Embed Size (px)
Citation preview

Introduction
● Why vector for Natural language ?● Convensional representations for words and documents ● Methods of Dimensionality reduction
Deep learning models:
● Continuous Bag of words model ● Other Models (SKip Gram Model, GloVe)● Evaluation of Word Vectors● Readings and references

Introduction: Why Vectors
Document Classification or Clustering :
● Documents composed of words ● Similar documents will contain similar words● Machine Learning love vectors ● A Machine Learning algorithm shall know
which words are significant which category

Bag of Words Model
“Represent each document which the bag of words it contains”
d1 : Mary loves Movies, Cinema and Art Class 1 : Artsd2 : John went to the Football game Class 2 : Sports
d3 : Robert went for the Movie Delicatessen Class : Arts
Mary Loves Movies Cinema Art John Went to the Delicatessen Robert Football Game and for
d1 1 1 1 1 1 1
d2 1 1 1 1 1 1
d3 1 1 1 1 1

Bag of Words Model
Can a Machine learning algorithm know that “the” and “for” are un important words ?
● Yes : But will need lots of training labeled data
What to do ?
● Use hand crafted features (weighting features for words)● Make lots of them● Keep doing this for 50 years● Regret later .. cry hard

Bag of Words Model + Weghting eiFeatures
Weighting features example TF-IDF
● TF-IDF ~= Term Frequency / Document frequency ● Motivation : Words appearing in large number of documents are not
significant
Mary Loves Movies Cinema Art John Went to the Delicatessen Robert Football Game and for
d1 0.3779 0.3779 0.3779 0.3779 0.3779 0.0001
d2 0.4402 0.001 0.02 0.4558 0.458
d3 0.001 0.01 0.01 0.458 0.0001

Word Vector Representations
Document can be represented by words, But how to represent words themselves ?
“You shall know a word by the company it keeps”

Word Vector Representations
Use a sliding window over a big corpus of text and count word co-occurences in between.
1. I enjoy flying.
2. I like NLP.
3. I like deep learning.

Bag of words Representations: Drawbacks
● High dimensionality and Very sparse !!!!!
● Unable to capture word order ○ “ good but expensive” “expensive but good” will have same representation.
● Unable to capture semantic similarities (mostly because of sparsity)○ “boy”, “girl” and “car”○ “Human”, “Person” and “Giraffe”

Bag of words Representations: Drawbacks
How to over come this ?
● Keep using hand crafted features ● Make lots of them● Keep doing this for 50 years● Regret later .. cry hard
Or … Dimensionality reduction

Dimensionality Reduction using Matrix factorization
Singular value decomposition
where : σ1> σ
2 .. > σ
n > 0

Singular value decomposition
● Lower dimensionality K << |V|● taking the most significant projection of your vectors
space

Latent semantic Indexing / Analysis (1994)
⋃ : are dense word vector representations
V : are dense Document vector representations
LSA / LSI , HAL methods made huge advancements in document retrieval and semantic similarity

Deep learning Word Embeddings (2003)
“A Neural Probabilistic Language Model” Bengio et al. 2003
Original task “Language Modeling” :
- Prediction of next word given sequence of previous words.- Useful in Speech Recognition, Autcompletion, Machine translation.
“The Cat Chills on a mat ” , Calculate : P( mat | the, cat, chills, on, a )

Deep learning Word Embeddings (2003)
“A Neural Probabilistic Language Model” Bengio et al. 2003
Quoting from the paper:
“This is intrinsically difficult because of the curse of dimensionality: a word sequence on which the model will be tested is likely to be different from all the word sequences seen during training.”
“We propose to fight the curse of dimensionality by learning a distributed representation for words”

Continuous Bag of Words model (CBOW) Tomas Mikolov et al. (2013)
The model Predicts the current word given the context
scan text in large corpus with a window
Input : x0 , x1 , x3 , x4 output : x2
“ The Cat Chills on a mat ”
x0 x1 x2 x3 x4 x5

