Embed Size (px)
Citation preview

Anca Dumitrache, Lora Aroyo, Chris Welty http://CrowdTruth.org
Measures for Language Ambiguity Medical Relation Extraction
Linked Data for Information Extraction @ ISWC2015
#CrowdTruth @anouk_anca @laroyo @cawelty #LD4IE2015

• Most knowledge is in text, but it’s not structured
• Linked Data sources are a good start, but incomplete
• Goal (Distance Supervision): – extract LD triples from text – given exis@ng tuples find sentences
that men@on both args – use resul@ng sentences as TP to train
a classifier • But can some8mes be wrong – <PALPATION> loca8on <CHEST> – feeling the way CHEST expands
(PALPATION), can iden8fy areas of lung that are full of fluid
• Standard approach ⇒ Expert Annota8on
Background http://CrowdTruth.org

• Human annotators with domain knowledge provide be>er annotated data, e.g – if you want medical texts annotated
for medical rela@ons you need medical experts
• But experts are expensive & don’t scale
• MulFple perspecFves on data can be useful, beyond what experts believe is salient or correct
Human AnnotaFon Myth: Experts know best
What if the CROWD IS BETTER?
http://CrowdTruth.org

What is the relation between the highlighted terms?
He was the first physician to identify the relationship between HEMOPHILIA and HEMOPHILIC ARTHROPATHY.
Experts Know Best?
Crowd reads text literally -‐ provide be>er examples to machine
experts: cause crowd: no relaFon
hMp://CrowdTruth.org

Experts Know Best?
experts vs. crowd?
What is the (medical) relation between the highlighted (medical) terms?
• 91% of expert annotations covered by the crowd • expert annotators reach agreement only in 30% • most popular crowd vote covers 95% of this
expert annotation agreement
hMp://CrowdTruth.org

• rather than accep@ng disagreement as a natural property of seman@c interpreta@on
• tradi@onally, disagreement is considered a measure of poor quality in the annota@on task because: – task is poorly defined or – annotators lack training
This makes the eliminaFon of
disagreement a goal
Human AnnotaFon Myth: Disagreement is Bad
What if it is GOOD?
http://CrowdTruth.org

Disagreement Bad? Does each sentence express the TREAT relation?
ANTIBIOTICS are the first line treatment for indications of TYPHUS. → agreement 95% Patients with TYPHUS who were given ANTIBIOTICS exhibited side-effects. → agreement 80% With ANTIBIOTICS in short supply, DDT was used during WWII to control the insect vectors of TYPHUS. → agreement 50%
Disagreement can reflect the degree of clarity in a sentence
hMp://CrowdTruth.org

• Annotator disagreement is signal, not noise.
• It is indicative of the variation in human semantic interpretation of signs
• It can indicate ambiguity, vagueness, similarity, over-generality, etc, as well as quality
CrowdTruth http://CrowdTruth.org

• Goal: collecting a Medical RelEx Gold
Standard improve the performance of a
RelEx Classifier
• Approach: crowdsource 900 medical
sentences measure disagreement with
CrowdTruth Metrics train & evaluate classifier with
CrowdTruth SRS Score
CrowdTruth for medical relaFon extracFon
http://CrowdTruth.org

RelEx TA
SK in CrowdFlow
er PaFents with ACUTE FEVER and nausea could be suffering from INFLUENZA AH1N1
Is ACUTE FEVER – related to → INFLUENZA AH1N1?
hMp://CrowdTruth.org

