Embed Size (px)
Citation preview

Block Sampling: Efficient Accurate Online
Aggregation in MapReduce
5th IEEE International Conference on Cloud Computing Technology and Science (CloudCom 2013)
Vasiliki Kalavri, Vaidas Brundza, Vladimir Vlassov{kalavri, vaidas, vladv}@kth.se
3 December 2013, Bristol, UK
Problem and Motivation
Luckily, in many cases results can be useful even before job completion
○ tolerate some inaccuracy○ benefit from faster answers
2
Big data processing is usually very time-consuming...
… but many applications require results really fast or can only use results for a limited window of time

MapReduce vs. MapReduce Online
mapper
reducer
Local Disk
Input Record map
function
Output Record
HTTP request
In original MR, a reducer task cannot fetch the output of a map task which hasn't committed its output to disk
mapper
reducer
Input Record map
function
Output Record
TCP- push/pull
3
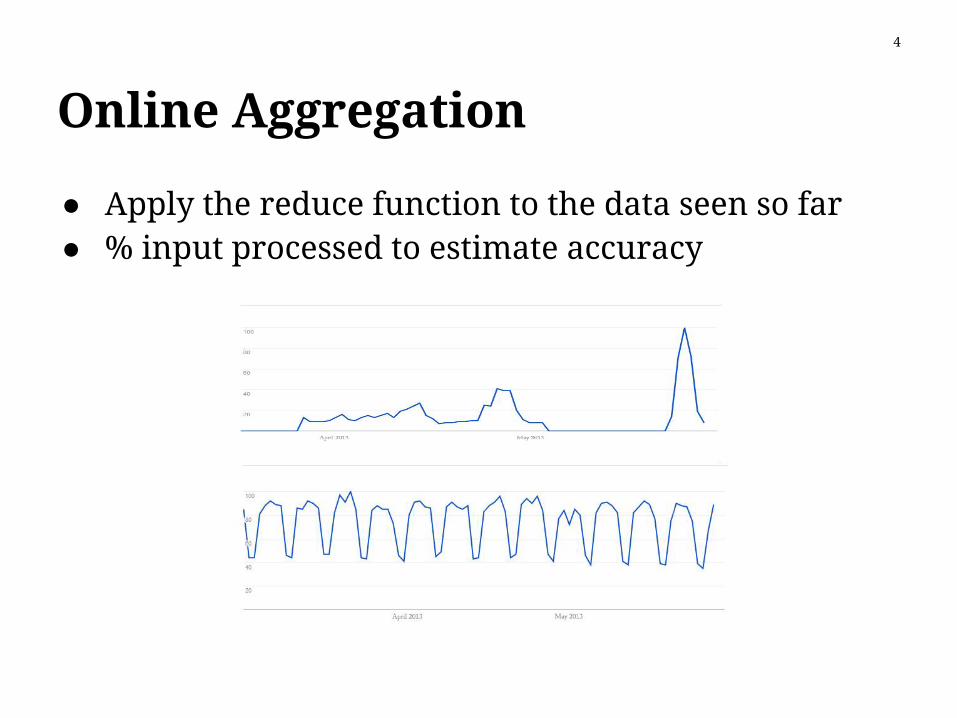
Online Aggregation
● Apply the reduce function to the data seen so far● % input processed to estimate accuracy
4

