Embed Size (px)
Citation preview

C++ on its way to exascale and beyond– The HPX Parallel Runtime System
Thomas Heller ([email protected])January 21, 2016
This project has received funding from the Eu-ropean Union‘s Horizon 2020 research and in-novation programme under grant agreement No.671603

What is Exascale anyway?
This project has received funding from the Eu-ropean Union‘s Horizon 2020 research and in-novation programme under grant agreement No.671603

Exascale in numbers
• An Exascale Computer is supposed to execute 1018 floating pointoperations in a second• Exa: 1018 = 1000000000000000000• People on Earth: 7.3 Billion = 7.3 ∗ 109
• Imagine each person is able to compute one operation per second. Ittakes:⇒ 136986301 seconds⇒ 2283105 minutes⇒ 38051 hours⇒ 1585 days⇒ 4 years
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 3/ 51
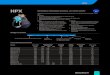
Why do we need that many calculations?
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 4/ 51

Why do we need that many calculations?
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 4/ 51

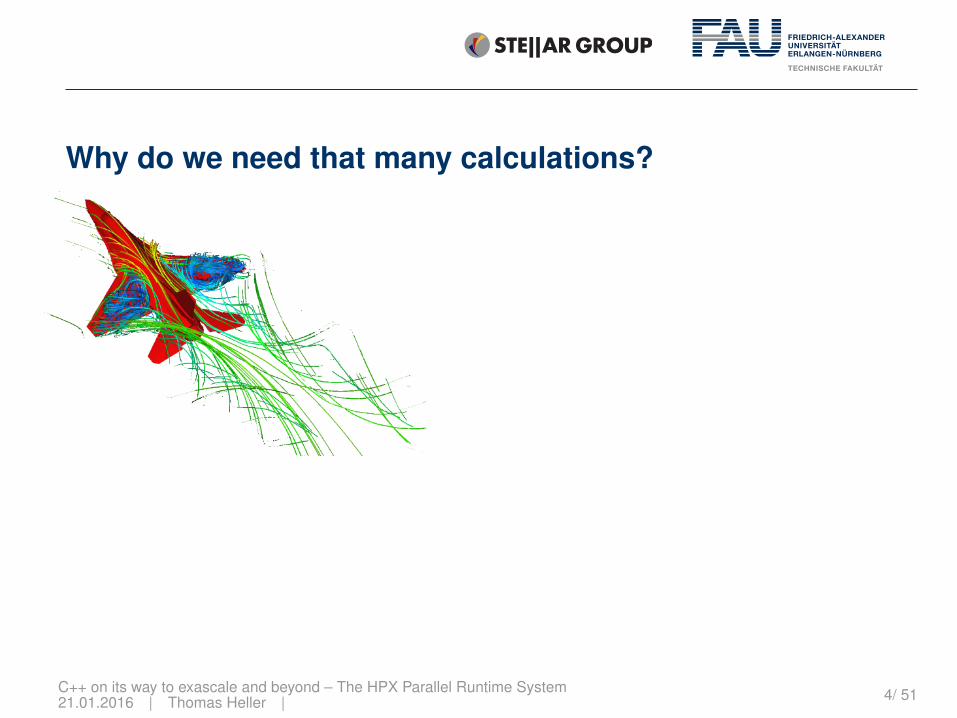
Why do we need that many calculations?
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 4/ 51
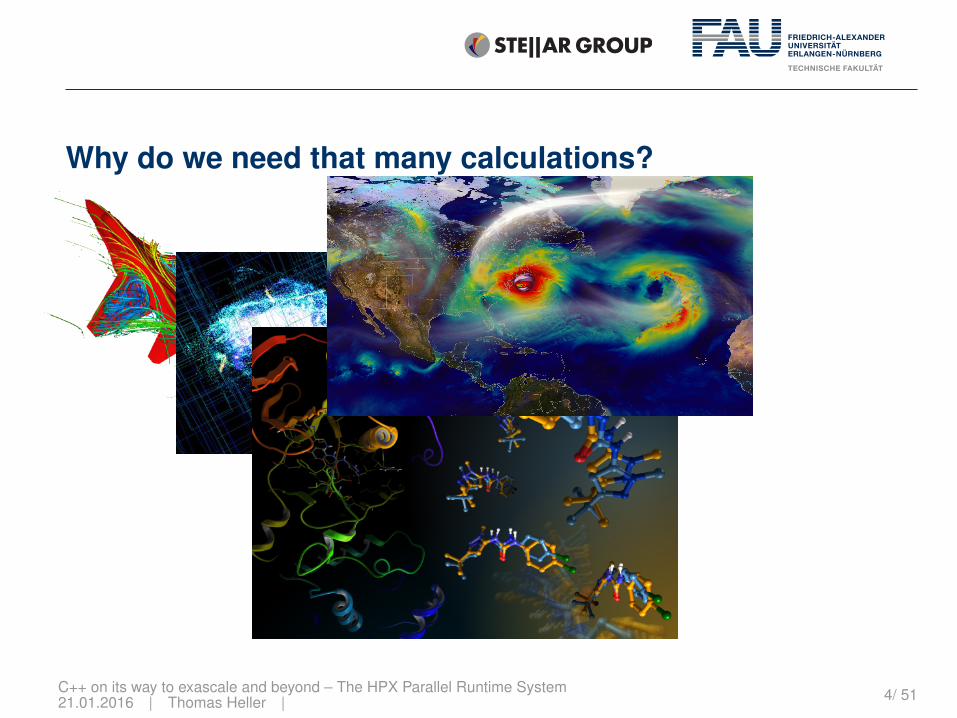
Why do we need that many calculations?
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 4/ 51
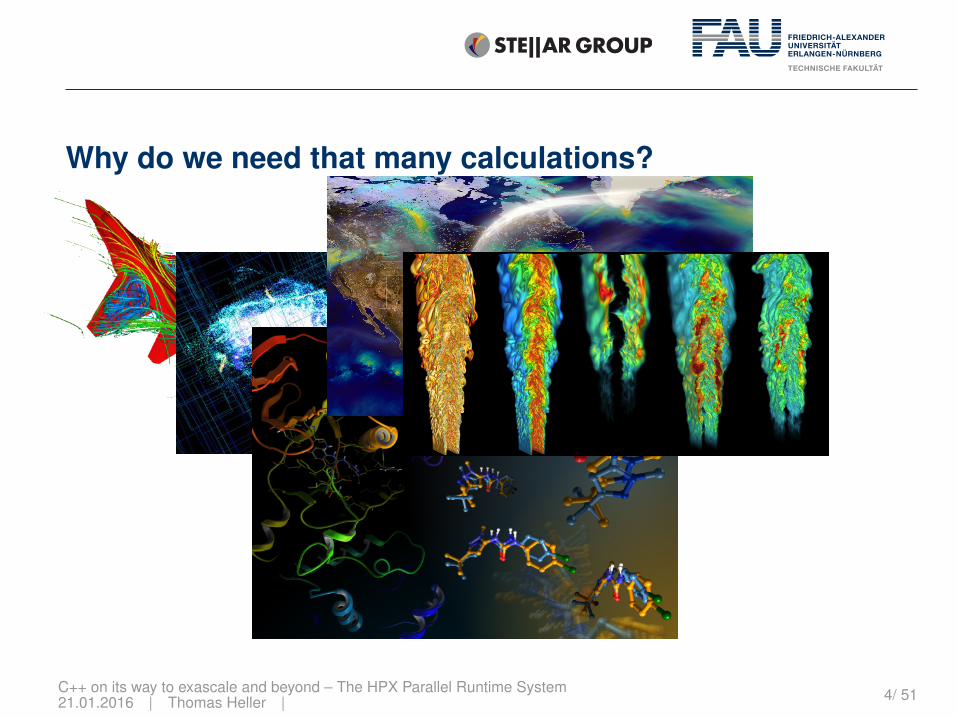
Why do we need that many calculations?
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 4/ 51

Why do we need that many calculations?
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 4/ 51
Why do we need that many calculations?
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 4/ 51
Why do we need that many calculations?
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 4/ 51

