Embed Size (px)
Citation preview

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Scott Donaldson – Senior Director, FINRA
Vincent Saulys – Senior Director, FINRA
November 2016
BDM203
FINRABuilding a Secure Data Science Platform on AWS

2

DATA SCIENCE NEEDS
• Data discovery & exploration
• Bring disparate sources of data together
• Semantic understanding of the data sets
• Ease of use: enable users without having to understand underlying data
infrastructure
• Safeguard information with high degree of security and least privileges access
• Model migration from research to prototype to production
• Avoid time spent on environment administration
3
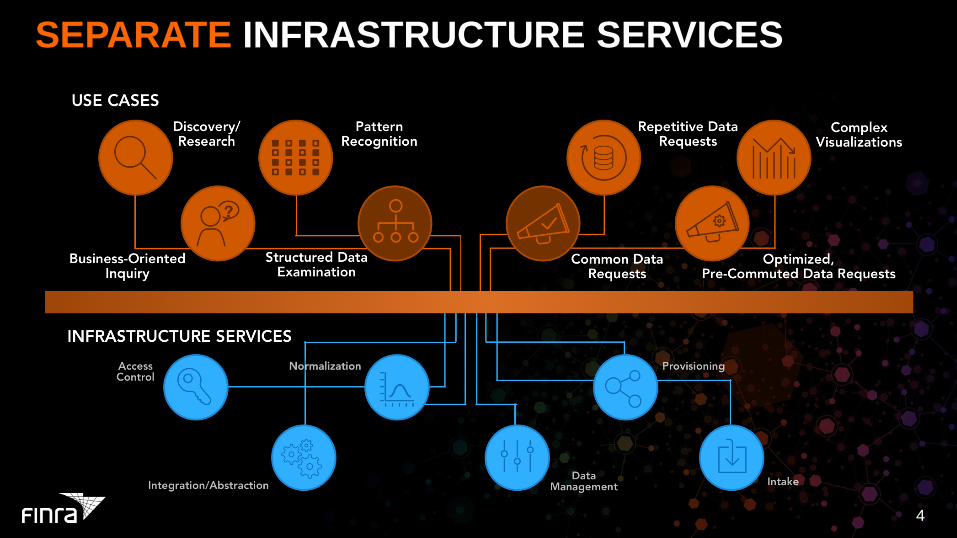
SEPARATE INFRASTRUCTURE SERVICES
4
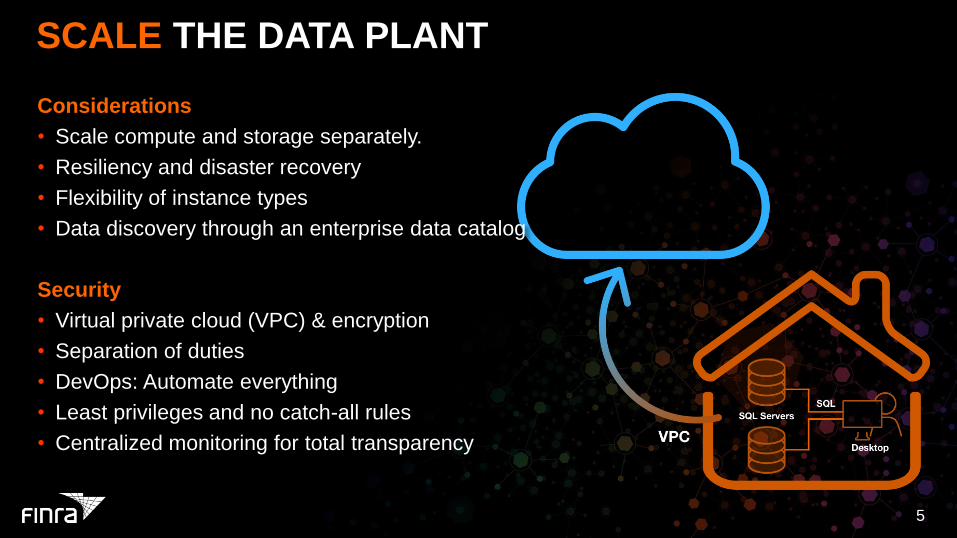
SCALE THE DATA PLANT
Considerations
• Scale compute and storage separately.
• Resiliency and disaster recovery
• Flexibility of instance types
• Data discovery through an enterprise data catalog
Security
• Virtual private cloud (VPC) & encryption
• Separation of duties
• DevOps: Automate everything
• Least privileges and no catch-all rules
• Centralized monitoring for total transparency
5
