Embed Size (px)
Citation preview

Melbourne / April 2015
Introducing DataFrames
R on Spark
Large Scale Machine Learning
Speakers
Ned Shawa
Mark Moloney
Dr. Zhen He

Agenda
• Apache Spark 1.3 Overview 6:15 – 6:30 (Ned)• DataFrames for Apache Spark 6:30 – 7:00 (Ned)• R on Apache Spark 7:00 – 7:30 (Mark)• Large Scale Machine Learning on Spark 7:30 – 8:15 (Zhen)

News
• Hadoop + Strata• Jobs• Meetup Update• Personal Announcement• Call for Contribution

Contributions so far…..
• Mark with R on Spark, Scala 101• Tim with Building Spark on IDEs• Con with building Spark with Gradle• More?

Whats new in Spark 1.3
• Multi Level Aggregation Trees• Improved Error reporting• SSL Encryption for Control messages and WebUI• DataFrames API• Backward compatibility for HIVE• Writing data in source• JDBC Driver• New Algorithms for MLLIB• Direct KAFKA API

More Data Sources APIs
04/13/15

What are DataFrames?
• Distributed Collection of Data organized in Columns• Equivalent to Tables in Databases or DataFrame in R/PYTHON• Much richer optimization than any other implementation of DF• Can be constructed from a wide variety of sources and APIs

Writing a DataFrame
val df = sqlContext.jsonFile("/home/ned/attendees.json")
df.show()
df.printSchema()
df.select ("First Name").show()
df.select("First Name","Age").show()
df.filter(df("age")>40).show()
df.groupBy("age").count().show()

DataFrame with RDD
case class attendees_class (first_name: String, last_name:String, age:Int)
Val attendees=sc.textFile("/home/ned/attendees.csv").map(_.split(",")).map(p=>attendees_class(p(0),p(1),p(2).trim.toInt)).toDF()
people.registerTempTable("attendees")
val youngppl=sqlContext.sql("select first_name,last_name from attendees where age <35")
youngppl.map(t=>"Name: " +t(0)+ " " + t(1)).collect().foreach(println)

DataFrames and Parquet
attendees.saveAsParquetFile("/home/ned/attendees.parquet")
val pfile = sqlContext.parquetFile("/home/ned/attendees.parquet")
pfile.printSchema()
pfile.registerTempTable("attendees_parquet")
val old_ppl=sqlContext.sql("select first_name,last_name,age from attendees_parquet where age >=35 order by age desc")
old_ppl.map(t=>"Name: " + t(0)+" "+t(1)+ " Age " +t(2)).collect().foreach(println)

DataFrames and JDBC
val jdbc_attendees = sqlContext.load("jdbc", Map("url" -> "jdbc:mysql://localhost:3306/db1?user=root&password=xxx","dbtable" -> "attendees"))
jdbc_attendees.show()
jdbc.attendees.count()
jdbc_attendees.registerTempTable("jdbc_attendees")
val countall = sqlContext.sql("select count(*) from jdbc_attendees")
countall.map(t=>"Records count is "+t(0)).collect().foreach(println)

Dataframes for Apache Spark
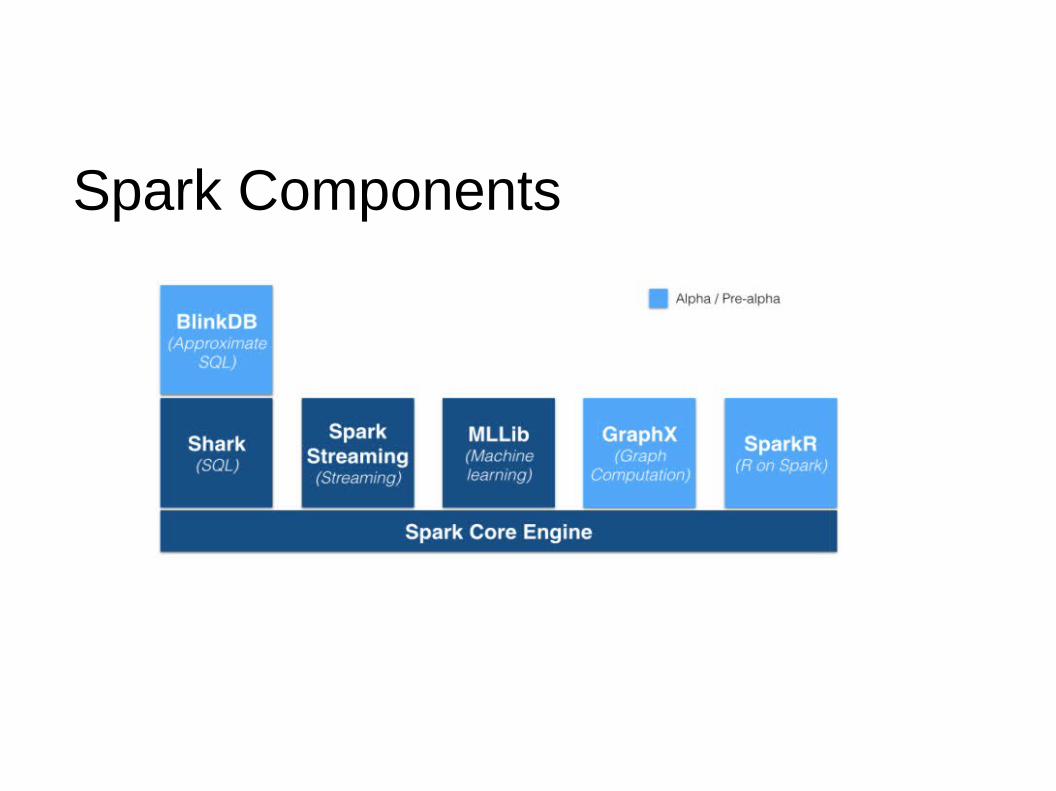
Spark Components