Challenges
• How do we program those beasts?⇒ Massively parallel processors⇒ Massive amount of compute nodes⇒ Deep Memory hierarchies• How can we design the architecture to be affordable?⇒ Biggest Operational cost is Energy⇒ Power Envelop of 20MW⇒ Current fastest Computer (Tian-He 2): 17MW
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 5/ 51
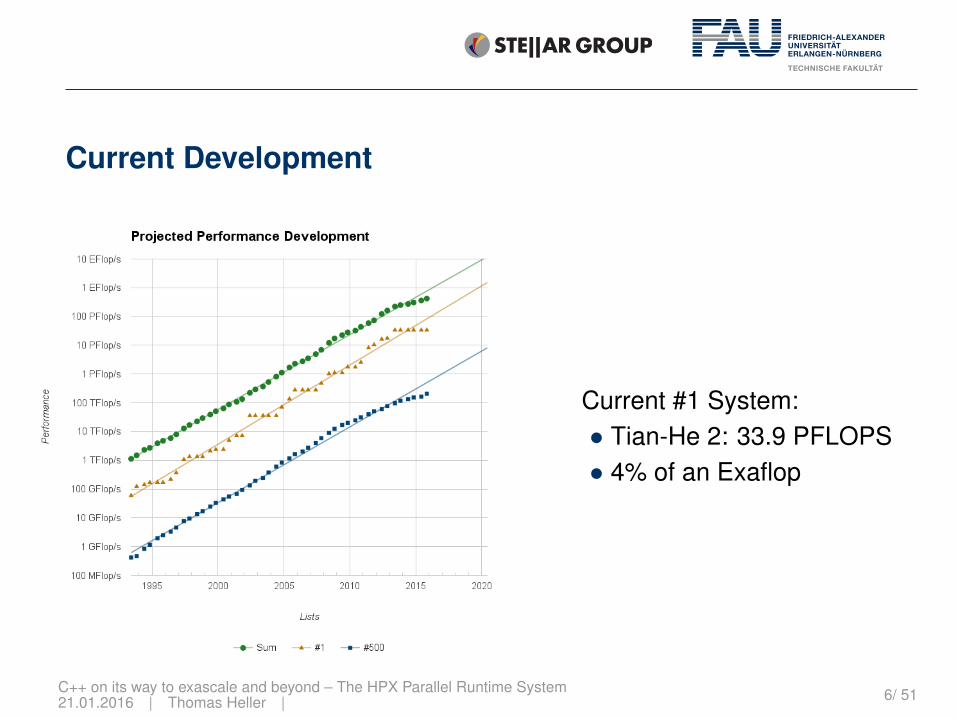
Current Development
Current #1 System:• Tian-He 2: 33.9 PFLOPS• 4% of an Exaflop
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 6/ 51

Hardware Trends
• ARM: Low-Power ARM64 cores (maybe adding embedded GPUaccelerators)• IBM: POWER + NVIDIA Accelerators• Intel: Knights Landing (Xeon Phi) Many Core processor
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 7/ 51

How will C++ deal with all that?!?
This project has received funding from the Eu-ropean Union‘s Horizon 2020 research and in-novation programme under grant agreement No.671603

Challenges
• Programmability• Expressing Parallelism• Expressing Data Locality
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 9/ 51

The 4 Horsemen of the Apocalypse: SLOW
StarvationLatencyOverheadWaiting for contention
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 10/ 51

State of the Art
• Modern architectures impose massive challenges on programmability inthe context of performance portability• Massive increase in on-node parallelism• Deep memory hierarchies
• Only portable parallelization solution for C++ programmers (today):OpenMP and MPI• Hugely successful for years• Widely used and supported• Simple use for simple use cases• Very portable• Highly optimized
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 11/ 51

State of the Art – Parallelism in C++
• C++11 introduced lower level abstractions• std::thread, std::mutex, std::future, etc.• Fairly limited, more is needed• C++ needs stronger support for higher-level parallelism
• Several proposals to the Standardization Committee are accepted orunder consideration• Technical Specification: Concurrency (P0159, note: misnomer)• Technical Specification: Parallelism (P0024)• Other smaller proposals: resumable functions, task regions, executors
• Currently there is no overarching vision related to higher-level parallelism• Goal is to standardize a ‘big story’ by 2020• No need for OpenMP, OpenACC, OpenCL, etc.
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 12/ 51

Stepping Aside – Introducing HPX
This project has received funding from the Eu-ropean Union‘s Horizon 2020 research and in-novation programme under grant agreement No.671603

HPX – A general purpose parallel Runtime System
• Solidly based on a theoretical foundation – a well defined, new executionmodel (ParalleX)• Exposes a coherent and uniform, standards-oriented API for ease of
programming parallel and distributed applications.• Enables to write fully asynchronous code using hundreds of millions of threads.• Provides unified syntax and semantics for local and remote operations.
• Open Source: Published under the Boost Software License
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 14/ 51

