Embed Size (px)
Citation preview

NoSQL: Capacity Planning
Senior Solutions Architect, MongoDB Inc.
Asya Kamsky
#MongoDB #CMGNews

No SQL?

Some History
• 1970's Relational Databases Invented – Storage is expensive – Data is normalized – Data is abstracted away from app

Some History
• 1970's Relational Databases Invented – Storage is expensive – Data is normalized – Data is abstracted away from app
• 1980's RDBMS commercialized – Client/Server model – SQL becomes the standard
Some History
• 1970's Relational Databases Invented – Storage is expensive – Data is normalized – Data storage is abstracted away from app
• 1980's RDBMS commercialized – Client/Server model – SQL becomes the standard
• 1990's Things begin to change – Client/Server=> 3-tier architecture – Internet and the Web
Some History
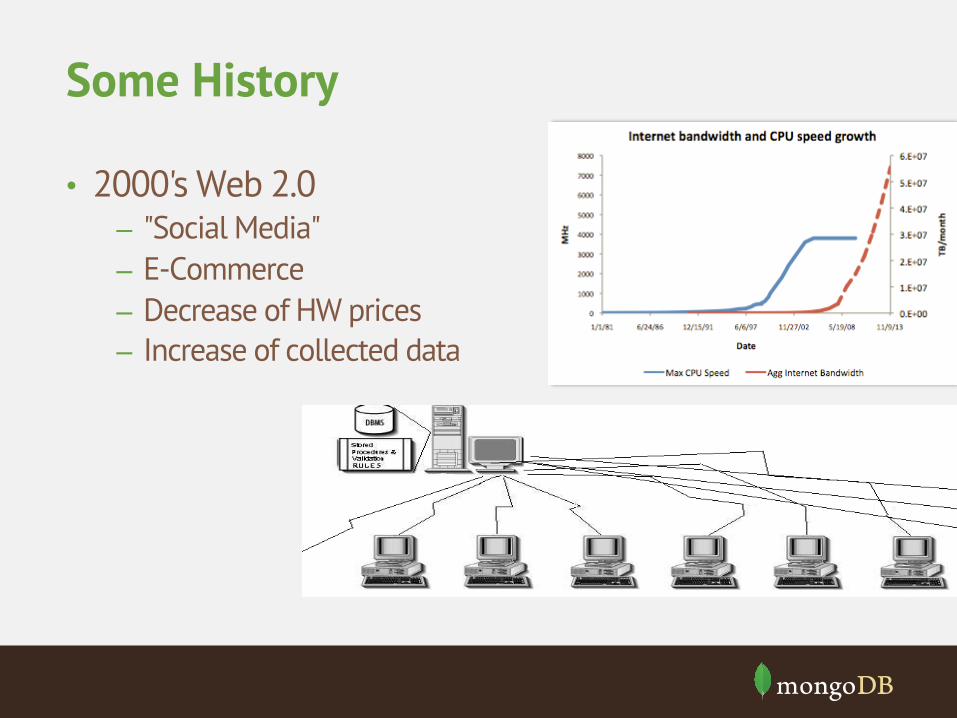
• 2000's Web 2.0 – "Social Media" – E-Commerce – Decrease of HW prices – Increase of collected data
Some History
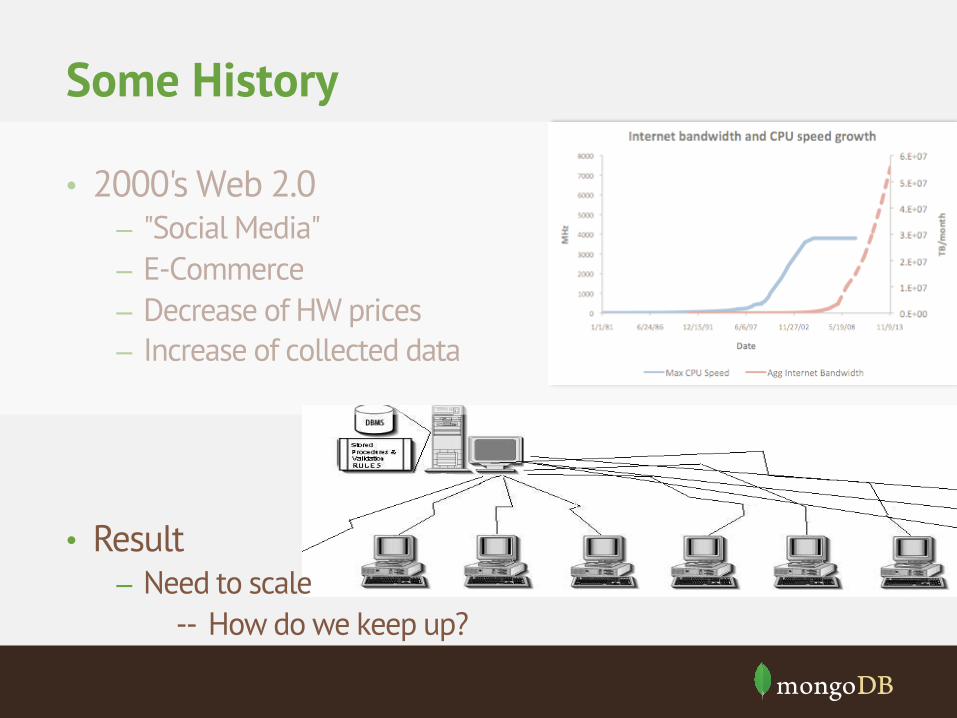
• 2000's Web 2.0 – "Social Media" – E-Commerce – Decrease of HW prices – Increase of collected data
• Result – Need to scale -- How do we keep up?
Developers
• Agile Development Methodology – Shorter development cycles – Constant evolution of requirements – Flexibility at design time
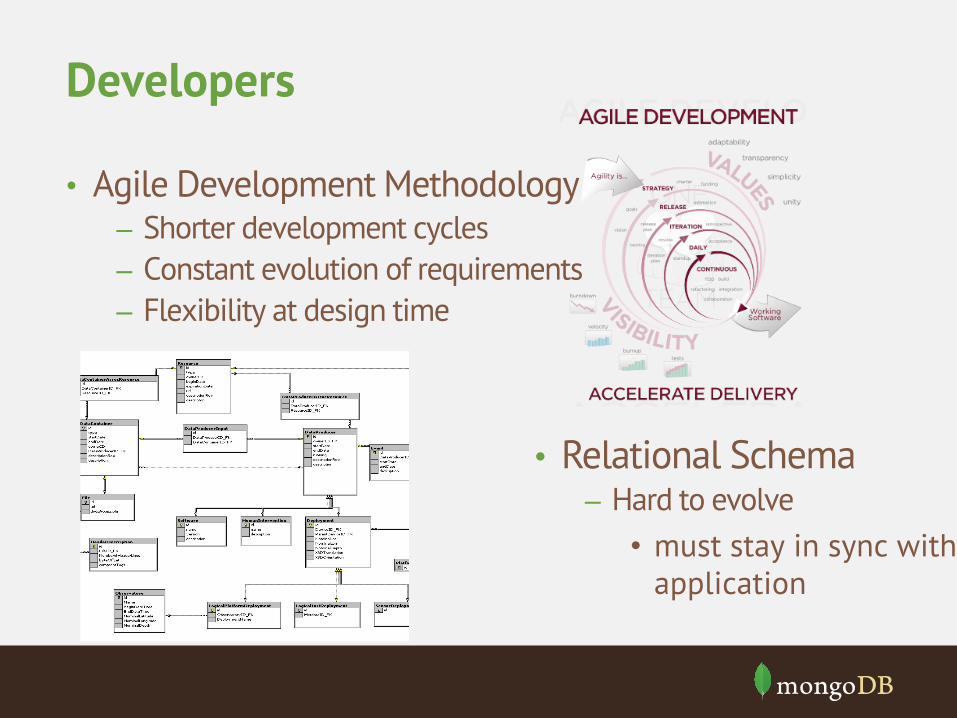
Developers
• Agile Development Methodology – Shorter development cycles – Constant evolution of requirements – Flexibility at design time
• Relational Schema – Hard to evolve
• must stay in sync with application
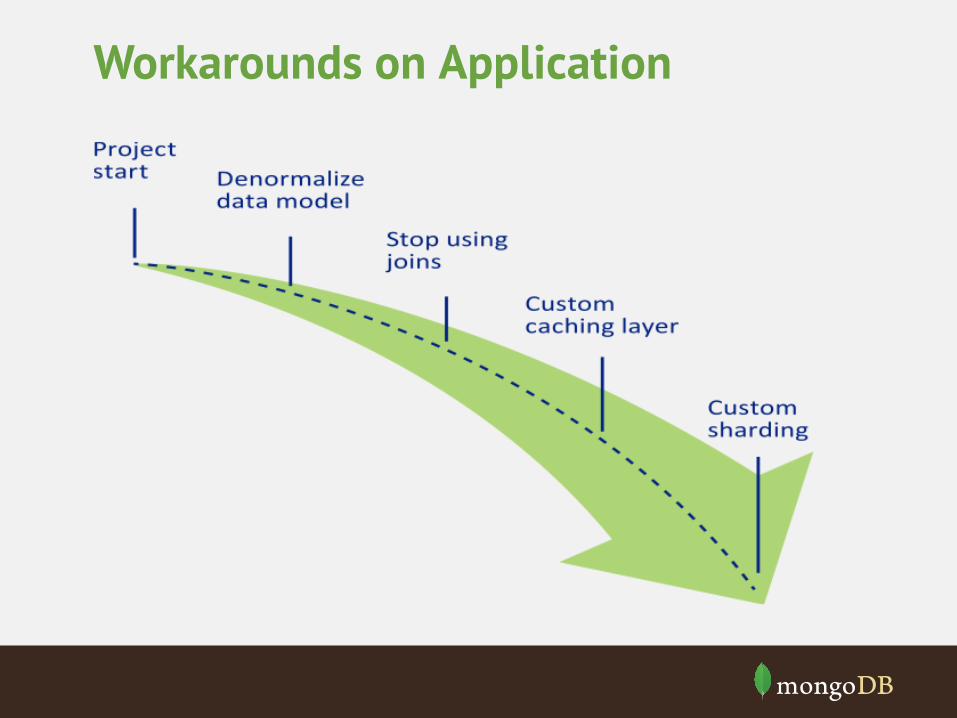
Workarounds on Application

