Embed Size (px)
DESCRIPTION
How can we rewrite our application to handle new challenges coming from applications that need to scale over the cloud? Use patterns, so you can use the best technology at every tier
Citation preview

Introduzione al Cloud ComputingEdizione 2012
Application Architecture for Cloud
Marco Parenzan

Many Application Types…

Web Hosting Massive scale infrastructure
Burst & overflow capacity
Temporary, ad-hoc sites
Application Hosting Hybrid applications
Composite applications
Automated agents / jobs
Media Hosting & Processing CGI rendering
Content transcoding
Media streaming
Distributed Storage External backup and
storage
High Performance Computing Parallel & distributed
processing
Massive modeling & simulation
Advanced analytics
Information Sharing Reference data
Common data repositories
Knowledge discovery & mgmt
Collaborative Processes Multi-enterprise integration
B2B & e-commerce
Supply chain management
Health & life sciences
Domain-specific services
Many Application Models…

Computing-Oriented
Application

Calculation intensive Focus on
Algorithms Speed Parallelism
Computing-Oriented Applications

Data-Oriented
Application

Data access intensive Focus on
Storage Capacity Storage Realibility Access Speed Query API
Data-Oriented Applications

Internet-driven (now classic)Architecture
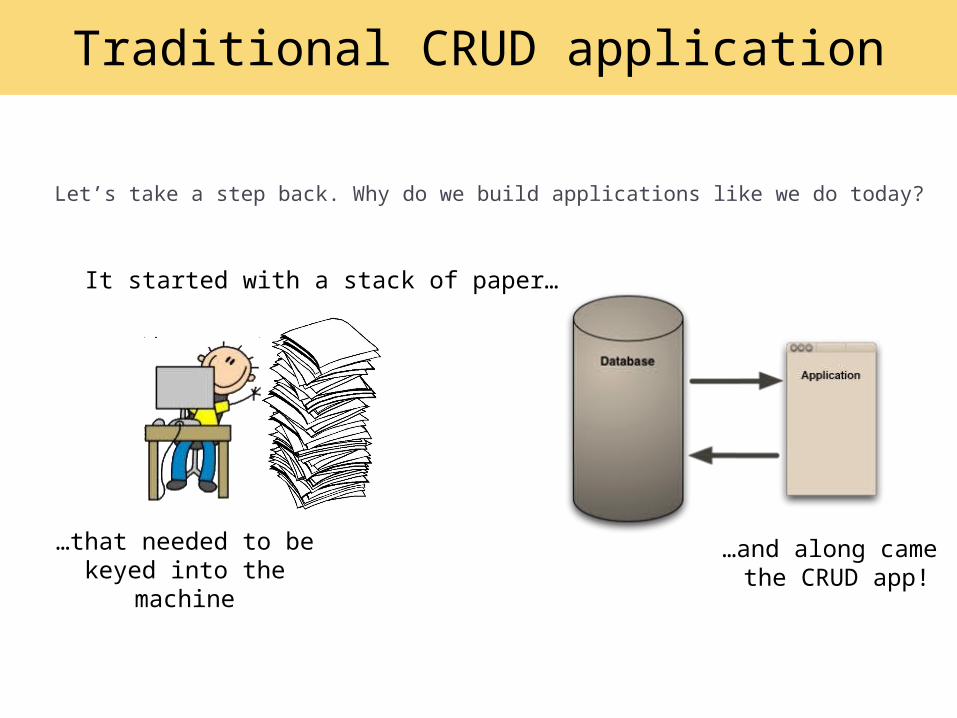
Traditional CRUD application
Let’s take a step back. Why do we build applications like we do today?
It started with a stack of paper…
…that needed to be keyed into the machine
…and along came the CRUD app!
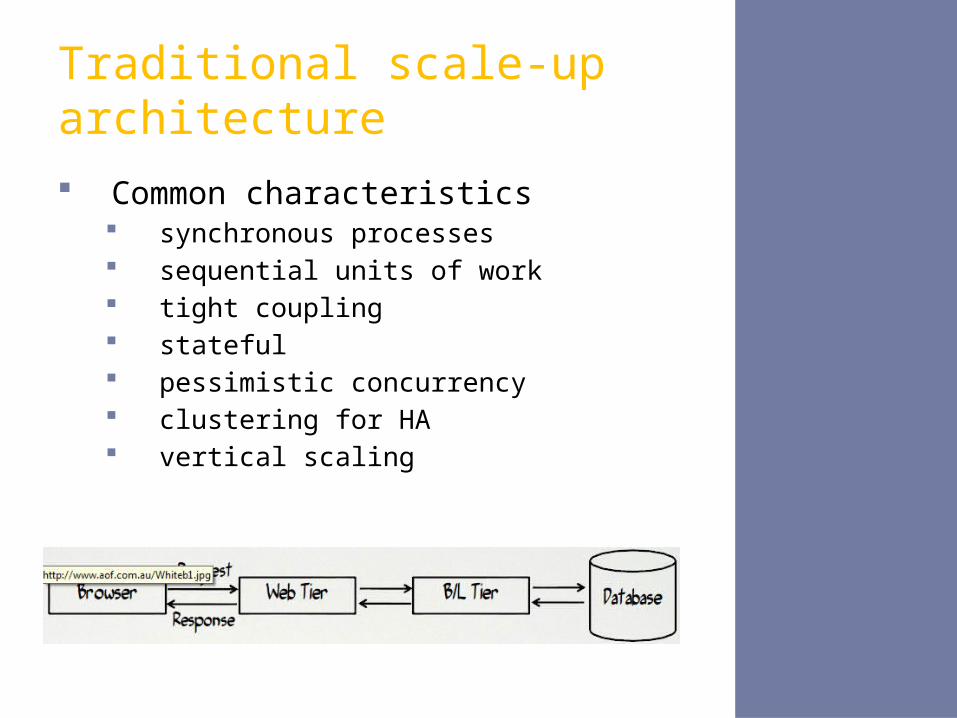
Common characteristics synchronous processes sequential units of work tight coupling stateful pessimistic concurrency clustering for HA vertical scaling
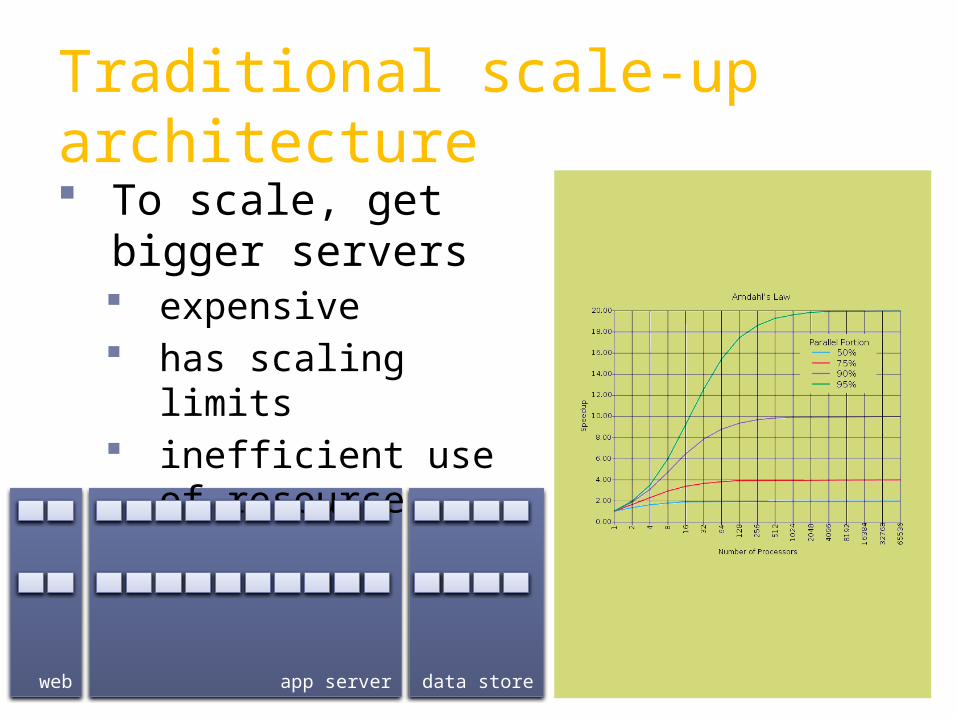
Traditional scale-up architecture
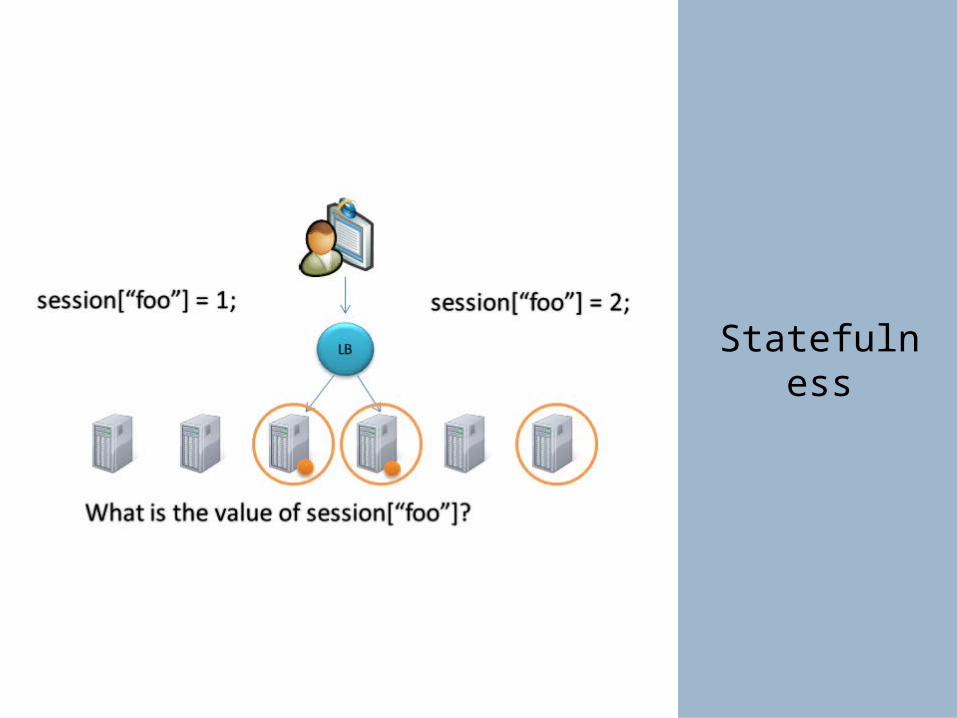
Statefulness
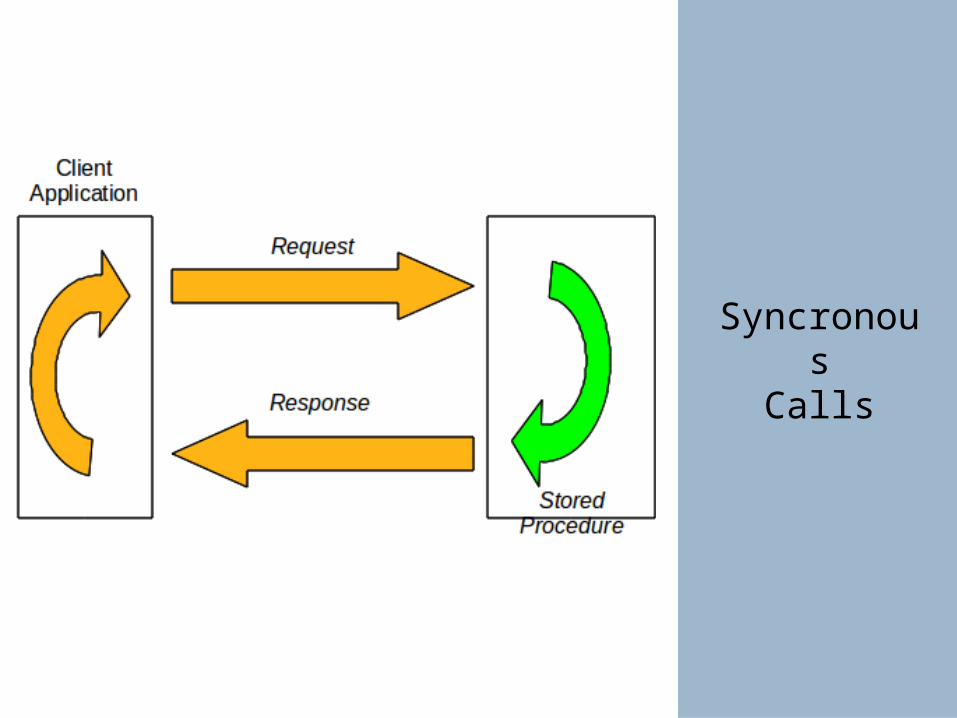
Syncronous
Calls

