Embed Size (px)
Citation preview

● Currently a Senior Site Reliability Engineer for Claranet|Bashton
● Background in Software Engineering, Systems Engineering & System Administration
● Contributed to several open source projects (YAWL, PostgreSQL & Terraform)
● Been using Linux & Open Source software since 1999
About Me

● Typical cloud migration strategies
● The drawbacks of typical cloud migration strategies
● The five theses of a disposable infrastructure
● How we build a disposable infrastructure
Overview

● Duplicate existing estate in the cloud
● Use cloud as spare/batch capacity
● Brave New World
– Greenfield development
– “Version 2.0”
Approaching Cloud Migration

● Direct mapping of existing infrastructure to the cloud
– Load balancers become Elastic Load Balancers
– SANs become Buckets or Elastic File Systems
● Minimal operational change required
– Everything is the same just in a new location
● Perceived as a “quick win” to cloud adoption
– Little AWS/GCP/Azure specific knowledge required
The Appeal of a Lift & Shift

● No “legacy” baggage
● Free reign for experimentation
● Perceived as a “low risk” path to cloud adoption
– If it doesn’t work, switch it off
– “No risk” to existing production environment
The Appeal of a Brave New World

● Are we just building a traditional but virtual data centre?
– Lift & Shift is operationally the same
– Brave New World isn’t part of the Real World
● How are we leveraging the power of a dynamic infrastructure?
– Our infrastructure is scalable, but is the application?
● Are we using IAAS where we could be using PAAS?
– e.g. Running a message broker instead of SQS
Are we really “doing cloud”?

● We’re changing only where our hardware is
– Instance size based on current hardware size
– No change to deployment process
● Under utilisation of resource
– Still paying for excess capacity
● Stunted scalability
– We can throw more virtual hardware at it
– Add additional node behind load balancers
The Penalty of a Lift & Shift

● Organisationally isolated
– Limited impact to existing practices
– Leads to a “Us vs. Them” mentality
● Focus is usually on application functionality with infrastructure seen as a necessity
● Project has a high risk of failure
– Care free scoping leads to an unfocused project
– Significant time can be lost to integrating with the old world
The Penalty of a Brave New World

● Conway’s Law: “Organisations which design systems … are constrained to produce designs which are copies of the communication structures of these organisations”
● Kief Morris: “In many cases, applying existing patterns will, at best, miss out on opportunities to leverage newer technology to simplify and improve the architecture. At worst, replicating existing patterns with the newer platforms will involve adding even more complexity.”
● Fred Brooks: “A scaling-up of a software entity is not merely a repetition of the same elements in larger size; it is necessarily an increase in the number of different elements. In most cases, the elements interact with each other in some nonlinear fashion, and the complexity of the whole increases much more than linearly.”
Breaking the Mould

1) The attitude you have to your environment will determine the limits of your scalability
2) Continuous integration (CI) and delivery (CD) is a must
3) Your applications need to be (re)built to fit a dynamic infrastructure
4) Dynamic infrastructure must be treated as a first class citizen in any cloud project
5) Planning to fail will lead to success
The Five Theses

● The more you care about individual things the more they will hold your attention
● In a truly scalable environment you should only care about the combination of many individual things
Attitude
Thesis 1
The attitude you have to your environment will determine the limits of your scalability

● You treat your servers like pets
– You give them names (igloo, husky, snowshoe)
– You give them homes (racks on site or co-located)
– If they fail, you do everything you can to save them
● Every server is an investment
– Often the best hardware that can be afforded
– Amortised over years
– Excess capacity to allow for growth
● Provisioning new servers takes weeks
Attitude: Living in the Iron Age

● You treat your servers like cattle
– They have identifiers
– You care only where they are geographically
– If they fail, you put them down and get a new one
● Your architecture is your investment
– Configuration is chosen for your current load
– Pay for what you use
– Capacity can be added when required
● Provisioning new servers takes seconds
Attitude: Living in the Cloud Age

● Are we simply herding our pets?
– In a Lift & Shift this is almost certainly so
– Scaling groups is a start but it is not the end
● How are we managing our virtual servers?
– Complex cloud-init scripts?
– Traditional configuration management?
Attitude: Is Pets v Cattle enough?