• Relational
• ACID
• Two-phase commit
• Joins
• Key-Value Graph XML
Document Column
• BASE
• ACID on document level
• No Joins
NoSQL vs Relational

NoSQL Examples

NoSQL Examples
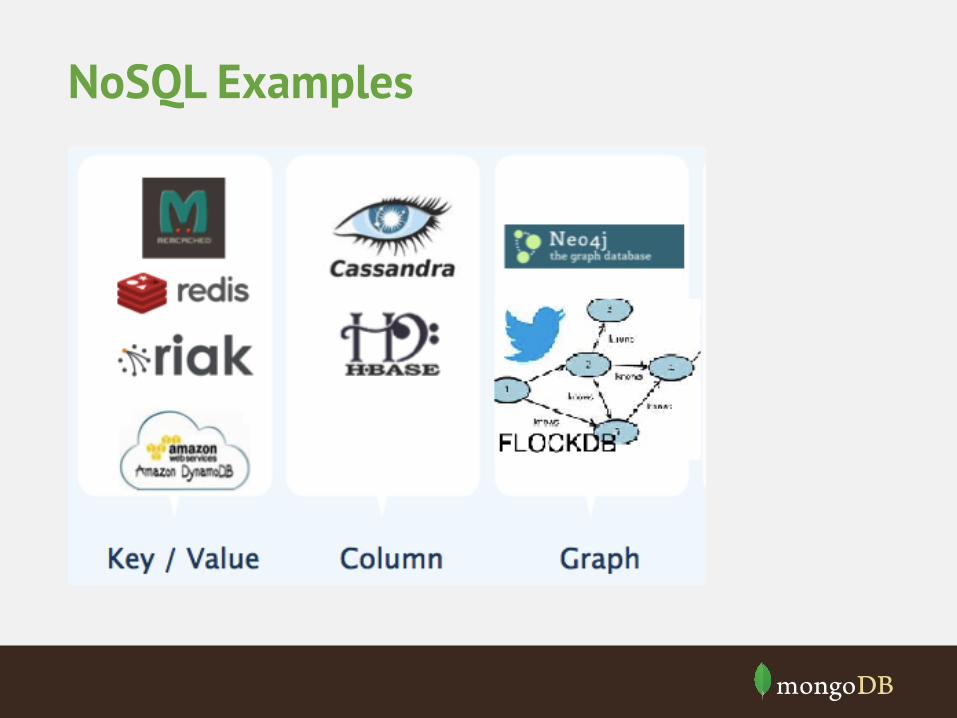
NoSQL Examples
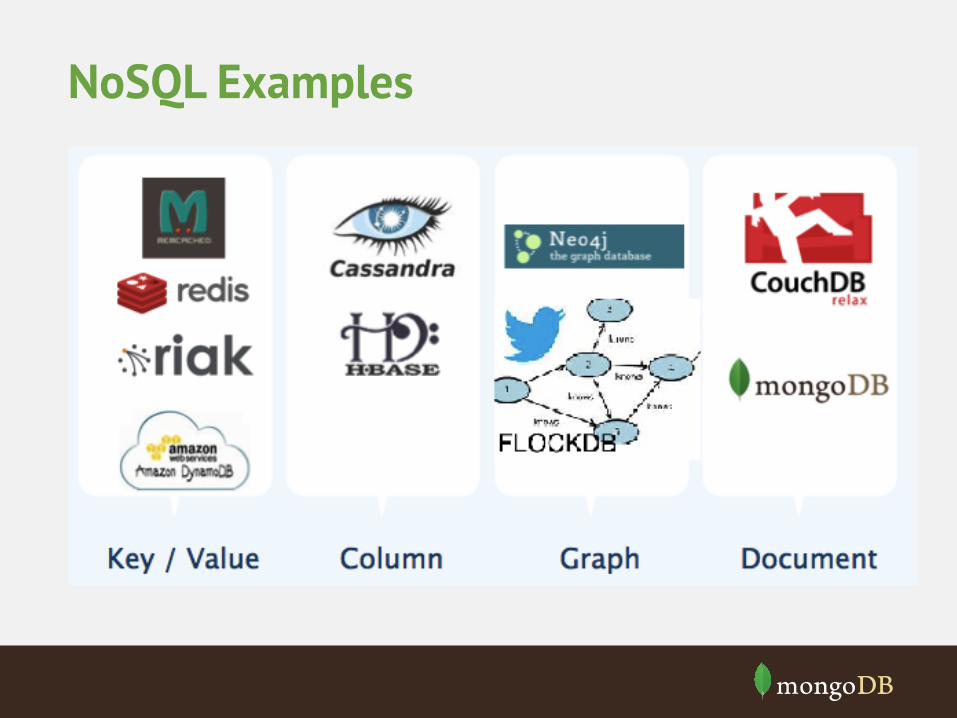
NoSQL Examples

