Embed Size (px)
Citation preview

El mundo Big Data y las APIs
Marco Antonio Sanz

Índice
❏ ¿Quienes somos?
❏ ¿Por qué unir Big Data y las Apis?
❏ ¿Qué es Big Data?
❏ Las 4 Vs
❏ Bases de datos noSQL
❏ Datawarehouses Big Data
❏ Arquitectura Lambda
❏ Arquitectura de Apis
❏ Ejemplos

¿Quienes somos?
Grupo de meetup
http://www.meetup.com/API-Addicts/
Meetups realizados
❏ MADA. Metodología ágil de
definición de APIs
❏ Taller de definición de APIs
❏ Desarrolla tu primera API
❏ Seguridad en las APIs
❏ Las Apis como modelo de negocio
❏ El Mundo Cloud y las APis
Marco Antonio Sanz:http://es.linkedin.com/pub/marco-antonio-sanz-molina-prados/18/335/97/

Patrocinadores
¿qué nos ofrece?
➢ know - how de apis
➢ Experiencia en el gobierno de Apis
➢ Ejemplos de arquitecturas
➢ Experiencia en el mundo Cloud
Calle Velasco 13
Tlf: 658 89 75 75
www.cloudappi.net

➢ Del internet de las cosas...
¿Cómo se van a conectar?
Internet de las APIs
¿Por qué unir Big Data y las Apis?
¿Qué se hacía antes del Big Data?
¿Qué es Big Data?
➢ Clusters
➢ Optimización de servidores de aplicaciones
(cacheo, …)
➢ Optimización de servidores de base de datos
(vistas, vistas materializadas..)
➢ Data Warehouses (OBI, Mondrian…)
➢ ETLs (OBI, Kettle…)

¿Qué es Big Data?
¿Qué es Big Data?
➢ Conjunto de tecnologías
que permiten la
acumulación masiva de
datos.

Convirtiendo Big Data en Valor
The Four V’s
http://www.slideshare.net/BernardMarr/140228-big-data-slide-share

Actividad
Toda las actividades que están
realizando con tu smartphone
se está realizando tracking.
Cualquier app recoge toda la
información de uso, pero
también cosas que utilizamos
cotidianamente como los
navegadores web.
Los sistemas operativos de
cada móvil también recogen
toda la actividad que
realizamos.
The Four V’s
http://www.slideshare.net/BernardMarr/140228-big-data-slide-share

Conversaciones
Todas las conversaciones se
guardan digitalmente. Existen
potentes sistemas de
reconocimiento de voz para
realizar acciones con nuestros
dispositivos son recordadas.
Pj: SIRI de Apple
The Four V’s
http://www.slideshare.net/BernardMarr/140228-big-data-slide-share

Fotos y videos
Todos los dispositivos móviles
se han convertido en cámaras
que van generando contenidos
digitales que a su vez son
subidos en redes sociales,
como Facebook, twiiter,
instagram…
Casi todos los locales tienen su
cámara CCTV, que está
grabando las 24 horas del día.
The Four V’s
http://www.slideshare.net/BernardMarr/140228-big-data-slide-share

Sensores
Cada vez los dispositivos que
utilizamos poseen más
sensores, como el de posición
(GPS), el acelerómetro (lo
llevan normalmente los relojes
inteligentes y las pulseras),
pulsómetros..
La popularización de la
Raspberry pi o las placas
Arduino han ayudado a
aumentar el número de
sensores conectados a internet.
The Four V’s
http://www.slideshare.net/BernardMarr/140228-big-data-slide-share

El internet de las cosas
Cada vez más dispositivos
están conectados a internet.
Hemos pasado de tener los
teléfonos móviles, ordenadores
y tablets, ha tener cualquier
dispositivo como los coches,
relojes, pulseras,
electrodomésticos...
The Four V’s
http://www.slideshare.net/BernardMarr/140228-big-data-slide-share

