Embed Size (px)
Citation preview


Galene: LinkedIn’s search architecture Diego Buthay & Sriram Sankar

LinkedIn’s Vision “Create economic opportunity for every member of the global workforce”
• Find work
• Realize your dream job
• Be great at what you do
LinkedIn’s Vision
Search and Recommendations are core to our Vision

Overview • Infrastructure scaling
• Developer productivity scaling
• Result quality scaling

Comparison of different Search Engines Netflix: AirBnB: Ebay: Bing: Google: Facebook:

Comparison of different Search Engines Netflix: 100K AirBnB: 800K Ebay: 500M Bing: 100’s of Billions Google: 100’s of Billions Facebook: Trillions

Comparison of different Search Engines Netflix: 100K Lucene AirBnB: 800K Lucene Ebay: 500M Custom C++ Bing: 100’s of Billions Custom C++ Google: 100’s of Billions Custom C++ Facebook: Trillions Custom C++
LinkedIn: 100’s of Millions
Galene (Lucene based)
Lucene
Galene (Custom)

Important Galene Features • Offline index building • Live updates at a fine granularity • Static rank and early termination • Faceting • Data distribution • Relevance framework

Offline index building Live updates at a fine granularity
A little about LinkedIn data • Most datasets at LinkedIn are available in 2 ways
• A real 9me, change no9fica9on stream • A complete dataset, ETL’d to Hadoop
• We often rely on derived datasets • Many derived datasets can’t be crunched in real time

