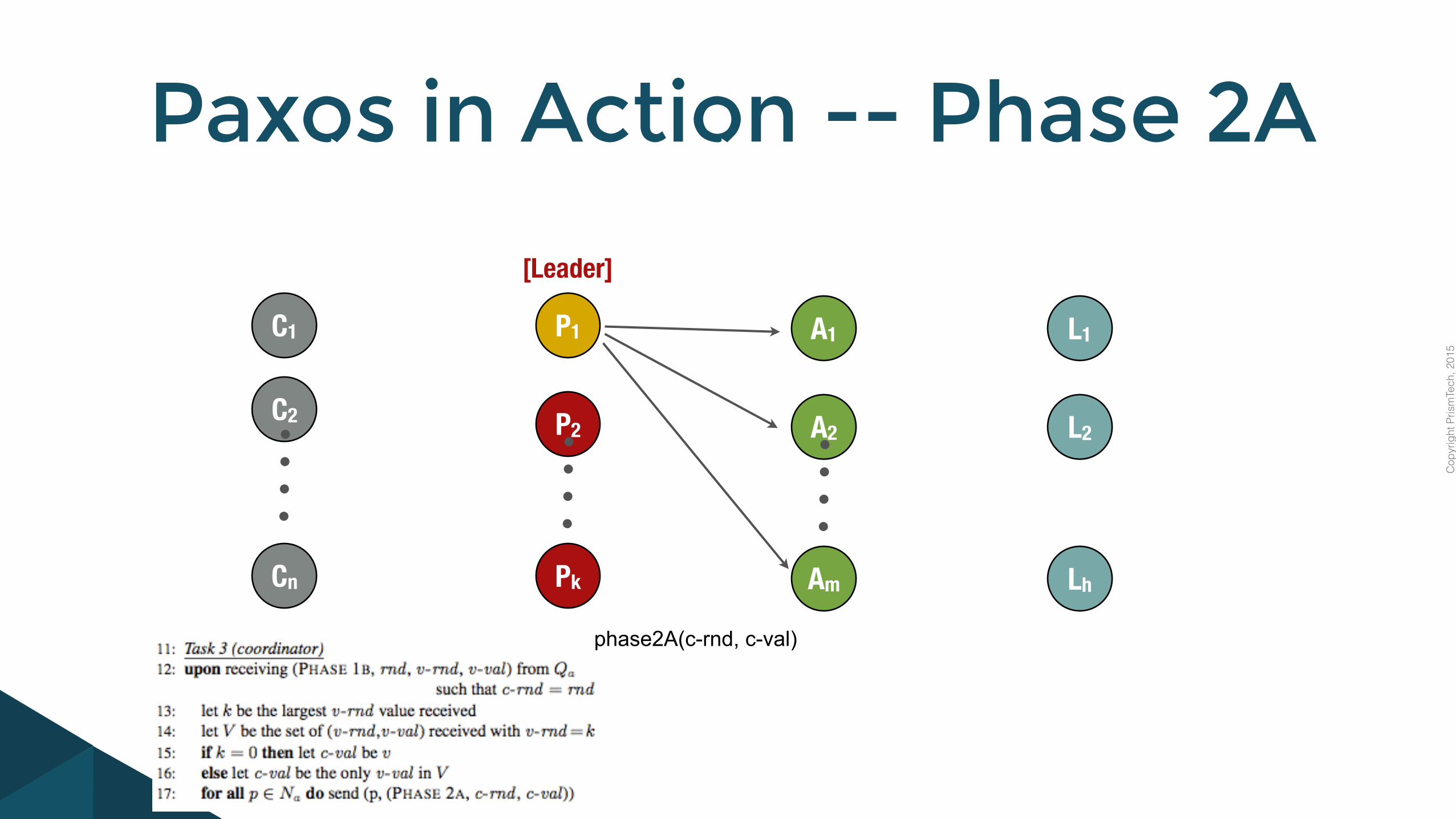
Paxos in Action -- Phase 2A
C1
C2
Cn
P1
P2
Pk
[Leader]
A2
Am
A1
L2
Lh
L1
phase2A(c-rnd, c-val)
Cop
yrig
ht P
rism
Tech
, 201
5
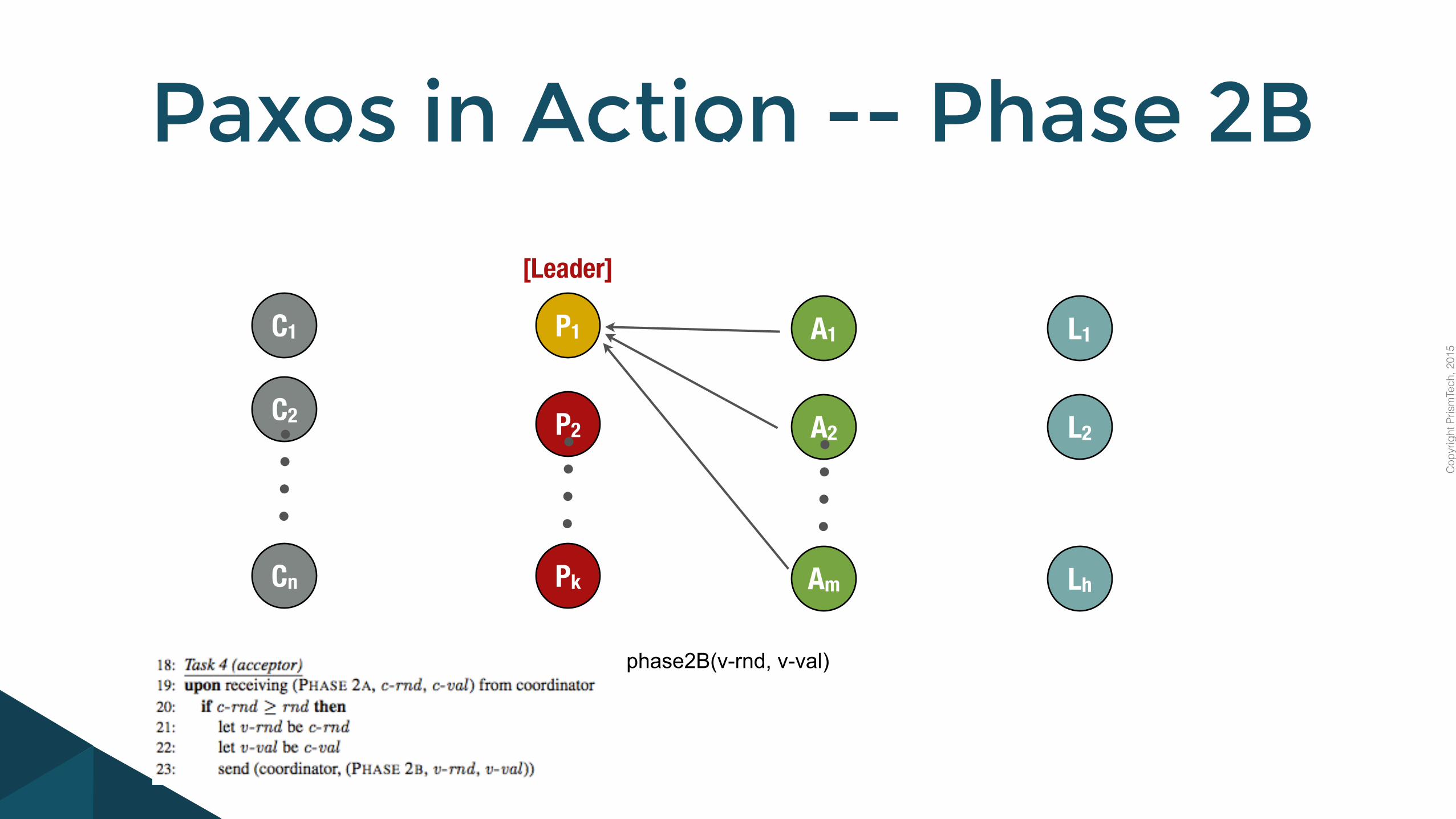
Paxos in Action -- Phase 2B
C1
C2
Cn
P1
P2
Pk
[Leader]
A2
Am
A1
L2
Lh
L1
phase2B(v-rnd, v-val)
Cop
yrig
ht P
rism
Tech
, 201
5
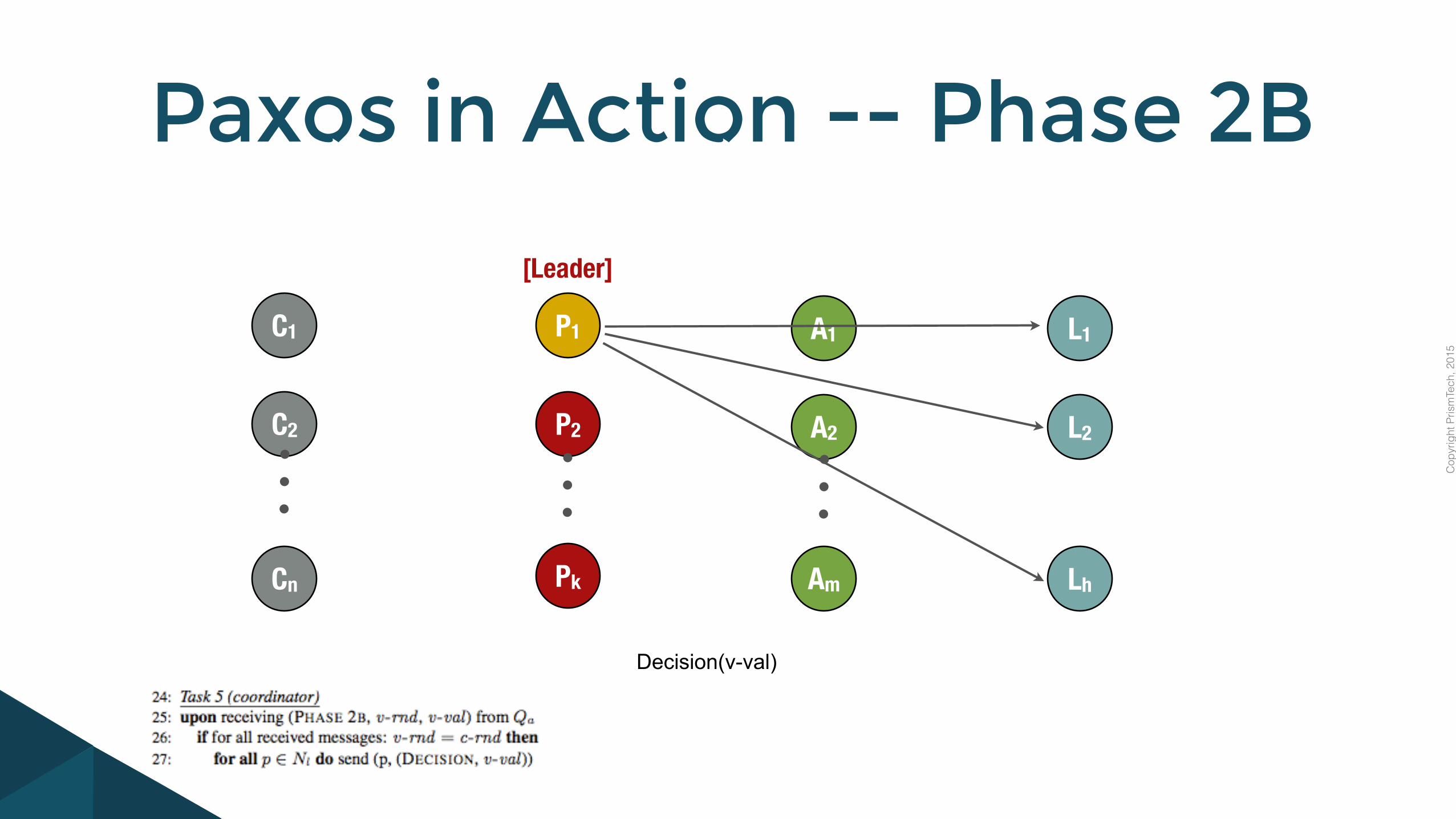