All Different
NoSQL != RDBMS
MongoDB != Cassandra != Neo4j != Redis != Riak != CouchDB != Couchbase

MongoDB

MongoDB History • Designed/developed by founders of Doubleclick, ShopWiki, GILT
groupe, etc.
• First production site March 2008 - businessinsider.com
• Open Source – AGPL, written in C++
• Version 0.8 – first official release February 2009
• Version 2.4 – March 2013
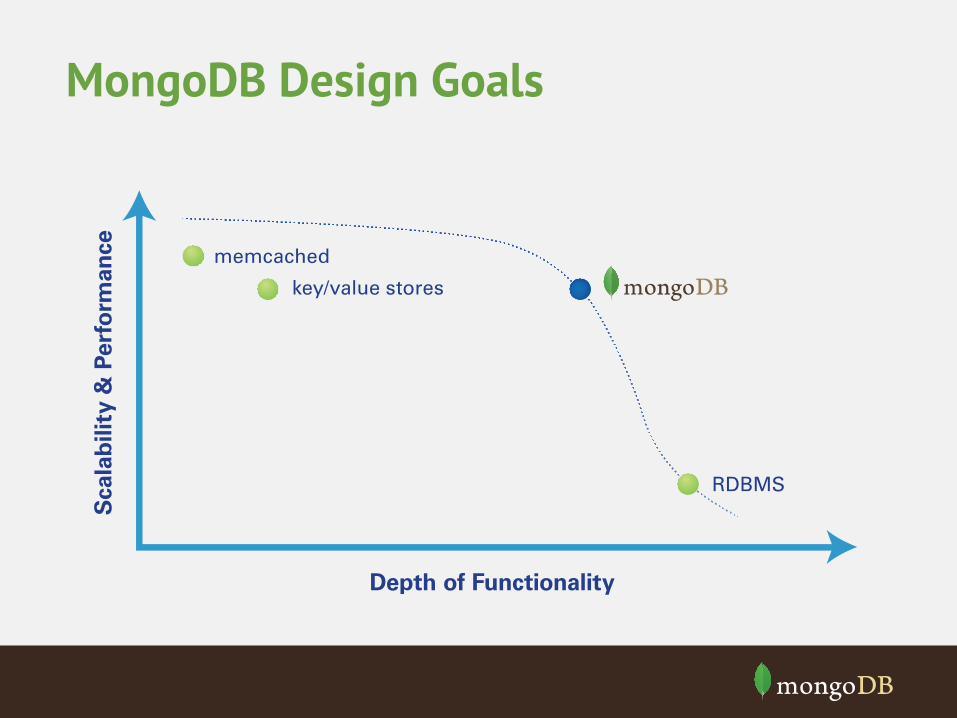
MongoDB Design Goals
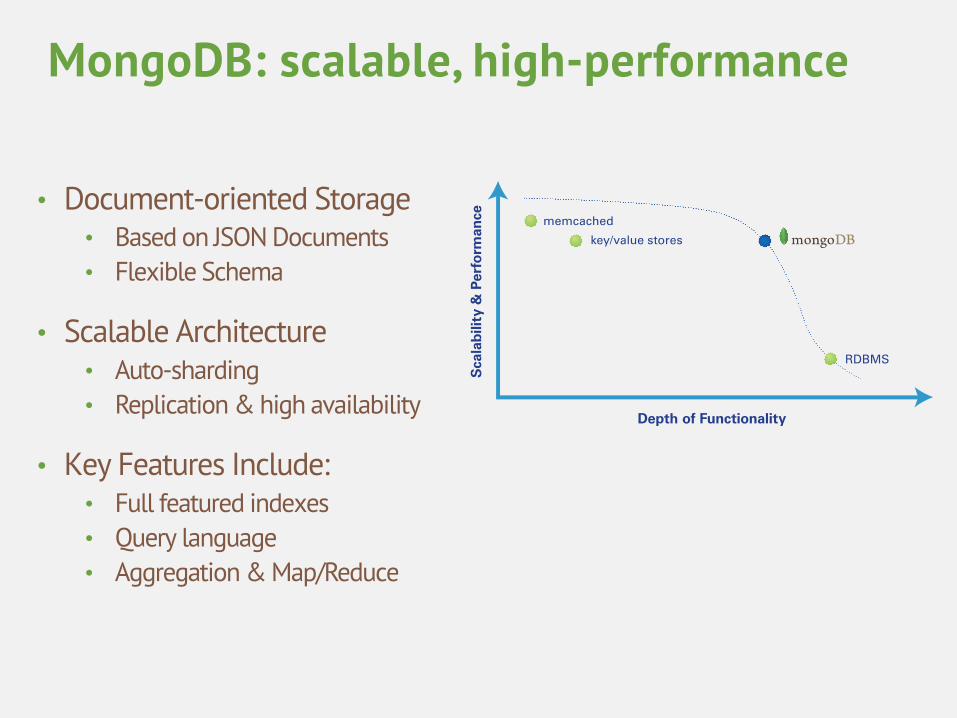
• Document-oriented Storage • Based on JSON Documents • Flexible Schema
• Scalable Architecture • Auto-sharding • Replication & high availability
• Key Features Include: • Full featured indexes • Query language • Aggregation & Map/Reduce
MongoDB: scalable, high-performance