Introduction to SparkR
Mark Moloney
April 2015
https://github.com/markmo/sparkr-meetup-sparkr-demo
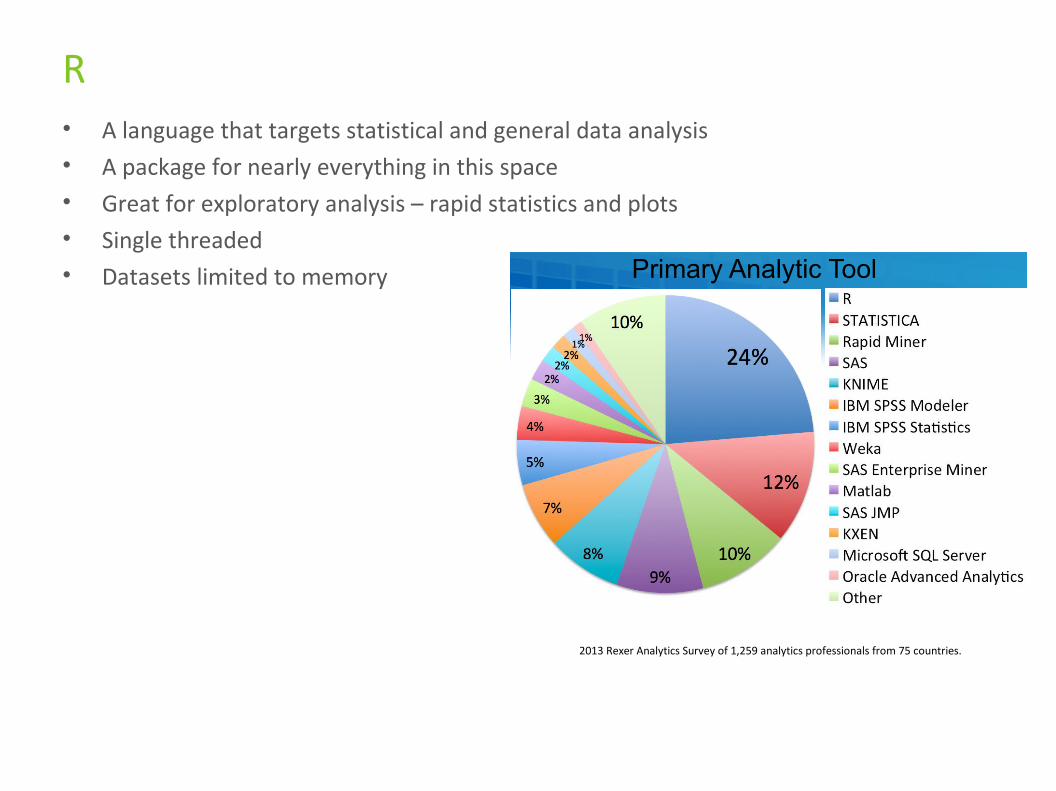
R• A language that targets statistical and general data analysis• A package for nearly everything in this space• Great for exploratory analysis – rapid statistics and plots• Single threaded• Datasets limited to memory
2013 Rexer Analytics 29
Tool Selection
*Cluster analysis was conducted on data miners’ ratings of the importance of 22 tool selection factors.
Primary Analytic Tool
11%
18%
15%
35%
Cost is important
Cost is not important
A
D
B
C
E Ease-of-use & interface quality are important
Ability to write one’s own code is
important
Everything is important
21%
Data miners are a diverse group who are looking for different things from their data mining tools. They report using multiple tools to meet their analytic needs, and even the most popular tool is identified as their primary tool by just 24% of data miners. Over the years, R and Rapid Miner have shown substantial increases.
Cluster analysis* reveals that, in their tool-selection preferences, data miners fall into 5 groups. The primary dimensions that distinguish them are price sensitivity and code-writing / interface / ease-of-use preferences.
2013 Rexer Analytics Survey of 1,259 analytics professionals from 75 countries.

Spark• An evolutionary step up from Map-Reduce programming on Hadoop• Do more with less work• Simpler API than Map-Reduce. Apply functional transforms to datasets. The
framework takes care of distribution of work across multiple machines.• Can cache interim results in memory, which speeds up iterative procedures

SparkR• An R API to Spark’s RDDs (Resilient Distributed Datasets)• Work with massive datasets in R• Works on top of YARN or Mesos• Interactively run jobs on a cluster from the R shell• Exposes the RDD API of Spark as distributed lists in R• Packages and ships variables in the closure to each node• Use includePackage to include third-party packages on
other nodes• Currently only suports R lists and vectors. Data frame
support is in the works.
map / lapplymapPartitions / lapplyPartitiongroupByKeyreduceByKeysampleRDDcollectcachetextFileparallelizebroadcastincludePackage
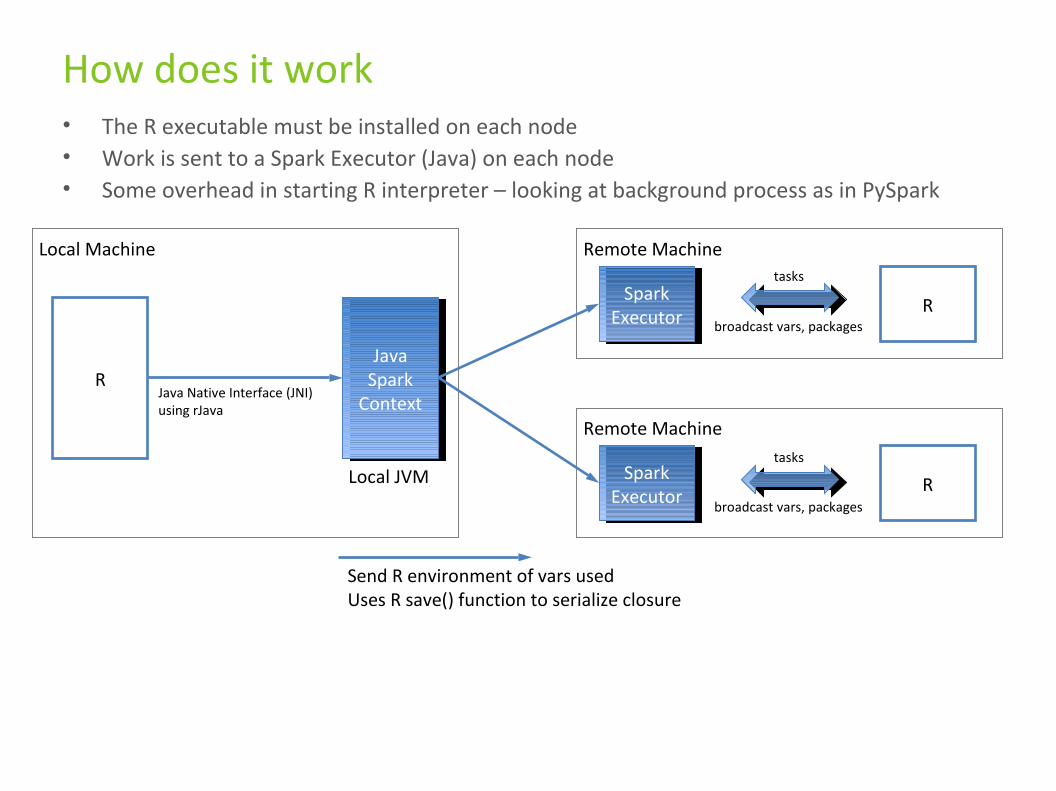
How does it work• The R executable must be installed on each node• Work is sent to a Spark Executor (Java) on each node• Some overhead in starting R interpreter – looking at background process as in PySpark
RJava
Spark Context
Java Spark
ContextJava Native Interface (JNI)using rJava
Local JVM
Local Machine Remote Machine
Remote Machine
Spark ExecutorSpark
Executor
Spark ExecutorSpark
Executor
R
R
tasks
tasks
broadcast vars, packages
broadcast vars, packages
Send R environment of vars usedUses R save() function to serialize closure

Roadmap• Feature-complete DataFrame API• MLLib integration
DataFrame Methods•Filter
– filter(df, df$col1 > 0)
•Sort– sortDF(df, asc(df$col1), desc(df$col2))
•Join– join(df1, df2, df1$col1 == df2$col2, "right_outer")
•GroupBy– groupBy(df, df$col1)
•Agg– agg(groupDF, sum(groupDF$col2), max(groupDF$col3))

Demos

Document Similarity Example• Collection of inaugural speeches of US presidents• Using Shingles and Jaccard similarity
– A k-shingle for a document is a sequence of k characters that appear in the document– Example: k = 2; doc = abcab. Set of 2-shingles = {ab, bc, ca}– Intuitively, documents that are similar will have many shingles in common– Robust to small changes, e.g. reordering a paragraph only affects the 2k chingles that cross
paragraph boundaries– Jaccard similarity is intersection / union
k = 6doc1: “The cat sat”doc2: “The cat ate”
‘The ca’‘he cat’‘e cat ‘‘ cat s’‘cat sa’‘at sat’‘ cat a’‘cat at’‘at ate’
doc1111111000
doc2111000111
characteristic matrix:
too large in real-world problemstherefore use minhashing

Machine Learning ExampleDigit Classification (MNIST database)
Digit(Classification:(MNIST(
Digits consist of 784 pixel valuesTraining set: 60,000 images; Test set: 10,000
Citations• http://amplab-extras.github.io/SparkR-pkg/ - main site• http://ampcamp.berkeley.edu/5/exercises/sparkr.html - hands-on exercises• http://spark-summit.org/2014/talk/sparkr-interactive-r-programs-at-scale-2 - MNIST example• https://github.com/kiendang/sparkr-naivebayes-example - how to integrate with MLLib now• https://github.com/cafreeman/Demo_SparkR - New API

24
Spark Machine Learning Experiences
Speaker: Zhen He

25
Talk Outline● Spark is awesome!● Example of spark in action● Why spark is good for machine learning?● Big Data versus big parameters● What I wish you could do in spark● Competing scalable machine learning systems● Dispel some common myths about spark and
Scala● Current spark machine learning projects from our
group● Conclusion● Demonstration

26
Spark is Awesome!

27
Focus of Talk is on Performance

28
Example of Spark in Action
● Recently did some work with an Australian Government Agency
● Taught Mastering Hadoop and Spark course● Students loved it
● Brain dead at the end ● Use Spark for Machine Learning● Really made excellent use of skills leant in the course for
their project.

