Embed Size (px)
Citation preview

All product images owned by respective companies/institutions
Intro to Apache

Takeaways
To understand: • Why we have big data today • What big data problems Spark solves • How Spark approaches big data differently
But most of all… to feel comfortable trying Spark out!

Image Credit: http://commons.wikimedia.org/wiki/File:BigData_2267x1146_white.png
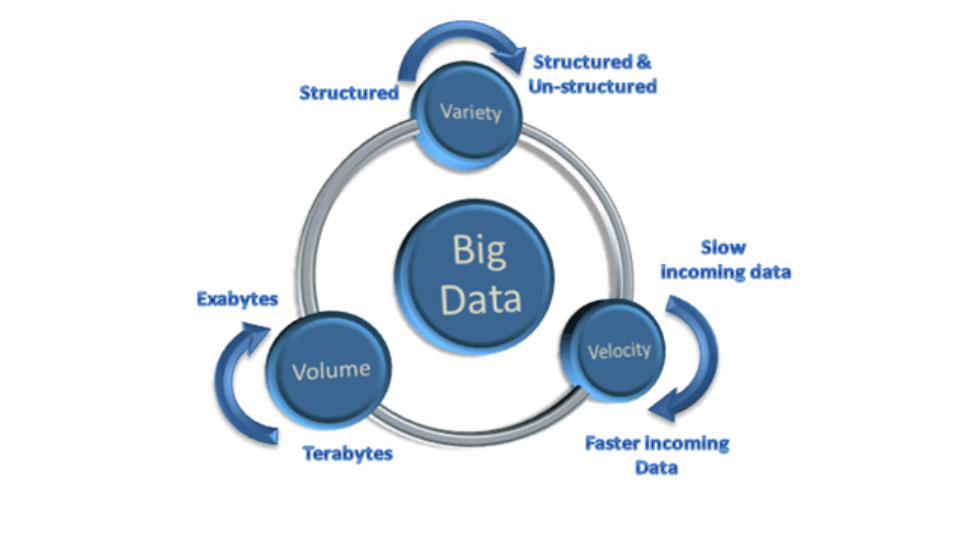

Why does big data exist?

All product images owned by respective companies/institutions

7.2 B 6.8 B 1.44 B 300 M 236 M 3.5 B / day
All product images owned by respective companies/institutions

When data is small it’s cute and cuddly, easy to contain…

When data gets big, we need tools to help us.

What tools can help?

2002 - MapReduce @ Google
2004 – MapReduce Paper
2006 – Hadoop @ Yahoo
2011 – Hadoop Released
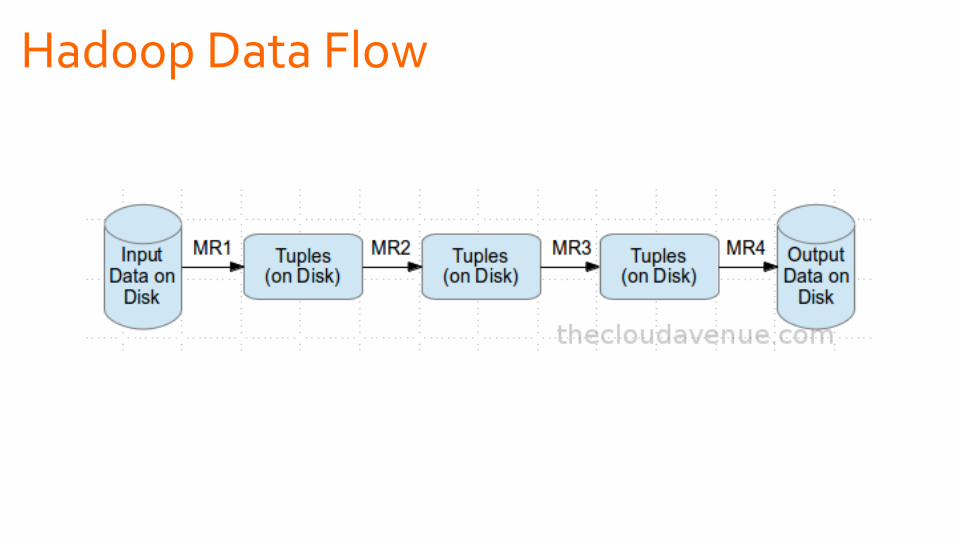
Hadoop Data Flow

But MapReduce falls short…

Hadoop’s Limitations
Lacks one thing to succeed for: • Iterative Queries • Interactive Queries Fast data sharing

Image courtesy of: http://workinganalytics.com/

a better way. We need…

We need… fault tolerance and speed.

We need… a better data abstraction.

