Embed Size (px)
Citation preview

Active Object Localization with Deep Reinforcement Learning
Juan C. Caicedo & Svetlana Lazebnik (ICCV 2015)
Slides by Miriam Bellver, from the Computer Vision Reading Group. (16/02/2016)https://imatge.upc.edu/web/teaching/computer-vision-reading-group
[Paper] [Reddit] [Slides by Jiren Jin]

IntroductionGoal: Localizing Objects in scenes
Efficient Strategy
Visual attention model
Active detection model: Uses an ‘agent’ to identify the correct locations
Class specific

Introduction
“The agent learns to deform a bounding box using simple transformation actions, with the goal of determining the most specific location of target objects
following a top-down reasoning”
The agent is trained using Deep reinforcement learning

ModelTop-down search strategy
whole scene
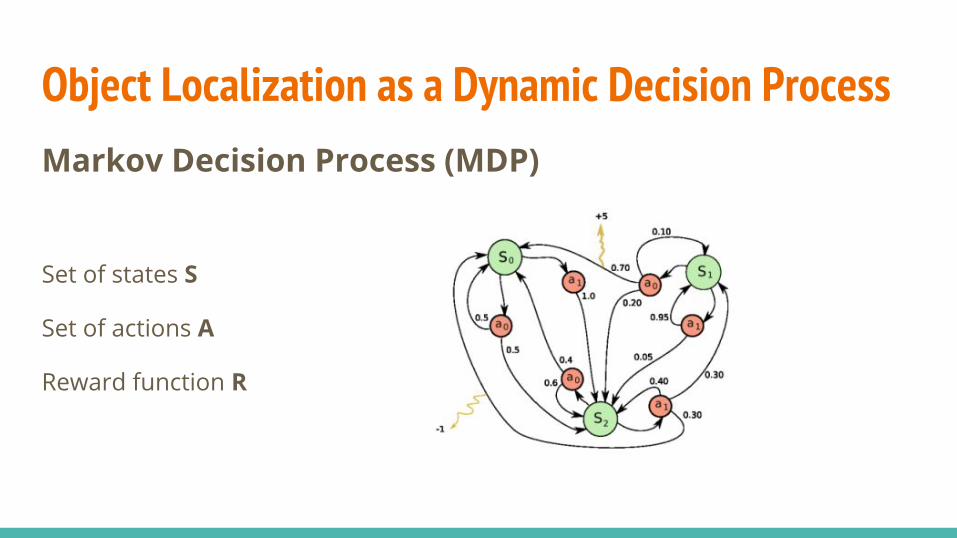
Object Localization as a Dynamic Decision ProcessMarkov Decision Process (MDP)
Set of states S
Set of actions A
Reward function R
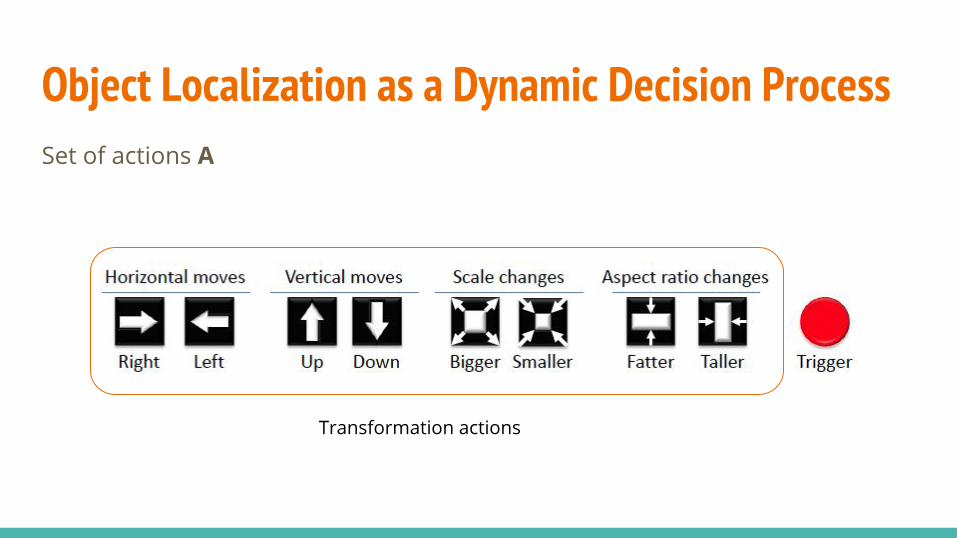
Object Localization as a Dynamic Decision ProcessSet of actions A
Transformation actions

