Embed Size (px)
Citation preview

• Suning Overview
• Suning OpenStack Journey
• Suning Cloud Workload
• Lessons Learnt
• Wishlists
2

• Basic Information• Established in 1990
• The largest commercial enterprise in China
• Top 3 Chinese private enterprises
• The 50th among the Top 500 enterprises in China
• Business Lines• retail, logistics, supply chain, real estates, investments, ...
• By the end of 2012• Suning has stores in 700+ cities in China and other countries.
• The total number of staff is 180,000
• 4 R&D centers: Beijing, Shanghai, Nanjing, Silicon Valley
• Brand value of $ 13 B, annual revenue $ 37 B3
$ 175 Billion43.9% YTY Growth
1H 2014, China
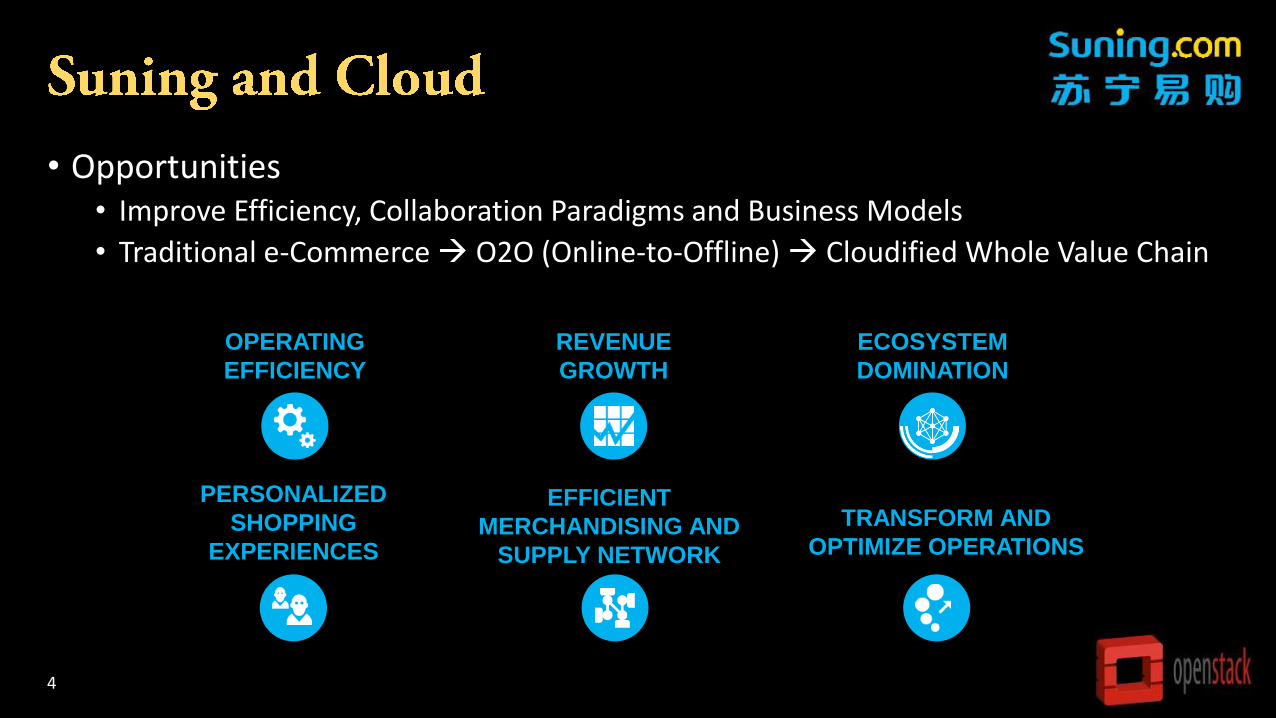
