Embed Size (px)
Citation preview

1

I’d just built an Apex application, and was happy to see it get through dev and test without any major issues. It was deployed into UAT and we started giving demos to users. One user opened up the application, logged in, and we showed them around. At one point, I noticed that the “Admin” tab was visible. It shouldn’t have been. I asked the user to hit the Refresh button, and the tab disappeared. “Well, that’s a bit odd,” I thought to myself. I had personally written every line of code for this application and knew that the “Admin” tab’s visibility was controlled by an Authorization Scheme that queried the Users table to check if they had the “Administrator” role. That tab shouldn’t just appear and disappear. I assumed at the time that another user was playing with the security admin interface, and that this user just happened to get the Administrator role temporarily.
2

A little later, we got a bug report. The Submit button on a particular page had disappeared. I logged into UAT and checked – no the button was there. I rang the user who had been testing, and asked them to refresh the page. “Thanks, you fixed it!” I hadn’t done anything. At this point I started suspecting my security checking code, because I knew that Submit button had a condition on it that was controlled by another Authorization Scheme that was based on the Users table.
3

So now I had seen two cases where the security checking appeared to sporadically fail to correctly check a user’s authorization. I decided it was high time I investigated this and work out exactly what was going wrong. First thing was to investigate that “Admin” tab. I checked the history of changes to the Users table and noticed that that user had never had Administrator privilege assigned to them – so they should never have been able to see that tab. So I checked the Condition on the tab. It was correctly limited to the Administrator authorization scheme. I checked the Authorization scheme. It correctly called my database function that is supposed to return TRUE if the current user has the specified Role.
4

Here is the function. It looked alright. The query was perfect and should perform well with the unique index on username. It had passed all our tests in our dev and test environments. It seemed to only fail a few times in UAT, so far. I started thinking about the Result Cache that I’d added to this function. I’d only added it so that I’d feel safe calling this function many times over and over again and not have to worry about the query being run too many times during each page request. At the time our dev environment was running Oracle 11gR1 so we had to add the RELIES_ON clause. I took it out, and immediately my regression tests failed. So the RELIES_ON clause was certainly needed and was doing the right thing. Why would the function not return the right results? From my limited understanding at the time, I knew that a result-cached function will return results from the cache if the same parameters have been passed to the function before – and that this works between sessions. That, after all, was the point of using a result cache. Then I started thinking about that v('APP_USER') expression in the query. My first version of this function had accepted the user name as a parameter, but at one stage of development I realised I could simplify the rest of my code by just referring directly to the Apex APP_USER variable.
5

Maybe that was the problem – but why would v(‘APP_USER’) return the wrong username?
5
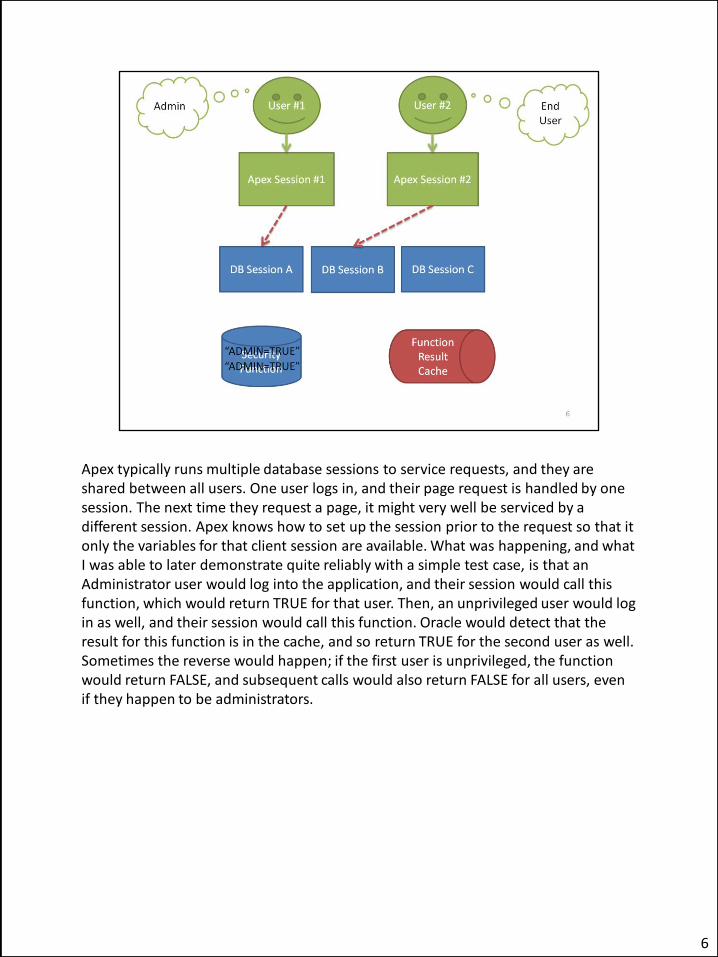
Apex typically runs multiple database sessions to service requests, and they are shared between all users. One user logs in, and their page request is handled by one session. The next time they request a page, it might very well be serviced by a different session. Apex knows how to set up the session prior to the request so that it only the variables for that client session are available. What was happening, and what I was able to later demonstrate quite reliably with a simple test case, is that an Administrator user would log into the application, and their session would call this function, which would return TRUE for that user. Then, an unprivileged user would log in as well, and their session would call this function. Oracle would detect that the result for this function is in the cache, and so return TRUE for the second user as well. Sometimes the reverse would happen; if the first user is unprivileged, the function would return FALSE, and subsequent calls would also return FALSE for all users, even if they happen to be administrators.
6

