Embed Size (px)
Citation preview

Adaptive Thread Scheduling Techniques for Improving Scalability of Software
Transactional Memory
Kinson Chan, King Tin Lam, Cho-Li Wang
Presenter: Kinson ChanDate: 16 February 2010
PDCN 2011, Innsbruck, Austria
DEPARTMENT OF COMPUTER SCIENCETHE UNIVERSITY OF HONG KONG

Outline
• Motivation –‣ hardware trend and software transactional memory
• Background –‣ performance scalability‣ ratio-based concurrency control and its myth
• Solution –‣ our rate-based heuristic, Probe.
• Evaluation –‣ performance comparison
2

MotivationWhat is the current computing hardware trend,
and why is software transactional memory relevant?

Hardware trend: multicores
• Multicore processors‣ a.k.a. chip multiprocessing‣ multiple cores on a processor die‣ cores share a common cache‣ faster data sharing among threads‣ more running threads per cabinet
• Chip Multithreading‣ e.g. hyperthreading, coolthreads‣ more than one threads per core‣ hide the data load latency
4
L1! L1! L1! L1!
L2! L2! L2! L2!
L3!
1! 2! 3! 4! 5! 6! 7! 8!
a typical modern processor

Hardware trend: multicores
• Multicore processors‣ a.k.a. chip multiprocessing‣ multiple cores on a processor die‣ cores share a common cache‣ faster data sharing among threads‣ more running threads per cabinet
• Chip Multithreading‣ e.g. hyperthreading, coolthreads‣ more than one threads per core‣ hide the data load latency
4
L1! L1! L1! L1!
L2! L2! L2! L2!
L3!
1! 2! 3! 4! 5! 6! 7! 8!
Multiple cores
a typical modern processor

Hardware trend: multicores
• Multicore processors‣ a.k.a. chip multiprocessing‣ multiple cores on a processor die‣ cores share a common cache‣ faster data sharing among threads‣ more running threads per cabinet
• Chip Multithreading‣ e.g. hyperthreading, coolthreads‣ more than one threads per core‣ hide the data load latency
4
L1! L1! L1! L1!
L2! L2! L2! L2!
L3!
1! 2! 3! 4! 5! 6! 7! 8!
Mutli-threadper core
a typical modern processor

Now and future multicores
5
Micro-architecture Clock rate Cores Threads per
coreThreads per
package Shared cache Memory arrangement
IBM Power 7 ~ 3 GHz 4 ~ 8 4 32 Max 4 MBshared L3 NUMA
Sun Niagara2 1.2 ~ 1.6 GHz 4 ~ 8 8 64 Max 4 MBshared L2 NUMA
Intel Westmere ~ 2 GHz 4 ~ 8 2 16 Max 12 ~ 24 MB
shared L3 NUMA
Intel Harpertown ~ 3 GHz 2 x 2 2 8 2 x 6 MB
shared L3 UMA
AMD Bulldozer ~ 2 GHz 2 x 6 ~ 2 x 8 1 16 Max 8 MB
shared L3 NUMA
AMD Magny-Cours ~ 3 GHz 8 modules 2 per module 16 Max 8 MB
shared L3 NUMA
Intel Terascale ~ 4 GHz 80? 1? 80? 80 x 2 KBdist. cache NUCA

Now and future multicores
5
Micro-architecture Clock rate Cores Threads per
coreThreads per
package Shared cache Memory arrangement
IBM Power 7 ~ 3 GHz 4 ~ 8 4 32 Max 4 MBshared L3 NUMA
Sun Niagara2 1.2 ~ 1.6 GHz 4 ~ 8 8 64 Max 4 MBshared L2 NUMA
Intel Westmere ~ 2 GHz 4 ~ 8 2 16 Max 12 ~ 24 MB
shared L3 NUMA
Intel Harpertown ~ 3 GHz 2 x 2 2 8 2 x 6 MB
shared L3 UMA
AMD Bulldozer ~ 2 GHz 2 x 6 ~ 2 x 8 1 16 Max 8 MB
shared L3 NUMA
AMD Magny-Cours ~ 3 GHz 8 modules 2 per module 16 Max 8 MB
shared L3 NUMA
Intel Terascale ~ 4 GHz 80? 1? 80? 80 x 2 KBdist. cache NUCA
How can we scale our program to have these many threads?

Multi-threading and synchronization
6

Multi-threading and synchronization
6
Coarse grain locking
Easy / Correct(few locks, predictable)
Difficult to scale(excessive mutual
exclusion)

Multi-threading and synchronization
6
Coarse grain locking
Easy / Correct(few locks, predictable)
Difficult to scale(excessive mutual
exclusion)
Fine-grain locking
Error prone(deadlock, forget to
lock, ...)
Scales better(allows more parallelism)

Multi-threading and synchronization
6
Coarse grain locking
Easy / Correct(few locks, predictable)
Difficult to scale(excessive mutual
exclusion)
Fine-grain locking
Error prone(deadlock, forget to
lock, ...)
Scales better(allows more parallelism)
Do we have anything in between?
Easy / Correct
Scales good

STM optimistic execution
7
Begin Begin
Proceed Proceed
Commit Commit
Retry
Commit
x=x+4
y=y-4
x=x+2
y=y-2
Begin
Proceed Begin
Proceed
Commit
Commit
x=x+4
y=y-4
w=w+5
z=w
Thread 1 Thread 2 Thread 3 Thread 1 Thread 2 Thread 3
x=x+2
y=y-2
Success
Success
Success
Success
conflict detection
conflict detection
begin; x=x+4; y=y-4; commit;
begin; x=x+2; y=y-2; commit;
begin; x=x+4; y=y-4; commit;
begin; w=w+5; z=w; commit;
begin;x = x + 4;y = y - 4;commit;

STM optimistic execution
7
Begin Begin
Proceed Proceed
Commit Commit
Retry
Commit
x=x+4
y=y-4
x=x+2
y=y-2
Begin
Proceed Begin
Proceed
Commit
Commit
x=x+4
y=y-4
w=w+5
z=w
Thread 1 Thread 2 Thread 3 Thread 1 Thread 2 Thread 3
x=x+2
y=y-2
Success
Success
Success
Success
conflict detection
conflict detection
begin; x=x+4; y=y-4; commit;
begin; x=x+2; y=y-2; commit;
begin; x=x+4; y=y-4; commit;
begin; w=w+5; z=w; commit;

STM optimistic execution
7
Begin Begin
Proceed Proceed
Commit Commit
Retry
Commit
x=x+4
y=y-4
x=x+2
y=y-2
Begin
Proceed Begin
Proceed
Commit
Commit
x=x+4
y=y-4
w=w+5
z=w
Thread 1 Thread 2 Thread 3 Thread 1 Thread 2 Thread 3
x=x+2
y=y-2
Success
Success
Success
Success
conflict detection
conflict detection
begin; x=x+4; y=y-4; commit;
begin; x=x+2; y=y-2; commit;
begin; x=x+4; y=y-4; commit;
begin; w=w+5; z=w; commit;
case 1: two transactions conflicts:rollback and retry one of them.

STM optimistic execution
7
Begin Begin
Proceed Proceed
Commit Commit
Retry
Commit
x=x+4
y=y-4
x=x+2
y=y-2
Begin
Proceed Begin
Proceed
Commit
Commit
x=x+4
y=y-4
w=w+5
z=w
Thread 1 Thread 2 Thread 3 Thread 1 Thread 2 Thread 3
x=x+2
y=y-2
Success
Success
Success
Success
conflict detection
conflict detection
begin; x=x+4; y=y-4; commit;
begin; x=x+2; y=y-2; commit;
begin; x=x+4; y=y-4; commit;
begin; w=w+5; z=w; commit;
case 1: two transactions conflicts:rollback and retry one of them.
case 2: two transactions do not conflict: they execute together,
achieving better parallelism.