• Opportunities• Improve Efficiency, Collaboration Paradigms and Business Models
• Traditional e-Commerce O2O (Online-to-Offline) Cloudified Whole Value Chain
4
PERSONALIZED
SHOPPING
EXPERIENCES
EFFICIENT
MERCHANDISING AND
SUPPLY NETWORK
TRANSFORM AND
OPTIMIZE OPERATIONS
OPERATING
EFFICIENCY
REVENUE
GROWTH
ECOSYSTEM
DOMINATION
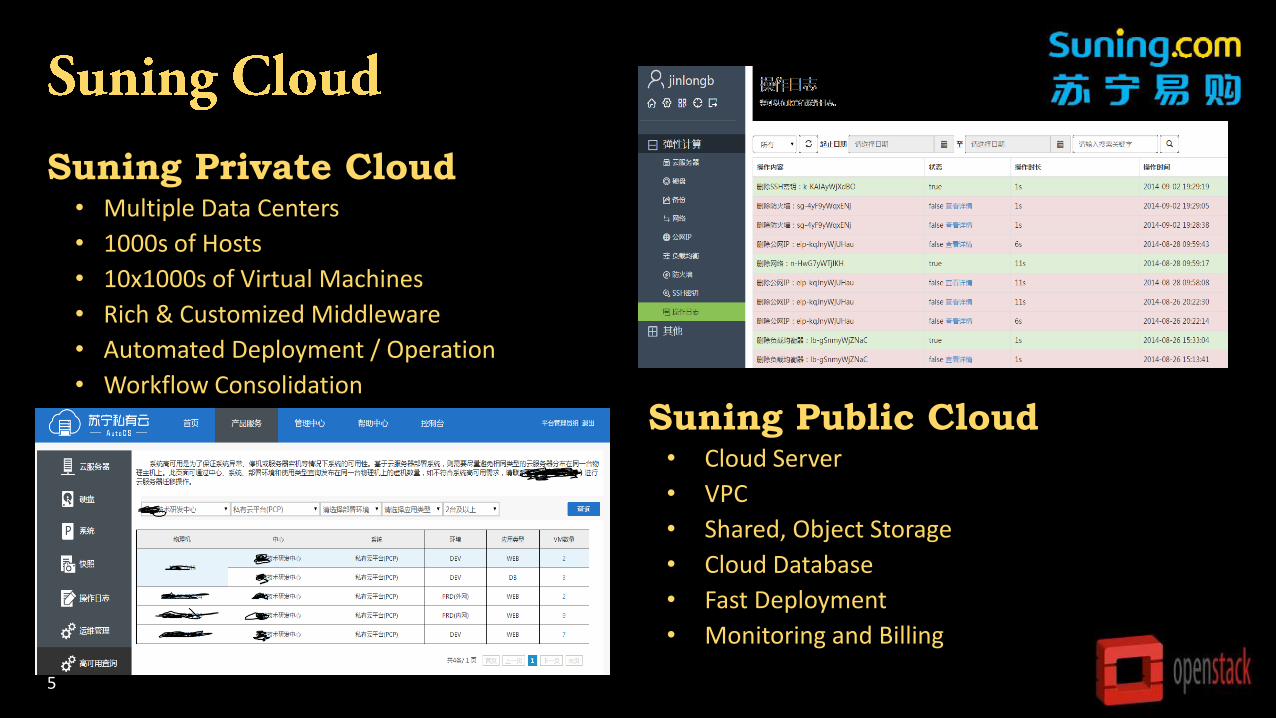
Suning Private Cloud• Multiple Data Centers
• 1000s of Hosts
• 10x1000s of Virtual Machines
• Rich & Customized Middleware
• Automated Deployment / Operation
• Workflow Consolidation
5
Suning Public Cloud• Cloud Server
• VPC
• Shared, Object Storage
• Cloud Database
• Fast Deployment
• Monitoring and Billing

