Embed Size (px)
Citation preview

Causative Adversarial Learning
Huang Xiao, am 24.06.2015xiaohu(at)in.tum.de
Talk presented on Deep Learning in Action @Munich

Motivation
Deep networks can be easily fooled … [1]
Evolution Algor. generated images
99.99% confidence
“It turns out some DNNs only focus on discriminative features in images.”
[1] Nguyen A, Yosinski J, Clune J. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images. In Computer Vision and Pattern Recognition (CVPR '15), IEEE, 2015.

Motivation
Spam alerts

Google brain, 16000 CPUs
Learning is expensive!
Motivation

Adversarial Learning
Reverse engineering of machine learning. It aims to design robust and secure learning
algorithms.
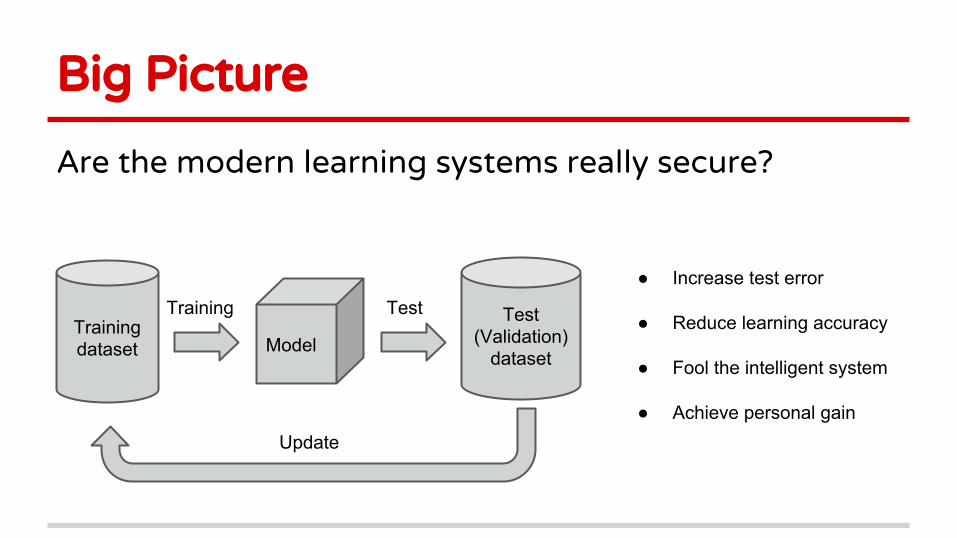
Big Picture
Are the modern learning systems really secure?
Training dataset Model
Test (Validation)
dataset
Training Test
Update
● Increase test error
● Reduce learning accuracy
● Fool the intelligent system
● Achieve personal gain

Big Picture
Are the modern learning systems really secure?
Training dataset Model
Test (Validation)
dataset
Training Test
Update
Causative Attack
Exploratory Attack

Attack’s capability
Access to Data Knowledge about features
Knowledge about the classifier
Limited Knowledge Partially Maybe Yes
Perfect Knowledge Yes Yes Yes
These are real inputs from users.

Basics
❏ Observations❏ True signal:❏ Polynomial curve fitting ❏ is unknown❏ => learn the green curve
Observation
Original signal

Least square
TrainingMinimize empirical squared error.
Estimated output
Observed output
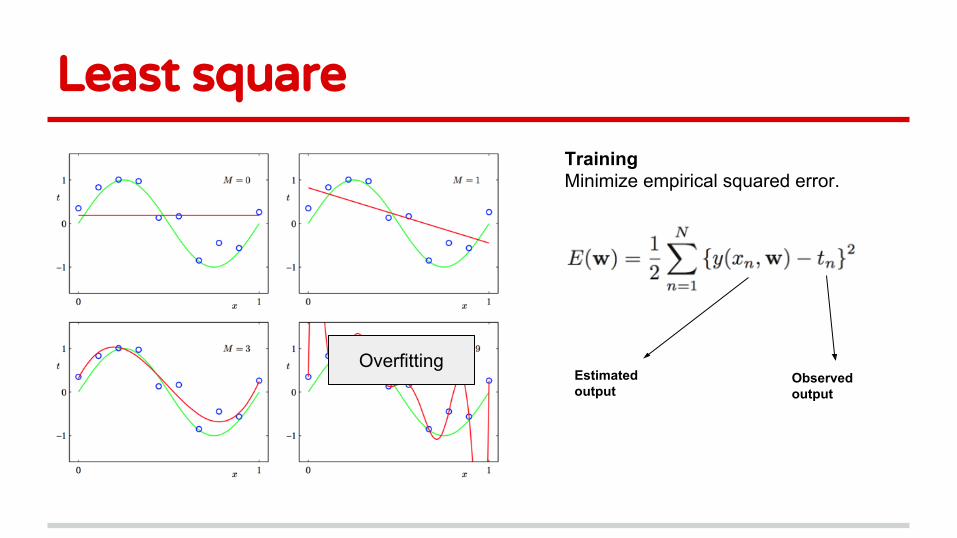
Least square
TrainingMinimize empirical squared error.
OverfittingEstimated output
Observed output

