Embed Size (px)
Citation preview

STLab ISTC - CNR
ESWC-15 Open Knowledge Extraction Challenge
2 June 2015 - Portrož, Slovenia
Andrea Giovanni Nuzzolese1, Anna Lisa Gentile2, Valentina Presutti1, Aldo Gangemi1,3, Roberto Navigli4, Dario Garigliotti4
1STLab, Institute of Cognitive Science and Technology, National Research Council, Italy2University of Sheffield, UK
3LIPN, Université Paris 13, Sorbone Cité, UMR CNRS, France 4University of Roma “La Sapienza”, Italy

STLab ISTC - CNR
• Semantic Web vision
• populate the Web with machine understandable data
• Most of the Web content consists of natural language text, e.g., Web sites, news, blogs, micro-posts, etc.
• Goal:
• extract relevant knowledge
• publish as Linked Data
Background
2

STLab ISTC - CNR
Motivations
3
• Problem
• existing Knowledge Extraction systems are often not directly reusable for populating the Semantic Web (SW)
• lack of a “genuine” SW reference evaluation framework
• Tasks such as named entity recognition, relation extraction, frame detection, etc.
• often do not provide output as Linked Data
• Aim of OKE challenge:
• reference framework for Knowledge Extraction from text
• produce output wrt specific SW requirements

STLab ISTC - CNR
Task 1
4
Entity Recognition, Linking and Typing for Knowledge Base population
• Identifying Entities in a sentence and create an OWL individual (owl:Individual statement) representing it
• entity: any discourse referent either named or anonymous
• Linking (owl:sameAs statement) such an individual to DBpedia
• Assigning a type to such individual (rdf:type statement) selected from a set of top-level DOLCE Ultra Lite classes
• i.e., dul:Person, dul:Place, dul:Organization and dul:Role

STLab ISTC - CNR
• We want to recognize the following entities
Task 1: Example
5
• The results must be provided in NIF format
Florence May Harding studied at a school in Sydney, and with Douglas Robert Dundas, but in effect had no formal training in either botany or art.

STLab ISTC - CNR
Task 1: Evaluation criteria
6
• Ability to recognize entities in a text
• only full matches are counted as correct
• Ability to assign the correct type
• evaluation will be carried out only on the 4 target DOLCE types
• Ability to link individuals to DBpedia 2014
• participants must link entities to DBpedia only when relevant
• We calculate the average Precision, Recall and F-measure

STLab ISTC - CNR
Task 2
7
• Identifying the type(s) of a given entity
• as expressed in a given definition
• Creating owl:Class statements for defining each of them
• as a new class in the knowledge base
• Creating a rdf:type statements
• between the given entity and the new created classes
• Aligning the identified types to a subset of DOLCE Ultra Lite classes
Class Induction and entity typing for Vocabulary and Knowledge Base enrichment

STLab ISTC - CNR
Task 2: Example
8
Brian Banner is a fictional villain from the Marvel Comics Universe created by Bill Mantlo and Mike Mignola and first appearing in print in late 1985.
• Brian Banner will be given as the input target entity
• We want to recognize the following
• The results must be provided in NIF format

STLab ISTC - CNR
Task 2: Evaluation criteria
9
• Ability to recognize strings that describe the type of a target entity
• Ability to align the identified type with the reference ontology, i.e., DOLCE

STLab ISTC - CNR
Participants
10
• M. Röder, R. Usbeck and A. Ngonga Ngomo. CETUS — A Baseline Approach to Type Extraction (Tasks 1-2)
• J. Plu, G. Rizzo and R. Troncy. A Hybrid Approach for Entity Recognition and Linking (Task 1)
• S. Consoli and D. Reforgiato. Using FRED for Named Entity Resolution, Linking and Typing for Knowledge Base population (Tasks 1-2)
• J. Gao and S. Mazumdar. Exploiting Linked Open Data to Uncover Entity Type (Task 2)

STLab ISTC - CNR
CETUS - A Baseline Approach to Type Extraction
11
• FOX
• Entity Recognition based on Stanford NER, Illinois, Balie and OpenNLP
• Entity Linking based on AGDISTIS, an open-source named entity disambiguation system
Task 1

STLab ISTC - CNR
CETUS - A Baseline Approach to Type Extraction
12
Task 2Entity replacementCoreference resolution
Pattern-based evidence recognition Ontology Matching

STLab ISTC - CNR
A Hybrid Approach for Entity Recognition and Linking
13
• Hybrid: NER + NEL combining linguistics and semantics
• NER - output: set of entity candidates
• Stanford POS Tagger & Stanford NER
• Dictionary of Wikipedia titles built wrt to the dataset types
• In case of overlaps, the longest entity is considered
• NEL - output: each candidate is matched with a DBpedia referent if any (NIL otherwise)
• distance function that compares the candidate with: title, redirect, disambiguation page, and Page Rank of the Wikipedia resource