1 1 1
Worker Vector
hMp://CrowdTruth.org
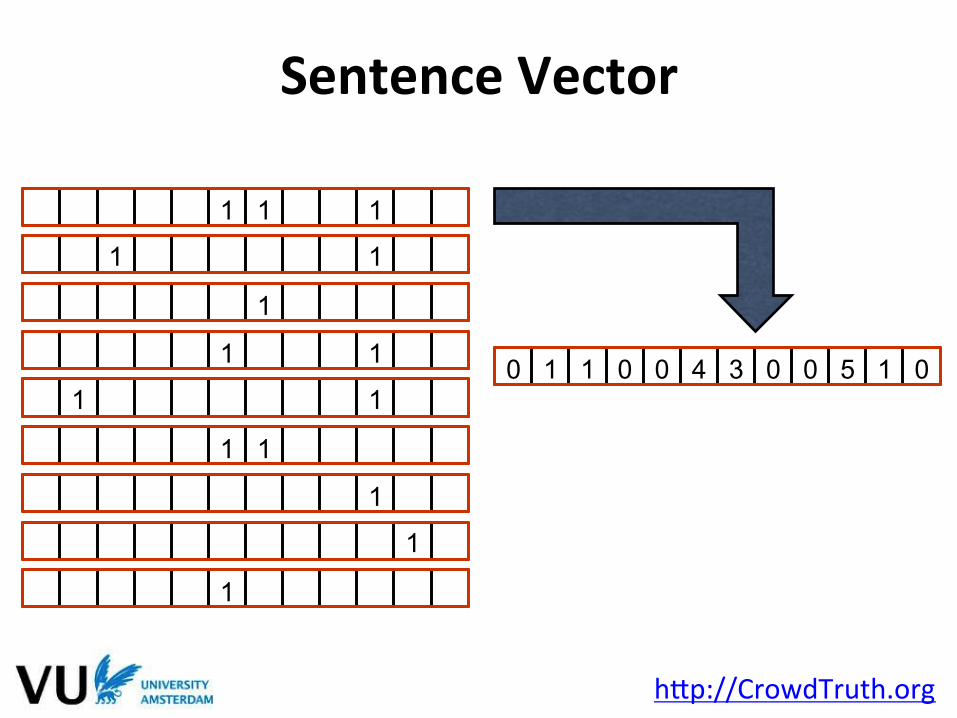
1 1 1
1 1
1
1 1
1 1
1 1
1
1
1
0 1 1 0 0 4 3 0 0 5 1 0
Sentence Vector
hMp://CrowdTruth.org

Unclear relaFonship between the two arguments reflected in the disagreement
Sentence Clarity
hMp://CrowdTruth.org

