Embed Size (px)
Citation preview

Introduction
Swapnil Bawaskar@sbawaskar

• Introduction • What? • Who? • Why? • How?
• Q&A
2
Agenda

3
What?

4
What is it?

A distributed, memory-based data management platform for data oriented apps that need: • high performance, scalability, resiliency and continuous
availability • fast access to critical data set • location aware distributed data processing • event driven data architecture
5
What is it?

6
Who?
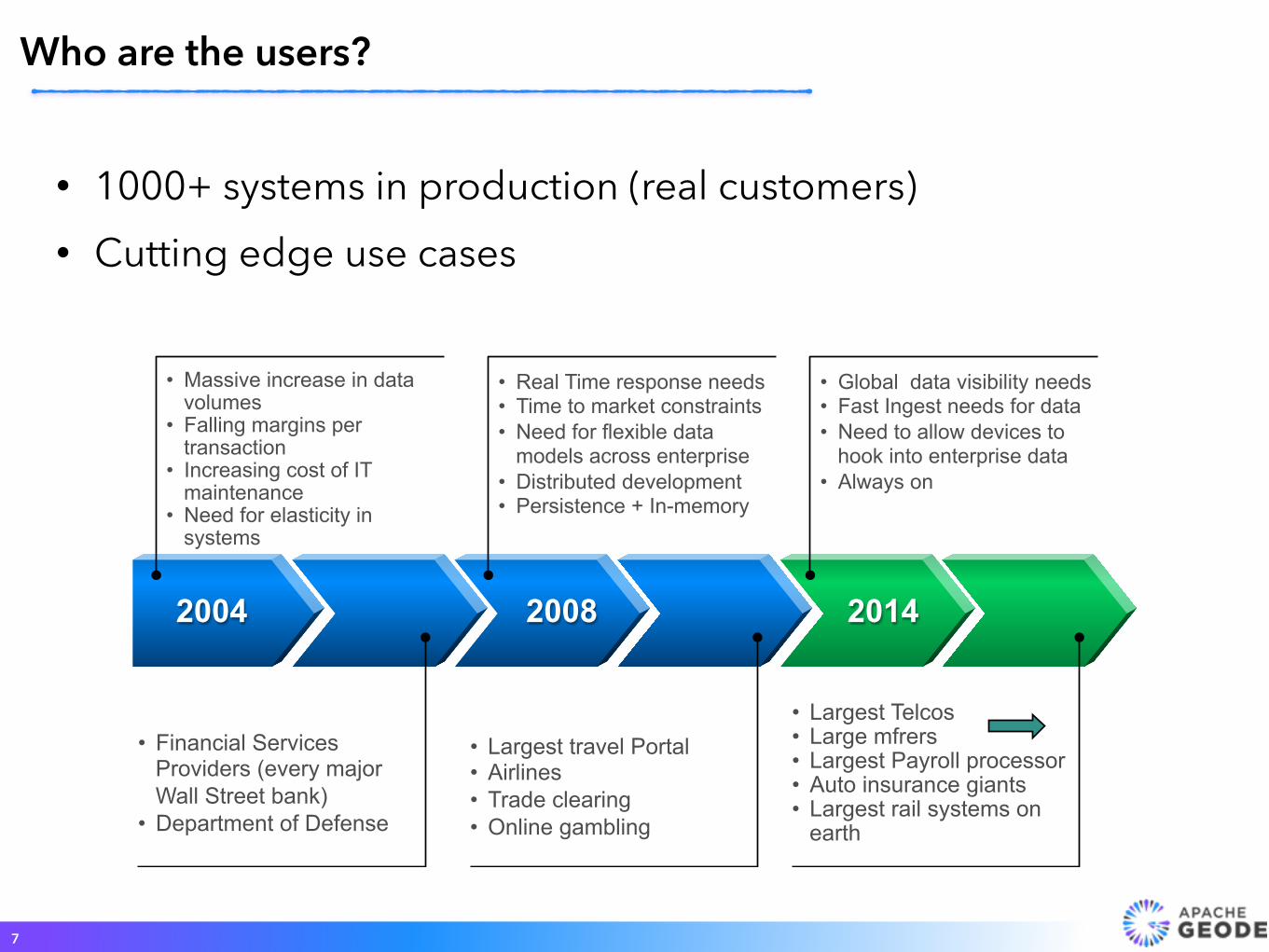
• 1000+ systems in production (real customers) • Cutting edge use cases
7
Who are the users?
2004 2008 2014
• Massive increase in data volumes
• Falling margins per transaction
• Increasing cost of IT maintenance
• Need for elasticity in systems
• Financial Services Providers (every major Wall Street bank)
• Department of Defense
• Real Time response needs • Time to market constraints • Need for flexible data
models across enterprise • Distributed development • Persistence + In-memory
• Global data visibility needs • Fast Ingest needs for data • Need to allow devices to
hook into enterprise data • Always on
• Largest travel Portal • Airlines • Trade clearing • Online gambling
• Largest Telcos • Large mfrers • Largest Payroll processor • Auto insurance giants • Largest rail systems on
earth

