Embed Size (px)
Citation preview

Big Data / HadoopCiclo de Seminários
MO655B – Gerência de Redes de Computadores
Alunos: Flavio Vit
Marco Aurelio Wolf
Professor: Edmundo Madeira
Dez/2014

Agenda
Big data
Hadoop
MapReduce
HDFS
Hadoop Ecosystem
Conclusion

Big Data Hot Topic
Big Buzz Word

Big Data Hot Topic
Big Buzz Word
Web 2.0
SOA
Social Networks
Cloud Computing
Big Data

Why is data getting bigger? New devices generating data
Decreasing costs with storage
Increasing processors speed
Use of hardware commodity
Open Source code usage

Data Sources From Humans:
Blogs
Forums
Web Sites
Documents
Social Networks
From machines
Sensors
App logs
Web site tracking info
House hood appliances
Hadoop MapReduce application results
Internet of Things (Computers, cell phones, cars …)

Big Data Drivers Science (CERN 40TB / second)
Financial (Risk analysis)
Web (logs, online retail, cookies)
Social Medias (Facebook, LinkedIn, Twitter)
Mobile devices (~6 Billion cell phones / Sensory data)
Internet of Thinks (Wearables / Sensors / Home Automation)
You!!!
Big Data Examples
Click Trails Books
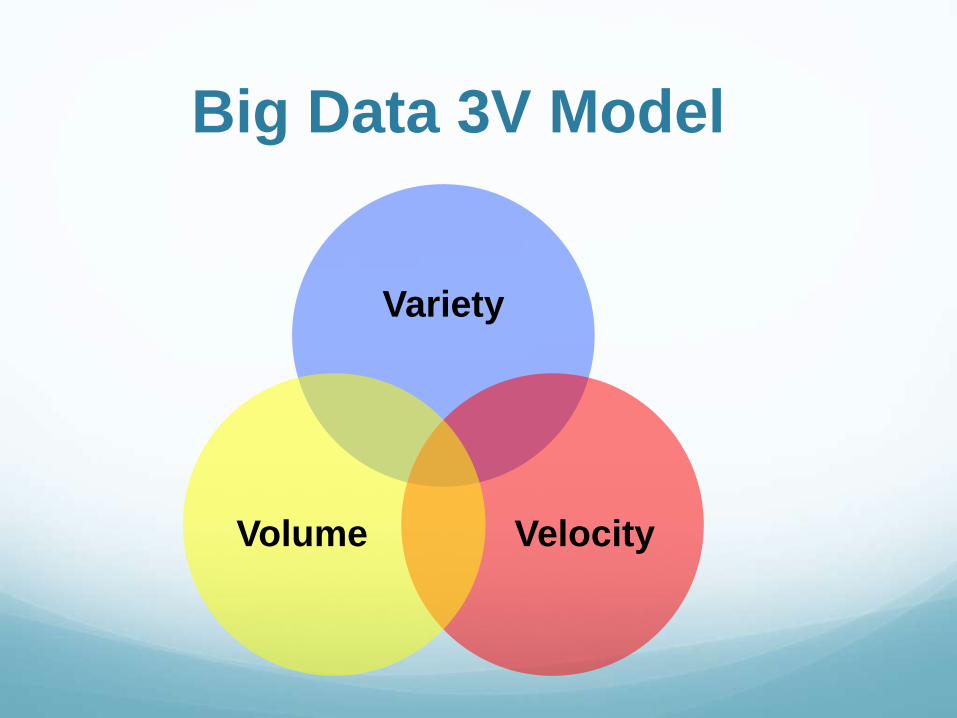
Big Data 3V Model
Variety
VelocityVolume

