Embed Size (px)
Citation preview

1© Cloudera, Inc. All rights reserved.
Speedpitch @ TDWI
Big Data Integration
Stefan Lipp
ACM, Cloudera
@snlipp

2© Cloudera, Inc. All rights reserved.
Cloudera - company snapshot
Founded 2008, by former employees of
Funding More than $1B invested, $740M primary investment from
NOW Publicly Traded on the NYSE: CLDR
Employees Today 1,500+ worldwide
World Class Support Pro-active & predictive support programs using our EDH
Mission Critical Production deployments in run-the-business applications worldwide – Financial Services, Pharma, Retail, Telecom, Media, Health Care, Energy, Government
Largest Ecosystem More than 2,600 Partners
Cloudera University Over 40,000 trained
Open Source Leaders Cloudera employees are leading developers & contributors to the complete Apache Hadoop ecosystem of projects

3© Cloudera, Inc. All rights reserved.
4© Cloudera, Inc. All rights reserved.
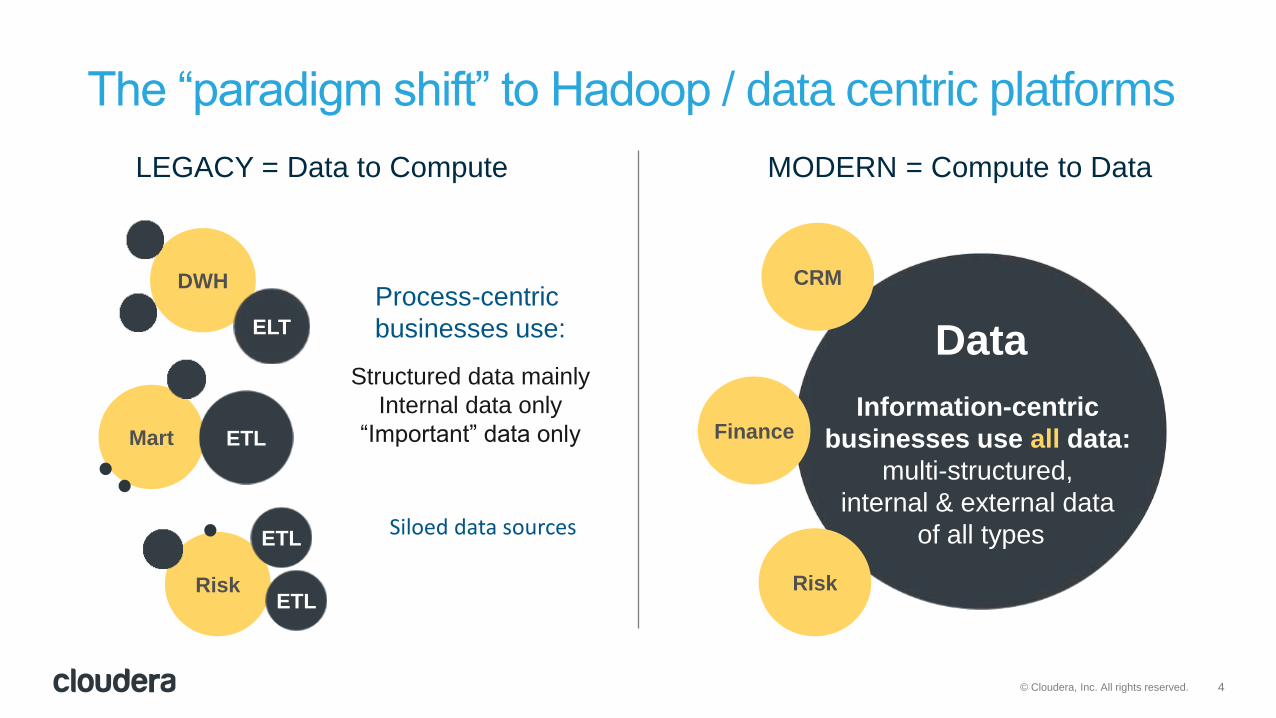
LEGACY = Data to Compute MODERN = Compute to Data
Data
Information-centric
businesses use all data:
multi-structured,
internal & external data
of all types
CRM
Finance
Risk
Process-centric
businesses use:
Structured data mainly
Internal data only
“Important” data only
DWH
Risk
Mart
ELT
ETL
ETL
ETL
Siloed data sources
The “paradigm shift” to Hadoop / data centric platforms