Clearly expressed relaFon between the two arguments reflected in the agreement
Sentence Clarity
hMp://CrowdTruth.org
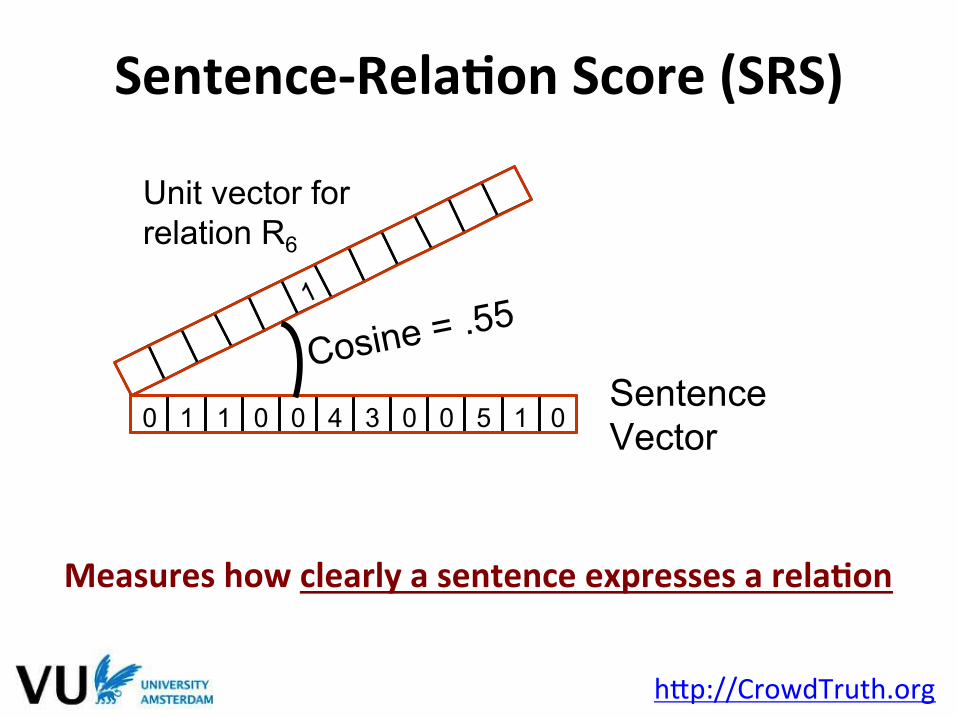
Measures how clearly a sentence expresses a relaFon
0 1 1 0 0 4 3 0 0 5 1 0
Unit vector for relation R6
Sentence Vector
Cosine = .55
Sentence-‐RelaFon Score (SRS)
hMp://CrowdTruth.org
