Embed Size (px)
Citation preview

Y! Research Barcelona Y! Labs Haifa
Roi Blanco Edward BortnikovFlavio Junqueira Ronny LempelLuca Telloli *Hugo Zaragoza
Caching Search Engine Results over Incremental Indices
•* currently at Barcelona Supercomputing Center

- 2 -
Overview
Caching (Background & Prior Art)
Cache Invalidation Predictors
Experimental Setup
Results
Conclusions and Future Work

- 3 -
CIP ArchitectureHigh Level Architecture of Search Engines
Parser/Tokenizer
Index
terms
CacheQueryEngine
queries
Indexing pipeline
Runtime system
results
WWW WWW

- 4 -
Caching of Web Search Results is crucial:
• Query stream is extremely REDUNDANT and BURSTY– Zipfian distribution of query popularity (redundant)
– Extreme trending of topics (bursty)
• CACHE {q} Search_Results(q)
• Caching benefits :– Shorten the engine’s response time (user waiting)
– Lower the number/cost of query executions (# data centers)
• Caveat: data (pages) is constantly changing!
Web Search Results Caching

- 5 -
Caching Search Engine Results – Prior Art
• Markatos, 2001: applied classical replacement policies (LRU, SLRU) to a 1M query log from Excite; demonstrated hit rates of ~30%
• Replacement policies tailored for search engines:
– PDC: Probability Driven Cache (Lempel & Moran, 2003)
– SDC: Static/Dynamic Cache (Silvestri, Fagni, Orlando, Palmerini and Perego, 2003)
– AC: Admission-based Caching (Baeza-Yates, Junqueira, Plachouras and Witschel, 2007)
• Other observations and approaches:
– Lempel & Moran, 2004: theoretical study via competitive analysis
– Gan & Suel, 2009: optimizing query evaluation work rather than hit rates
– Cambazoglu, Junqueira, Plachouras, Banachowski, Cui, Lim, and Bridge, 2010: refreshing aged entries during times of low back-end load

- 6 -
Traditional View:
Dilemma: Freshness versus Computation
Extreme #1: do not cache at all – evaluate all queries
100% fresh results, lots of redundant evaluations
Extreme #2: never invalidate the cache
A majority of stale results – results refreshed only due to cache replacement, no redundant work
Middle ground: invalidate periodically (TTL) A time-to-live parameter is applied to each cached entry

- 7 -
Caching in the Presence of Index Changes
• Increasing importance of freshness in search:– News, Blogs, Twitter, Social, Reviews, Local…
• Moving towards “Real Time Crawling”:
– Latency measured in seconds instead of hours or days.
• Caching, by definition, returns OLD results – Traditionally as TTL 0, caching hit rate 0
• Can we have our cake and eat it too?– Can a cache operate on a very-fast changing collection?

- 8 -
Cache Invalidation Predictors
Main idea: Not ALL the documents change ALL the time.
When a document changes (or is created / deleted)remove from the cache any quires that may have returned it.
e.g: a new document on Spanish cooking arrives; no need to invalidate queries about quantum physics!
Cache Invalidator Predictors (CIP):1. Capture document insertions/updates as they enter the index
2. Using document features, predict which cached search results will be affected by the updates
3. Invalidate those cached entries (equivalent to eviction)
4. Upon document deletion, invalidate any cached entry containing that document

- 9 -
CIP Architecture
Legend
Cache Invalidation Predictor Architecture
Parser/Tokenizer
Index
terms
CacheQueryEngine
CIP
Synopsis generator
queries
Indexing pipeline
Runtime system
Data flow
API calls

- 10 -
The Invalidator: Brief Implementation Notes
• The CIP needs to quickly locate, given a synopsis (e.g. document),
which cached entries it matches
• Essentially a reversed search engine:
– The synopses are the queries
– The queries (whose results are cached) are the documents
• (!) Non-negligible cost of communication, indexing and querying.

