Embed Size (px)
Citation preview

Click to add text
© 2011 IBM Corporation August 17, 2011
Improve the Speed and Performance
Samar Desai ([email protected]) Call-in details:

Information Management – IDS 11
© 2011 IBM Corporation 2
Talk Outline
Query Processing • Index Self Join • Update Statistics • Sorting
Index Optimization
• Partial Column • Forest of Trees
Fragmentation
Overview • Fragment by expression • Using Hash Functions • New Fragmentation
techniques
Miscellaneous
• External Tables • Pre-Load C-UDRs
Information Management – IDS 11
© 2011 IBM Corporation 3
Query Processing

Information Management – IDS 11
© 2011 IBM Corporation 4
Index Self Join

Information Management – IDS 11
© 2011 IBM Corporation 5
Purpose of Index Self Join
Improve performance on range based indexes scans which have highly duplicate lead keys
Improve use of subsequent parts of composite index when used with range expression

Information Management – IDS 11
© 2011 IBM Corporation 6
Situation
Composite index defined on columns (DayOfWeek, FamilySize, part, partdesc).
(DayOfWeek, FamilySize) have lots of duplicates
Only consider to use self joins on columns with distributions
Query: SELECT * FROM tab
WHERE (DayOfWeek >= 1 and DayOfWeek <= 5) AND (FamilySize >= 2 and FamilySize <= 4)
AND (part >= 100 and part <= 102)
Information Management – IDS 11
© 2011 IBM Corporation 7
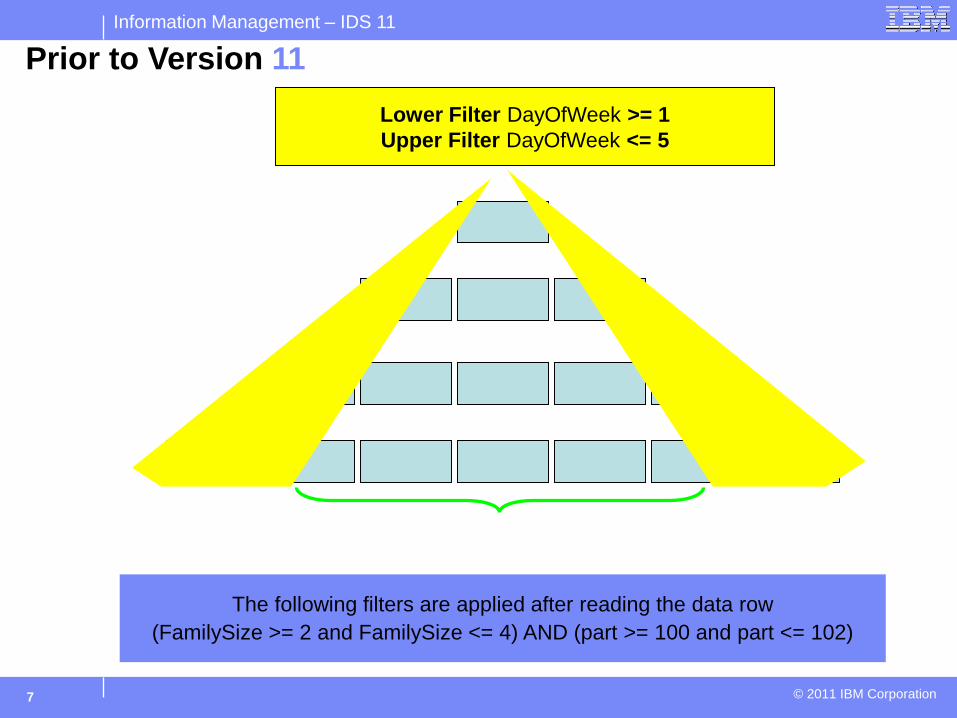
Prior to Version 11
Lower Filter DayOfWeek >= 1 Upper Filter DayOfWeek <= 5
The following filters are applied after reading the data row (FamilySize >= 2 and FamilySize <= 4) AND (part >= 100 and part <= 102)
Information Management – IDS 11
© 2011 IBM Corporation 8
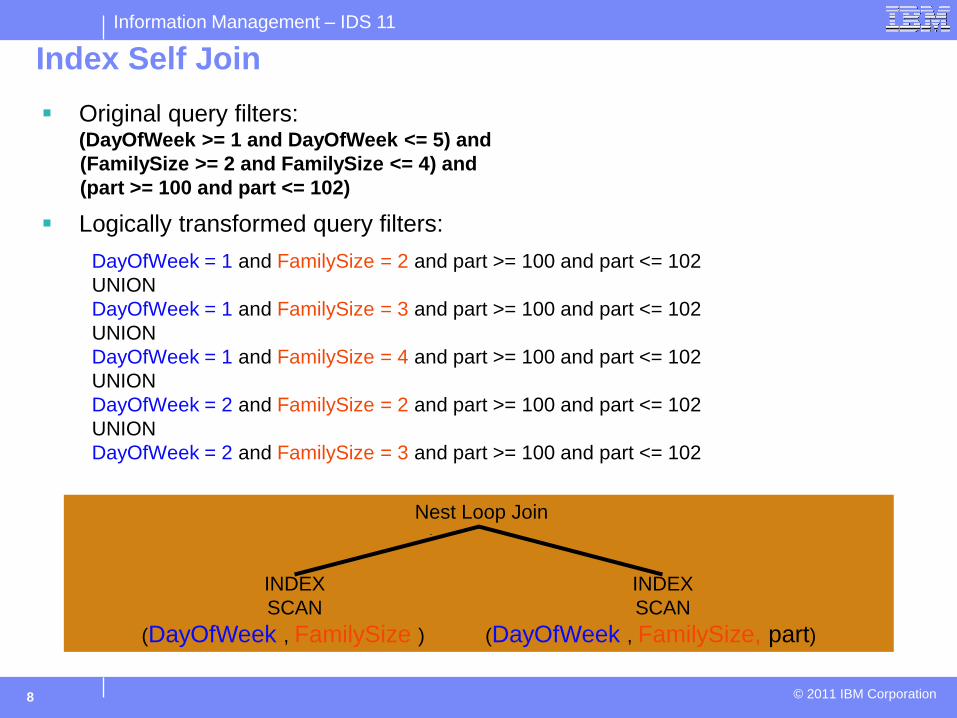
Index Self Join
Original query filters: (DayOfWeek >= 1 and DayOfWeek <= 5) and (FamilySize >= 2 and FamilySize <= 4) and (part >= 100 and part <= 102)
Logically transformed query filters:
DayOfWeek = 1 and FamilySize = 2 and part >= 100 and part <= 102 UNION DayOfWeek = 1 and FamilySize = 3 and part >= 100 and part <= 102 UNION DayOfWeek = 1 and FamilySize = 4 and part >= 100 and part <= 102 UNION DayOfWeek = 2 and FamilySize = 2 and part >= 100 and part <= 102 UNION DayOfWeek = 2 and FamilySize = 3 and part >= 100 and part <= 102
Nest Loop Join
INDEX INDEX SCAN SCAN
(DayOfWeek , FamilySize ) (DayOfWeek , FamilySize, part)
Information Management – IDS 11
© 2011 IBM Corporation 9
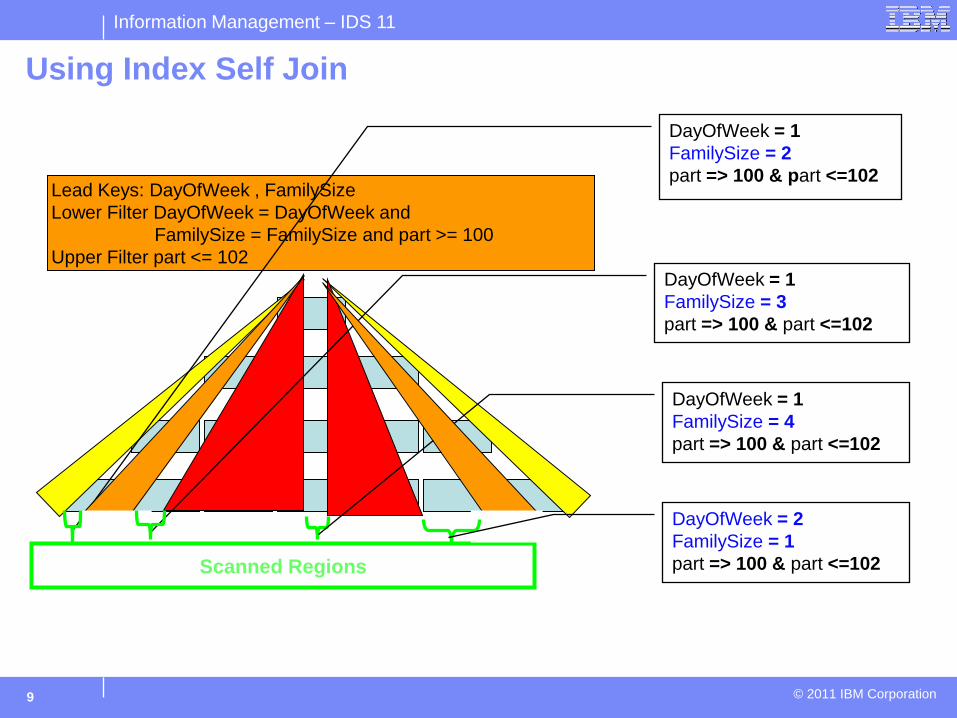
Using Index Self Join
Lead Keys: DayOfWeek , FamilySize Lower Filter DayOfWeek = DayOfWeek and FamilySize = FamilySize and part >= 100 Upper Filter part <= 102
Scanned Regions
DayOfWeek = 1 FamilySize = 2 part => 100 & part <=102
DayOfWeek = 1 FamilySize = 3 part => 100 & part <=102
DayOfWeek = 1 FamilySize = 4 part => 100 & part <=102
DayOfWeek = 2 FamilySize = 1 part => 100 & part <=102