C. J. Rossbach, O. S. Hofmann and Emmett Witchel, Is transactional programming actually easier, In Proceedings of the 15th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 45–56, 2010.
STM is easy
• In the University of Texas at Austin, 237 students taking Operating System courses were instructed to program the same problem with coarse locks, fine-grained locks, monitors and transactions...
8
DevelopmentTime
Errors
CodeComplexity

C. J. Rossbach, O. S. Hofmann and Emmett Witchel, Is transactional programming actually easier, In Proceedings of the 15th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 45–56, 2010.
STM is easy
• In the University of Texas at Austin, 237 students taking Operating System courses were instructed to program the same problem with coarse locks, fine-grained locks, monitors and transactions...
8
DevelopmentTime
Errors
CodeComplexity
LongShort
TMCoarse Fine

C. J. Rossbach, O. S. Hofmann and Emmett Witchel, Is transactional programming actually easier, In Proceedings of the 15th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 45–56, 2010.
STM is easy
• In the University of Texas at Austin, 237 students taking Operating System courses were instructed to program the same problem with coarse locks, fine-grained locks, monitors and transactions...
8
DevelopmentTime
Errors
CodeComplexity
LongShort
TMCoarse Fine
Simple Complex
TMCoarse Fine

C. J. Rossbach, O. S. Hofmann and Emmett Witchel, Is transactional programming actually easier, In Proceedings of the 15th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 45–56, 2010.
STM is easy
• In the University of Texas at Austin, 237 students taking Operating System courses were instructed to program the same problem with coarse locks, fine-grained locks, monitors and transactions...
8
DevelopmentTime
Errors
CodeComplexity
LongShort
TMCoarse Fine
Simple Complex
TMCoarse Fine
Less More
TM Coarse Fine

STM is a research toy
9

STM is a research toy
9
STM
SXMOSTM
DSTM
ASTM
TL2
TinySTM
TLRW
SwissTM
NOrec
TML
RingTM
InvalTM
DeuceTM
D2STM

STM is a research toy
9
STM
SXMOSTM
DSTM
ASTM
TL2
TinySTM
TLRW
SwissTM
NOrec
TML
RingTM
InvalTM
DeuceTM
D2STM
not
Company Products ResearchSun Dynamic STM library DSTM, TL2, TLRW,
Rock processor, ...
Intel Intel C++ STM compiler McRT-STM, ...
IBM C/C++ for TM on AIX STM extension on X10, ...
Microsoft STM.NET STM on Haskell, ...
AMD ASF instruction set extension

BackgroundWhat affects the transactional memory performance?
How can we adjust concurrency for best performance?

Threads and performance
11

Threads and performance
11
thread#
attempt#
more threads, more transactional
attempts

Threads and performance
11
×thread#
attempt#
more threads, more transactional
attempts
thread#
comm
it prob.
more threads, smaller portion of
transactions to commit

Threads and performance
11
× ∝thread#
attempt#
more threads, more transactional
attempts
thread#
comm
it prob.
more threads, smaller portion of
transactions to commit
thread#
performance
concave curve of performance

Threads and performance
11
× ∝thread#
attempt#
more threads, more transactional
attempts
thread#
comm
it prob.
more threads, smaller portion of
transactions to commit
thread#
performance
concave curve of performance
optimal

Ratio- vs rate-based concurrency controls
12

Ratio- vs rate-based concurrency controls
12
• Concurrency control in STM:‣ achieve optimal performance by scheduling means.

Ratio- vs rate-based concurrency controls
12
• Concurrency control in STM:‣ achieve optimal performance by scheduling means.
• Different concepts:

Ratio- vs rate-based concurrency controls
12
• Concurrency control in STM:‣ achieve optimal performance by scheduling means.
• Different concepts:‣ commit ratio-based heuristics

Ratio- vs rate-based concurrency controls
12
• Concurrency control in STM:‣ achieve optimal performance by scheduling means.
• Different concepts:‣ commit ratio-based heuristics
✴ ratio = commits / (commits + aborts)

Ratio- vs rate-based concurrency controls
12
• Concurrency control in STM:‣ achieve optimal performance by scheduling means.
• Different concepts:‣ commit ratio-based heuristics
✴ ratio = commits / (commits + aborts)✴ reduce concurrency when ratio gets too low✴ relax concurrency when ratio gets higher than a threshold

Ratio- vs rate-based concurrency controls
12
• Concurrency control in STM:‣ achieve optimal performance by scheduling means.
• Different concepts:‣ commit ratio-based heuristics
✴ ratio = commits / (commits + aborts)✴ reduce concurrency when ratio gets too low✴ relax concurrency when ratio gets higher than a threshold
‣ commit rate-based heuristics

Ratio- vs rate-based concurrency controls
12
• Concurrency control in STM:‣ achieve optimal performance by scheduling means.
• Different concepts:‣ commit ratio-based heuristics
✴ ratio = commits / (commits + aborts)✴ reduce concurrency when ratio gets too low✴ relax concurrency when ratio gets higher than a threshold
‣ commit rate-based heuristics✴ rate = commits / time

Ratio- vs rate-based concurrency controls
12
• Concurrency control in STM:‣ achieve optimal performance by scheduling means.
• Different concepts:‣ commit ratio-based heuristics
✴ ratio = commits / (commits + aborts)✴ reduce concurrency when ratio gets too low✴ relax concurrency when ratio gets higher than a threshold
‣ commit rate-based heuristics✴ rate = commits / time
‣ queuing after winner transactions✴ kernel-level programming, conditional waiting...

Ratio-based solutions
• Ansari, et al.:‣ introduces total commit [ratio] (TCR)‣ increases / decreases threads by comparing TCR and set-point (70%)
• Yoo and Lee:‣ introduces per-thread contention intensity (CI)‣ (likelihood of a thread to encounter contentions)‣ stalls for acquiring mutex when CI goes above a value (70%)
• Dolev, et al.:‣ activates hotspot detection when CI goes above a value (40%)‣ a thread stalls for acquiring mutex when hotspot is detected
13

14
Myths of ratio-based heuristics
• We want an application finishes faster‣ i.e. more transactions committed per unit time‣ (assumption: constant number of transactions)
• High commit ratio ≠ high performance‣ 1 thread + 100% ratio vs 4 threads + 40% commit ratio‣ engine rotation ≠ vehicle velocity
• Watching commit ratio is an inexact science‣ happens to be close estimation, though
• Drawbacks‣ over-serialization when commit ratio is low‣ over-relaxation when the commit ratio is high

14
Myths of ratio-based heuristics
• We want an application finishes faster‣ i.e. more transactions committed per unit time‣ (assumption: constant number of transactions)
• High commit ratio ≠ high performance‣ 1 thread + 100% ratio vs 4 threads + 40% commit ratio‣ engine rotation ≠ vehicle velocity
• Watching commit ratio is an inexact science‣ happens to be close estimation, though
• Drawbacks‣ over-serialization when commit ratio is low‣ over-relaxation when the commit ratio is high

• At any instance, we can only pick a thread count‣ “what if” questions not allowed in run-time
• What is high and what is low?‣ commit ratio goes between 0% and 100%‣ commit rate depends on transaction lengths
• Changing patterns‣ transaction nature may change along execution:‣ getting longer / shorter‣ getting more / less contentions
• Pre-defined bounds not acceptable‣ the optimal spot changes across execution timeline.
15
Challenges with rate-based solution