Consecuencias
➢ Todo lo anterior generar
una gran cantidad de datos
con problemas de :
○ Volumen
○ Velocidad
○ Variedad
○ Veracidad
The Four V’s
http://www.slideshare.net/BernardMarr/140228-big-data-slide-share

Volumen
➢ Toda los datos que se generan van a crear
problemas de almacenamiento y procesamiento de
datos. Hemos pasado de hablar de Terabytes a
Zettabytes o Bronotobytes.
➢ En Internet, cada minuto se publican 6 artículos en
Wikipedia, se envían 204 millones de correos
electrónicos, se descargan 47.000 aplicaciones para
Smartphone y tablets, se abren más de 100 nuevas
cuentas en Linkedin y 320 en Twitter, se realizan
277.000 logins en Facebook que suponen 6 millones
de vistas, se escriben 100.000 tweets, se suben 30
horas de video a YouTube y se ven 1,3 millones de
videos
The Four V’s
http://www.slideshare.net/BernardMarr/140228-big-data-slide-share

Velocidad
➢ Los millones de
dispositivos van a enviar
datos que en ocasiones
van a requerir que sean
procesados en tiempo real.
Las aplicaciones de social
media necesitan que cada
actualización se visualice
al instante.
The Four V’s
http://www.slideshare.net/BernardMarr/140228-big-data-slide-share

Variedad
➢ Actualmente se reciben gran
cantidad de datos de
diferentes fuentes. Los
sistemas tradicionales nos
obliga a tener una gran
cantidad de tablas que hacen
que los sistemas adquieran
mayor complejidad.
➢ Más del 80% de los datos son
no estructurados (texto,
imágenes, video, voz..)
The Four V’s
http://www.slideshare.net/BernardMarr/140228-big-data-slide-share

Veracidad
➢ Antes, todos los datos debían
ser veraces, por lo que se
trabajan con sistemas
transaccionales.
➢ Actualmente, los datos
permiten que se pueda jugar
con la veracidad de los datos.
The Four V’s
http://www.slideshare.net/BernardMarr/140228-big-data-slide-share
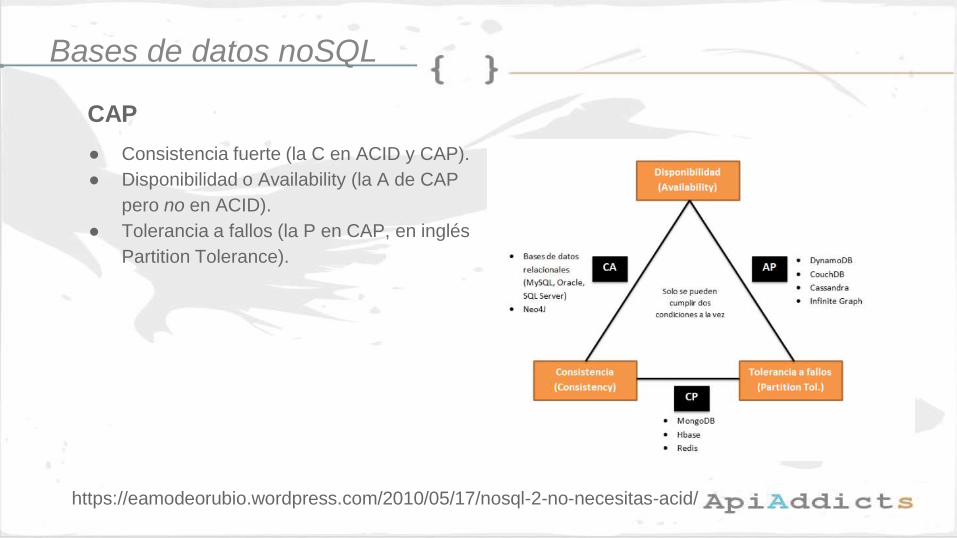
CAP
● Consistencia fuerte (la C en ACID y CAP).
● Disponibilidad o Availability (la A de CAP
pero no en ACID).
● Tolerancia a fallos (la P en CAP, en inglés
Partition Tolerance).
Bases de datos noSQL
https://eamodeorubio.wordpress.com/2010/05/17/nosql-2-no-necesitas-acid/