Information Management – IDS 11
© 2011 IBM Corporation 10
Setup of Index Self Join Example
create raw table customer ( dayofweek integer, familysize integer, part integer, partdesc char(60) ) lock mode row; INSERT INTO customer SELECT mod(A.tabid,7), mod(A.tabid,4), value+A.tabid, tabname FROM sysmaster:systables A, sysmaster:sysshmhdr B, sysmaster:syscolumns WHERE B.number=4;
create index ix1 on customer (dayofweek,familysize,part,partdesc) insert into customer values (1,3,77,“JUICE"); insert into customer values (2,3,77," JUICE "); insert into customer values (3,3,78,“MILK"); insert into customer values (4,3,78," MILK "); insert into customer values (5,3,78," MILK "); insert into customer values (1,4,77," JUICE "); insert into customer values (2,4,77," JUICE "); insert into customer values (3,4,78," MILK "); insert into customer values (4,4,78," MILK "); insert into customer values (5,4,78," MILK ");

Information Management – IDS 11
© 2011 IBM Corporation 11
Sample Queries
Only difference is the directive
select {+ AVOID_INDEX_SJ(customer ix1) } count(*) from customer where dayofweek >=1 and dayofweek <=5 AND familysize>=3 and familysize<=4 and partnumber >76 and partnumber < 80; select count(*) from customer where dayofweek >=1 and dayofweek <=5 AND familysize>=3 and familysize<=4 and partnumber >76 and partnumber < 80;

Information Management – IDS 11
© 2011 IBM Corporation 12
Retrieving Query Results
SELECT sql_runtime,sql_bfreads,sql_pgreads,sql_statement[1,30] FROM sysmaster:syssqltrace WHERE sql_sid = DBINFO('sessionid') AND lower(sql_tablelist) matches "*customer*"
sql_runtime sql_bfreads sql_statement
1.0920813 303236 select {+ AVOID
0.3031994 92435 select count(*)

Information Management – IDS 11
© 2011 IBM Corporation 13
Add distributions to the second column in the index
Improving Results
update statistics high for table customer(familysize) distributions only;
sql_runtime sql_bfreads sql_statement
1.0920813 303236 select {+ AVOID
0.3031994 92435 select count(*)
0.0006977 142 select count(*)