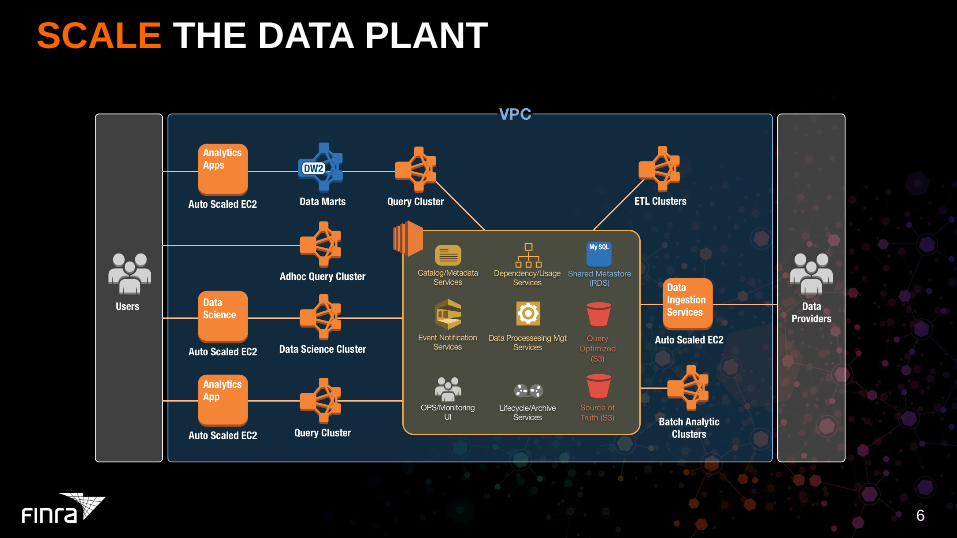
SCALE THE DATA PLANT
6
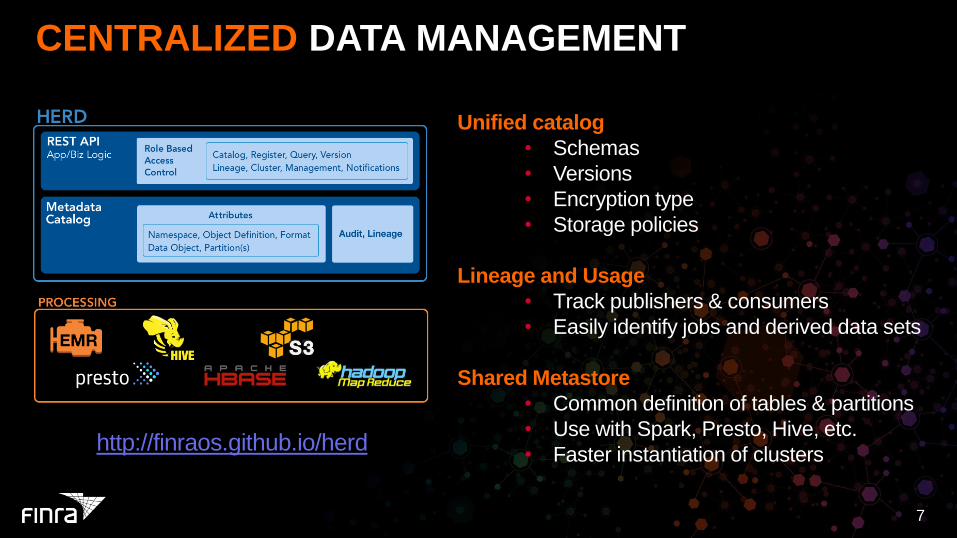
CENTRALIZED DATA MANAGEMENT
http://finraos.github.io/herd
Unified catalog
• Schemas
• Versions
• Encryption type
• Storage policies
Lineage and Usage
• Track publishers & consumers
• Easily identify jobs and derived data sets
Shared Metastore
• Common definition of tables & partitions
• Use with Spark, Presto, Hive, etc.
• Faster instantiation of clusters
7
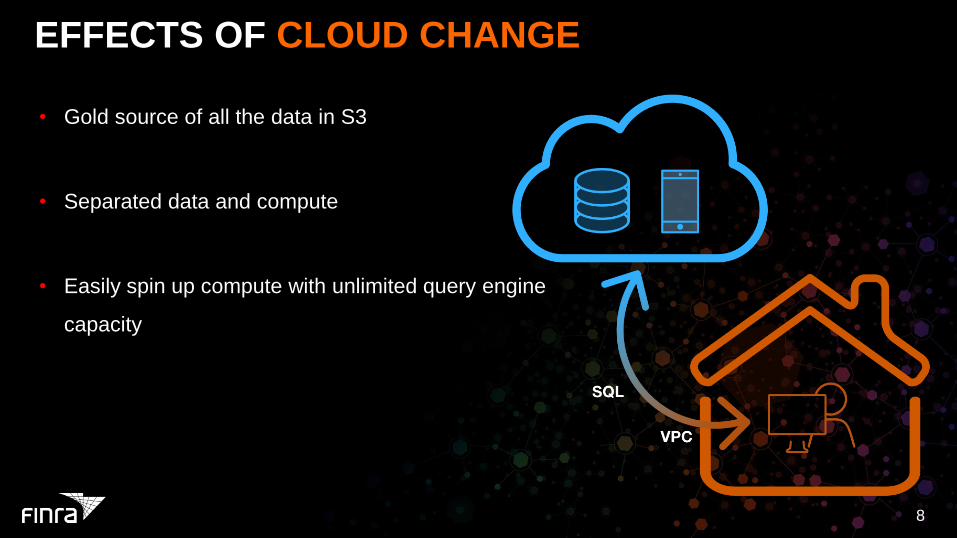
EFFECTS OF CLOUD CHANGE
• Gold source of all the data in S3
• Separated data and compute