The Solution..
• Resilient Distributed Datasets – A distributed memory abstraction that lets
programmers perform in-memory computations on large clusters in a fault-tolerant manner.
2002 - MapReduce @ Google
2004 – MapReduce Paper
2006 – Hadoop @ Yahoo
2013 – Spark @ Apache
2014 – Spark 1.0 Released
2011 – Hadoop Released
2011 – Hadoop Released 2009 – Spark at UC Berkeley

2002 - MapReduce @ Google
2004 – MapReduce Paper
2006 – Hadoop @ Yahoo
2013 – Spark @ Apache
2014 – Spark 1.0 Released
2009 – Spark at UC Berkeley
2011 – Hadoop Released
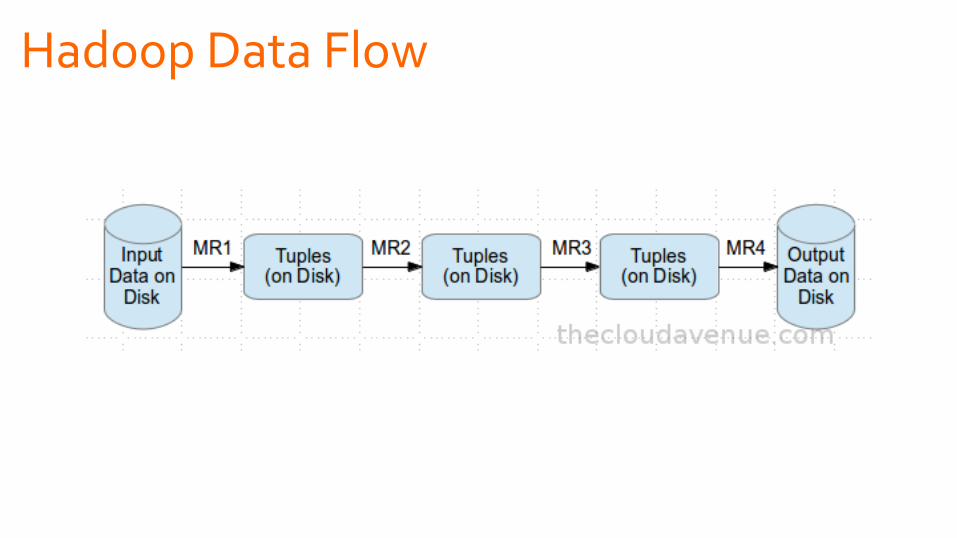
Hadoop Data Flow
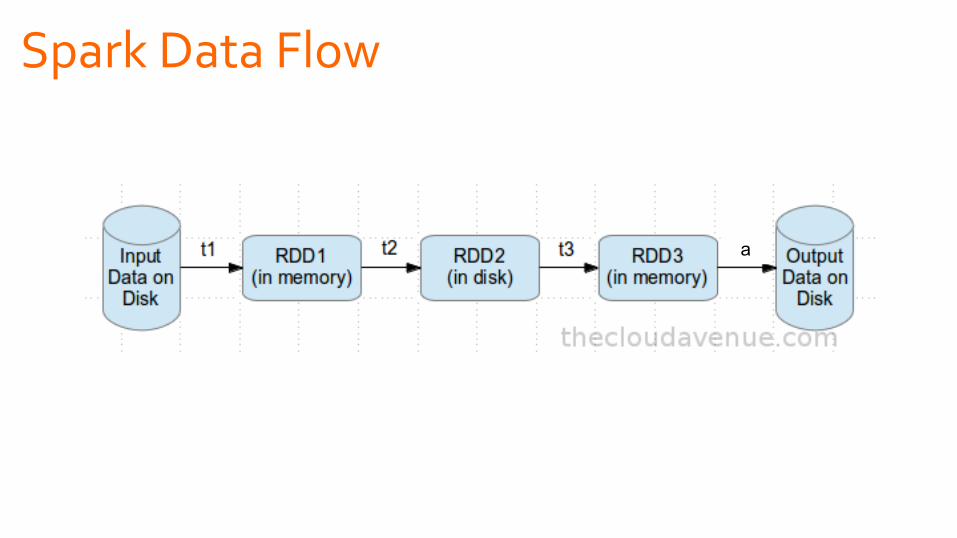
Spark Data Flow
a
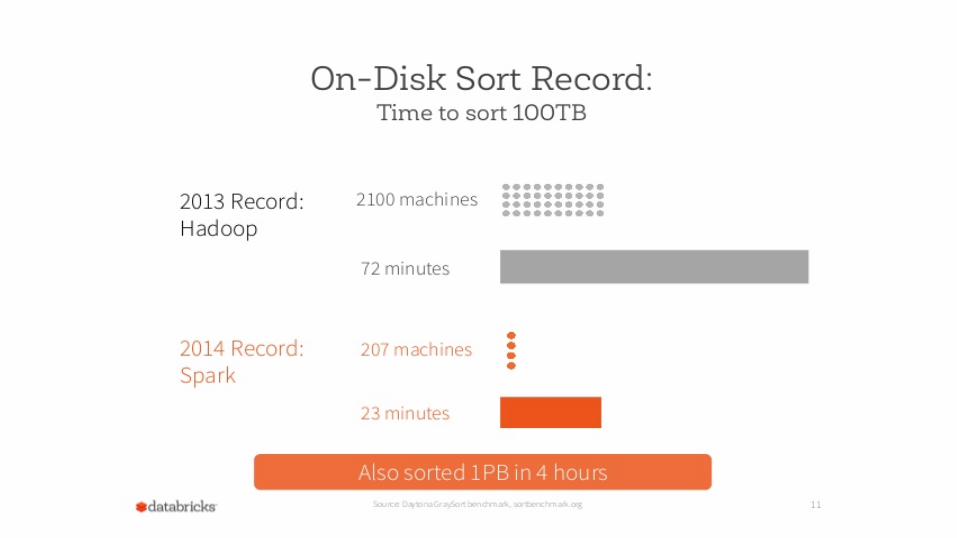