• The journey starts since early 2013• single deployment -> multi-region deployment across data centers
• R & D workloads testing -> Internet/production workload
6
Domain Status
Compute • 256 GB memory, 4 GB NICs, 64 cores; Windows/Linux guests
Network • Isolated network for admin, data and storage; OVS bonding; HW LB
Storage • LVM and GlusterFS resource pool with QoS support; Cinder multi-backend
Container • Docker resource pool and docker repo with HA enabled
Deployment • Cobbler, Puppet
Management • 3 nodes HA setup for controllers; RabbitMQ cluster
Monitoring • Proprietary resource/service monitoring tools, guest agents for data collection• RabbitMQ portal and LogStash
Optimization • Resource scheduling for standalone, clustered and layered applications

• 100+ applications of diverse characteristics
• Mixed CPU-intensive and I/O Intensive workload:• CPU-intensive, long-hour duration mobile application compilation and building
• huge storage and volume (800G ~ 1T)
• search engine compilation
• big data analytics, e.g. sentiment analysis
• thumbnail generation
• Different software stacks for Internet applications• Apache + JBoss + MySQL
• IHS + WAS + DB2
• Others
7
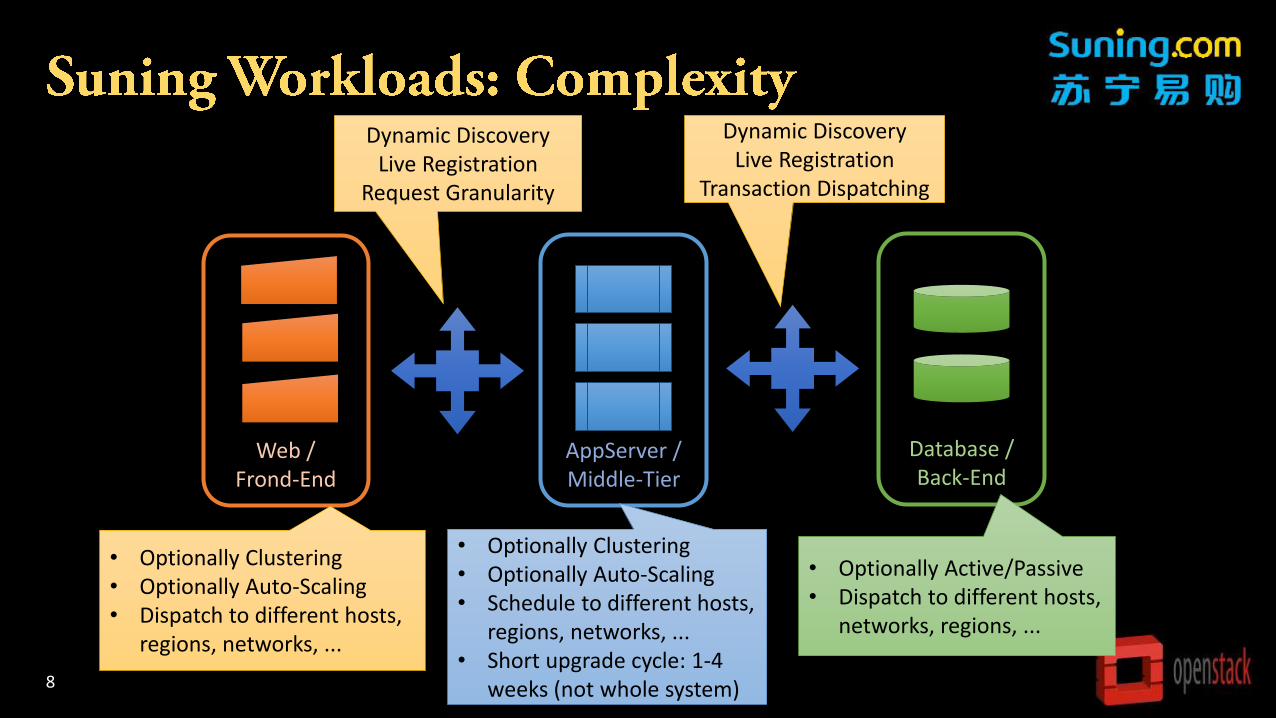
8
Web /Frond-End
AppServer / Middle-Tier
Database / Back-End
• Optionally Clustering• Optionally Auto-Scaling• Dispatch to different hosts,
regions, networks, ...
• Optionally Clustering• Optionally Auto-Scaling• Schedule to different hosts,
regions, networks, ...• Short upgrade cycle: 1-4
weeks (not whole system)
• Optionally Active/Passive• Dispatch to different hosts,
networks, regions, ...
Dynamic DiscoveryLive Registration
Request Granularity
Dynamic DiscoveryLive Registration
Transaction Dispatching

