Embed Size (px)
Citation preview

Learning with Exploration
Alina BeygelzimerYahoo Labs, New York
(based on work by many)
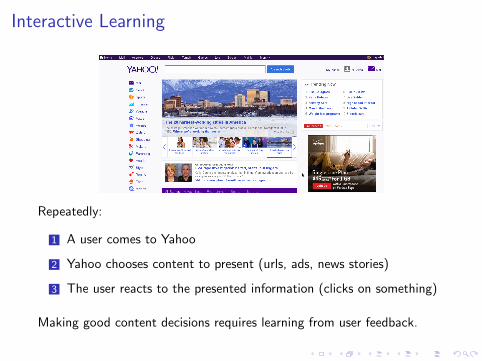
Interactive Learning
Repeatedly:
1 A user comes to Yahoo
2 Yahoo chooses content to present (urls, ads, news stories)
3 The user reacts to the presented information (clicks on something)
Making good content decisions requires learning from user feedback.

Abstracting the Setting
For t = 1, . . . ,T :
1 The world produces some context x ∈ X
2 The learner chooses an action a ∈ A
3 The world reacts with reward r(a, x)
Goal: Learn a good policy for choosing actions given context

Dominant Solution
1 Deploy some initial system
2 Collect data using this system
3 Use machine learning to build a reward predictor r̂(a, x) fromcollected data
4 Evaluate new system = arg maxa r̂(a, x)
offline evaluation on past databucket test
5 If metrics improve, switch to this new system and repeat

Example: Bagels vs. Pizza for New York and Chicago users
Initial system: NY gets bagels, Chicago gets pizza.
Observed CTR/Estimated CTR/True CTR
New York
?/1 0.6
Chicago
0.4/0.4/0.4
Bagels win. Switch to serving bagels for all and update modelbased on new data. Yikes! Missed out big in NY!
Example: Bagels vs. Pizza for New York and Chicago users
Initial system: NY gets bagels, Chicago gets pizza.
Observed CTR/Estimated CTR/True CTR
New York
?/1 0.6
Chicago
0.4/0.4/0.4
Bagels win. Switch to serving bagels for all and update modelbased on new data. Yikes! Missed out big in NY!

Example: Bagels vs. Pizza for New York and Chicago users
Initial system: NY gets bagels, Chicago gets pizza.
Observed CTR
/Estimated CTR/True CTR
New York ?
/1
0.6
Chicago 0.4
/0.4/0.4
?
Bagels win. Switch to serving bagels for all and update modelbased on new data. Yikes! Missed out big in NY!

Example: Bagels vs. Pizza for New York and Chicago users
Initial system: NY gets bagels, Chicago gets pizza.
Observed CTR/Estimated CTR
/True CTR
New York ?/0.5
/1
0.6/0.6
Chicago 0.4/0.4
/0.4
?/0.5
Bagels win. Switch to serving bagels for all and update modelbased on new data. Yikes! Missed out big in NY!

Example: Bagels vs. Pizza for New York and Chicago users
Initial system: NY gets bagels, Chicago gets pizza.
Observed CTR/Estimated CTR
/True CTR
New York ?/0.5
/1
0.6/0.6
Chicago 0.4/0.4
/0.4
?/0.5
Bagels win. Switch to serving bagels for all and update modelbased on new data.
Yikes! Missed out big in NY!

Example: Bagels vs. Pizza for New York and Chicago users
Initial system: NY gets bagels, Chicago gets pizza.
Observed CTR/Estimated CTR
/True CTR
New York ?/0.5
/1
0.6/0.6
Chicago 0.4/0.4
/0.4
0.7/0.5
Bagels win. Switch to serving bagels for all and update modelbased on new data.
Yikes! Missed out big in NY!

Example: Bagels vs. Pizza for New York and Chicago users
Initial system: NY gets bagels, Chicago gets pizza.
Observed CTR/Estimated CTR
/True CTR
New York ?/0.4595
/1
0.6/0.6
Chicago 0.4/0.4
/0.4
0.7/0.7
Bagels win. Switch to serving bagels for all and update modelbased on new data.
Yikes! Missed out big in NY!