29
Summary● Initial R solution
● Never finished● Approximate R + C single core solution
● A couple of days● Accurate spark parallel solution
● 18 minutes● The model worked very well in initial
trial.

30
Lessons Learnt● First reduce complexity of problem● Pre and post processing performance is
very important● Spark is excellent for both the modeling
and the pre and post processing
31
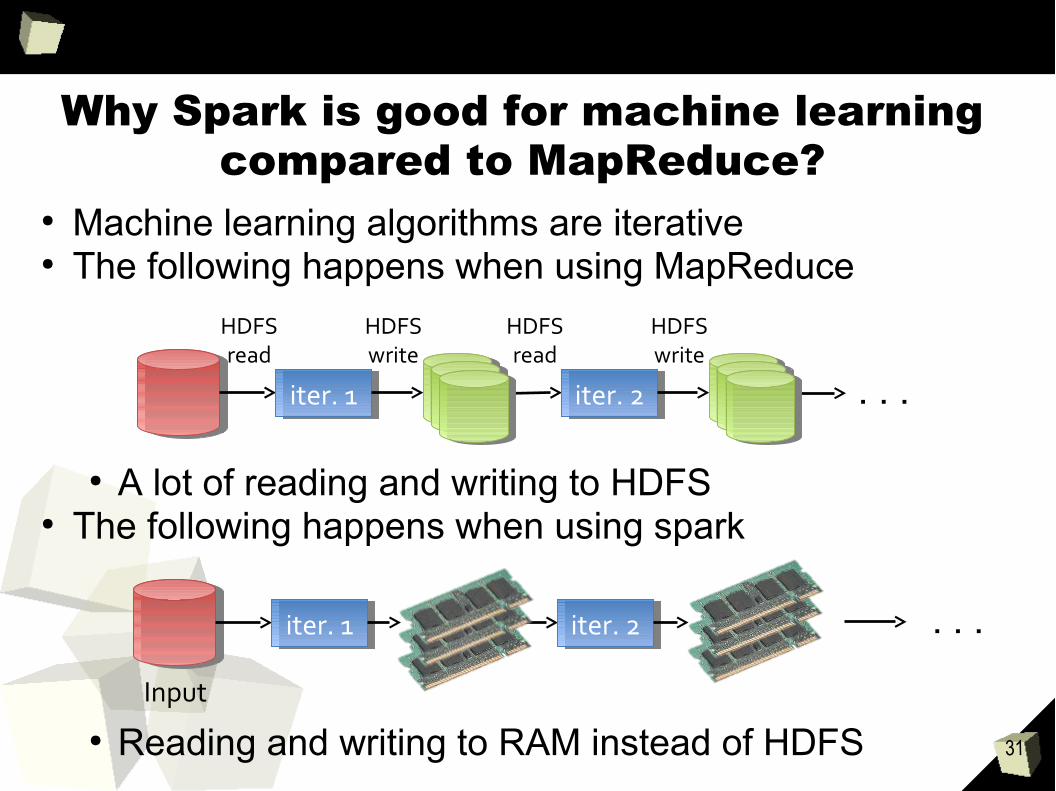
Why Spark is good for machine learning compared to MapReduce?
● Machine learning algorithms are iterative● The following happens when using MapReduce
● A lot of reading and writing to HDFS● The following happens when using spark
● Reading and writing to RAM instead of HDFS
iter. 1iter. 1 iter. 2iter. 2 . . .
HDFSread
HDFSwrite
HDFSread
HDFSwrite
iter. 1iter. 1 iter. 2iter. 2 . . .
Input

32
Make sure you actually cache the data!
val data = MLUtils.loadLibSVMFile(sc, ”datafile.txt")val LR = new LogisticRegressionWithSGD()LR.optimizer.setNumIterations(10)val model = LR.run(data)
The above runs 10 x slower then the code below!
val data = MLUtils.loadLibSVMFile(sc, ”datafile.txt").cacheval LR = new LogisticRegressionWithSGD()LR.optimizer.setNumIterations(10)val model = LR.run(data)

33
Big Data versus Big Parameters
● Spark is great at doing machine learning on Big Data as long as the size of the parameters is small.
● Big parameters is hard for Spark to handle efficiently.