● Everything is a package and can be discarded
● You treat your servers like single use products
– They’re pre-packaged for a particular purpose
– You still care only where they are geographically
– If they fail, you toss it away and grab another
● You automate everything
– Servers should be immutable
– Never make a manual change
Attitude: The Disposable Infrastructure

● Repeatability brings reliability and predictability
● Defining a build pipeline:
– Ensures the same process is followed for every change
– Provides an audit trail for every change
– Gives visibility of your value stream
Be Continuous
Thesis 2
Continuous integration (CI) and delivery (CD) is a must

● Your developers probably already practice CI
– It is the standard for code development
– The output of CI can be the start of CD
● Continuous delivery doesn’t have to mean continuous deployment
– Build pipelines can have approval stages
– Every change should be deployable
Be Continuous

● Many applications expect a static infrastructure
– Hard-coded assumptions that an IP address won’t change once an application is started
● Many applications are cluster unaware
– Sticky sessions on load balancers can help
– Some protocols don’t load balance well
Reactoring to the Cloud
Thesis 3
Your applications need to be (re)built to fit a dynamic infrastructure

● Refactor to contemporary architectural approaches
– Service Oriented Architectures & Microservices
– Transition from stateful services to stateless
● Package everything using distribution packagers
– The output of your build pipeline is a RPM/DEB
– Your $CM_TOOL already supports this
● Chose a deployment strategy
– Machine images vs. containers
Reactoring to the Cloud

● Fear not vendor lock in, savings are to be reaped leveraging commodity services
– Use SQS instead of automating the installation and configuration of a message broker and accepting the operational burden of maintaining it
– Careful abstraction of the API will allow porting to a different platform if absolutely necessary
Reactoring to the Cloud

● Design the infrastructure in parallel to the cloud aware application changes
● Mandate every instance is part of a scaling group to enforce cluster awareness
● Use the same principles for infrastructure development as you use for applications
Infrastructure is Code
Thesis 4
Dynamic infrastructure must be treated as a first class citizen in any cloud project

● Script/encode everything unless there is no API/tooling support
● Deploy the same infrastructure in development, test and production environments
– Sizing can be parameterised
● Your deployment pipeline becomes the assembly of application packages and infrastructure configuration
● High cohesion and loose coupling applies to infrastructure as much as it does to applications
Infrastructure is Code

● If it can go wrong, it will go wrong so think in terms of when and not if
● Treating our infrastructure and its hosted applications as disposable in conjunction with CD eliminates a number of failure scenarios
Planning to fail
Thesis 5
Planning to fail will lead to success

● Regularly test your disposability
– Terminate instances at random to ensure resiliency
– Block all network access to an instance
– Chaos Monkey & the Simian Army
– Trigger failovers for less disposable services
● Constantly churning disposable instances helps prevent configuration drift of immutable servers
Planning to fail

● Availability and durability cost
– Favour numerous small instances over a handful of large instances
● Identify points of failure and assess:
– How often will this failure occur?
– How do I mitigate this failure?
– How do I test this failure to ensure mitigation?
– Is the cost of mitigation worth the customer impact during failure?
Planning to fail

● Be honest in assessing the worth of your business
– Do you really need to double your costs to run in multiple regions?
– Trello, Slack & many other high profile companies – including Amazon - were affected by the S3 outage
Planning to fail

● Data is not disposable and is probably more important than your availability
● Ship log files to CloudWatch or Stackdriver
● Make back-ups and regularly test they restore
– Gitlab had 5 separate backup processes, they all failed
– Consider storing backups in both S3 & Google
– Store backups in multiple regions
Data is not Disposable

● If you must use persistent disks:
– Use multiple disks and use RAID-1
– Snapshot the disks regularly
● Test the durability of your data
– User error is your biggest risk● “I forgot the WHERE clause”● “I thought I was in the test environment”
– Regularly exercise data loss & recovery scenarios in development and test environments
Data is not Disposable