• 17 billion records in memory • GE Power & Water's Remote Monitoring & Diagnostics Center
• 3 TB operational data in-memory, 400 TB archived • China Railways
• 4.6 Million transactions a day / 40K transactions a second • China Railways
• 120,000 Concurrent Users • Indian Railways
8
Who are the users?

World: ~7,349,000,000
~36% of the world population
Population: 1,251,695,6161,401,586,609
China RailwayCorporation
Indian Railways

10
Why?

Numbers Everyone Should Know
11
L1 cache reference 0.5 ns Branch mispredict 5 ns L2 cache reference 7 ns Mutex lock/unlock 100 ns Main memory reference 100 ns Compress 1K bytes with Zippy 10,000 ns 0.01 ms Send 1K bytes over 1 Gbps network 10,000 ns 0.01 ms Read 1 MB sequentially from memory 250,000 ns 0.25 ms Round trip within same datacenter 500,000 ns 0.5 ms Disk seek 10,000,000 ns 10 ms Read 1 MB sequentially from network 10,000,000 ns 10 ms Read 1 MB sequentially from disk 30,000,000 ns 30 ms Send packet CA->Netherlands->CA 150,000,000 ns 150 ms
http://static.googleusercontent.com/media/research.google.com/en/us/people/jeff/stanford-295-talk.pdf

What makes it fast?• No ORM
• Minimize copying
• Minimize contention points
• Run user code in-process
• Partitioning and parallelism
• Avoid disk seeks
• Automated benchmarks