- 11 -
Some Definitions
• At any given time, a query in the cache may be:
– Stale: cache entry no longer represents the results the engine would return for q
– or not stale.
• Stale Rate: proportion of queries for which the search engine returns stale results
• (Both computable, given enough computing time!)

- 12 -
Some Definitions (2)
At any given time a CIP may invalidate a query or not: True Positive: invalidation of stale query -
True Negative: non-invalidation of non-stale query !
False Positive: invalidation of non-stale query $
False Negative: non-invalidation of stale-query !
False Negatives are much more expensive than False Positives: User dissatisfaction vs. computational time
Frequency of query!
Error spread forward in time!
True Negatives lead to huge savings (x query volume)

- 13 -
Invalidation Policies – Upon Match
Upon match: invalidate query q whenever the synopsis of document d matches q
E.g., for conjunctive queries, q d
The Boston Celtics beat the L.A.Lakers on their home court in the 4th game of the 2010 NBA Finals
URL1 0.875URL2 0.834
…URL9 0.692URL10 0.511
URL1 0.924URL2 0.876
…URL9 0.769URL10 0.631
URL1 0.899URL2 0.867
…URL9 0.741URL10 0.651
URL1 0712URL2 0.690
…URL9 0.482URL10 0.375
Oil Spill
URL1 0.905URL2 0.704
…URL9 0.662URL10 0.583
home
URL1 0.999URL2 0.888
…URL9 0.222URL10 0.111
Boston Celtics Barack Obama World Cup L.A. Lakers
Very low stale rate e.g. for a BOW engine, stale rate=0
High FP! $$
- 14 -
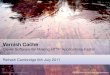
Invalidation Policies – Score Thresholding
Score Thresholding: invalidate q whenever projected score(q,d) is high enough (prerequisite: q matches d)
Requires maintaining the min score per result set, and the stand-alone ability to compute the score of a synopsis w/respect to any query
Reduces FP’s, increases FN’s President Barack Obama criticizedBP yesterday for mishandling the
oil spill in the gulf of Mexico
URL1 0.875URL2 0.834
…URL9 0.692URL10 0.511
URL1 0.924URL2 0.876
…URL9 0.769URL10 0.631
URL1 0.899URL2 0.867
…URL9 0.741URL10 0.651
URL1 0712URL2 0.690
…URL9 0.482URL10 0.375
Oil Spill
URL1 0.905URL2 0.704
…URL9 0.662URL10 0.583
home
URL1 0.999URL2 0.888
…URL9 0.222URL10 0.111
Boston Celtics Barack Obama World Cup L.A. Lakers
Score=0.503 Score=0.681

- 15 -
CIP Policies – Synopsis Generation
Full synopsis: entire document + all ranking attributes
Idea: reduce synopsis by dropping stuff “unlikely” to affect scoring
Less communication but more prediction errors In this paper: transfer some fraction of top TF-IDF terms
drop document revisions that didn’t “change much”
We the people ofthe United States,in Order to form a
more perfect Union,. . .
OrderPeoplePerfectunion

- 16 -
Experimental Setting #1
Sandbox experiment – static cache containing fixed query set, controlled document/query dynamics (no interleaving)
Data Source: en.wikipedia.org History span: 2006 – 2008
2.8 TB, > 1M pages
Dominated by updates (> 95%)
Query Source: Y! query log 2 days of queries with a click on Wikipedia (2.5 M)
Sample of 10K queries (9234 unique) chosen u.a.r.
Evaluation pattern: 120 single-day epochs (~4% change/day)
The same 10K query batch at the end of each epoch
Search library: Apache Lucene open-source library

- 17 -
CIP Parameters – Notation Summary
η Fraction of top-terms in synopsis 0 … 1
δ Revision modification threshold 0 … 1
1sScore thresholding applied? 0/1
τ Time-to-live (TTL) threshold 0 .. ∞
Basic CIP: η = 1, δ = 0, τ = ∞, 1s = 0

- 18 -
Baseline Comparison
Policy False Positives
False Negatives
Stale Rate
No invalidation
(TTL τ=∞)
0 0.108 0.768 (!)
No caching
(TTL τ=0)
0.892 0 0
TTL τ=2 0.446 0.054 0.055
TTL τ=5 0.179 0.086 0.175
Basic CIP
(Full synopses, invalidate upon match,
threshold=no, τ=∞)
0.679 0.001 0.008 (!)