• Easily spin up compute with unlimited query engine
capacity
8
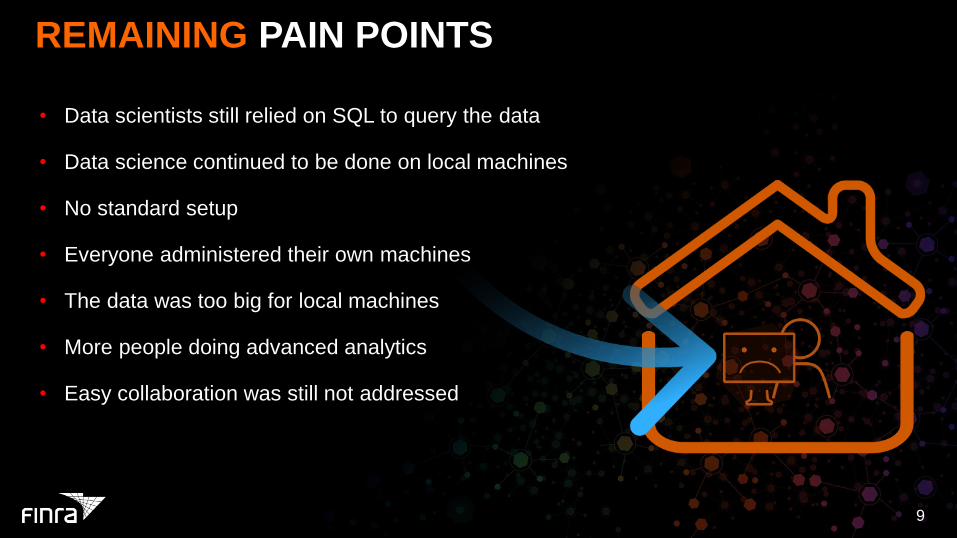
REMAINING PAIN POINTS
• Data scientists still relied on SQL to query the data
• Data science continued to be done on local machines
• No standard setup
• Everyone administered their own machines
• The data was too big for local machines
• More people doing advanced analytics
• Easy collaboration was still not addressed
9
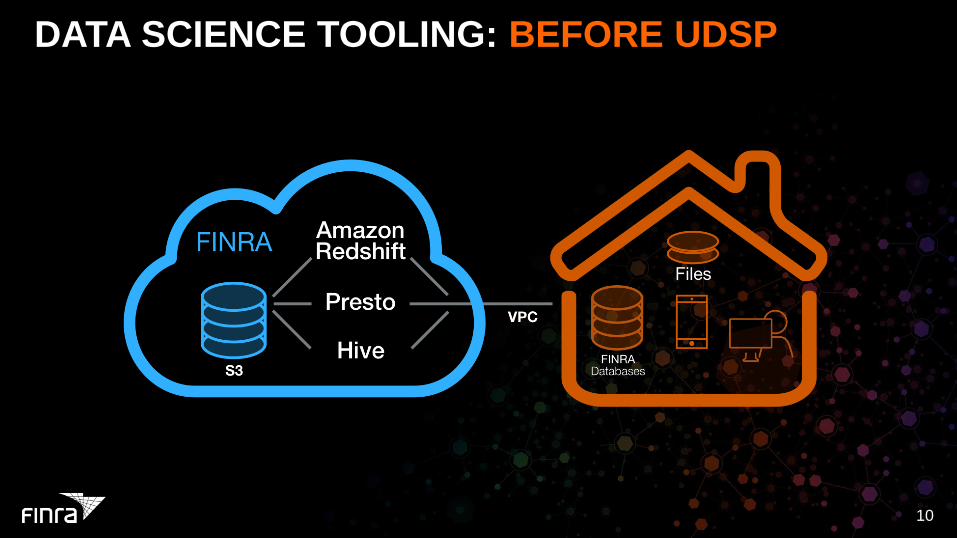
DATA SCIENCE TOOLING: BEFORE UDSP
10
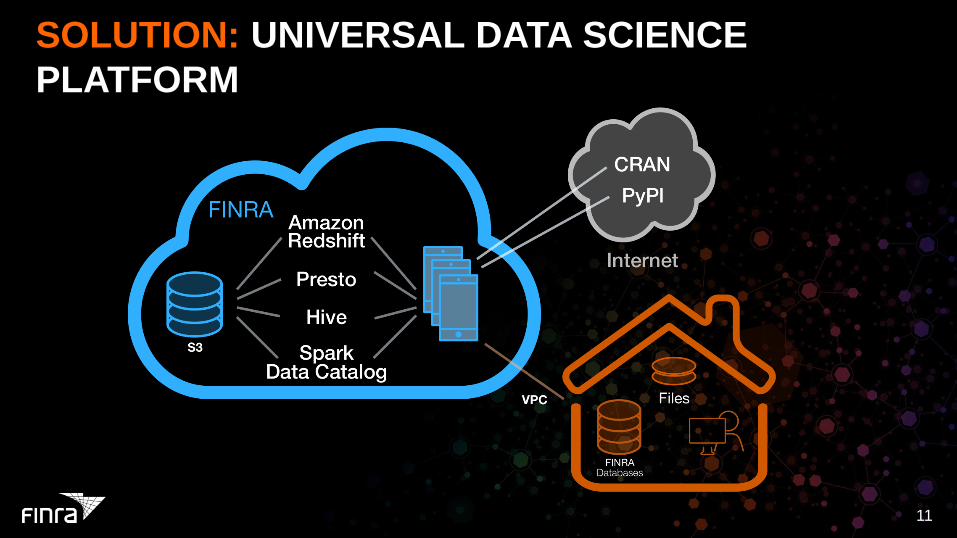
SOLUTION: UNIVERSAL DATA SCIENCE
PLATFORM
11