YCSB
13
oper
atio
ns p
er s
econ
d
0
200000
400000
600000
800000
YCSB Workloads
A Re
ads
A U
pdat
es
B Re
ads
B U
pdat
es
C R
eads
D In
serts
D R
eads
F Re
ads
F U
pdat
es
CassandraGeode
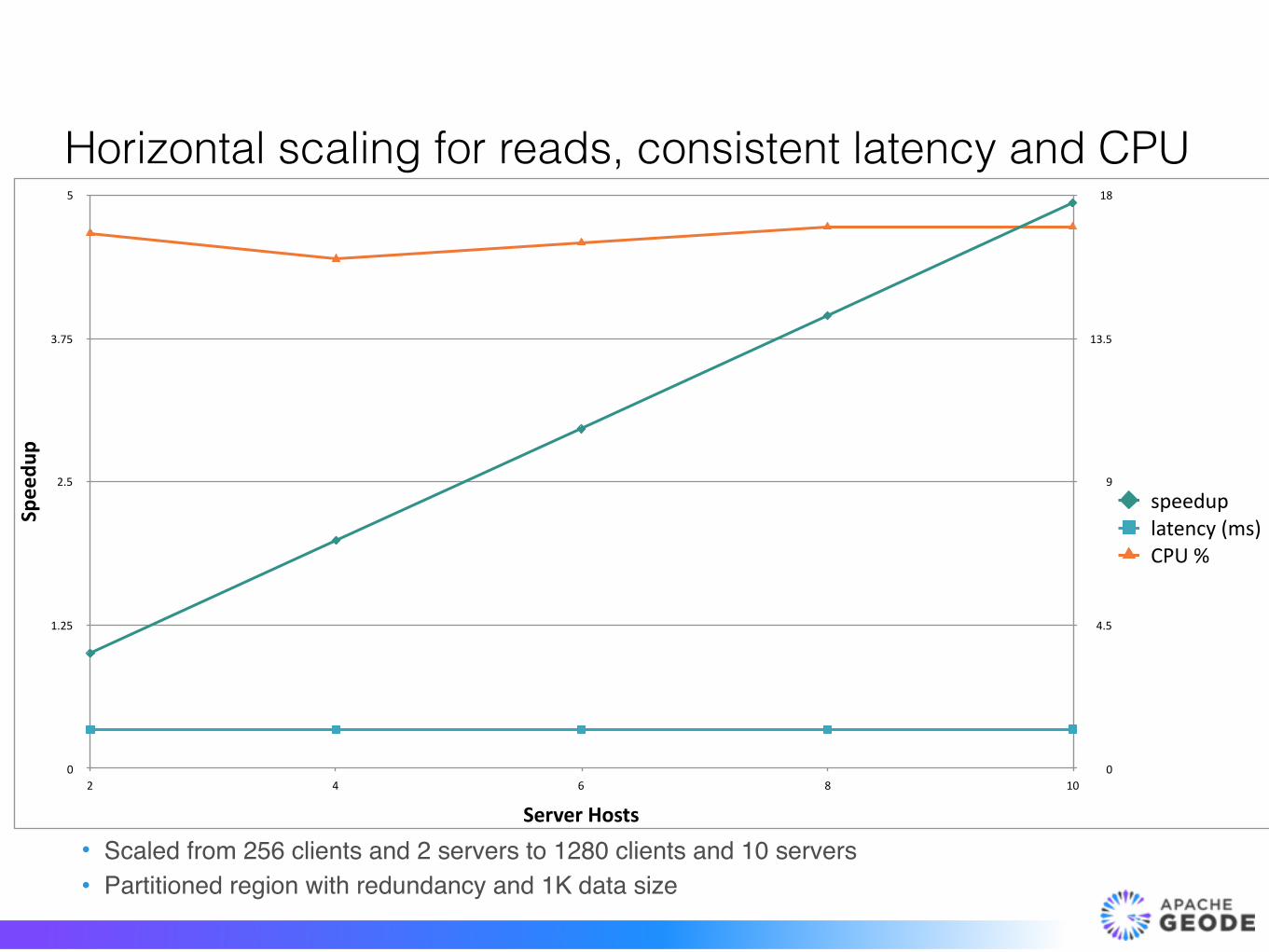
Horizontal scaling for reads, consistent latency and CPU
0
4.5
9
13.5
18
Speedu
p
0
1.25
2.5
3.75
5
ServerHosts2 4 6 8 10
speeduplatency(ms)CPU%
• Scaled from 256 clients and 2 servers to 1280 clients and 10 servers• Partitioned region with redundancy and 1K data size