Sampling Challenges
● Data in HDFS○ Disk already access is terribly slow○ Random disk access for sampling is even slower
● Unstructured Data○ Sample based on what?
○ We don’t know the query, we don’t know the
key or the value!
5
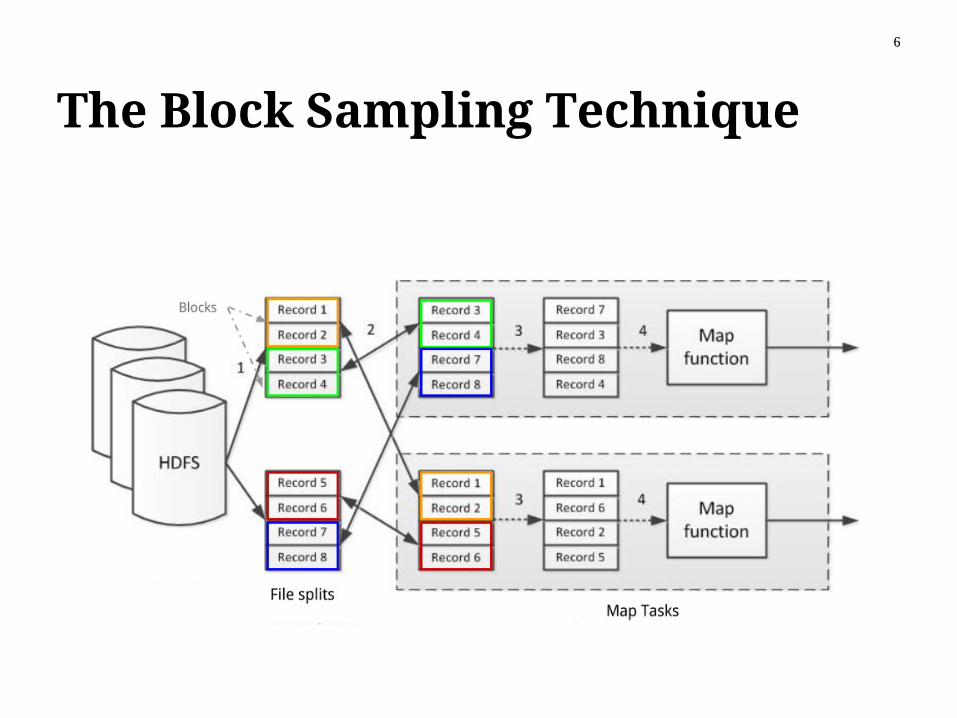
The Block Sampling Technique
6
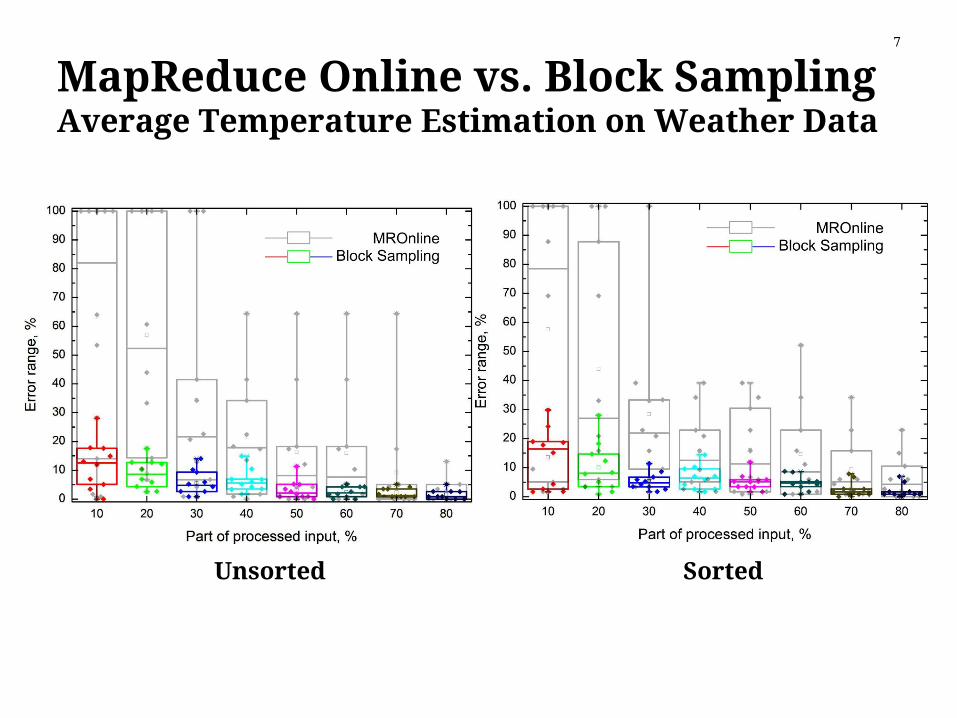
MapReduce Online vs. Block SamplingAverage Temperature Estimation on Weather Data
Unsorted Sorted
7

Takeaway
8
● Useful results even before job completion● Disk random access is prohibitively
expensive → efficiently emulate sampling using in-memory shuffling
● Higher sampling rate improves accuracy but also increases communication costs among mapper tasks