34
What is Big Parameters?
● Big parameter is caused by high dimensional data● Modeling high dimensional data requires a large number
of parameters● In the example above the parameters are the b0, b1, b2,
… bn
35
Examples of High Dimensional Data
Time series
Text
Image
Speech
36
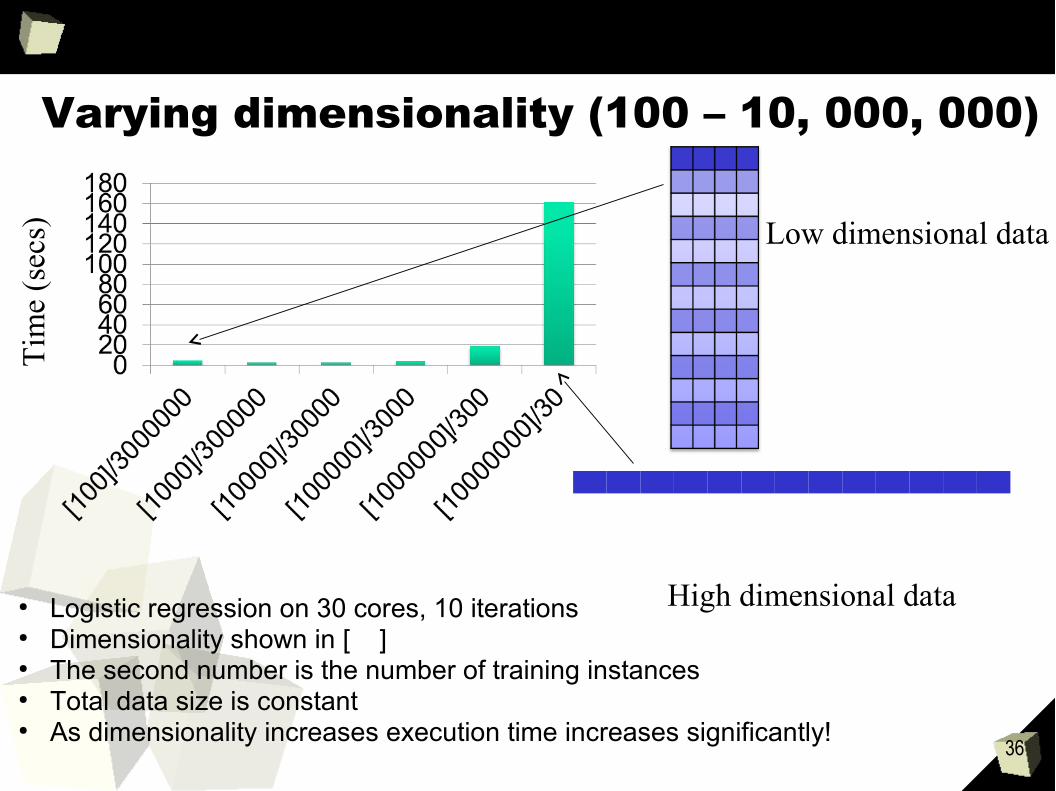
Varying dimensionality (100 – 10, 000, 000)
● Logistic regression on 30 cores, 10 iterations● Dimensionality shown in [ ]● The second number is the number of training instances● Total data size is constant● As dimensionality increases execution time increases significantly!
Tim
e (s
ecs) Low dimensional data
High dimensional data
37
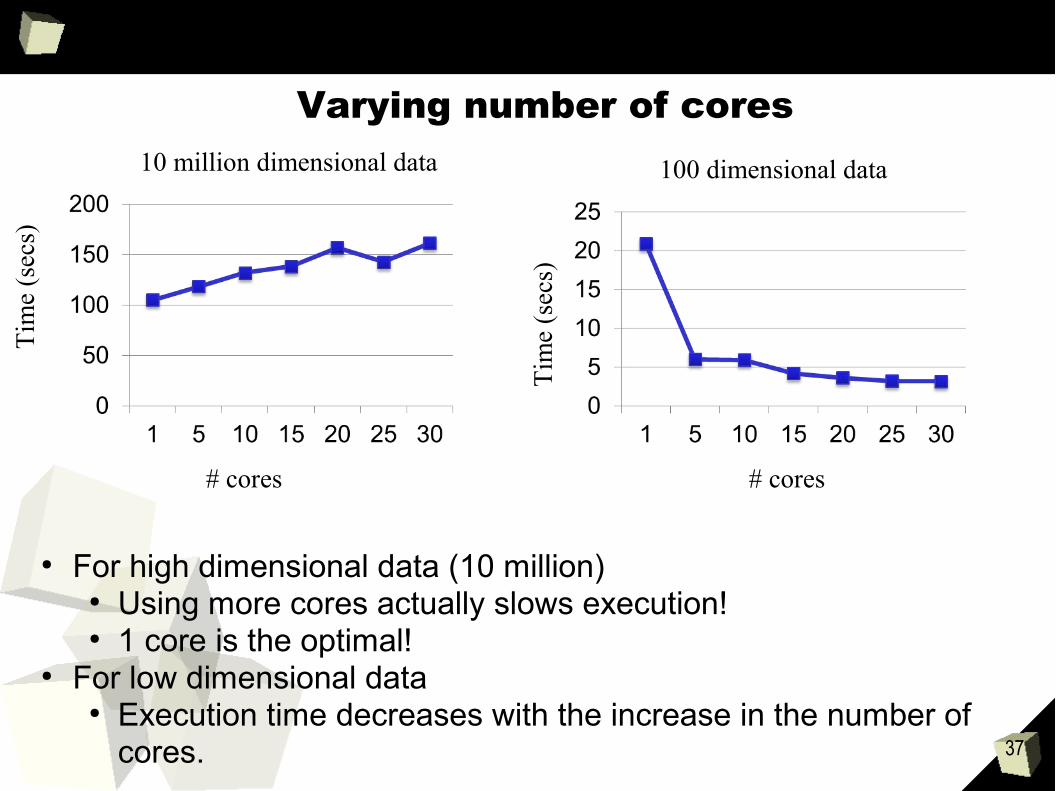
Varying number of cores
● For high dimensional data (10 million)● Using more cores actually slows execution!● 1 core is the optimal!
● For low dimensional data● Execution time decreases with the increase in the number of
cores.
Tim
e (s
ecs)
# cores
10 million dimensional data
# cores
Tim
e (s
ecs)
100 dimensional data