Information Management – IDS 11
© 2011 IBM Corporation 14
Automatic Read Ahead
What is read ahead • Sequential scan read ahead • Index scan read ahead • Index/Data scan read ahead
Benefits of automatic read ahead
• Automatically detects when read ahead would improve the performance of a query
• Automatically detects when read ahead would not improve performance of a query
• Read ahead daemon • Query detects it waited on i/o so it submits a read ahead
request • Start read ahead from the point in the scan where the i/o
was detected • Leaf read ahead for index/data scans

Information Management – IDS 11
© 2011 IBM Corporation 15
A sequential scan of large tables which read pages in parallel from disk and store in private buffers in Virtual memory
Advantages of light scans for sequential scans: • Bypass the overhead of the buffer pool when many pages are
read • Prevent frequently accessed pages from being forced out of the
buffer pool • Transfer larger blocks of data in one I/O operation (64K/128K
platform dependent)
Conditions to invoke light scans: • The optimizer chooses a sequential scan of the table • The isolation level dirty read or a shared lock on the table
Monitor using onstat -g scn
What are Light Scans (Recap)?

Information Management – IDS 11
© 2011 IBM Corporation 16
onstat -g scn
• Displays the status of all scans using BATCHEDREAD
Monitoring Scans
RSAM sequential scan info
SesID Thread Partnum Rowid Rows Scan'd Scan Type Lock Mode 16 96 20002 8301 2708 Buffpool SLock+Test 16 97 30002 5b10 1898 Light Table
RSAM index scan info
SesID Thread Partnum Scan Type Lock Mode 15 129 20008 SLock+Test Start Key GTEQ :5: Stop Key GT :10: Current key :6: Current position: buffp 0 pagenum 3 slot 6 rowoff 4 flags 0

Information Management – IDS 11
© 2011 IBM Corporation 17
Update Statistics

Information Management – IDS 11
© 2011 IBM Corporation 18
Improved Optimizer Statistics •Auto Statistics on index creation •Improved Tracking of Update Statistics •Improved Temp Table Statistics •Auto Update Statistics

Information Management – IDS 11
© 2011 IBM Corporation 19
Create Index with Statistics
Statistics (i.e. update statistics high and low) are created automatically when an index is created either implicit or explicit.
Sample size is the data seen during the static phase of the online index build, catch up data is ignored.
Leverages the sorted data produced by create index
Little to no additional time is added to the create index

Information Management – IDS 11
© 2011 IBM Corporation 20
Tracking of Update Statistics
Low / Statistics • Columns added to systables to track last time low was run
SELECT ustlowts FROM SYSTABLES WHERE tabname = “foo”;
ustlowts 2006-09-26 11:42:50.00000
Medium & High / Distributions • Four new columns added to sysdistrib to track distribution creation
SELECT constr_time, smplsize, rowssmpld, ustnrows FROM sysdistrib WHERE colno=1 AND tabid = (SELECT tabid FROM systables WHERE tabname=‘foo’);
constr_time smplsize rowssmpld ustnrows
2007-09-07 13:43:59.00000 0.00 66.00000 66.00000

Information Management – IDS 11
© 2011 IBM Corporation 21
Temp Table Statistics Improvements
Users are no longer required to run update statistics low on temp tables.
• Number of rows and pages is updated every time we access the temp tables data dictionary entry.
• Adding indexes to temp tables will automatically create distributions and statistics for the temp table.

Information Management – IDS 11
© 2011 IBM Corporation 22
Improving Update Statistics
Fragment Level Statistics • When attaching a new fragment only the new fragments
needs to be scanned, not the entire table • Only fragments which have expired statistics are scanned
Defining statistics expiration policies at the table level Detailed tracking of modification to each table and fragment Automatically skipping tables or fragments whose statistics
are not expired ANSI database implicitly commit after each index/column
statistics is updated

Information Management – IDS 11
© 2011 IBM Corporation 23
Table Level Optimizer Statistics Policies
STATLEVEL • Defines the granularity of statistics created for a table
STATCHANGE
• Percentage of the table modified before table/fragment statistics are considered expired
CREATE TABLE …. STATLEVEL [ TABLE | FRAGMENT | AUTO ] STATCHANGE 1...100
TABLE Entire table is level statistics stored in sysdistrib catalog
FRAGMENT Each fragment has its own statistics stored in the new sysfragdist catalog
AUTO System automatically determines the STATLEVEL

Information Management – IDS 11
© 2011 IBM Corporation 24 24
New Syntax for “Smarter” Update Statistics
AUTO • Only tables or fragments having expired statistic are re-calculated
FORCE • All indexes and columns listed in the command will have their
statistics re-calculated
Default behavior is set by AUTO_STAT_MODE parameter • Enabled by default (i.e. AUTO)
UPDATE STATISTICS FOR TABLE …. [ AUTO | FORCE ]
Page 24

Information Management – IDS 11
© 2011 IBM Corporation 25
Customer Comment about Implementing DS_NONPDQ_QUERY_MEM
…CPU load average on the server dropped
from 90% during peak to less than 50%. I also tracked the actual CPU seconds that oninit was using before and after the change. During
peak times the oninit's for this instance was using 5 out of the 8 physical cpu's. After the
change we consume less than 3 cpu's.

Information Management – IDS 11
© 2011 IBM Corporation 26
PDQ – Enable PDQPRIORITY to allow more threads and
resources – Ensure DS_TOTAL_MEMORY in the onconfig file is set
properly – Make sure PSORT_NPROCES is set to the number of
CPU VPs – DS_MAX_QUERIES is set
Large Sort Tasks
If large sorting batch jobs run at night consider dynamically increase this at the start of the evening and resetting it to its
original value in the early morning with onmode -M

Information Management – IDS 11
© 2011 IBM Corporation 27
Selecting only the First Set of Rows
First rows can be optimized by not requiring the entire result set be returned
– SELECT FIRST N • Used to limit the number of rows returned from the query
– SKIP & FIRST
• Return the 7 to 17 row
SELECT SKIP 7 FIRST 10 * FROM employees
SELECT FIRST 10 * FROM employees

Information Management – IDS 11
© 2011 IBM Corporation 28
First Rows Optimizer Directive
Optimizer to choose the query plan that returns the first record as soon as possible
Always prefers pipeline operations versus blocking operations – Pipeline operations
• Nest loop Join • Index Scans
– Blocking operations • Sorts • Hash Joins
SELECT {+ first_rows } * FROM employees

