Embed Size (px)
Citation preview

1 April 2012
Dereverberation in the STFT and
log mel-frequency feature domains
Takuya Yoshioka

Dereverberation is necessaryfor many speech applications“ ”

0
10
20
30
0.2 0.3 0.4 0.5 0.6
ASR (connected digit recognition)
T60 in seconds
Word
err
or
rate
in %

ASR (LVCSR using WSJ-20K)
0
20
40
60
80
100
Clean training +MLLR Multi-style training
Word
err
or
rate
in
%

Source separation
T60=0.3 s T60=0.5 s0
2
4
6
8
10
12S
NR
in
dB

And others…
• Source localization
• Adaptive beamforming
• VAD

Dereverberation is necessaryfor many speech applications“ ”

Acoustic feature extraction process
STFT
| ・ |2
Mel FB
Log compression
DCT
Δ, ΔΔ
Microphone
Decoder

Acoustic feature extraction process
STFT
| ・ |2
Mel FB
Log compression
DCT
Δ, ΔΔ
Microphone
Decoder
STFT coefficients
Fully benefit fromthe use of
microphone arrays

Acoustic feature extraction process
STFT
| ・ |2
Mel FB
Log compression
DCT
Δ, ΔΔ
Microphone
Decoder
Power spectra
Easy to combinewith noise suppressors

Acoustic feature extraction process
STFT
| ・ |2
Mel FB
Log compression
DCT
Δ, ΔΔ
Microphone
Decoder
Log mel-frequencyfeatures
Efficient for reducingthe acoustic mismatchbetween observations
and training data

n: frame index
ny: corrupted vector
nx: clean vector
nx̂: estimate of xn
Notations

Optimal estimation in the MMSE sense
nn xx̂ ),,|(p 1nnYY,|X pastyyx ndx

nn xx̂ ),,|(p 1nnYY,|X pastyyx ndx
),,,|(p 11-nnnYX,|Y pastyyxy )(p nX x
×
Clean speech modelReverberation model
Generative approach (using Bayes rule)

nn xx̂ ),,|(p 1nnYY,|X pastyyx ndx
),,,|(p 11-nnnYX,|Y pastyyxy )(p nX x
×
Clean speech modelReverberation model
Generative approach (using Bayes rule)

STFT domain
Clean speech model
Reverberation model
Posterior distribution
Parameter estimation
Clean speech model
Reverberation model
Posterior distribution
Parameter estimation
Log mel-frequency feature domain
Linear prediction
VTS

STFT domain
Clean speech model
Reverberation model
Posterior distribution
Parameter estimation
Clean speech model
Reverberation model
Posterior distribution
Parameter estimation
Log mel-frequency feature domain

n: frame index
ny :corrupted complex-valued spectrum(consisting of 257 bins)
nx: clean complex-valued spectrum
nx̂: estimate of xn
Notations

j
Xjn,jn,CNnX,nX )λ;0,(xf)Λ;(p x
Clean STFT coefficients: normally distributed
XJn,
Xn,1 λ,...,λ
XnP1,...,p
Xpn, σ,)(a 2
p
piωXpn,
XnX
jn,jea1
σλ
All-pole model
No model
Model Form Parameters
Clean PSD

STFT domain
Clean speech model
Reverberation model
Posterior distribution
Parameter estimation
Clean speech model
Reverberation model
Posterior distribution
Parameter estimation
Log mel-frequency feature domain

1-source 1-microphone case: multi-step LP
Δpjp,njp,jn,jn, ygxy
1,2,...njn, )(y
1,2,...njn, )(x

1-source 1-microphone case: multi-step LP
Δpjp,njp,jn,jn, ygxy
+
1,2,...njn, )(y
1,2,...njn, )(x

)xygδ (y
)Λ;y,,y,x|(yp
jn,jn,p jp,jn,
Rj1,j1,-njn,jn,YX,|Y past

STFT domain
Clean speech model
Reverberation model
Posterior distribution
Parameter estimation
Clean speech model
Reverberation model
Posterior distribution
Parameter estimation
Log mel-frequency feature domain