16
Commit ratio vs Commit rateC
omm
it R
atio
/ %
(G
reen
Lin
e)!
Com
mit
Rat
e (R
ed L
ine)!

16
Commit ratio vs Commit rateC
omm
it R
atio
/ %
(G
reen
Lin
e)!
Com
mit
Rat
e (R
ed L
ine)!
commit ratio

16
Commit ratio vs Commit rateC
omm
it R
atio
/ %
(G
reen
Lin
e)!
Com
mit
Rat
e (R
ed L
ine)!
commit rate

16
Commit ratio vs Commit rateC
omm
it R
atio
/ %
(G
reen
Lin
e)!
Com
mit
Rat
e (R
ed L
ine)!
More threads results in better
performance

16
Commit ratio vs Commit rateC
omm
it R
atio
/ %
(G
reen
Lin
e)!
Com
mit
Rat
e (R
ed L
ine)!
Excessive threads kills performance

16
Commit ratio vs Commit rateC
omm
it R
atio
/ %
(G
reen
Lin
e)!
Com
mit
Rat
e (R
ed L
ine)!
Changing application
natures
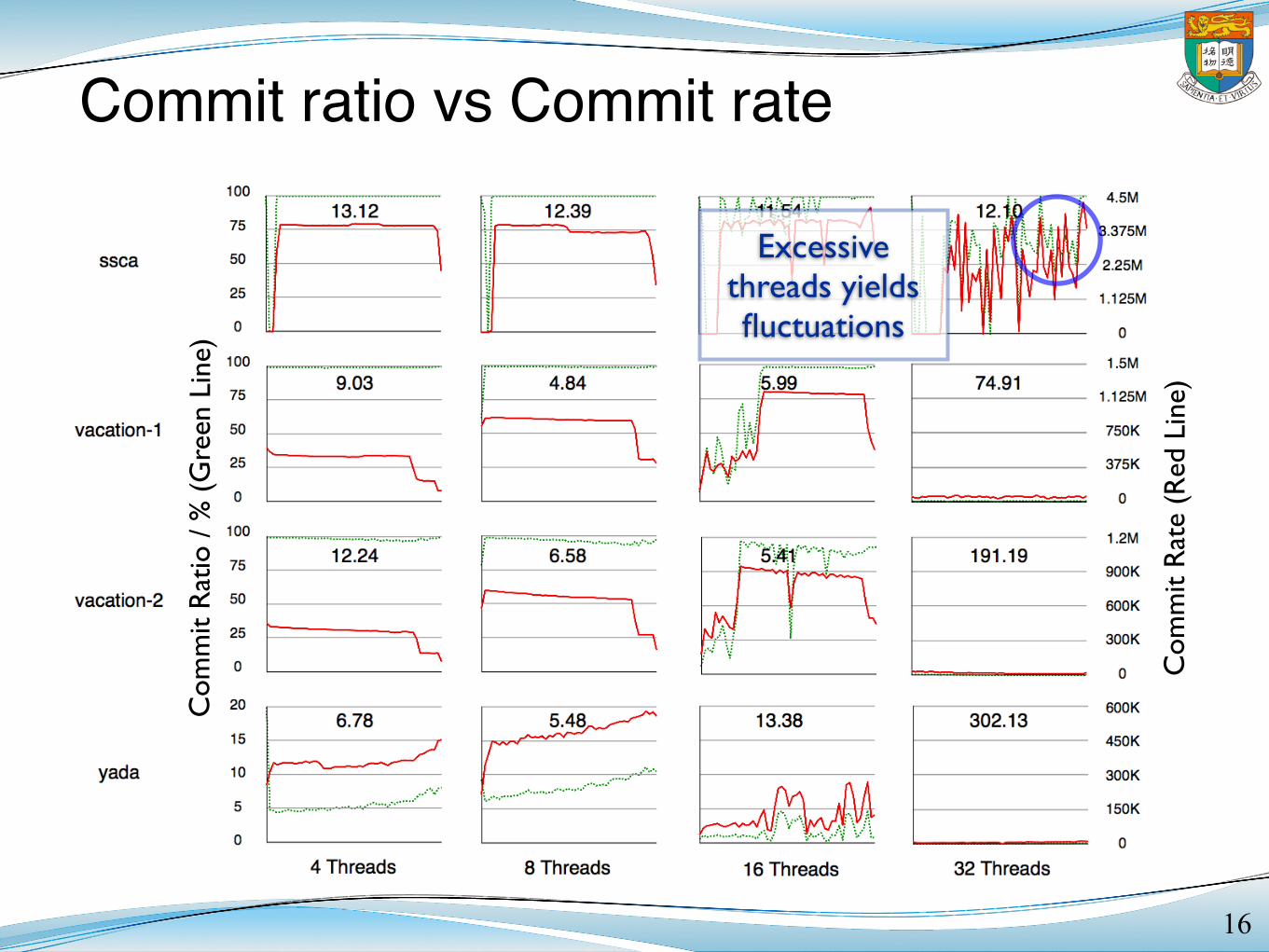
16
Commit ratio vs Commit rateC
omm
it R
atio
/ %
(G
reen
Lin
e)!
Com
mit
Rat
e (R
ed L
ine)!
Excessive threads yields fluctuations

16
Commit ratio vs Commit rateC
omm
it R
atio
/ %
(G
reen
Lin
e)!
Com
mit
Rat
e (R
ed L
ine)!
Dropping ratioIncreasing rateShorter time

16
Commit ratio vs Commit rateC
omm
it R
atio
/ %
(G
reen
Lin
e)!
Com
mit
Rat
e (R
ed L
ine)!
Low commit ratio, but still
scalable...

16
Commit ratio vs Commit rateC
omm
it R
atio
/ %
(G
reen
Lin
e)!
Com
mit
Rat
e (R
ed L
ine)!

SolutionNow we know ratio-based solutions are not right.
What shall we do for a rate-based alternative?

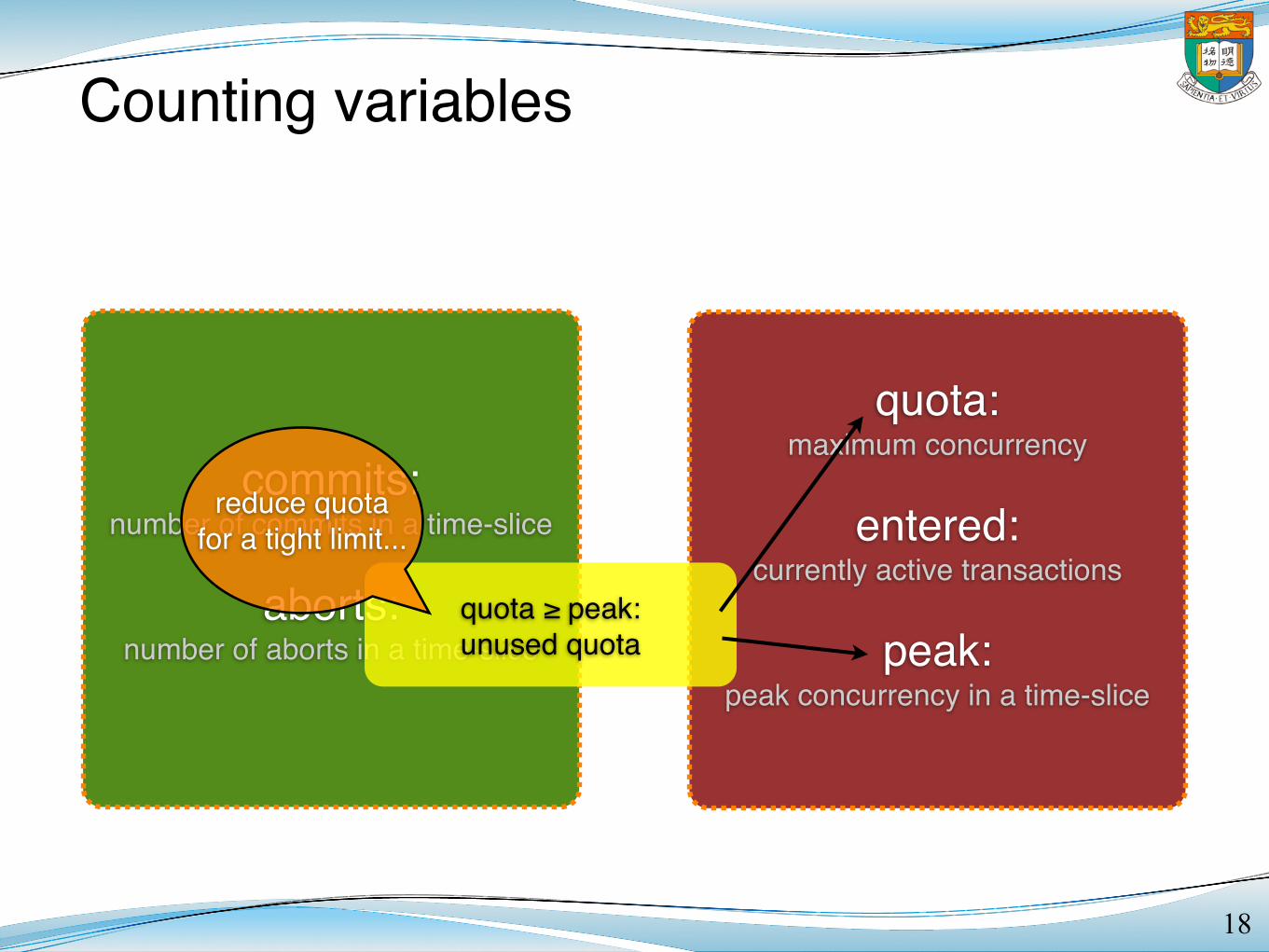
Counting variables
18
commits:number of commits in a time-slice
aborts:number of aborts in a time-slice
quota:maximum concurrency
entered:currently active transactions
peak:peak concurrency in a time-slice