So, the fix was very simple really. Just add a second parameter, with a default value, that will never be actually used by the function. Because it has a default, I didn’t have to change any other code in my application. Now, when the function is called, the username is also recorded in the result cache; if a different user logs in, the parameters will be different and the correct value will be returned and cached, just for that user.
7

As it turns out, I could have found all this out had I just read the docs. In this context (no pun intended), an Apex variable is very much like an Application Context and the same restrictions apply to it.
8

9

10

These are other things. They are all methods for trading memory for speed.
11

12

Here’s an innocent little function.
13

Base function that does some work. No intrinsic caching. With no other changes, we can expect some benefit from the query and block caching if the function is called more than once. The tables have approx 2K records each and have indexes on the ID columns referenced in this query. The query is pretty much tuned as well as much as is practical while remaining easily read and maintainable.
14

package spec with one function for each test case.
15

This is our run script for the baseline test case. First, we run the function once for each row in the table; then we do it all again.
16

Show our database version, 11gR2
17

First run for the day: 0.57 seconds
18

On the second run, we get 0.24 seconds, most probably due to the SQL cache and block cache. That’s an improvement of 42% already.
19

Home-grown caching solution. We store the results of repeated calls in a PL/SQL array.
20

Manual cache invalidation – we would need to call this from triggers or application code whenever an underlying row changes that might mean the value needs to be re-evaluated.
21

Here’s our script to run the method #1 test case. I’ve removed the “SET TIMING ON/OFF” statements. First, we run the function for each row in the table, and then do it all again, expecting to get a performance boost from our home-grown PL/SQL cache. Then, we mark the cache as invalid (e.g. because we updated all the records in a batch job), and run the test again, expecting the performance to drop as it has to re-evaluate the function for each record.
22

First run, the function has to be called for each record, and as it goes it is caching the results. 0.23 seconds
23

On the second run, our function never needs to be called; our cache is being hit for each record, and the performance benefit is profound: 0.01 seconds, an improvement of 43%.
24

After invalidating the cache, we test that the function is still being called as it should. The run time is 0.22 seconds which is expected.
25

Function that takes advantage of the Oracle 11gR2 function result cache.
26

Function that takes advantage of the Oracle 11gR1 function result cache. Note that RELIES_ON is only in the package body, not the spec. Our test case will not use this version as we’re on 11gR2 which ignores the RELIES_ON clause.
27

Here’s our script to run the final test case. We call our result-cache function once for each record, and then again a second time, expecting a performance benefit. Then, we update each row in the table to simulate the invalidation of the cache; and we run the test again, expecting to see the performance suffer as the function has to be called again for each record.
28