Why Spark? Fast
Image Credit: http://pixabay.com/en/tunnel-light-speed-fast-auto-101976/

Why Spark? Fast
General Purpose
Image Credit: http://www.freestockphotos.biz/stockphoto/9182

Why Spark? Fast
General Purpose
Easy
Image Credit: http://upload.wikimedia.org/wikipedia/commons/9/92/Easy_button.JPG

Why Spark? Fast
General Purpose
Easy
Streaming
Image Credit: http://pixabay.com/en/faucet-water-bad-sanitaryblock-686958/

Why Spark? Fast
General Purpose
Easy
Streaming
Adoption
All product images owned by respective companies/institutions

All product images owned by respective companies/institutions
Use Cases

Spark Use Cases ETL

Spark Use Cases ETL
Machine Learning
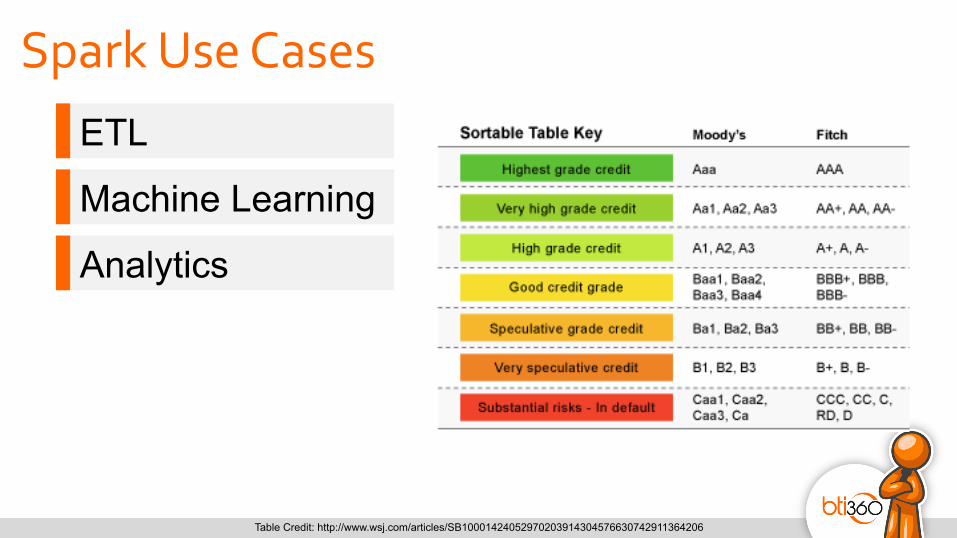
Spark Use Cases ETL
Machine Learning
Analytics
Table Credit: http://www.wsj.com/articles/SB10001424052970203914304576630742911364206
Spark Use Cases ETL
Machine Learning
Analytics
Modeling
Table Credit: http://www.wsj.com/articles/SB10001424052970203914304576630742911364206

Spark Use Cases ETL
Machine Learning
Analytics
Modeling
Data Mining
Table Credit: http://www.wsj.com/articles/SB10001424052970203914304576630742911364206
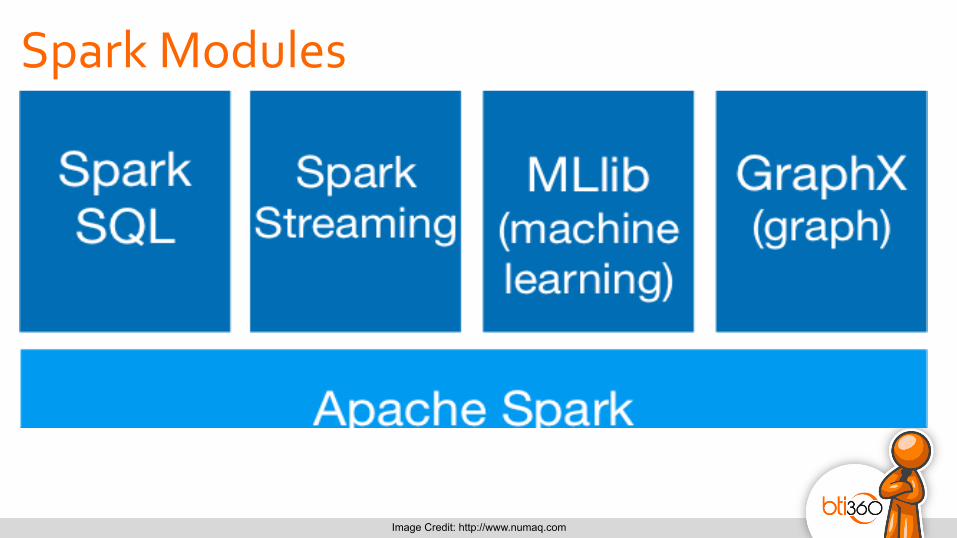
Spark Modules
Image Credit: http://www.numaq.com

