Embed Size (px)
Citation preview

1Confidential
Running Kafka At ScaleGwen Shapira

2Confidential
About Me
System Architect @ ConfluentCommitter @ Apache KafkaPreviously:
Software Engineer @ Cloudera
Senior Consultant @ Pythian
Find me:[email protected]@gwenshap

3Confidential
Kafka
High ThroughputScalableLow LatencyReal-timeCentralizedAwesome
So, we are done, right?

4Confidential
When it comes to critical production systems – Never trust a vendor.
4

5Confidential
Strong FoundationsBuilding a Kafka cluster from the hardware up

6Confidential
What’s Important To You?
Message Retention - Disk size
Message Throughput - Network capacity
Producer Performance - Disk I/O
Consumer Performance - Memory

7Confidential
Go Wide
RAIS - Redundant Array of Inexpensive Servers
Kafka is well-suited to horizontal scaling
Also helps with CPU utilization• Kafka needs to decompress and recompress every message batch• KIP-31 will help with this by eliminating recompression
Don’t co-locate Kafka

8Confidential
Disk Layout
RAID• Can survive a single disk failure (not RAID 0)• Provides the broker with a single log directory• Eats up disk I/O
JBOD• Gives Kafka all the disk I/O available• Broker is not smart about balancing partitions• If one disk fails, the entire broker stops
Amazon EBS performance works!

9Confidential
Operating System Tuning
Filesystem Options• EXT or XFS• Using unsafe mount options
Virtual Memory• Swappiness• Dirty Pages
Networking

10Confidential
Java
Only use JDK 8 now
Keep heap size small• Even our largest brokers use a 6 GB heap• Save the rest for page cache
Garbage Collection - G1 all the way• Basic tuning only• Watch for humongous allocations

11Confidential
Monitoring the Foundation
CPU LoadNetwork inbound and outboundFilehandle usage for KafkaDisk
• Free space - where you write logs, and where Kafka stores messages
• Free inodes• I/O performance - at least average wait and percent utilization
Garbage Collection

12Confidential
Broker Ground Rules
Tuning• Stick (mostly) with the defaults• Set default cluster retention as appropriate• Default partition count should be at least the number of brokers
Monitoring• Watch the right things• Don’t try to alert on everything
Triage and Resolution• Solve problems, don’t mask them

13Confidential
Too Much Information!
Monitoring teams hate Kafka• Per-Topic metrics• Per-Partition metrics• Per-Client metrics
Capture as much as you can• Many metrics are useful while
triaging an issue
Clients want metrics on their own topics
Only alert on what is needed to signal a problem

14Confidential
Broker Monitoring
Bytes In and Out, Messages In• Why not messages out?
Partitions• Count and Leader Count• Under Replicated and Offline
Threads• Network pool, Request pool• Max Dirty Percent
Requests• Rates and times - total, queue, local, and send

15Confidential
Topic Monitoring
Bytes In, Bytes OutMessages In, Produce Rate, Produce Failure RateFetch Rate, Fetch Failure RatePartition BytesQuota ThrottlingLog End Offset
• Why bother?• KIP-32 will make this unnecessary
Provide this to your customers for them to alert on

16Confidential
Staying out of Trouble

17Confidential
Anticipating Trouble
Trend cluster utilization and growth over time
Use default configurations for quotas and retention to require customers to talk to you
Monitor request times• If you are able to develop a consistent baseline, this is early
warning

18Confidential
Under Replicated Partitions
Count of number of partitions which are not fully replicated within the cluster
Also referred to as “replica lag”
Primary indicator of problems within the cluster

19Confidential
Appropriately Sizing Topics
Topics are “Logical” – data modeling is based on data and consumers
Number of partitions:• How many brokers do you have in the cluster?• How many consumers do you have?• Do you have specific partition requirements?
Keeping partition sizes manageableDon’t have too many partitions

20Confidential
Choosing Topics/Partitions
More partitions higher throughput• t: target throughput, p: producer throughput per partition, c:
consumer throughput per partition• max(t/p, t/c)
Downside with more partitions • requires more open file handle• may increase unavailability• may increase end-to-end latency• may require more memory in the client
Rule of thumb• 2-4 K partitions per broker• 10s K partitions per cluster