LandScape MAP
Bases de datos noSQL
http://files.meetup.
com/1789394/Matt
%20Aslett%20-
%20DB%20landsc
ape.pdf

Arquitecturas
Bases de datos noSQL

Llave / Valor
Bases de datos noSQL
La arquitectura Llave/Valor consta en una llave como
“Colonia” que se asocia con un valor “Centro”.
Estas estructuras pueden ser utilizadas como colecciones,
diccionarios, arreglos asociados o caches.
Las búsquedas realizadas en este tipo de estructuras son
rápidas ya que funcionan bajo el concepto de tablas hash.
Considerando la ausencia de índices, este tipo de
estructuras no son útiles para realizar operaciones complejas
con los datos, solo soportan sentencias simples de creación,
lectura, actualización y eliminación.

Llave / Valor - Casandra
Bases de datos noSQL
Apache Cassandra es una base de datos NoSQL distribuida y basada en un modelo de almacenamiento de «clave-valor», escrita en Java.
Permite grandes volúmenes de datos en forma distribuida. Por ejemplo, lo usa Twitter para su plataforma.
Su objetivo principal es la escalabilidad lineal y la disponibilidad. La arquitectura distribuida de Cassandra está basada en una serie de nodos iguales que se comunican con un protocolo P2P con lo que la redundancia es máxima.
Cassandra está desarrollada por Apache Software Foundation.

Llave / Valor - Redis
Bases de datos noSQL
Redis es Open Source, con licencia BSD, que permite el almacenamiento clave valor tanto en memoria como en disco.
Las claves pueden contener texto, hashes, listas, conjuntos, bitmaps o hyperlogs.
Permite suscribirse a la información, por lo que n clientes pueden recibir la información al momento.

Orientadas a Documentos
Bases de datos noSQL
La arquitectura basada en documentos
utiliza una estructura compleja de datos
denominada documento para almacenar los
campos de cada registro. Se pueden
generar arreglos de registros o
anidamientos de documentos. Estas
estructuras de datos son del tipo JavaScript
Object Notation (JSON), XML o BSON o del
tipo binario como PDF

MongoDB
Bases de datos noSQL
Sistema de base de datosNoSQL orientado a documentos, desarrollado bajo el concepto de código abierto.
MongoDB forma parte de la nueva familia de sistemas de base de datos NoSQL. En vez de guardar los datos en tablas como se hace en las base de datos relacionales, MongoDB guarda estructuras de datos en documentos tipo JSON con un esquema dinámico (MongoDB llama ese formato BSON), haciendo que la integración de los datos en ciertas aplicaciones sea más fácil y rápida.
Posee algunas características de las bases de datos tradicionales, como transaccionalidad a nivel de documento, índices…
Además, permite un escalamiento horizontal.

Columnar
Bases de datos noSQL
El modelo de columnar utiliza el esquema de llave/valor para
almacenar la información pero introduce un patrón de
jerarquías y un semi-esquema para ordenar y almacena
los datos, generando las columnas por la que es llamada
esta arquitectura. Las filas contenidas en esta base de datos
pueden variar, es decir pueden contener un número
diferente de campos ya que es una propiedad de los
registros llave/valor. Las tablas de estas bases de datos
deben ser declaradas, lo cual amarra a este tipo de bases a
la presencia de esquemas definidos para trabajar los datos.

Columnar - DynamoDB
Bases de datos noSQL
Amazon DynamoDB es un servicio de base de datos
NoSQL rápido y flexible para todas las aplicaciones
que requiren latencias de milisegundos de un solo
dígito constantes a cualquier escala. Se trata de una
base de datos totalmente gestionada compatible con
modelos de datos de valor de clave y de documentos.
Su modelo de datos flexible y su rendimiento fiable la
convierten en una herramienta ideal para móviles,
web, juegos, tecnología publicitaria, Internet de las
cosas (IoT) y muchas otras aplicaciones.