Tightly coupled
architectures

Scalability
The ability to increase or reduce the number of resources without affecting the end user experience.
app server
To scale, get bigger servers expensive has scaling limits inefficient use of
resources
Traditional scale-up architecture
web data store
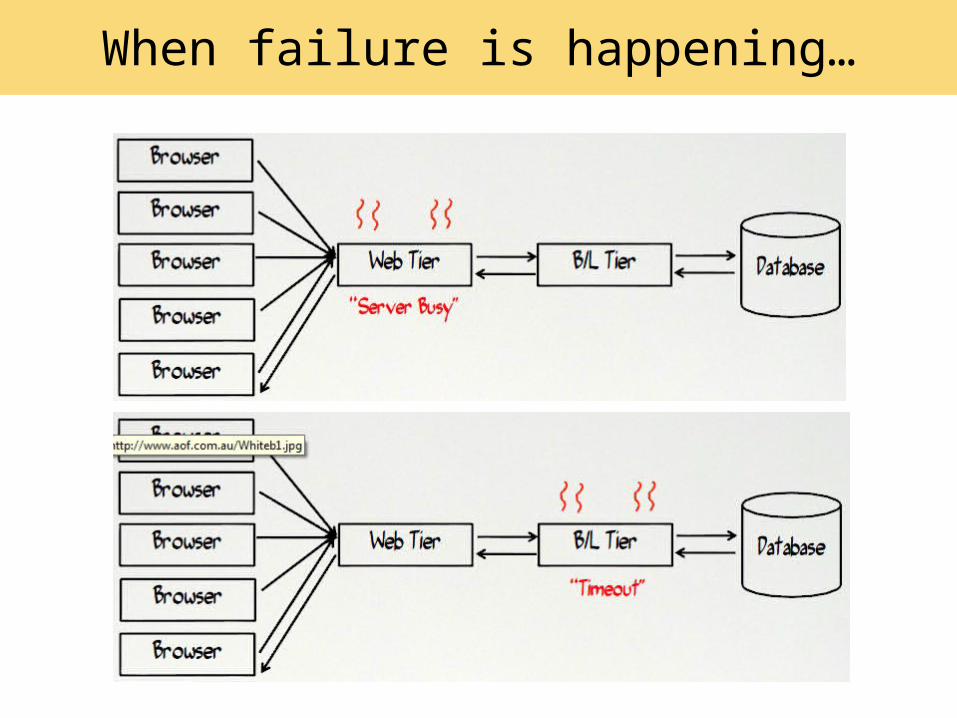
When failure is happening…

bigger failure impact
When problems occur…
data storeapp server
app serverweb
web
app serverweb
data storeweb
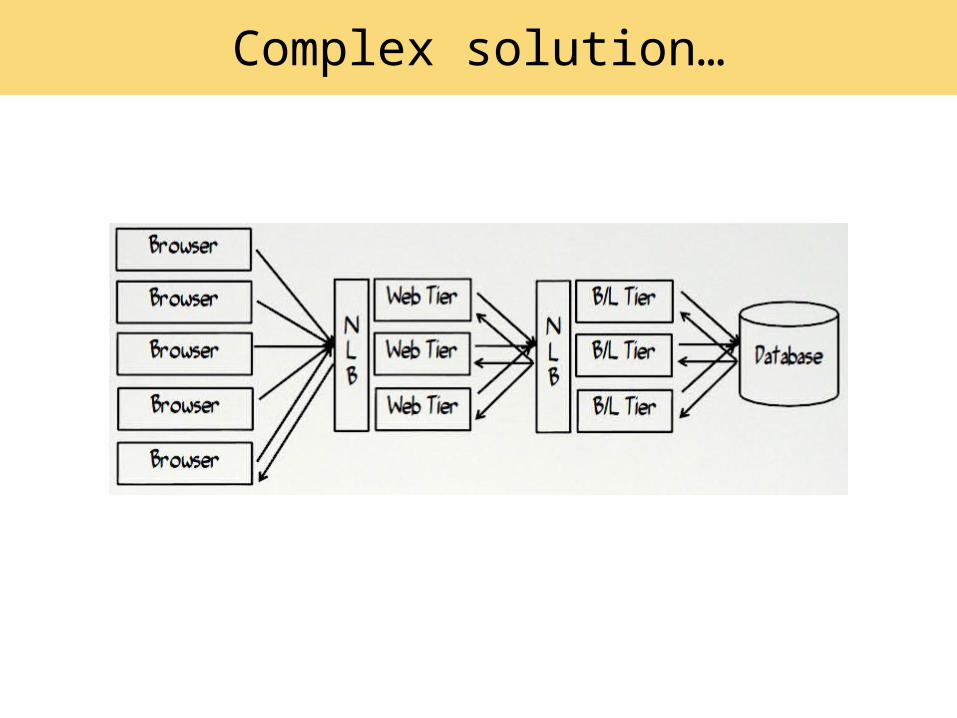
Complex solution…

DB-oriente
d

Paura??

In computer processing, if a processor changes the value of an operand and then, at a subsequent time, fetches the operand and obtains the old rather than the new value of the operand, then it is said to have seen stale data.
Stale Data
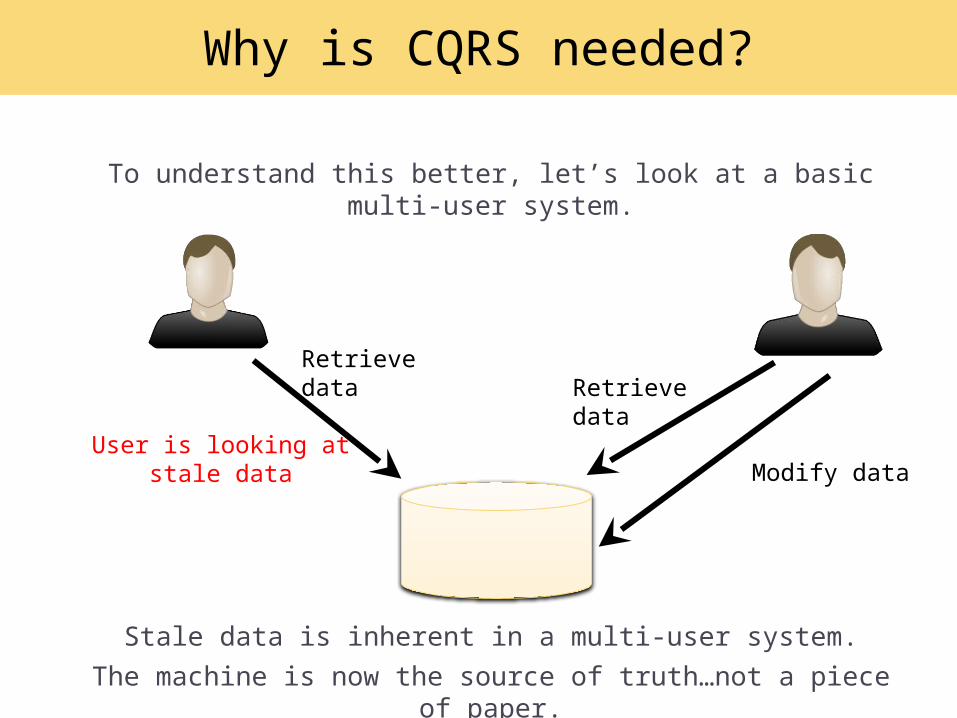
Why is CQRS needed?
Retrieve dataRetrieve data
Modify dataUser is looking at stale
data
Stale data is inherent in a multi-user system.
To understand this better, let’s look at a basic multi-user system.
The machine is now the source of truth…not a piece of paper.