Overfitting
❏ Bad on unseen test set❏ Central problem of ML.❏ Generalization❏ E.g., regularization, prior,
more data, model selection

Bias-Variance
❏ Trade off❏ Overfitting == low bias, high variance❏ Underfitting == high bias, low variance❏ Noise is dominating!
W is very sensitive
Bias Variance Decomposition

Objective
Increase bias or variance?

Types of Adversaries
● Causative Attack (Poisoning)○ Understanding how the learning algorithms work○ Engineering on features or labels of training set○ Change the discriminant function
● Exploratory Attack (Evasion)○ Engineering features of a test point○ Circumvent the legitimate detection○ Change the discriminant result

Types of Adversaries
● Causative Attack (Poisoning)○ Understanding how the learning algorithms work○ Engineering on features or labels of training set○ Change the discriminant function
● Exploratory Attack (Evasion)○ Engineering features of a test point○ Circumvent the legitimate detection○ Change the discriminant result

Label Noises on SVM
● SVM: One of the state-of-art classifier● Binary case: +1, -1● Label flips attack under a certain budget● Maximizing error on validation set● Methods:
○ ALFA○ Distance based: far-first, near-first, random○ Continuous relaxation gradient ascend○ Correlated cluster

BasicsWe measure the error on a validation set using the function trained on training set.
A training data set
A validation data set
Classifier trained on
Regularization coefficient
Risk measurement on validation set

Flip Labels

Flip Labels

Huang Xiao, B. Biggio, B. Nelson, Han Xiao, C. Eckert, and F. Roli, “Support Vector Machines under Adversarial Label Contamination”, Neurocomputing, vol. Special Issue on Advances in Learning with Label Noise, In Press.

Poisoning Attack on SVM
● Noises on features, not on labels● Design a malicious training point● Maximizing the error (e.g., test error,
hinge loss, ...)● Gradient ascend

How to?
Retrain the SVM after injecting a malicious point ,, , move the point such that the classification error on validation set is maximized.
Validation data set with m samples
SVM trained on training set with a malicious point

Poisoning Attack on SVM

Poisoning Attack on SVM

B. Biggio, B. Nelson, and P. Laskov, “Poisoning attacks against support vector machines”, in 29th Int'l Conf. on Machine Learning (ICML), 2012.

Walking example
B. Biggio, B. Nelson, and P. Laskov, “Poisoning attacks against support vector machines”, in 29th Int'l Conf. on Machine Learning (ICML), 2012
You can:● Mimic the ‘9’ as ‘8’ or,● Label a ‘9’ as a ‘8’

Poisoning Lasso
● Lasso: feature selection, more generally, L1 regularization
● Feature selection is often the first step for many learning system
● Other targets: Rigid regression, elastic network
● Gradient based method
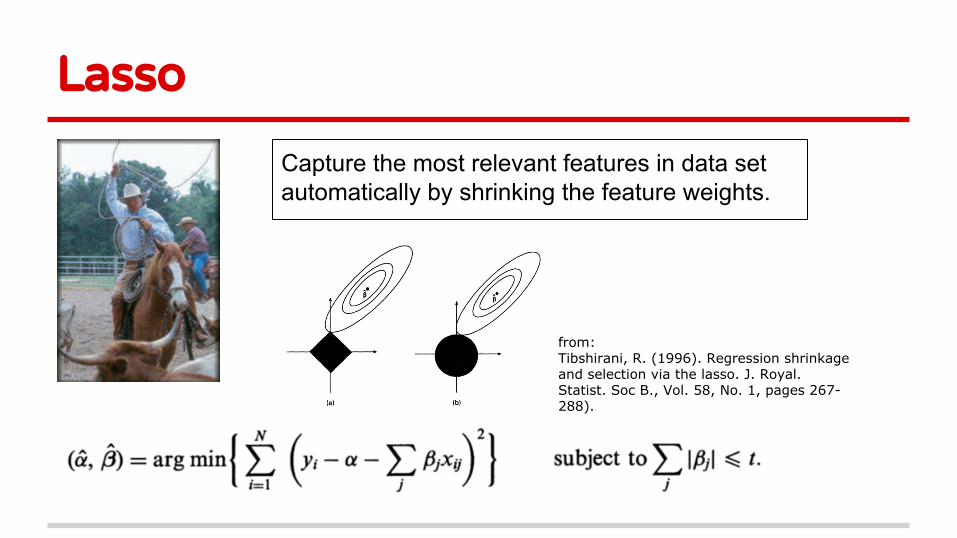
Lasso
Capture the most relevant features in data set automatically by shrinking the feature weights.
from:Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. J. Royal. Statist. Soc B., Vol. 58, No. 1, pages 267-288).

