Embed Size (px)
Citation preview

An Extensible NoSql Enhancing Application System

Big data emergency:needing to scale horizontally linearly RDBMS systems support complex interrogation (e.g. JOINs, GROUP BYs ..) and guarantees property which are complex to execute in a cluster.
Atomicy Consistency Isolation Durability:=> master-slave architecture.
GROUP BYs, JOINs and Transactions (2PC) => distribute locks, possible deadlocks
Why : NoSql
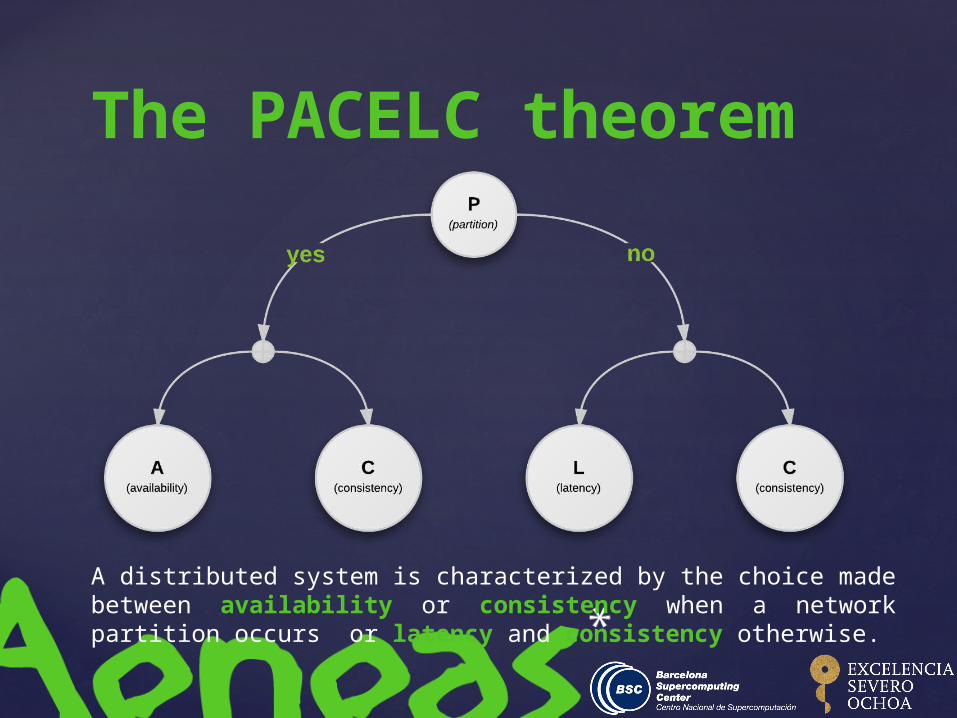
The PACELC theorem
A distributed system is characterized by the choice made between availability or consistency when a network partition occurs or latency and consistency otherwise.