Velocity Data Concurrent access
Real time requirements
Illness detection
Traffic congestion for bus routes
Patient care – brain signals analyzes
Huge amount of new data is generated:
• 500 millions tweets/day
• 1 million transactions per hour – Walmart
• Every 60 seconds on Facebook:
• 510 comments are posted
• 293,000 statuses are updated
• 136,000 photos are uploaded
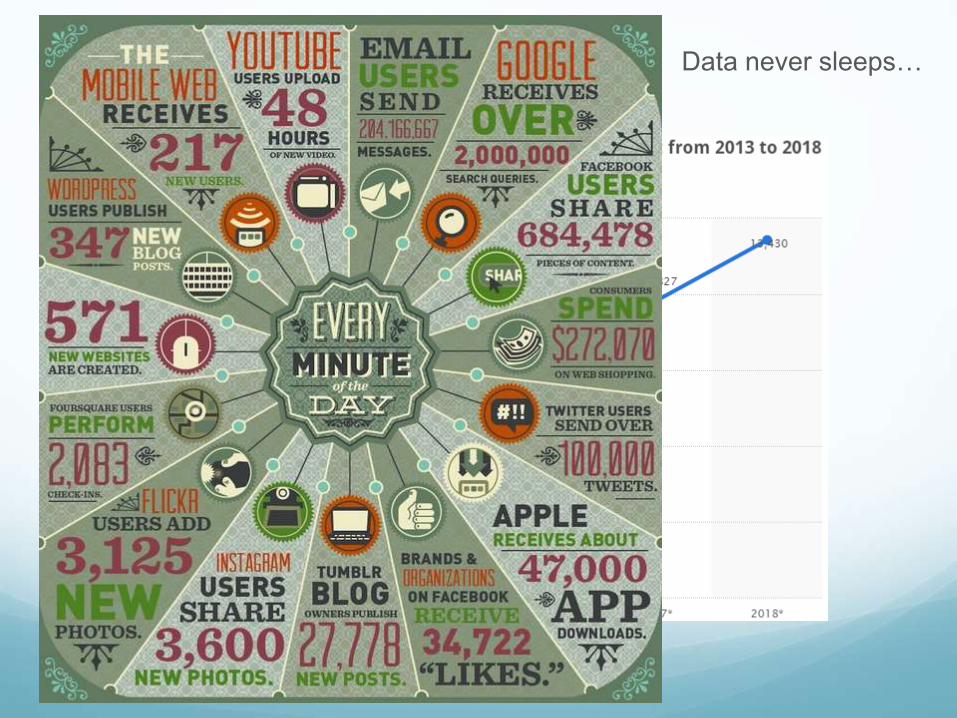
Volume
Big data implies enormous
volumes of data
Terabytes / Petabytes / …
Transactions: Walmart’s database
estimated in 2.5+ petabytes.
100 terabytes of data uploaded daily to
Data never sleeps…

Variety Structured Data
Tables and well defined schemas (RDB)
Regular structures
Semi Structured Data
Irregular structures (xml)
Schemas are not mandatory
Unstructured Data
No specific data model (free text, emails, logs)
heterogeneous data (audio, video)
All the above