For test measurement purposes we flush the result cache first.
29
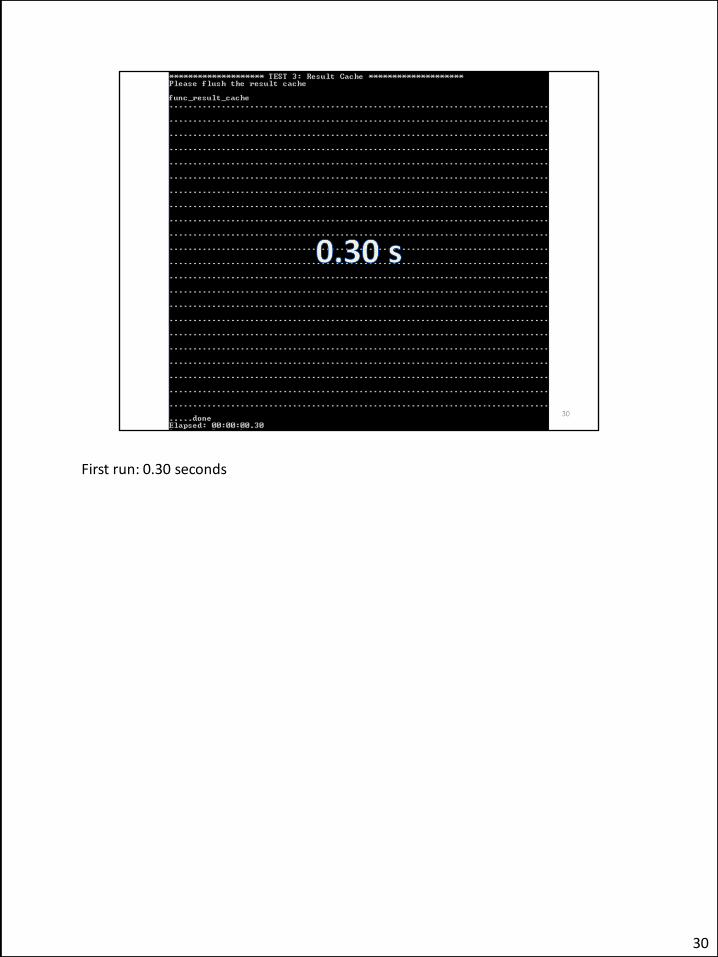
First run: 0.30 seconds
30