All of this to provide scalability & a consistent view of the data.
Why is CQRS needed?
But did we succeed?

Why is CQRS needed?
Back to our CRUD app…
Where is the consistency? We have stale data all over the place!
?
?
?
?
??

Since stale data always exists, is all of this complexity really needed to scale? No, we need a different approach.
One that offers extreme scalability Inherently handle multiple users Can grow to handle complex problems
without growing development costs
Why is new model needed?


Use more pieces, not bigger pieces
LEGO 10179 Ultimate Collector's Millennium Falcon• 33 x 22 x 8.3 inches (L/W/H)• 5,195 pieces
LEGO 7778 Midi-scale Millennium Falcon• 9.3 x 6.7 x 3.2 inches (L/W/H) • 356 pieces

Cloud-driven Architecture
Scale out

Horizontal scaling Small pieces, loosely coupled Distributed computing best practices
asynchronous processes (event-driven design) parallelization idempotent operations (handle duplicity) optimistic concurrency shared nothing architecture fault-tolerance by redundancy
and replication etc.
Fundamental concepts
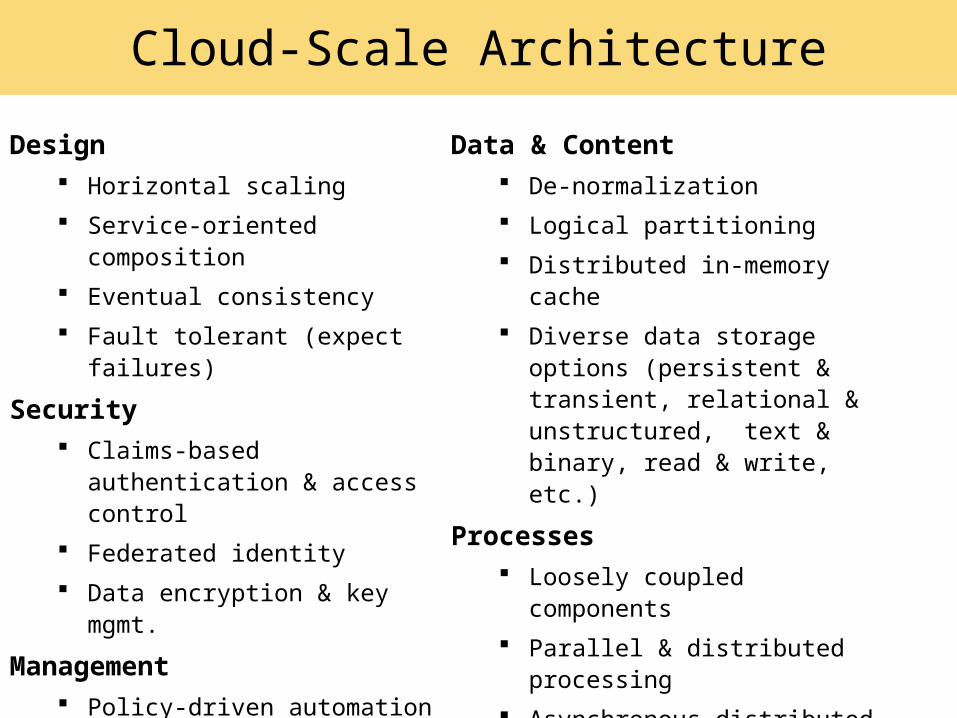
Cloud-Scale Architecture
Design Horizontal scaling Service-oriented composition Eventual consistency Fault tolerant (expect failures)
Security Claims-based authentication &
access control Federated identity Data encryption & key mgmt.
Management Policy-driven automation Aware of application lifecycles Handle dynamic data schema and
configuration changes
Data & Content De-normalization Logical partitioning Distributed in-memory cache Diverse data storage options
(persistent & transient, relational & unstructured, text & binary, read & write, etc.)
Processes Loosely coupled components Parallel & distributed processing Asynchronous distributed
communication Idempotent (handle duplicity) Isolation (separation of concerns)
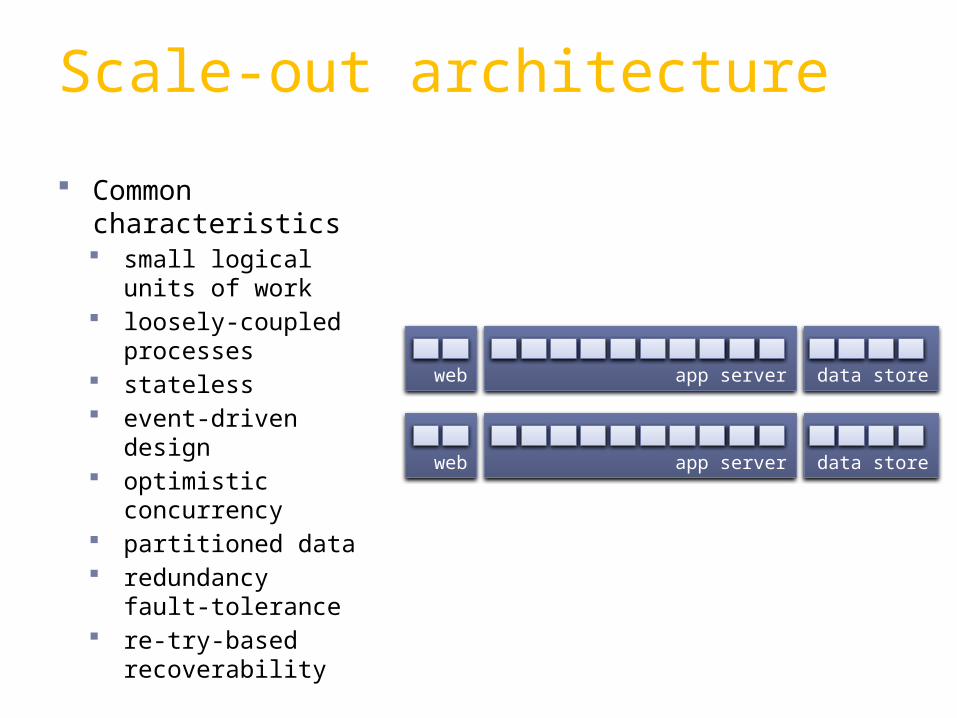
app server
Common characteristics small logical
units of work loosely-coupled
processes stateless event-driven
design optimistic
concurrency partitioned data redundancy
fault-tolerance re-try-based
recoverability
Scale-out architecture
app serverweb data store
web data store
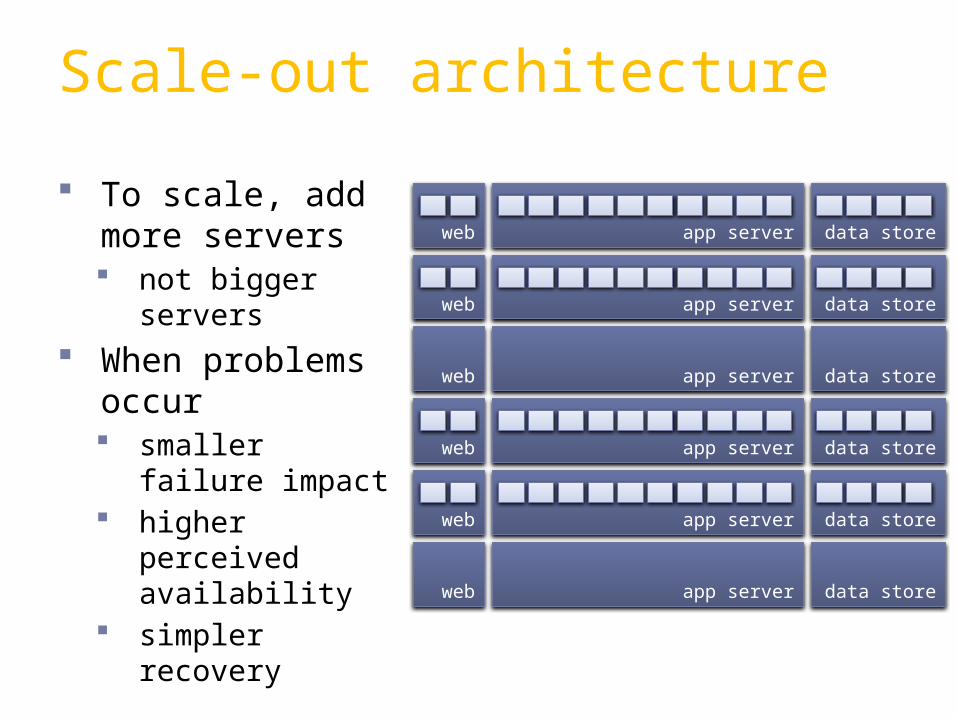
To scale, add more servers not bigger
servers When problems
occur smaller failure
impact higher
perceived availability
simpler recovery
Scale-out architecture
app server
app server
app server
app server
app server
app serverweb data store
web
web
web data store
web
web
data store
data store
data store
data store
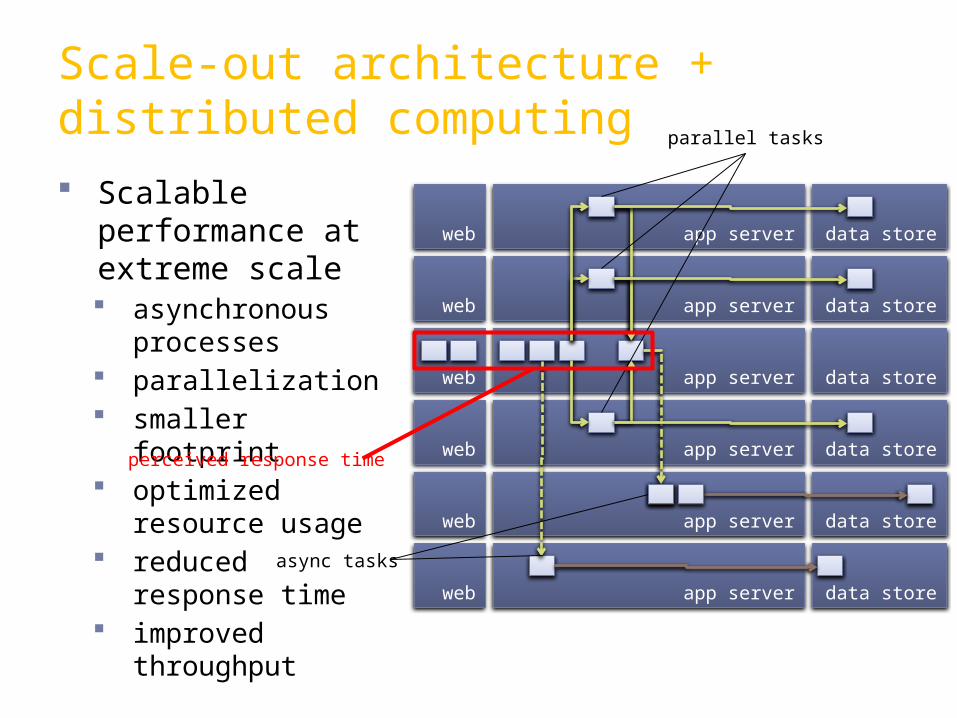
Scalable performance at extreme scale asynchronous
processes parallelization smaller
footprint optimized
resource usage reduced
response time improved
throughput
Scale-out architecture + distributed computing
app server
app server
app server
app server
app serverweb data store
web
web app server
web data store
web
web
data store
data store
data store
data store
parallel tasks
async tasks
perceived response time