• A component/service may play different roles• Apache: web-server and/or reverse-proxy and/or load-balancer• JBoss: front-end, back-end or both
• Master agent, Host agent, JBoss instances
• Service discovery and registration is complex• IT requirements like SSH key, service user, password, directory, package repository…• Legacy script and automation tools (taking in or discard)
• Workload distribution has to be planned ahead• traditional process forking is not acceptable on a virtualized platform• VMs become the management unit on cloud
• tuning specs: quota, profile, application characteristics
• scaling VMs instead of forking new processes
9
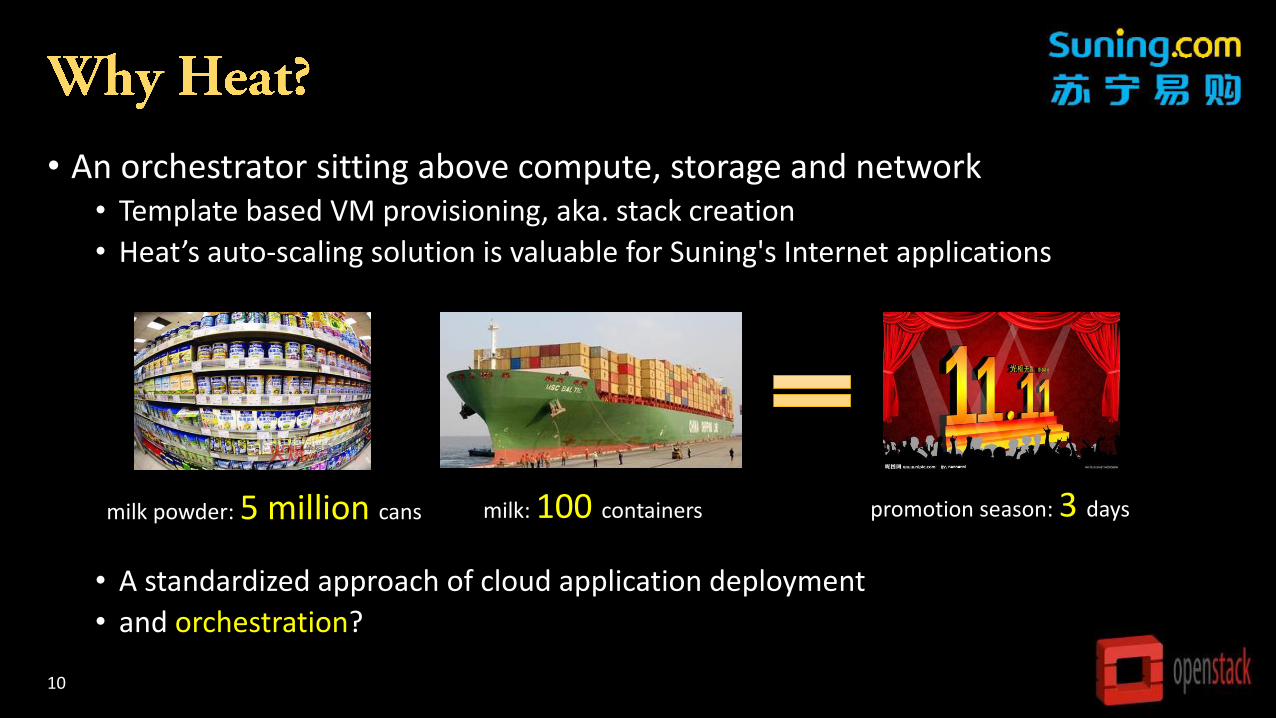
• An orchestrator sitting above compute, storage and network• Template based VM provisioning, aka. stack creation
• Heat’s auto-scaling solution is valuable for Suning's Internet applications
• A standardized approach of cloud application deployment
• and orchestration?
10
milk powder: 5 million cans milk: 100 containers promotion season: 3 days

• Standard images and software packages
• Post-launch configuration• creation of user accounts
• key distribution and revocation
• VM roles assignment
• package update or upgrade
• middleware install and configuration
• application install and configuration
• monitoring tools install and configuration
• service discover and registration ???
• .......
11

• Deployment and Orchestration• Heat based deployment only covers part of the story
• Cloud-init only concerns with the initial deployment
• What we need is an integrated end-to-end tool chainthat covers runtime/maintenance orchestration as well
12
• Orchestration is not thoroughly tested in community (e.g. Auto-scaling)• involves Heat, Ceilometer, Nova, Keystone...
• rolling-update may not work as expected
• scaling out may jump from one to many directly
• ceilometer alarm evaluator may not work
• ...
• fixing these is not an easy job

• Triggers for scaling• network metrics (packets processed, bytes transferred) sounds interesting, but
• CPU and memory are still the primary bottlenecks
• Scaling may be triggered with combination factors of CPU, memory, disk I/O and/or network I/O with customized algorithm
• Rolling update is of critical importance• ensure a given number of instances are always online when performing updates
• Deletion policy from resource groups• sometimes the newest members are preferred to oldest members, considering that
• old members may have state cached, may have proved to be stable, ...
• Fast detection and fast scaling (seconds level)
13

• Availability• Storage Reliability/Availability
• Hard disk errors are common
• VM High-Availability (aka. the "Pets" story)• it doesn't seem like a single project mission
• host failure, network failure, storage failure, guest failure, application failure ...
• may need to get Nova, Ceilometer (Zaqar?), Heat, Keystone to work together
• AutoScaling• Semi-AutoScaling (Scale at a given point in time)
• Smarter VM placement, aka. Global Scheduling• e.g. 3 Apache server per host is okay, but 9 Apache per host is risky
• VM placement is mainly concerned with service availability
• Scaling across availability zones, across regions14

• Application Profile and Management• Each application has a unique architecture where some components are reusable
• Most components are capable of playing different roles (e.g. front-end vs back-end)• domain role, slave role, host role, etc.
• Combinations are difficult to predict and manage
• Solum? Murano?
• Provider Templates?+ promote template reusability
+ facilitate fine granularity version control
- difficult to reference resources (attributes) from outer/inner templates
- difficult to get dependencies done right
- Tools to standardize Heat template collections
15

• Configurable frequency for Heat engine calls• mostly from os-xxx-config
• may need a short interval during bootup, then switch to a longer interval
• Tools and guidance for the establishment of standard workflows• need to abstract away common features and parameters
• need to simplify the deployment, management process
• need to adapt to new technologies• e.g. transition from using shared disk volumes to use storage cloud
16

Thank You!
17






