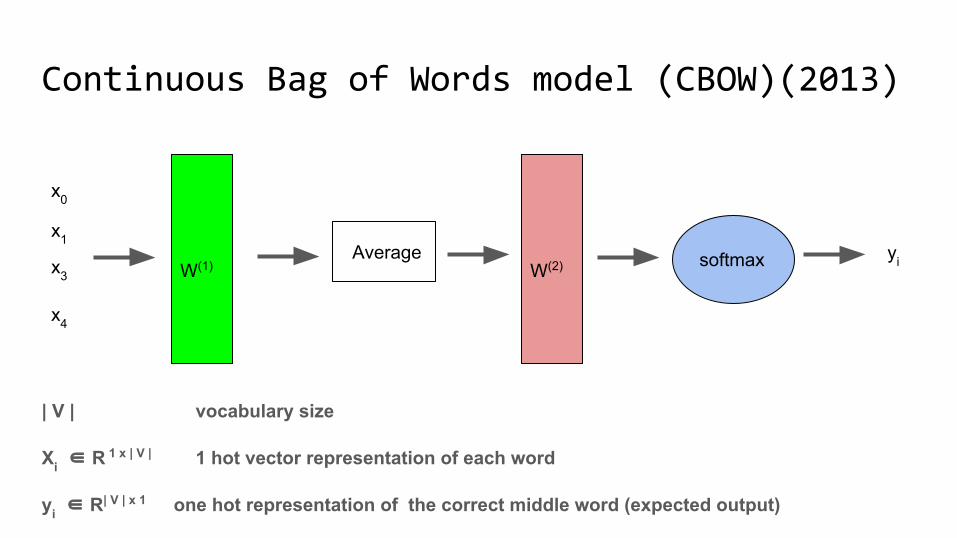
Continuous Bag of Words model (CBOW)(2013)
| V | vocabulary size
Χi ∈ R 1 x | V | 1 hot vector representation of each word
yi ∈ R| V | x 1 one hot representation of the correct middle word (expected output)
1 0 0 0 0 0yi 0 0 0 0 1 0 0
0 0 0 1 0 0 0
0 0 0 0 0 0 1
0 0 1 0 0 0 0
x0
x1
x3
x4
| V |
Black box
Continuous Bag of Words model (CBOW)(2013)
| V | vocabulary size
Χi ∈ R 1 x | V | 1 hot vector representation of each word
yi ∈ R| V | x 1 one hot representation of the correct middle word (expected output)
yi
x0
x1
x3
x4
W(1)
Average W(2) softmax

Continuous Bag of Words model (CBOW)(2013)
n arbitary length of our word embeddings
W(1) ∈ Rn × |V| Input word vector
ui∈ R n x 1 Representation of Xi After multiplication with input matrix
0 0 0 0 1 0 0
0 0 0 1 0 0 0
0 0 0 0 0 0 1
0 0 1 0 0 0 0
x0
x1
x3
x4
| V | 0 1 31 3 65 0 39 8 0 2 2 2 5 6 7 8 8 8
|V|
n
W(1)
2 2 2
9 8 0
8 8 8
5 0 3
u0
u1
u3
u4
n

Continuous Bag of Words model (CBOW)(2013)
hi ∈ R n x 1
hi = Average of u0 u1 u3u4
2 2 2
9 8 0
8 8 8
5 0 3
u0
u1
u3
u4
n
Average 20.25 4.5 3.25
hi

Continuous Bag of Words model (CBOW)(2013)
W (2) ∈ R n x | V | Output word vector
Z ∈ R | V | x 1 Output vector representation of Xi
Z = hi W(2)
| V |
W(2)
0 1 3 1 3 6 5 0 3 9 8 0 2 2 2 5 6 7 8 8 8
n 32 14 23 0.22 12 14 55 19
Z
| V |
20.25 4.5 3.25
hi

Continuous Bag of Words model (CBOW)(2013)
How to compare Z to yi ?
Largest value corresponds to the correct class ? … no Softmax
Softmax: squashes a K-dimensional vector of arbitrary real values to a K-dimensional vector of real values in the range (0, 1)
1 0 0 0 0 0 0 0 yi
32 14 23 0.22 2 14 55 19 Z

Continuous Bag of Words model (CBOW)(2013)
y^ = softmax ( Z )
yi ∈ R| V | x 1 one hot representation of the correct middle word
1 0 0 0 0 0 0 0 yi
32 14 23 0.22 2 14 55 19 Z
y^ 0.7 0.1 0.02 0.08 0 0 0.1