- 19 -
Shrinking synopsis
Growing TTL
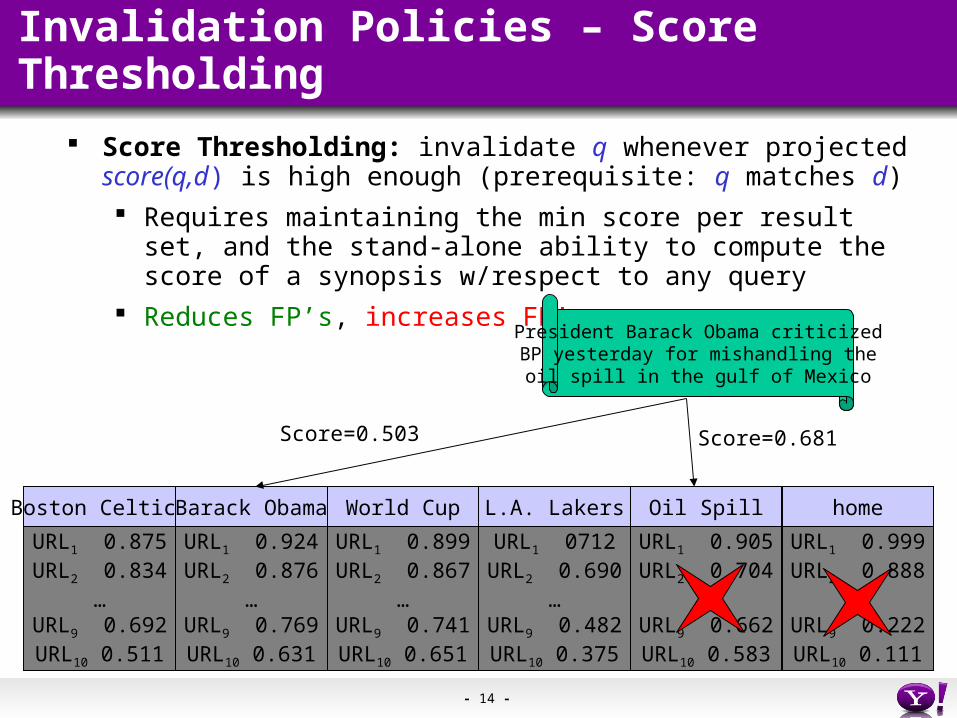
CIP Effectiveness: varying 1s, τ, and η

- 20 -
CIP Effectiveness: varying 1s and δ
Increasing revision threshold
- 21 -
Best-in-Class Picture
??

- 22 -
Conclusions
The problem of maintaining cached search results over incremental indexes is real, and under-explored
We proposed the CIP framework for real-time search cache management
We proposed an experimental setting for CIPs
Demonstrated a simple CIP that significantly improves over prior art (TTL), and measured sensitivity to various parameters

- 23 -
Future Work
• Analyze a real-world scenario (News)
– More drastic update and query dynamics
– More realistic implementation to measure cost overhead
– Compare to dynamic TTL
• Continue Improving CIPs
– Better synopsis
– Connections between corpus dynamics and query dynamics
• Study relation between real-time caching with CIPs and pre-fetching of results
- 24 -
Thank you! Questions?

- 25 -
Policy Stability: Curbing Stale Results
Still growing
stable
stableStill growing but slowly