15
How?
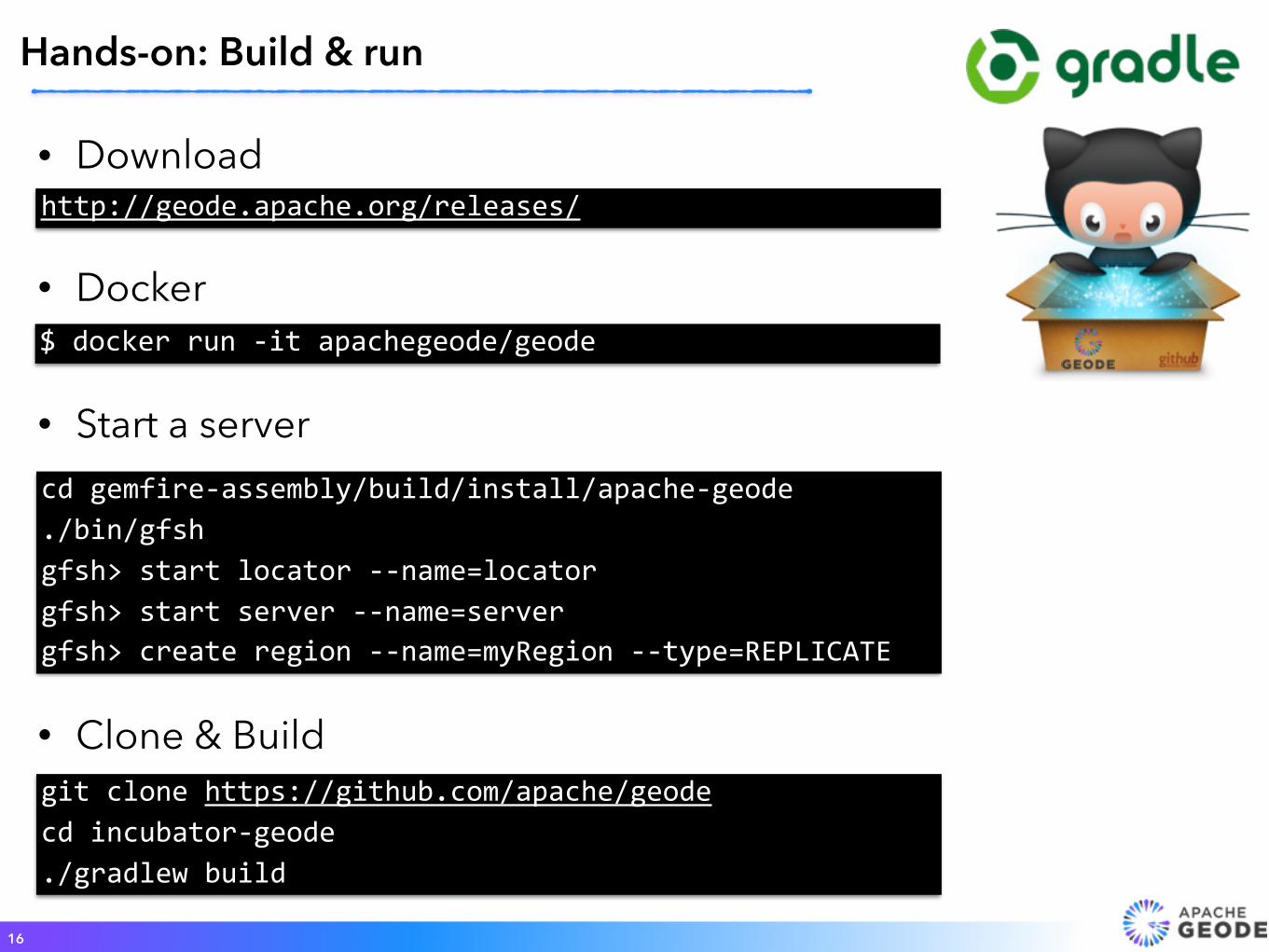
• Clone & Build
16
Hands-on: Build & run
gitclonehttps://github.com/apache/geodecdincubator-geode./gradlewbuild
• Start a servercdgemfire-assembly/build/install/apache-geode./bin/gfshgfsh>startlocator--name=locatorgfsh>startserver--name=servergfsh>createregion--name=myRegion--type=REPLICATE