When model parameters are known
jn,p jp,jn,jn, ygyx ˆˆ
)ygyδ (x jn,p jp,jn,jn, ˆ
)Λ,Λ;y,y|(xp RXj1,jn,jn,YY,|X past
ˆˆ
Inverse filtering

STFT domain
Clean speech model
Reverberation model
Posterior distribution
Parameter estimation
Clean speech model
Reverberation model
Posterior distribution
Parameter estimation
Log mel-frequency feature domain

ML for parameter estimation
j n
RXj1,j1,-njn,Y|YRX )Λ,Λ;y,y|(ylogp)Λ,L(Λpast

ML for parameter estimation
j n
RXj1,j1,-njn,Y|YRX )Λ,Λ;y,y|(ylogp)Λ,L(Λpast
∫
×
)xygδ (y
)Λ;y,,y,x|(yp
jn,jn,p jp,jn,
Rj1,j1,-njn,jn,YX,|Y past
j
Xjn,jn,CN
nX,nX
)λ;0,(xf
)Λ;(p x

ML for parameter estimation
j n
RXj1,j1,-njn,Y|YRX )Λ,Λ;y,y|(ylogp)Λ,L(Λpast
j n
Xjn,
2
p jp,njp,jn,Xjn, λ
|ygy|)log(λ

ML for parameter estimation
j n
RXj1,j1,-njn,Y|YRX )Λ,Λ;y,y|(ylogp)Λ,L(Λpast
j n
Xjn,
2
p jp,njp,jn,Xjn, λ
|ygy|)log(λ
n
Xjn,
2
p jp,njp,jn,
ΛjR,
λ
|ygy|argminΛ
jR,ˆ
ˆ
If is knownXjn,λ̂

Iterative optimization
Initializing ΛR
Inverse filtering
Updating ΛR
Convergent?
Updating ΛR
RΛ̂
RΛ̂
XΛ̂

Why LP model for reverberation?Chain rule is applicable to derive the likelihood function

Drawback
Non-minimum phase terms cannot be accurately modeled
“ ”Solution: using extra microphones

Extensions
• Integration with source separation
• Integration with additive noise reduction
• Adaptive inverse filtering – Using an RLS-like algorithm
• Application to music signals– Using a clean source model accounting for
strong harmonic structures
• Exploiting prior knowledge on room properties

STFT domain
Clean speech model
Reverberation model
Posterior distribution
Parameter estimation
Clean speech model
Reverberation model
Posterior distribution
Parameter estimation
Log mel-frequency feature domain

n: frame index
ny :corrupted log mel-frequency feature(consisting of 24 coefficients)
nx: clean log mel-frequency feature
nx̂: estimate of xn
Notations
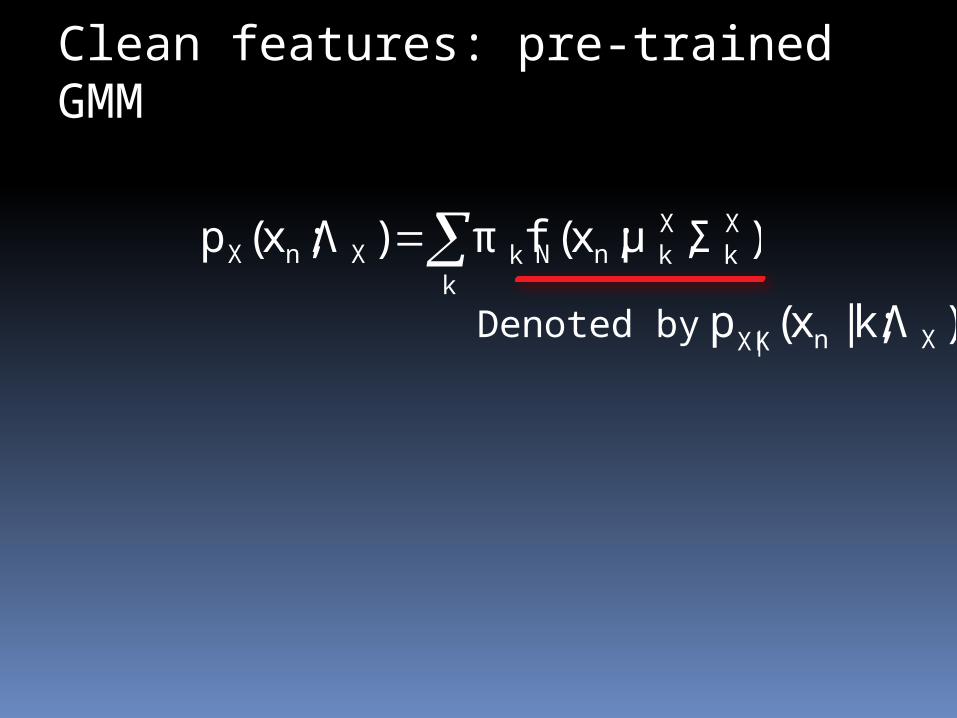
k
Xk
XknNkXnX ),;(fπ)Λ;(p Σμxx
Clean features: pre-trained GMM
)Λk;|(p XnK|X xDenoted by