UDSP V1Secure
• Technology controls and curates content
Self-Service
• Users manage their machines
Scalable Compute
• Size machines to your needs
Turnkey
• Libraries pre-built and installed
12

NO USERS, WHY?
Needs driven by technology
• IT: Reduce costs
• Users: need more compute
Secure but inflexible
• Local machines where more flexible
• Install any package and experiment
Data availability
• On-premises databases not reachable
Setup still required
• Driver configuration to connect to databases
Technology in the way
• Technology required to install any new package
13

UDSP V2Flexible
• Download/Install any package
Data Availability
• No additional setup necessary
• On-premises and cloud data accessible
Ownership
• Changes proposed and vetted through
the data science forum
14

ADOPTION METRICS
15

INVENTORY
R 3.2.5, Python (2.7.12 and 3.4.3)
Packages
• R: 300+ Python: 100+
Tools for Building Packages
• gcc, gfortran, make, java, maven,
ant…
IDEs
• Jupyter, RStudio Server
Deep Learning
• CUDA, CuDNN (if GPU present)
• Theano, Caffe, Torch
• TensorFlow
16

SELF SERVICE
Completely self service, no technology administration
• Users select UDSP version and machine capacity
Users associated to groups (AWS billing tags and machine selection choices)
Users manage their instances
• Create, Stop, Terminate (delete)
Managers can administer their team’s instances
Dashboard to monitor resource usage
• Stop instances from the dashboard
Reports for historical usage
17
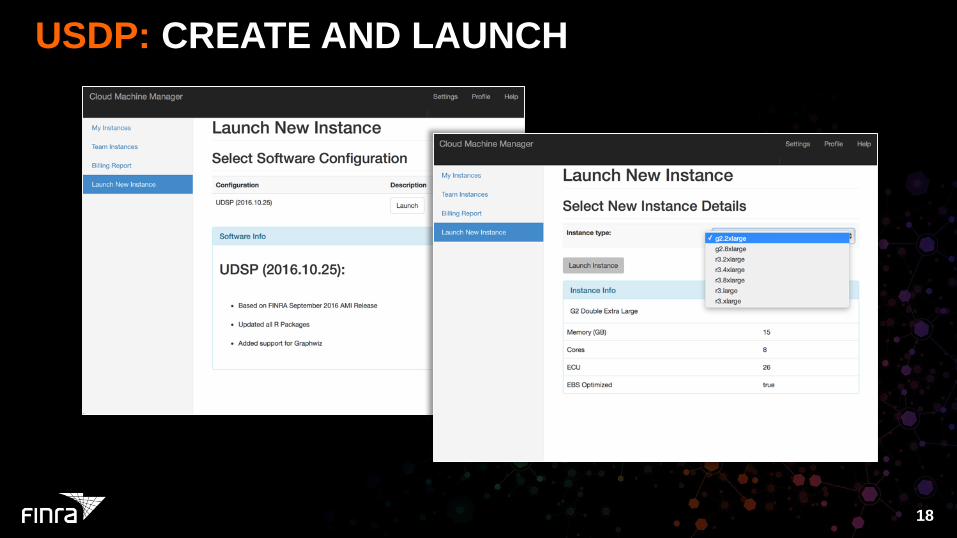
USDP: CREATE AND LAUNCH
18
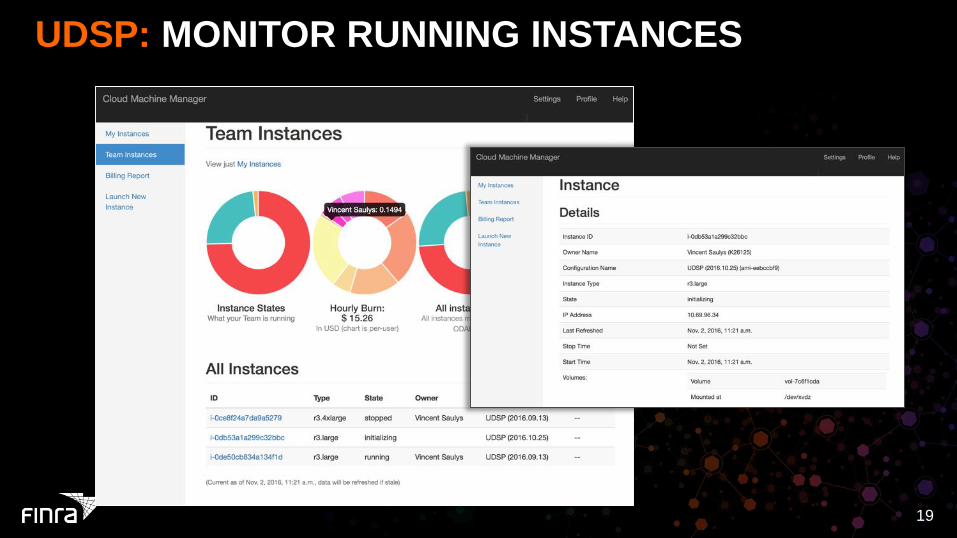
UDSP: MONITOR RUNNING INSTANCES
19
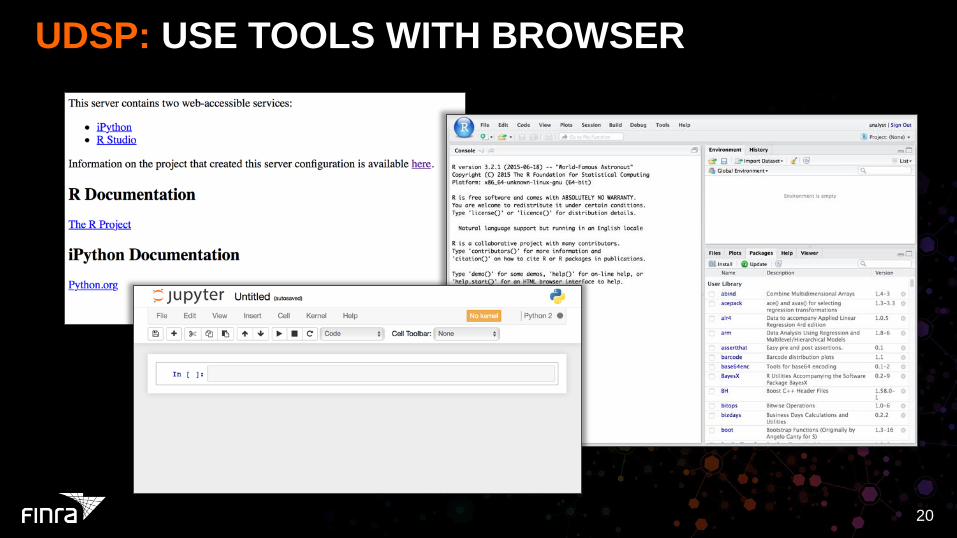
UDSP: USE TOOLS WITH BROWSER
20