$dockerrun-itapachegeode/geode
• Docker
• Downloadhttp://geode.apache.org/releases/
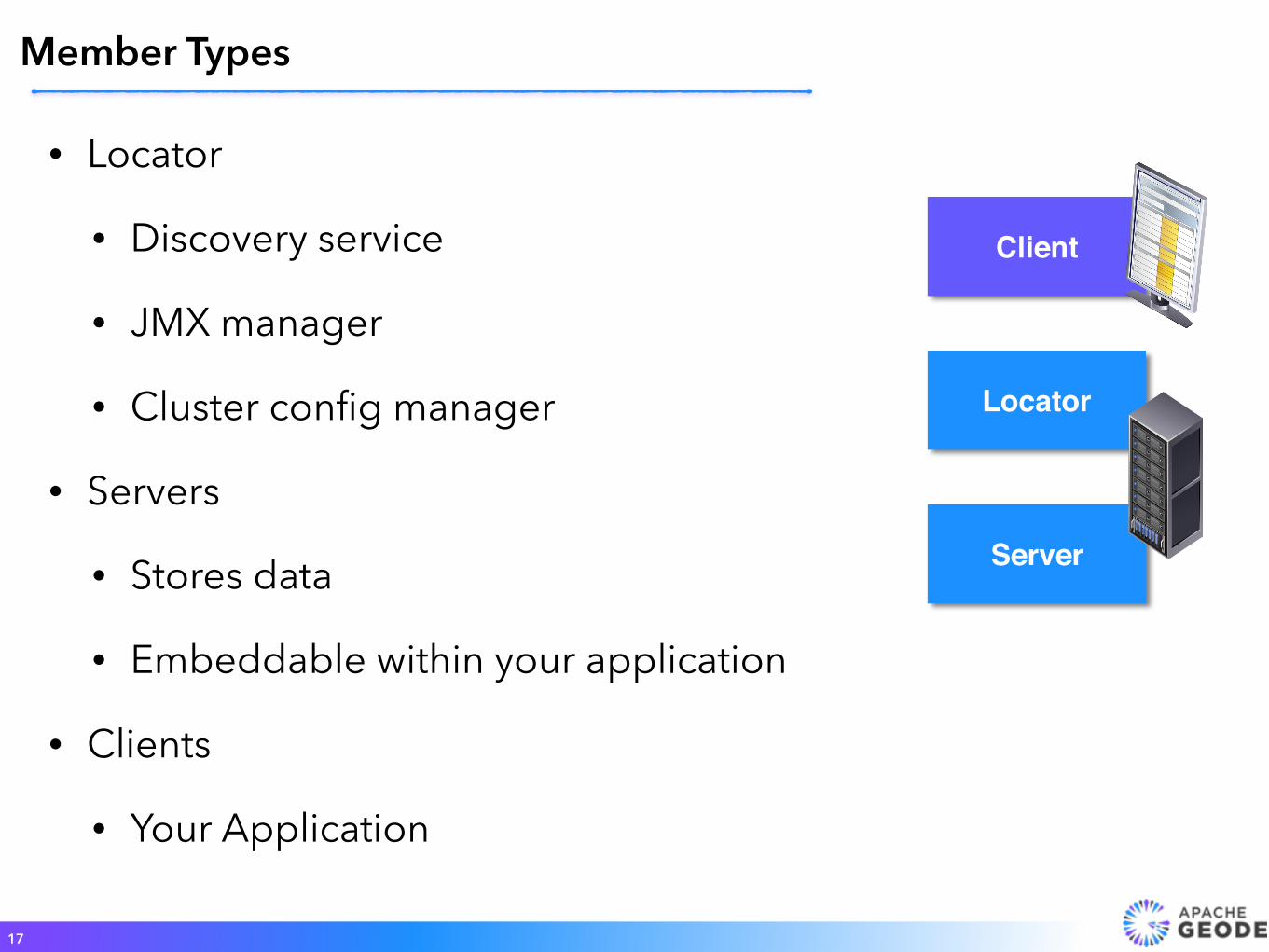
• Locator
• Discovery service
• JMX manager
• Cluster config manager
• Servers
• Stores data
• Embeddable within your application
• Clients
• Your Application
17
Member Types
Client
Locator
Server