Counting variables
18
commits:number of commits in a time-slice
aborts:number of aborts in a time-slice
quota:maximum concurrency
entered:currently active transactions
peak:peak concurrency in a time-slice
commits per timeslice:commit rate

Counting variables
18
commits:number of commits in a time-slice
aborts:number of aborts in a time-slice
quota:maximum concurrency
entered:currently active transactions
peak:peak concurrency in a time-slice
commit ratio

Counting variables
18
commits:number of commits in a time-slice
aborts:number of aborts in a time-slice
quota:maximum concurrency
entered:currently active transactions
peak:peak concurrency in a time-slice
quota ≤ entered:no more new transactions
stall new comers with pthread_sched();
Counting variables
18
commits:number of commits in a time-slice
aborts:number of aborts in a time-slice
quota:maximum concurrency
entered:currently active transactions
peak:peak concurrency in a time-slice
quota ≥ peak:unused quota
reduce quota for a tight limit...

Counting variables
18
commits:number of commits in a time-slice
aborts:number of aborts in a time-slice
quota:maximum concurrency
entered:currently active transactions
peak:peak concurrency in a time-slice

System architecture
19
Threadcreation
Threadscheduling
Memorymanagement
Input / outputsystem
Concurrencycontrol unit
Conflictdetectionengine
Shared memory
Activitylogger
Txn
Activitylogger
Txn
Activitylogger
Txn
Activitylogger
Txn
User code
Transactionalthreads
Transactionalmemorysystem
Operatingsystem

System architecture
19
Threadcreation
Threadscheduling
Memorymanagement
Input / outputsystem
Concurrencycontrol unit
Conflictdetectionengine
Shared memory
Activitylogger
Txn
Activitylogger
Txn
Activitylogger
Txn
Activitylogger
Txn
User code
Transactions execute as normal,
with conflict detection
Transactionalthreads
Transactionalmemorysystem
Operatingsystem

System architecture
19
Threadcreation
Threadscheduling
Memorymanagement
Input / outputsystem
Concurrencycontrol unit
Conflictdetectionengine
Shared memory
Activitylogger
Txn
Activitylogger
Txn
Activitylogger
Txn
Activitylogger
Txn
User code
Concurrency control unit is
added as a hook, monitoring the performance
Transactionalthreads
Transactionalmemorysystem
Operatingsystem

System architecture
19
Threadcreation
Threadscheduling
Memorymanagement
Input / outputsystem
Concurrencycontrol unit
Conflictdetectionengine
Shared memory
Activitylogger
Txn
Activitylogger
Txn
Activitylogger
Txn
Activitylogger
Txn
User code
Scheduler is invoked to stall
some new transactions, if appropriate
Transactionalthreads
Transactionalmemorysystem
Operatingsystem

System architecture
19
Threadcreation
Threadscheduling
Memorymanagement
Input / outputsystem
Concurrencycontrol unit
Conflictdetectionengine
Shared memory
Activitylogger
Txn
Activitylogger
Txn
Activitylogger
Txn
Activitylogger
Txn
User code
Transactionalthreads
Transactionalmemorysystem
Operatingsystem

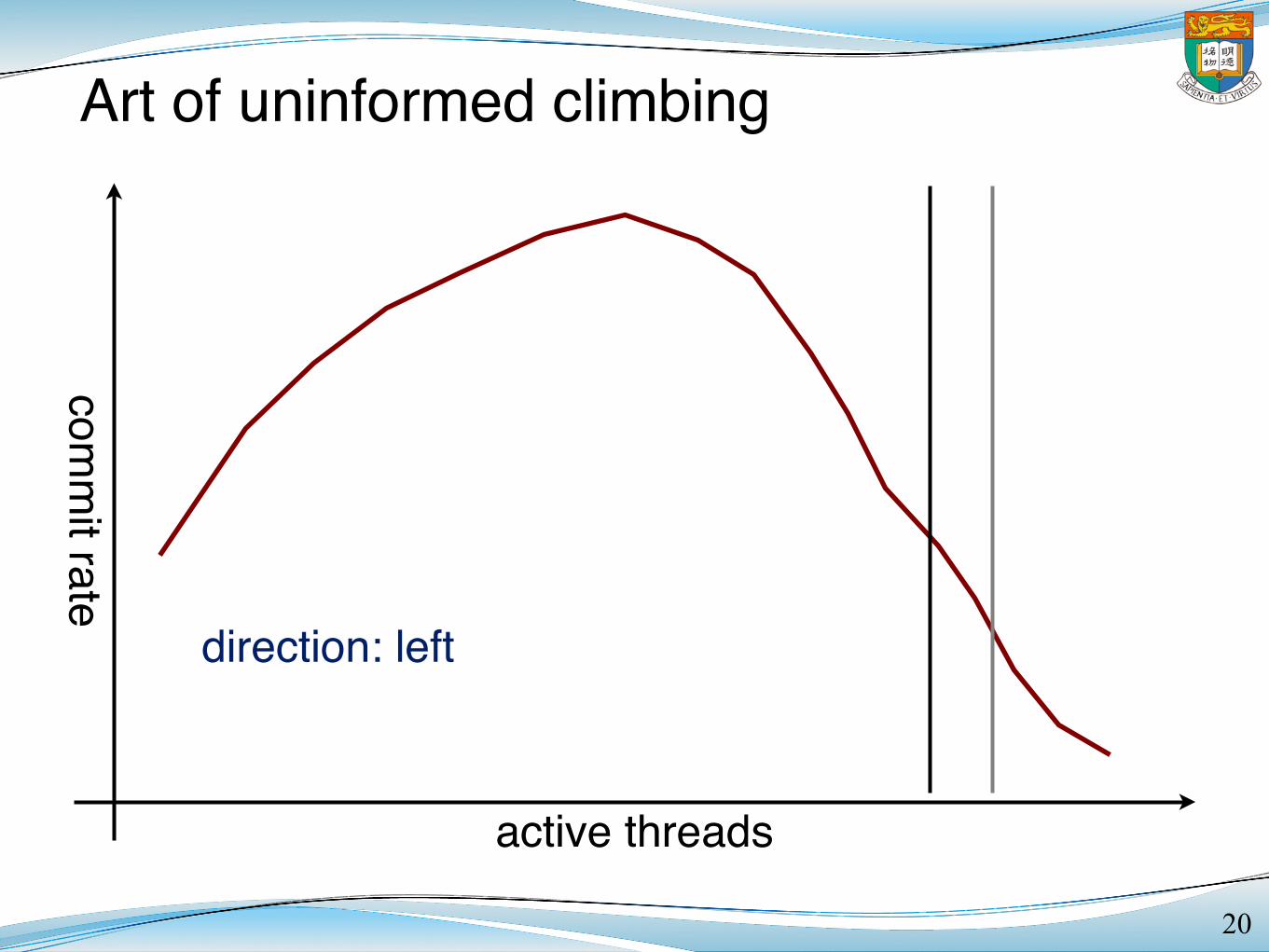
Art of uninformed climbing
20
comm
it rate
active threads
direction: left