Example: Bagels vs. Pizza for New York and Chicago users
Initial system: NY gets bagels, Chicago gets pizza.
Observed CTR/Estimated CTR/True CTR
New York ?/0.4595/1 0.6/0.6/0.6
Chicago 0.4/0.4/0.4 0.7/0.7/0.7
Bagels win. Switch to serving bagels for all and update modelbased on new data.
Yikes! Missed out big in NY!

Basic Observations
1 Standard machine learning is not enough. Model fits collecteddata perfectly.
2 More data doesn’t help: Observed = True where data wascollected.
3 Better data helps! Exploration is required.
4 Prediction errors are not a proxy for controlled exploration.

Basic Observations
1 Standard machine learning is not enough. Model fits collecteddata perfectly.
2 More data doesn’t help: Observed = True where data wascollected.
3 Better data helps! Exploration is required.
4 Prediction errors are not a proxy for controlled exploration.

Basic Observations
1 Standard machine learning is not enough. Model fits collecteddata perfectly.
2 More data doesn’t help: Observed = True where data wascollected.
3 Better data helps! Exploration is required.
4 Prediction errors are not a proxy for controlled exploration.

Basic Observations
1 Standard machine learning is not enough. Model fits collecteddata perfectly.
2 More data doesn’t help: Observed = True where data wascollected.
3 Better data helps! Exploration is required.
4 Prediction errors are not a proxy for controlled exploration.

Attempt to fix
New policy: bagels in the morning, pizza at night for bothcities
This will overestimate the CTR for both!
Solution: Deployed system should be randomized withprobabilities recorded.

Attempt to fix
New policy: bagels in the morning, pizza at night for bothcities
This will overestimate the CTR for both!
Solution: Deployed system should be randomized withprobabilities recorded.

Attempt to fix
New policy: bagels in the morning, pizza at night for bothcities
This will overestimate the CTR for both!
Solution: Deployed system should be randomized withprobabilities recorded.

Offline Evaluation
Evaluating a new system on data collected by deployed systemmay mislead badly:
New York ?/1/1 0.6/0.6/0.5
Chicago 0.4/0.4/0.4 0.7/0.7/0.7
The new system appears worse than deployed system oncollected data, although its true loss may be much lower.

The Evaluation Problem
Given a new policy, how do we evaluate it?
One possibility: Deploy it in the world.
Very Expensive! Need a bucket for every candidate policy.

The Evaluation Problem
Given a new policy, how do we evaluate it?
One possibility: Deploy it in the world.
Very Expensive! Need a bucket for every candidate policy.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2 Policy 1 Policy 2 Policy 1
no click no click click no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2 Policy 1 Policy 2 Policy 1
no click no click click no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2
Policy 1 Policy 2 Policy 1
no click no click click no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2
Policy 1 Policy 2 Policy 1
no click no click click no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2
Policy 1 Policy 2 Policy 1
no click
no click click no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2
Policy 1 Policy 2 Policy 1
no click
no click click no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2 Policy 1
Policy 2 Policy 1
no click
no click click no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2 Policy 1
Policy 2 Policy 1
NYno click
no click click no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2 Policy 1
Policy 2 Policy 1
no click no click
click no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2 Policy 1
Policy 2 Policy 1
no click no click
click no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2 Policy 1 Policy 2
Policy 1
no click no click
click no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2 Policy 1 Policy 2
Policy 1
no click no click
click no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2 Policy 1 Policy 2
Policy 1
no click no click click
no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2 Policy 1 Policy 2
Policy 1
no click no click click
no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2 Policy 1 Policy 2 Policy 1
no click no click click
no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2 Policy 1 Policy 2 Policy 1
Chicagono click no click click
no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2 Policy 1 Policy 2 Policy 1
no click no click click no click
. . .
Two weeks later, evaluate which is better.