• Region
• Distributed java.util.ConcurrentHashMap on steroids (Key/Value)
• Consistent API regardless of where or how data is stored
• Observable (reactive)
• Highly available, redundant on cache Member (s).
Concepts - Region
18
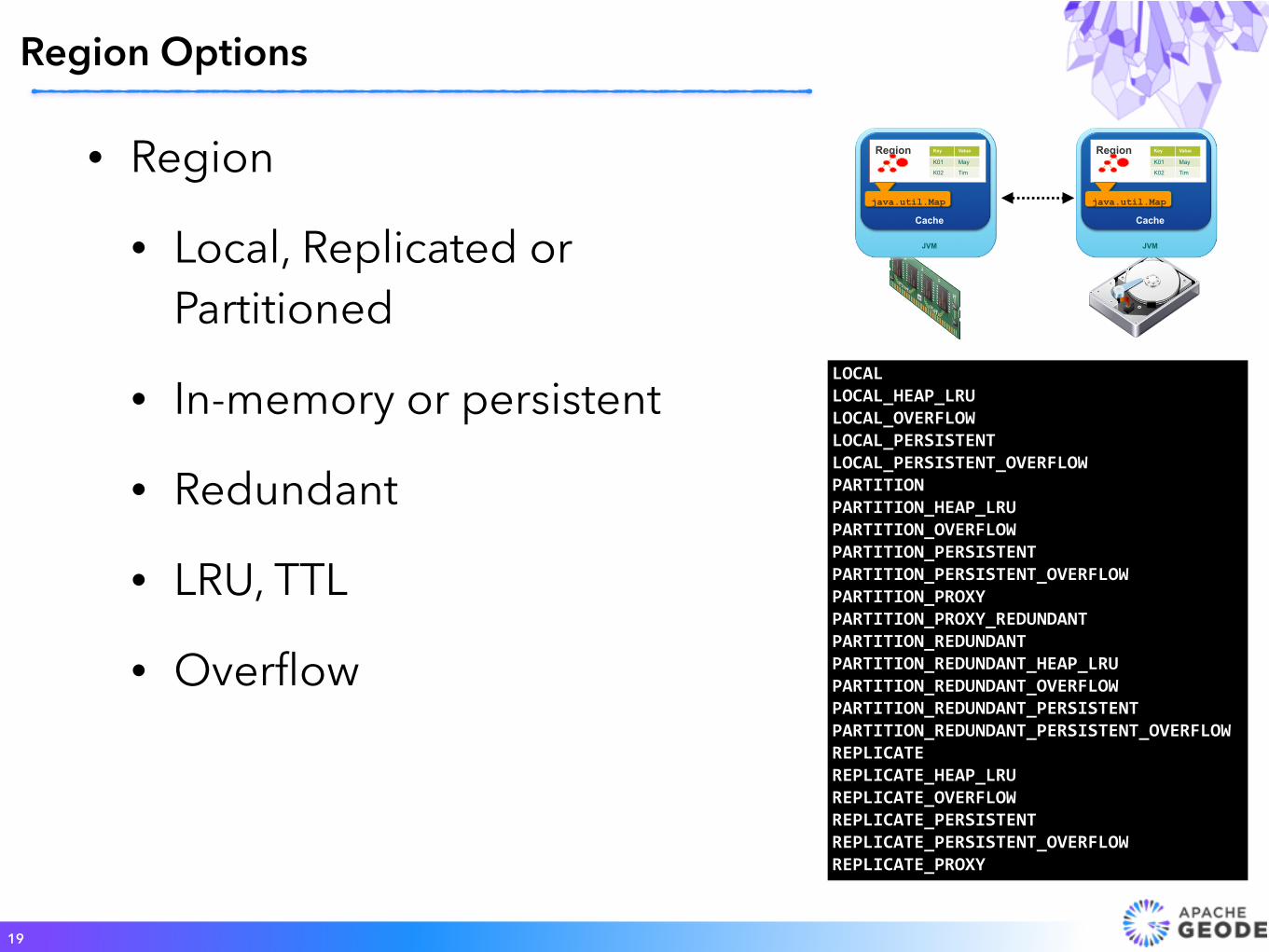
Region
Cache
java.util.Map
JVM
Key Value
K01 May
K02 Tim
• Region
• Local, Replicated or Partitioned
• In-memory or persistent
• Redundant
• LRU, TTL
• Overflow
Region Options
19
Region
Cache
java.util.Map
JVM
Key Value
K01 May
K02 Tim
Region
Cache
java.util.Map
JVM
Key Value
K01 May
K02 Tim
LOCALLOCAL_HEAP_LRULOCAL_OVERFLOWLOCAL_PERSISTENTLOCAL_PERSISTENT_OVERFLOWPARTITIONPARTITION_HEAP_LRUPARTITION_OVERFLOWPARTITION_PERSISTENTPARTITION_PERSISTENT_OVERFLOWPARTITION_PROXYPARTITION_PROXY_REDUNDANTPARTITION_REDUNDANTPARTITION_REDUNDANT_HEAP_LRUPARTITION_REDUNDANT_OVERFLOWPARTITION_REDUNDANT_PERSISTENTPARTITION_REDUNDANT_PERSISTENT_OVERFLOWREPLICATEREPLICATE_HEAP_LRUREPLICATE_OVERFLOWREPLICATE_PERSISTENTREPLICATE_PERSISTENT_OVERFLOWREPLICATE_PROXY