MongoDB Performance
Just like all other systems, w/o understanding what their strengths and weaknesses are, it is easy to build a bad system.

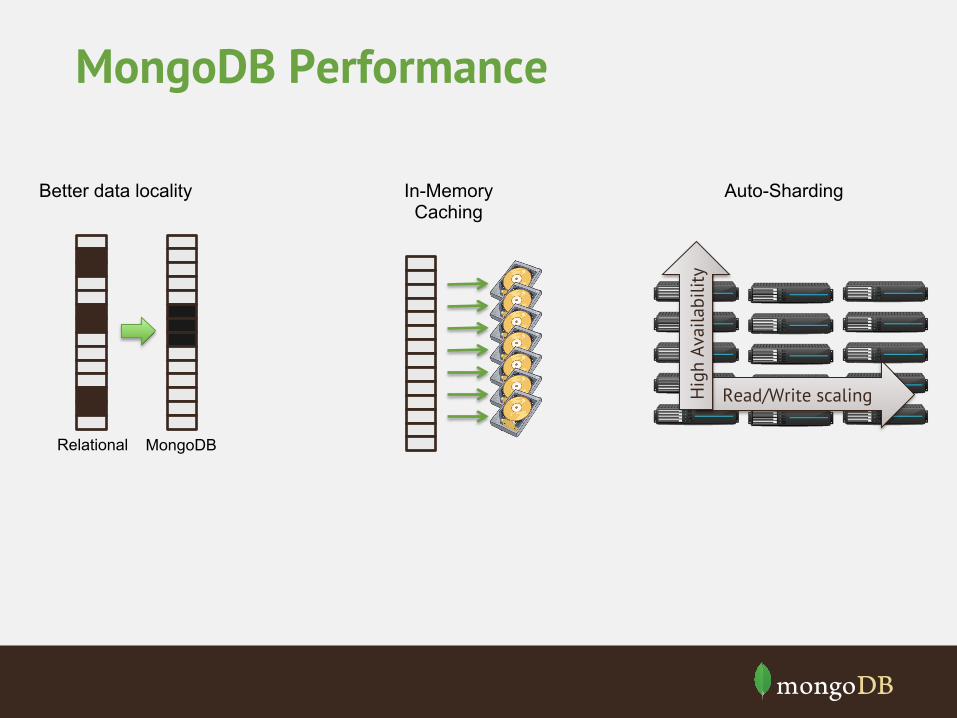
Better data locality
Relational MongoDB
MongoDB Performance

Better Data Locality
• Data model means "entities" can reside "together"
• Optimize schema for read and write access patterns
• Minimize "seeks" as they dominate IO slowdown
• Failure to take advantage of document model: – no improved performance – all the disadvantages with non of the advantages! – incorrect model can overshoot "all data embedded"

Better data locality
Relational MongoDB
In-Memory Caching
MongoDB Performance

In-memory Caching
• memory mapped files,
• caching handled by OS,
• naturally leaves most frequently accessed data in RAM
• have enough RAM to fit indexes and working data set for best performance
Better data locality
Relational MongoDB
In-Memory Caching
Auto-Sharding
Read/Write scaling Hig
h Av
aila
bilit
y
MongoDB Performance

Auto-Sharding
• horizontal scaling is "built-in" to the product
• Replication is for HA
• Sharding is for scaling
• Number of servers in replica set based on HA requirements
• Number of shards is based on capacity needed vs. single server/replicaset capacity
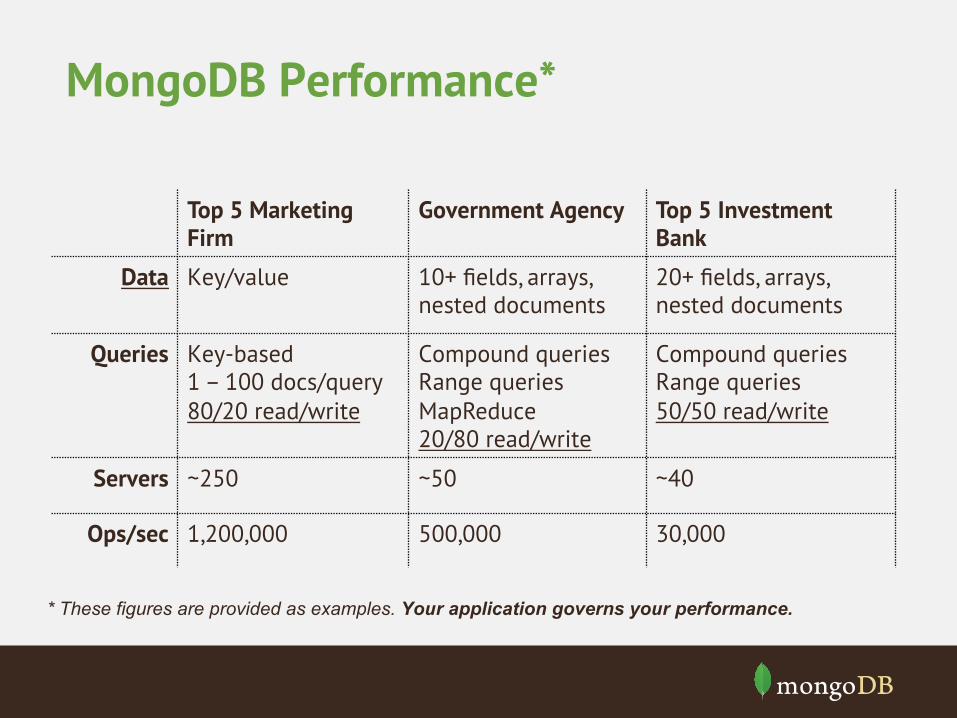
MongoDB Performance*
Top 5 Marketing Firm
Government Agency Top 5 Investment Bank
Data Key/value 10+ fields, arrays, nested documents
20+ fields, arrays, nested documents
Queries Key-based 1 – 100 docs/query 80/20 read/write
Compound queries Range queries MapReduce 20/80 read/write
Compound queries Range queries 50/50 read/write
Servers ~250 ~50 ~40
Ops/sec 1,200,000 500,000 30,000
* These figures are provided as examples. Your application governs your performance.