Art of uninformed climbing
20
comm
it rate
active threads
direction: left
Art of uninformed climbing
20
comm
it rate
active threads
direction: left

Art of uninformed climbing
20
comm
it rate
active threads
direction: left

Art of uninformed climbing
20
comm
it rate
active threads
direction: left

Art of uninformed climbing
20
comm
it rate
active threads
direction: left

Art of uninformed climbing
20
comm
it rate
active threads
direction: left

Art of uninformed climbing
20
comm
it rate
active threads
direction: left

Art of uninformed climbing
20
comm
it rate
active threads
direction: left

Art of uninformed climbing
20
comm
it rate
active threads
direction: left
decreasing rate! change direction!

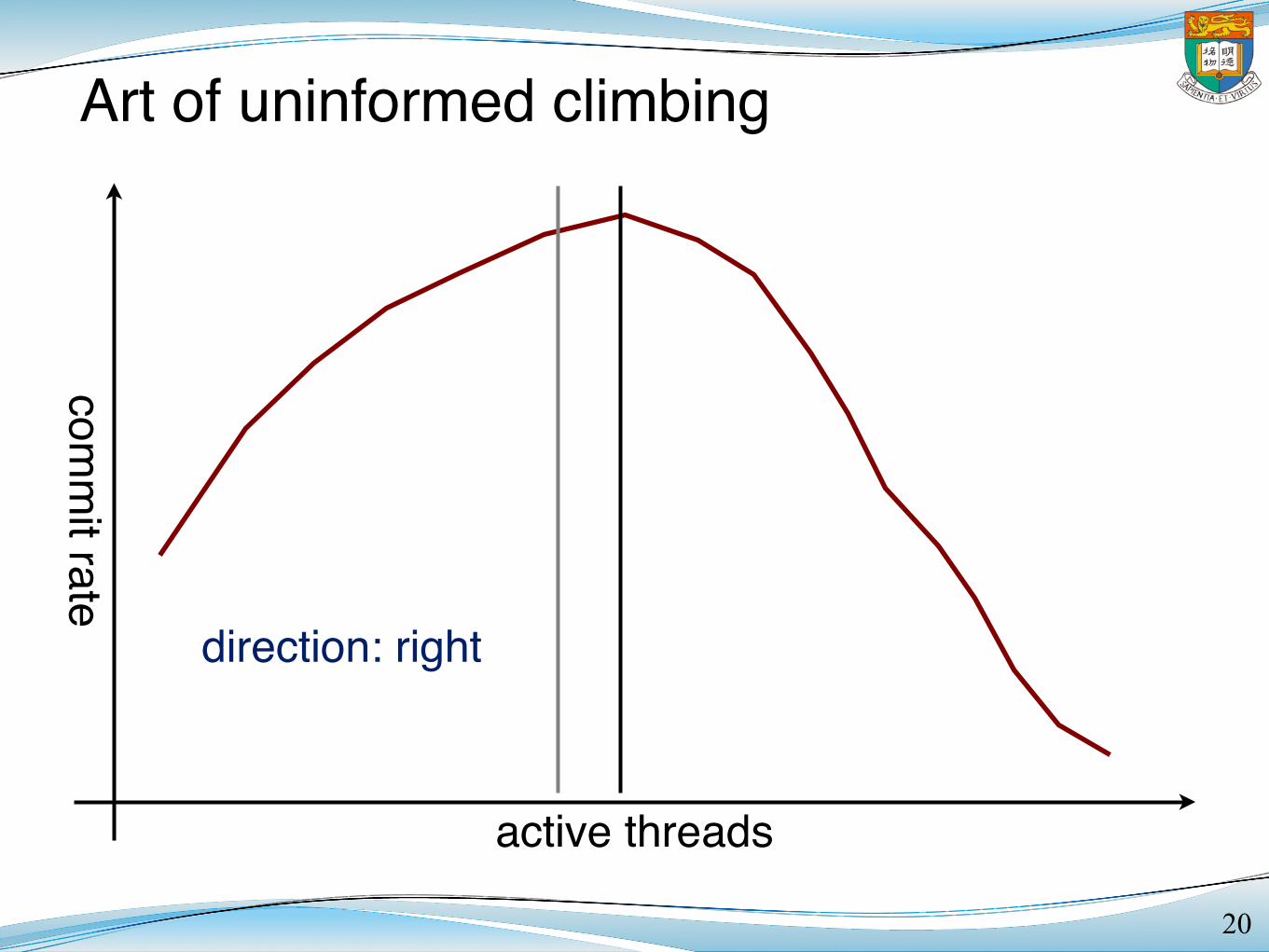
Art of uninformed climbing
20
comm
it rate
active threads
direction: right
Art of uninformed climbing
20
comm
it rate
active threads
direction: right

Art of uninformed climbing
20
comm
it rate
active threads
direction: right

Art of uninformed climbing
20
comm
it rate
active threads
direction: right
decreasing rate! change direction!

Art of uninformed climbing
20
comm
it rate
active threads
direction: left

Art of uninformed climbing
20
comm
it rate
active threads
direction: left
resultant probingregion

Performance EvaluationHow does our rate-based solution
compares with other ratio-based ones?

Evaluation Platform
• Dell PowerEdge M610 Blade Server‣ 2x Intel “Nehalem” Xeon E5540 2.53 GHz (8 cores, 16 threads)‣ ECC DDR3-1066 36 GB main memory
• STAMP Benchmark‣ original from Stanford University – http://stamp.stanford.edu/‣ modified version for TinySTM: http://www.tinystm.org/
• TinySTM 0.9.5‣ open-source version – http://www.tinystm.org/
• Yoo’s and Shrink concurrency control‣ from EPFL Distributed Programming Laboratory –
http://lpd.epfl.ch/site/research/tmeval/
22