HPX – A general purpose parallel Runtime System
HPX represents an innovative mixture of• A global system-wide address space (AGAS - Active Global Address
Space)• Fine grain parallelism and lightweight synchronization• Combined with implicit, work queue based, message driven computation• Full semantic equivalence of local and remote execution, and• Explicit support for hardware accelerators (through percolation)
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 15/ 51
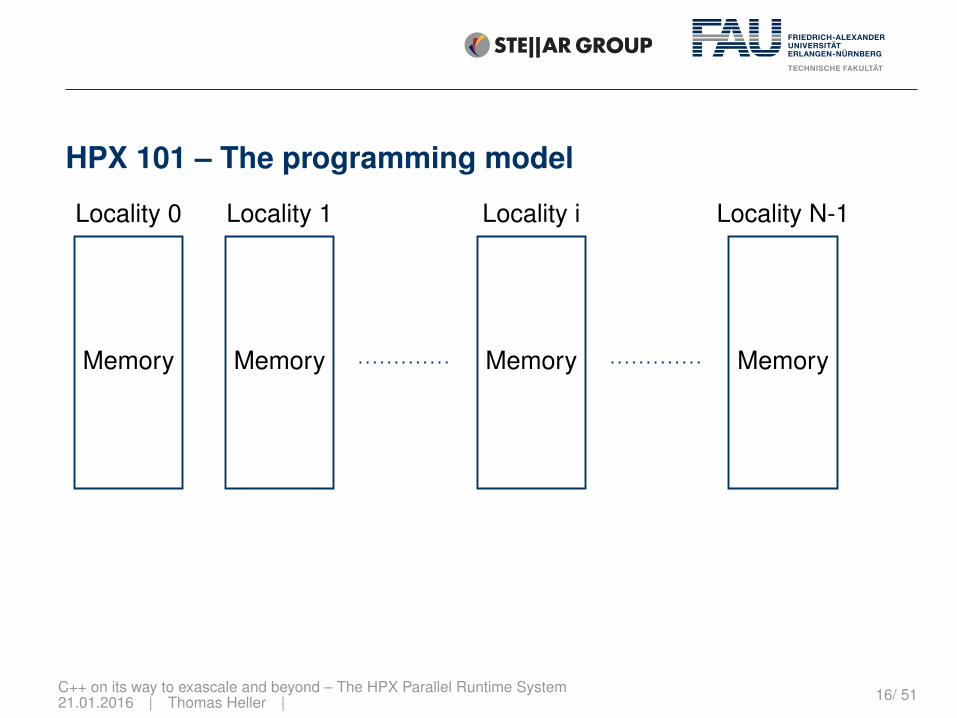
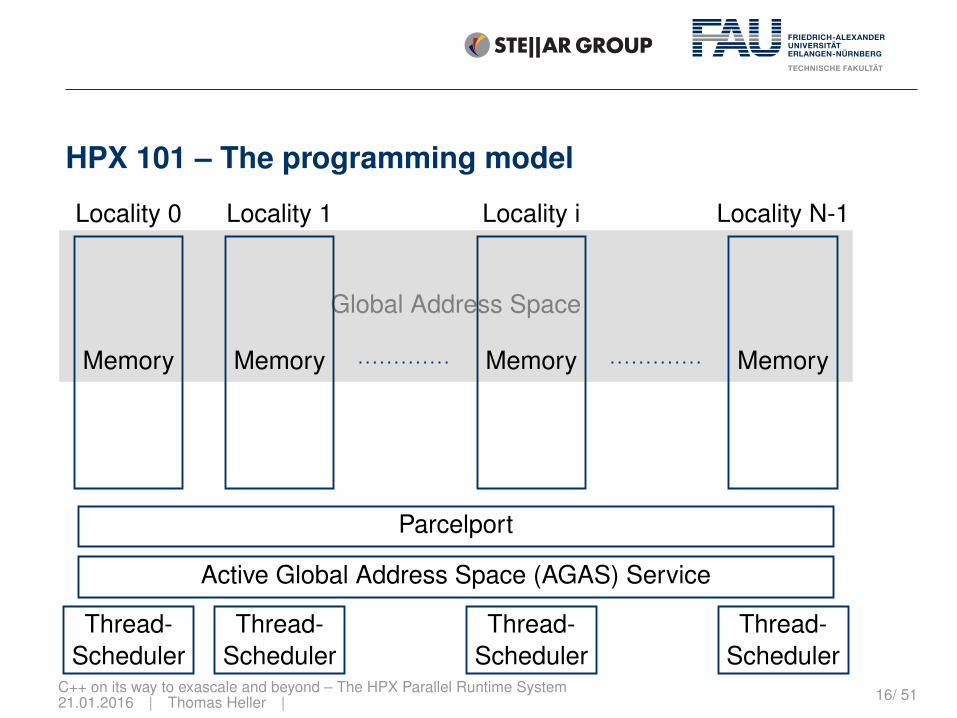
HPX 101 – The programming model
Memory
Locality 0
Memory
Locality 1
Memory
Locality i
Memory
Locality N-1
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 16/ 51
HPX 101 – The programming model
Global Address Space
Memory
Locality 0
Memory
Locality 1
Memory
Locality i
Memory
Locality N-1
Parcelport
Active Global Address Space (AGAS) Service
Thread-Scheduler
Thread-Scheduler
Thread-Scheduler
Thread-Scheduler
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 16/ 51
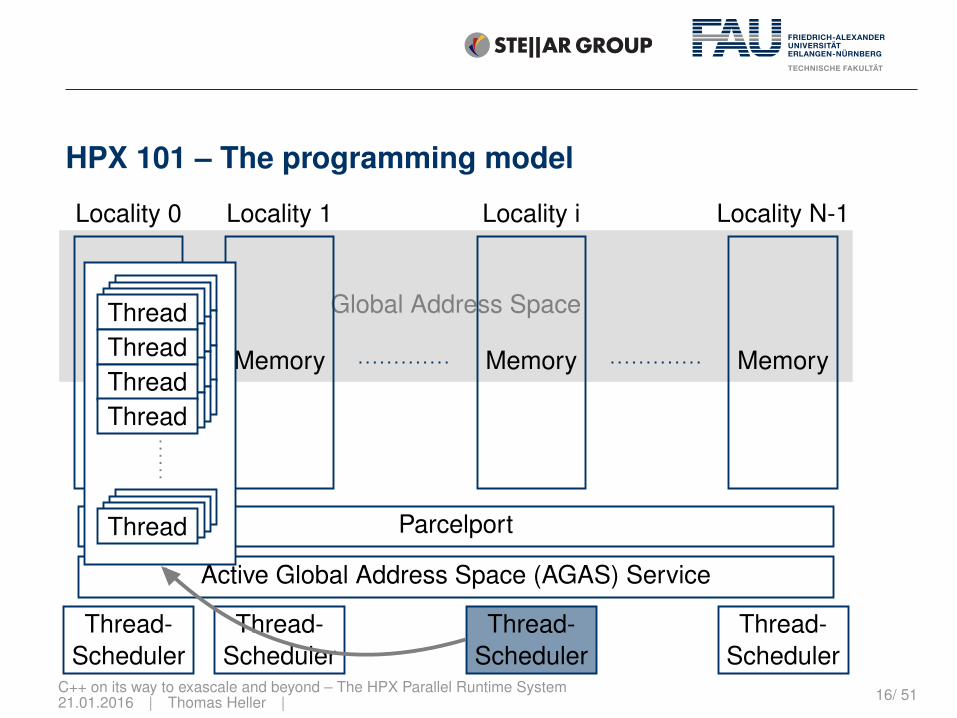
HPX 101 – The programming model
Global Address Space
Memory
Locality 0
Memory
Locality 1
Memory
Locality i
Memory
Locality N-1
Parcelport
Active Global Address Space (AGAS) Service
Thread-Scheduler
Thread-Scheduler
Thread-Scheduler
Thread-Scheduler
ThreadThreadThreadThread
Thread
ThreadThreadThreadThread
Thread
ThreadThreadThreadThread
Thread
ThreadThreadThreadThread
Thread
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 16/ 51
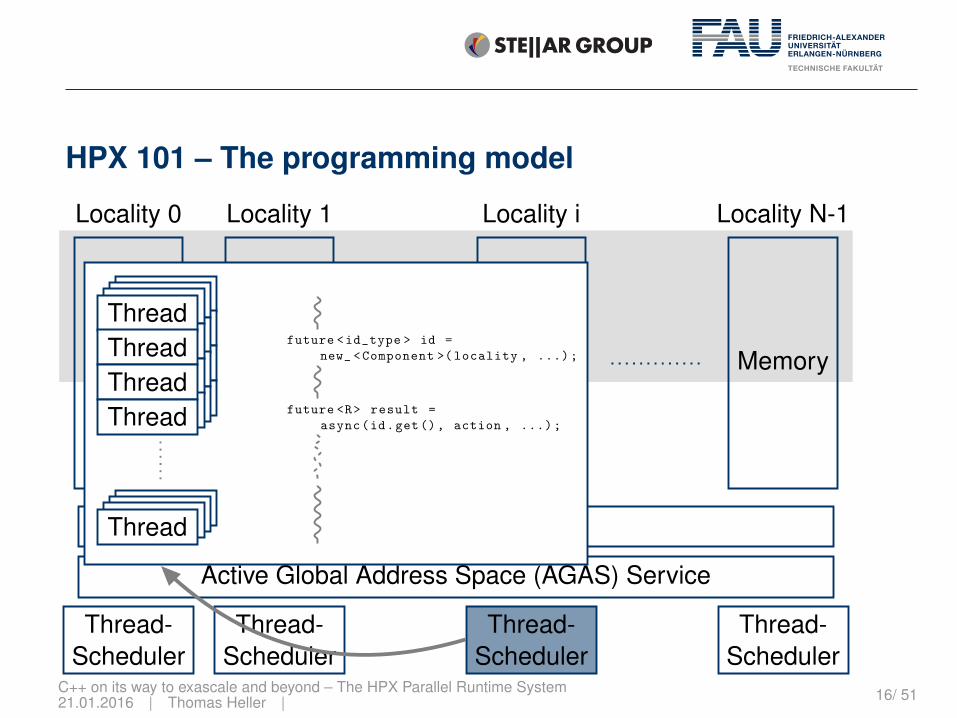
HPX 101 – The programming model
Global Address Space
Memory
Locality 0
Memory
Locality 1
Memory
Locality i
Memory
Locality N-1
Parcelport
Active Global Address Space (AGAS) Service
Thread-Scheduler
Thread-Scheduler
Thread-Scheduler
Thread-Scheduler
ThreadThreadThreadThread
Thread
ThreadThreadThreadThread
Thread
ThreadThreadThreadThread
Thread
ThreadThreadThreadThread
Thread
future <id_type > id =new_ <Component >(locality , ...);
future <R> result =async(id.get(), action , ...);
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 16/ 51
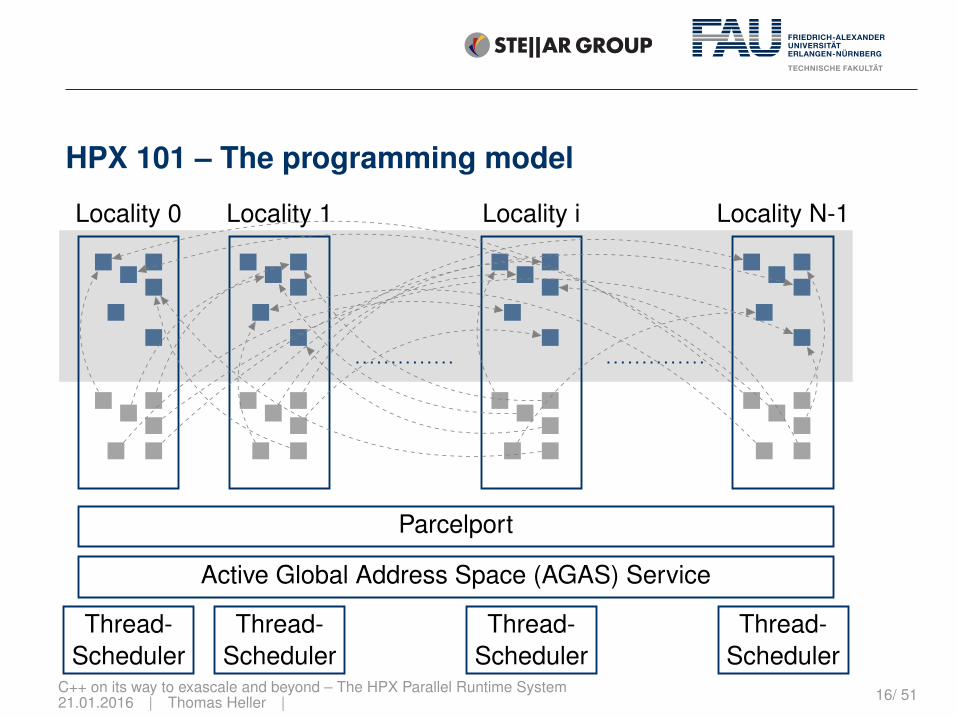
HPX 101 – The programming model
Locality 0 Locality 1 Locality i Locality N-1
Parcelport
Active Global Address Space (AGAS) Service
Thread-Scheduler
Thread-Scheduler
Thread-Scheduler
Thread-Scheduler
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 16/ 51