A/B testing for evaluating two policies
Policy 1 : Use pizza for New York, bagels for Chicago rule
Policy 2 : Use bagels for everyone rule
Segment users randomly into Policy 1 and Policy 2 groups:
Policy 2 Policy 1 Policy 2 Policy 1
no click no click click no click
. . .
Two weeks later, evaluate which is better.

Instead randomize every transaction(at least for transactions you plan to use for learning and/or evaluation)
Simplest strategy: ε-greedy. Go with empirically best policy, butalways choose a random action with probability ε > 0.
no click no click click no click · · ·(x , b, 0, pb) (x , p, 0, pp) (x , p, 1, pp) (x , b, 0, pb)
Offline evaluation
Later evaluate any policy using the same events. Each evaluationis cheap and immediate.

Instead randomize every transaction(at least for transactions you plan to use for learning and/or evaluation)
Simplest strategy: ε-greedy. Go with empirically best policy, butalways choose a random action with probability ε > 0.
no click no click click no click · · ·(x , b, 0, pb) (x , p, 0, pp) (x , p, 1, pp) (x , b, 0, pb)
Offline evaluation
Later evaluate any policy using the same events. Each evaluationis cheap and immediate.

Instead randomize every transaction(at least for transactions you plan to use for learning and/or evaluation)
Simplest strategy: ε-greedy. Go with empirically best policy, butalways choose a random action with probability ε > 0.
no click no click click no click · · ·(x , b, 0, pb) (x , p, 0, pp) (x , p, 1, pp) (x , b, 0, pb)
Offline evaluation
Later evaluate any policy using the same events. Each evaluationis cheap and immediate.

Instead randomize every transaction(at least for transactions you plan to use for learning and/or evaluation)
Simplest strategy: ε-greedy. Go with empirically best policy, butalways choose a random action with probability ε > 0.
no click
no click click no click · · ·
(x , b, 0, pb)
(x , p, 0, pp) (x , p, 1, pp) (x , b, 0, pb)
Offline evaluation
Later evaluate any policy using the same events. Each evaluationis cheap and immediate.

Instead randomize every transaction(at least for transactions you plan to use for learning and/or evaluation)
Simplest strategy: ε-greedy. Go with empirically best policy, butalways choose a random action with probability ε > 0.
no click
no click click no click · · ·
(x , b, 0, pb)
(x , p, 0, pp) (x , p, 1, pp) (x , b, 0, pb)
Offline evaluation
Later evaluate any policy using the same events. Each evaluationis cheap and immediate.

Instead randomize every transaction(at least for transactions you plan to use for learning and/or evaluation)
Simplest strategy: ε-greedy. Go with empirically best policy, butalways choose a random action with probability ε > 0.
no click
no click click no click · · ·
(x , b, 0, pb)
(x , p, 0, pp) (x , p, 1, pp) (x , b, 0, pb)
Offline evaluation
Later evaluate any policy using the same events. Each evaluationis cheap and immediate.

Instead randomize every transaction(at least for transactions you plan to use for learning and/or evaluation)
Simplest strategy: ε-greedy. Go with empirically best policy, butalways choose a random action with probability ε > 0.
no click no click
click no click · · ·
(x , b, 0, pb) (x , p, 0, pp)
(x , p, 1, pp) (x , b, 0, pb)
Offline evaluation
Later evaluate any policy using the same events. Each evaluationis cheap and immediate.

Instead randomize every transaction(at least for transactions you plan to use for learning and/or evaluation)
Simplest strategy: ε-greedy. Go with empirically best policy, butalways choose a random action with probability ε > 0.
no click no click
click no click · · ·
(x , b, 0, pb) (x , p, 0, pp)
(x , p, 1, pp) (x , b, 0, pb)
Offline evaluation
Later evaluate any policy using the same events. Each evaluationis cheap and immediate.