21Confidential
Tuning 101

22Confidential
Broker Performance Checks
Are all the brokers in the cluster working?Are the network interfaces saturated?
• Reelect partition leaders• Rebalance partitions in the cluster• Spread out traffic more (increase partitions or brokers)
Is the CPU utilization high? (especially iowait)• Is another process competing for resources?• Look for a bad disk
Are you still running 0.8?Do you have really big messages?
23Confidential
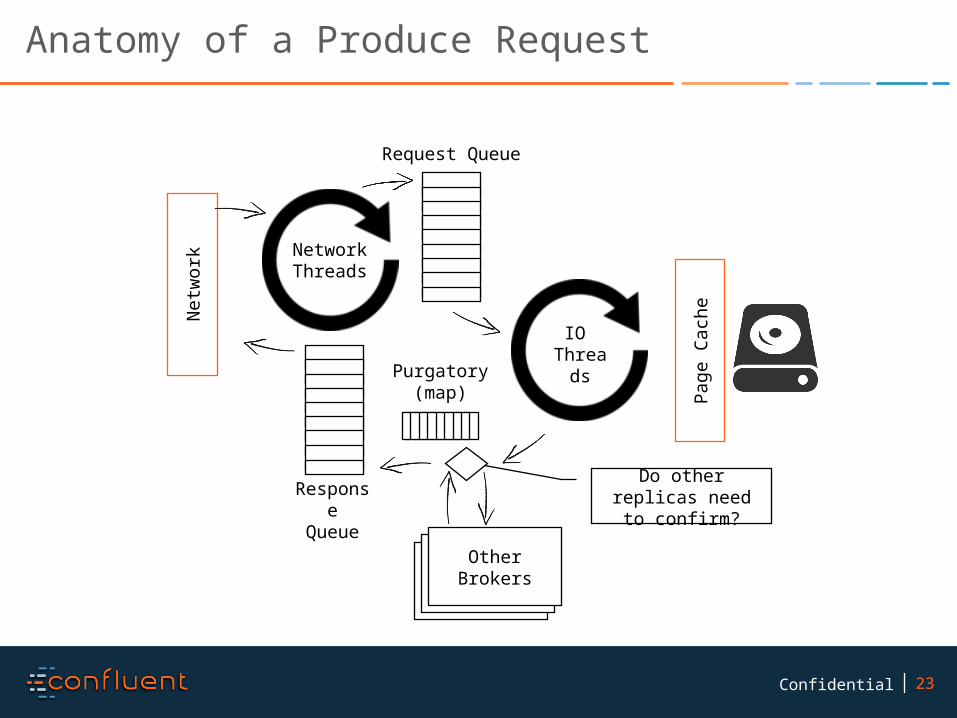
Anatomy of a Produce Request
Netw
ork Network
Threads
IO Thread
s
Page
Cac
he
Purgatory(map)
Request Queue
Response
Queue
Other Brokers
Other Brokers
Other Brokers
Do other replicas need to confirm?
24Confidential
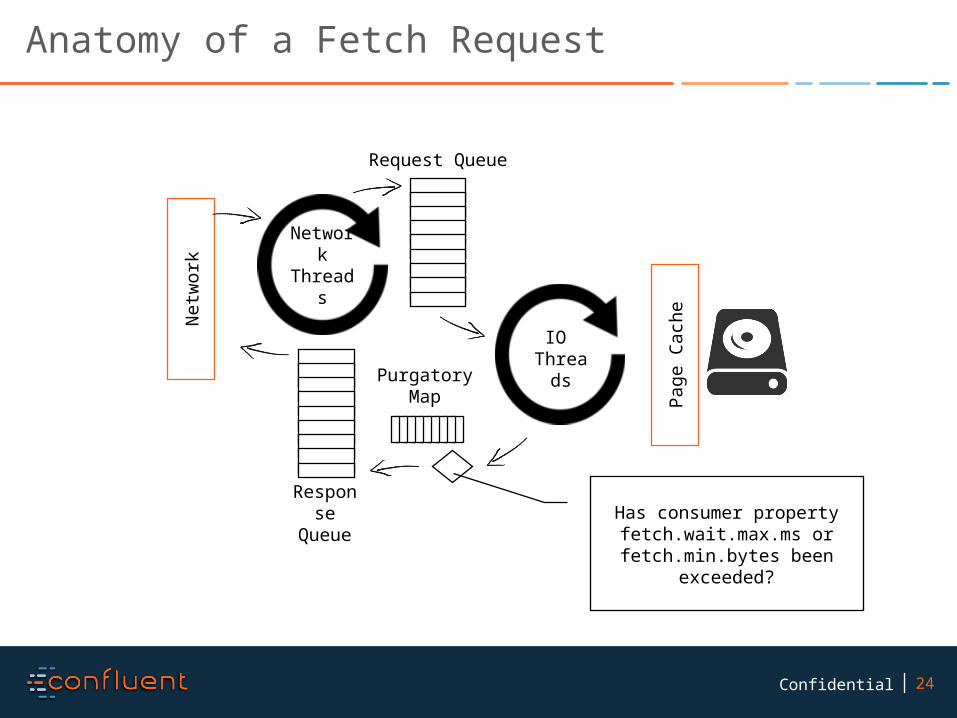
Anatomy of a Fetch Request
Netw
ork
Network
Threads
IO Threa
ds
Page
Cac
he
Purgatory Map