STFT domain
Clean speech model
Reverberation model
Posterior distribution
Parameter estimation
Clean speech model
Reverberation model
Posterior distribution
Parameter estimation
Log mel-frequency feature domain

Reverberation model
Early reflections
Late reverberation
Directsound

Reverberation model
Early reflections
Late reverberation
HnY nX nR
Directsound
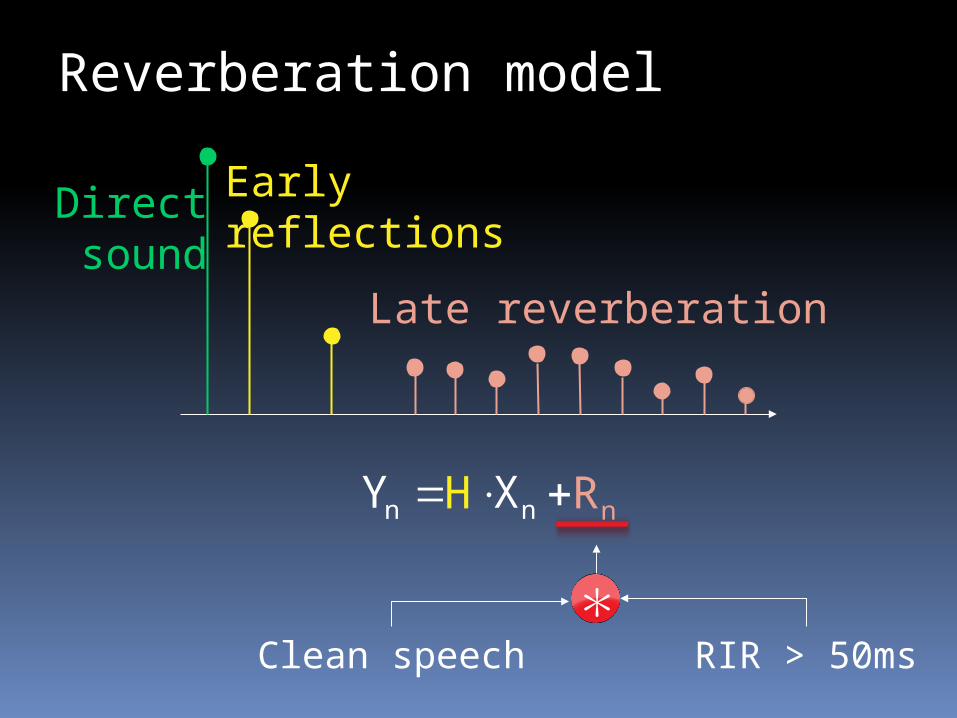
Reverberation model
Early reflections
Late reverberation
*Clean speech RIR > 50ms
HnY nX nR
Directsound


Reverberation model
Early reflections
Late reverberation
),,(
))--exp(log(1
nn
nnnn
hrxg
hxrhxy
)),,(δ ()Λ;,|(p nnnRnnnRX,|Y hrxgyrxy
Directsound