HPX 101 – Overview
HPX
C++ Standard Library
C++
R f(p...) Synchronous Asynchronous Fire & Forget(returns R) (returns future<R>) (returns void)
Functions f(p...) async(f, p...) apply(f, p...)(direct)
Functions bind(f, p...)(...) async(bind(f, p...), ...) apply(bind(f, p...), ...)(lazy)
Actions HPX_ACTION(f, a) HPX_ACTION(f, a) HPX_ACTION(f, a)(direct) a()(id, p...) async(a(), id, p...) apply(a(), id, p...)
Actions HPX_ACTION(f, a) HPX_ACTION(f, a) HPX_ACTION(f, a)(lazy) bind(a(), id, p...)
(...)async(bind(a(), id, p...),...)
apply(bind(a(), id, p...),...)
In Addition: dataflow(func, f1, f2);
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 17/ 51

The Future, an example
int universal_answer () { return 42; }void deep_thought () {
future <int > promised_answer= async(& universal_answer);
// do other things for 7.5 million yearscout << promised_answer.get() << endl;// prints 42, eventually
}
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 18/ 51

Compositional facilities
• Sequential composition of futures
future <string > make_string () {future <int > f1 =
async ([]() -> int { return 123; });future <string > f2 = f1.then(
[](future <int > f) -> string{
// here .get() won’t blockreturn to_string(f.get());
});return f2;
}
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 19/ 51

Compositional facilities
• Parallel composition of futures
future <int > test_when_all () {future <int > future1 =
async ([]() -> int { return 125; });future <string > future2 =
async ([]() -> string { return string("hi"); });auto all_f = when_all(future1 , future2);future <int > result = all_f.then(
[]( auto f) -> int {return do_work(f.get());
});return result;
}
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 20/ 51

Dataflow – The new ’async’ (HPX)
• What if one or more arguments to ’async’ are futures themselves?• Normal behavior: pass futures through to function• Extended behavior: wait for futures to become ready before invoking the
function:
template <typename F, typename ... Arg >future <result_of_t <F(Args ...) >>// requires(is_callable <F(Arg ...) >)dataflow(F && f, Arg &&... arg);
• If ArgN is a future, then the invocation of F will be delayed• Non-future arguments are passed through
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 21/ 51

Parallel Algorithms
This project has received funding from the Eu-ropean Union‘s Horizon 2020 research and in-novation programme under grant agreement No.671603

Concepts of Parallelism – Parallel Execution Properties
• The execution restrictions applicable for the work items• In what sequence the work items have to be executed• Where the work items should be executed• The parameters of the execution environment
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 23/ 51

Concepts and Types of Parallelism
Application
Concepts
Execution Policies
Executors Executor Parameters
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 24/ 51

Concepts and Types of Parallelism
Application
Concepts
Execution Policies
Executors Executor Parameters
Restrictions
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 24/ 51

Concepts and Types of Parallelism
Application
Concepts
Execution Policies
Executors Executor Parameters
Restrictions
Sequence, WhereC++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 24/ 51

Concepts and Types of Parallelism
Application
Concepts
Execution Policies
Executors Executor Parameters
Restrictions
Sequence, Where
Grain Size
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 24/ 51

Concepts and Types of Parallelism
Application
Concepts
Execution Policies
Executors Executor Parameters
Restrictions
Sequence, Where
Grain SizeFutures, Async, Dataflow
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 24/ 51

Concepts and Types of Parallelism
Application
Concepts
Execution Policies
Executors Executor Parameters
Restrictions
Sequence, Where
Grain SizeFutures, Async, Dataflow
Parallel Algorithms Fork-Join, etc
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 24/ 51

Execution Policies (std)
• Specify execution guarantees (in terms of thread-safety) for executedparallel tasks:• sequential_execution_policy: seq• parallel_execution_policy: par• parallel_vector_execution_policy: par_vec
• In parallelism TS used for parallel algorithms only
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 25/ 51

Execution Policies (Extensions)
• Asynchronous Execution Policies:• sequential_task_execution_policy: seq(task)• parallel_task_execution_policy: par(task)
• In both cases the formerly synchronous functions return a future<>• Instruct the parallel construct to be executed asynchronously• Allows integration with asynchronous control flow
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 26/ 51

Executors
• Executor are objects responsible for• Creating execution agents on which work is performed (P0058)• In P0058 this is limited to parallel algorithms, here much broader use
• Abstraction of the (potentially platform-specific) mechanisms for launchingwork• Responsible for defining the Where and How of the execution of tasks
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 27/ 51

Execution Parameters
Allows to control the grain size of work• i.e. amount of iterations of a parallel for_each run on the same thread• Similar to OpenMP scheduling policies: static, guided, dynamic• Much more fine control
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 28/ 51

Putting it all together – SAXPY routine with data locality
• a[i] = b[i] ∗ x + c[i], for i from 0 to N − 1• Using parallel algorithms• Explicit Control over data locality• No raw Loops
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 29/ 51

Putting it all together – SAXPY routine with data locality
Complete serial version:
std::vector <double > a = ...;std::vector <double > b = ...;std::vector <double > c = ...;double x = ...;
std:: transform(b.begin (), b.end(),c.begin(), c.end(), a.begin(),[x]( double bb, double cc){
return bb * x + cc;});
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 30/ 51

Putting it all together – SAXPY routine with data locality
Parallel version, no data locality:
std::vector <double > a = ...;std::vector <double > b = ...;std::vector <double > c = ...;double x = ...;
parallel :: transform(parallel ::par ,b.begin(), b.end(),c.begin(), c.end(), a.begin(),[x]( double bb, double cc){
return bb * x + cc;});
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 31/ 51

Putting it all together – SAXPY routine with data locality
Parallel version, no data locality:std::vector <double , numa_allocator > a = ...;std::vector <double , numa_allocator > b = ...;std::vector <double , numa_allocator > c = ...;double x = ...;
for(numa_executor : numa_executors) {parallel :: transform(
parallel ::par.on(numa_executor),b.begin() +..., b.begin() +...,c.begin() +..., c.begin() +..., a.begin() +...,[x]( double bb, double cc){ return bb * x + cc; });
}C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 32/ 51

Case Studies
This project has received funding from the Eu-ropean Union‘s Horizon 2020 research and in-novation programme under grant agreement No.671603

LibGeoDecomp
• C++ Auto-parallelizing framework• Open Source• High scalability• Wide range of platform support• http://www.libgeodecomp.org
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 34/ 51

LibGeoDecompFuturizing the Simulation Flow
Basic Simulation flow:for(Region r: innerRegion) {
update(r, oldGrid , newGrid , step);}swap(oldGrid , newGrid);++step;for(Region r: outerGhostZoneRegion) {
notifyPatchProviders(r, oldGrid);}for(Region r: outerGhostZoneRegion) {
update(r, oldGrid , newGrid , step);}for(Region r: innerGhostZoneRegion) {
notifyPatchAccepters(r, oldGrid);}
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 35/ 51