Basics
All product images owned by respective companies/institutions
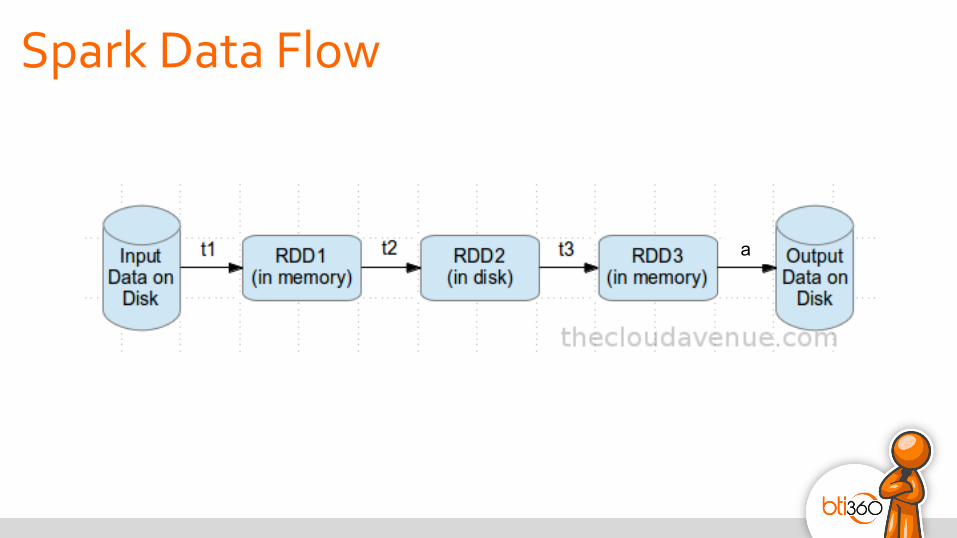
a
Spark Data Flow

Creating RDDs
• From practically any data source – HDFS – Local file system – S3 – NoSQL (Cassandra, Hbase, …) – JDBC
• From any collection • Transform an existing RDD

Text File
We start with some data. Put it in a form Spark understands…
File RDD
Read File