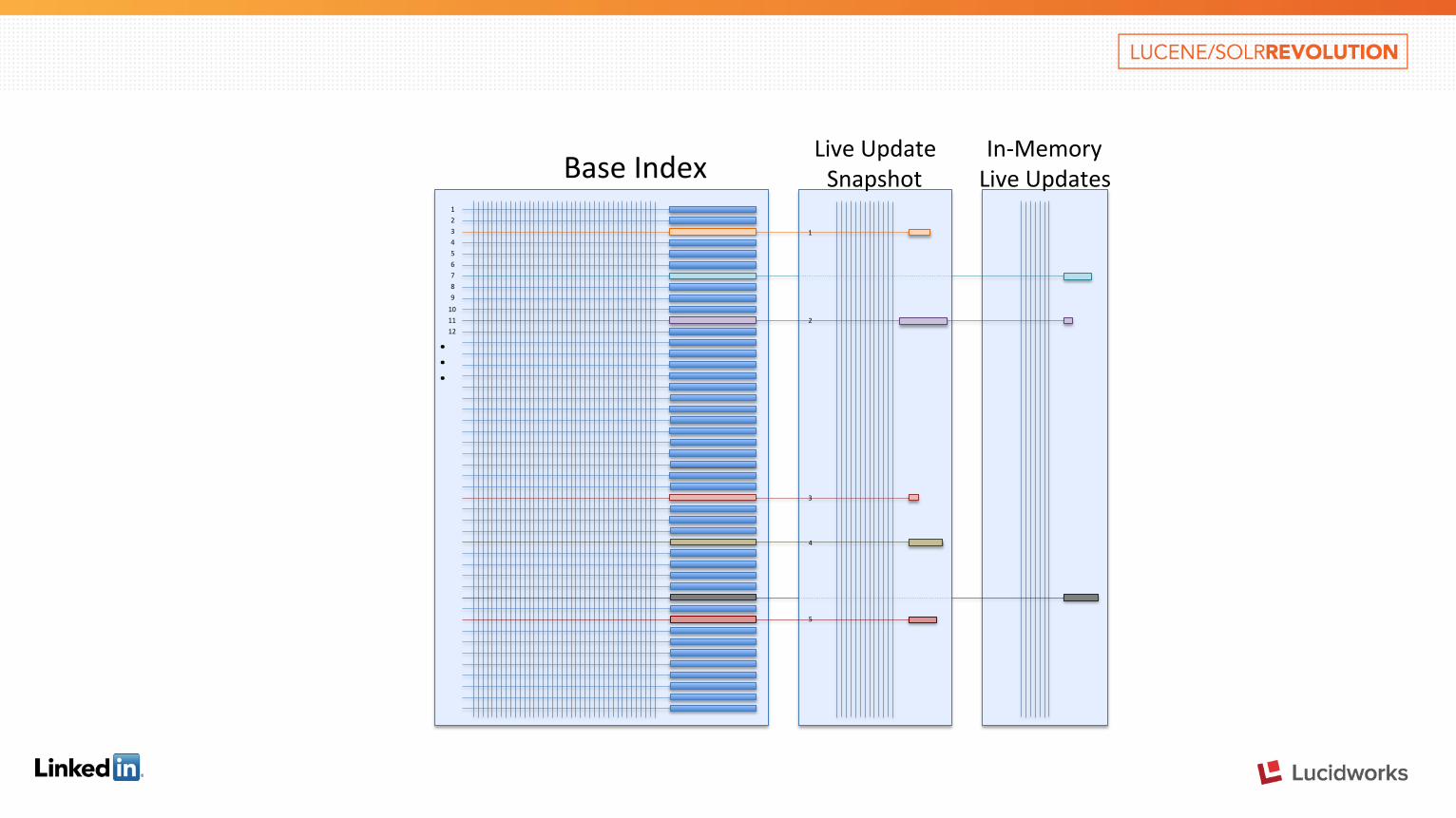
Anatomy of a Galene index • Base Index
• Generated by Hadoop periodically • Single-‐segment Lucene index • On Disk. Immutable. MMAPed and MLOCKed • Contains complex / rich features, that we can only afford to compute offline
• Live Index • Inverted index with our own format • In-‐memory data structure • Contains incremental updates to documents
• Snapshot Index • On Disk Snapshot of Live index when necessary • Ini9ally empty • Single segment Lucene Index. Live index is folded in regularly
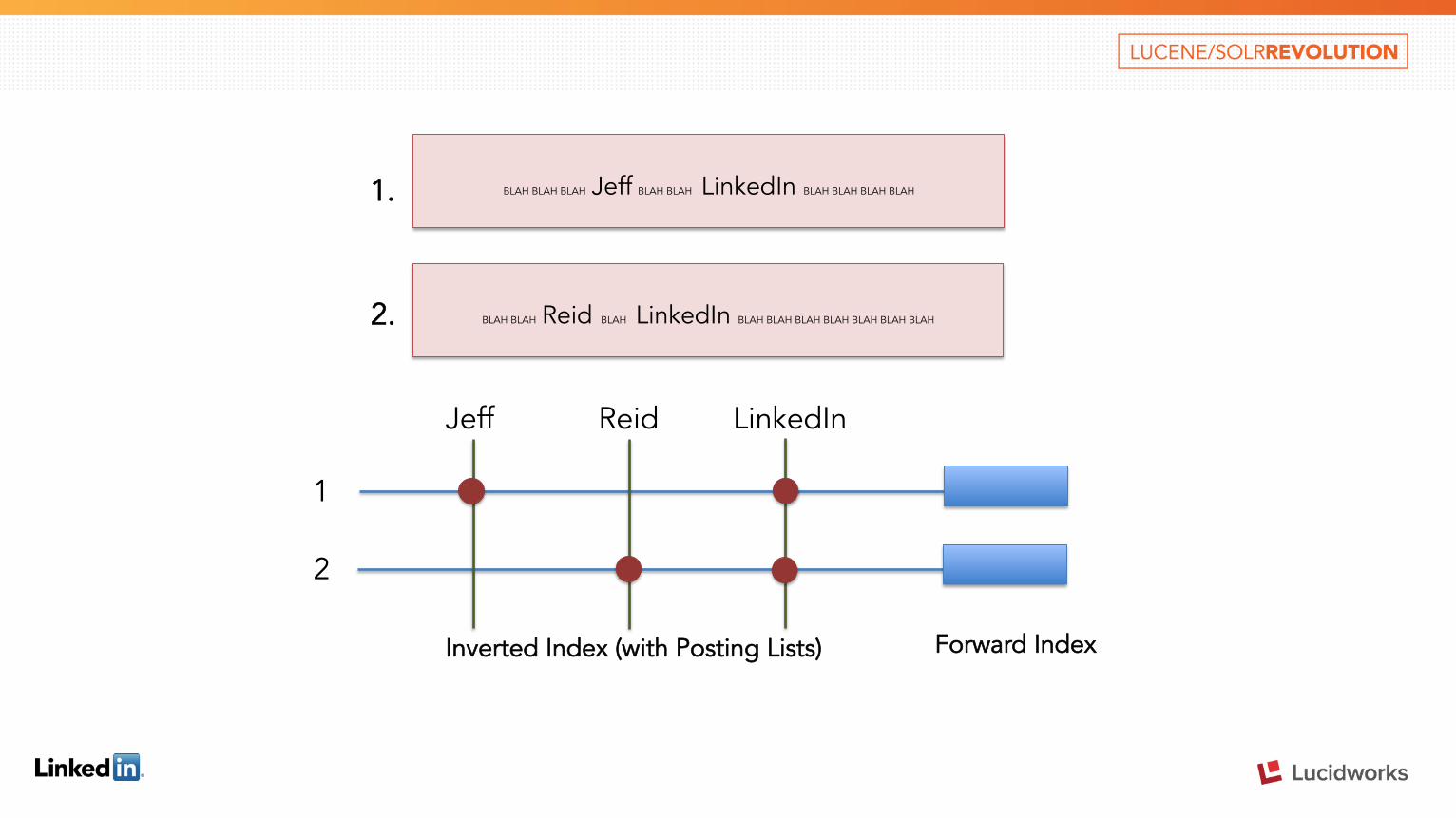
BLAH BLAH BLAH Jeff BLAH BLAH LinkedIn BLAH BLAH BLAH BLAH
BLAH BLAH Reid BLAH LinkedIn BLAH BLAH BLAH BLAH BLAH BLAH BLAH 2.
1.
Jeff Reid LinkedIn
2
1
Inverted Index (with Posting Lists) Forward Index
1 2 3 4
6
8
5
7
9
1
2
3
4
5
11 10
12 . . .
Base Index Live Update Snapshot
In-‐Memory Live Updates

