Embed Size (px)
Citation preview

Simone [email protected]
Who Am I
Simone Bordet [email protected] @simonebordet
Open Source Contributor Jetty, CometD, MX4J, Foxtrot, LiveTribe, JBoss, Larex
Lead Architect at Intalio/Webtide Jetty's SPDY and HTTP client maintainer
CometD project leader Web messaging framework
JVM tuning expert

Simone [email protected]
Mechanical Sympathy
Term coined by Jackie Stewart (Formula 1 driver) Jackie Stewart believed that to be a great driver one
must have a mechanical sympathy for how a car works to get the best out of it.
Term “revived” by Martin Thompson (Disruptor fame) But now applied to software (driver) and hardware (car)
Servers/libraries should be mechanically sympathetic To exploit the full power of modern CPUs

Simone [email protected]
CPU Execution
Modern CPUs are super-scalar Each core has multiple execution units Independent operations can be executed in parallel in
the same clock cycle by different execution units a = b + c d = e + f
Modern CPUs perform out-of-order-execution Semantic ordering retained via instruction retirement
a = b * c => multiplication takes few clocks d = a + 1 => depends on a, must wait e = b + 1 => can be executed before d

Simone [email protected]
CPU Execution Quiz
int[] a = new int[2];
// Loop 1
for (int i=0; i<bazillion; ++i) { a[0]++; a[0]++; }
// Loop 2
for (int i=0; i<bazillion; ++i) { a[0]++; a[1]++; }
Loop 2 could be twice as fast Provided no optimizations to first loop: a[0] += 2;

Simone [email protected]
CPU Instruction Rate
CPUs are fast 3 GHz => 3 clock cycles / ns
CPUs are parallel 4x (or more) instructions per clock cycle
Potential Instruction Rate 3 x 4 = 12 instructions / ns
Cache miss to main memory 12 x 65 = 780 instructions !
Compilers and JITs help with reordering Developers must pay attention to memory access patterns

Simone [email protected]
CPU Access Patterns
CPUs are good at guessing what is accessed next Prefetch of instructions and data into caches
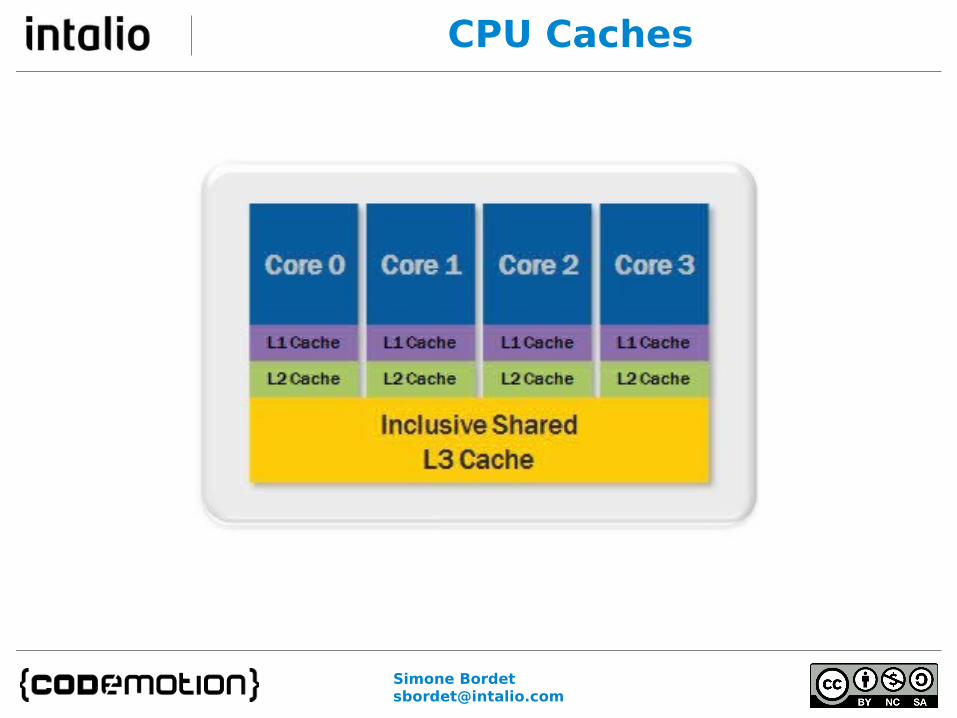
CPUs access memory in “cache lines” 64 bytes of contiguous data
Different cores can access the same cache line MESI protocol to keep the data consistent
MESI – Modified / Exclusive / Shared / Invalid