Information Management – IDS 11
© 2011 IBM Corporation 29
First Rows Optimization
Very fast to retrieve the first few rows To process the entire query can takes more resources
and time Set in either: ONCONFIG parameter, Application
Statement, Optimizer directive
FIRST_ROWS ALL_ROWS
Time for first row returned
1 second 12 seconds
Time for last row returned
62 seconds 15 seconds

Information Management – IDS 11
© 2011 IBM Corporation 30
Index Optimization

Information Management – IDS 11
© 2011 IBM Corporation 31
Partial Column Index
Ability to create an index on the first N bytes of string column
Benefits
– Smaller index size, few pages – Faster searching for long character strings which
are unique in the beginning
create index index1 on tab1(col1(3));

Information Management – IDS 11
© 2011 IBM Corporation 32
Create Index with a Specific Extent Size Create Index with a Specific Extent Size
• The create index syntax has been enhanced to support the addition of an extent size for indexes
• Better sizing and utilization
Default index extent size is the
• index key size / data row size * data extent size
CREATE INDEX index_1 ON tab_1(col_1) EXTENT SIZE 32 NEXT SIZE 32;

Information Management – IDS 11
© 2011 IBM Corporation 33
Creating Constraints without an Index
Saves the overhead of the index for small child tables Bang for the Buck
• When the ratio of rows between the parent and the child exceed 10,000
• Removes indexes with large number of duplicates
CREATE TABLE parent(c1 INT PRIMARY KEY CONSTRAINT parent_c1, c2 INT, c3 INT);
CREATE TABLE child(x1 INT, x2 INT, x3 VARCHAR(32));
ALTER TABLE child ADD CONSTRAINT (FOREIGN KEY(x1) REFERENCES parent(c1) CONSTRAINT cons_child_x1 INDEX DISABLED);
Information Management – IDS 11
© 2011 IBM Corporation 34
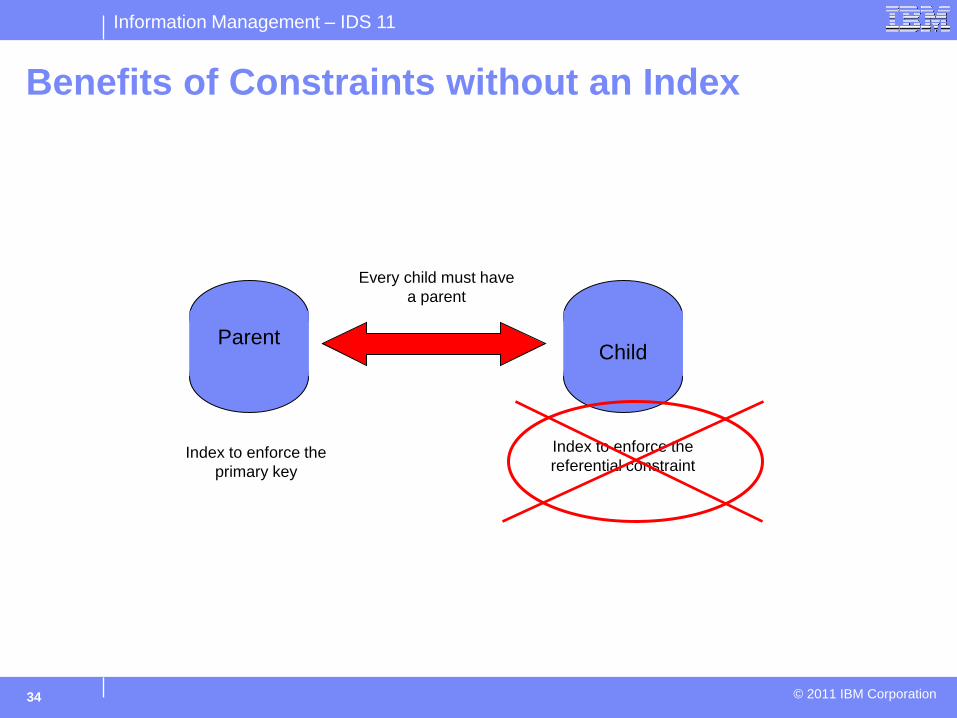
Benefits of Constraints without an Index
Parent Child
Every child must have a parent
Index to enforce the primary key
Index to enforce the referential constraint
Information Management – IDS 11
© 2011 IBM Corporation 35
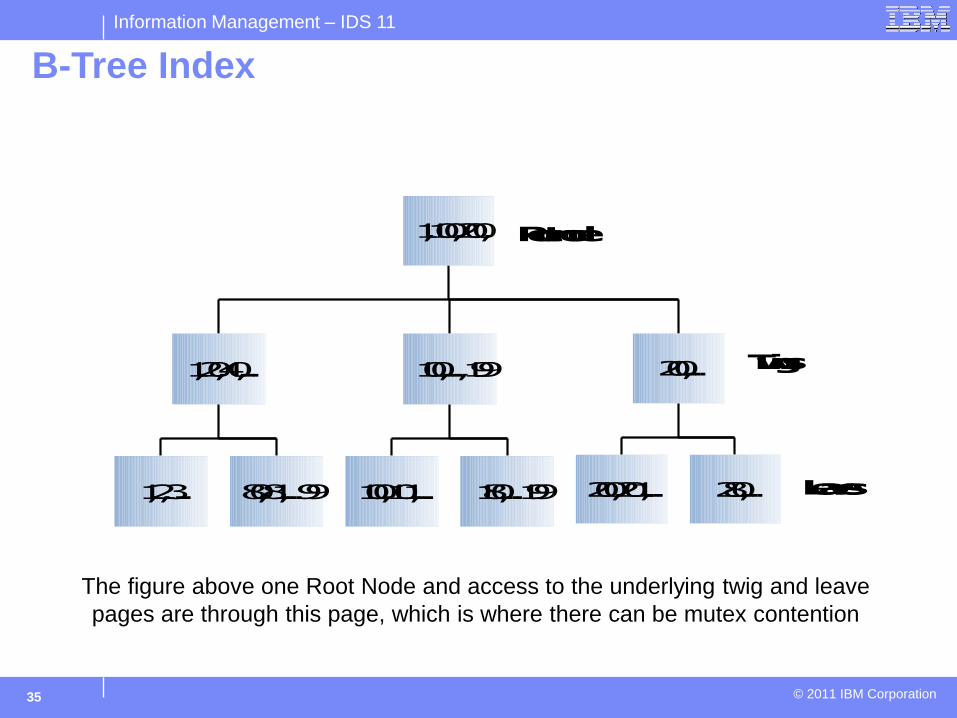
B-Tree Index
1,20,40,... 100,...,199 200,...
1,100,200,
1,2,3... 80,81,...99 100,101,... 180,...199 200,201,... 280,...
Rootnode
Twigs
Leaves
The figure above one Root Node and access to the underlying twig and leave pages are through this page, which is where there can be mutex contention

