Embed Size (px)
Citation preview

IDS Lab
Universal Approximation Theoremwhy does deep neural network work?
basic maths for deep learningJamie Seol
IDS Lab
Jamie Seol
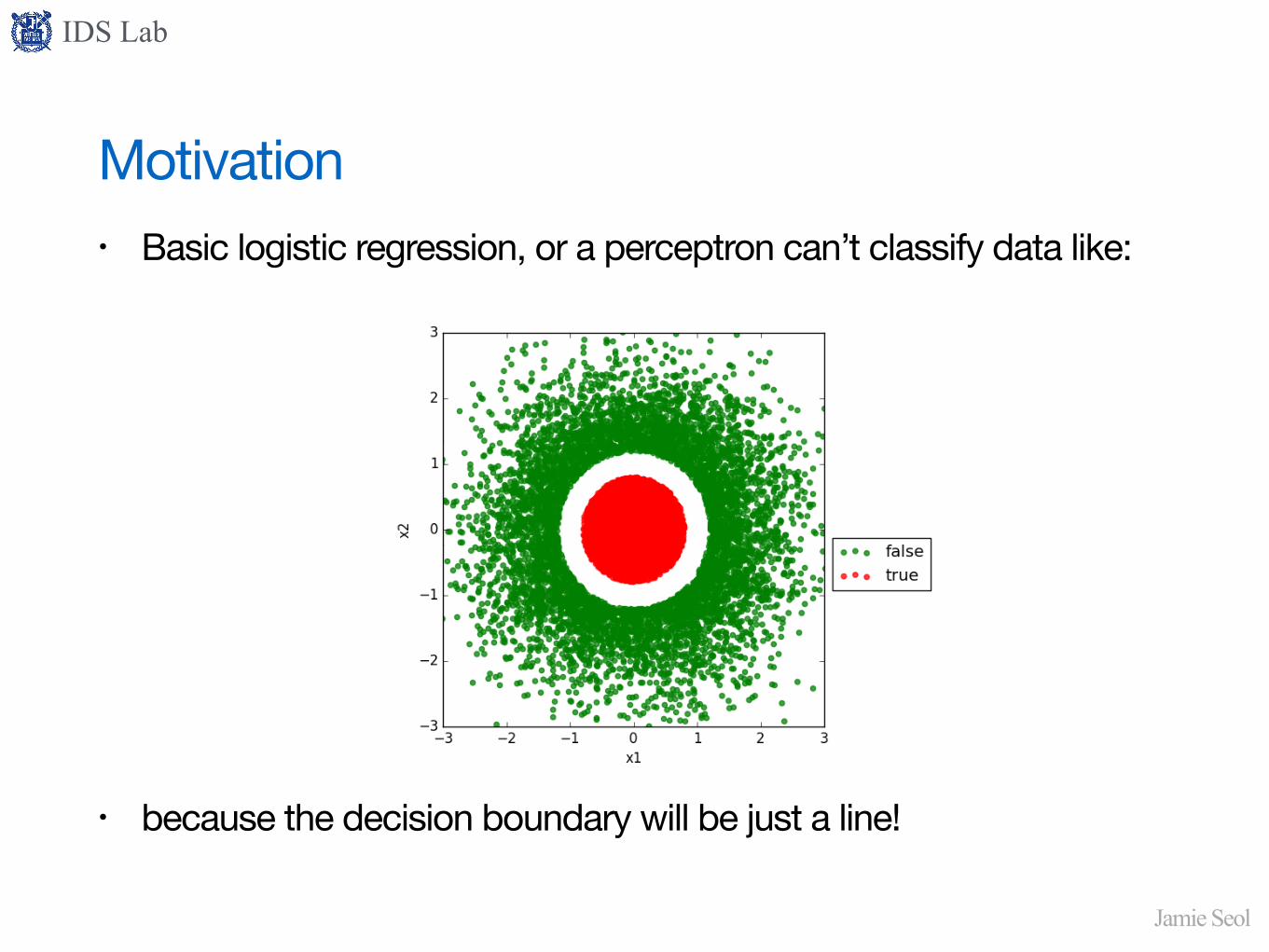
Motivation• Basic logistic regression, or a perceptron can’t classify data like:
• because the decision boundary will be just a line!

IDS Lab
Jamie Seol
Motivation• Unless we put additional features like x3 = x12, x4 = x22
• but this is a feature engineering!• we need to do it by our hands!!