Block Sampling: Efficient Accurate Online
Aggregation in MapReduce
5th IEEE International Conference on Cloud Computing Technology and Science (CloudCom 2013)
Vasiliki Kalavri, Vaidas Brundza, Vladimir Vlassov{kalavri, vaidas, vladv}@kth.se
3 December 2013, Bristol, UK
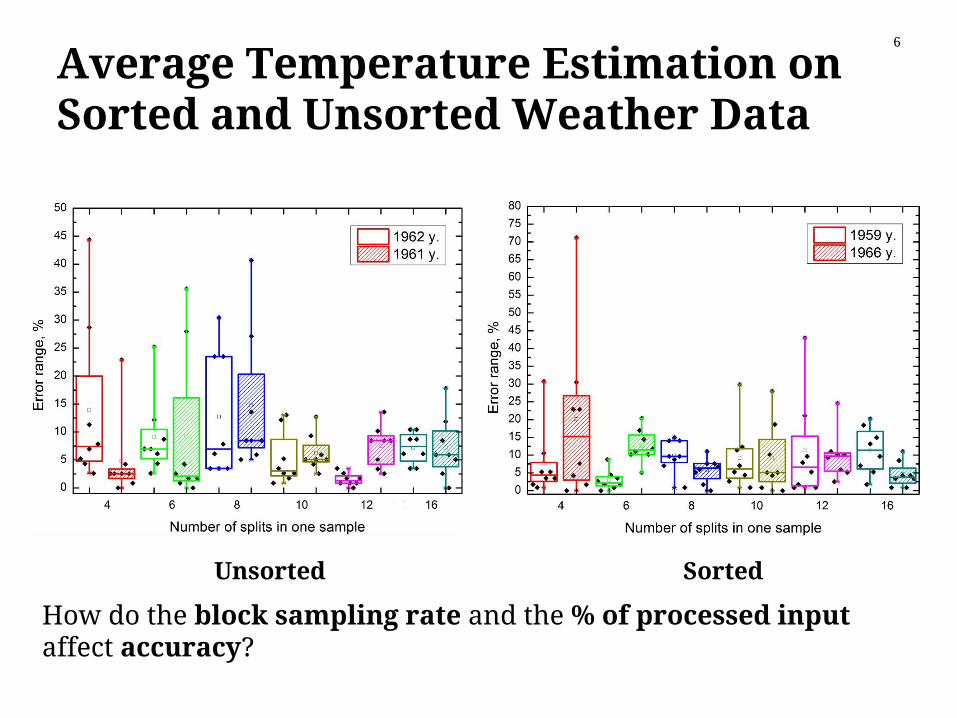
Average Temperature Estimation on Sorted and Unsorted Weather Data
Unsorted Sorted
6
How do the block sampling rate and the % of processed input affect accuracy?
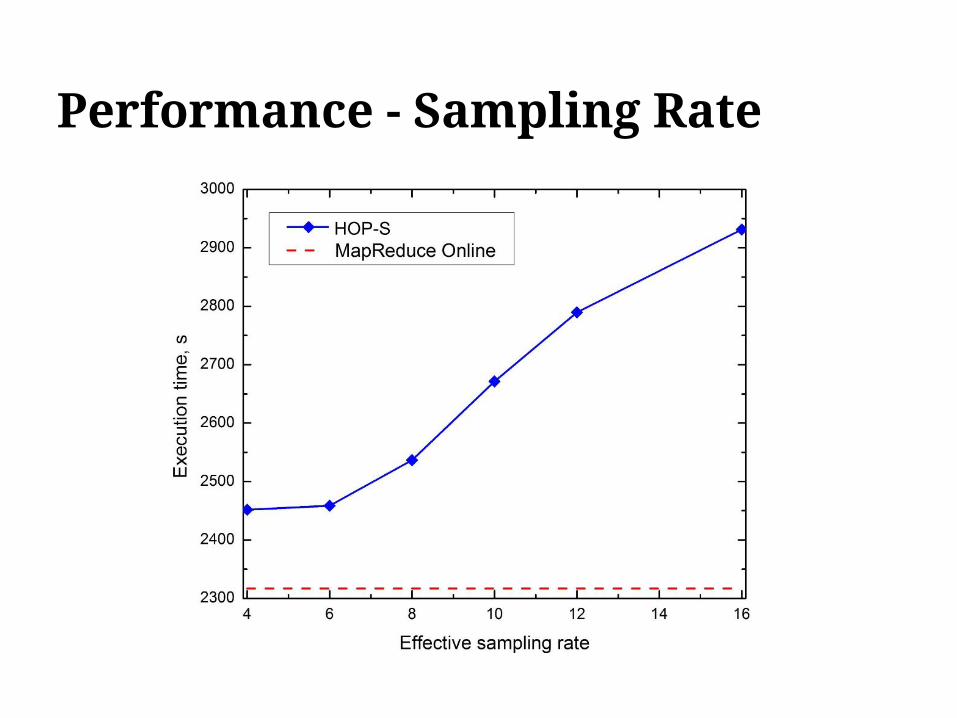
Performance - Sampling Rate
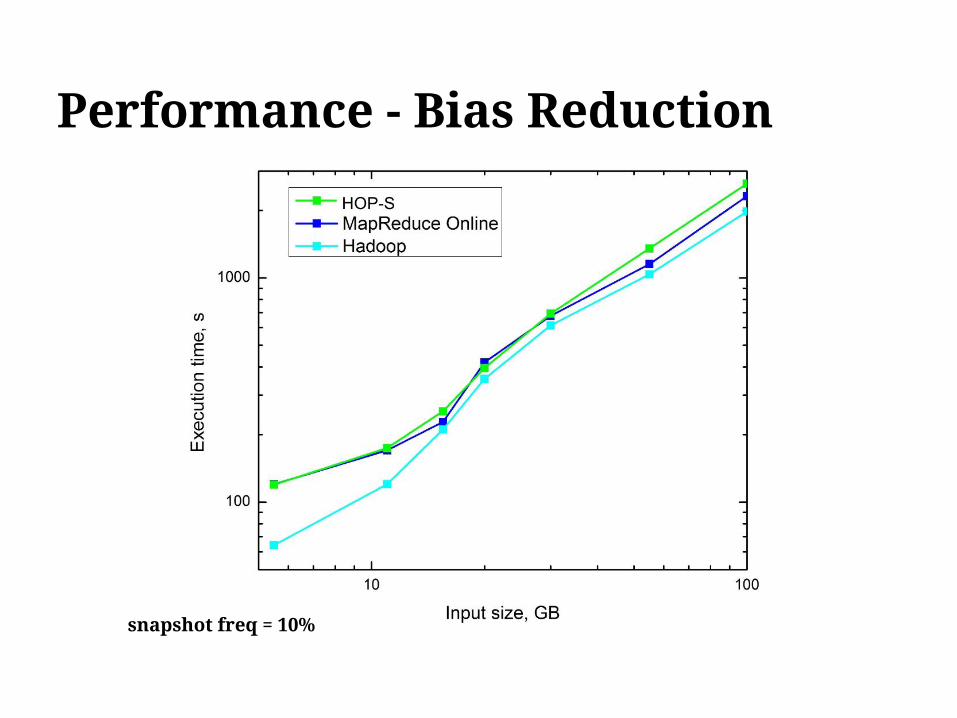
Performance - Bias Reduction
snapshot freq = 10%