Information Management – IDS 11
© 2011 IBM Corporation 36
New Index Type “Forest Of Trees”
Traditional B-tree index suffer from performance issues when many concurrent users access the index • Root Node contention can occur when many session are reading
the same index at the same time • The depth of large B-tree index increases the number of levels
created, which results in more buffer reads required
Forest Of Tress (FOT) reduces some of the B-tree
index issues: • Index is larger but often not deeper
Reduces the time for index traversals to leaf nodes • Index has multiple subtrees (root nodes) called buckets
Reduces root node contention by enabling more concurrent users to access the index

Information Management – IDS 11
© 2011 IBM Corporation 37
Forrest of Trees Index (FOT Index) Reduces contentions on an indexes root
node Several root nodes Some B-Tree functional is NOT supported
• max() and min()
Hash on key value to pick a bucket /rootnode
Bucket 1 Bucket 2 Bucket 3
2,189,... 1,198,... 4,201,...
2,... 189,... 1,... 198,... 4,... 201,...
Rootnodes
Leaves
Key Value Bucket
1 2
2 1
3 2
... ...
47 3
221 1
create index index_2 on TAB1( C1, C2 ) hash on ( C1 ) with 3 buckets;

Information Management – IDS 11
© 2011 IBM Corporation 38
Check oncheck –pT information
Check sysmaster database
select nhashcols, nbuckets from sysindices
Average Average
Level Total No. Keys Free Bytes
----- -------- -------- ----------
1 100 27 21350
2 655 15 4535
----- -------- -------- ----------
Total 755 42 25885
There are 100 Level 1 buckets (Root Nodes)
FOT - Determining use - ONCHECK & SYSMASTER

Information Management – IDS 11
© 2011 IBM Corporation 39
When to use a FOT Index
Lead index column(s) using equality predicates Contention on the root node of an index
– onstat -g spi | sort -nr
Spin locks with waits: Num Waits Num Loops Avg Loop/Wait Name 121434 8283634 68.22 fast mutex, 0:bf[421226] 0x30000b 0x83d61000 9362 644934 68.89 fast mutex, 0:bf[388111] 0x300009 0x7fcb3800 7864 519351 66.04 fast mutex, 0:bf[410993] 0x30000a 0x82964800

Information Management – IDS 11
© 2011 IBM Corporation 40
Fragmentation Overview Introduction to Fragmentation Defining Fragmented Tables Altering/Attach/Detach Monitoring/Guidelines New Fragmentation Schemes

Information Management – IDS 11
© 2011 IBM Corporation 41
What is Fragmentation?
Also called “Table Partitioning” Fragmentation is a database server feature that
allows you to – Distribute data for a table across separate dbspaces or
partitions – Control where data is stored at the row level
Transparent to end users and client applications
– No changes for applications whether the table is fragmented or not fragmented
– Optimizer automatically takes advantage of the fragment expression
Information Management – IDS 11
© 2011 IBM Corporation 42
Data in a non-fragmented table
Feb
Jan
Mar
Information Management – IDS 11
© 2011 IBM Corporation 43
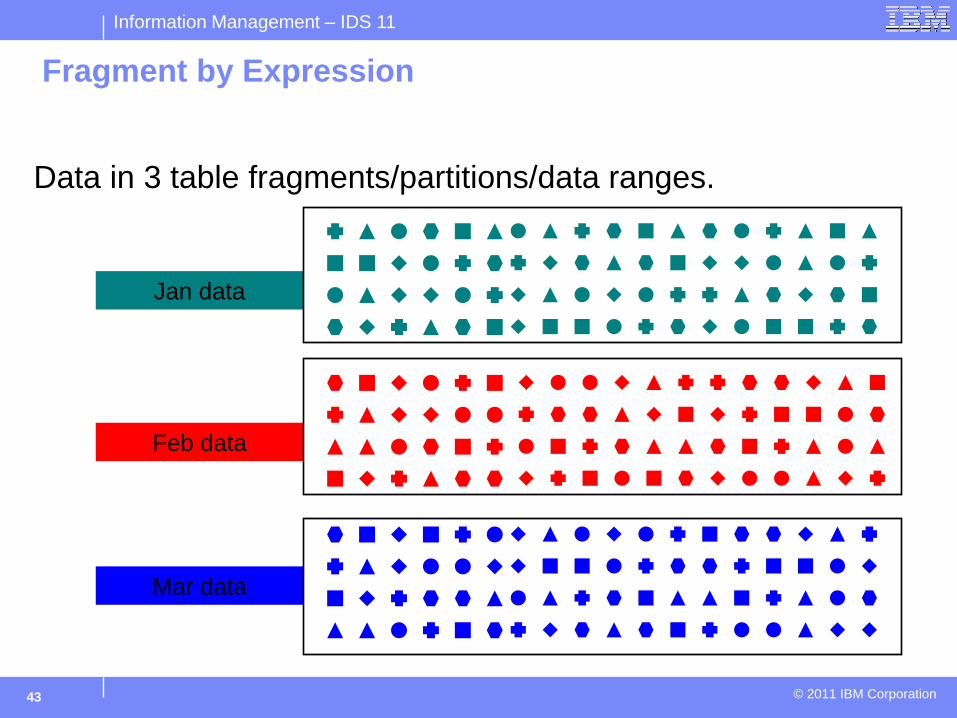
Fragment by Expression
Feb data
Jan data
Mar data
Data in 3 table fragments/partitions/data ranges.