5© Cloudera, Inc. All rights reserved.
Big Data Technology = Multi-In + Scale + Multi-Out
1. Multi-In: Process different types of data together
Structured: From relational and transactional systems (RDBMS).
Semi-structured: e.g. Server Logs, Sensor Logs, Clickstreams, …
Unstructured: e.g. Emails, Tweets, Images, Audio, Video, …
2. Scale technically & economically (reduce
cost/byte).
3. Multi-Out: Run different types of data processing
workloads as part of a unified data pipeline.©2014 Cloudera, Inc. All rights reserved.
6© Cloudera, Inc. All rights reserved.
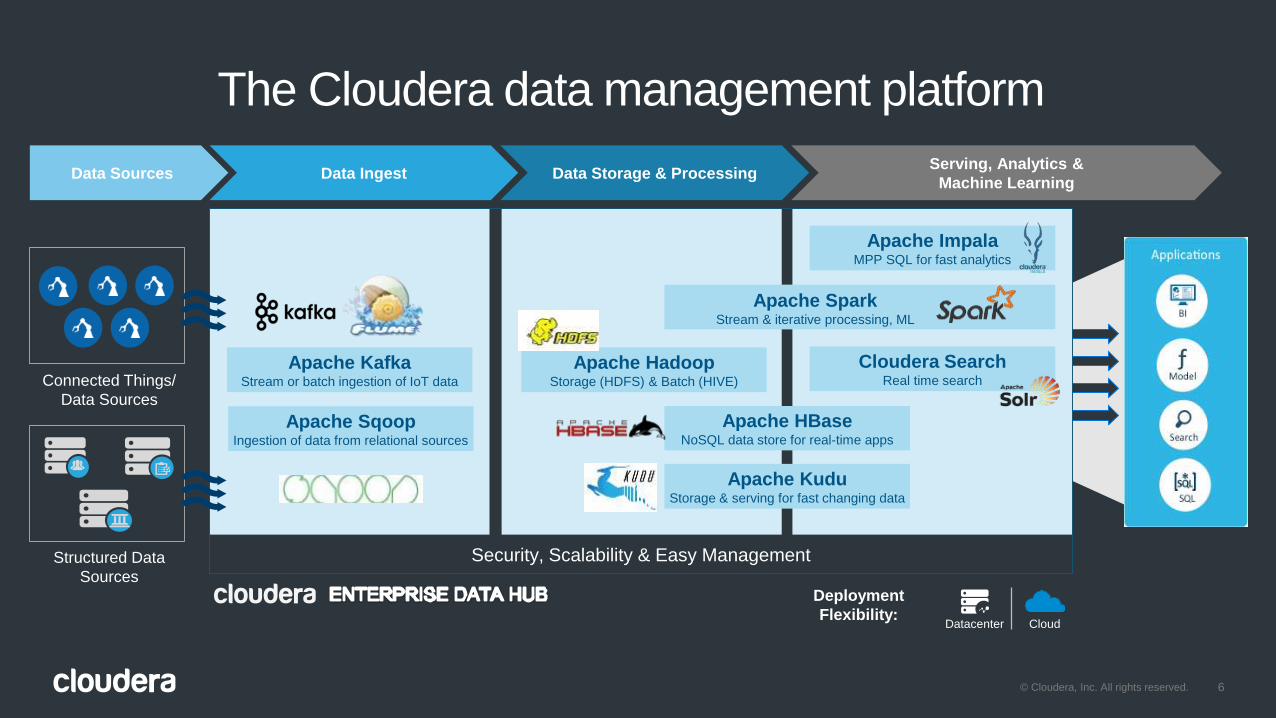
The Cloudera data management platform
Data Sources Data Ingest Data Storage & ProcessingServing, Analytics &
Machine Learning
Apache KafkaStream or batch ingestion of IoT data
Apache SqoopIngestion of data from relational sources
Apache HadoopStorage (HDFS) & Batch (HIVE)
Apache KuduStorage & serving for fast changing data
Apache HBaseNoSQL data store for real-time apps
Apache ImpalaMPP SQL for fast analytics
Cloudera SearchReal time searchConnected Things/
Data Sources
Structured Data
Sources
Security, Scalability & Easy Management
Deployment
Flexibility:Datacenter Cloud
Apache SparkStream & iterative processing, ML