Storage Scale Storage now cheep or free
More devices kicking off more data all the time
Year average cost per GB
0.00
50,000.00
100,000.00
150,000.00
200,000.00
250,000.00
300,000.00
350,000.00
400,000.00
450,000.00
500,000.00
1980 1990 2000 2005 2010 2013 2014
US$
Year
2014 $0.03
2013 $0.05
2010 $0.09
2005 $1.24
2000 $11.00
1990 $11,200
1980 $437,500
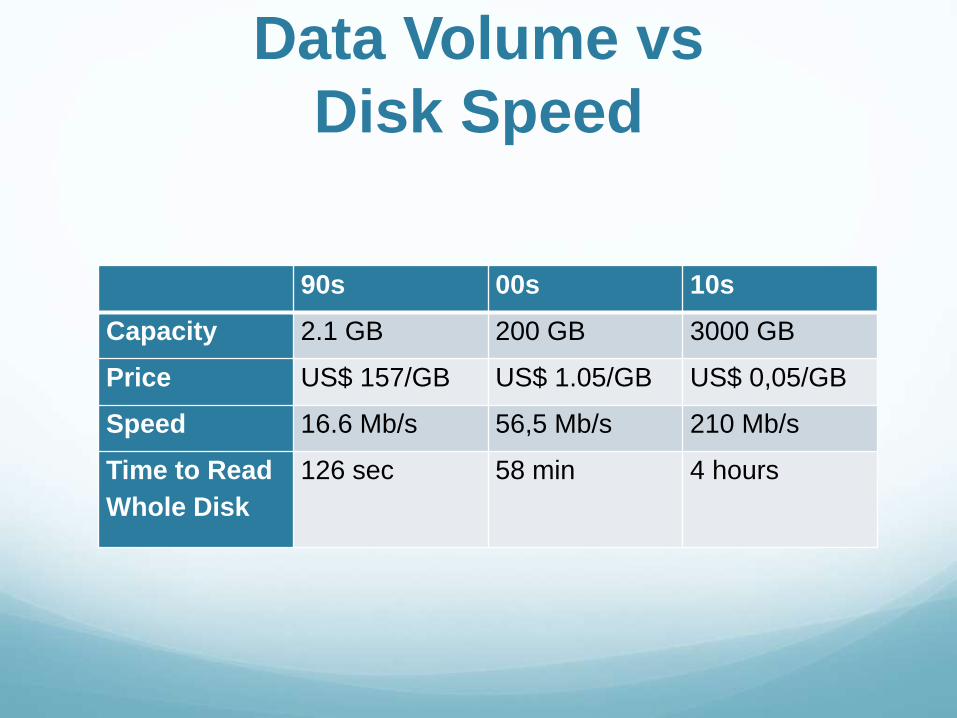
Data Volume vs
Disk Speed
90s 00s 10s
Capacity 2.1 GB 200 GB 3000 GB
Price US$ 157/GB US$ 1.05/GB US$ 0,05/GB
Speed 16.6 Mb/s 56,5 Mb/s 210 Mb/s
Time to Read
Whole Disk
126 sec 58 min 4 hours

Processing Scale Analyzing Large datasets requires distributed
processing
Multiple concurrent access to a given dataset is
required
Organizations sitting on decades of raw data
How to process huge amount of data?

How Big will it get? Nobody knows!
Systems need to:
Use horizontal linear scale
Distributed from the start
Cost effective
Easy to use


Hadoop History 2003 Doug Cutting was creating Nutch
Open Source “Google”
Web Crawler
Indexer
Crawler and Indexing processing was difficult
Massive storage and processing problem
In 2003 Google publishes GFS paper and in 2004
MapReduce paper
Based in Google’s paper, Doug redesign Nutch

What is Hadoop?
Framework of tools
Open source maintained by and under Apache
License
Support running apps for BigData
Addressing the BigData challenges:
Variety
VelocityVolume

Hadoop Main Attributes Distributed Master/Slave Architecture
Fault-tolerant
Commodity Hardware
Written in Java
Mature language
Each daemon runs in a dedicated JVM
Abstract away all infrastructure from Developer
Developers think in and codes for processing individual
records, or “Key->Value pairs”
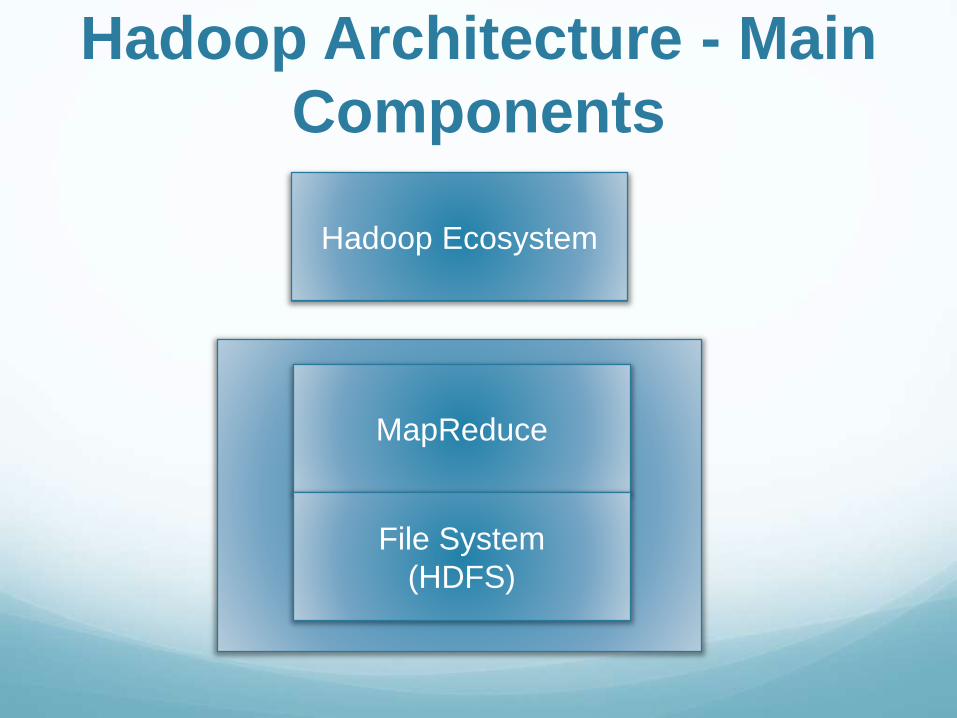
Hadoop Architecture - Main
Components
MapReduce
File System
(HDFS)
Hadoop Ecosystem