Paxos in Action -- Phase 2B
C1
C2
Cn
P1
P2
Pk
[Leader]
A2
Am
A1
L2
Lh
L1
Decision(v-val)
Cop
yrig
ht P
rism
Tech
, 201
5
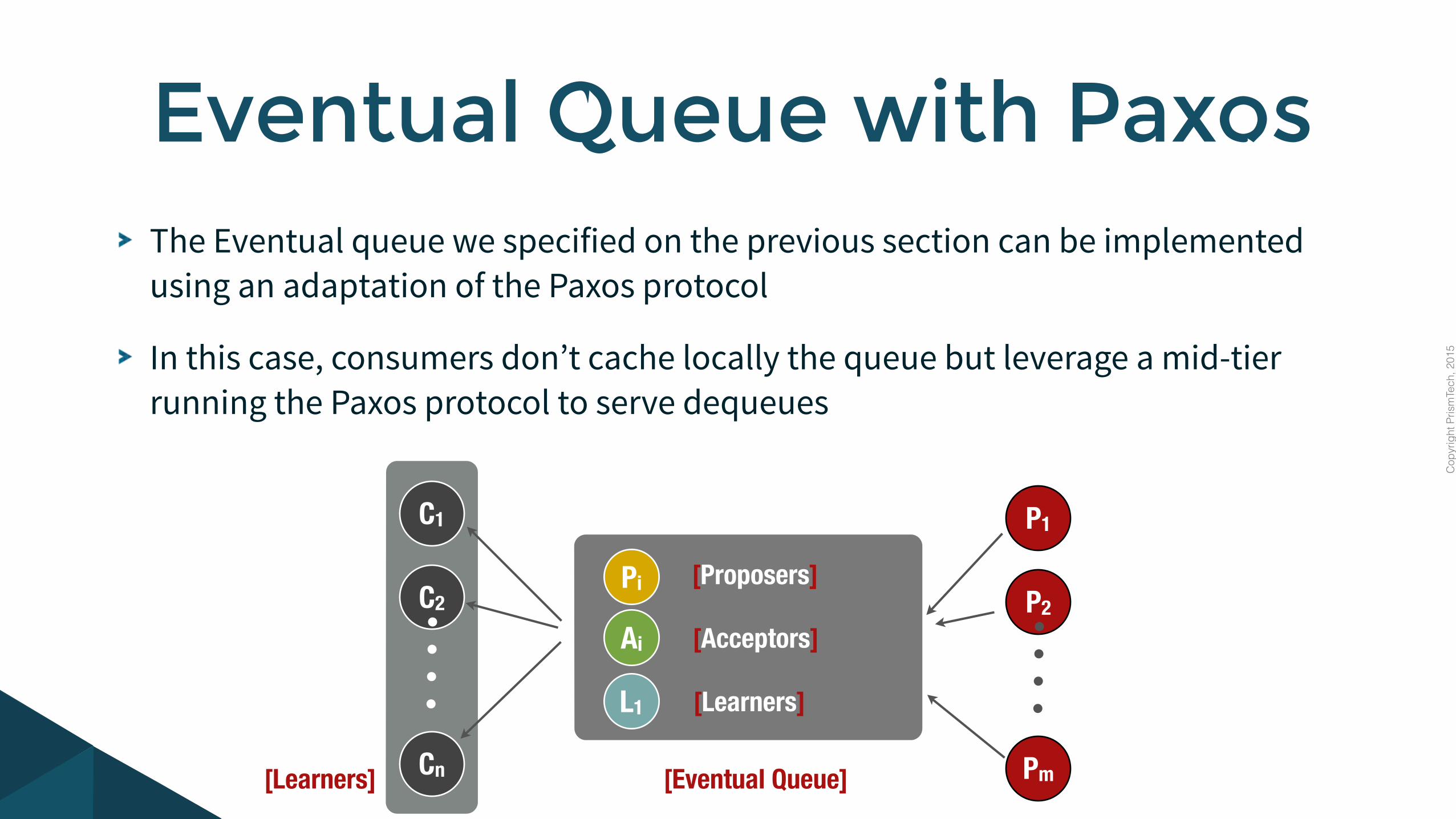
The Eventual queue we specified on the previous section can be implemented using an adaptation of the Paxos protocol
In this case, consumers don’t cache locally the queue but leverage a mid-tier running the Paxos protocol to serve dequeues
Eventual Queue with Paxos
C1
C2
Cn
P1
P2
Pm[Learners]
Pi
Ai
[Proposers]
[Acceptors]
[Eventual Queue]
L1 [Learners]

Summing Up

Cop
yrig
ht P
rism
Tech
, 201
5
DDS provides a good foundation to effectively and efficiently express some of the most important distributed algorithms
- e.g. DataWriter fault-detection and FT-Reliable Multicast
dada provides access to reference implementations of many of the most important distributed algorithms
- It is implemented in Scala, but that means you can also use these libraries from Java too!
Concluding Remarks

Cop
yrig
ht P
rism
Tech
, 201
5

Cop
yrig
ht P
rism
Tech
, 201
5
struct Point { long x, long y }
struct Point3D : Point { long z }