{ {RDBMS
Standard:Schema with tables with a fixed structure: each row with the same number and type of columns
NOSQL
Far West:Each database has is a different data model with its peculiarity. It can be a key-Value store, Tables , Document one , Column or Row Oriented, Graphs….
Why: Data models
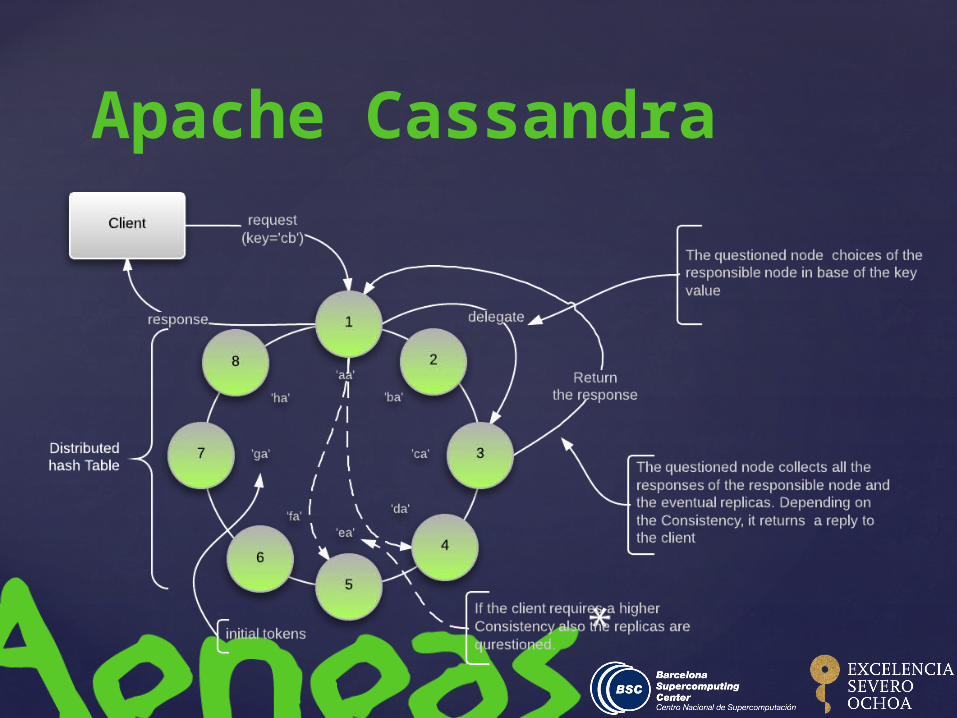
Apache Cassandra
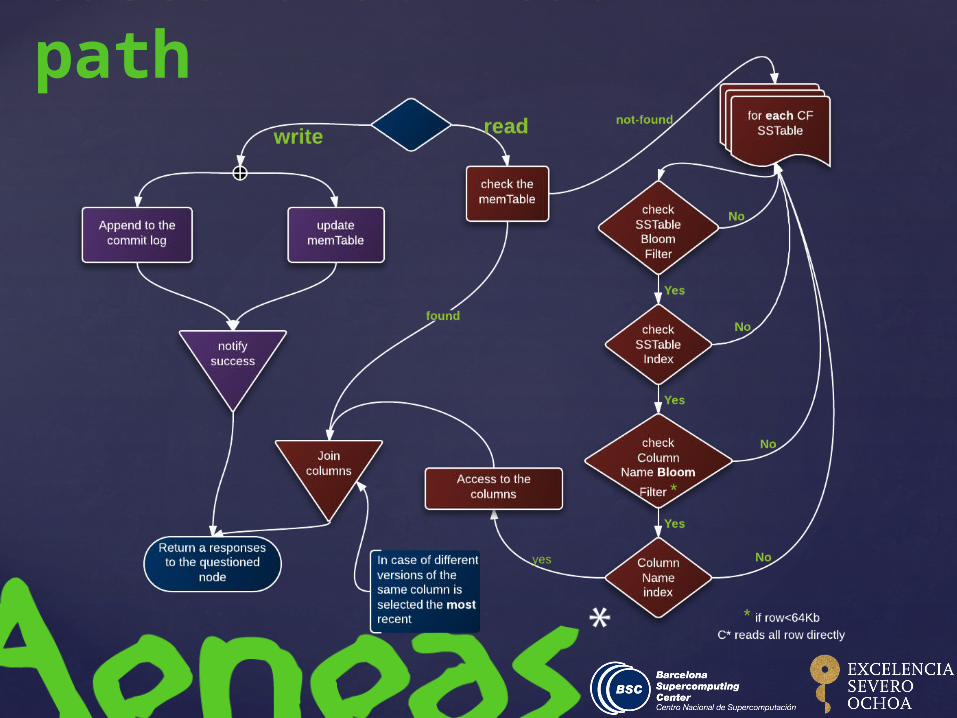
Cassandra: read path