Inverted Index: Three Segments Three independent segments with non-overlapped UIDs: • B1S1L1 (Base/snapshot/live) segment
• Base has all UIDs. • Neither of Snapshot nor Live introduces new UIDs.
• S2L2 (Snapshot/live) segment • None of UIDs exist in BSL. • Snapshot has all UIDs • Live does not introduce any new UIDs.
• L3 (live) segment • None of UIDs exist in BSL or SL.
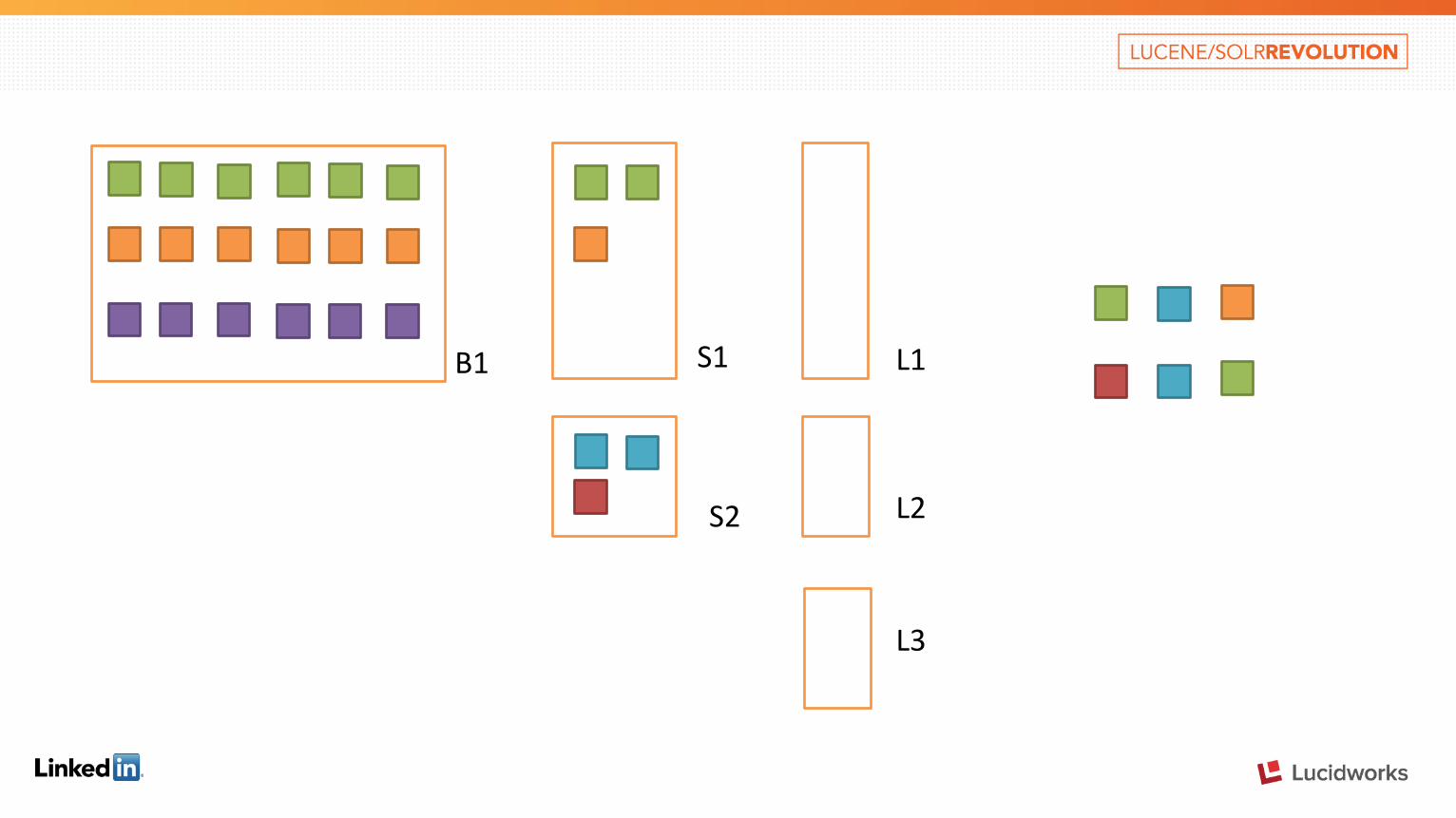
B1 L1 S1
L3
L2 S2