Key Performance Considerations
Capacity Planning
Performance Tuning

Capacity Planning: Why, What, When
Consequences of not planning?
Why?

Capacity Planning: Why, What, When

Capacity Planning: Why, What, When
Requirements What?

What
• There is one thing that is absolutely mandatory to have in order to succeed in capacity planning
• Without it, you will not be successful
• We must have REQUIREMENTS from business – without requirements, we're building a roadmap without
knowing the desired destination Imagine building a car without knowing what its top speed should be, acceleration, MPH, and cost?

Capacity Planning: Why, What, When
• Availability
• Throughput
• Responsiveness
What?

• Availability: what is uptime requirement?
• Throughput – average read/write/users – peak throughput? – OPS (operations per second)? per hour? per day?
• Responsiveness – what is acceptable latency? – is higher during peak times acceptable?
What

Capacity Planning: Why, What, When
What?
• Availability
• Throughput
• Responsiveness
Capacity Planning: Why, What, When
• Before it's too late!
When?
Start Launch Version 2

• At the beginning before production, but after you launch you must continue the process
• Lack of future planning: Failure to project performance drop-off as the amount of data increases –
• Process (steps): -> ACTIONS – Requirements ask, guess, try/measure. – Understand application needs – Choose hardware to meet that pattern (...) – How many machines you need – Monitor to recognize growth exceeding current capacity.
When
Capacity Planning: What?
Understand Resources
– Storage – Memory – CPU – Network
• Understand Your Application – Monitor and Collect Metrics – Model to Predict Change – Allocate and Deploy – (repeat process)
Resource Usage
Storage
– IOPS – Size – Data & Loading Patterns
Memory
– Working Set
CPU
– Speed – Cores
Network
– Latency – Throughput
Storage
• Active • Archival • Loading Patterns • Integration (BI/DW)

Storage Capability
Example IOPS 7,200 rpm SATA ~ 75-100 IOPS
15,000 rpm SAS ~ 175-210 IOPS
Amazon EBS/Provisioned ~ 100 IOPS "up to" 2,000 IOPS
Amazon SSD 9,000 – 120,000 IOPS Intel X25-E (SLC) ~ 5,000 IOPS
Fusion IO ~ 135,000 IOPS
Violin Memory 6000 ~ 1,000,000 IOPS

Storage
Measuring and Monitoring
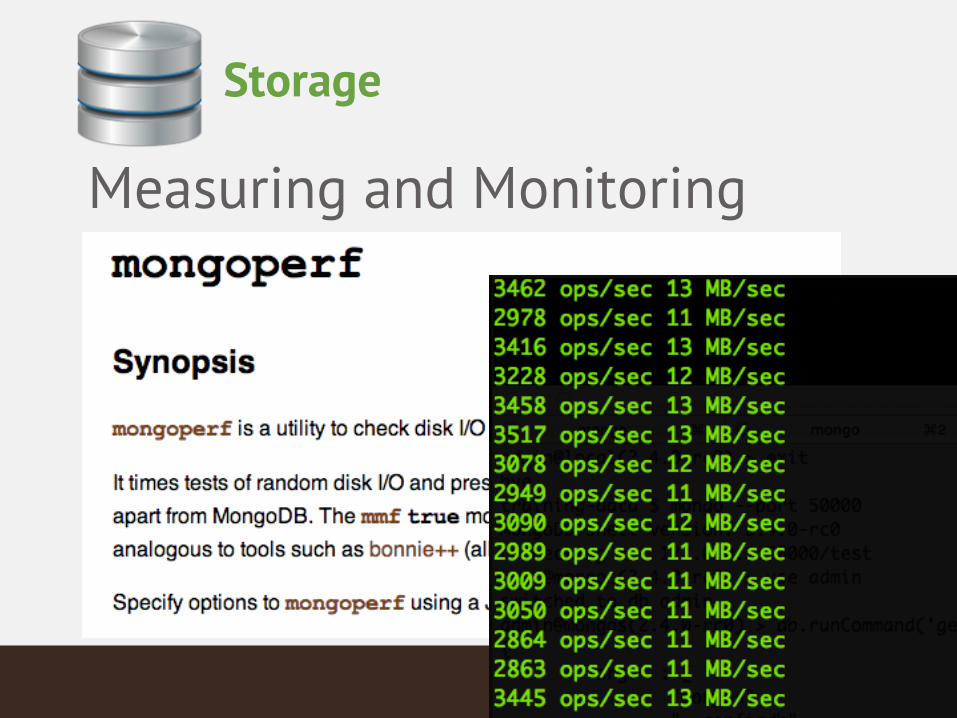
Storage
Measuring and Monitoring
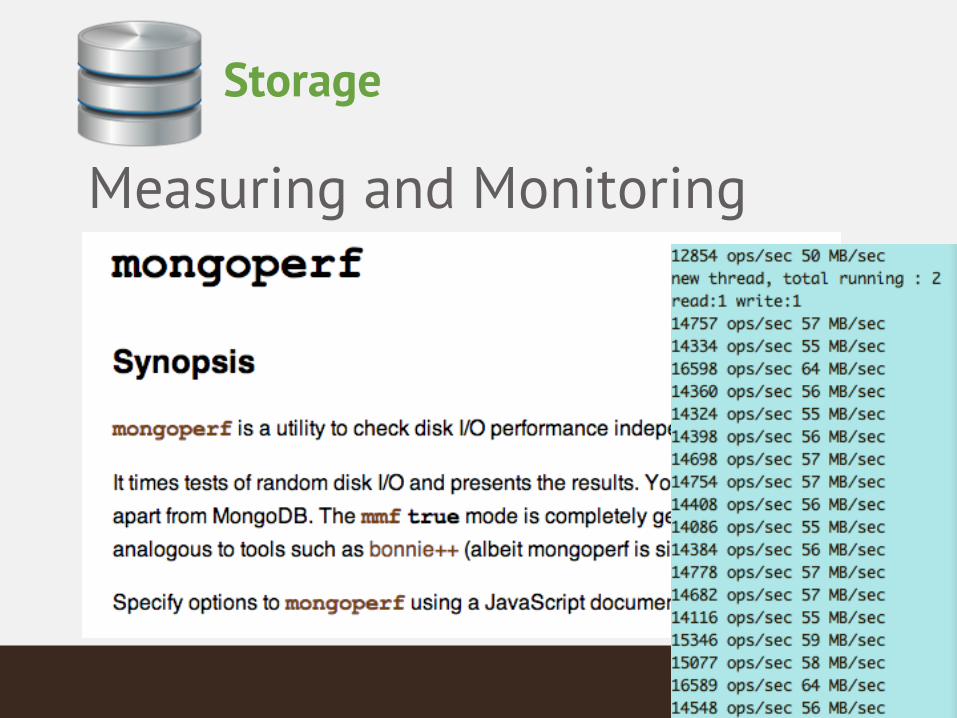
Storage
Measuring and Monitoring