It is basically a 2 level map.. with “some” extensions.
The easier way to access to a value is through a row id and a columns id:
clients[‘cesare88’][‘surname’]=“cugnasco”
Cassandra data model
Column family
Row key
Column name
Value
But…

The data model is flexible, it can be used in different ways.
The easier way to access to a value is through a row id and a columns id:
sports[‘cesare88’][’9.5:bike’]=“02/02/2013” sports[‘cesare88’][’8.3:running’]=“02/07/2013” sports[‘cesare88’][’0.3:swimming’]=“02/09/2012”
The behavior is similar to a an hash map which contains sorted maps(similar to a java HashMap<?, SortedMap<?,?>>(), or a SortedMap<?, SortedMap<?,?>>())
Cassandra data model

Sorting: where to store the values? Into the keys:
it requires to have a order preserving partitioner: one would have to rebalance the token every time the data distribution change
Into the column names:one can finely define how sort the values… but all the values will be stored in a single node and thus only in a single node (plus replicas)
Indexing: custom indexing or Cassandra’s hash ones? Composite types Query design: better reiterate an interrogation or duplicate data? Workload distribution: are the query well distributed on the nodes?
How to find the right solution? …many experiments.
Data model implications

Testing many data model and configuration is a time and money consuming process. The goal of the platform is to reduce this time by: Supporting the data insertion:
loading a data source sample into many different data-models could be made by a single configuration xml file.
Generate a queries code and workload :the framework generates statically the code of the query and offers and offers a support for trying the querying with different workload type: uniformly distributed, zip-fian, consequential…
Collect data and analyze it:running tests on a distributed environment requires to gather information from many different server and application layers. The framework support it by recording all metrics and storing them in a unique data store easy to interrogate.
Benchmarking platform
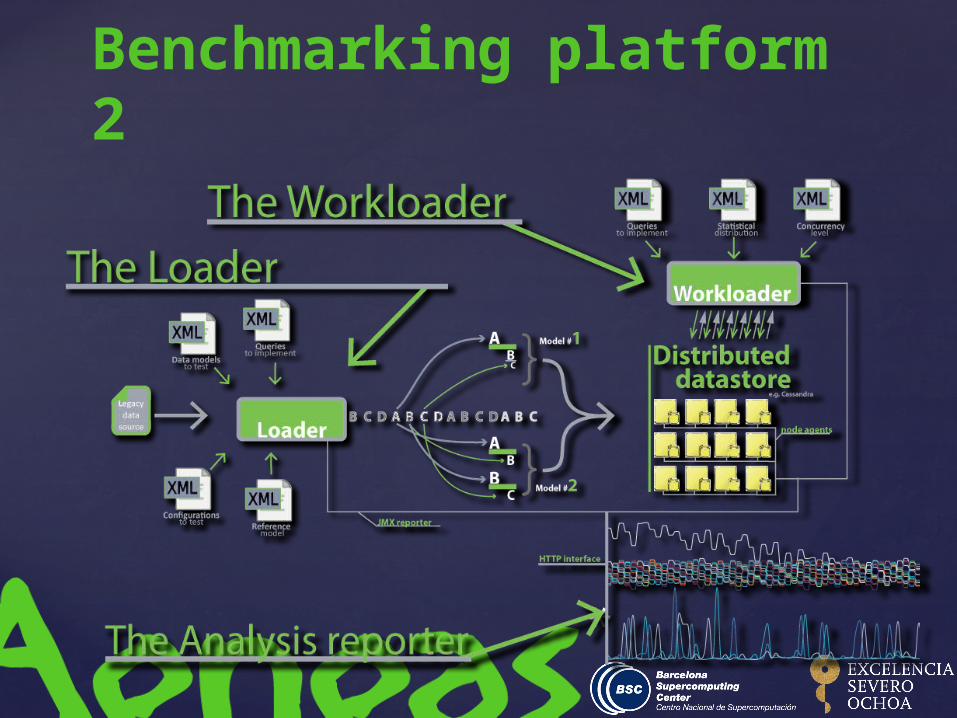
Benchmarking platform 2
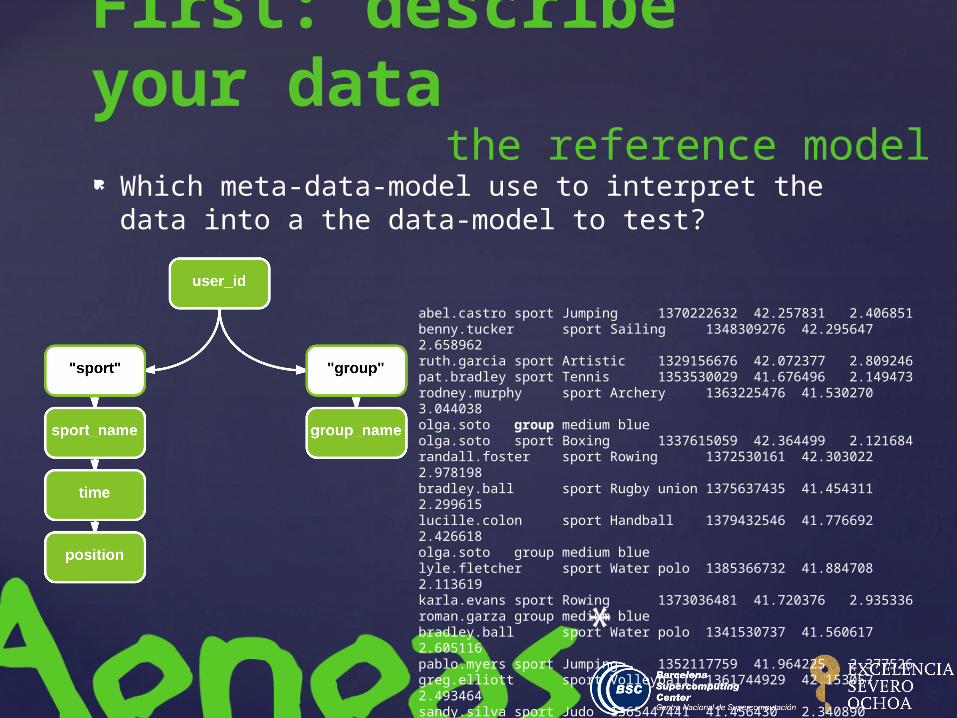
Which meta-data-model use to interpret the data into a the data-model to test?
First: describe your data
the reference model