Hadoop Architecture Slaves
Task Tracker: execute small piece of main global task
Data Node: store small piece of the total data
Master, same as Slave plus:
Job Tracker: break the higher task coming from
application and send them to the appropriate task tracker.
Name Node: keep and index to track where, or on which
Data Node, is residing each piece of the total data.
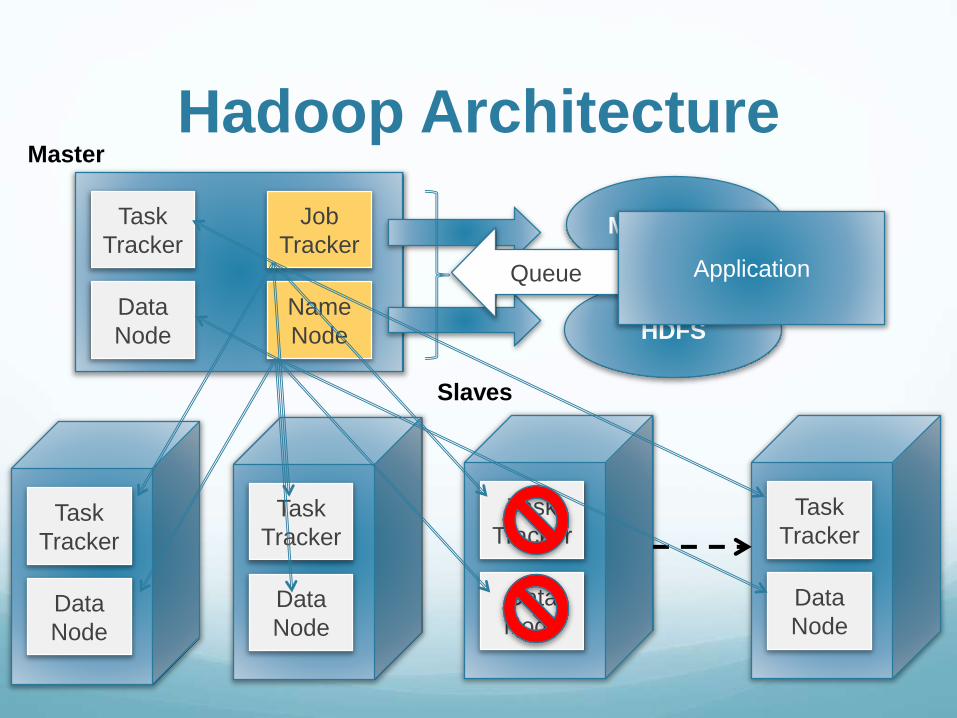
Hadoop Architecture
Task
Tracker
Data
Node
Job
Tracker
Name
Node
Task
Tracker
Data
Node
Task
Tracker
Data
Node
Task
Tracker
Data
Node
Task
Tracker
Data
Node
MapReduce
HDFS
Master
Slaves
Queue Application