Architecture Proposal

How does CQRS work?
Why rethink the User Interface?
Task-based UI
» Grids don’t capture the user’s intent

As a concept A set of principles A way of thinking about software
architecture.As a pattern Is a way of designing and developing
scalable and robust enterprise solutions where reads are independent from writes.
What is not The CQRS pattern says nothing
about how this should be implemented
CQRS
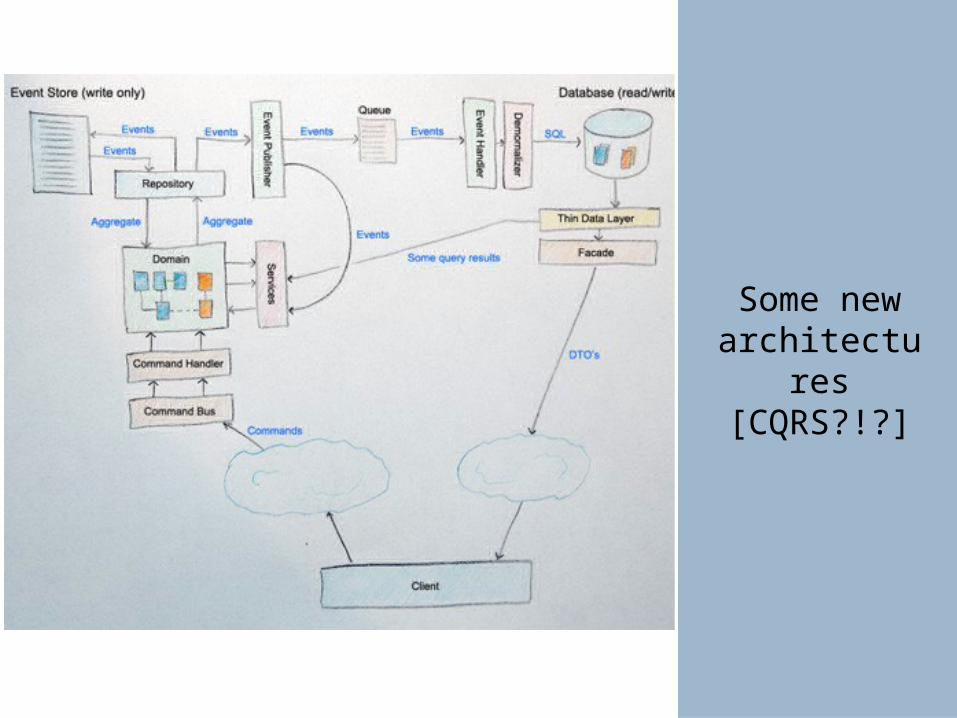
Some new architectures [CQRS?!?]