7© Cloudera, Inc. All rights reserved.
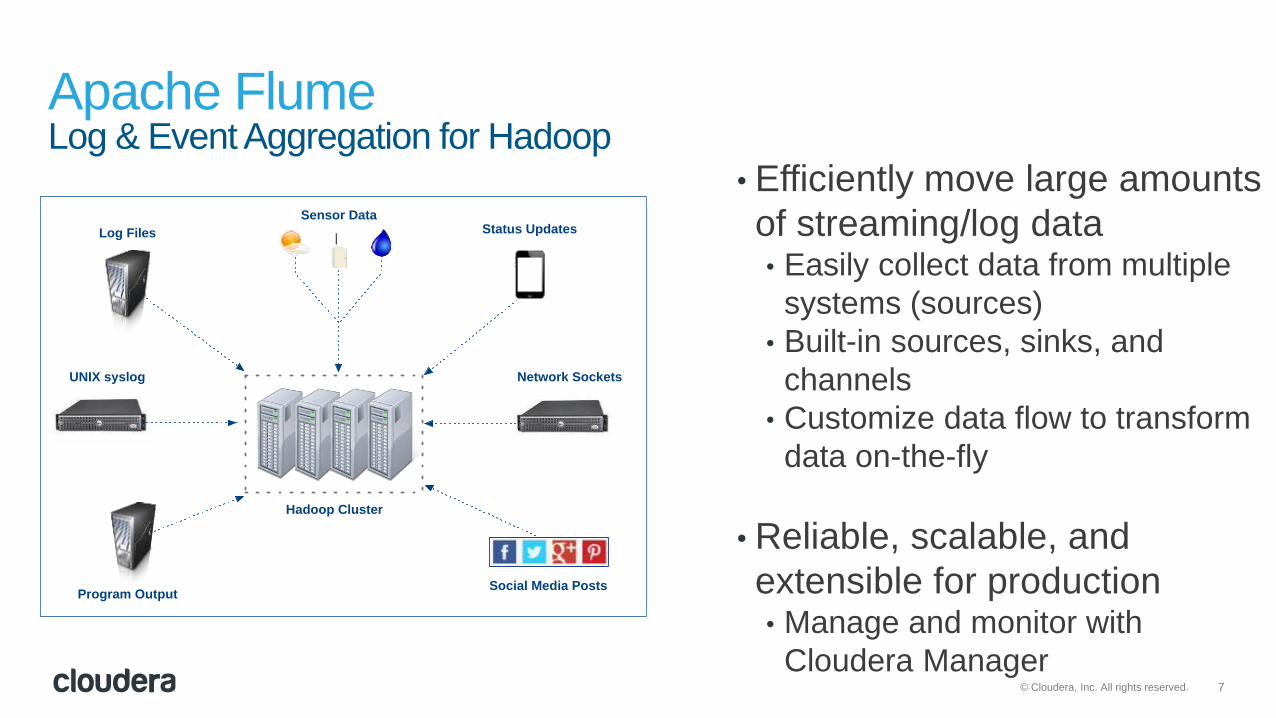
Apache FlumeLog & Event Aggregation for Hadoop
• Efficiently move large amounts
of streaming/log data• Easily collect data from multiple
systems (sources)
• Built-in sources, sinks, and
channels
• Customize data flow to transform
data on-the-fly
• Reliable, scalable, and
extensible for production• Manage and monitor with
Cloudera Manager
Log Files
Sensor Data
UNIX syslog
Hadoop Cluster
Program Output
Network Sockets
Status Updates
Social Media Posts
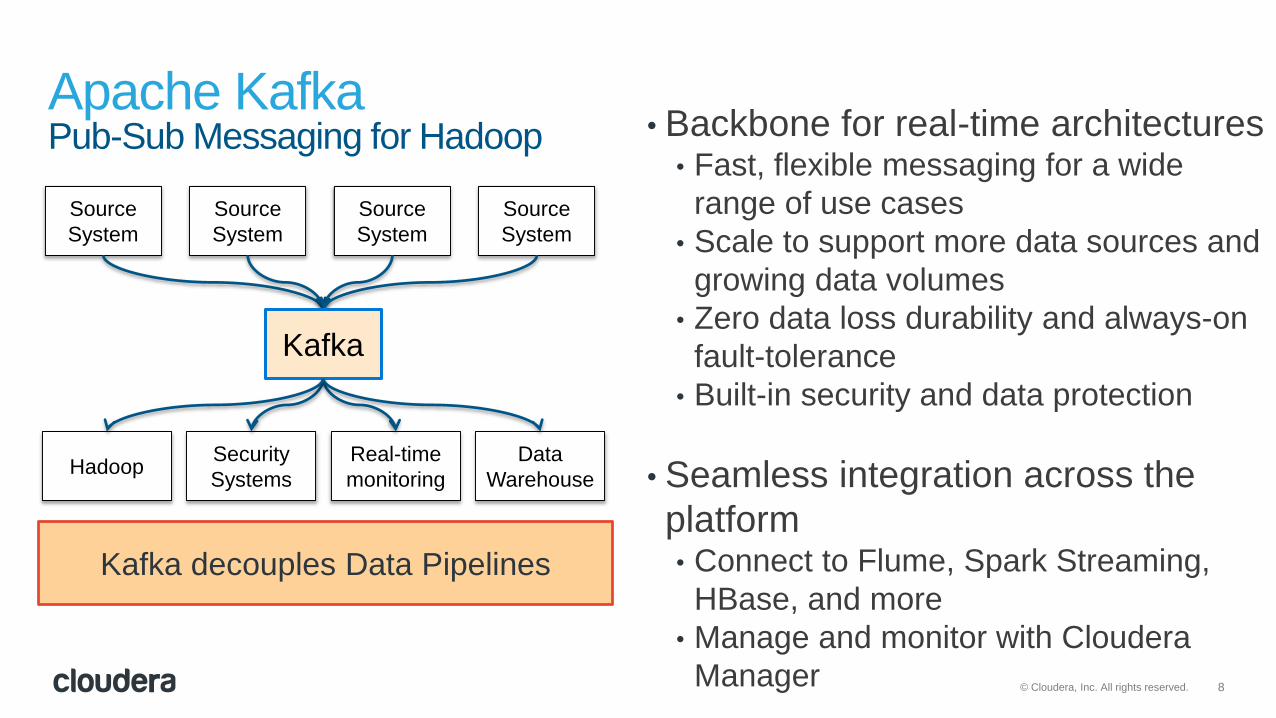
8© Cloudera, Inc. All rights reserved.
Apache KafkaPub-Sub Messaging for Hadoop • Backbone for real-time architectures
• Fast, flexible messaging for a wide
range of use cases
• Scale to support more data sources and
growing data volumes
• Zero data loss durability and always-on
fault-tolerance
• Built-in security and data protection
• Seamless integration across the
platform• Connect to Flume, Spark Streaming,
HBase, and more
• Manage and monitor with Cloudera
Manager
Kafka decouples Data Pipelines
Source
System
Source
System
Source
System
Source
System
HadoopSecurity
Systems
Real-time
monitoring
Data
Warehouse
Kafka