Hadoop Daemons Dedicated JVMs are created Hadoop Daemons (Data
Nodes, Task Trackers, Name Nodes and Job Tracker) as well as for developer’s algorithm code.
Task tracker daemons are responsible for instantiating and populating these JVMs with the Mapping and Reducing code.
Hadoop Daemons and developer tasks are isolated from one another
Problems like “stack overflow”, “out of memory” are isolated and do not jump out of containers
Each has dedicated memory / independently tunable
Automatically “garbage collected”

Hadoop
Easier life for programmers
Programmers don’t need to worry about:
Where files are located
How to manage failures
How to break computation into pieces
How to program for scaling

Why Hadoop?
Scalable
Breaks data into smaller equal pieces (blocks, typically 64/128 Mb)
Breaks big computation task down into smaller individual tasks
More slaves, more processing and storage power
Cheap
Commodity hardware, open source software
Extremely fault tolerant
“Easy” too use

MapReduce Programming Model initially developed by Google
Large Data sets processing and generation
Parallel and distributed algorithm on Clusters
Easy to use by programmers hiding details of
parallelization
fault-tolerance
locality optimization
load balancing

MapReduce Scales to large clusters of machines (thousands of
machines)
Easy to parallelize and distribute computations
Turns computations fault-tolerant
Task are executed at same place where data is located:
Optimizations for reducing the amount of data sent
across the network