Grafos
Bases de datos noSQL
Las bases de datos de grafos reconocen entidades en un
negocio o dominio, y explícitamente siguen las relaciones
entre estas. Las entidades reciben el nombre de nodos y
las relaciones el nombre de aristas. Nuevas aristas
pueden ser agregadas en cualquier momento,
permitiendo relaciones uno a muchos o muchos a
muchos de una manera sencilla, evitando el uso de
tablas intermedias para la representación de esta unión,
como será en el caso en una base de datos relacional.
Estas bases de datos se enfocan más en las relaciones
de los datos, más que en las características de sus
valores.

Grafos - neo4j
Bases de datos noSQL
Neo4j es altamente escalable, robusta base de datos
orientada a grafos (full ACID) . Es utilizada por miles
de startups, compañías y gobiernos. Sus
características principales son las siguiente:
➢ Alto rendimiento para datos altamente
conectados.
➢ Alta disponibilidad en Clúster.
➢ Cypher, un lenguaje de queries para grafos.
➢ ETL, fácil importar a través de un CSV
➢ Backups en caliente y monitorización avanzada.

Big Query
➢ Big Query permite que los
datos puedan ser
consumidos y utilizados
utilizando SQL - like queries
que utilizan la
infraestructura de Google
para realizar computación
paralela.
DWS Big Data
https://cloud.google.com/bigquery/what-is-bigquery

Amazon Redshift
➢ Amazon Redshift es una solución
rápida y totalmente gestionada de
almacén de datos a escala de
petabytes que permite analizar todos
los datos empleando de forma
sencilla y rentable las herramientas
de inteligencia empresarial de que ya
disponga.
DWS Big Data
http://aws.amazon.com/es/redshift/
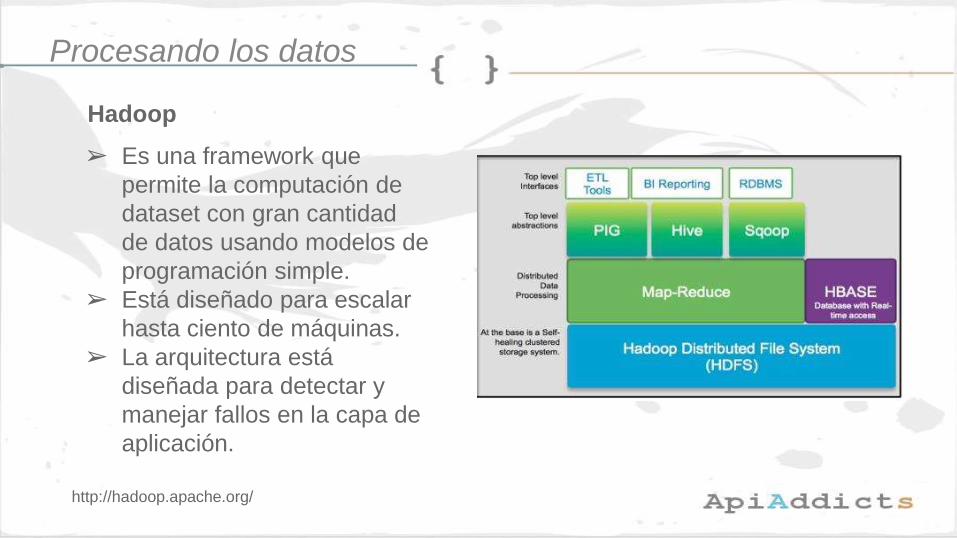
Hadoop
➢ Es una framework que
permite la computación de
dataset con gran cantidad
de datos usando modelos de
programación simple.
➢ Está diseñado para escalar
hasta ciento de máquinas.
➢ La arquitectura está
diseñada para detectar y
manejar fallos en la capa de
aplicación.
Procesando los datos
http://hadoop.apache.org/