Request Queue
Response
QueueHas consumer property fetch.wait.max.ms or fetch.min.bytes been
exceeded?
25Confidential
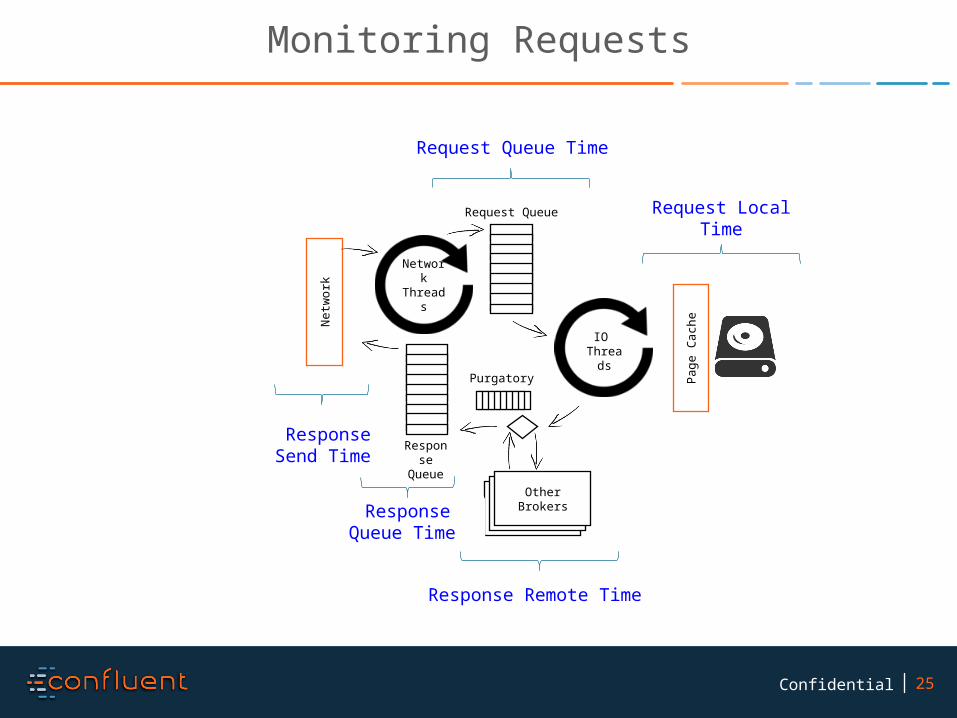
Monitoring Requests
Netw
ork Networ
kThreads
IO Threa
ds
Page
Cac
he
Purgatory
Request Queue
Response
Queue
Other Brokers
Other Brokers
Other BrokersResponse
Queue Time
Response Send Time
Request Local Time
Request Queue Time
Response Remote Time
26Confidential
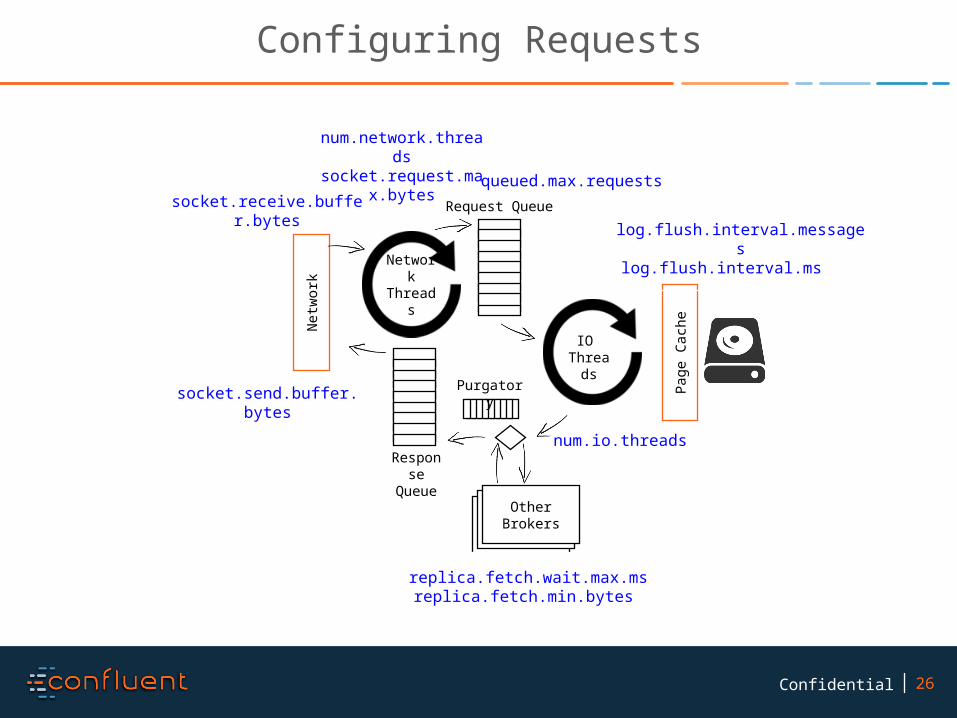
Configuring Requests
Netw
ork
Network
Threads
IO Threa
ds
Page
Cac
he
Purgatory
Request Queue
Response
QueueOther
BrokersOther
BrokersOther
Brokers
log.flush.interval.messageslog.flush.interval.ms
queued.max.requests
replica.fetch.wait.max.msreplica.fetch.min.bytes
num.network.threads
socket.request.max.bytes
num.io.threads
socket.receive.buffer.bytes
socket.send.buffer.bytes