The Map Master Node orchestrate the distributed work
Data is split and sent to Worker nodes
Workers apply the map() function over the data
Output is written to intermediate storage
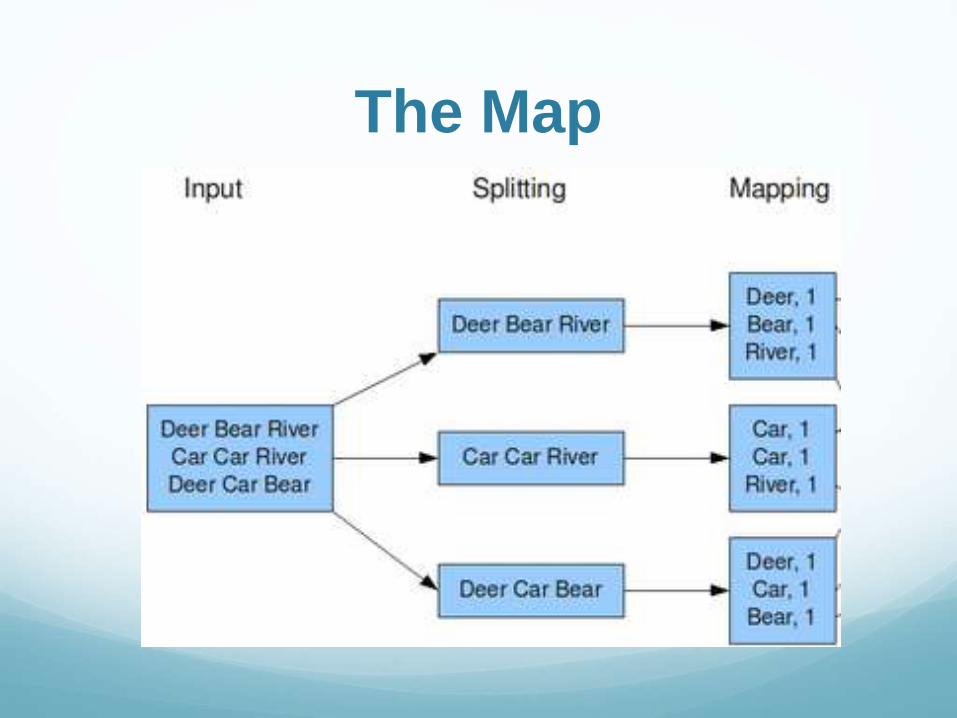
The Map
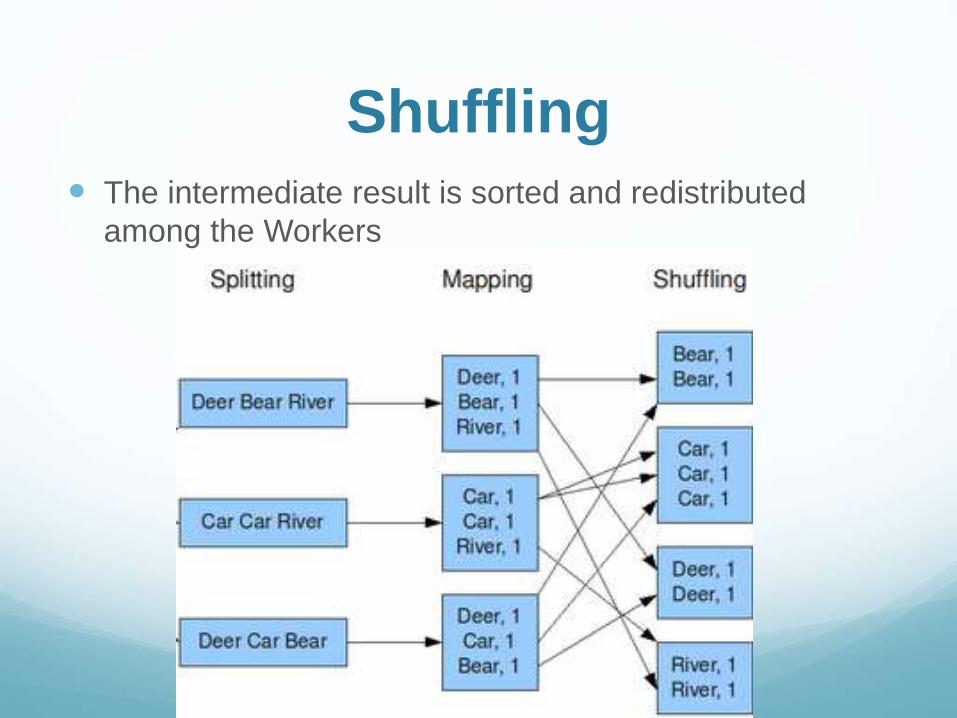
Shuffling The intermediate result is sorted and redistributed
among the Workers
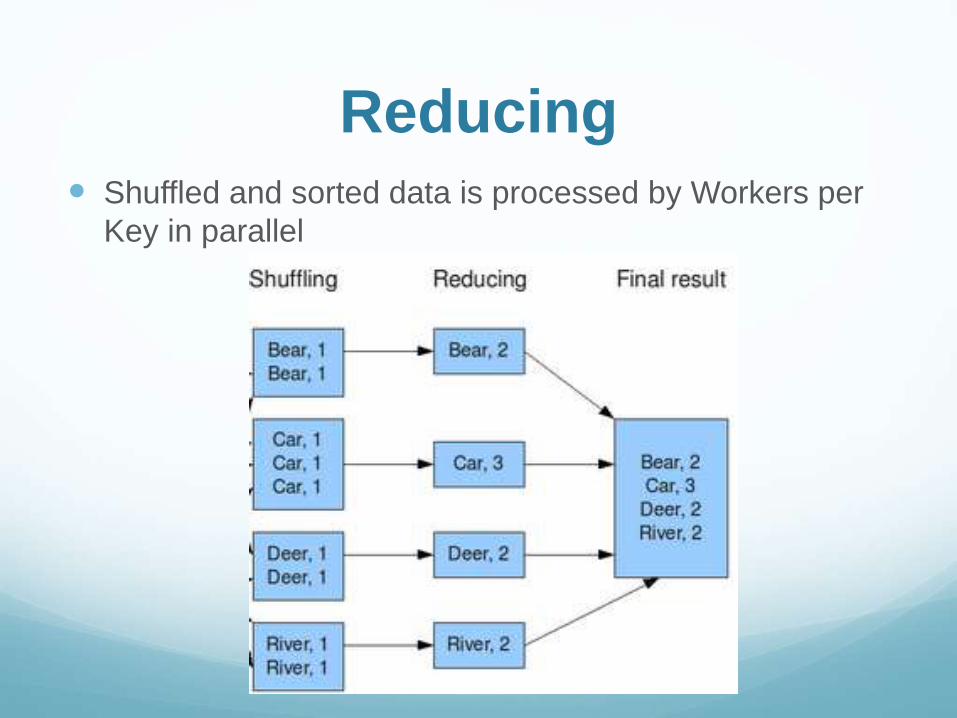
Reducing Shuffled and sorted data is processed by Workers per
Key in parallel