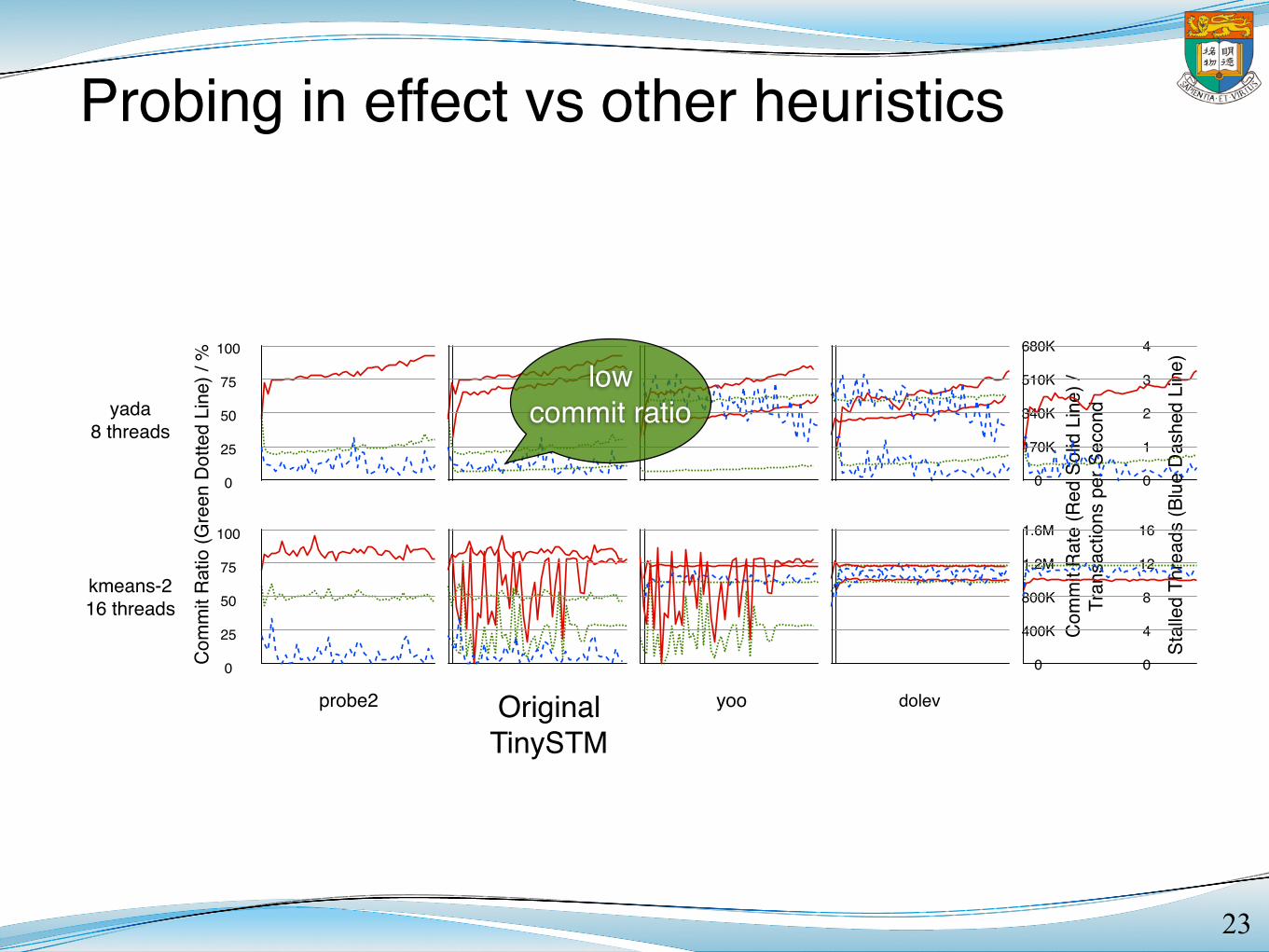
Probing in effect vs other heuristics
23
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
dolev

Probing in effect vs other heuristics
23
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
commit ratio
dolev

Probing in effect vs other heuristics
23
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
commit rate
dolev

Probing in effect vs other heuristics
23
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
threads stalled
dolev
Probing in effect vs other heuristics
23
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
low commit ratio
OriginalTinySTM
dolev
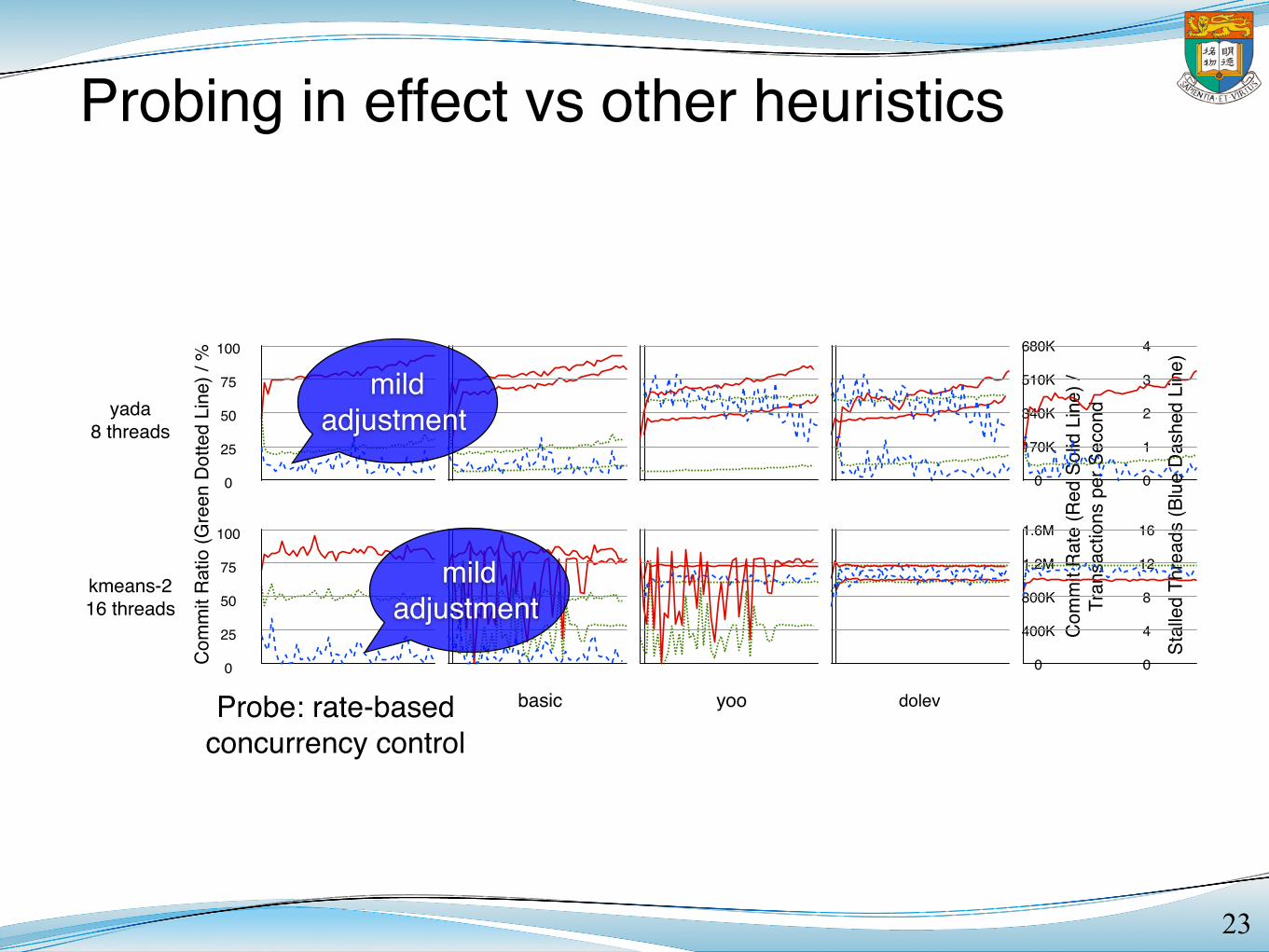
Probing in effect vs other heuristics
23
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
mild adjustment
mild adjustment
Probe: rate-basedconcurrency control
dolev

Probing in effect vs other heuristics
23
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
higher commit rate
higher commit rate
Probe: rate-basedconcurrency control
dolev