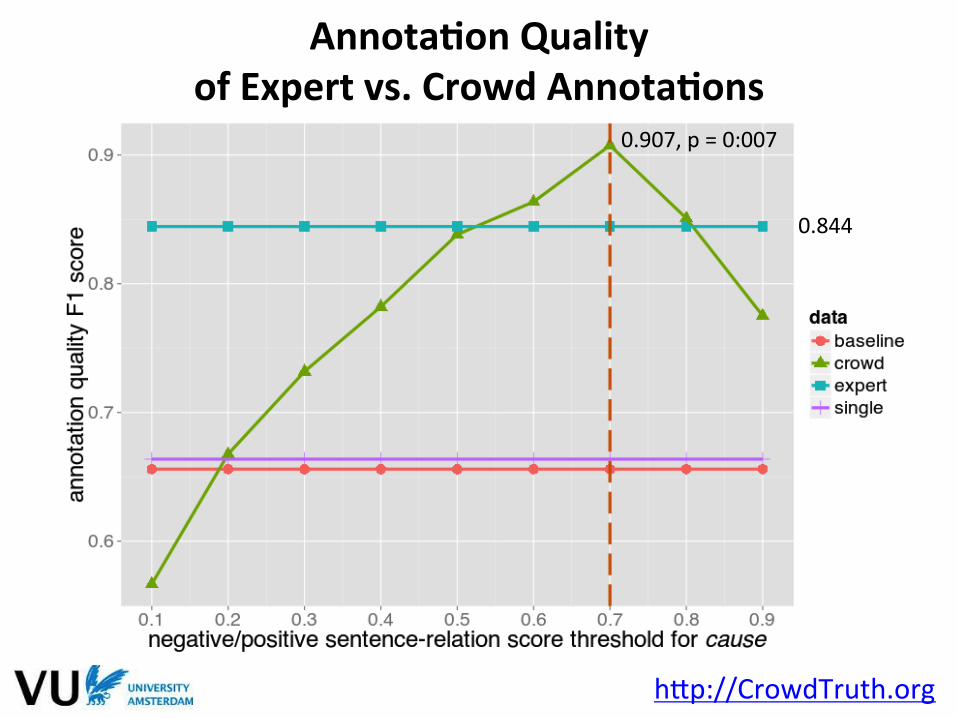
0.907, p = 0:007
0.844
AnnotaFon Quality of Expert vs. Crowd AnnotaFons
hMp://CrowdTruth.org
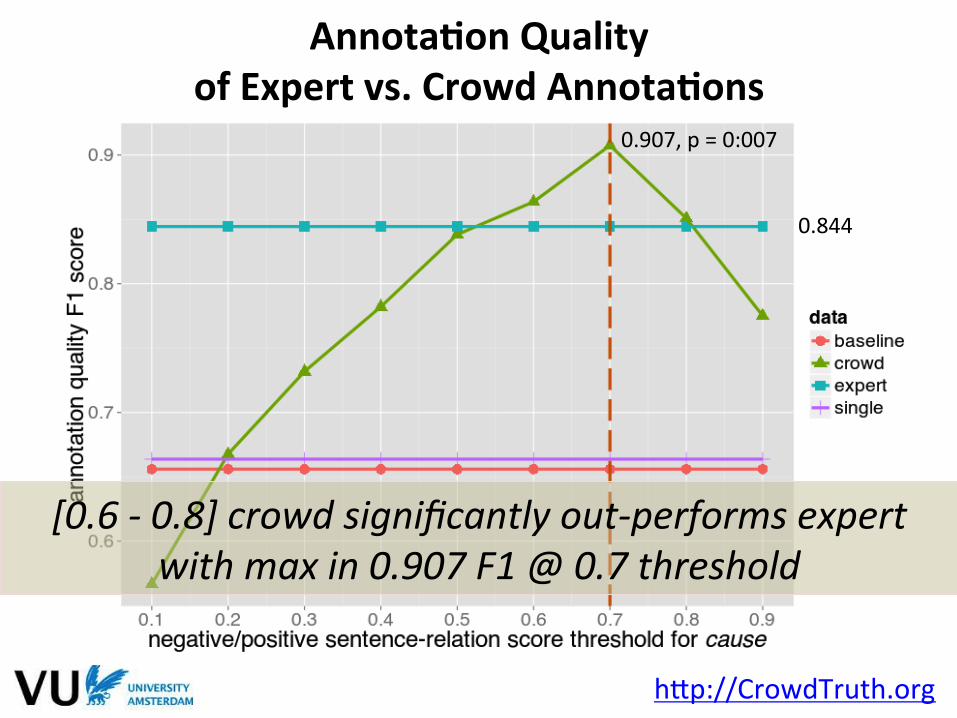
0.907, p = 0:007
0.844
[0.6 -‐ 0.8] crowd significantly out-‐performs expert with max in 0.907 F1 @ 0.7 threshold
AnnotaFon Quality of Expert vs. Crowd AnnotaFons
hMp://CrowdTruth.org