Feature selection
x1
x2
x3
x4
x5
x6
x7
x8
x9
x10
5.1 4.6 4.5 4.0 4.0 1.8 0 0 0 0
Non-zero (weight) features are selected for next stage training!

Feature selection
x1
x2
x3
x4
x5
x6
x7
x8
x9
x10
5.13.64.23.14.21.80000
Non-zero (weight) features are selected for next stage training!
Adding a malicious point
Training set

Intuition
# features
# S
amp
les
# features
# S
amp
les
#samples ≪ #features #samples ≫ #features

Intuition
# features
# S
amp
les
# features
# S
amp
les
#samples ≪ #features #samples ≫ #features
Danger!

Add some random noises

Research goals
● Investigating robustness of feature selection algorithms
● Design a multiple point attack method ● Warning: feature selection might not be
reliable● A gradient based poisoning framework

Objective function
We inject a malicious point to form a new compromised Data .
Variable: , we are maximising w.r.t
Remark that is learnt on contaminated data .
Maximise Generalization Error!

Gradient Ascent
Update rule:
descent
ascent
min
max
bound box

Demonstration
Error surface
Initial attack point
on each (x, y)
Xiao, Huang, Battista Biggio, Gavin Brown, Giorgio Fumera, Claudia Eckert, and Fabio Roli. Is Feature Selection Secure against Training Data Poisoning?. In ICML'15,Lille, France, July 2015.
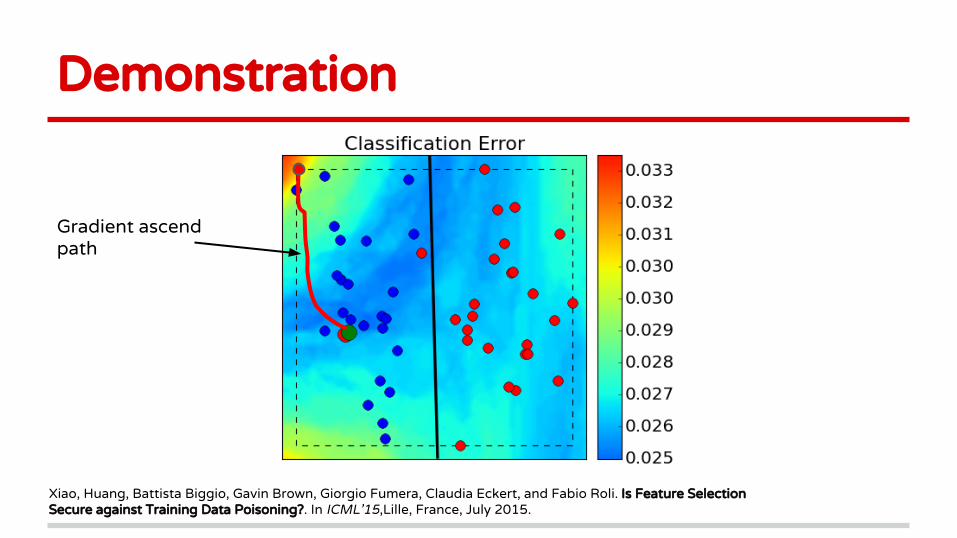
Demonstration
Gradient ascend path
Xiao, Huang, Battista Biggio, Gavin Brown, Giorgio Fumera, Claudia Eckert, and Fabio Roli. Is Feature Selection Secure against Training Data Poisoning?. In ICML'15,Lille, France, July 2015.

Wrap up
● Don’t expect your algorithms too fancy● Don’t expect adversaries too silly ● Setup objective and do the worst-case
study● Machine learning needs to be more
robust● There’s no innocent data

Thank you, question?










![9$( $'9 Variational Adversarial Active Learningstrategies can both be used for active learning in semantic segmentation [43, 3]. Adversarial learning: Adversarial learning has been](https://img.pdfslide.us/doc/110x75/5fc7ff57cade14589338905f/9-9-variational-adversarial-active-learning-strategies-can-both-be-used-for.jpg)


