Object Localization as a Dynamic Decision ProcessSet of actions A
Terminates the sequence of the current search
Marks the region, inhibition-of-return (IoR)

Object Localization as a Dynamic Decision ProcessSet of states S
(o,h)
o = feature vector from pre-trained CNN fc6 : 4096 dim
h = history of taken actions binary vector dim 90

Object Localization as a Dynamic Decision ProcessReward Function R
ground-truthbounding box

Object Localization as a Dynamic Decision ProcessReward Function R for trigger action
The Reward function considers the number of steps as a cost
3
minimum IoU:0.6

Localization Policy with Reinforcement LearningPolicy function
If the current state is S, which should be the next action A?
Reinforcement Learning using a Q-learning

Localization Policy with Reinforcement LearningThe action-value function is estimated using a neural network that:
● has as many output units as actions● the algorithm incorporates a replay-memory to collect experiences● category-specific Q-network
Policy of the agent: selection action A with maximum estimated value of the learnt action-value function.
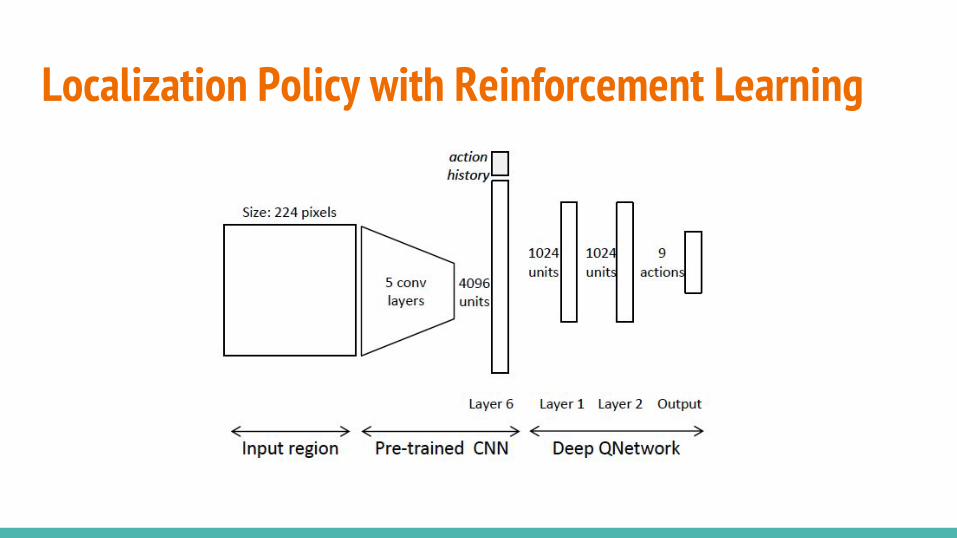
Localization Policy with Reinforcement Learning
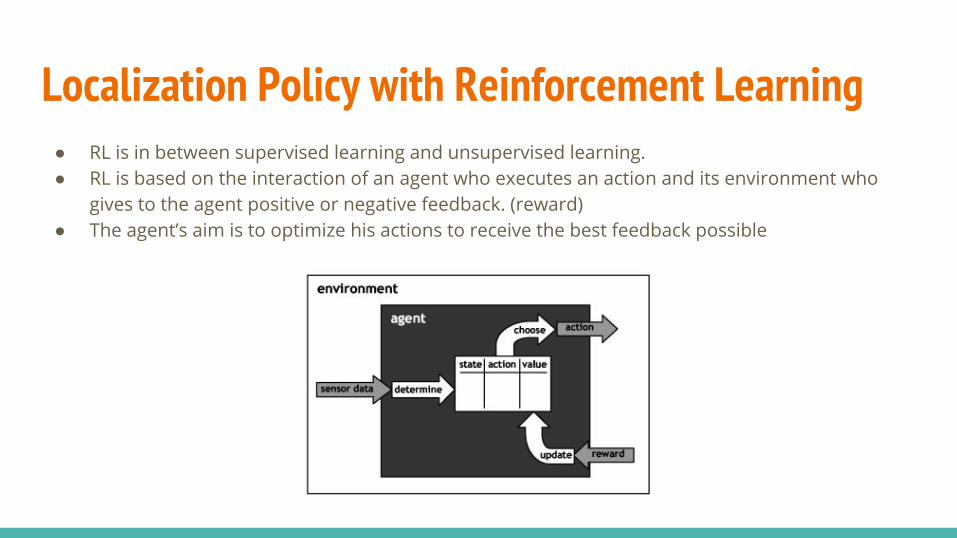
Localization Policy with Reinforcement Learning● RL is in between supervised learning and unsupervised learning.● RL is based on the interaction of an agent who executes an action and its environment who
gives to the agent positive or negative feedback. (reward)● The agent’s aim is to optimize his actions to receive the best feedback possible