Continuous Bag of Words model (CBOW)(2013)
● We need estimated words y^ to be closest to the original answer● One common error function is the cross entropy H(yˆ, y) (why ?).
Since y is one hot vector

Continuous Bag of Words model (CBOW)(2013)
● We need estimated words y^ to be closest to the original answer● One common error function is the cross entropy error H(yˆ, y) (why ?).
Since y is one hot vector

Continuous Bag of Words model (CBOW)(2013)
Perfect language model will expect the propability of the correct word y^i = 1
So loss will be 0
Optimization task :
● Learn W(1) and W(2) to minimize the cost function over all the dataset.● using back propagation, update weights in W(1) and W(2)

Continuous Bag of Words model (CBOW)(2013)
0 1 31 3 65 0 39 8 0 2 2 2 5 6 7 8 8 8
|V|
n
W(1)
W (1) :
● After training over a large corpus ● Each row represents a dense vector for each word in the
vocabulary ● These word vectors contains better semantic and syntactic
representation than other dense vectors ( will be proven later)● These word vectors performs better for all NLP tasks (will be
proven later)

Skip Gram model (2013)

GloVe: Global Vectors for Word Representation, Pennington et al. (2014)
Motivation:
ice - steam = ( solid, gas, water, fashion ) ?
● A distributional model should capture words that appears with “ice” but not “steam”.
● Hence, doing well in semantic analogy task (explained later)

GloVe: Global Vectors for Word Representation, Pennington et al. (2014)
Starts from a co-oocurrrence matrix
p(solid | ice ) = Xsolid,ice / Xice

GloVe: Global Vectors for Word Representation, Pennington et al. (2014)
Optimize the Objective function:
wi word vector of word i
Pik probability of word k to occurs in context of word i

Ok, But are word vectors really good ?!
Evaluation of word vectors :
1. Intrinsic evaluation : make sure it encodes semantic information
2. Extrinsic evaluation : make sure it’s useful for other NLP tasks (the hype)

Intrinsic Evaluation of Word Vectors
Word similarity task

Intrinsic Evaluation of Word Vectors
Results from : GloVe: Global Vectors for Word Representation, Pennington et al 2014. Word similarity dataset “WS353”: http://www.cs.technion.ac.il/~gabr/resources/data/wordsim353/
Word similarity task

Intrinsic Evaluation of Word Vectors
Word Analogy task

Intrinsic Evaluation of Word Vectors
Word Analogy task
Evaluation data : https://word2vec.googlecode.com/svn/trunk/questions-words.txt
: capital-worldAbuja Nigeria Accra Ghana
: gram3-comparativebad worse big bigger
: gram2-oppositeacceptable unacceptable aware unaware
: gram1-adjective-to-adverbamazing amazingly apparent apparently
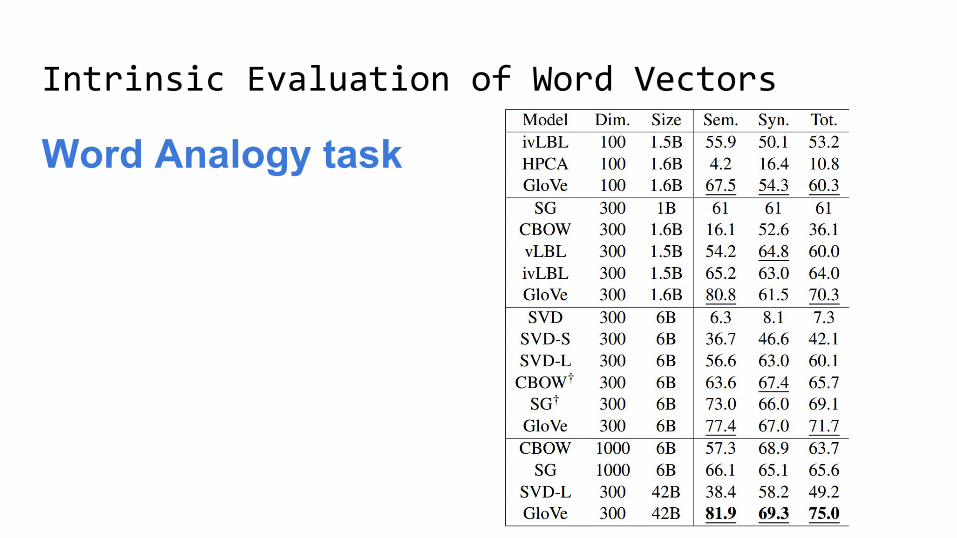
Intrinsic Evaluation of Word Vectors
Word Analogy task