AWS Elastic Map Reduce
➢ Es un web service que hace
más fácil el proceso de
ingentes cantidades de
datos. Amazon EMR usas
Hadoop, para distribuir los
datos a través del clúster
formado por Amazon EC2.
➢ También puede ejecutar
otros frameworks como
Spark y Presto.
Procesando batch
http://aws.amazon.com/elasticmapreduce/

Storm
Es una tecnología open source que
permite el procesamiento en tiempo
real de datos.
El funcionamiento es simple, va
procesando millones de tuplas por
segundo, en una arquitectura
escalable, orientada a fallos que
garantiza que tus datos van a ser
procesados
Procesamiento online
https://storm.apache.org/

Descripción
Es un conjunto de principios para una
arquitectura de sistemas Big Data en
Tiempo Real.
Tres capas:
❏ Batch layer
❏ Serving layer
❏ Speed layer
Arquitectura Lambda
https://unpocodejava.wordpress.com/2013/09/07/arquitectura-lambda-
principios-de-arquitectura-para-sistemas-big-data-en-tiempo-real/

Batch Layer
Almacena en HDFS el dataset
maestro que es inmutable y
constantemente crece
Crear vistas arbitrarias desde este
dataset vía MapReduce (Hive,
Pig,…).
Arquitectura Lambda
https://unpocodejava.wordpress.com/2013/09/07/arquitectura-lambda-
principios-de-arquitectura-para-sistemas-big-data-en-tiempo-real/

Serving Layer
Se encarga de indexar y exponer las
vistas para que puedan ser
consultadas.
Como las Vistas Batch son estáticas
esta Capa sólo necesita proveer
lecturas y para eso puede usar
Impala, Stinger,…
Arquitectura Lambda
https://unpocodejava.wordpress.com/2013/09/07/arquitectura-lambda-
principios-de-arquitectura-para-sistemas-big-data-en-tiempo-real/

Speed Layer
Computa Vistas cuando llegan los
datos.
Esta Capa sirve para compensar la
alta latencia de la Capa Batch
generando vistas en tiempo real
usando pj Storm
Arquitectura Lambda
https://unpocodejava.wordpress.com/2013/09/07/arquitectura-lambda-
principios-de-arquitectura-para-sistemas-big-data-en-tiempo-real/

Al desarrollar una API
➢ Selección de la base de datos noSQL según el teorema CAP.
Pueden coexistir bases de datos noSQL con SQL.
➢ Utilizar el mundo cloud como base.
➢ Utilizar las tecnologías que mejor se ajusten a tu negocio (tener
en cuenta arquitectura Lambda).
➢ Usar formato ligeros de datos (por ejemplo, peticiones rest).
➢ No utilizar sesión en las peticiones.
➢ Al invocar servicios de terceros se deben realizar siempre de
forma asíncrona
Arquitectura de Apis

Ejemplo
Arquitectura de Apis

Ejemplos
➢ GPS status. Ayuda a senderistas a geolocalizarse
➢ BBVA wallet. Envía automáticamente los
tickets de compra
Big Data

➢ http://books.google.es/books?id=HpHcGAkFEjkC&printsec=frontcover&s
ource=gbs_ge_summary_r&cad=0#v=onepage&q&f=false
➢ http://www.slideshare.net/BernardMarr/140228-big-data-slide-share
➢ http://www.slideshare.net/IMEXresearch/big-data-overview-
9997959?next_slideshow=1
➢ http://www.slideshare.net/dpottecher/20141113-big-
tourismmygosunbigdata?qid=52b87c49-1c33-4326-8f5d-
9254ce57b4bd&v=default&b=&from_search=1
➢ http://slides.com/vadail/bigdata#/
Referencias

Ruegos y preguntas


Contacta en:
Email: [email protected]
Web:
http://www.meetup.com/APIAddicts
Siguenos en:
➢ Linkedin: ApiAddicts
➢ Twitter: @apiaddicts
➢ Facebook: APIAddicts
➢ Meetup: APIAddicts
Contacta





