Information Management – IDS 11
© 2011 IBM Corporation 44
Create a Fragmented Table
This syntax (fragments/partitions in different dbspaces) works on all IDS versions.
CREATE TABLE employee (
empnum SERIAL, ... ) FRAGMENT BY EXPRESSION empnum <= 2500 IN dbspace1, empnum <= 5000 AND empnum > 2500 IN dbspace2, empnum > 5000 IN dbspace3 EXTENT SIZE 100 NEXT SIZE 60 LOCK MODE ROW;

Information Management – IDS 11
© 2011 IBM Corporation 45
Using Hash Functions
CREATE TABLE employee ( empnum serial, empname char(50) ) FRAGMENT BY EXPRESSION partition p1 mod(empnum,3) = 0 in rootdbs, partition p2 mod(empnum,3) = 1 in rootdbs, partition p3 mod(empnum,3) = 2 in rootdbs;
Hash expression allows fragment elimination when there is an equality search (including inserts and deletes).
Useful when data is accessed via a particular column but the distribution of values within the column is not known.

Information Management – IDS 11
© 2011 IBM Corporation 46
Using Hash Functions
Only 2/3 of the table is scanned Scans a single fragment at a time
QUERY: (OPTIMIZATION TIMESTAMP: 09-12-2007 17:37:43) ------ select * from employee where empnum in( 6, 7)
Estimated Cost: 3 Estimated # of Rows Returned: 1
1) informix.employee: SEQUENTIAL SCAN (Serial, fragments: 0, 1)
Filters: informix.employee.empnum IN ( 6, 7 )

Information Management – IDS 11
© 2011 IBM Corporation 47
Using Hash Functions with PDQ
One fragment eliminated, Two fragments scan simultaneous
QUERY: (OPTIMIZATION TIMESTAMP: 09-12-2007 17:37:43) ------ select * from employee where empnum in( 6, 7)
Estimated Cost: 3 Estimated # of Rows Returned: 1
1) informix.employee: SEQUENTIAL SCAN (Parallel, fragments: 0, 1)
Filters: informix.employee.empnum IN ( 6, 7 )

Information Management – IDS 11
© 2011 IBM Corporation 48
Why Fragment?
Fragment Elimination – Improve query performance. – A large table can perform like a smaller one.
Larger Tables
– Internally, each table fragment is treated like a table. So, some limits/properties that apply to a table (like maximum number of extents) apply to each fragment/partition.
Balanced I/O If using PDQ, parallel scans, inserts, joins,
sorts, aggregates, groups. (DSS systems)

Information Management – IDS 11
© 2011 IBM Corporation 49
Indexes on Fragmented Tables
If you do not want to fragment your index, specify the dbspace to put the index in
CREATE INDEX <idx1>... IN DBSPACE <dbspace1>;
If dbspace is NOT specified, index will be fragmented, following the fragmentation scheme of the table -- BAD if table is fragmented by ROUND ROBIN.
Index

Information Management – IDS 11
© 2011 IBM Corporation 50
Create Index Statement
Index fragmented by expression
Index not fragmented
•Index follows tables fragmentation schema
CREATE INDEX idx1 ON table1(col1) FRAGMENT BY EXPRESSION col1 < 10000 IN dbspace1, col1 >= 10000 IN dbspace2;
CREATE INDEX idx1 ON table1(col1) IN dbspace1;
CREATE INDEX idx1 ON table1(col1);

Information Management – IDS 11
© 2011 IBM Corporation 51
Two New Fragmentation Schemes
List Fragmentation • Fragments data based on a list of discrete values • Helps in logical segregation of data • Useful when a table has finite set of values for the
fragment key and queries on table have equality predicate on the fragment key
Interval Fragmentation
• Fragments data based on an interval (numeric or time) value
• Tables have an initial set of fragments defined by a range expression
• When a row is inserted that does not fit in the initial range fragments, Informix automatically creates a fragment to hold the row

Information Management – IDS 11
© 2011 IBM Corporation 52
List Fragmentation
Fragments data based on a list of discrete values • e.g. states in the country or departments in an
organization Table below is fragmented on column “state” – also
known as fragment key or partitioning key
CREATE TABLE customer (cust_id INTEGER, name VARCHAR(128), street VARCHAR(128), state CHAR(2), zipcode INTEGER, phone CHAR(12)) FRAGMENT BY LIST (state) PARTITION p0 VALUES ("WA","OR", "AZ") in rootdbs, PARTITION p1 VALUES ("CA") in rootdbs, PARTITION p2 VALUES (NULL) in rootdbs, PARTITION p4 REMAINDER in rootdbs;
Fragment Key List Values

Information Management – IDS 11
© 2011 IBM Corporation 53
Details of Interval Fragmentation
Fragments data based on an interval (numeric or time) value
Table’s initial set of fragment(s) are defined by a range
expression
When a row is inserted that does not fit in the initial range fragments • Informix automatically creates a fragment to hold the row • No exclusive access required for fragment addition • No DBA intervention
Purging a range can be done with a detach and drop • No exclusive access is required
If dbspace selected for the interval fragment is full or down, Informix will skip those dbspaces and select the next one in the list