Text File
File RDD
Read File
RDDs: • Computation blueprint • Lazy: Hold instructions – not data
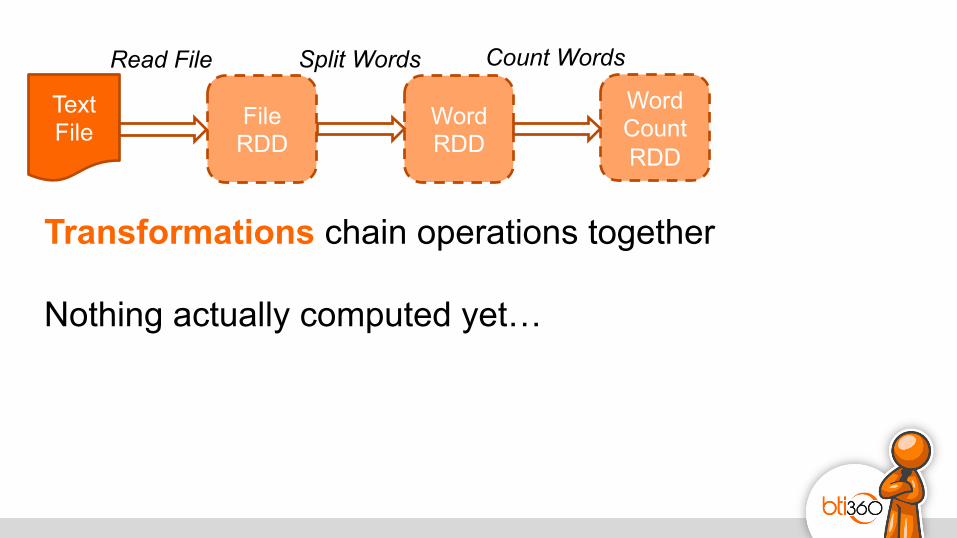
Text File
File RDD
Word RDD
Word Count RDD
Read File Split Words Count Words
Transformations chain operations together Nothing actually computed yet…
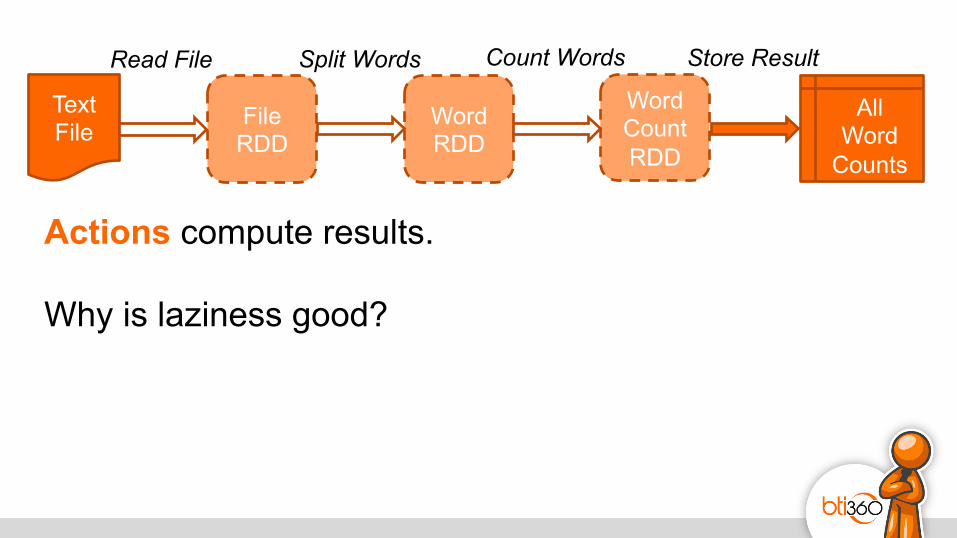
Text File
File RDD
Word RDD
Word Count RDD
All Word
Counts
Read File Split Words Count Words Store Result
Actions compute results. Why is laziness good?
Text File
File RDD
Word RDD
Word Count RDD
All Word
Counts
Read File Split Words Count Words Store Result
Top 10 Words
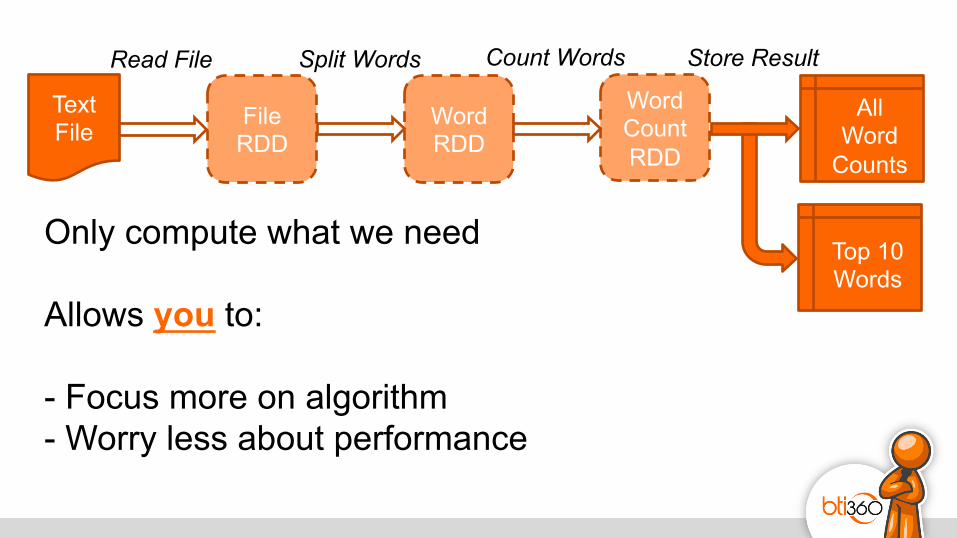
Only compute what we need Allows you to: - Focus more on algorithm - Worry less about performance
Text File
File RDD
Word RDD
Word Count RDD
All Word
Counts
Read File Split Words Count Words Store Result