Static rank and early termination

Search: Static Rank (SR) • A global score of a document
• Each document must have one and only one SR • It could be anything that can globally represent the importance of an UID, for
example, the number of 1st degree connec9ons • Different documents might have same SRs
• B1S1L1 segment • Base knows SRs of all UIDs of the segment
• S2L2 • Snapshot knows SRs of all UIDs of the segment
• L3 segments • We assign ar9ficial SRs in either of the two ways:
• Ascending order star9ng from the max SR of all UIDs in all 3 segments • Descending order star9ng from the min SR of all UIDs in all 3 segments

Search: Early Termination (ET) • Segment Level ET
• Depending on the ordering of sta9c ranking assignment of L segment, which will affect the ordering of all segments, we can search: • BSL -‐> SL -‐> L (if it is descending) • L -‐> SL -‐> BSL (if it is ascending)
• Posting List Level ET • Since all pos9ngs are first sorted by SR, early termina9on on pos9ng list guarantees
that documents with highest SRs are always first retrieved (however, this does not guarantee that the final scores are also highest scores).

Going Forward • Very efficient custom index in C++ • Base index build can be run in a distributed manner • BSL supported at a more fundamental level
Faceting

Faceting • Types of facets supported:
• discoverable (e.g. current company) • sta9c values (e.g. network) • supplied values (e.g. my groups)
• Legacy stack had no early termination allowing for exact facet counting (at a cost)
• Current Galene stack applies heuristics to determine counts in an approximate manner
• Going forward, custom posting list format will encode facet details for more efficient facet count estimation