27Confidential
Client Tuning
28Confidential
The basics
App
Client
Broker
Broker
Broker
Broker
29Confidential
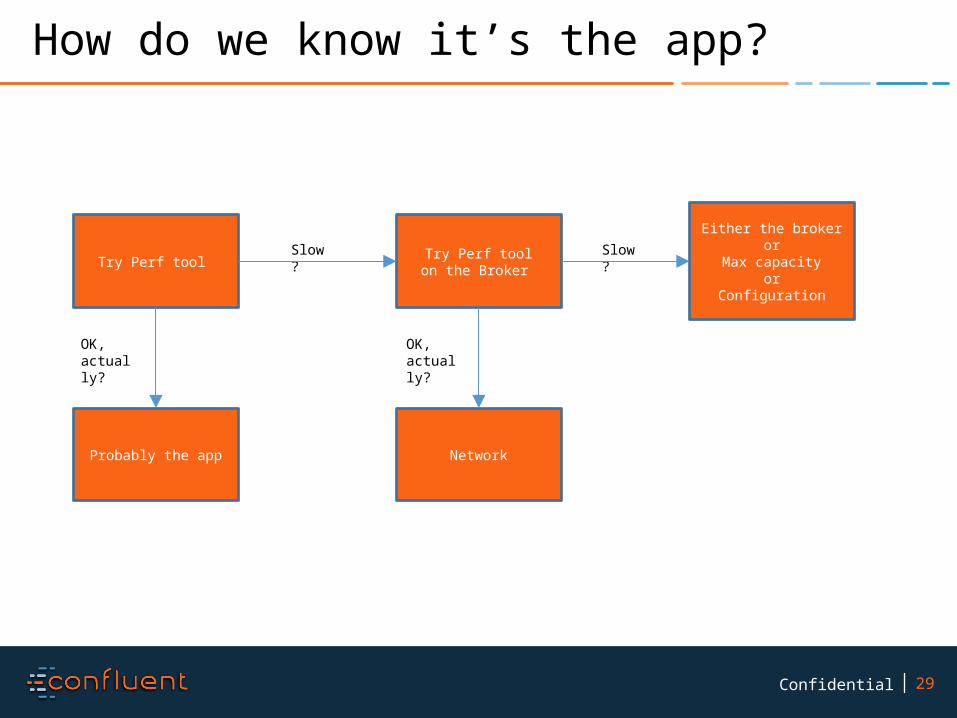
How do we know it’s the app?
Try Perf tool Slow?
OK, actually?
Try Perf toolon the Broker
Probably the app
Slow?Either the broker
orMax capacity
orConfiguration
OK, actually?
Network
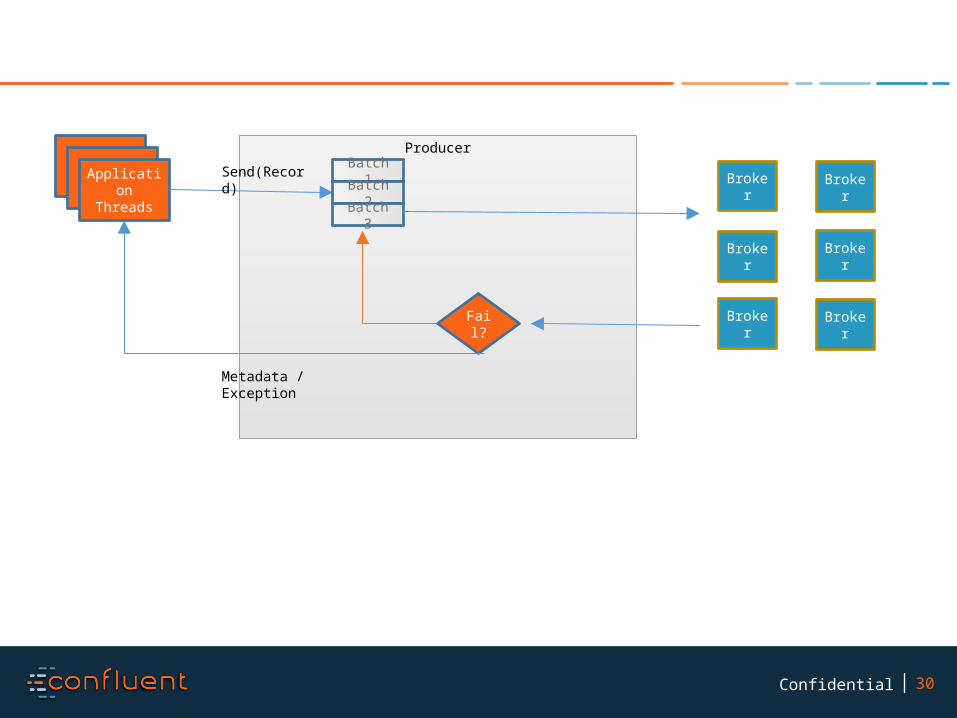
30Confidential
ApplicationThreads
Producer
Batch 1Batch 2Batch 3
Broker
Broker
Broker
Broker
Fail? Broker Broker
Send(Record)
Metadata / Exception
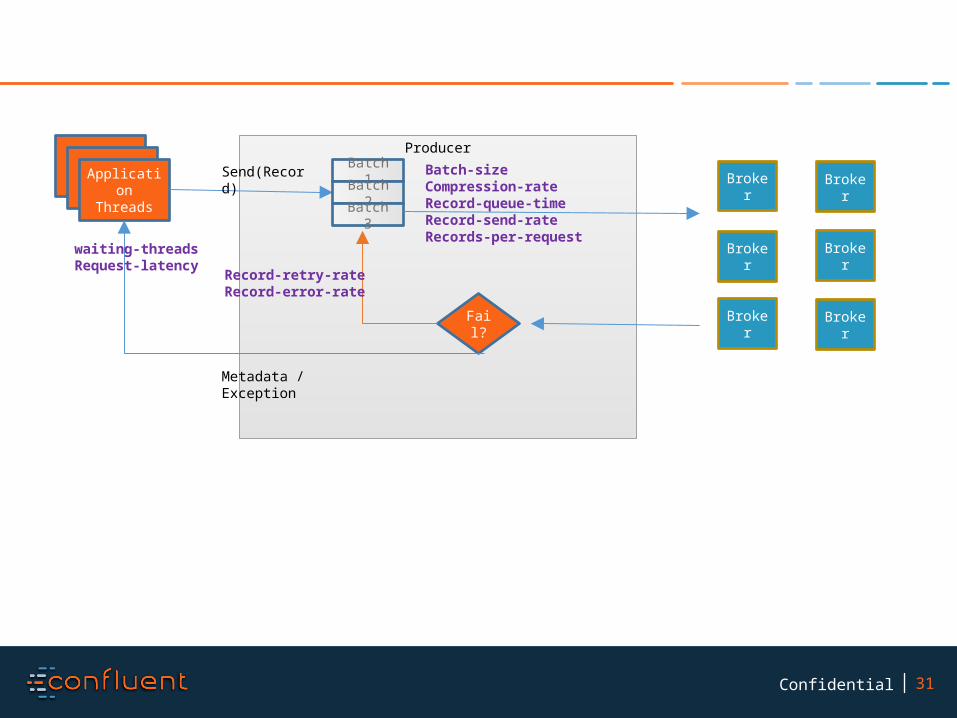
31Confidential