38
Why is big parameters / high dimensional data so
hard for spark?
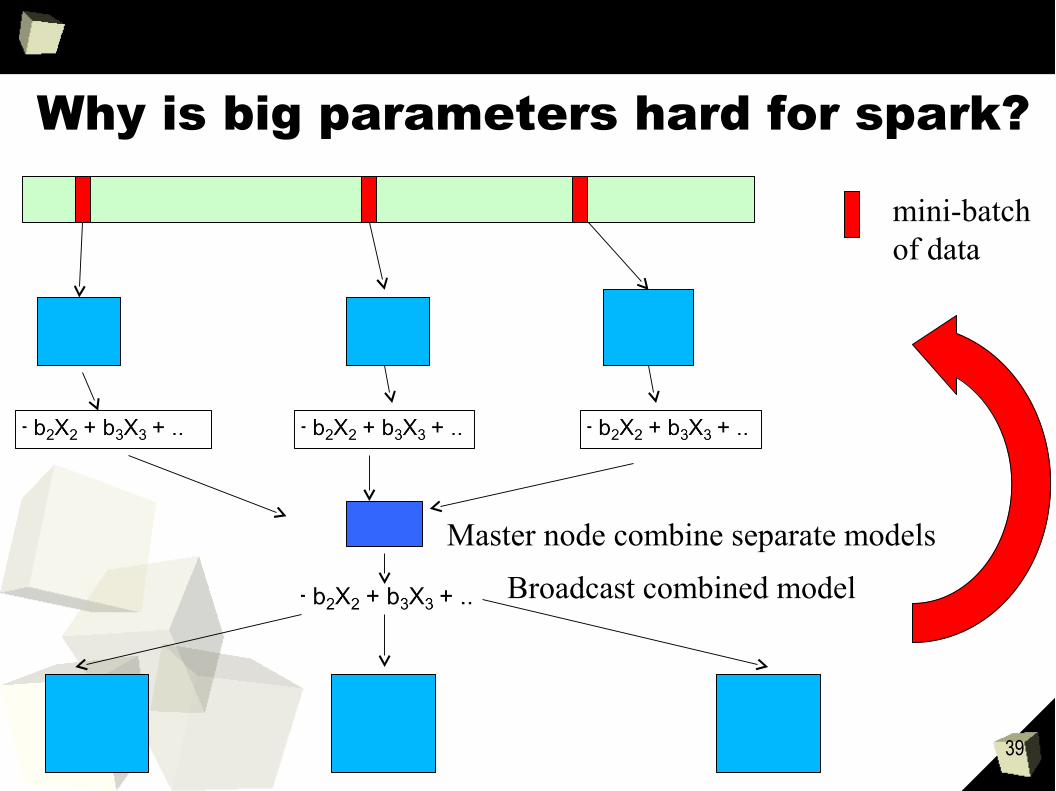
39
Why is big parameters hard for spark?
mini-batchof data
Master node combine separate models
Broadcast combined model
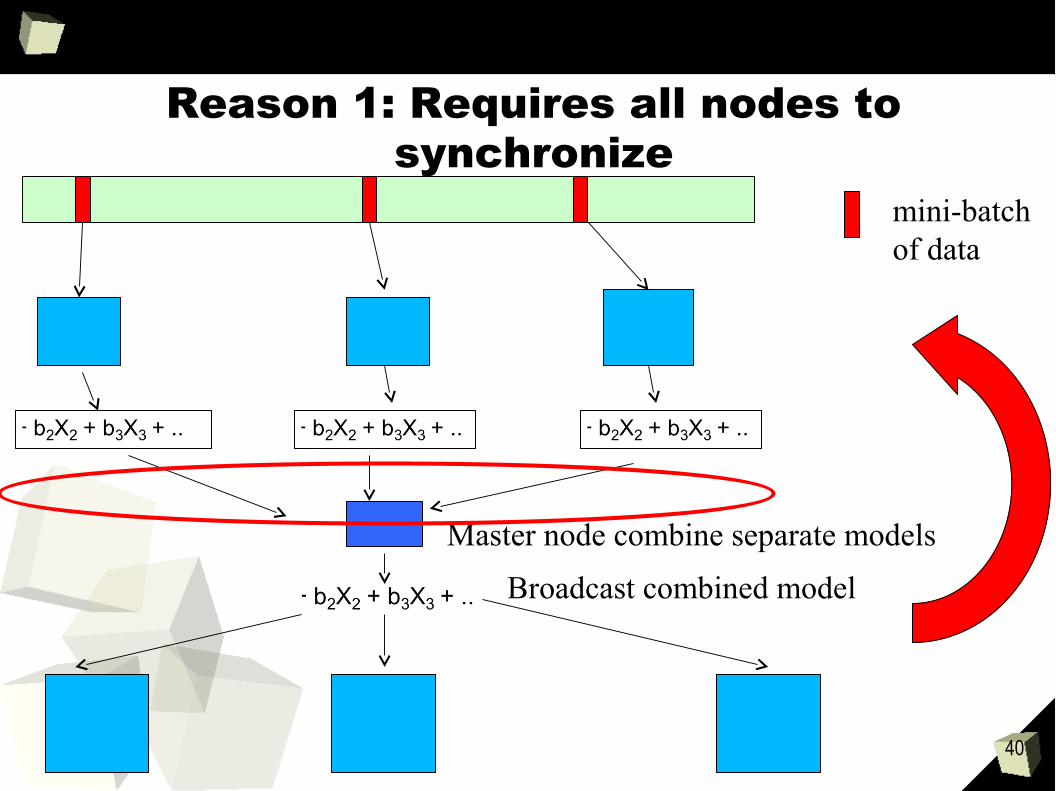
40
Reason 1: Requires all nodes to synchronize
mini-batchof data
Master node combine separate models
Broadcast combined model
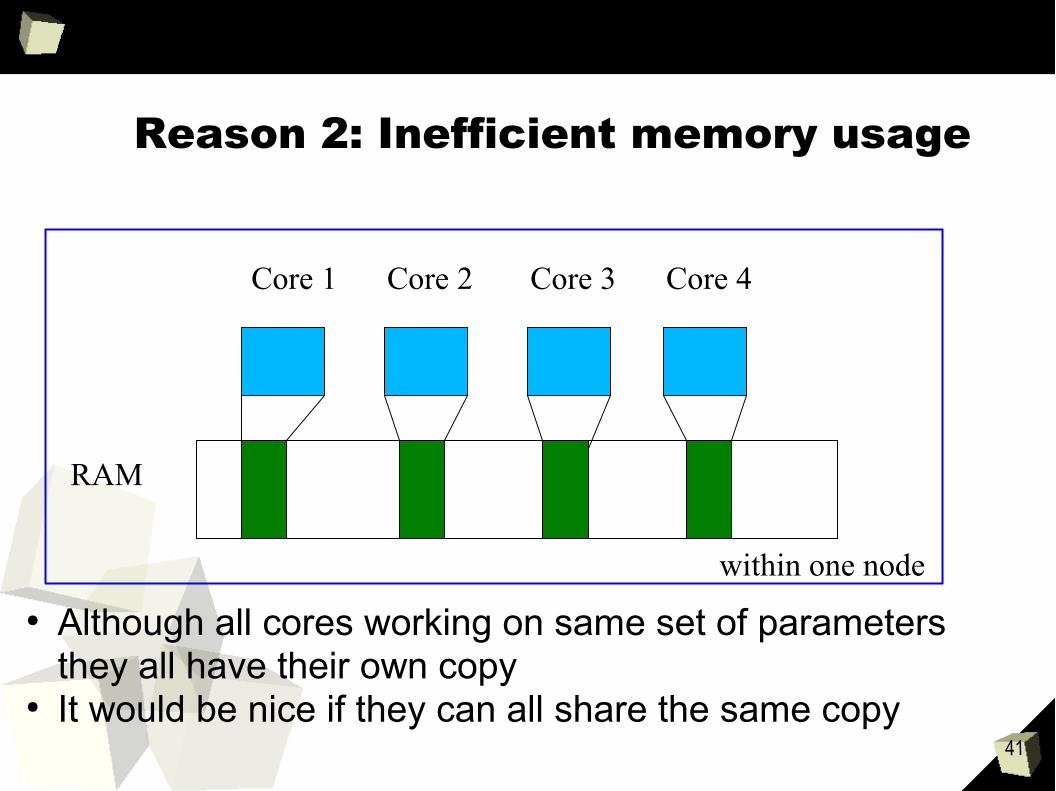
41
Reason 2: Inefficient memory usage
● Although all cores working on same set of parameters they all have their own copy
● It would be nice if they can all share the same copy
RAM
Core 1 Core 2 Core 3 Core 4
within one node