Extrinsic Evaluation of Word Vectors
Part of Speech Tagging :
input : Word Embeddings are cool
output: Noun Noun Verb Adjective
Named Entity recognition :
input : Nous sommes charlie hebdo
output: Out Out Person Person

Extrinsic Evaluation of Word Vectors
* systems: POS: (Toutanova et al. 2003), NER: (Ando & Zhang 2005)
** 130,000-word embedding trained on Wikipedia and Reuters with 11 word window, 100 unit hidden
layer – for 7 weeks! – then supervised task training
*** Features are character suffixes for POS and a gazeteer for NER

“Unsupervised Pretraining” (the secret sauce)
Problem:
1. Task T1: Few training data (D
1)
2. Hand crafted Feature representation of inputs R1
3. Machine learning Algorithm M1 on T
1 using R
1 performs bad
Solution:
1. Create Task T2: With lots of available training data (D
2)
(unsupervised) but has to have the same input as T1
2. Solve T2 using (D
2) and learn representation of the inputs (R
2)
3. R2 + M
1 better than R
1 + M
1 on task T
1

“Unsupervised Pretraining” (the secret sauce)
But what also if ?:
Learn D3
while doing T1
using R2 and
M1

Even better results !!
* Same architecture as C&W 2011, but word embeddings are kept constant during the supervised training phase ** C&W is unsupervised pre-train + supervised NN + features model of last slide

word2vec :
https://code.google.com/p/word2vec/
GloVe : http://nlp.stanford.edu/projects/glove/
Dependency based : https://levyomer.wordpress.com/...
Pretrained Word vectors ready for use

Other word embeddings :
● Dependency Based Word embeddings: Levy et al. 2014 : http://www.aclweb.org.....● Sentiment Analysis Word Embeddings: http://ai.stanford.edu/~ang/pap.....
Knowledge base embeddings : ● Structured Embeddings (SE) (Bordes et al ‘11 ) ● Collective Matrix Factorization (RESCAL) (Nickel et al., ’11)● Neural Tensor Networks (socher et al. ‘13)● TATEC (Garcia-Duran et al., ’14)
Other Types of Embeddings:

Joint embeddings (Text + Knowledge bases):
● Joint Learning of Words and Meaning Representations (Bordes et al. ‘12)● Knowledge Graph and Text Jointly Embedding (Wang et al ‘14)
Other Types of Embeddings:

References:
Before Word2Vec:
Rumelhart, David E., Geoffrey E. Hinton, and Ronald J. Williams. "Learning representations by back-propagating errors." Cognitive modeling 5 (1988): 3.http://www.iro.umontreal.ca/~vincentp/ift3395/lectures/backprop_old.pdf
Bengio, Yoshua, et al. "A neural probabilistic language model." The Journal of Machine Learning Research 3 (2003): 1137-1155.http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf

References:
Word2vec (CBOW and Skip Gram):
Mikolov, Tomas, et al. "Efficient estimation of word representations in vector space." arXiv preprint arXiv:1301.3781 (2013).Efficient Estimation of Word Representations in Vector Space.
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of NIPS, 2013.
Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic Regularities in Continuous Space Word Representations. In Proceedings of NAACL HLT, 2013.
GloVe: Global Vectors for Word Representation, Pennington et al.(2014) http://www-nlp.stanford.edu/pubs/glove.pdf

Further Readings:
Negative sampling: http://papers.nips.cc/paper/....
Energy based learning : http://yann.lecun.com/exdb/publis/pdf/lecun-06.pdf
Joint learning (learning tasks simultaneously): http://ronan.collobert.com/pub...

Learning Resources
Deep Learning for NLP ( Stanford Course )
http://cs224d.stanford.edu/
Deep Learning for Natural Language Processing (without Magic : NAACL 2013 Tutorial
http://nlp.stanford.edu/courses/NAACL2013/






