ApplicationThreads
Producer
Batch 1Batch 2Batch 3
Broker
Broker
Broker
Broker
Fail? Broker Broker
Send(Record)
Metadata / Exception
waiting-threadsRequest-latency
Batch-sizeCompression-rateRecord-queue-timeRecord-send-rateRecords-per-request
Record-retry-rateRecord-error-rate
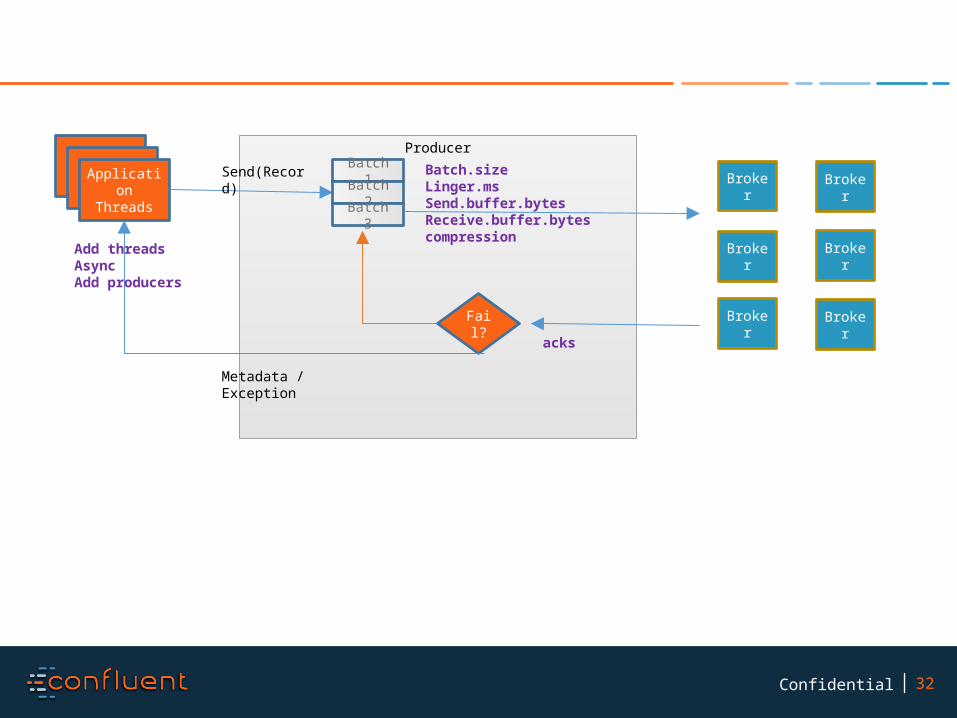
32Confidential
ApplicationThreads
Producer
Batch 1Batch 2Batch 3
Broker
Broker
Broker
Broker
Fail? Broker Broker
Send(Record)
Metadata / Exception
Add threadsAsyncAdd producers
Batch.sizeLinger.msSend.buffer.bytesReceive.buffer.bytescompression
acks