Task-based UI ViewModels
Commands Domain Objects Events Persistent View Model
Common components of the CQRS pattern
Scrum-based analysis
Collect user-stories Scenario
Each user-story is not an entity
Every user story is a task
Task-Driven User Interface

Rethinking the User Interface Adjust UI design to capture intent
what did the user really mean? intent becomes a command
Why is intent important?
Last name changed because of misspelling
Last name changed because of marriage
Last name changed because of divorce
User interface can affect your architecture
How does CQRS work?
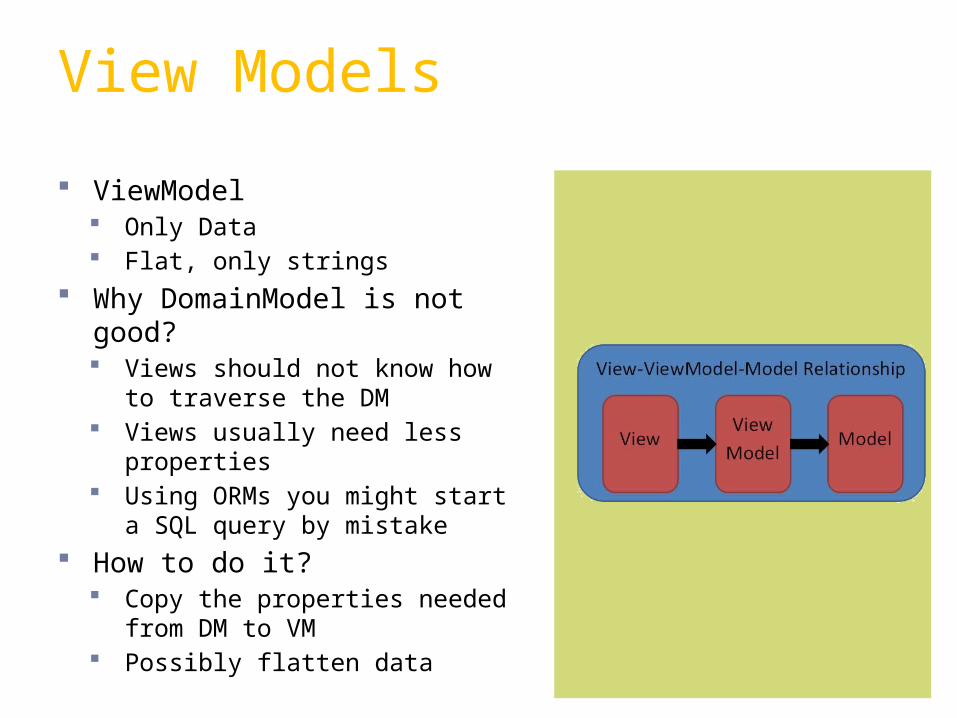
ViewModel Only Data Flat, only strings
Why DomainModel is not good? Views should not know how
to traverse the DM Views usually need less
properties Using ORMs you might start
a SQL query by mistake How to do it?
Copy the properties needed from DM to VM
Possibly flatten data
View Models

Validation increase likelihood of command
succeeding validate client-side optimize validation using persistent view
model What about user feedback?
Polling: wait until read model is updated Use asynchronous messaging such as
email “Your request is being processed. You will
receive an email when it is completed” Just fake it!
Scope the change to the current user. Update a local in-memory model
How does CQRS work?

Commands encapsulate the user’s intent but do not contain business logic, only enough data for the command
What makes a good command? A command is an action – starts with a verb The kind you can reply with: “Thank you.
Your confirmation email will arrive shortly”. Inherently asynchronous.
Commands can be considered messages Messaging provides an asynchronous
delivery mechanism for the commands. As a message, it can be routed, queued, and transformed all independent of the sender & receiver
How do Commands work?

The domain model is utilized for processing commands; it is unnecessary for queries.
Unlike entity objects you may be used to, aggregate roots in CQRS only have methods (no getters/setters)
Domain Model

Events describe changes in the system state
An Event Bus can be utilized to dispatch events to subscribers
Events primary purpose update the read model
Events can also provider integration with external systems
CQRS can also be used in conjunction with Event Sourcing.
Events

Reads are usually the most common activity – many times 80-90%. Why not optimize them?
Read model is based on how the user wants to see the data.
Read model can be denormalized RDBMS, document store, etc.
Reads from the view model don’t need to be loaded into the domain model, they can be bond directly to the UI.
Persistent View Model
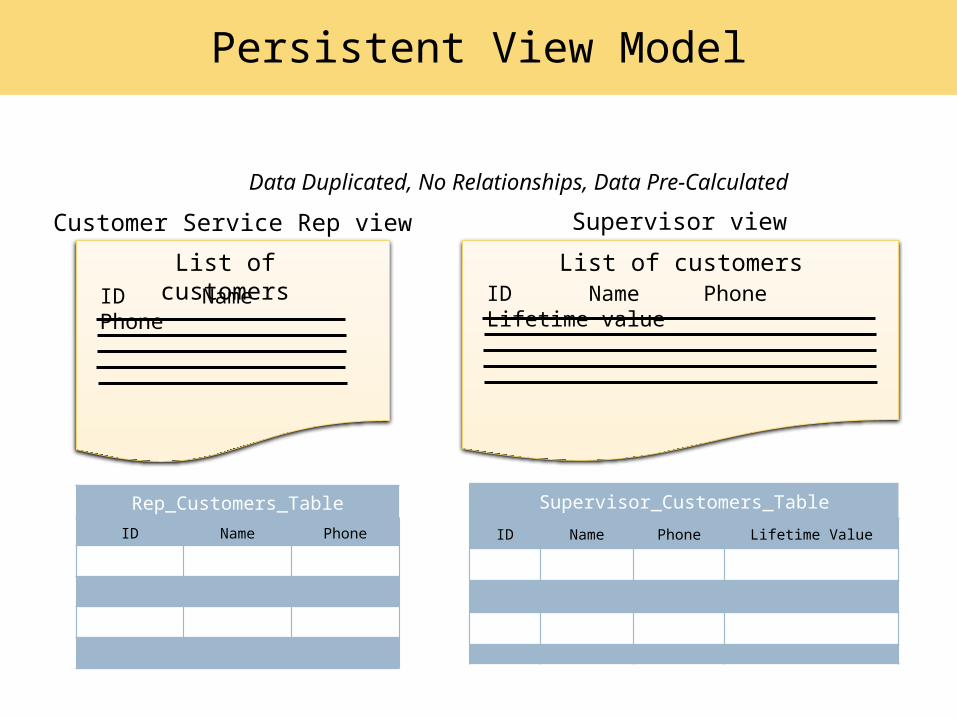
List of customers
Customer Service Rep view
ID Name Phone
List of customers
Supervisor view
ID Name Phone Lifetime value
Rep_Customers_Table
ID Name Phone
Supervisor_Customers_Table
ID Name Phone Lifetime Value
Persistent View Model
Data Duplicated, No Relationships, Data Pre-Calculated

Architecture ProposalThen??