LibGeoDecompFuturizing the Simulation Flow
Futurized Simulation flow:parallel for(Region r: innerRegion) {
update(r, oldGrid , newGrid , step);}
swap(oldGrid , newGrid); ++step;parallel for(Region r: outerGhostZoneRegion) {
notifyPatchProviders(r, oldGrid);}
parallel for(Region r: outerGhostZoneRegion) {update(r, oldGrid , newGrid , step);
}
parallel for(Region r: innerGhostZoneRegion) {notifyPatchAccepters(r, oldGrid);
}
Continuation
Continuation
Continuation
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 36/ 51

HPXCL – Extending the Global Adress Space
• All GPU devices are addressable globally• GPU memory can be allocated and referenced remotely• Events are extensions of the shared state⇒ API embedded into the already existing future facilities
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 37/ 51

From async to GPUs
Spawning single tasks not feasible⇒ offload a work group (Think of parallel::for_each)
auto devices= hpx:: opencl :: find_devices(hpx:: find_here (),
CL_DEVICE_TYPE_GPU).get();// create buffers , programs and kernels ...hpx:: opencl :: buffer buf = devices [0]. create_buffer(CL_MEM_READ_WRITE , 4711);
auto write_future = buf.enqueue_write(some_vec.begin(), some_vec.end());
auto kernel_future = kernel.enqueue(dim ,write_future);
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 38/ 51