Simone [email protected]
CPU Access Pattern Quiz
int[] arr = new int[bazillion];
// Loop 1
for (int i = 0; i < arr.length; ++i) arr[i] *= 3;
// Loop 2
for (int i = 0; i < arr.length; i += 16) arr[i] *= 3;
Loop 2 does only 1/16 – 6.25% – of the work Same performance Loop is dominated by memory access, not computation

Simone [email protected]
CPU Branch Prediction
CPU branch predictor improves instruction flow Branch predictor keeps track of branch history
An if/else branch is guessed The branch is speculatively executed
Guess is right => instructions are retired
Guess is wrong => 3-6 ns penalty + re-execution

Simone [email protected]
Tools
Java Microbenchmark Harness – JMH http://openjdk.java.net/projects/code-tools/jmh/ Vastly superior to any other framework
Probably the only non-flawed solution for HotSpot
Linux Perf Tools perf list
Shows hardware events
perf stat Attaches to a running process to gather events

Simone [email protected]
HEX Conversion
Branching code
String hex = "A6";
int value = (x2i(hex.charAt(0)) << 4) | x2i(hex.charAt(1));
public int x2i(char c)
{
if (c >= 'A' && c <= 'F')
return 10 + c – 'A';
else
return c – '0';
}

Simone [email protected]
HEX Conversion
Branchless code
String hex = "A6";
int value = (x2i(hex.charAt(0)) << 4) | x2i(hex.charAt(1));
public int x2i(char c)
{
return (c & 0x1F) + ((c >> 6) * 0x19) – 0x10;
}

Simone [email protected]
HEX Conversion Benchmark
JMH benchmark runs (bigger is better) Branching: 270.686 ops/ms Branchless: 701.206 ops/ms
perf stat -e branches -e branch-misses Branching
1.27 insns/cycle 13,353,788,164 branches 11.92% branch-misses
Branchless 2.31 insns/cycle 2,553,447,200 branches 0.02% branch-misses

Simone [email protected]
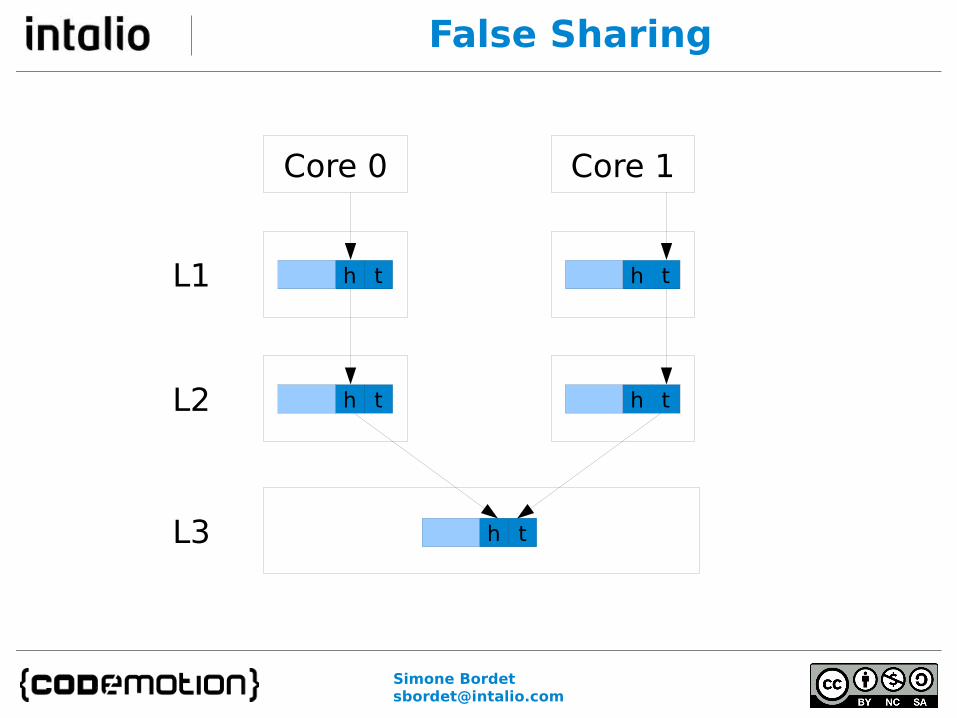
False Sharing
Jetty uses a customized queue for its thread pool
public class BlockingArrayQueue
{
private int _head;
private int _tail;
}
Memory Layout
header _head _tail
8 bytes 4 bytes 4 bytes