MapReduce Usage Distributed Pattern based search
Distributed sorting
Inverted index (word belonging to which documents?)
Web access log statistics (URL access frequency)
Machine learning
Data mining

Many Ways to MapReduce Raw Java Code
Hard to write well!!!
Best performance if well written
Hadoop Streaming
Uses Standard In / Out
Written in any language
25% lower performance than Java
Hive or Pig
Further Processing Abstraction (SQL and scripts data access)
10% lower performance than Java

HDFS
Hadoop Distributed File System
Distributed File System for large Data Sets
Focused on Batch processing execution
High throughput data access rather than low latency
Uses Native File System
Scalable and Fault Tolerant
Simple Coherency Model => write once, read many
Portable across heterogeneous HW/SW
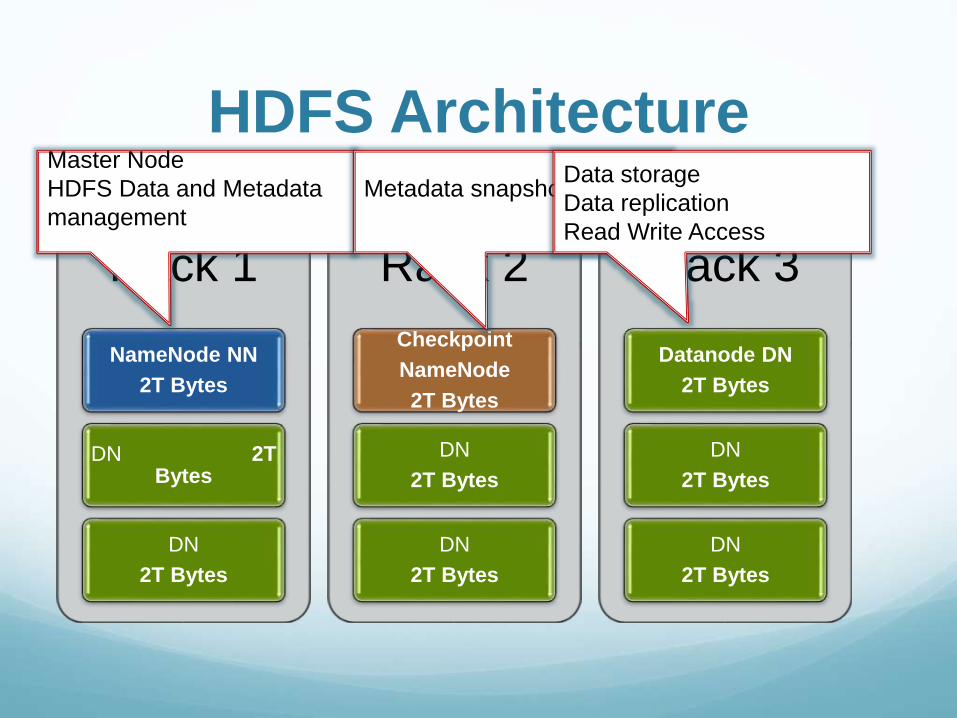
HDFS Architecture
Rack 1
NameNode NN
2T Bytes
DN 2T Bytes
DN
2T Bytes
Rack 2
Checkpoint
NameNode
2T Bytes
DN
2T Bytes
DN
2T Bytes
Rack 3
Datanode DN
2T Bytes
DN
2T Bytes
DN
2T Bytes
Master Node
HDFS Data and Metadata
management
Metadata snapshotsData storage
Data replication
Read Write Access