Memory
Working Set – Active Data in Memory – Measured Over Periods

Memory
Work:
– Sorting – Aggregation – Connections
Memory
Work:
– Sorting – Aggregation – Connections
SORTS
Connections
Aggregations

Memory
New in 2.4 – workingSet option on db.serverStatus() db.serverStatus( { workingSet: 1 } )
Measuring and Monitoring

Memory & Storage
> < ?

Memory & Storage
MOPS: MongoDB Ops/sec
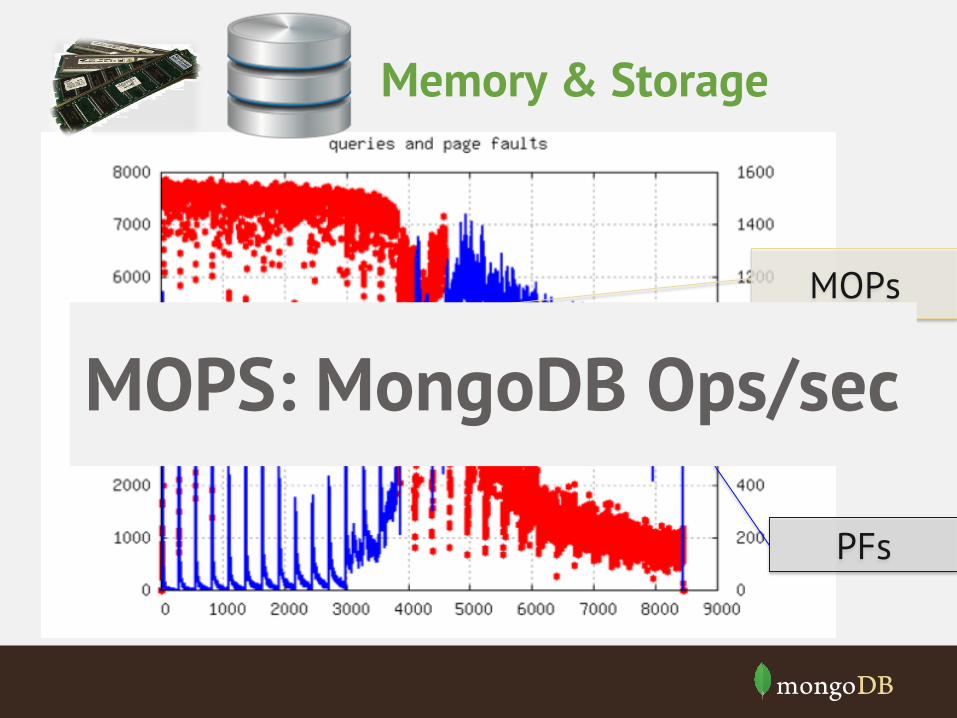
Memory & Storage
MOPs
PFs
MOPS: MongoDB Ops/sec
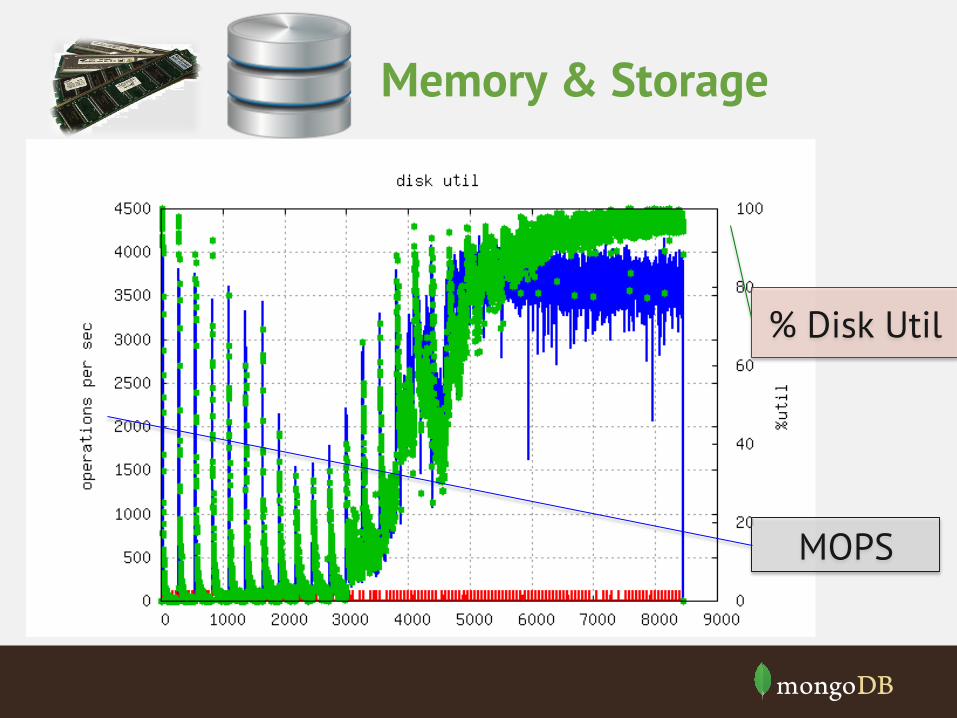
Memory & Storage
% Disk Util
MOPS
Non-indexed Data
Sorting
Aggregation
– Map/Reduce – Framework
Data
– Fields – Nesting – Arrays/Embedded-Docs
CPU
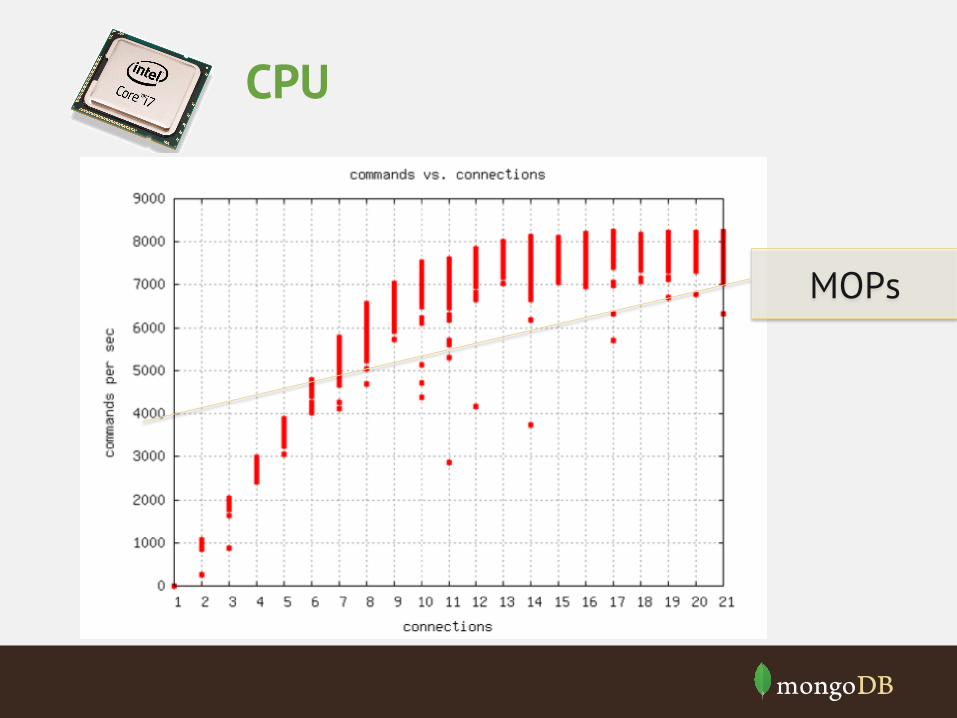
CPU
MOPs
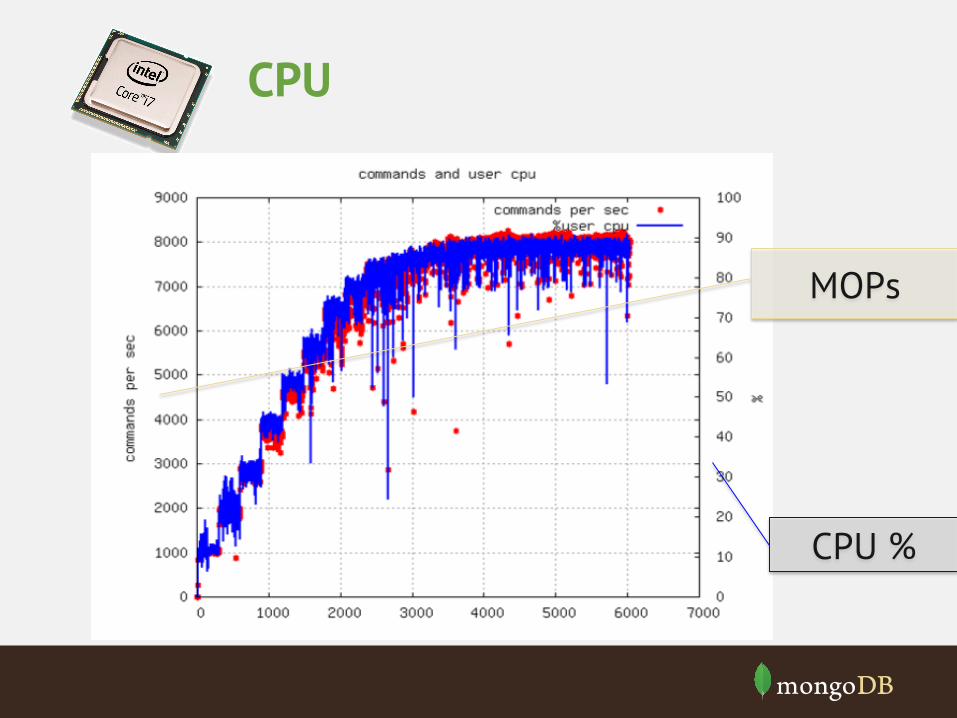
CPU
MOPs
CPU %