From async to GPUs
Spawning single tasks not feasible⇒ offload a work group (Think of parallel::for_each)
• Proof of Concept• Future Directions:• Embedd OpenCL devices behind Execution Policies and Executors• Hide OpenCL stuff behind parallel algorithms• Hide OpenCL buffer management behind "distributed data structures"
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 38/ 51
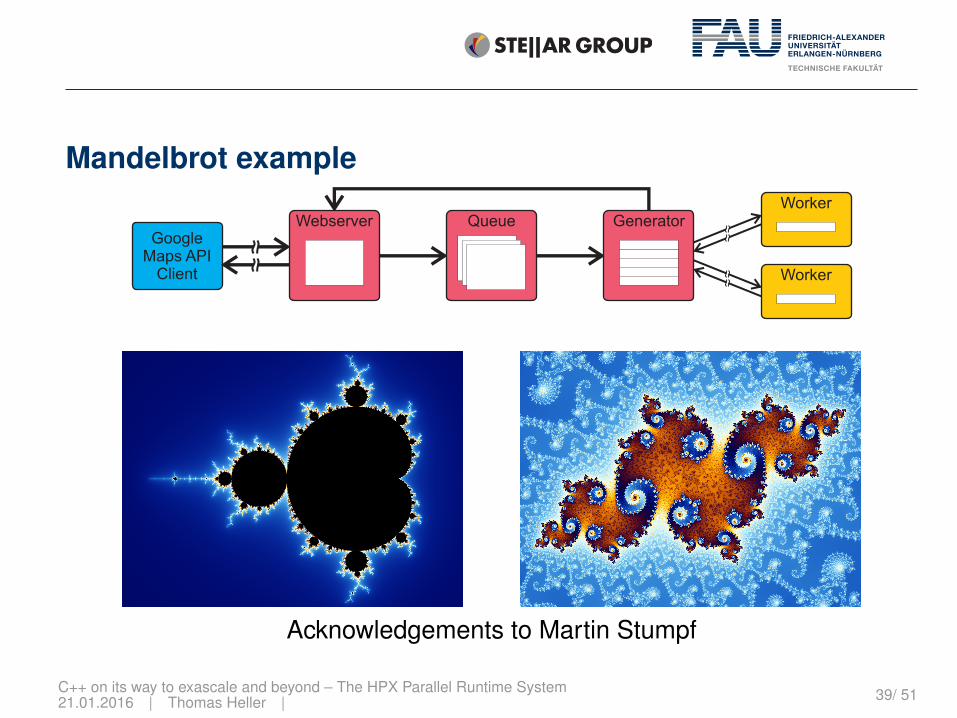
Mandelbrot example
QueueGoogle
Maps APIClient
WorkerGenerator
Worker
Webserver
Acknowledgements to Martin Stumpf
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 39/ 51
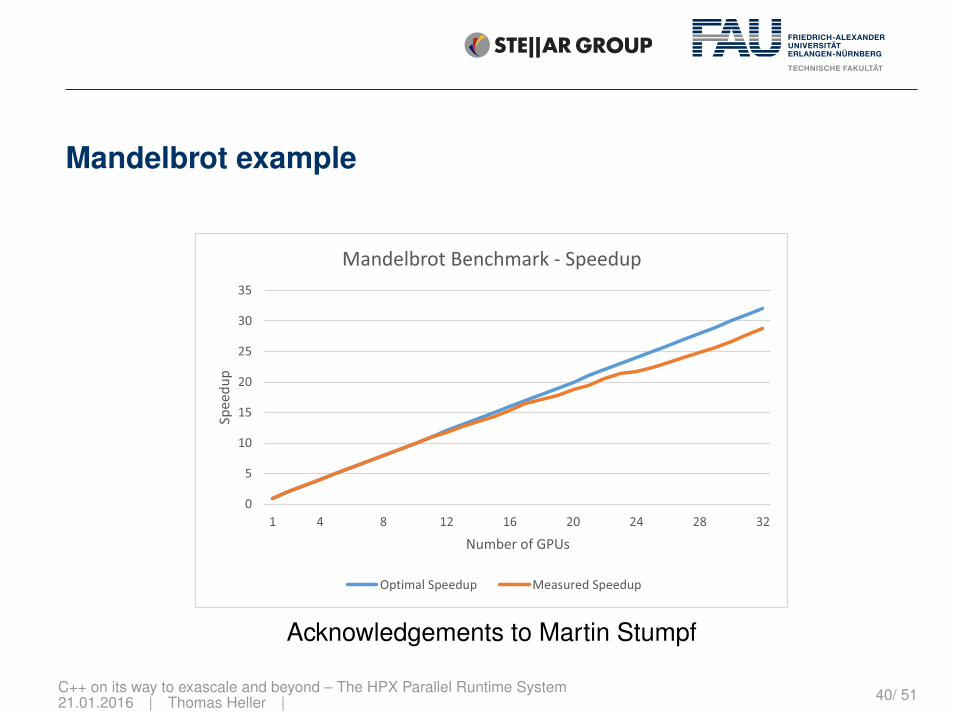
Mandelbrot example
Acknowledgements to Martin Stumpf
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 40/ 51
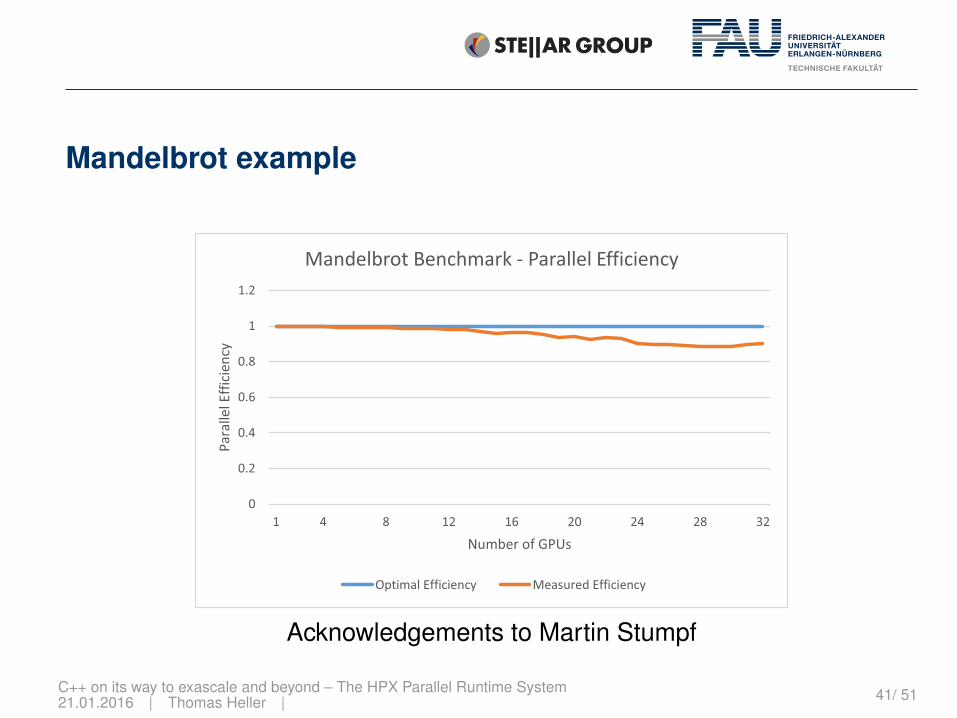
Mandelbrot example
Acknowledgements to Martin Stumpf
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 41/ 51
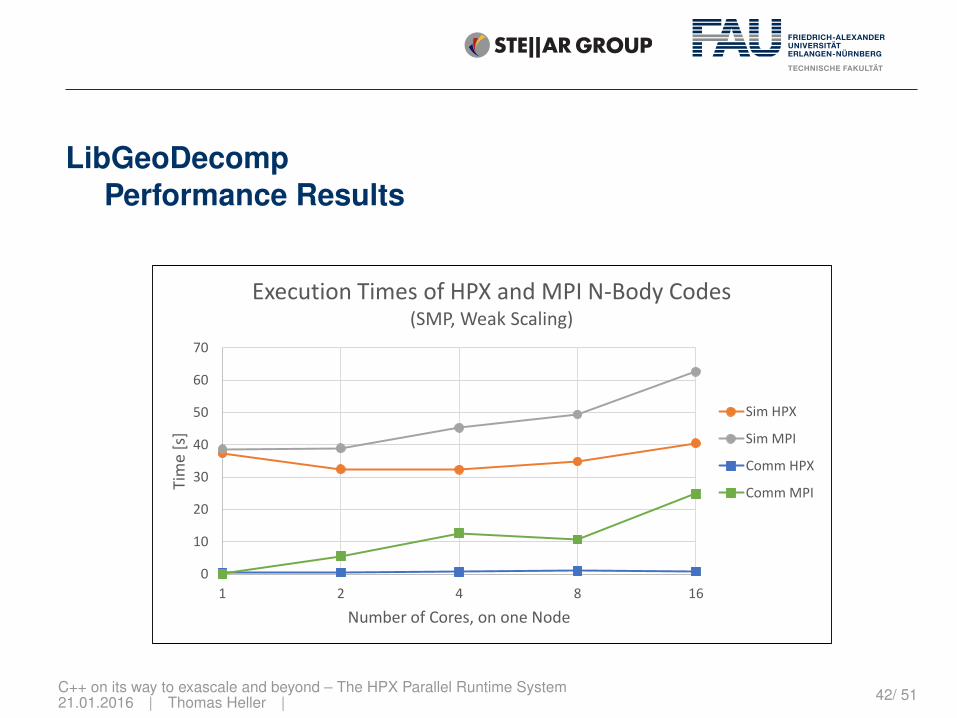
LibGeoDecompPerformance Results
0
10
20
30
40
50
60
70
1 2 4 8 16
Tim
e [s
]
Number of Cores, on one Node
Execution Times of HPX and MPI N-Body Codes(SMP, Weak Scaling)
Sim HPX
Sim MPI
Comm HPX
Comm MPI
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 42/ 51
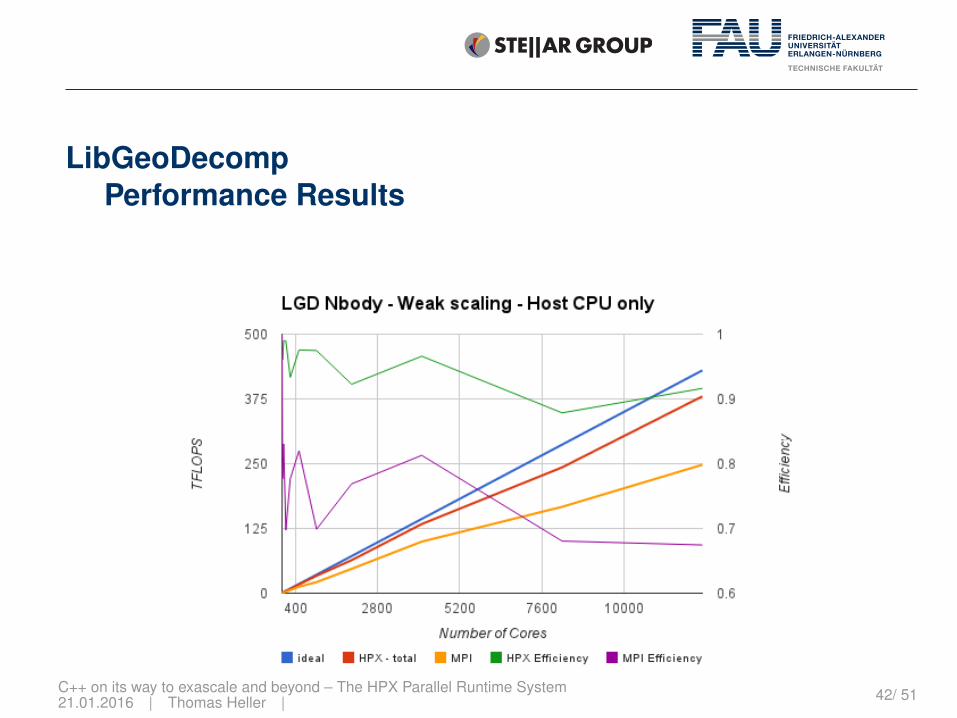
LibGeoDecompPerformance Results
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 42/ 51
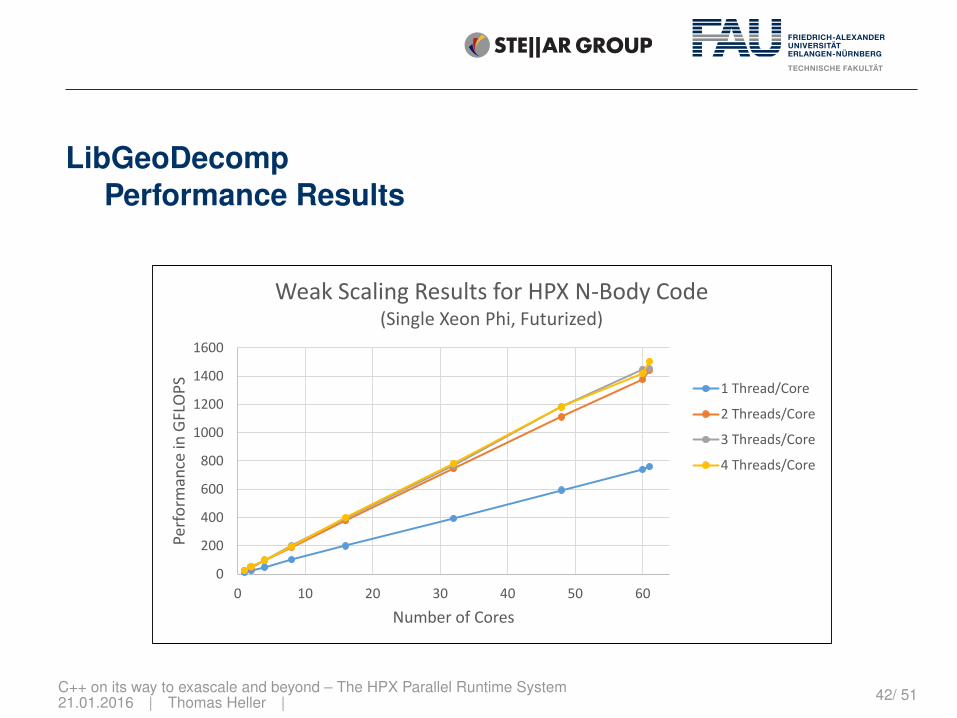
LibGeoDecompPerformance Results
0
200
400
600
800
1000
1200
1400
1600
0 10 20 30 40 50 60
Perf
orm
ance
in G
FLO
PS
Number of Cores
Weak Scaling Results for HPX N-Body Code(Single Xeon Phi, Futurized)
1 Thread/Core
2 Threads/Core
3 Threads/Core
4 Threads/Core
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 42/ 51