Second run: 0.01 seconds, as expected
31
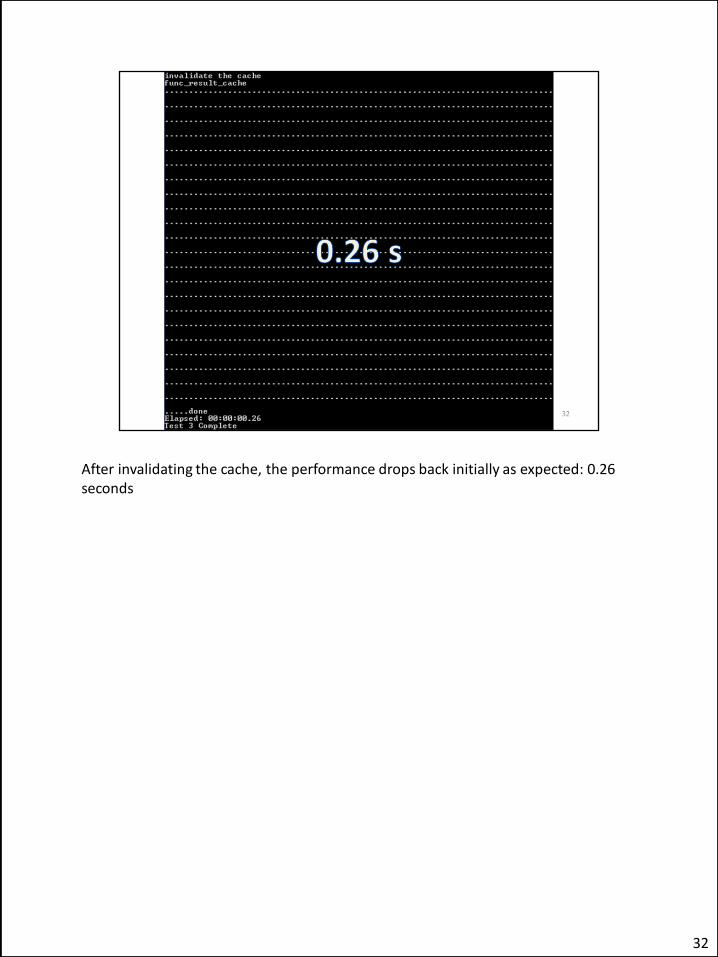
After invalidating the cache, the performance drops back initially as expected: 0.26 seconds
32
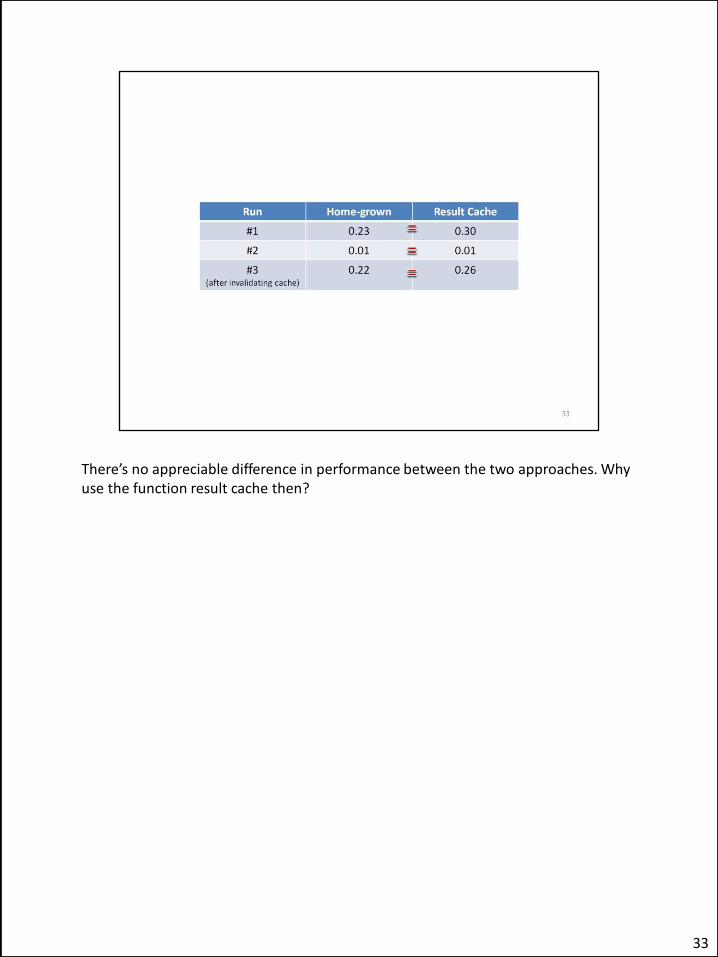
There’s no appreciable difference in performance between the two approaches. Why use the function result cache then?
33

34

All these reasons are correct. The code is simpler, no arrays to manage, no triggers to write, and altogether much reduced risk of bugs. But, there’s one BIG reason missing from this list…
35

There is one potentially significant difference
36
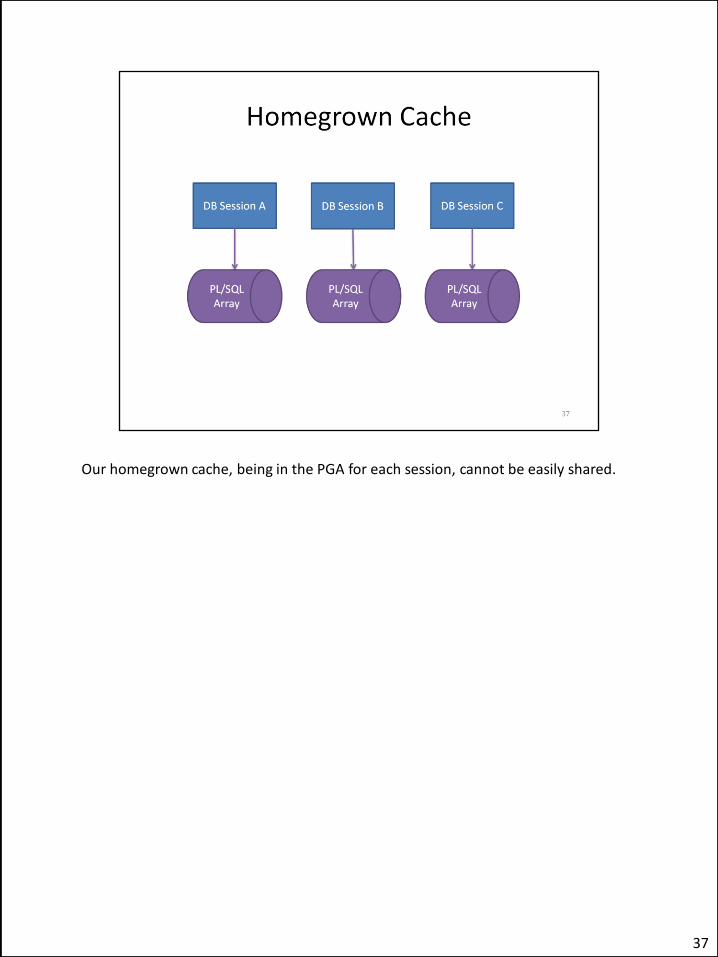
Our homegrown cache, being in the PGA for each session, cannot be easily shared.
37