Relevance framework

Relevance Framework
• Infrastructure to support common scoring needs
• Provides framework to evaluate relevance changes
• Enables rapid iterations over relevance experiments
• Allows relevance engineers to focus on building features
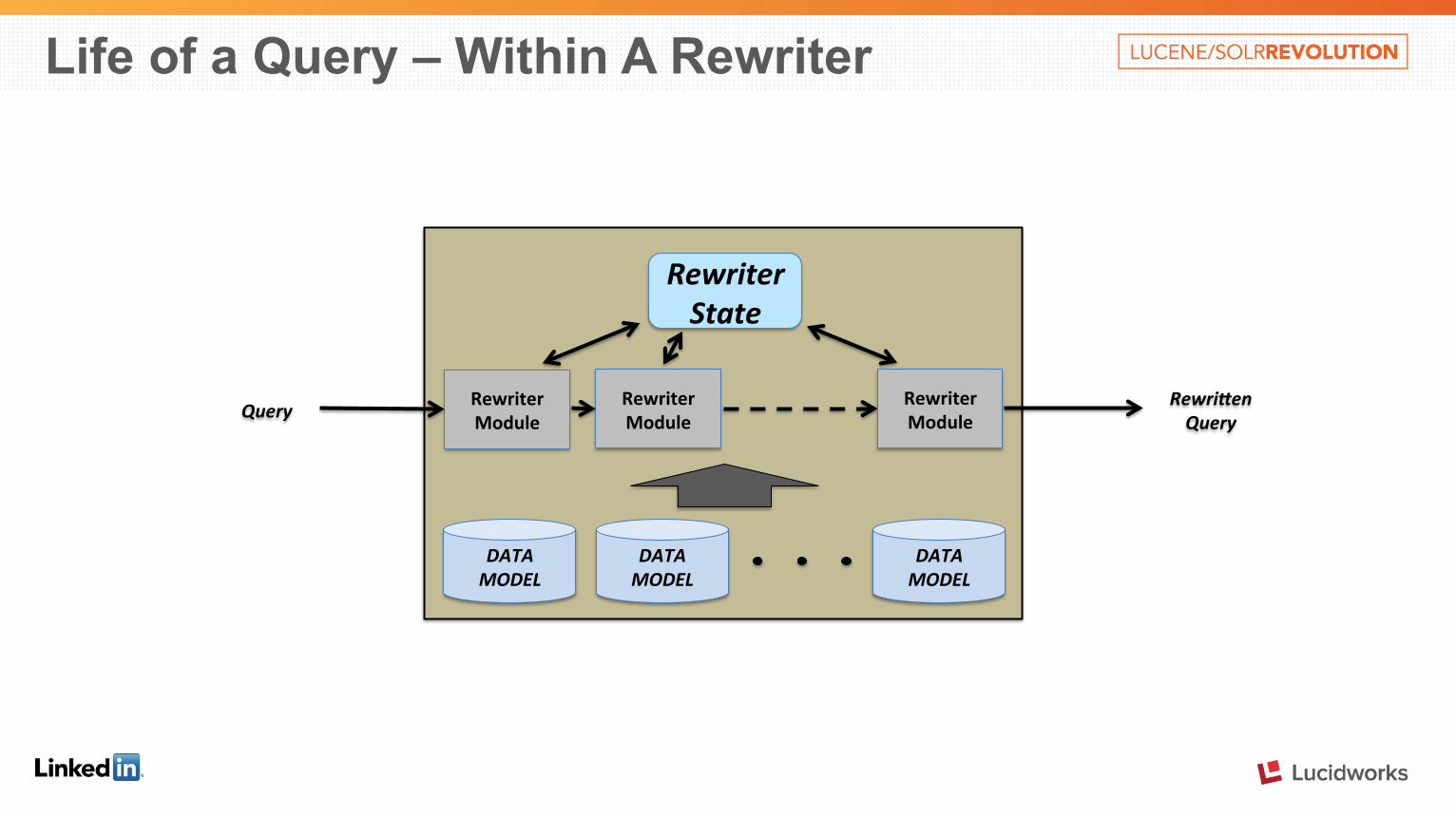
Life of a Query – Within A Rewriter
Query
DATA MODEL
Rewriter State
Rewriter Module
DATA MODEL
DATA MODEL
Rewri4en Query
Rewriter Module
Rewriter Module
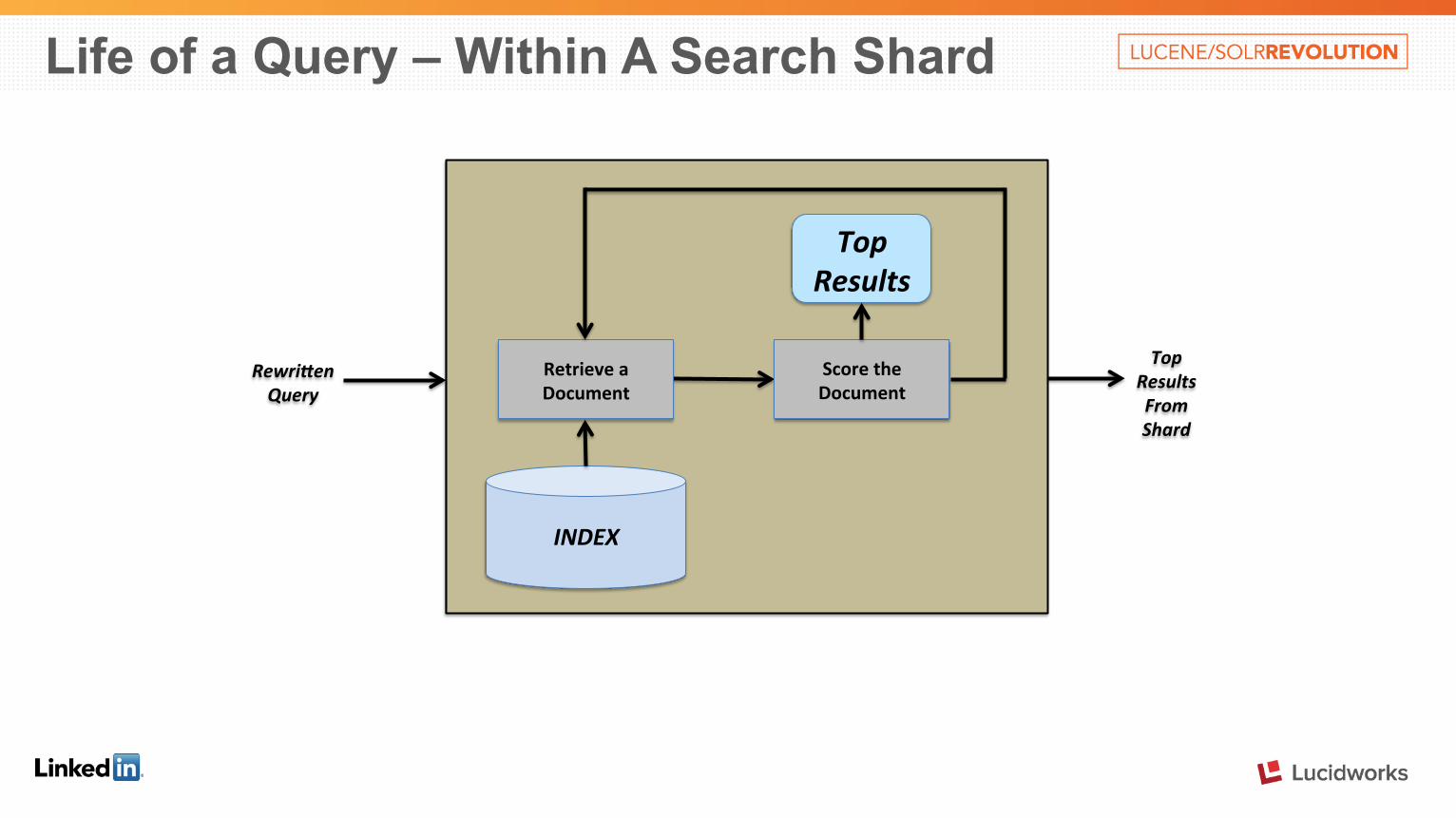
INDEX
Top Results
Retrieve a Document
Score the Document
Life of a Query – Within A Search Shard
Rewri4en Query
Top Results From Shard
Case study – Instant Search

Case Study: Instant Member Search • The index contains connections as document terms
(term:diego AND prefix:buth AND (connec>on:35176 OR connec>on:418001 OR connec>on:1520032))
• Static Rank of documents reflects popularity • Documents are augmented offline with spell correction data
• “shreeram sa” : (term:shreeram OR cluster:5678) AND (prefix:sa) AND (connec9on:1234)

Summary • Infrastructure scaling
• Developer productivity scaling
• Result quality scaling

30