• Normally P = TP/(TP+FP) • Intuition:
– some sentences make better examples – more important to get the clear cases right – but P normally treats all examples as equal
• We propose: – weight P with sentence-relation score (SRS)
PW = ∑i (TPi x SRSi) ∑i (TPi x SRSi) + ∑i (FPi x SRSi)
*and similarly for F1, Recall, and Accuracy
Weighted Precision*
hMp://CrowdTruth.org
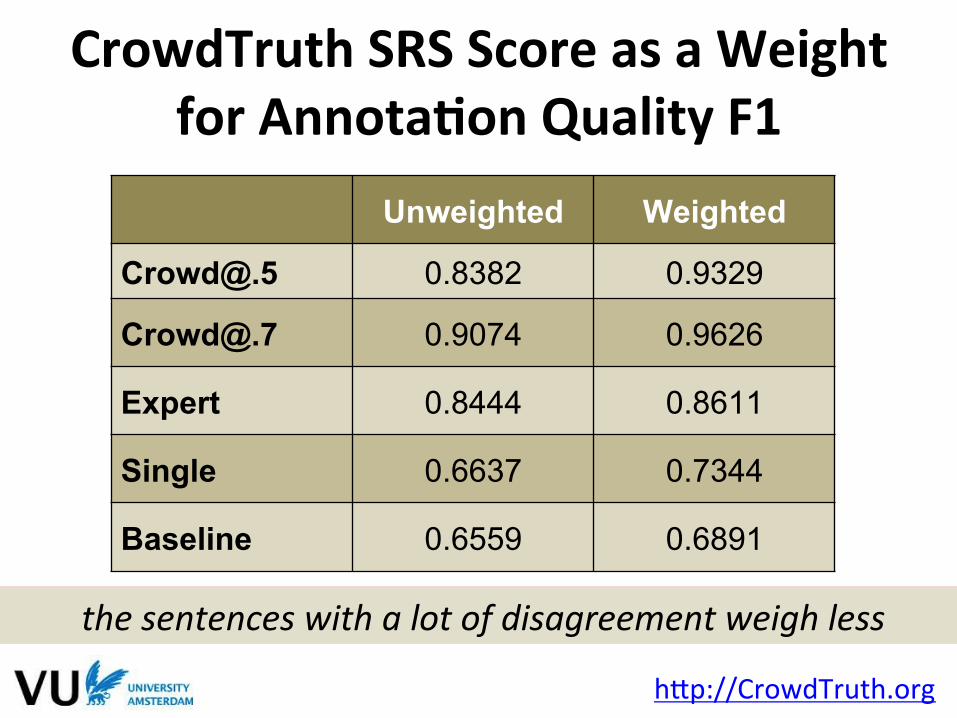
CrowdTruth SRS Score as a Weight for AnnotaFon Quality F1
Unweighted Weighted
[email protected] 0.8382 0.9329
[email protected] 0.9074 0.9626
Expert 0.8444 0.8611
Single 0.6637 0.7344
Baseline 0.6559 0.6891
the sentences with a lot of disagreement weigh less
hMp://CrowdTruth.org
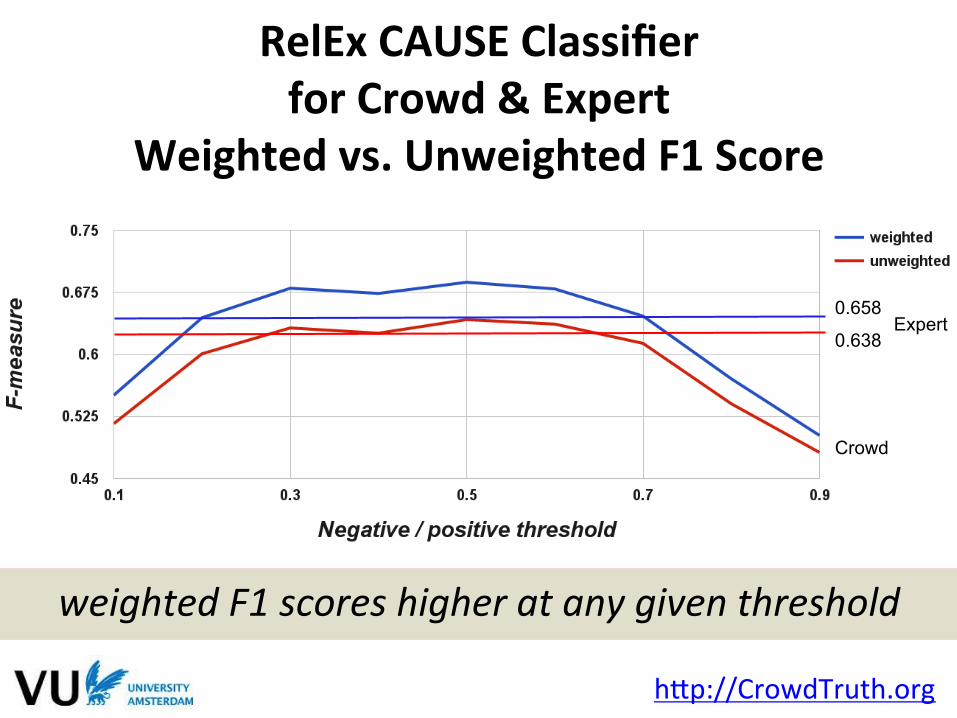
hMp://CrowdTruth.org
weighted F1 scores higher at any given threshold
RelEx CAUSE Classifier for Crowd & Expert
Weighted vs. Unweighted F1 Score
0.658
0.638
Crowd
Expert
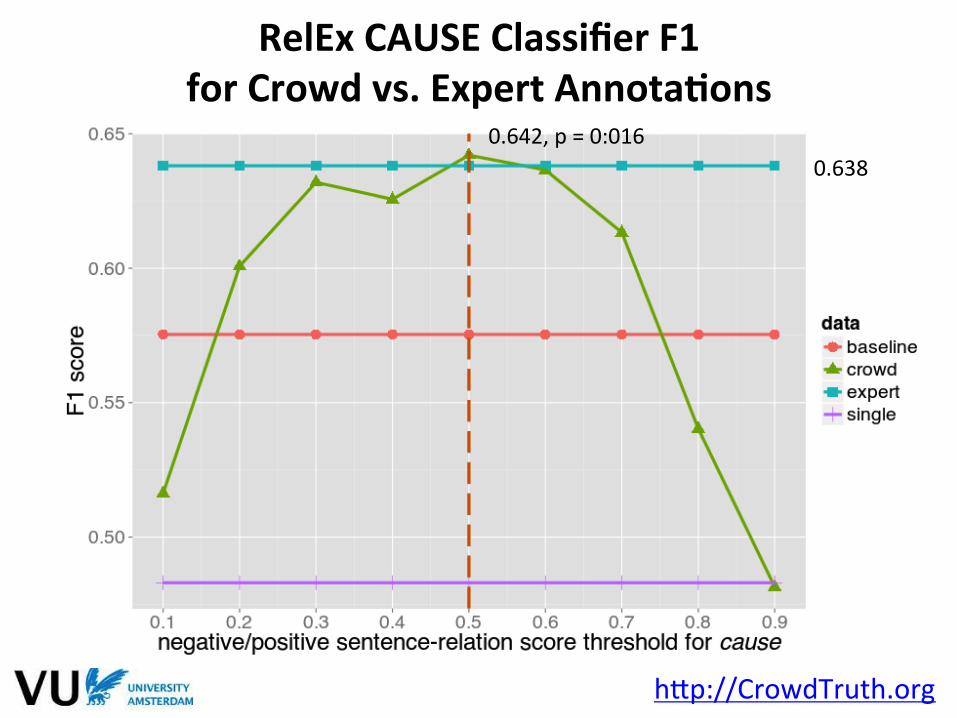
0.642, p = 0:016 0.638
RelEx CAUSE Classifier F1 for Crowd vs. Expert AnnotaFons
hMp://CrowdTruth.org
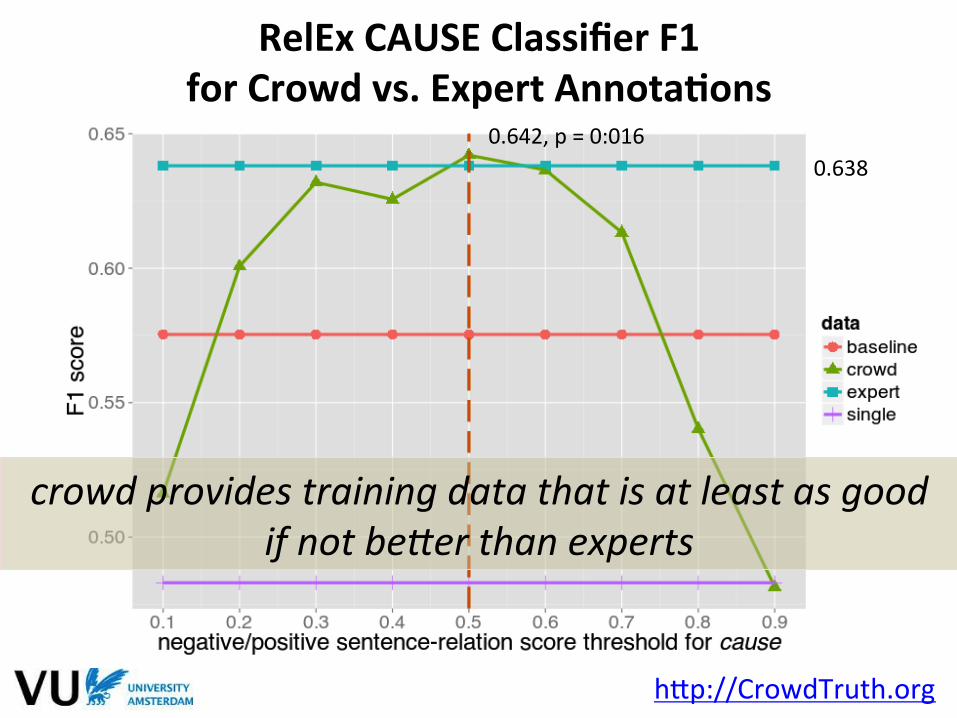
0.642, p = 0:016 0.638