33Confidential
Send() API
Sync = Slow
producer.send(record).get();
Async
producer.send(record);
Or
producer.send(record, new Callback()
);

34Confidential
Batch.size vs Linger.ms
• Batch will be sent as soon as it is full• Therefore small batch size can decrease throughput• Increase batch size if the producer is running near saturation• If consistently sending near-empty batchs – increase to linger.ms will add a bit of latency, but improve throughput
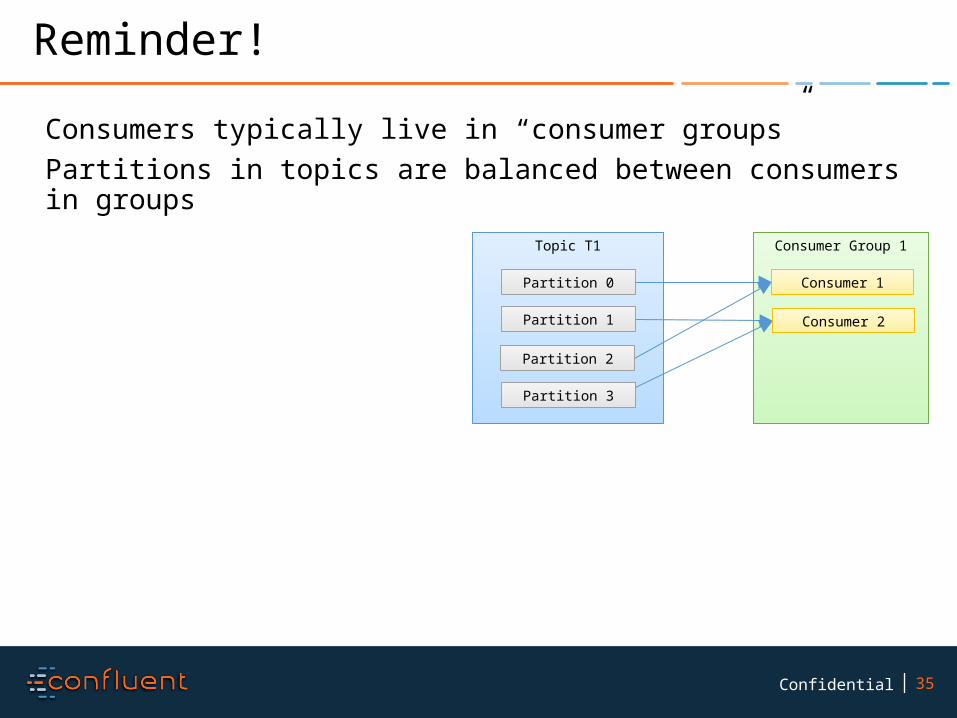
35Confidential
Reminder!
Consumers typically live in “consumer groups”Partitions in topics are balanced between consumers in groups
Topic T1
Partition 0
Partition 1
Partition 2
Partition 3
Consumer Group 1
Consumer 1
Consumer 2