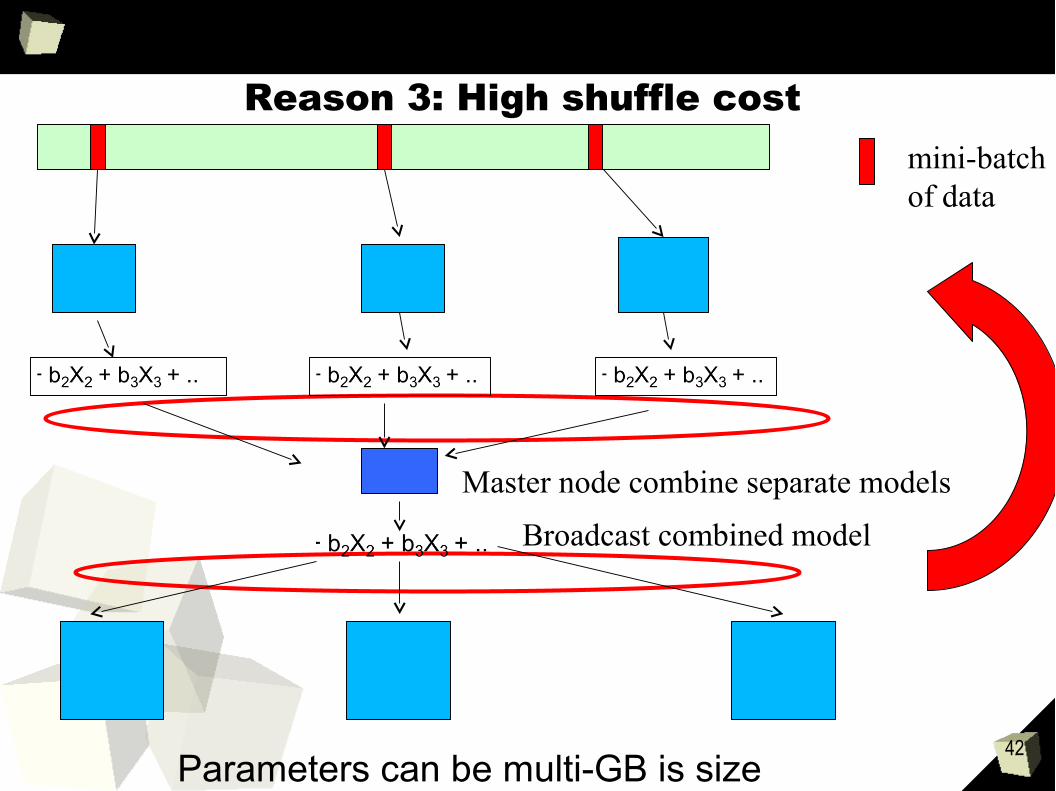
42Parameters can be multi-GB is size
Reason 3: High shuffle costmini-batchof data
Master node combine separate models
Broadcast combined model
43
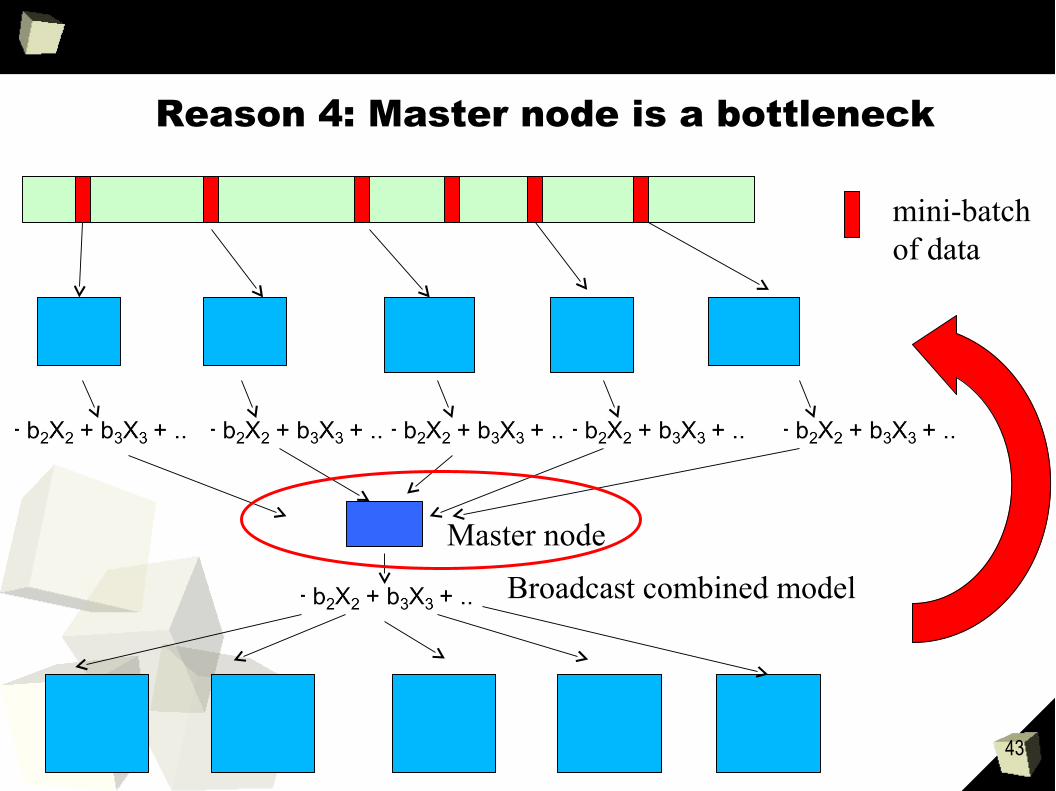
Reason 4: Master node is a bottleneck
mini-batchof data
Master node
Broadcast combined model
44
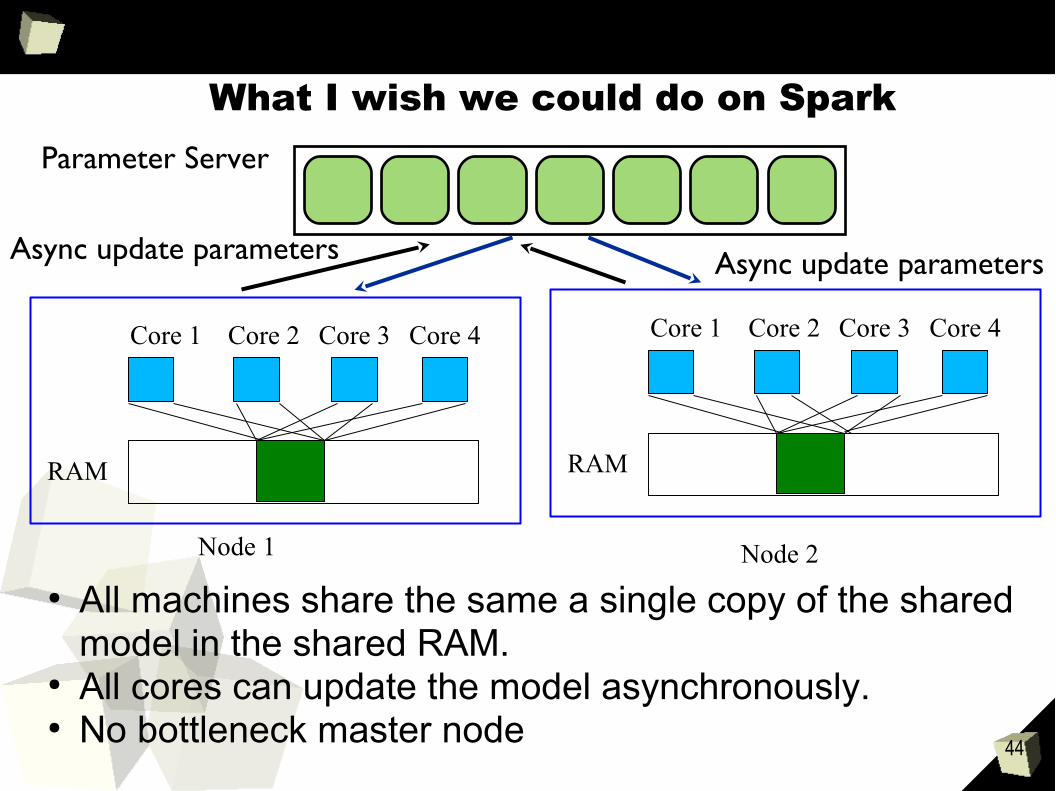
What I wish we could do on Spark
● All machines share the same a single copy of the shared model in the shared RAM.
● All cores can update the model asynchronously.● No bottleneck master node
RAM
Core 1 Core 2 Core 3 Core 4
RAM
Core 1 Core 2 Core 3 Core 4
Node 1 Node 2
Parameter Server
Async update parameters Async update parameters