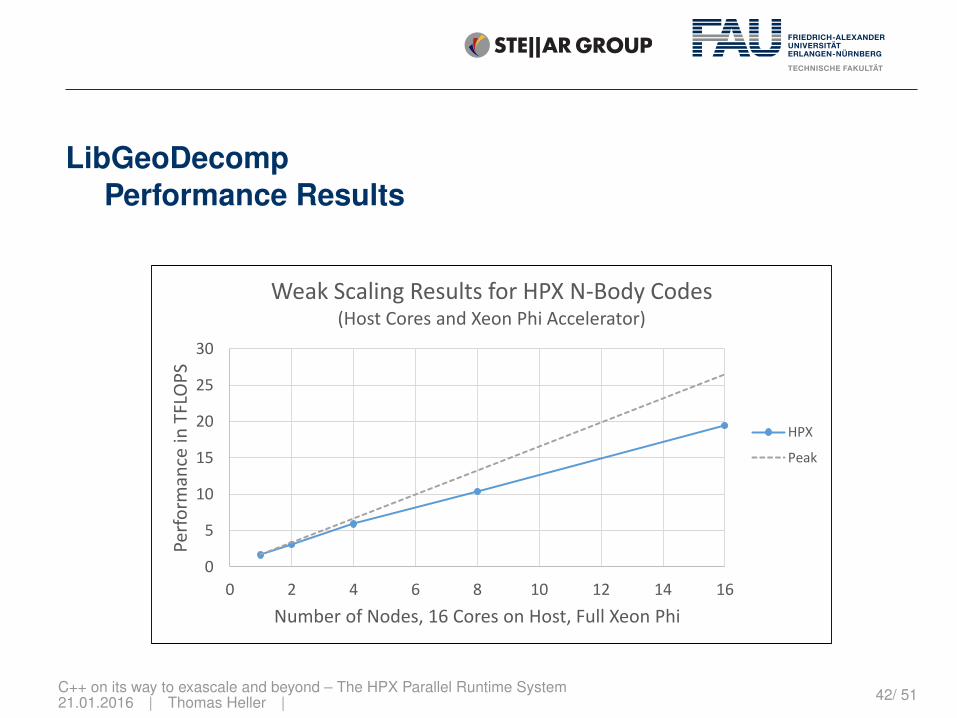
LibGeoDecompPerformance Results
0
5
10
15
20
25
30
0 2 4 6 8 10 12 14 16
Perf
orm
ance
in T
FLO
PS
Number of Nodes, 16 Cores on Host, Full Xeon Phi
Weak Scaling Results for HPX N-Body Codes(Host Cores and Xeon Phi Accelerator)
HPX
Peak
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 42/ 51
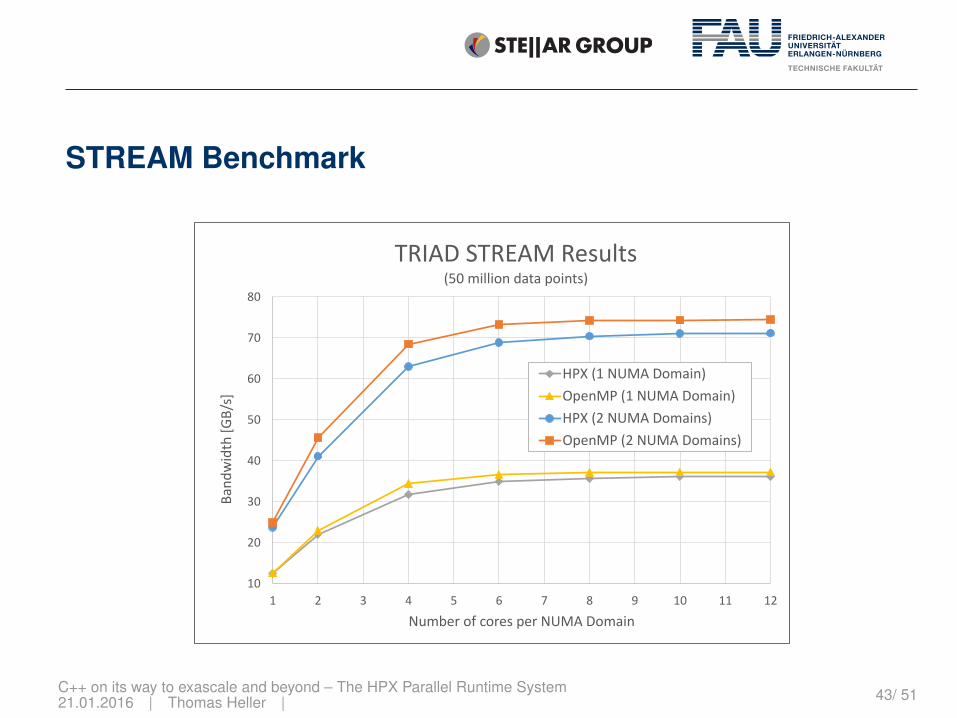
STREAM Benchmark
10
20
30
40
50
60
70
80
1 2 3 4 5 6 7 8 9 10 11 12
Ban
dw
idth
[G
B/s
]
Number of cores per NUMA Domain
TRIAD STREAM Results(50 million data points)
HPX (1 NUMA Domain)
OpenMP (1 NUMA Domain)
HPX (2 NUMA Domains)
OpenMP (2 NUMA Domains)
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 43/ 51
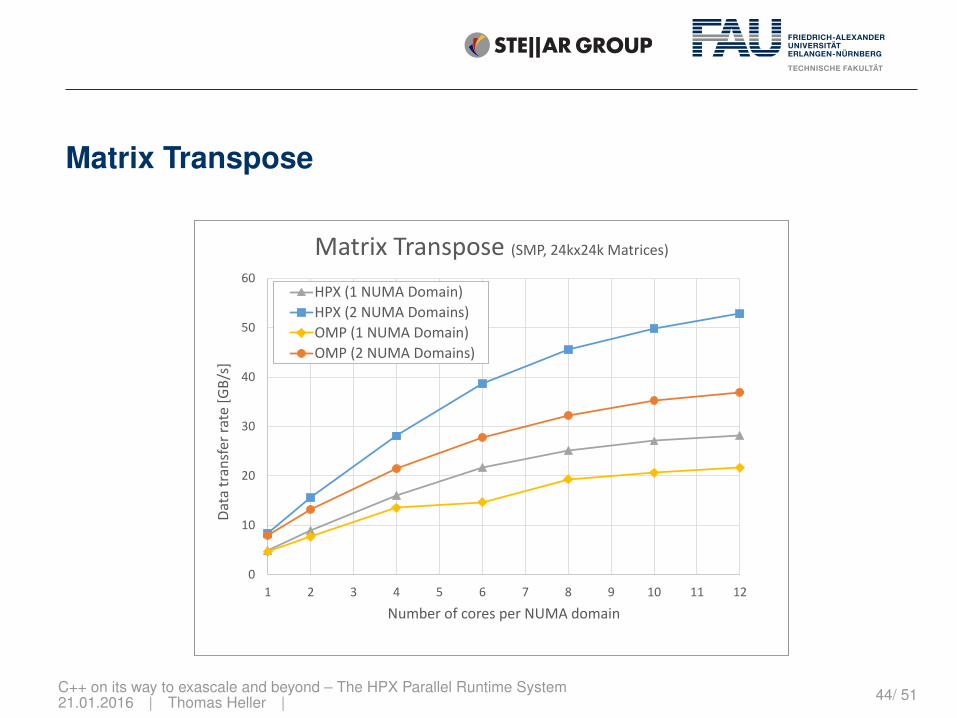
Matrix Transpose
0
10
20
30
40
50
60
1 2 3 4 5 6 7 8 9 10 11 12
Dat
a tr
ansf
er r
ate
[GB
/s]
Number of cores per NUMA domain
Matrix Transpose (SMP, 24kx24k Matrices)
HPX (1 NUMA Domain)
HPX (2 NUMA Domains)
OMP (1 NUMA Domain)
OMP (2 NUMA Domains)
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 44/ 51
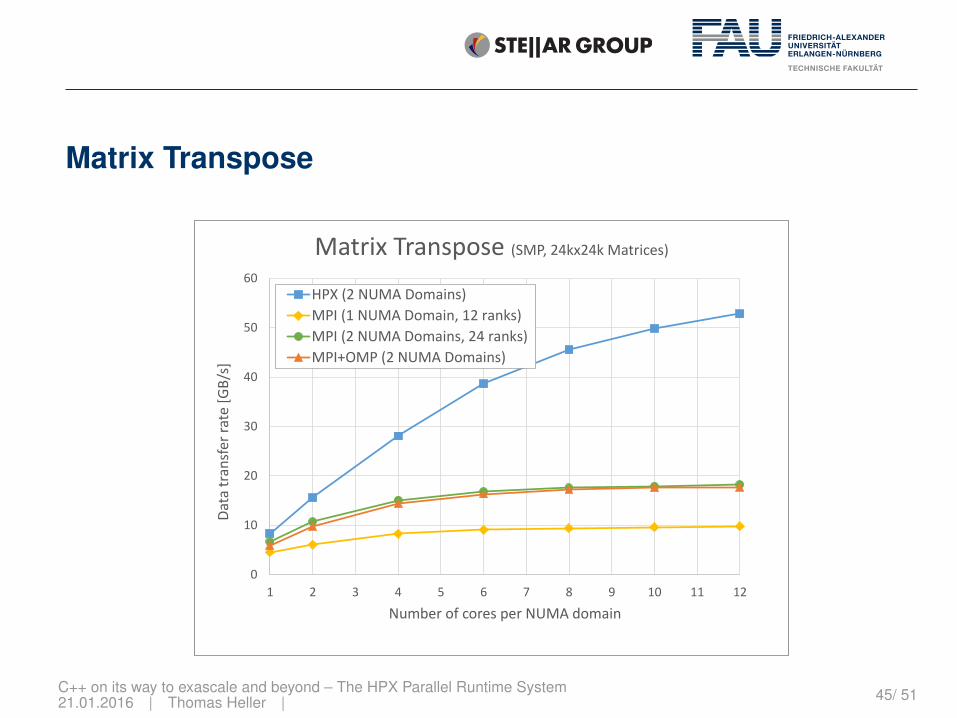
Matrix Transpose
0
10
20
30
40
50
60
1 2 3 4 5 6 7 8 9 10 11 12
Dat
a tr
ansf
er r
ate
[GB
/s]
Number of cores per NUMA domain
Matrix Transpose (SMP, 24kx24k Matrices)
HPX (2 NUMA Domains)
MPI (1 NUMA Domain, 12 ranks)
MPI (2 NUMA Domains, 24 ranks)
MPI+OMP (2 NUMA Domains)
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 45/ 51
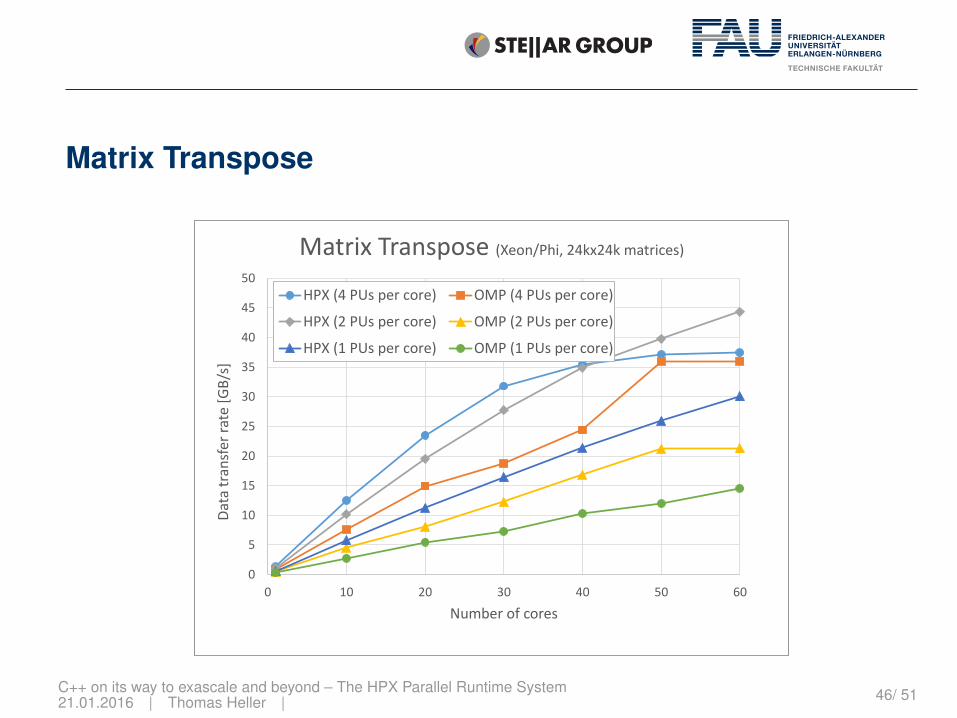
Matrix Transpose
0
5
10
15
20
25
30
35
40
45
50
0 10 20 30 40 50 60
Dat
a tr
ansf
er r
ate
[GB
/s]
Number of cores
Matrix Transpose (Xeon/Phi, 24kx24k matrices)
HPX (4 PUs per core) OMP (4 PUs per core)
HPX (2 PUs per core) OMP (2 PUs per core)