Reverberation model
)),,(δ ()Λ;,|(p nnnRnnnRX,|Y hrxgyrxy
);( RR-nnNR11-nnY|R ,f)Λ;,,|(p
pastΣβyryyr
∫×

Reverberation model
),;(f)Λk;,,,,|(p X|Ykn,
X|Ykn,nNR11-nnnK,YX,|Y past
Σμyyyxy
),,(
))(,,(R
ΔnXk
Xkn
RΔn
Xk
X|Ykn,
hβyμg
μxhβyμGμ
R2RΔn
Xk
X|Ykn, )),,(( ΣhβyμGIΣ

STFT domain
Clean speech model
Reverberation model
Posterior distribution
Parameter estimation
Clean speech model
Reverberation model
Posterior distribution
Parameter estimation
Log mel-frequency feature domain
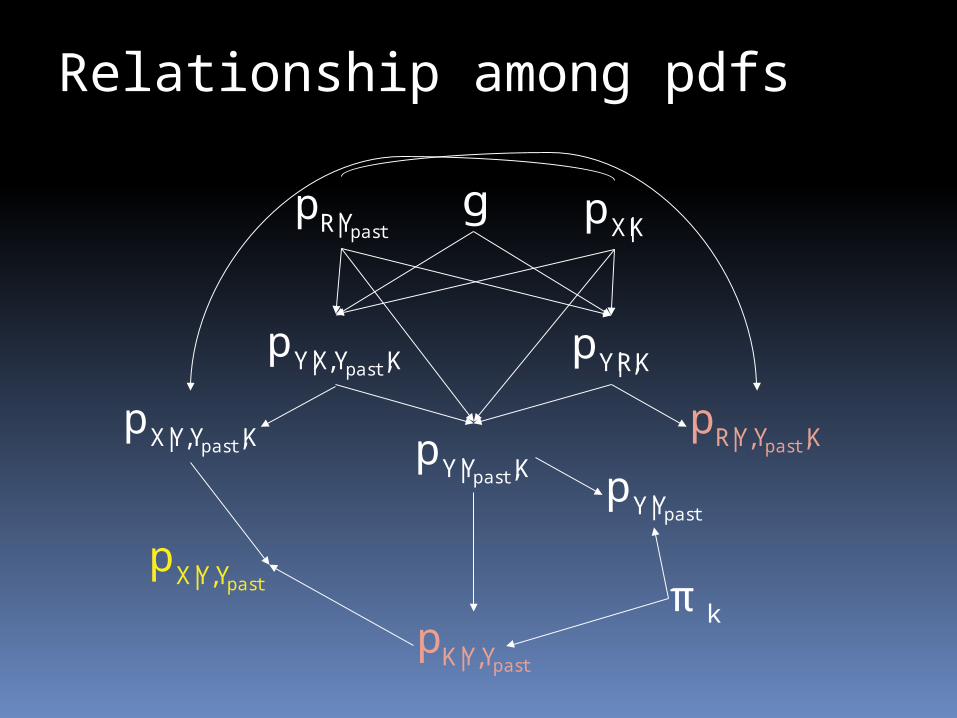
pastY|RpK|Xpg
KR,|YpK,YX,|Y pastp
pastY|YpK,Y|Y pastp
pastYY,|Kp
K,YY,|X pastp K,YY,|R past
p
pastYY,|Xpkπ
Relationship among pdfs

Connected digit recognition
• 1024-component GMM for VTS
• Clean complex back-end defined in Aurora2
• Evaluation data set consisting of 4004 reverberant utterances– Simulated data
– Impulse responses measured in a varechoic room
– Speaker-microphone distance = 3.5 m
– T60 = 0.2~0.6 sec

0
5
10
15
20
25
30
35
0.2 0.3 0.4 0.5 0.6
Unprocessed
Dereverberated
Dereverberated(lower bound)
Word
err
or
rate
in %
T60 in seconds

Concluding remarks
• Dereverberation can be performed in different domains
• Reverberation model must accounts for the strong statistical dependencies between consecutive observation frames