Instead randomize every transaction(at least for transactions you plan to use for learning and/or evaluation)
Simplest strategy: ε-greedy. Go with empirically best policy, butalways choose a random action with probability ε > 0.
no click no click
click no click · · ·
(x , b, 0, pb) (x , p, 0, pp)
(x , p, 1, pp) (x , b, 0, pb)
Offline evaluation
Later evaluate any policy using the same events. Each evaluationis cheap and immediate.

Instead randomize every transaction(at least for transactions you plan to use for learning and/or evaluation)
Simplest strategy: ε-greedy. Go with empirically best policy, butalways choose a random action with probability ε > 0.
no click no click click
no click · · ·
(x , b, 0, pb) (x , p, 0, pp) (x , p, 1, pp)
(x , b, 0, pb)
Offline evaluation
Later evaluate any policy using the same events. Each evaluationis cheap and immediate.

Instead randomize every transaction(at least for transactions you plan to use for learning and/or evaluation)
Simplest strategy: ε-greedy. Go with empirically best policy, butalways choose a random action with probability ε > 0.
no click no click click
no click · · ·
(x , b, 0, pb) (x , p, 0, pp) (x , p, 1, pp)
(x , b, 0, pb)
Offline evaluation
Later evaluate any policy using the same events. Each evaluationis cheap and immediate.

Instead randomize every transaction(at least for transactions you plan to use for learning and/or evaluation)
Simplest strategy: ε-greedy. Go with empirically best policy, butalways choose a random action with probability ε > 0.
no click no click click
no click · · ·
(x , b, 0, pb) (x , p, 0, pp) (x , p, 1, pp)
(x , b, 0, pb)
Offline evaluation
Later evaluate any policy using the same events. Each evaluationis cheap and immediate.

Instead randomize every transaction(at least for transactions you plan to use for learning and/or evaluation)
Simplest strategy: ε-greedy. Go with empirically best policy, butalways choose a random action with probability ε > 0.
no click no click click no click
· · ·
(x , b, 0, pb) (x , p, 0, pp) (x , p, 1, pp) (x , b, 0, pb)
Offline evaluation
Later evaluate any policy using the same events. Each evaluationis cheap and immediate.

Instead randomize every transaction(at least for transactions you plan to use for learning and/or evaluation)
Simplest strategy: ε-greedy. Go with empirically best policy, butalways choose a random action with probability ε > 0.
no click no click click no click · · ·(x , b, 0, pb) (x , p, 0, pp) (x , p, 1, pp) (x , b, 0, pb)
Offline evaluation
Later evaluate any policy using the same events. Each evaluationis cheap and immediate.

The Importance Weighting Trick
Let π : X → A be a policy. How do we evaluate it?
Collect exploration samples of the form
(x , a, ra, pa),
wherex = contexta = actionra = reward for actionpa = probability of action a
then evaluate
Value(π) = Average
(ra 1(π(x) = a)
pa
)

The Importance Weighting Trick
Let π : X → A be a policy. How do we evaluate it?
Collect exploration samples of the form
(x , a, ra, pa),
wherex = contexta = actionra = reward for actionpa = probability of action a
then evaluate
Value(π) = Average
(ra 1(π(x) = a)
pa
)

The Importance Weighting Trick
Theorem
Value(π) is an unbiased estimate of the expected reward of π:
E(x ,~r)∼D
[rπ(x)
]= E[ Value(π) ]
with deviations bounded by O( 1√T minx pπ(x)
).
Example:
Action 1 2
Reward 0.5 1Probability 1
434
Estimate
2 | 0 0 | 43

The Importance Weighting Trick
Theorem
Value(π) is an unbiased estimate of the expected reward of π:
E(x ,~r)∼D
[rπ(x)
]= E[ Value(π) ]
with deviations bounded by O( 1√T minx pπ(x)
).
Example:
Action 1 2
Reward 0.5 1Probability 1
434
Estimate 2
| 0
0
| 43