Simone [email protected]
False Sharing
Avoid false sharing by padding
public class BlockingArrayQueue
{
private int _head;
private int h01, h02, h03, h04, h05, h06, h07, h08;
private int h11, h12, h13, h14, h15, h16, h17, h18;
private int _tail;
private int t01, t02, t03, t04, t05, t06, t07, t08;
private int t11, t12, t13, t14, t15, t16, t17, t18;
}

Simone [email protected]
False Sharing Benchmark
JMH Benchmark runs (bigger is better) Dense: 624,644.870 ops/ms Padded: 790,501.896 ops/ms Improvement: 26%
j.u.c.LinkedBlockingQueue
JDK 8: sun.misc.Contended

Simone [email protected]
Quiz
SLF4J Logger.debug(String, Object...)
int read = socket.read(buffer);
logger.debug("Bytes read {}", read);
Vararg array creation
Boxing of the read variable Values are likely not cached
Simone [email protected]
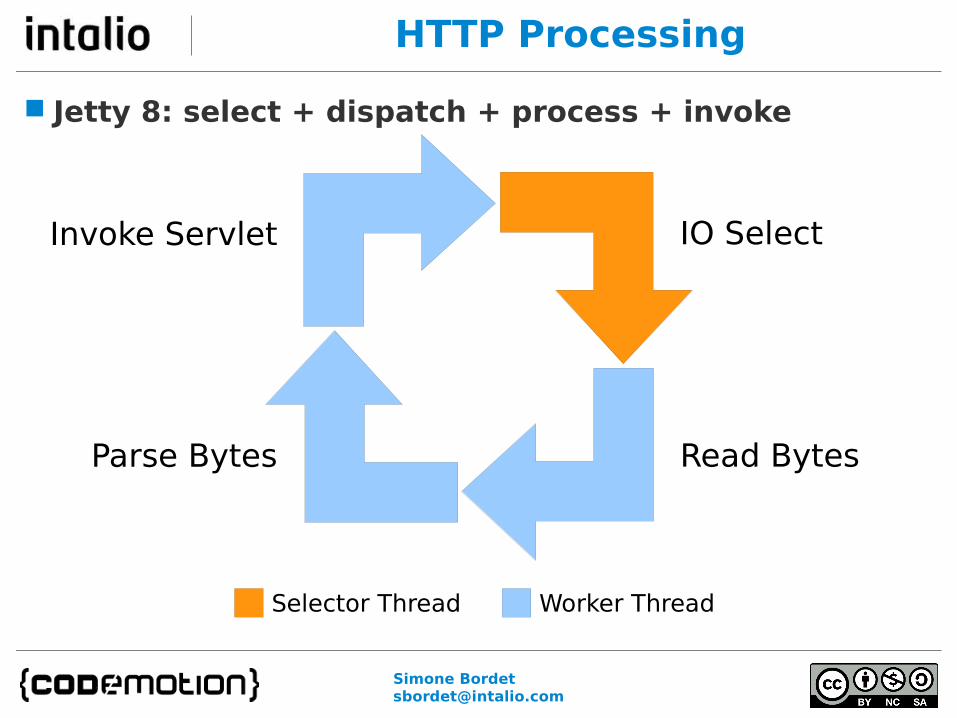
HTTP Processing
Jetty 8: select + dispatch + process + invoke
IO Select
Read BytesParse Bytes
Invoke Servlet
Selector Thread Worker Thread
Simone [email protected]
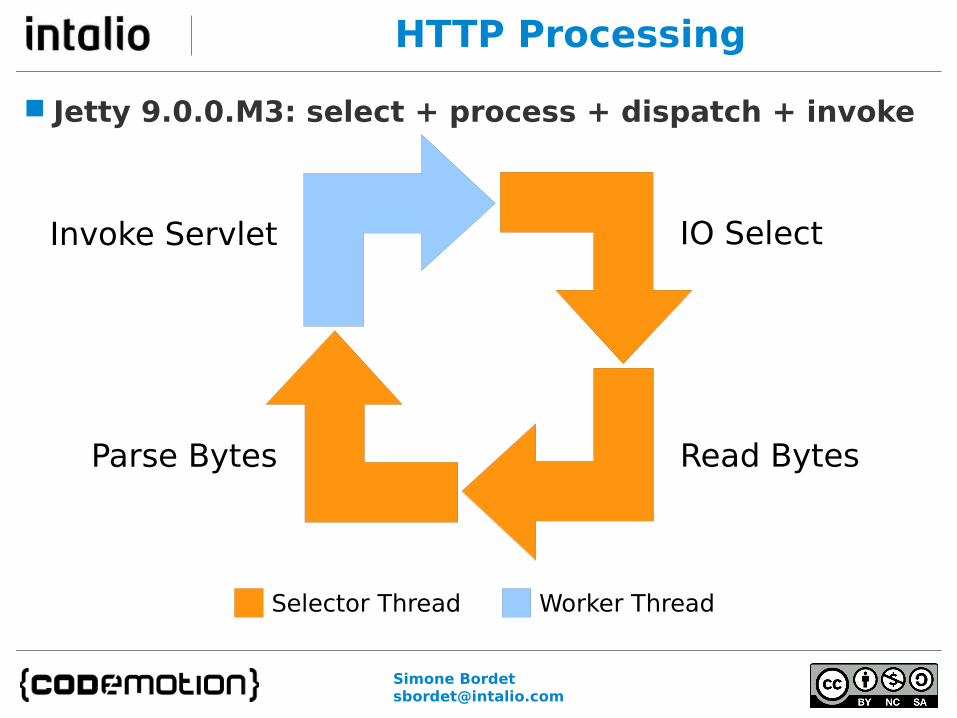
HTTP Processing
Jetty 9.0.0.M3: select + process + dispatch + invoke
IO Select
Read BytesParse Bytes
Invoke Servlet
Selector Thread Worker Thread