Probing in effect vs other heuristics
23
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
aim: high ratio
aim: high ratio
dolevYoo’s and Dolev’sratio-based concurrency control

Probing in effect vs other heuristics
23
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
large adjustment
large adjustment
dolevYoo’s and Dolev’sratio-based concurrency control

Probing in effect vs other heuristics
23
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
even lower rate...
even lower rate...
dolevYoo’s and Dolev’sratio-based concurrency control

Probing in effect vs other heuristics
23
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
throttle2 probe2 basic yoo shrink
kmeans-216 threads
yada8 threads
100
75
50
0
25
100
75
50
0
25
680K
510K
340K
0
170K
1.6M
1.2M
800K
0
400K
4
3
2
0
1
16
12
8
0
4
Com
mit
R�t��
(Gre
en D
otte
d Li
ne) /
%
Com
mit
Rat
e (R
ed S
olid
Lin
e) /
Tran
sact
ions
per
Sec
ond
Stal
led
Thre
ads
(Blu
e D
ashe
d Li
ne)
Figure 3. Commit Ratio, Commit Rate and Number of Stalled Threads of Some TM Applications
We have found Probe more favourable than Throttle, as wellas two other concurrency control policies. We have also foundour solutions are sensitive to the cache sharing, and refined ourimplementation accordingly.
In future we may consider new adaptive scheduling policiesthat observe more STM parameters for smarter decisions, includingtransaction length, read-write ratio, etc.
We also noticed that modern word-based STM come with acommon logical clock, which is atomically incremented every timea transaction commits. We believe this is a potential cache bottle-neck and we foresee a new STM protocol in the future.
AcknowledgmentsThis research was supported by XXX grant.
References[1] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, C. Kirkham, and I. Wat-
son. Adaptive concurrency control for transactional memory. In Pro-ceedings of the 1st workshop on Programmability Issues for Multi-Core Computers, 2008.
[2] M. Ansari, C. Kotselidis, K. Jarvis, M. Lujan, and I. Watson. Ad-vanced concurrency control for transactional memory using transac-tion commit rate. In Proceedings of the 32rd International Conferenceon Distributed Computing Systems, pages 522–529, 2008.
[3] D. Dice, O. Shalev, and N. Shavit. Transactional locking ii. In Pro-ceedings of the 20th International Symposium on Distributed Comput-ing, pages 194–208, 2006.
[4] S. Dolev, D. Hendler, and A. Suissa. Car-stm: Scheduling-based col-lision avoidance and resolution for software transactional memory. InProceedings of the 27th ACM Symposium on Principles of DistributedComputing, pages 125–134, 2008.
[5] A. Dragojevic, A. Guerraoui, R. amd Singh, and V. Singh. Prevent-ing versus curing: Avoiding conflicts in transactional memories. InProceedings of the 28th ACM Symposium on Principles of DistributedComputing, pages 7–16, 2009.
[6] A. Dragojevic, R. Guerraoui, and M. Kapalka. Stretching transactionalmemory. In Proceedings of the 13th ACM SIGPLAN Symposium onProgramming Language Design and Implementation, pages 155–165,2009.
[7] R. Ennals. Software transactional memory should not be obstruction-free. Intel Research Cambridge, 2005.
[8] P. Felber, C. Fetzer, and T. Riegel. Dynamic performance tuning ofword-based software transactional memory. In Proceedings of the 13thACM SIGPLAN Symposium on Principles and Practice of ParallelProgramming, pages 237–246, 2008.
[9] M. Herlihy and J. Moss. Transactional memory: Architectural supportfor lock-free data structures. In Proceedings of the 20th annual
International Symposium on Computer Architecture, pages 289–300,1993.
[10] M. Herlihy, V. Luchangco, and M. Moir. Obstruction free synchroniza-tion: Double ended queues as an example. In Proceedings of the 23rdInternational Conference on Distributed Computing Systems, pages522–529, 2003.
[11] LPD-EPFL. How good is a transactional memory implementation.http://lpd.epfl.ch/site/research/tmeval, accessed on 30 July 2010.
[12] W. Maldonado, P. Marlier, P. Felber, A. Suissa, D. Hendler, A. Fe-dorova, J. Lawall, and G. Muller. Scheduling support for transactionalmemory contention management. In Proceedings of the 15th ACMSIGPLAN Symposium on Principles and Practice of Parallel Program-ming, pages 79–90, 2010.
[13] V. Marathe, M. Spear, C. Heriot, A. Acharya, D. Eisenstat,W. Scherer III, and M. Scott. Toward high performance nonblockingsoftware transactional memory. In Proceedings of the 1st ACM SIG-PLAN Workshop on Languages, Compilers, and Hardware Support forTransactional Computing, 2006.
[14] C. Minh, J. Chung, C. Kozyrakis, and K. Olukotun. Stamp: Standfordtransactional applciations for multi-processing. In Proceedings of the2008 IEEE International Symposium on Workload Characterization,pages 35–46, 2008.
[15] M. OGara. The intel roadmap: The shift to multicore is an inflectionpoint for software design philosophy. 2005. http://opensource.sys-con.com/node/48477, accessed on 28 July 2010.
[16] H. Ramadan, C. Rossbach, and E. Witchel. Dependance-aware trans-actional memory for increased concurrency. In Proceedings of the41st IEEE/ACM International Symposium on Microarchitecture, pages246–257, 2008.
[17] W. Scherer III and M. Scott. Contention management in dynamicsoftware transactional memory. In Proceedings of the 24th ACMSymposium on Principles of Distributed Computing, pages 240–248,2005.
[18] N. Shavit and D. Touitou. Software transactional memory. In Pro-ceedings of the 14th ACM Symposium on Principles of DistributedComputing, pages 204–213, 1995.
[19] T. Usui, Y. Smaragdakis, and R. Behrends. Adaptive locks: Combiningtransactions and locks for efficient concurrency. In Proceedings of the27th ACM Symposium on Principles of Distributed Computing, 2009.
[20] R. Yoo and H. Lee. Adaptive transaction scheduling for transactionalmemory systems. In Proceedings of the 20th ACM Symposium onParallelism in Algorithms and Architectures, pages 169–178, 2009.
9 2010/8/3
dolev

Yoo’s Dolev’s Throttle Probe Probe2
yada
vacation-1
kmeans-2
vacation-2
kmeans-1
intruder
genome
ssca
labyrinth
average
+70.5% +61.02% +81.33% +101.79% +81.59%
+38.14% +18.39% +35.68% +54.90% +66.26%
-6.50% -19.56% -11.38% +2.52% +31.59%
+3.19% -19.04% +6.63% +2.42% +8.81%
-1.45% -28.96% -24.49% -1.38% +8.19%
-12.95% -28.03% -35.13% -14.65% +5.26%
+0.46% -11.80% -4.73% -7.55% -1.01%
+0.58% +0.29% -25.08% -26.51% -4.62%
-2.37% -1.34% -27.66% -12.22% -6.73%
+9.96% -3.23% -0.54% +11.03% +21.04%
Performance comparison
24

Yoo’s Dolev’s Throttle Probe Probe2
yada
vacation-1
kmeans-2
vacation-2
kmeans-1
intruder
genome
ssca
labyrinth
average
+70.5% +61.02% +81.33% +101.79% +81.59%
+38.14% +18.39% +35.68% +54.90% +66.26%
-6.50% -19.56% -11.38% +2.52% +31.59%
+3.19% -19.04% +6.63% +2.42% +8.81%
-1.45% -28.96% -24.49% -1.38% +8.19%
-12.95% -28.03% -35.13% -14.65% +5.26%
+0.46% -11.80% -4.73% -7.55% -1.01%
+0.58% +0.29% -25.08% -26.51% -4.62%
-2.37% -1.34% -27.66% -12.22% -6.73%
+9.96% -3.23% -0.54% +11.03% +21.04%
Performance comparison
24
Ratio-based Heuristics