The Importance Weighting Trick
Theorem
Value(π) is an unbiased estimate of the expected reward of π:
E(x ,~r)∼D
[rπ(x)
]= E[ Value(π) ]
with deviations bounded by O( 1√T minx pπ(x)
).
Example:
Action 1 2
Reward 0.5 1Probability 1
434
Estimate 2 | 0 0 | 43

Can we do better?
Suppose we have a (possibly bad) reward estimator r̂(a, x). Howcan we use it?
Value′(π) = Average
((ra − r̂(a, x))1(π(x) = a)
pa+ r̂(π(x), x)
)
Why does this work?
Ea∼p
(r̂(a, x)1(π(x) = a)
pa
)= r̂(π(x), x)
Keeps the estimate unbiased. It helps, because ra − r̂(a, x) smallreduces variance.

Can we do better?
Suppose we have a (possibly bad) reward estimator r̂(a, x). Howcan we use it?
Value′(π) = Average
((ra − r̂(a, x))1(π(x) = a)
pa+ r̂(π(x), x)
)
Why does this work?
Ea∼p
(r̂(a, x)1(π(x) = a)
pa
)= r̂(π(x), x)
Keeps the estimate unbiased. It helps, because ra − r̂(a, x) smallreduces variance.

Can we do better?
Suppose we have a (possibly bad) reward estimator r̂(a, x). Howcan we use it?
Value′(π) = Average
((ra − r̂(a, x))1(π(x) = a)
pa+ r̂(π(x), x)
)
Why does this work?
Ea∼p
(r̂(a, x)1(π(x) = a)
pa
)= r̂(π(x), x)
Keeps the estimate unbiased. It helps, because ra − r̂(a, x) smallreduces variance.

Can we do better?
Suppose we have a (possibly bad) reward estimator r̂(a, x). Howcan we use it?
Value′(π) = Average
((ra − r̂(a, x))1(π(x) = a)
pa+ r̂(π(x), x)
)
Why does this work?
Ea∼p
(r̂(a, x)1(π(x) = a)
pa
)= r̂(π(x), x)
Keeps the estimate unbiased. It helps, because ra − r̂(a, x) smallreduces variance.

Can we do better?
Suppose we have a (possibly bad) reward estimator r̂(a, x). Howcan we use it?
Value′(π) = Average
((ra − r̂(a, x))1(π(x) = a)
pa+ r̂(π(x), x)
)
Why does this work?
Ea∼p
(r̂(a, x)1(π(x) = a)
pa
)= r̂(π(x), x)
Keeps the estimate unbiased. It helps, because ra − r̂(a, x) smallreduces variance.

How do you directly optimize based on past explorationdata?
1 Learn r̂(a, x).
2 Compute for each x and a′ ∈ A:
(ra − r̂(a, x))1(a′ = a)
pa+ r̂(a′, x)
3 Learn π using a cost-sensitive multiclass classifier.

Take home summary
Using exploration data
1 There are techniques for using past exploration data toevaluate any policy.
2 You can reliably measure performance offline, and henceexperiment much faster, shifting from guess-and-check (A/Btesting) to direct optimization.
Doing exploration
1 There has been much recent progress on practicalregret-optimal algorithms.
2 ε-greedy has suboptimal regret but is a reasonable choice inpractice.

Comparison of Approaches
Supervised ε-greedy Optimal CB algorithms
Feedback full bandit bandit
Regret O
(√ln |Π|
δT
)O
(3
√|A| ln |Π|
δT
)O
(√|A| ln |Π|
δT
)Running time O(T ) O(T ) O(T 1.5)
A. Agarwal, D. Hsu, S. Kale, J. Langford, L. Li, R. Schapire, Taming theMonster: A Fast and Simple Algorithm for Contextual Bandits, 2014
M. Dudik, D. Hsu, S. Kale, N. Karampatziakis, J. Langford, L. Reyzin, T.Zhang: Efficient optimal learning for contextual bandits, 2011
A. Beygelzimer, J. Langford, L. Li, L. Reyzin, R. Schapire: Contextual BanditAlgorithms with Supervised Learning Guarantees, 2011





