Top 10 Words
“A” Word RDD
Words starting with “A”
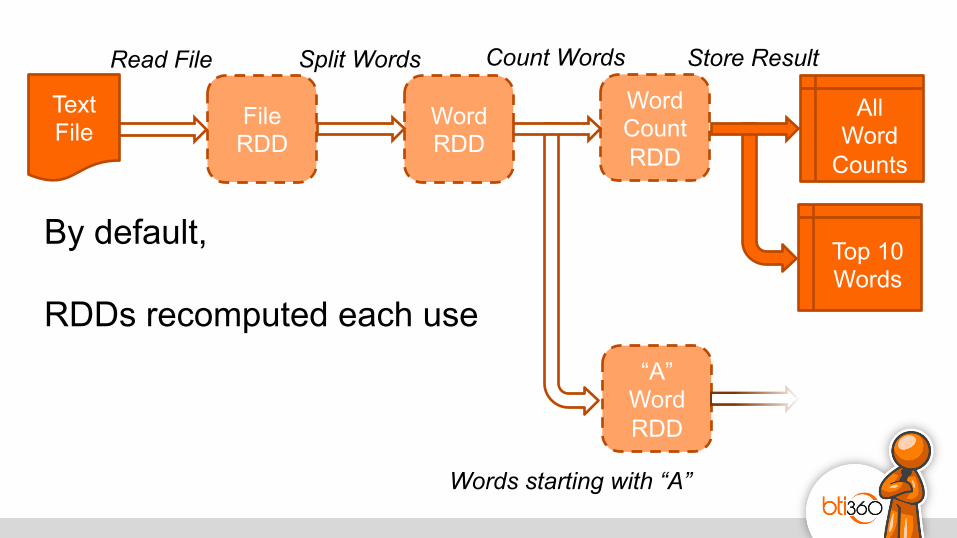
By default, RDDs recomputed each use
Word RDD
Text File
File RDD
Word Count RDD
All Word
Counts
Read File Split Words Count Words Store Result
Top 10 Words
“A” Word RDD
Words starting with “A”
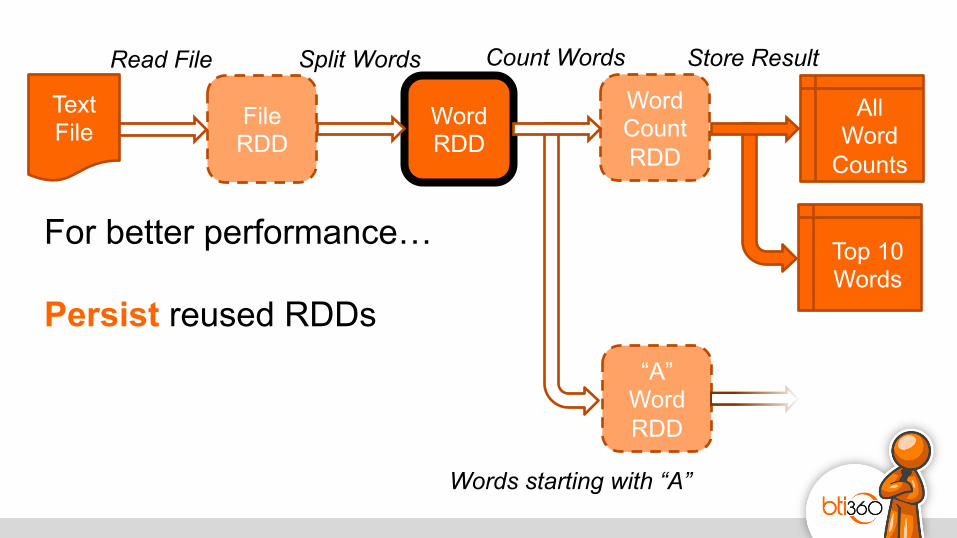
For better performance… Persist reused RDDs
Word RDD
Word RDD
Text File
File RDD
Word Count RDD
All Word
Counts
Read File Split Words Count Words Store Result
Top 10 Words
“A” Word RDD
Words starting with “A”
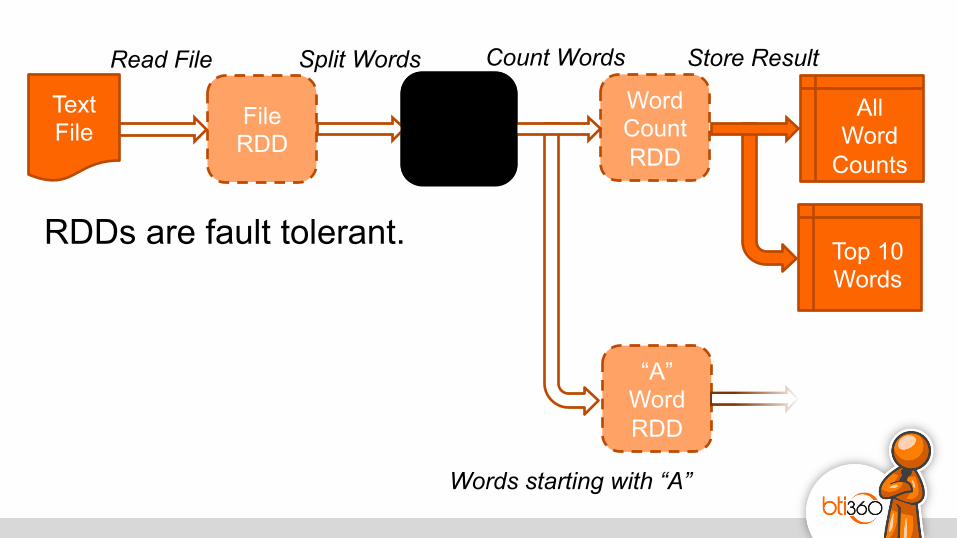
RDDs are fault tolerant.
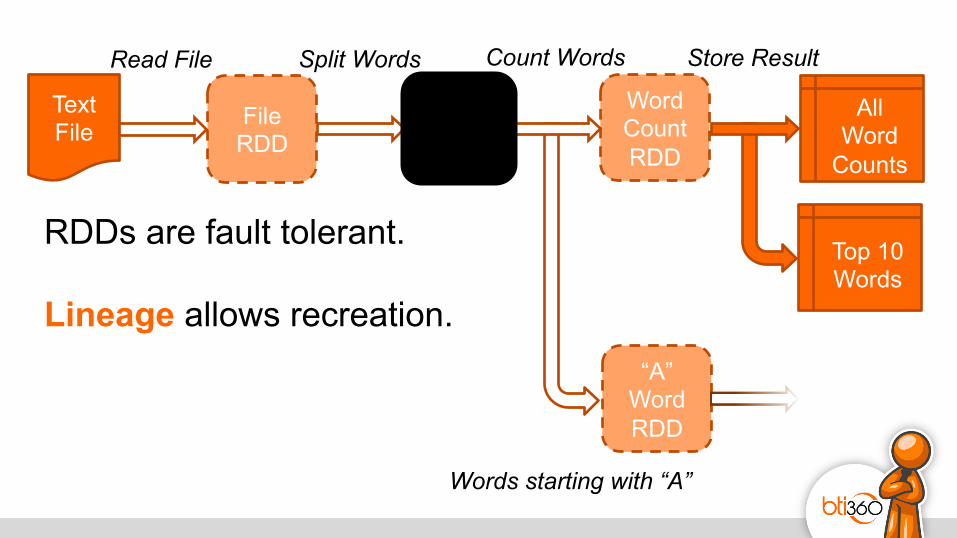
Text File
File RDD
Word RDD
Word Count RDD
All Word
Counts
Read File Split Words Count Words Store Result
Top 10 Words
“A” Word RDD
Words starting with “A”
RDDs are fault tolerant. Lineage allows recreation.