Simone [email protected]
HTTP Processing Benchmark
Pipeline Benchmark, 1 M requests Jetty 8: 37.696 s Jetty 9.M3: 47.212 s
Even if Jetty 9.0.0.M3 was faster in each step the overall performance was horrible Parallel slowdown
From Jetty 9.0.0.M4 onward we switched back to the select + dispatch + process + invoke model

Simone [email protected]
HTTP Processing Benchmark
Pipeline Benchmark, 1 M requests Jetty 8: 37.696 s Jetty 9.M4+: 29.172 s
Jetty 9 is way faster than Jetty 8 Produces less garbage too

Simone [email protected]
JDK 7 NIO2 AsyncSocketChannel
JDK7's NIO AsynchronousSocketChannel I/O operations and CompletionHandler notifications only
happen in the “channel group” thread
Two problems: Unnecessary context switch for I/O operations Stack overflow for I/O operations performed by
completion handlers Additional context switch after N recursions

Simone [email protected]
Atomic State Machines
Jetty 9: no synchronized blocks in the core All replaced by atomic state machines
No StackOverflowError typical of asynchronous callbacks Without context switch to a new thread
public abstract class IteratingCallback implements Callback
{
protected enum State
{ IDLE, PROCESSING, PENDING, ... };
private final AtomicReference<State> _state =
new AtomicReference<>(State.IDLE);
}

Simone [email protected]
Atomic State Machines
public void succeeded()
{
loop: while (true)
{
State current = _state.get();
switch (current)
{
case PENDING:
if (_state.compareAndSet(current, State.PROCESSING))
break loop;
continue;
...
}
}
}

Simone [email protected]
Conclusions
Know your hardware You will become a better programmer
Do not try this at home These optimizations only matter in the right context Ask library writers to optimize though !
Use Jetty 9.x We do care about these optimizations