Information Management – IDS 11
© 2011 IBM Corporation 54
Example of Interval Fragmentation with Integers
CREATE TABLE orders (order_id INTEGER, cust_id INTEGER, order_date DATE, order_desc LVARCHAR)
FRAGMENT BY RANGE (order_id) INTERVAL( 10000 ) STORE IN (dbs1, dbs2, dbs3) PARTITION p0 VALUES < 100000 in rootdbs;
Fragment Key Interval Expression
List of DBSpaces
Initial Value
Information Management – IDS 11
© 2011 IBM Corporation 55
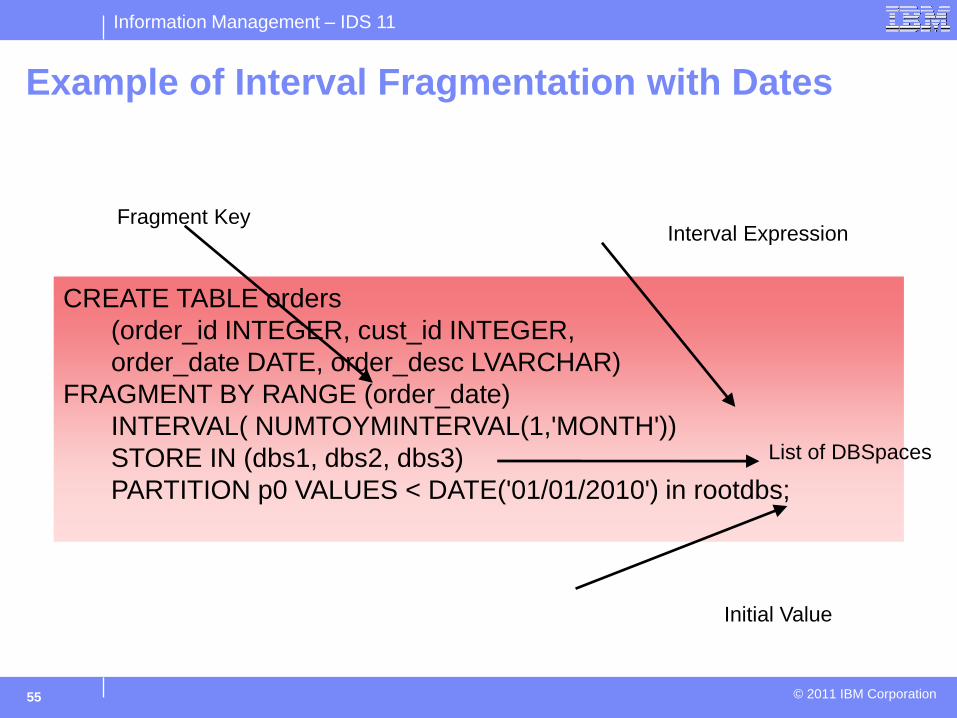
Example of Interval Fragmentation with Dates
CREATE TABLE orders (order_id INTEGER, cust_id INTEGER, order_date DATE, order_desc LVARCHAR)
FRAGMENT BY RANGE (order_date) INTERVAL( NUMTOYMINTERVAL(1,'MONTH')) STORE IN (dbs1, dbs2, dbs3) PARTITION p0 VALUES < DATE('01/01/2010') in rootdbs;
Fragment Key Interval Expression
List of DBSpaces
Initial Value

Information Management – IDS 11
© 2011 IBM Corporation 56
Usage Example of Interval Fragmentation with Dates
CREATE TABLE orders (order_id INTEGER, cust_id INTEGER, order_date DATE, order_desc LVARCHAR)
FRAGMENT BY RANGE (order_date) INTERVAL( NUMTOYMINTERVAL(1,'MONTH')) STORE IN (dbs1, dbs2, dbs3) PARTITION p0 VALUES < DATE('01/01/2010') in rootdbs;
What happens when you insert into order_date “07/07/2010”?
A new fragment is automatically allocated for the month of July and will hold values 7/1/2010 through 7/31/2010
What happens when you insert into order_date “10/10/2009”?
The value is insert into the existing partition p0
Information Management – IDS 11
© 2011 IBM Corporation 57
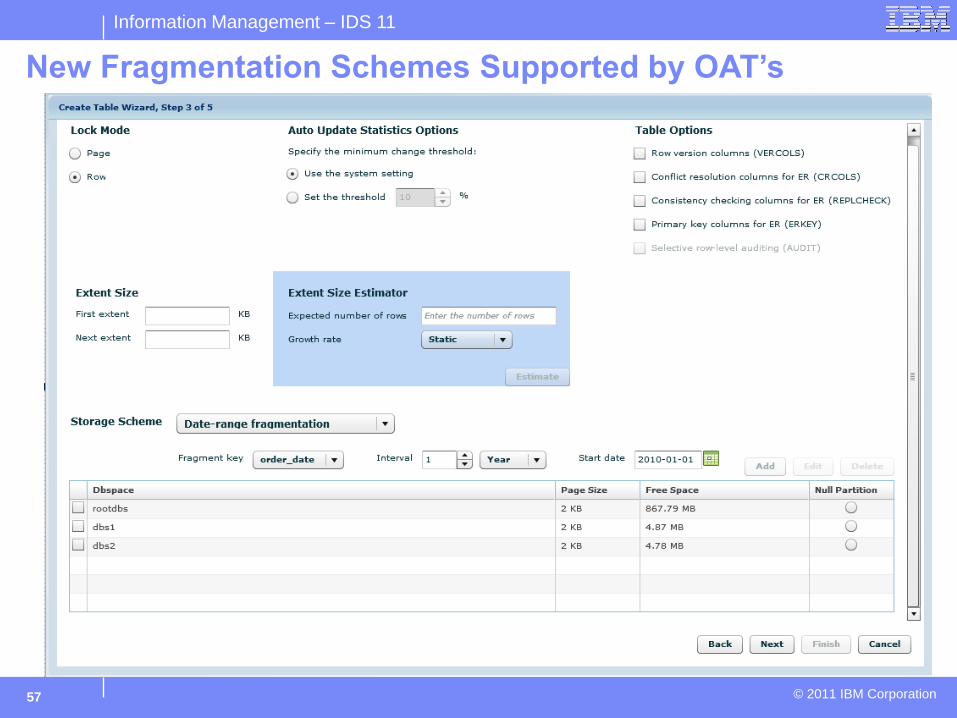
New Fragmentation Schemes Supported by OAT’s