Network
Latency
– WriteConcern – ReadPreference – Batching – Documents (and Collections)
Throughput
– Update/Write Patterns – Reads/Queries

Starter Questions
What is the working set?
– How does that equate to memory – How much disk access will that require
How efficient are the queries?
What is the rate of data change?
How big are the highs and lows?

Deployment Types
All of these use the same resources:
• Single Instance
• Multiple Instances (Replica Set)
• Cluster (Sharding)
• Data Centers

Capacity Planning: Monitoring
Monitor § Storage § Memory § CPU § Network § Application Metrics

Monitoring
• CLI and internal status commands • mongostat; mongotop; db.serverStatus()
• Plug-ins for munin, Nagios, cacti, etc.
• Integration via SNMP to other tools
• MMS
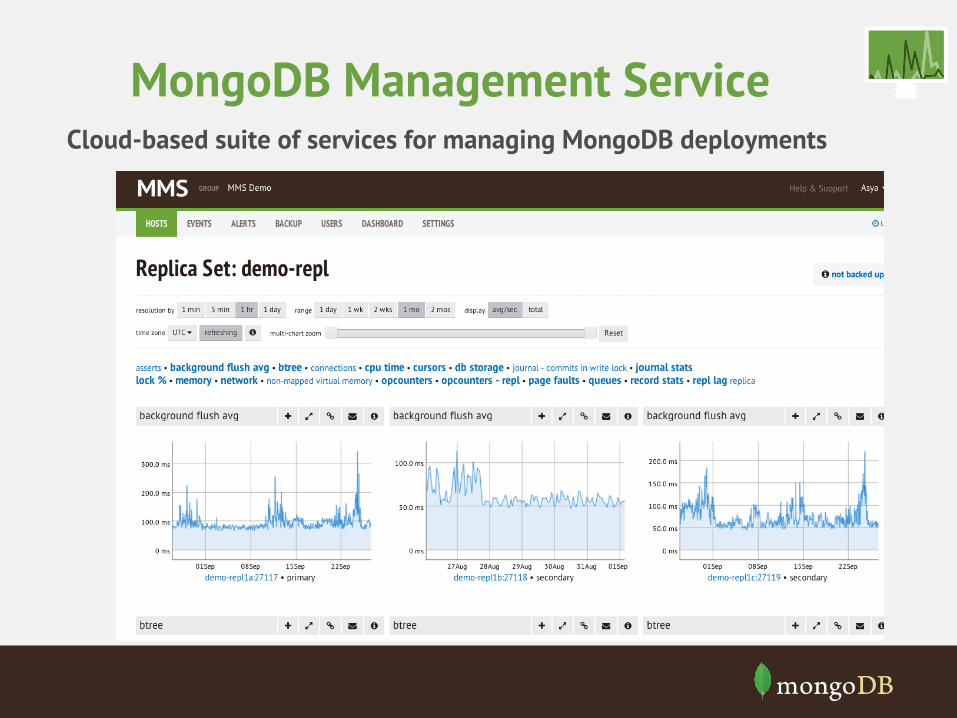
MongoDB Management Service Cloud-based suite of services for managing MongoDB deployments
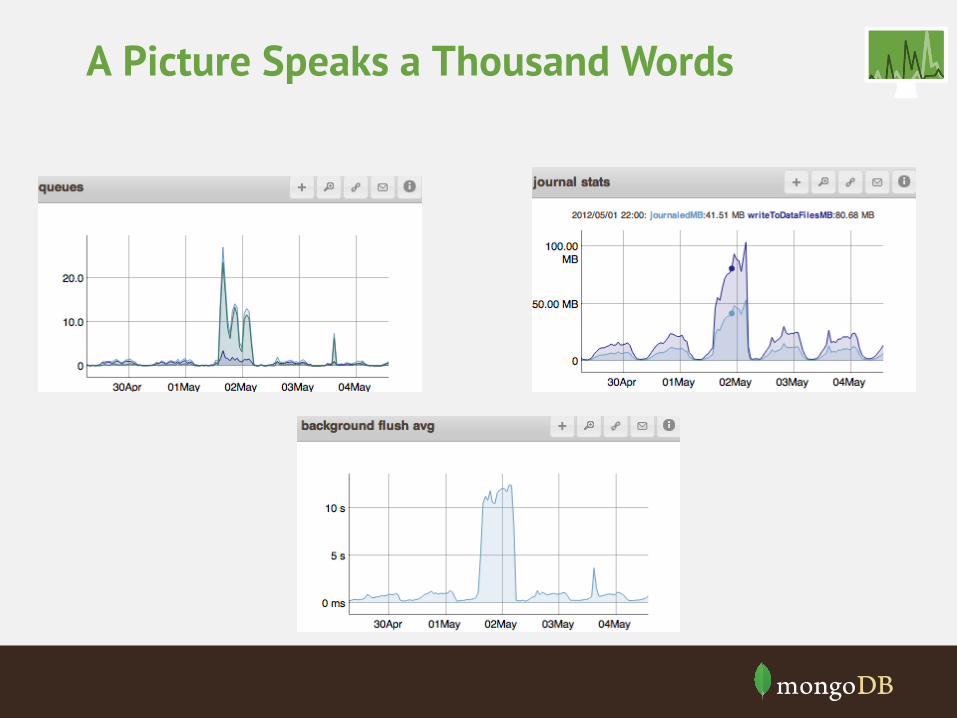
A Picture Speaks a Thousand Words
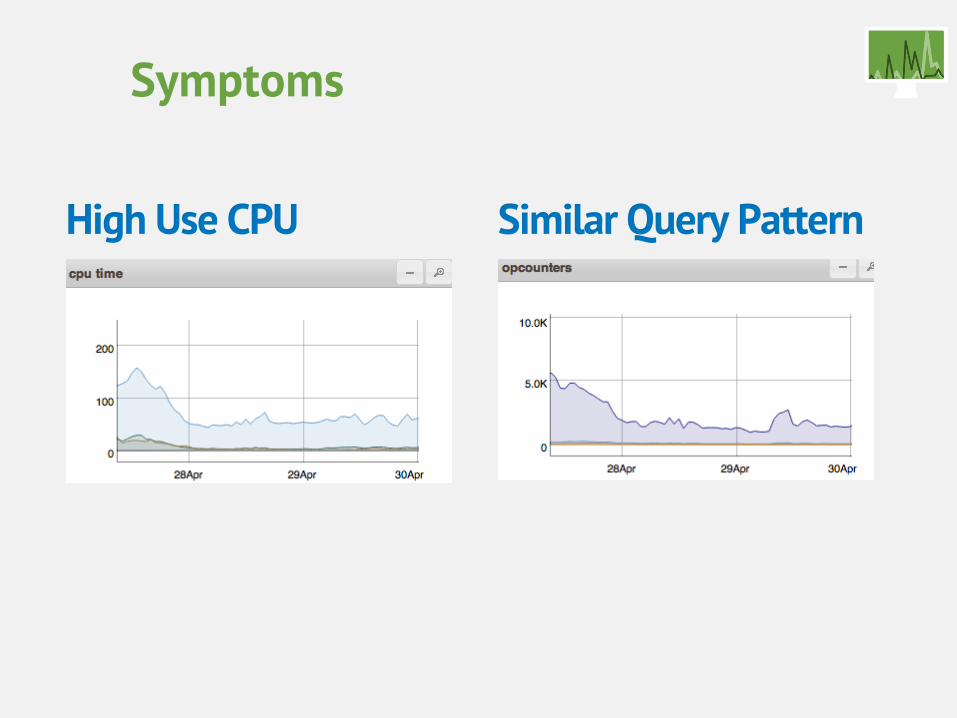
Symptoms
High Use CPU Similar Query Pattern

Monitoring Best Practices
• Monitor Logs – Alert, escalate – Correlate
• Disk – Monitor
• Instrument/Monitor App (including logs!) • Know your application and application (write)
characteristics

Models
• Load/Users – Response Time/TTFB
• System Performance – Peak Usage – Min/avg Usage

Velocity of Change
• Limitations -> takes time – Data Movement – Allocation/Provisioning (servers/mem/disk)
• Improvement – Limit Size of Change (if you can) – Increase Frequency – MEASURE its effect – Practice

Repeat (continuously)
Repeat Testing
Repeat Evaluations
Repeat Deployment
Thank You
Senior Solutions Architect, MongoDB
Asya Kamsky
#MongoDB





