abel.castro sport Jumping 1370222632 42.2578312.406851benny.tucker sport Sailing 1348309276 42.2956472.658962ruth.garcia sport Artistic 1329156676 42.0723772.809246pat.bradley sport Tennis 1353530029 41.6764962.149473rodney.murphy sport Archery 136322547641.530270 3.044038olga.soto group medium blueolga.soto sport Boxing 1337615059 42.3644992.121684randall.foster sport Rowing 1372530161 42.3030222.978198bradley.ball sport Rugby union 1375637435 41.4543112.299615lucille.colon sport Handball 1379432546 41.7766922.426618olga.soto group medium bluelyle.fletcher sport Water polo 1385366732 41.8847082.113619karla.evans sport Rowing 1373036481 41.7203762.935336roman.garza group medium bluebradley.ball sport Water polo 1341530737 41.5606172.605116pablo.myers sport Jumping 1352117759 41.9642252.377526greg.elliott sport Volleyball? 1361744929 42.1530572.493464sandy.silva sport Judo 1365447441 41.4564302.340890devin.hardy sport Fencing 1343737817 41.9104212.749560ben.bowman sport Trampoline 1336532092 42.2733053.000000
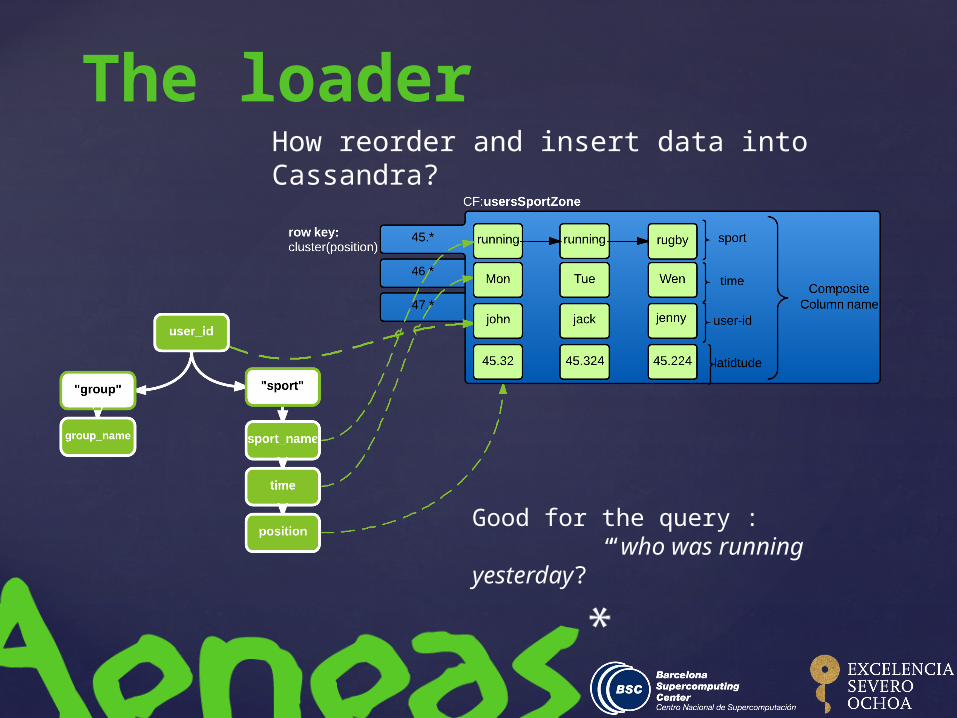
How reorder and insert data into Cassandra?
The loader
Good for the query : “who was running
yesterday?”
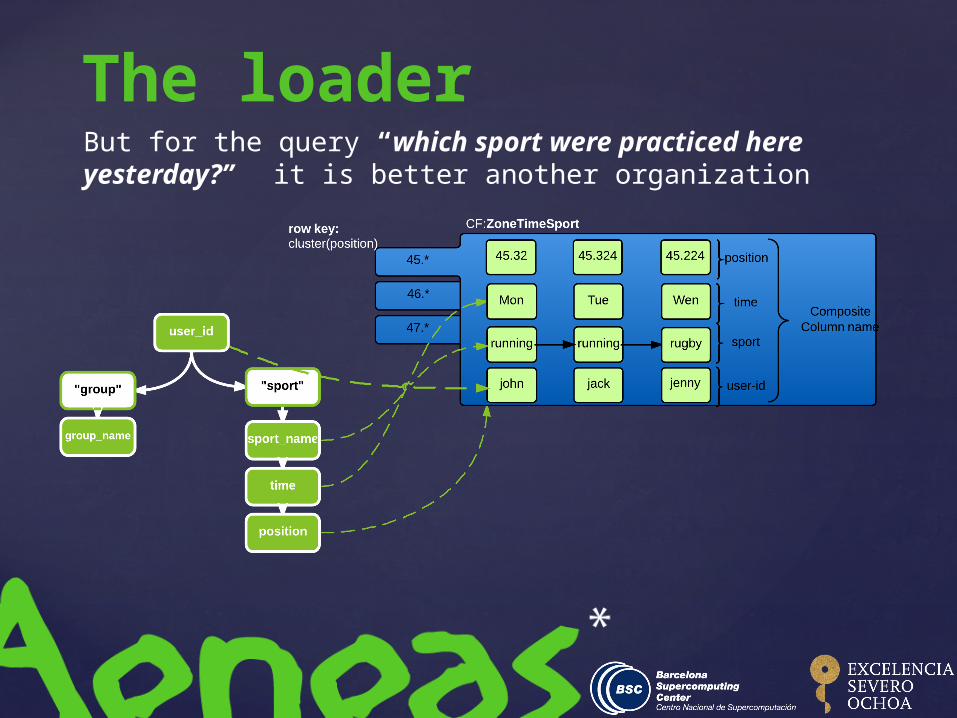
But for the query “which sport were practiced here yesterday?” it is better another organization
The loader