Information Management – IDS 11
© 2011 IBM Corporation 58
External Tables

Information Management – IDS 11
© 2011 IBM Corporation 59
What Are External Tables
A table where the data is managed outside of the database
Most SQL operations Support, such as, select, insert, merge,…
A variety of formats – Internal Informix format – ASCII formats CSV, delimited, fixed with
Parallelism supported – Requires PDQPRIORITY for executing in parallel – Both input and output sides can run in parallel
Advantages over current load/unload utilities – Faster than any other load/unload tool – Data is manipulated inside the engine and not transferred to
a client application
Information Management – IDS 11
© 2011 IBM Corporation 60
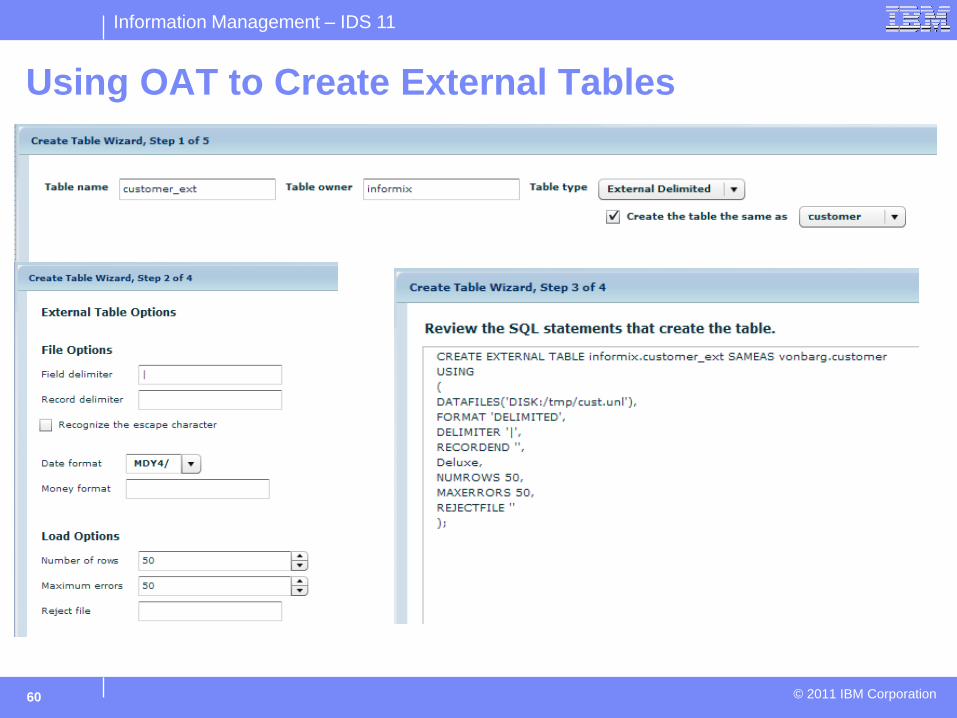
Using OAT to Create External Tables
Information Management – IDS 11
© 2011 IBM Corporation 61
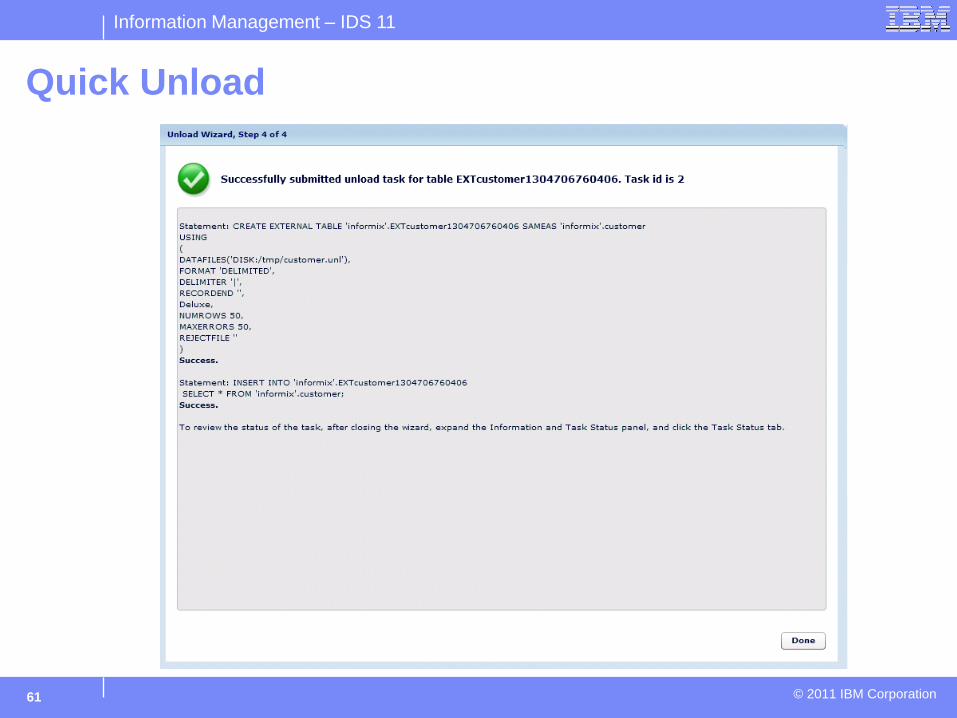
Quick Unload

Information Management – IDS 11
© 2011 IBM Corporation 62
A Few Uses for External Tables
Unload and load in Stored Procedures Programmatic way of writing data out to pipes Tailored dbexport/dbimport
– Parallel – Able to dirty read data

Information Management – IDS 11
© 2011 IBM Corporation 63 63
Improve Throughput of C User Defined Routines (C-UDR)
Preloading a C-UDR shared library allows Informix threads to migrate from one VP to another during the execution of the C-UDR • Increase in performance • Balance workloads
Without this feature • The C UDR shared libraries are loaded when the UDRs are first
used
• The thread executing the UDR is bound to the VP for the duration of the C-UDR execution
PRELOAD_DLL_FILE $INFORMIXDIR/extend/test.udr PRELOAD_DLL_FILE /var/tmp/my_lib.so
Page 63

Information Management – IDS 11
© 2011 IBM Corporation 64 64
Verifying the C-UDR shared library is preloaded
online.log during server startup
14:23:41 Loading Module </var/tmp/test.udr>
14:23:41 The C Language Module </var/tmp/test.udr> loaded
onstat –g dll new flags • ‘P’ represents preloaded • ‘M’ represents thread can migrate
Datablades:
addr slot vp baseaddr flags filename
0x4b247310 15 1 0x2a985e3000 PM
/var/tmp/test.udr
0x4c2bc310 15 2 0x2a985e3000 PM
0x4c2e5310 15 3 0x2a985e3000 PM

Information Management – IDS 11
© 2011 IBM Corporation 65





