Yoo’s Dolev’s Throttle Probe Probe2
yada
vacation-1
kmeans-2
vacation-2
kmeans-1
intruder
genome
ssca
labyrinth
average
+70.5% +61.02% +81.33% +101.79% +81.59%
+38.14% +18.39% +35.68% +54.90% +66.26%
-6.50% -19.56% -11.38% +2.52% +31.59%
+3.19% -19.04% +6.63% +2.42% +8.81%
-1.45% -28.96% -24.49% -1.38% +8.19%
-12.95% -28.03% -35.13% -14.65% +5.26%
+0.46% -11.80% -4.73% -7.55% -1.01%
+0.58% +0.29% -25.08% -26.51% -4.62%
-2.37% -1.34% -27.66% -12.22% -6.73%
+9.96% -3.23% -0.54% +11.03% +21.04%
Performance comparison
24
Ratio-based Heuristics
Naive: scales for 25% ~ 75%
of ratio

Yoo’s Dolev’s Throttle Probe Probe2
yada
vacation-1
kmeans-2
vacation-2
kmeans-1
intruder
genome
ssca
labyrinth
average
+70.5% +61.02% +81.33% +101.79% +81.59%
+38.14% +18.39% +35.68% +54.90% +66.26%
-6.50% -19.56% -11.38% +2.52% +31.59%
+3.19% -19.04% +6.63% +2.42% +8.81%
-1.45% -28.96% -24.49% -1.38% +8.19%
-12.95% -28.03% -35.13% -14.65% +5.26%
+0.46% -11.80% -4.73% -7.55% -1.01%
+0.58% +0.29% -25.08% -26.51% -4.62%
-2.37% -1.34% -27.66% -12.22% -6.73%
+9.96% -3.23% -0.54% +11.03% +21.04%
Performance comparison
24
Rate-based Heuristics

Yoo’s Dolev’s Throttle Probe Probe2
yada
vacation-1
kmeans-2
vacation-2
kmeans-1
intruder
genome
ssca
labyrinth
average
+70.5% +61.02% +81.33% +101.79% +81.59%
+38.14% +18.39% +35.68% +54.90% +66.26%
-6.50% -19.56% -11.38% +2.52% +31.59%
+3.19% -19.04% +6.63% +2.42% +8.81%
-1.45% -28.96% -24.49% -1.38% +8.19%
-12.95% -28.03% -35.13% -14.65% +5.26%
+0.46% -11.80% -4.73% -7.55% -1.01%
+0.58% +0.29% -25.08% -26.51% -4.62%
-2.37% -1.34% -27.66% -12.22% -6.73%
+9.96% -3.23% -0.54% +11.03% +21.04%
Performance comparison
24
Rate-based Heuristics
Better number counting
strategy

Yoo’s Dolev’s Throttle Probe Probe2
yada
vacation-1
kmeans-2
vacation-2
kmeans-1
intruder
genome
ssca
labyrinth
average
+70.5% +61.02% +81.33% +101.79% +81.59%
+38.14% +18.39% +35.68% +54.90% +66.26%
-6.50% -19.56% -11.38% +2.52% +31.59%
+3.19% -19.04% +6.63% +2.42% +8.81%
-1.45% -28.96% -24.49% -1.38% +8.19%
-12.95% -28.03% -35.13% -14.65% +5.26%
+0.46% -11.80% -4.73% -7.55% -1.01%
+0.58% +0.29% -25.08% -26.51% -4.62%
-2.37% -1.34% -27.66% -12.22% -6.73%
+9.96% -3.23% -0.54% +11.03% +21.04%
Performance comparison
24

Yoo’s Dolev’s Throttle Probe Probe2
yada
vacation-1
kmeans-2
vacation-2
kmeans-1
intruder
genome
ssca
labyrinth
average
+70.5% +61.02% +81.33% +101.79% +81.59%
+38.14% +18.39% +35.68% +54.90% +66.26%
-6.50% -19.56% -11.38% +2.52% +31.59%
+3.19% -19.04% +6.63% +2.42% +8.81%
-1.45% -28.96% -24.49% -1.38% +8.19%
-12.95% -28.03% -35.13% -14.65% +5.26%
+0.46% -11.80% -4.73% -7.55% -1.01%
+0.58% +0.29% -25.08% -26.51% -4.62%
-2.37% -1.34% -27.66% -12.22% -6.73%
+9.96% -3.23% -0.54% +11.03% +21.04%
Performance comparison
24
over-relaxation

Yoo’s Dolev’s Throttle Probe Probe2
yada
vacation-1
kmeans-2
vacation-2
kmeans-1
intruder
genome
ssca
labyrinth
average
+70.5% +61.02% +81.33% +101.79% +81.59%
+38.14% +18.39% +35.68% +54.90% +66.26%
-6.50% -19.56% -11.38% +2.52% +31.59%
+3.19% -19.04% +6.63% +2.42% +8.81%
-1.45% -28.96% -24.49% -1.38% +8.19%
-12.95% -28.03% -35.13% -14.65% +5.26%
+0.46% -11.80% -4.73% -7.55% -1.01%
+0.58% +0.29% -25.08% -26.51% -4.62%
-2.37% -1.34% -27.66% -12.22% -6.73%
+9.96% -3.23% -0.54% +11.03% +21.04%
Performance comparison
24
over-reaction

Yoo’s Dolev’s Throttle Probe Probe2
yada
vacation-1
kmeans-2
vacation-2
kmeans-1
intruder
genome
ssca
labyrinth
average
+70.5% +61.02% +81.33% +101.79% +81.59%
+38.14% +18.39% +35.68% +54.90% +66.26%
-6.50% -19.56% -11.38% +2.52% +31.59%
+3.19% -19.04% +6.63% +2.42% +8.81%
-1.45% -28.96% -24.49% -1.38% +8.19%
-12.95% -28.03% -35.13% -14.65% +5.26%
+0.46% -11.80% -4.73% -7.55% -1.01%
+0.58% +0.29% -25.08% -26.51% -4.62%
-2.37% -1.34% -27.66% -12.22% -6.73%
+9.96% -3.23% -0.54% +11.03% +21.04%
Performance comparison
24

Conclusions
• Trend of multicore urges us to write parallel computer programs
• Software transactional memory is part of future computation‣ easier to program, less errors, neat code‣ but it needs concurrency control for the best performance
• Ratio-based vs rate-based concurrency heuristics‣ ratio-based heuristics are inexact approximations‣ watching ratio only causes over-reaction / over-relaxation
• Rate-based concurrency heuristics, Probe, outperforms
25


Thank You!Contact me:[email protected]
HKU CS Systems Research Group:http://www.srg.cs.hku.hk/
Dr. Cho-Li Wang’s Webpage:http://www.cs.hku.hk/~clwang/




![GPU Performance vs. Thread-Level Parallelism: Scalability ...GPUs exploit high degrees of thread-level parallelism (TLP). Programmers use the CUDA [2] or OpenCL [1] programming models](https://img.pdfslide.us/doc/110x75/60517e934a933c476e74e5e4/gpu-performance-vs-thread-level-parallelism-scalability-gpus-exploit-high.jpg)
![final USC-2016alchem.usc.edu/ceng-seminar/slides/2016/rajiv_gupta.pdf[MICRO 2015] Branch Divergence (CCC) [IPDPS 2016] Thread Assignment (CTE) 27 Graphs on Clusters Scalability for](https://img.pdfslide.us/doc/110x75/5f1bcf53ccff0023623ddacf/final-usc-micro-2015-branch-divergence-ccc-ipdps-2016-thread-assignment-cte.jpg)