STLab ISTC - CNR
Using FRED for Named Entity Resolution, Linking and Typing for Knowledge Base population
The Black Hand might not have decided to barbarously assassinate Franz Ferdinand after he arrived in Sarajevo on June 28th, 1914
STLab ISTC - CNR
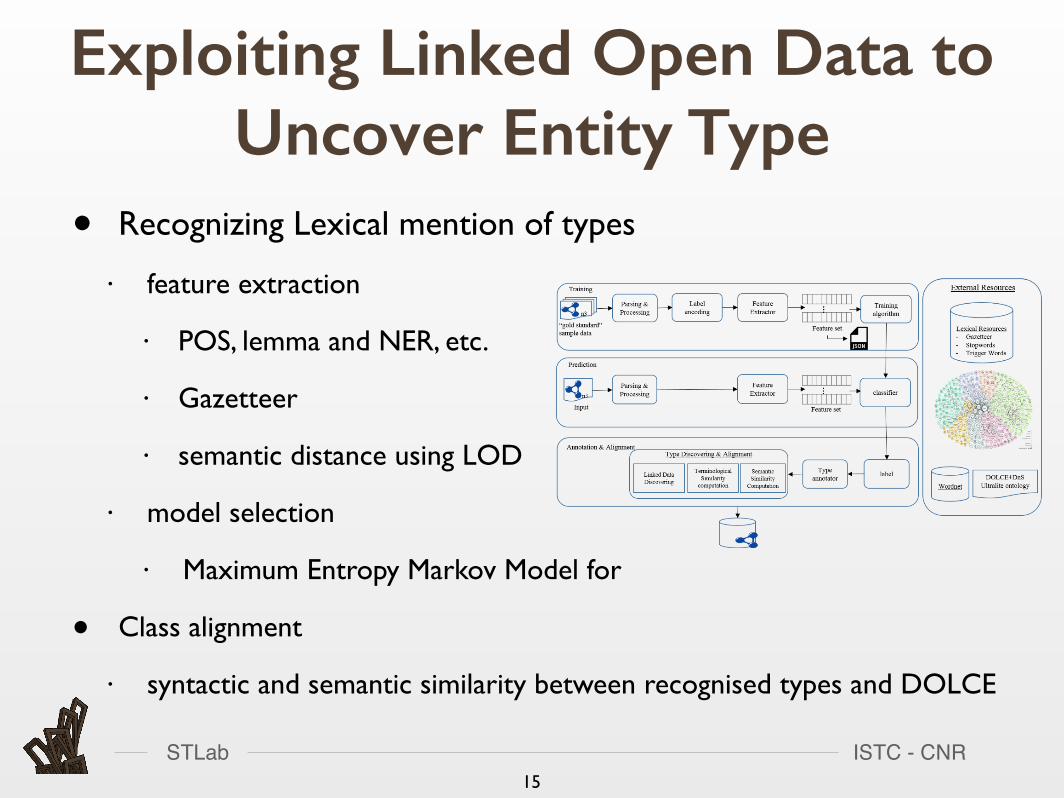
• Recognizing Lexical mention of types
• feature extraction
• POS, lemma and NER, etc.
• Gazetteer
• semantic distance using LOD
• model selection
• Maximum Entropy Markov Model for
• Class alignment
• syntactic and semantic similarity between recognised types and DOLCE
Exploiting Linked Open Data to Uncover Entity Type
15

STLab ISTC - CNR
Evaluation
16
1. GERBIL — General Entity Annotation Benchmark Framework by Ricardo Usbeck, Michael Röder, Axel-Cyrille Ngonga Ngomo, Ciro Baron, Andreas Both, Martin Brümmer, Diego Ceccarelli, Marco Cornolti, Didier Cherix, Bernd Eickmann, Paolo Ferragina, Christiane Lemke, Andrea Moro, Roberto Navigli, Francesco Piccinno, Giuseppe Rizzo, Harald Sack, René Speck, Raphaël Troncy, Jörg Waitelonis, and Lars Wesemann in 24th WWW conference
• GERBIL offers
• an easy-to-use web-based platform
• agile comparison of annotators
• multiple datasets support
• uniform measuring approaches
• We use GERBIL1 as benchmarking system for evaluating precision, recall and F-measure
http://aksw.org/Projects/GERBIL.html

STLab ISTC - CNR17
Thank you!
https://github.com/anuzzolese/oke-challenge





