9© Cloudera, Inc. All rights reserved.
Apache SqoopSQL to Hadoop
• Efficiently exchange data between database and Hadoop• Bidirectional
• Import all or partial/new data
• Export for shared data access across systems
• Easily get started with high performance connectors • Free to use
• Optimized connectors for popular RDBMS, EDW, and NoSQL options
Database Hadoop Cluster

10© Cloudera, Inc. All rights reserved.
Go beyond SQL with Python & Spark: Cloudera Data Science WorkbenchAccelerates data engineering from
development to production with:
• Secure self-service environments
for data scientists to work against
Cloudera clusters
• Support for Python, R, and Scala,
plus project dependency isolation
for multiple library versions
• Workflow automation, version
control, collaboration and sharing

11© Cloudera, Inc. All rights reserved.
Cloudera Altus PaaS for Data Engineering
Platform as a service for ETL
(machine learning, and data
processing)
● Pay as you Go
● Support for MR2, Hive, Spark,
Hive-on-Spark, Talend
● Job-first orientation
● Quick and easy workload
troubleshooting & analytics

12© Cloudera, Inc. All rights reserved.
DI/DQ/Profiling/Wrangling solutions from partners

13© Cloudera, Inc. All rights reserved.
Data stewardship and governance solutions
Centralized Stewardship End User Discovery
Pla
tform
Applic
ation
Unified technical metadata catalog
Extensible business metadata and glossary
Metadata rules engine
Comprehensive lineage
Unified audit/access logs
Dashboards and analytics
APIs for augmentation and consumption
Data wrangling
Data visualization
Query recommendations
Security profiling
Compliance: BCBS239,
GDPR
End user collaboration
Crowdsourced metadata
Data quality
Uniqueness
Data valuation
Data profiling
Content enrichment
Enterprise aggregation: metadata, lineage, SIEM,
auditing
Project management
Policy management
RACI
Stewardship workflows
ETL
Centralized curation
Centralized glossaries
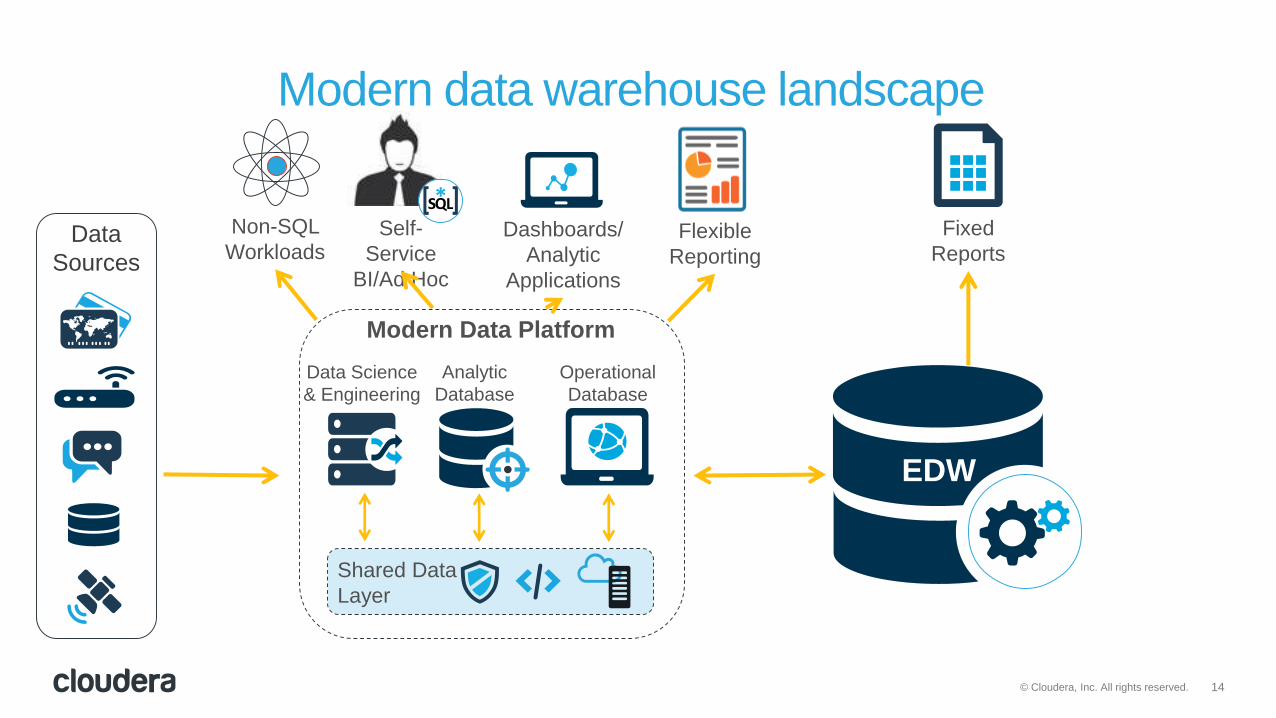
14© Cloudera, Inc. All rights reserved.
Modern data warehouse landscape
Data
Sources