A model may work poorly with a some type of workloads:
requests distribution
If 90% of your clients just practice soccer, does you model scale?

The workloader allows you to define the type of distribution for each argument of the query
Workloader
Who were running here yesterday?
There are sports more practiced then others?
Get user where sport=? andposition=? andday(time)=?
The placed some place more probable for some sports?
Does people make more sports on Saturdays?

You have a cluster of N database servers plus C clients and you need information about the internal metrics of the database, of the java virtual machine, of the load of the operative system, the network traffic load…
…..then collect all them and compare them by time.
The analysis reporter
And, last but not least, you do not know exactly what are you looking for!
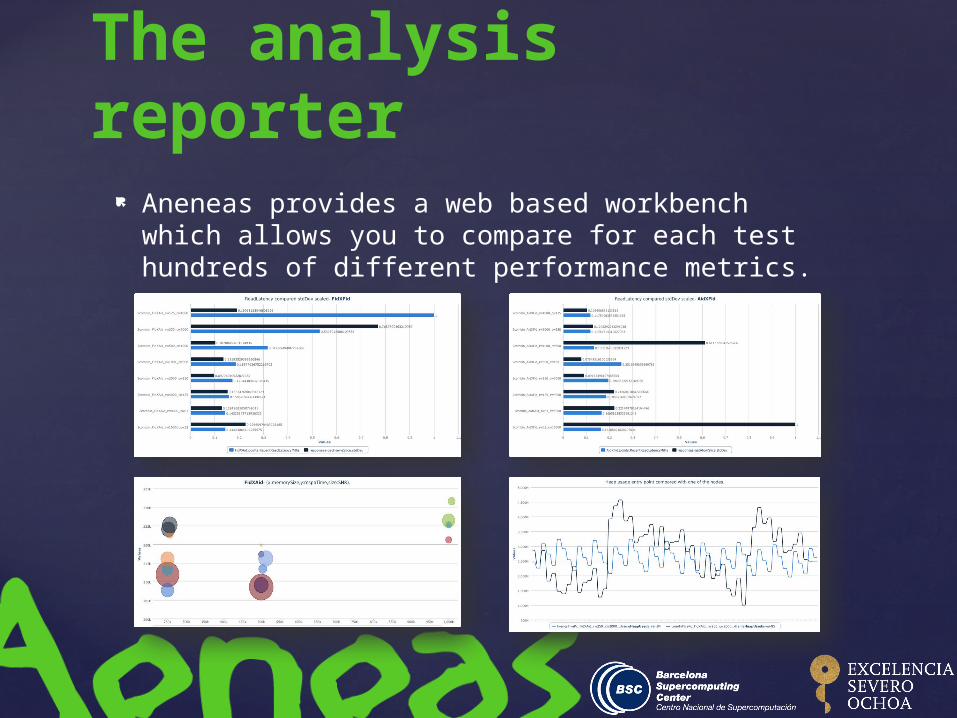
Aneneas provides a web based workbench which allows you to compare for each test hundreds of different performance metrics.
The analysis reporter

That’s all Folks!





