Localization Policy with Reinforcement LearningTraining Localization Agents
● Q-network parameters initialized at random.● Policy used during training:
● 15 epochs, and parameters updated using stochastic gradient descent and backpropagation.
exploration exploitation
random actions to gather
experiences
selected actions according policy
learnt, and learns from the results

Localization Policy with Reinforcement LearningTesting a Localization Agent
● The agent runs for max. 200 steps● When trigger is used, the search for other object continues● After 40 steps without triggering ---> object not found

Experiments and ResultsDatasets for training and testing : PASCAL VOC
Two modes of evaluation:
1) All attended Regions (AAR)2) Terminal regions (TR)

Experiments and Results
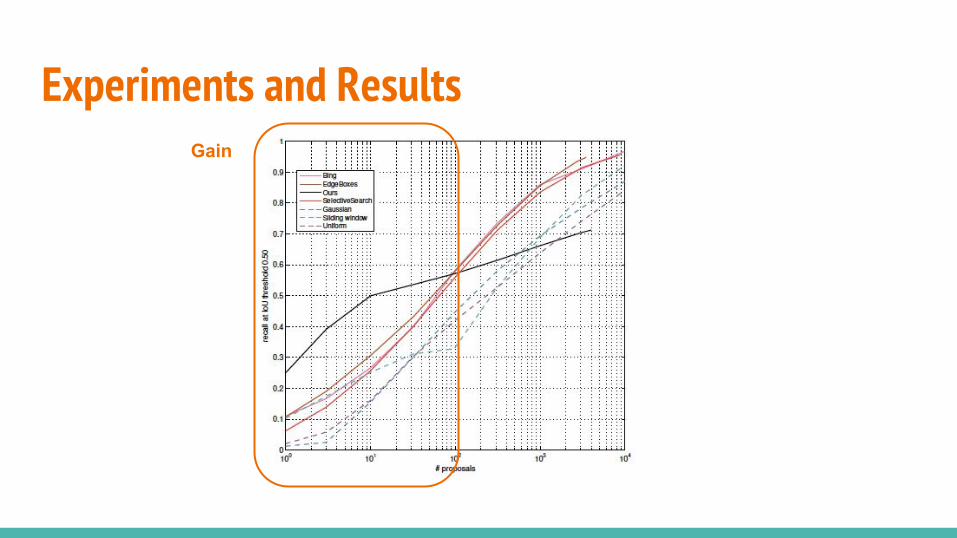
Experiments and ResultsGain
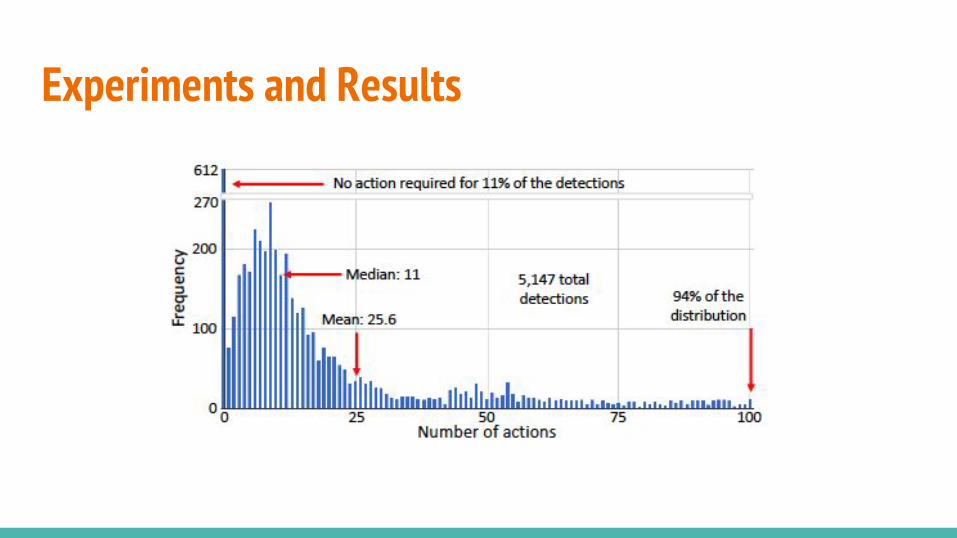
Experiments and Results

Experiments and Results
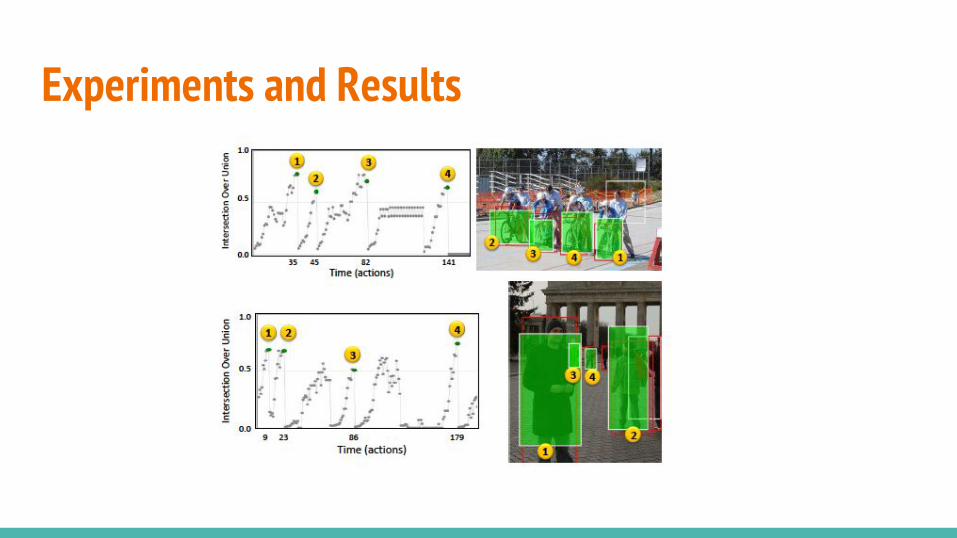
Experiments and Results

ConclusionsSystem localizes objects using an attention-action strategy
Reinforcement learning demonstrated to be efficient strategy to learn a localization policy.
The system can localize a single instance of an object processing between 11 and 25 regions only, so it is a very efficient strategy
Runtime detail: If we run 200 steps per image, 1.54s is average time/image

The EndThank you!




