Hadoop HDFS Accessibility
Natively => FileSystem Java API // or wrapper in C
HTTP browser over a HDFS instance
FS Shell => Command line:
bin/hadoop dfs -mkdir /foodir
bin/hadoop dfs -rmr /foodir
bin/hadoop dfs -cat /foodir/myfile.txt
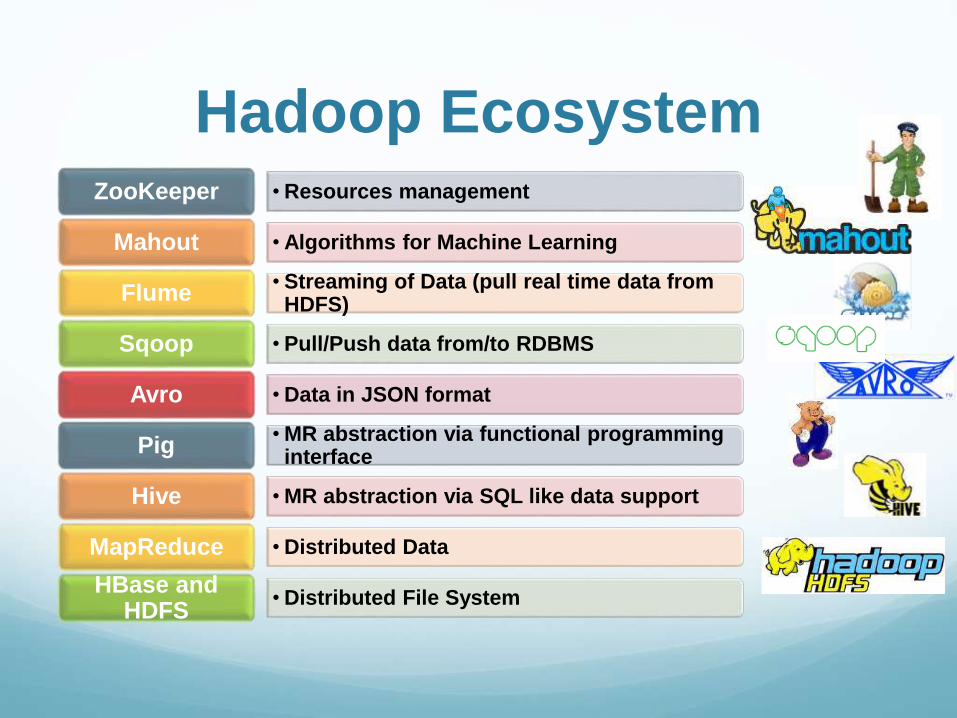
Hadoop Ecosystem• Resources managementZooKeeper
• Algorithms for Machine LearningMahout
• Streaming of Data (pull real time data from HDFS)
Flume
• Pull/Push data from/to RDBMSSqoop
• Data in JSON formatAvro
• MR abstraction via functional programming interface
Pig
• MR abstraction via SQL like data supportHive
• Distributed DataMapReduce
• Distributed File SystemHBase and
HDFS

Hadoop Usage Retail: Amazon, eBay, American Airlines
Social Networks: Facebook, Yahoo
Financial: Federal Reserve Board
Search tools: Yahoo
Government

Conclusion We live in the information era where everything is connected
and generates huge amount of data. Such data, if well analyzed, could aggregate value to society.
Hadoop addresses the Big Data challenges, proving to be an efficient framework of tools.
Hadoop is:
Scalable
Cost Effective
Flexible
Fast
Resilient to failures

Question
What is the overall flow of a
MapReduce operation proposed
by Google?
http://goo.gl/O5he92

ReferencesReferences:
http://hadoop.apache.org/
“MapReduce: Simplified Data Processing on Large Clusters” - Jeffrey Dean and Sanjay Ghemawat
http://www.statisticbrain.com/average-cost-of-hard-drive-storage/
http://zerotoprotraining.com
https://zephoria.com/





