EDW
Analytic
Database
Operational
Database
Data Science
& Engineering
Shared Data
Layer
Modern Data Platform
Fixed
ReportsDashboards/
Analytic
Applications
Non-SQL
WorkloadsSelf-
Service
BI/Ad Hoc
Flexible
Reporting

15© Cloudera, Inc. All rights reserved.
Powered by the best-of-breed technologies
Fastest ETL/ELT at Scale
for Data Engineers
• Flexible and scalable to handle any and all
data
• Fast data processing with distributed, in-
memory processing
• Processed data immediately available with
shared storage and metadata
• Cloud-native for contention-free resourcing
Self-Service BI & Reporting
for Analysts & SQL Developers
• Query data directly without rigid data
modeling
• Interactive multi-user performance for
iterative exploration
• Elastic scalability for more users/data on-
premises and cloud environments
• Cloud-native for insights over shared data
Impala

16© Cloudera, Inc. All rights reserved.
Cloudera’s goal: customer success with open source
By innovating in open sourceSome vendors consume the open source community’s activity; others help drive it. Cloudera leads in influencing the Hadoop platform's evolution by creating, contributing, and supporting new capabilities that meet customer requirements for security, scale, and usability.
By curating open standardsCloudera has a long and proven track record of identifying, curating, and supporting the open standards (including Apache HBase, Apache Spark, and Apache Kafka) that provide the mainstream, long-term architecture upon which new customer use cases are built.
By meeting the highest enterprise requirementsTo ensure the best customer experience, Cloudera invests significant resources in multi-dimensional testing on real workloads before releases, as well as in supportability of the entire platform via extensive involvement in the open source community.

17© Cloudera, Inc. All rights reserved.
Thank you
Live Demo CDSW – Spark Data Pipelines
heute 10:20-10:30 / Cloudera Stand @ TDWI
Live Demo Altus “Job First” Big Data Integration
heute 13:10-13:20 / Cloudera Stand @ TDWI