Experimental Setup
● 8 large-instance OpenStack VMs○ 4 vCPUs, 8 GB memory, 90 GB disk
● Linux Ubuntu 12.04.2 LTS OSm Java 1.7.0 14● up to 17 map tasks and 5 reduce tasks per job, HDFS
block size of 64MB
● weather station data from the National Climatic Data Center ftp server (available years 1901 to 2013)
● the complete Project Gutenberg e-books catalog (30615 e-books in .txt format)

System Configuration Parameters

Bias Reduction
● Access Phase: Store the entire input split in the reader task’s local memory
● Shuffling Phase: Shuffle the records of the block in-place
● Processing Phase: Serve a record to the mapper task from local memory (avoids additional disk I/O)

Future Work
● Integrate statistical estimators○ provide error bounds for users
● Automatically fine-tune sampling parameters based on system configuration
● Explore alternative sampling techniques and wavelet-approximation
![Large-Scale Temporal Aggregation Using MapReduce · 2014. 5. 5. · Navathe et al. [15] and in later works also referred to as cumulative temporal aggregation [20] [26]. In MWTA the](https://img.pdfslide.us/doc/110x75/6126e725b97452010830ff40/large-scale-temporal-aggregation-using-mapreduce-2014-5-5-navathe-et-al-15.jpg)




