● We will have two identical CI pipelines for the applications, the output of each being AMI images
● A separate CD pipeline executes infrastructure code and rolls out the new AMIs
● Goal is to promote infrastructure and AMIs between environments
Under Construction
Let us assume we have a front end web application which places orders in a queue for subsequent asynchronous fulfilment by a separate application backed by a database. We’ve already refactored our applications for the cloud.
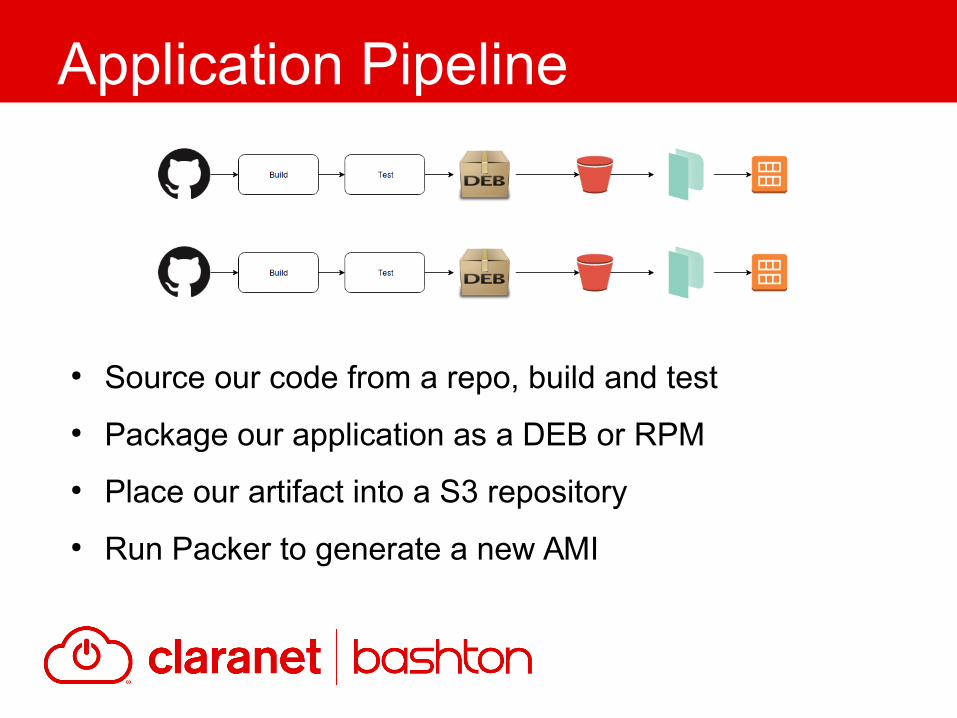
● Source our code from a repo, build and test
● Package our application as a DEB or RPM
● Place our artifact into a S3 repository
● Run Packer to generate a new AMI
Application Pipeline

● https://packer.io
● Can create many different machine images
● Consider creating a base image to control OS updates
● Use normal configuration management tools
– Support for Ansible, Chef & Puppet
– Can just write shell script if you must
● Use placeholders for configuration to be filled by launch scripts
Packer

● Triggered by new AMIs or Terraform code changes
● Apply Terraform to update the infrastructure
● Run integration tests to verify application build
● Wait for approval before promotion to next environment
Infrastructure Pipeline

● https://terraform.io
● Declarative language for the construction of infrastructure
● Supports all major vendors
● State can be stored in buckets to facilitate sharing
● Separate out infrastructure layers
– Minimises blast radius of changes
– Keep persistent apart from disposable
Terraform

● Any instance can be terminated
● Resilient to zone failure
● Cross-region read replica allows DR for region failure
– Just need to run Terraform to add the instances when required and update Route 53
Deployed Infrastructure

● Have attitude
● Be continuous
● Refactor to the Cloud
● Infrastructure is code
● Plan to fail
● Data is King
Summary