Once more, with code

Word Count Example
val input = sc.textFile(”hdfs://...") // HadoopRDD //Transformation val words = input.flatMap(line => line.split(" ")) //FlatMappedRDD //Transformation val result = words.map(word => (word, 1)).reduceByKey((acc, curr) => acc + curr) //Action val collectedResult = result.collect()

Image courtesy of http://blog.jetoile.fr

Cluster Basics
All product images owned by respective companies/institutions
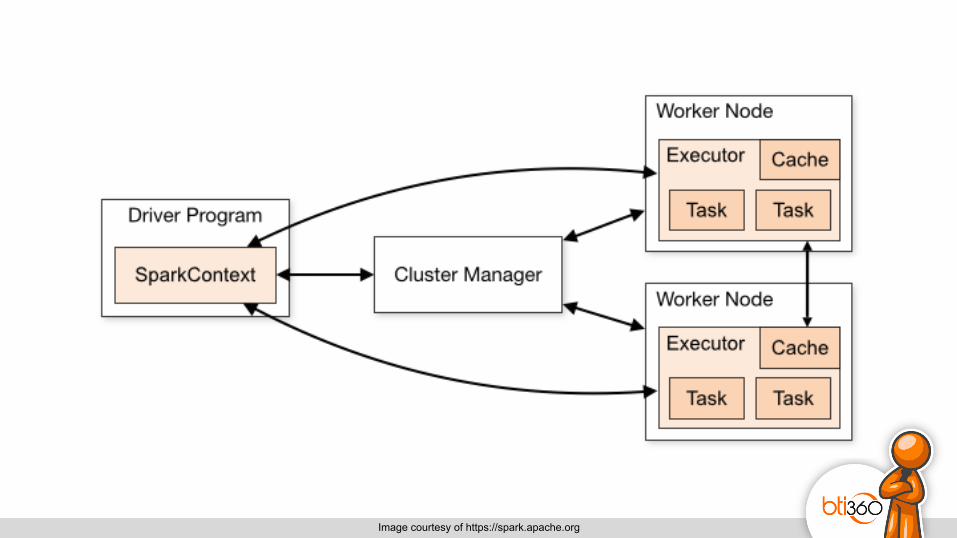
Image courtesy of https://spark.apache.org
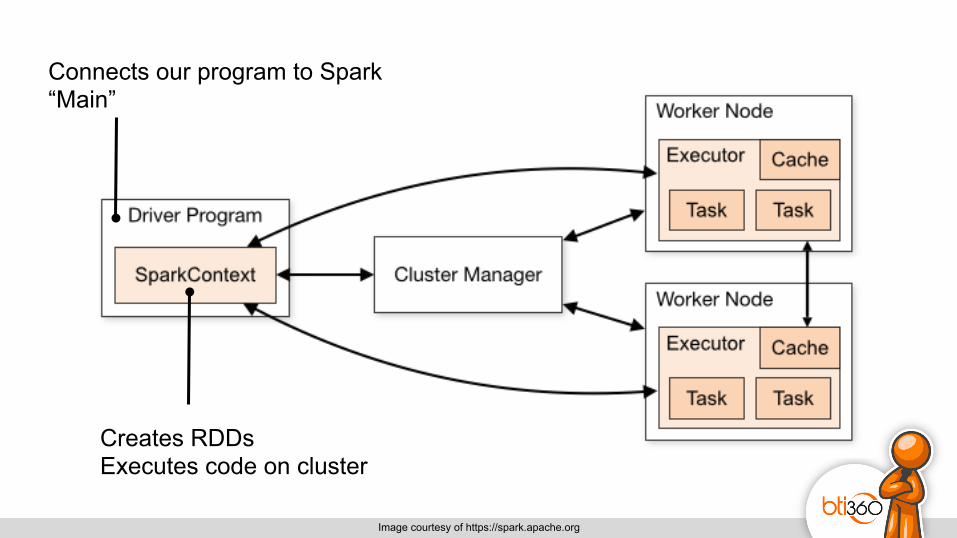
Image courtesy of https://spark.apache.org
Creates RDDs Executes code on cluster
Connects our program to Spark “Main”
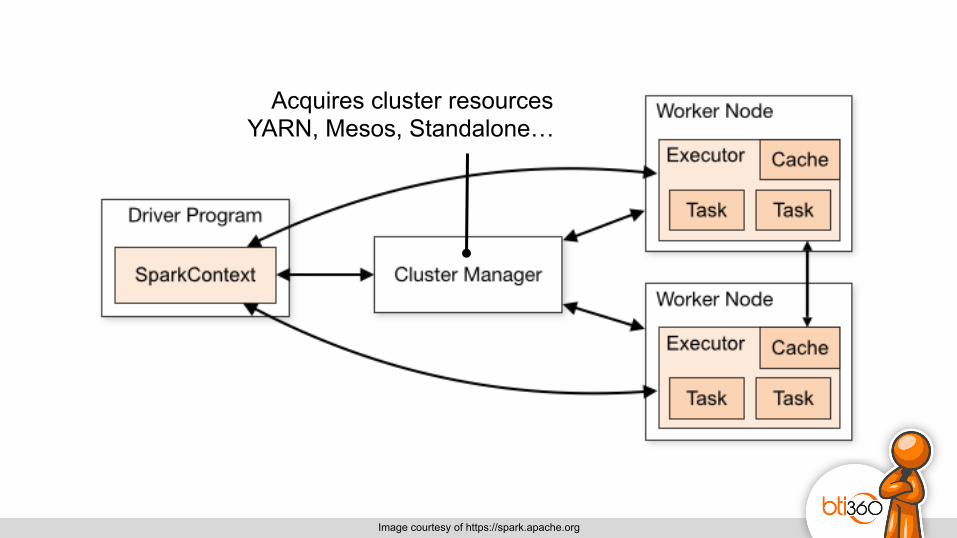
Image courtesy of https://spark.apache.org
Acquires cluster resources YARN, Mesos, Standalone…
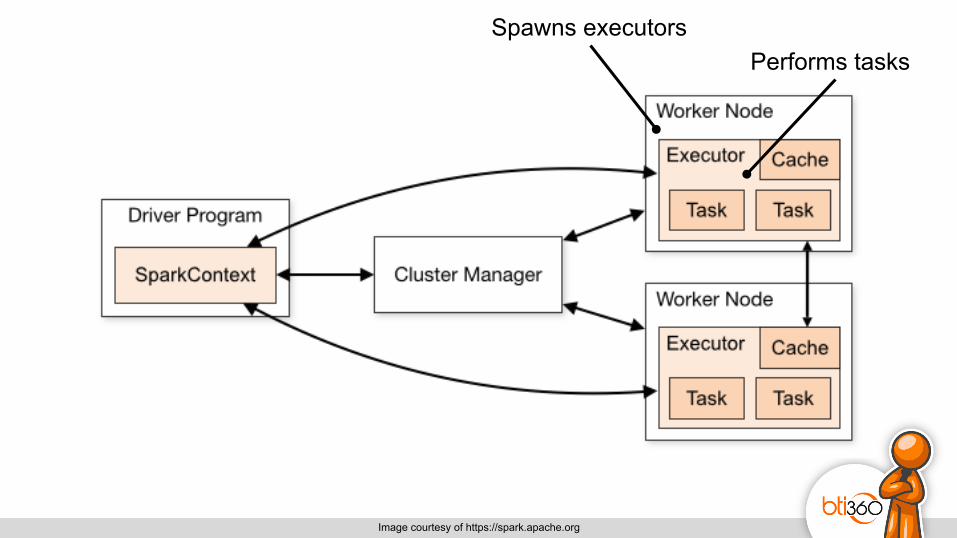
Image courtesy of https://spark.apache.org
Spawns executors Performs tasks
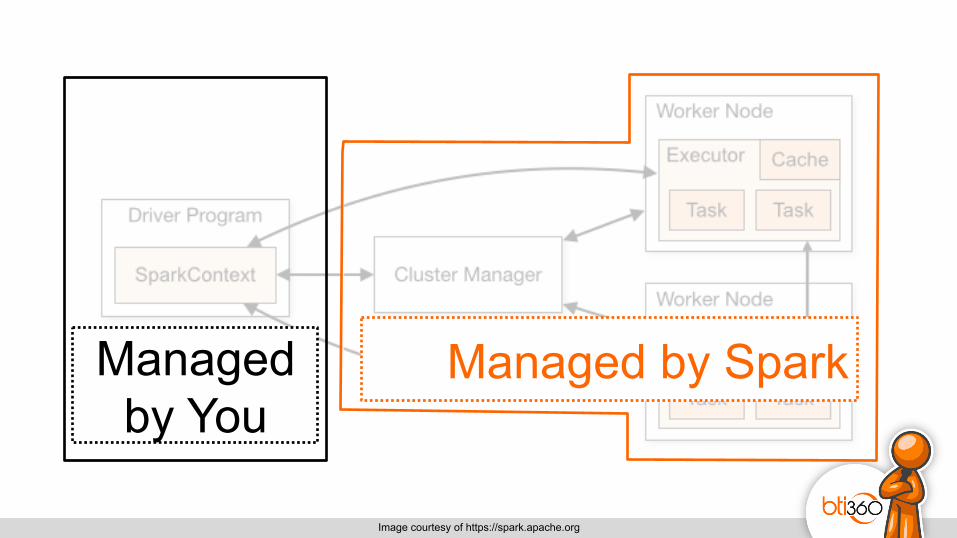
Image courtesy of https://spark.apache.org
Managed by Spark Managed by You

All product images owned by respective companies/institutions
In Action

Questions?

More Information on Spark
• https://spark.apache.org/docs/latest/index.html • http://www.cs.berkeley.edu/~matei/papers/2013/sosp_spark_streaming.pdf • http://www.cs.berkeley.edu/~matei/papers/2010/hotcloud_spark.pdf • http://www.cs.berkeley.edu/~matei/papers/2012/hotcloud_spark_streaming.pdf • http://www.cs.berkeley.edu/~matei/papers/2012/nsdi_spark.pdf • https://www.usenix.org/conference/nsdi12/technical-sessions/presentation/zaharia • http://www.meetup.com/Washington-DC-Area-Spark-Interactive/ • https://spark-summit.org/

Shared Variables
● Broadcast variables o Allows user to keep a read-only variable cached on each machine vs
shipping it with tasks. o e.g. lookup table
● Accumulators o workers can “add” to using associative operations o only driver can read o used for
§ counters § sums











![[@NaukriEngineering] Apache Spark](https://img.pdfslide.us/doc/110x75/588304451a28abe70d8b6157/naukriengineering-apache-spark.jpg)

