45
Such a system already exists
● Google’s DistBelief system● J. Dean, G.S. Corrado, R. Monga, K. Chen, M. Devin, Q.V. Le,
M.Z. Mao, M.A. Ranzato, A. Senior, P. Tucker, K. Yang, A. Y. Ng. Large Scale Distributed Deep Networks. NIPS, 2012.
● Closed source● Only people in Google can use it
● Used to train deep learning system with 1 billion parameters on 16, 000 cores

46
Comparison of some key machine learning algorithms in Spark
● Linear Models● Logistic regression● Linear regression● Support vector machines
● Linear kernel● Random forest
47
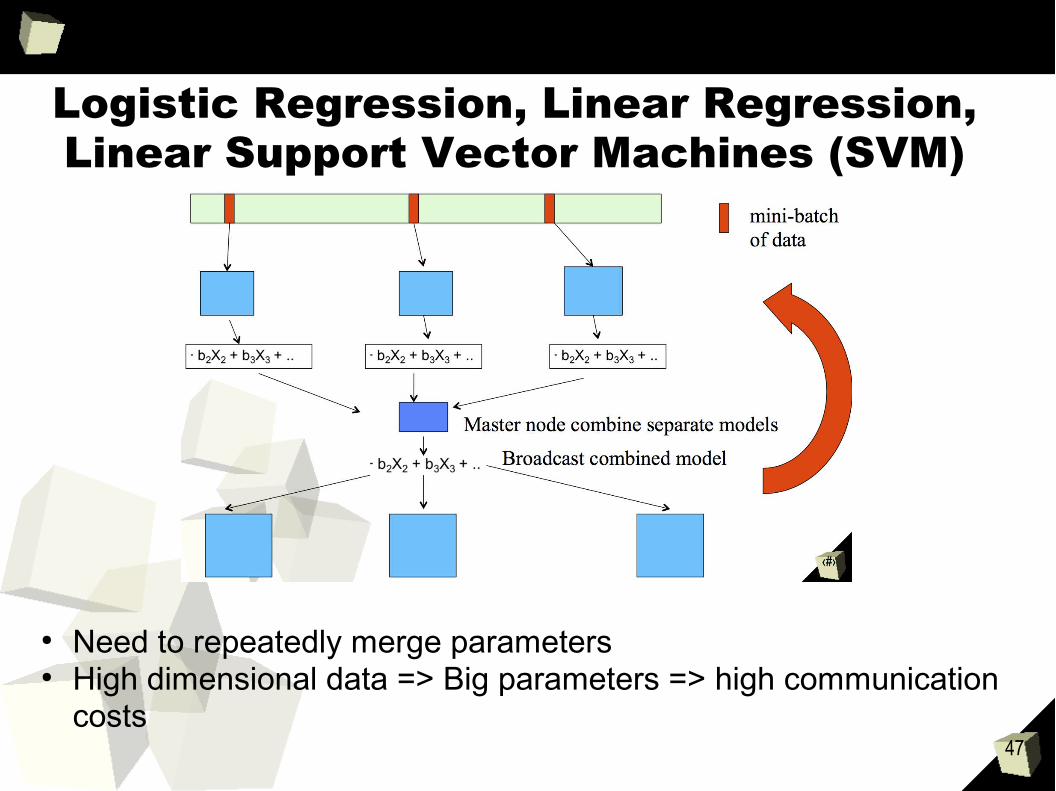
Logistic Regression, Linear Regression, Linear Support Vector Machines (SVM)
● Need to repeatedly merge parameters● High dimensional data => Big parameters => high communication
costs

48
Random Forest
● Can be trained very efficiently● Each task trains on the data of its own partition
● Each tree can be trained separately● No communication or synchronization needed

49
Competing Scalable Machine Learning Systems
● Greenplum● Machine learning via SQL
● Mahout● MapReduce based● Moving to using spark as underlying engine
● Vowpal Wabbit● Good performance● Specialized system
● Graph Lab● Good performance● Need to turn everything into graphs

50
Spark Misconceptions

51
Common Misconception: Spark is only good if data fits in RAM
● From inception Spark was designed to be a general execution engine that works both in-memory and on-disk
● Almost all operators perform external operations when data does not fit in RAM.
● Spark breaks large-scale sort record
52
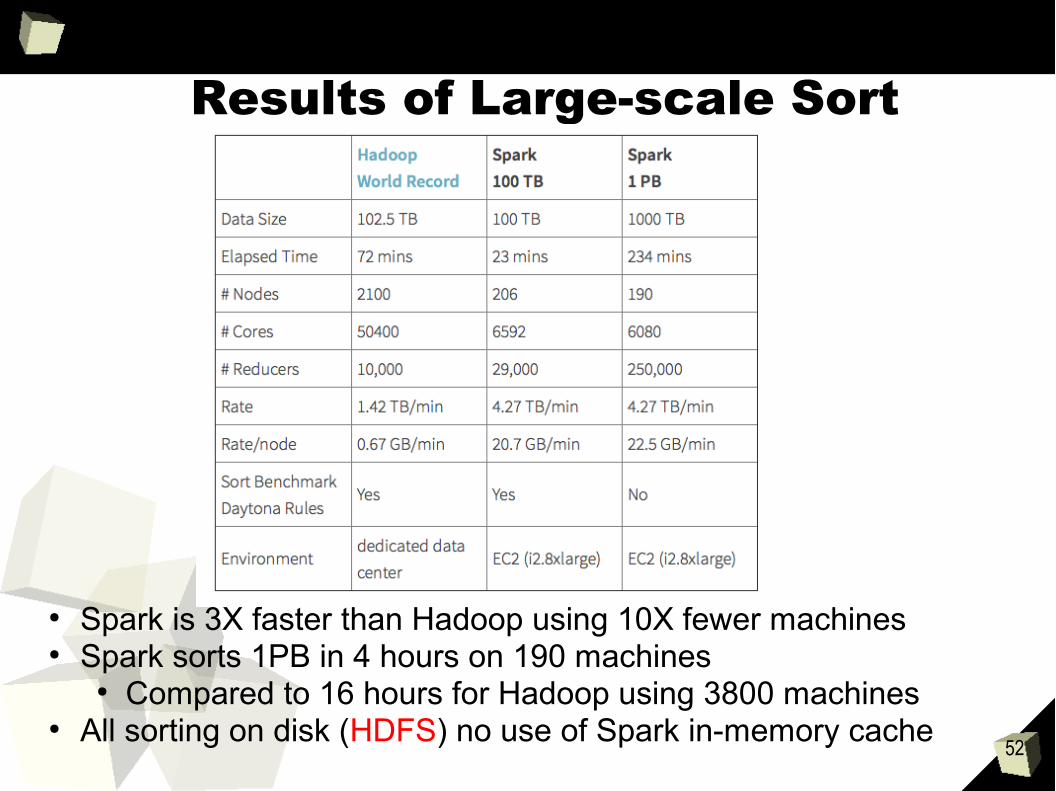
Results of Large-scale Sort
● Spark is 3X faster than Hadoop using 10X fewer machines● Spark sorts 1PB in 4 hours on 190 machines
● Compared to 16 hours for Hadoop using 3800 machines● All sorting on disk (HDFS) no use of Spark in-memory cache

53
How did they do it?
●More efficient Shuffle
●Very efficient scheduling of tasks
54
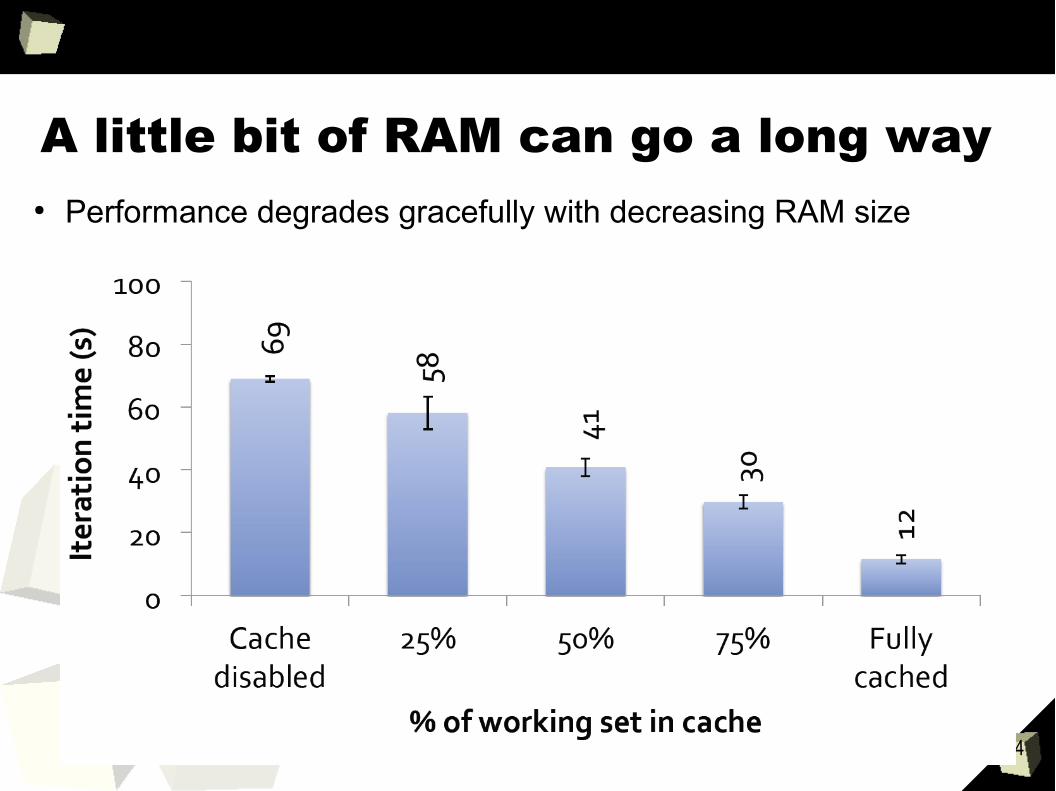
A little bit of RAM can go a long way● Performance degrades gracefully with decreasing RAM size