crowd provides training data that is at least as good if not bePer than experts
RelEx CAUSE Classifier F1 for Crowd vs. Expert AnnotaFons
hMp://CrowdTruth.org

Measured per worker
0 1 1 0 0 4 3 0 0 5 1 0
Worker’s sentence vector
Sentence Vector
AVG (Cosine)
Worker-‐Sentence Disagreement
hMp://CrowdTruth.org

• crowd can build a ground truth • performs just as well as medical
experts • crowd is also cheaper • crowd is always available
• crowd can be used as a weight • improved F1 scores for crowd
and expert ground truths
• CrowdTruth = a solution to Clinical NLP Challenge:
• lack of ground truth for training & benchmarking
Experimentsshowed:
http://CrowdTruth.org

CrowdTruth.org
http://data.CrowdTruth.org/medical-relex #CrowdTruth @anouk_anca @laroyo @cawelty #LD4IE2015 #ISWC2015





























![SANAPHOR: Ontology-Based Coreference Resolutioniswc2015.semanticweb.org/sites/iswc2015.semanticweb.org/files/93660417.pdf · 2.4 Coreference and Anaphora According to Ng [25], practically](https://img.pdfslide.us/doc/110x75/5e1ce397f236156b493987c4/sanaphor-ontology-based-coreference-24-coreference-and-anaphora-according-to-ng.jpg)