36Confidential
My Consumer is not just slow – it is hanging!
• There are no messages available (try perf consumer)• Next message is too large• Perpetual rebalance
• Not polling enough• Multiple consumers in same group in same thread

37Confidential
Rebalances are the consumer performance killer
Consumers must keep pollingOr they die.
When consumers die, the group rebalances.
When the group rebalances, it does not consume.

38Confidential
Min.fetch.bytes vs. max.wait
• What if the topic doesn’t have much data?• “Are we there yet?” “and now?”• Reduce load on broker by letting fetch requests wait a bit for data• Add latency to increase throughput• Careful! Don’t fetch more than you can process!

39Confidential
Commits take time
• Commit less often• Commit async

40Confidential
Add partitions
• Consumer throughput is often limited by target• i.e. you can only write to HDFS so fast (and it aint fast)
• My SLA is 1GB/s but single-client HDFS writes are 20MB/s• If each consumer writes to HDFS – you need 50 consumers• Which means you need 50 partitions
• Except sometimes adding partitions is a bitch• So do the math first

41Confidential
I need to get data from Dallas to AWS
• Put the consumer far from Kafka• Because failure to pull data is safer than failure to push
• Tune network parameters in Client, Kafka and both OS•Send buffer -> bandwidth X delay•Receive buffer•Fetch.min.bytes
This will maximize use of bandwidth.Note that cheap AWS nodes have low bandwidth

42Confidential
Monitor
• records-lag-max• Burrow is useful here
• fetch-rate• fetch-latency• records-per-request / bytes-per-request
Apologies on behalf of Kafka community.
We forgot to document metrics for the new
consumer

43Confidential
![Formatted: Figure [PACKT] cm, Width: 21.59 cm, Height: 27 ... · Kafka 0.7.x Consumer Kafka 0.7.x Cluster Kafka Migration Kafka 0.8 Cluster Kafka 0.8 Producer Producer (Front End)](https://img.pdfslide.us/doc/110x75/5e14bfe3329a5375133247ed/formatted-figure-packt-cm-width-2159-cm-height-27-kafka-07x-consumer.jpg)