55
A little bit of RAM can go a long way
● Just cache the small parts of the data that you will use again● Use filter and projection to reduce the amount that is cached.
● Spark SQL stores data compressed in columns● Fast compression/decompression● Column-stores have been proven to be way better than row-
stores for analytics● 100x better
● For normal Spark code (non-SparkSQL), you can store data serialized and compressed in RAM.
● RAM is cheap now days● Aggregate RAM on large cluster can be very large

56
Common Misconceptions● I need to learn a new language Scala
● Scala is easy to learn● Can program in Java and Python● Distributed Dataframes● SparkR
● I have to rewrite all my code● Spark will run MapReduce code unmodified● Spark SQL runs HiveQL

57
Some Real Problems● Scala allocates a lot of objects
● High GC overhead
● The nice functional scala code is much slower than writing C-styled while loops
● For example:● val y = x.map(x => x * x)
● is slower than● var i = 0● while (i < x.length) { y(i) = x(i) * x(i) i += 1
}

58
Our Work

59
Spark API Examples● Almost no good examples on the Spark API calls.● Matthias and I have written examples for over 110 Spark
API calls● http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIEx
amples.html● Great reference ● Currently over 33, 000 hits● Often top Google page returned when searching spark
API calls

60
Deep Learning on Spark● Deep learning is currently very popular● State-of-the-art performance in area such as
● Image recognition● Speech recognition● Natural language processing● etc.
● No good existing distributed open source deep learning implementation
● We are implementing the first serious deep learning implementation on Spark.
● Implemented in Scala

61
Features of our Open Source Spark Deep Learning System
● Stacked auto-encoder● Convolutional neural networks● RICA● Sparse coding● Fully connected networks● Many many different state-of-the-art optimization tricks
like● Dropout, reLU, adagrad, momentum, RMS prop,
etc.

62
Other Current Projects● Zendesk
● Australian institute of sports
● Precision agriculture
● More welcome

63
Mastering Big Data Analytics with Hadoop Course
● 3 day course on Hadoop and Spark● Only pre-requisite is Java programming experience● More than 35 programming exercises● Contents● Hadoop and MapReduce● Hive● Hadoop 2 ecosystem
● Storm, Yarn, Giraph● Spark and Scala● Spark on Amazon

64
Recruiting PhD Students● We have a lot of real world projects to do.● A lot of projects from industry
● Zendesk● Australian Institute of Sports● Precision agriculture● UXC Professional Solutions● More welcome
● We need to expand our research group.● Topics:
● Text mining● Time series mining● Reinforcement learning combined with deep learning● Video mining● etc.

65
Conclusion● Spark is best open source software for distributed
machine learning on Big Data● Be careful of using spark for high dimensional
data● Random forest does not suffer from
performance penalty● Spark programming using Scala is great for ease
of use● Spark is good even if data does not fit in RAM

66
Demonstration
R versus Spark Fight!
67
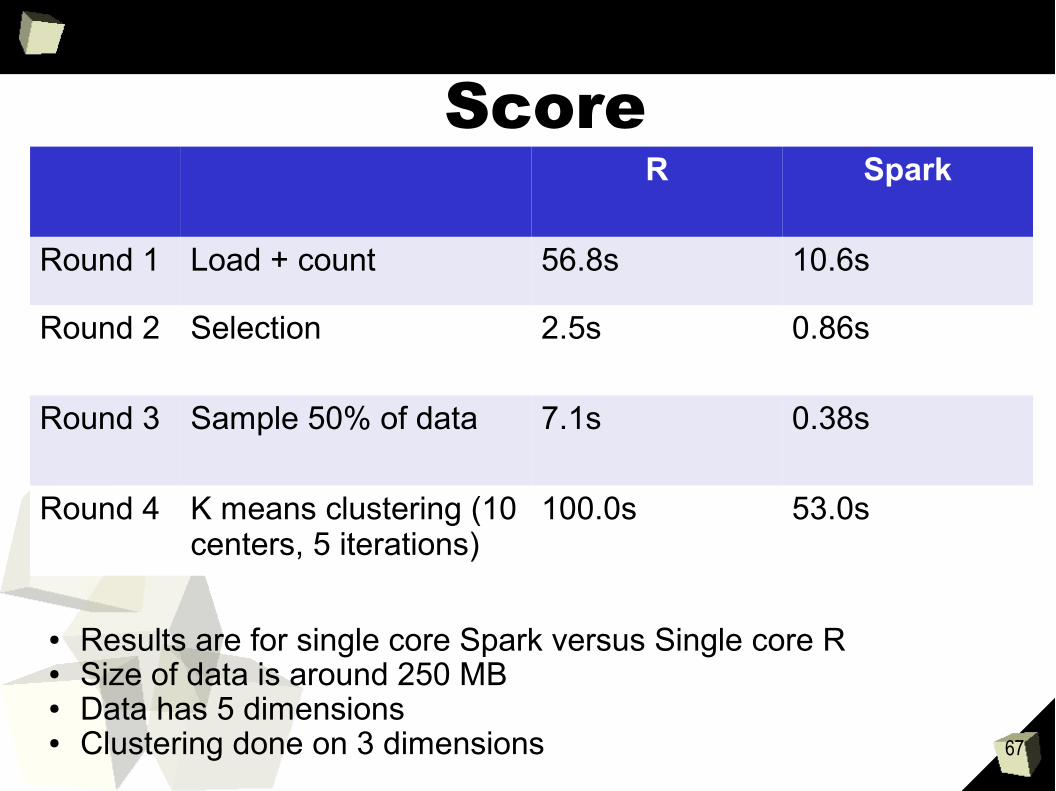
ScoreR Spark
Round 1 Load + count 56.8s 10.6s
Round 2 Selection 2.5s 0.86s
Round 3 Sample 50% of data 7.1s 0.38s
Round 4 K means clustering (10 centers, 5 iterations)
100.0s 53.0s
● Results are for single core Spark versus Single core R● Size of data is around 250 MB● Data has 5 dimensions● Clustering done on 3 dimensions

















![[Spark meetup] Spark Streaming Overview](https://img.pdfslide.us/doc/110x75/55a457161a28ab057e8b45fd/spark-meetup-spark-streaming-overview.jpg)