MAINTAINING THE USDP
Community Driven Experimentation
• Data scientists can install any package to try it out
• No technologist necessary to administer installation
New library (or version) is proposed for next release
• Releases have been monthly
• Envision quarterly releases
Philosophy: Support last major release (most recent
patch)
• R 3.3.1 is available and still releasing patches, UDSP
has 3.2.5
21

THE ROAD AHEAD
Clusters for Advanced Analytics
Surveillance Platform
• Facilitate surveillance development on spark
• Data Framework for accessing and manipulating data
• ML Framework standardizes algorithms, diagnostics and
best practices
22

SURVEILLANCE PLATFORM
Spark as the processing platform
Cluster based data processing cluster based data science
Frameworks will speed data engineering and data science
23

RECAP
• Each improvement brought pressures to legacy ways of working
• Flexibility of platform key to adoption
• Groups do what they are best at (administer setups, do analytics)
• Technology get out of the way!
• Full visibility to administer costs
24

Other FINRA Sessions:
• BDM203 – Building a Secure Data Science Platform
• DAT302 – Best Practices for Migrating to RDS / Aurora
• ENT313 – FINRA in the Cloud, Big Data Enterprise
• CMP316 – Aligning Billions of Time Ordered Events with Spark
• STG308 – Analytics Without Limits. FINRA’s Scalable Big Data Architecture on S3
RELATED SESSIONS
25

ABOUT THE PRESENTERS
Scott Donaldson
• Senior Director, FINRA
• Data Analytics and Surveillance Systems
• https://www.linkedin.com/in/scottdonaldson
Vincent Saulys
• Senior Director, FINRA
• Advanced Surveillance Development
• www.linkedin.com/in/vincentsaulys
26

QUESTIONS?
Learn more at
http://technology.finra.org
FINRA Technology is hiring
http://technology.finra.org/careers.html
27

Thank you!





