• Object Query Language (OQL) • SQL like • Query Complex Objects, attributes, methods • Not as performant at get()
Concepts - OQL
20
class Portfolio { int ID; String type; String status; Map positions; }
class Position { String secId; double mktValue; double qty; }
• SELECT * FROM /portfolio WHERE status = ‘active’ • SELECT p, pos FROM /portfolio p, p.positions.values pos WHERE pos.secId
= ‘VMW' • SELECT DISTINCT * FROM /portfolio p WHERE p.positions.size >= 2

Adapters
21
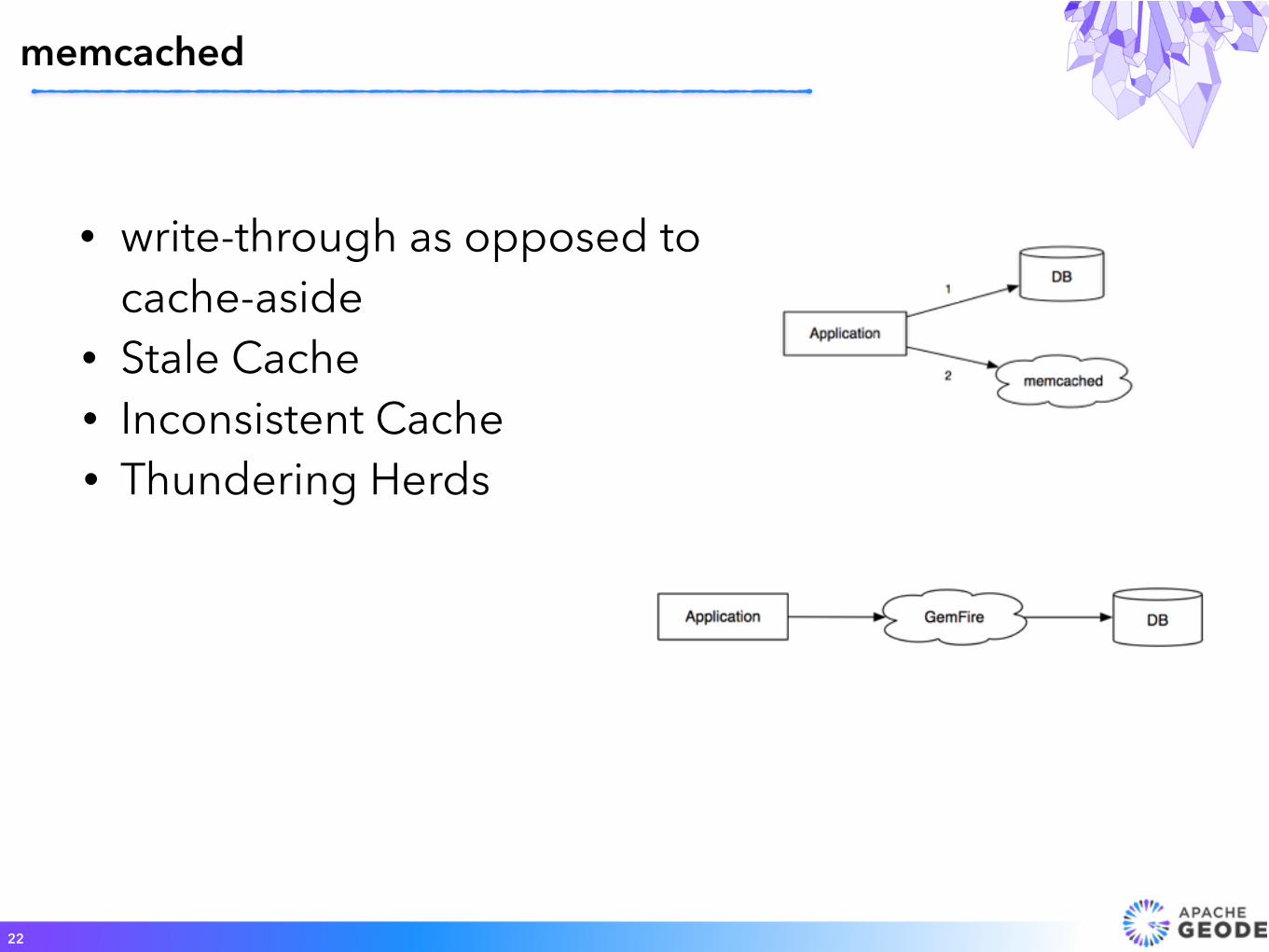
• write-through as opposed to cache-aside
• Stale Cache • Inconsistent Cache • Thundering Herds
memcached
22

• Scalable Data-Structures • Use All Cores • WAN Replication
Redis
23

Hands on
• Teeny repo at
URL shortener
25
https://github.com/sbawaska/teeny
cdapache-geode./bin/gfshgfsh>startlocator--name=locatorgfsh>startserver--name=server1--server-port=40404gfsh>startserver--name=server2--server-port=40405gfsh>createregion--name=myRegion--type=REPLICATE• From the Application:
• Create regions • Save Teeny • Lookup Teeny/update stats • Remove Teeny • Query Teeny
• Download Geodehttp://geode.apache.org/releases/





