The Function Result Cache, being in the SGA, is shared amongst all database sessions.
38

Two sessions, similar performance: 0.21 and 0.25 seconds for the baseline.
39

Just for completeness, the baseline run again in both sessions: 0.13 and 0.24 seconds
40

Method #1 in two sessions: 0.23 seconds in the first session, followed by 0.01 seconds in the second run, as before. In the second session, however, we see no benefit from our home-grown cache: 0.28 seconds again (followed by 0.01 seconds). This is because our home-grown PL/SQL cache uses the session’s private memory in the PGA which cannot be shared amongs multiple sessions. We might see some benefit in a stateless application that shares sessions between user calls; but even then the cache is doubled up for each database session.
41

Method #2, using Oracle’s Function Result Cache in two sessions. Session #1 primes the cache in 0.29 seconds, and sees the benefit in its second run (0.01 seconds); Session #2 sees an immediate benefit (0.04 and 0.03 seconds) for both runs of the test – proving that the result cache is shared (it is kept in the SGA).
42

43

44

In other words, how fine-grained is the dependency tracking used by the result cache? Not very. As soon as ANY transaction starts making changes to a table (in 11gR1, referred to in the RELIES_ON; in 11gR2, queried at all), all results are invalidated; and the function will always be called continuously until the transaction is committed.
45

*** exception is tables queried across a database link; the result cache is not invalidated if the table is changed
46

In other words, how fine-grained is the dependency tracking used by the result cache?
47

If we change another package or function in a way that should change the result of the function, Oracle unfortunately does not detect it, and will continue to use the result cache. In scenarios where you are deploying changes to the application (such as compiling new versions of code), you’ll need to consider flushing the cache. Another strategy might be to reserve RESULT_CACHE for simple functions and procedures that don’t call other packages.
48

The questioner here had a function that had to query a table, but they didn’t want the cache invalidated – even if the table was changed – and they didn’t want to build their own cache using a PL/SQL table in memory. This may be a common scenario for organisations upgrading from 11gR1 to 11gR2, which all of a sudden ignores the RELIES_ON clause. One trick offered is to use a database link that connects back to the same user!
49

50

51

Session-specific settings – watch out for things like TO_CHAR(v)!
52

* Take this with a pinch of salt. Even if you do call a nondeterministic SQL function (such as SYSDATE), you can still apply result cache to the function. You just have to test it to ensure that it takes the behaviour of the particular SQL function into account.
53

If it’s a single value to be shared across all sessions, a globally-accessible application context may be a viable alternative. Especially if you don’t want table DML to invalidate the cache and want to control the cache’s invalidation yourself.
54

55

No. A function that merely does some calculation and returns a result can still take advantage of the Result Cache feature.
56

No. Oracle’s function result cache is shared amongst all sessions, so a new session may very well be able to use the cache.
57

No. If this were really true, Oracle would probably remove the syntax entirely and just make it the default. You have to determine whether the function is suitable for the result cache, and whether it is really needed.
58

No. There are other reasons why the cache may be bypassed – e.g. if the cached result is aged out of the SGA, or if the database administrator disables the use of the result cache (e.g. to install a patch), or if the session executes DML on a table or view on which the function depends. Another reason is if you’re not using Enterprise Edition – the result cache keyword will be ignored.
59

No. There is no requirement for a result-cached function to be declared as, or even be, deterministic. If it isn’t, though, you may not get the results you expect (no pun intended).
60

Yes. Don’t do that.
61

62

63

Mistakes happen. Deal with it.
64

65
66





