CQRS can be overkill for simple applications.
Don’t use it in a non-collaborative domain or where you can horizontally add more database servers to support more users/requests/data at the same time you’re adding web servers – there is no real scalability problem – Udi Dahan
When should not use CQRS?

Guidelines for using CQRS: Large, multi-user systems CQRS is
designed to address concurrency issues. Scalability matters With CQRS you can
achieve great read and write performance. The system intrinsically supports scaling out. By separating read & write operations, each can be optimized.
Difficult business logic CQRS forces you to not mix domain logic and infrastructural operations.
Large or Distributed teams you can split development tasks between different teams with defined interfaces.
When should I use CQRS?

Cloud Offeringsfor Computing Oriented Applications

Low Availability Computing Nodes
High Availability Computing Node
Compute Services
ServiceLevel
Agreement

Many virtual servers of public clouds are offered at a low availability. Sometimes, availability is additionally expressed in an uncommon manner. For example, Amazon guarantees an availability of EC2 instances of 99.95% during a service year of 365 days [8]. 99.95% means about 4,4h/yr
However, this does not mean that a single instance has 99.95% availability during this time period, as could be expected.
Instead, unavailability is defined as the state when all running instances cannot be reached longer than five minutes and no replacement instances can be provisioned.
Low Available Compute Node

Resources shall be assigned to and revoked from applications dynamically depending on the current load.
The infrastructure must support dynamic provisioning and deprovisioning of resources
This functionality must be offered through an API to be used by atomized management tools and the applications that are hosted by the environment.
An elastic infrastructure supports the dynamic allocation of (virtual) resources that constitute a common resource pool.
Elastic Infrastructure

Strict Consistency Eventual Consistency
Storage Consistency

A storage offering usually consists of multiple replicas to ensure fault tolerance. It is of major importance that the consistency of the data contained in these replicas is pertained at all times while the performance is of secondary importance.
The highest level of consistency is granted if all replicas are updated if the data contained by them is altered. However, this would mean that the availability of the overall storage solution is decreased drastically. It has to be ensured that it is available even if not all replicas are available, but still the correct version of the data is read.
Strict Consistency

Eventually consistent data storage allows reducing data consistency to increase availability and performance, since the impact of network partitioning is reduced and fewer replicas have to be accessed during read and write operation.
While strictly consistent databases ensure that always at least one of the current version is read, eventually consistent databases allow that obsolete versions may also be read.
This increases the availability of the storage offering since only one replica has to be available to successfully execute a read operation.
Eventual Consistency
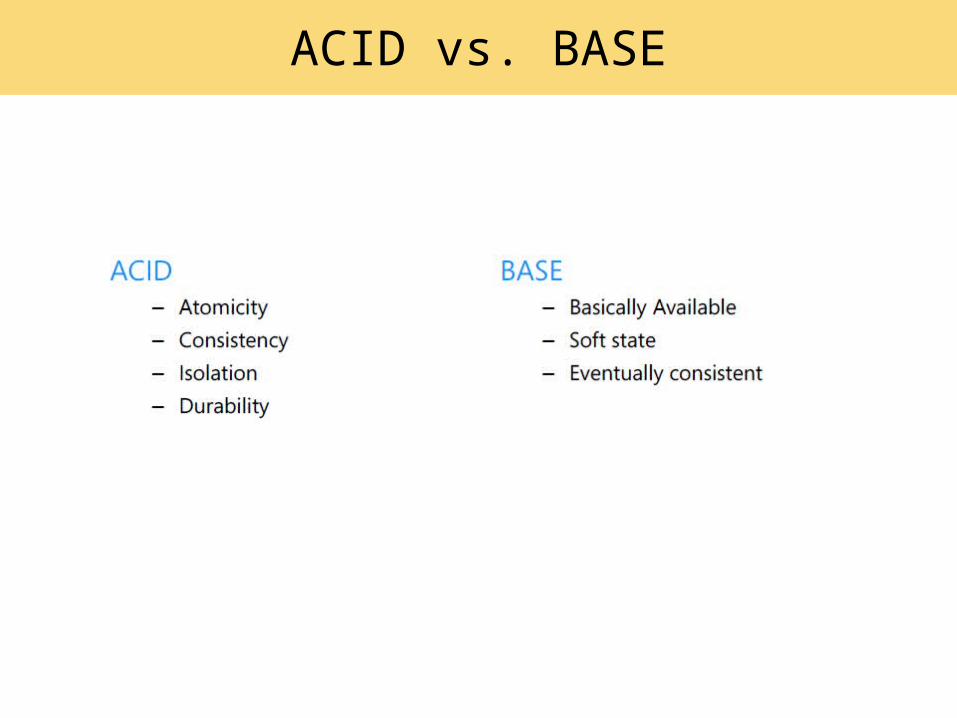
ACID vs. BASE

CAP (Consistency, Availability, Partition) Theorem
At most two of these properties for any shared-data system
C A
P
Consistency + Availability • High data integrity• Single site, cluster database, LDAP, xFS file
system, etc.• 2-phase commit, data replication, etc.
C A
P
Consistency + Partition • Distributed database, distributed locking, etc.• Pessimistic locking, minority partition
unavailable, etc.
C A
P
Availability + Partition • High scalability• Distributed cache, DNS, etc.• Optimistic locking, expiration/leases, etc.