HPX (1 PUs per core) OMP (1 PUs per core)
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 46/ 51
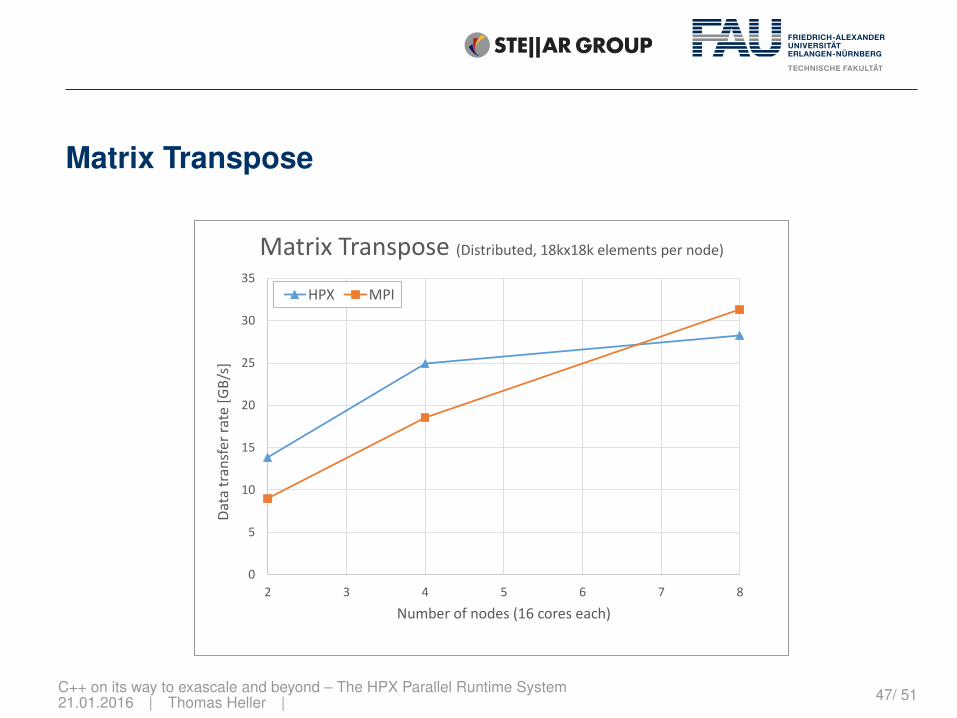
Matrix Transpose
0
5
10
15
20
25
30
35
2 3 4 5 6 7 8
Dat
a tr
ansf
er r
ate
[GB
/s]
Number of nodes (16 cores each)
Matrix Transpose (Distributed, 18kx18k elements per node)
HPX MPI
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 47/ 51

What’s beyond Exascale?
This project has received funding from the Eu-ropean Union‘s Horizon 2020 research and in-novation programme under grant agreement No.671603

Conclusions
Higher-level parallelization abstractions in C++:• uniform, versatile, and generic• All of this is enabled by use of modern C++ facilities• Runtime system (fine-grain, task-based schedulers)• Performant, portable implementation
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 49/ 51

Parallelism is here to stay!
• Massive Parallel Hardware is already part of our daily lives!• Parallelism is observable everywhere:⇒ IoT: Massive amount devices existing in parallel⇒ Embedded: Meet massively parallel energy-aware systems (Epiphany, DSPs,
FPGAs)⇒ Automotive: Massive amount of parallel sensor data to process
• We all need solutions on how to deal with this, efficiently and pragmatically
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 50/ 51

More Information
• https://github.com/STEllAR-GROUP/hpx• http://stellar-group.org• [email protected]• #STE||AR @ irc.freenode.org
Collaborations:• FET-HPC (H2020): AllScale (https://allscale.eu)• NSF: STORM (http://storm.stellar-group.org)• DOE: Part of X-Stack
C++ on its way to exascale and beyond – The HPX Parallel Runtime System21.01.2016 | Thomas Heller | 51/ 51