Hybrid architectures
• Scale-out (horizontal)– BASE: Basically Available, Soft state,
Eventually consistent– focus on “commit”– conservative (pessimistic)– shared nothing– favor extreme size– e.g., user requests, data collection &
processing, etc.
Scale-up (vertical) ACID: Atomicity, Consistency,
Isolation, Durability availability first; best effort aggressive (optimistic) transactional favor accuracy/consistency e.g., BI & analytics, financial
processing, etc.
Most distributed systems employ both approaches

Relations Data Storage Blob Data Storage Block Data Storage NoSQL Storage
Storage Services
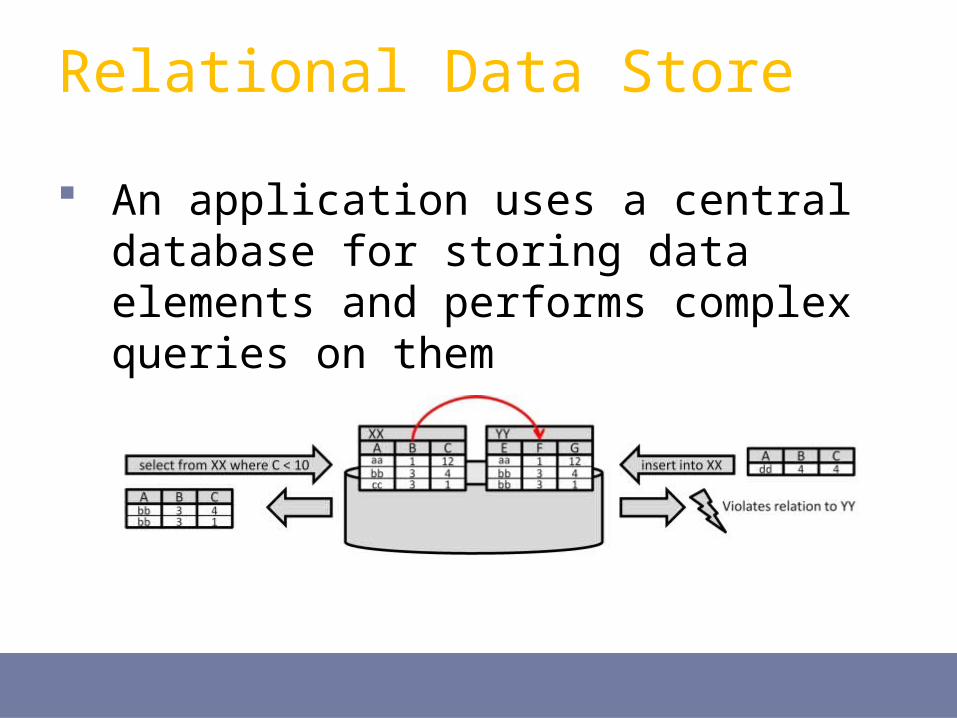
An application uses a central database for storing data elements and performs complex queries on them
Relational Data Store
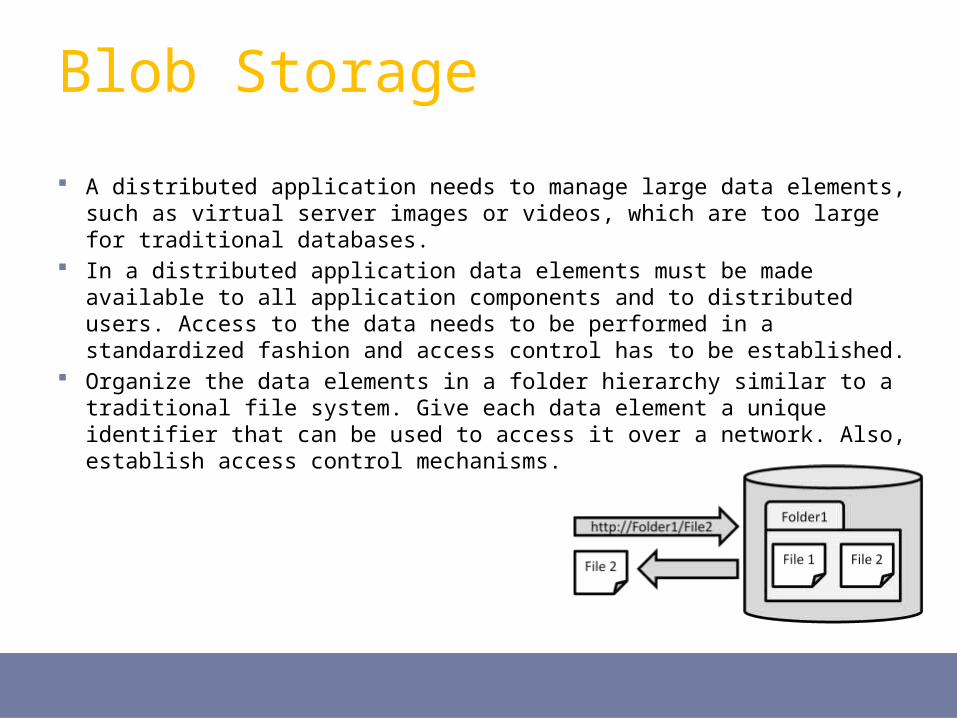
A distributed application needs to manage large data elements, such as virtual server images or videos, which are too large for traditional databases.
In a distributed application data elements must be made available to all application components and to distributed users. Access to the data needs to be performed in a standardized fashion and access control has to be established.
Organize the data elements in a folder hierarchy similar to a traditional file system. Give each data element a unique identifier that can be used to access it over a network. Also, establish access control mechanisms.
Blob Storage

Resources in clouds are often unreliable (low available compute nodes).
Therefore, the data that they access locally shall in fact be stored in a high available central data store. This way, if a server fails the data is not lost, but a new server can be started to use the secured data.
Offer data elements in a central storage that can be accessed by distributed servers and integrate them as local drives.
Block Storage

Need to handle very large amounts of data and also need to be adjusted to new user demands flexibly.
Database solution is required that focuses on scaling out rather than on optimizing the use of a single resource and that can adjust flexibly to changes of the data structure.
Use a schema-free storage solution, with limited query capabilities to enable extreme scale-out through easy data replication.
NoSQL Storage

Message Oriented Middleware
Reliable Messaging Exactly Once Delivery At least Once Delivery
Communication Services

Different applications usually use different languages, data formats, and technology platforms. When one application (component) needs to exchange information with another one, the format of the target application has to be respected.
Sending messages directly to the target application results in a tight coupling of sender and receiver since format changes directly affect both implementations.
Connect applications through an intermediary, the message oriented middleware, that hides the complexity of addressing and availability of communication partners as well as supports transformation of different message formats.
Message-oriented middleware

The message transfer from one communication partner to the other is performed under transactional context.
Especially, this transaction subsumes the operation performed to store the messages in persistent storage.
Thus, if an error occurs during message receiving, sending, or processing the transaction can be compensated transferring the overall system back to a correct and consistent state.
Reliable Messaging

The receiver of messages sends special acknowledge messages to the sender.
If the sender does not receive such an acknowledgement message in a given time frame it retransmits the message.
Thus, messages, which are lost due to communication errors, are still received eventually.
However, duplicate messages can occur, for example, if an acknowledgement message is lost.
To reduce the communication overhead, acknowledgement messages can be sent either after each individual message or after an agreed upon number of messages.
At-least once

Whenever a message is created it is associated with a unique identifier.
This is used by a filtering component on the message path to delete duplicates.
It does so by storing the identifiers of messages it has already seen.
The identifiers of messages passing through this filtering component are then compared to the identifiers that have been recorded to identify and delete duplicates.
Exaclty-once delivery





