• we don’t want to do this!• this is the one of main reasons why we’re studying deep
learning!• we can’t do this always!
• what if the input data was like 1000 dimensional vector?• we know that deep learning automatically finds these additional
features• but why and how?
IDS Lab
Jamie Seol
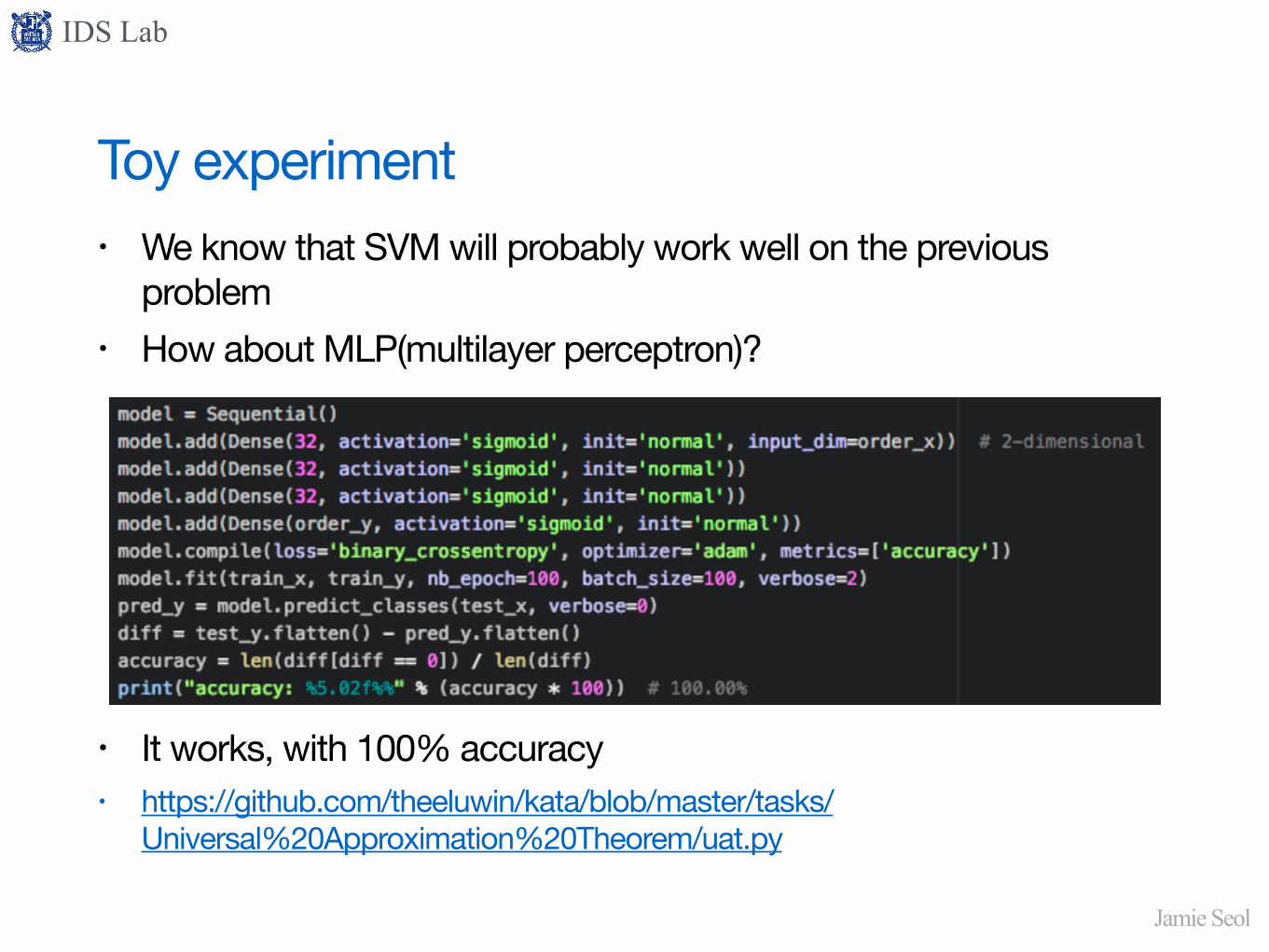
Toy experiment• We know that SVM will probably work well on the previous
problem• How about MLP(multilayer perceptron)?
• It works, with 100% accuracy• https://github.com/theeluwin/kata/blob/master/tasks/
Universal%20Approximation%20Theorem/uat.py
IDS Lab
Jamie Seol
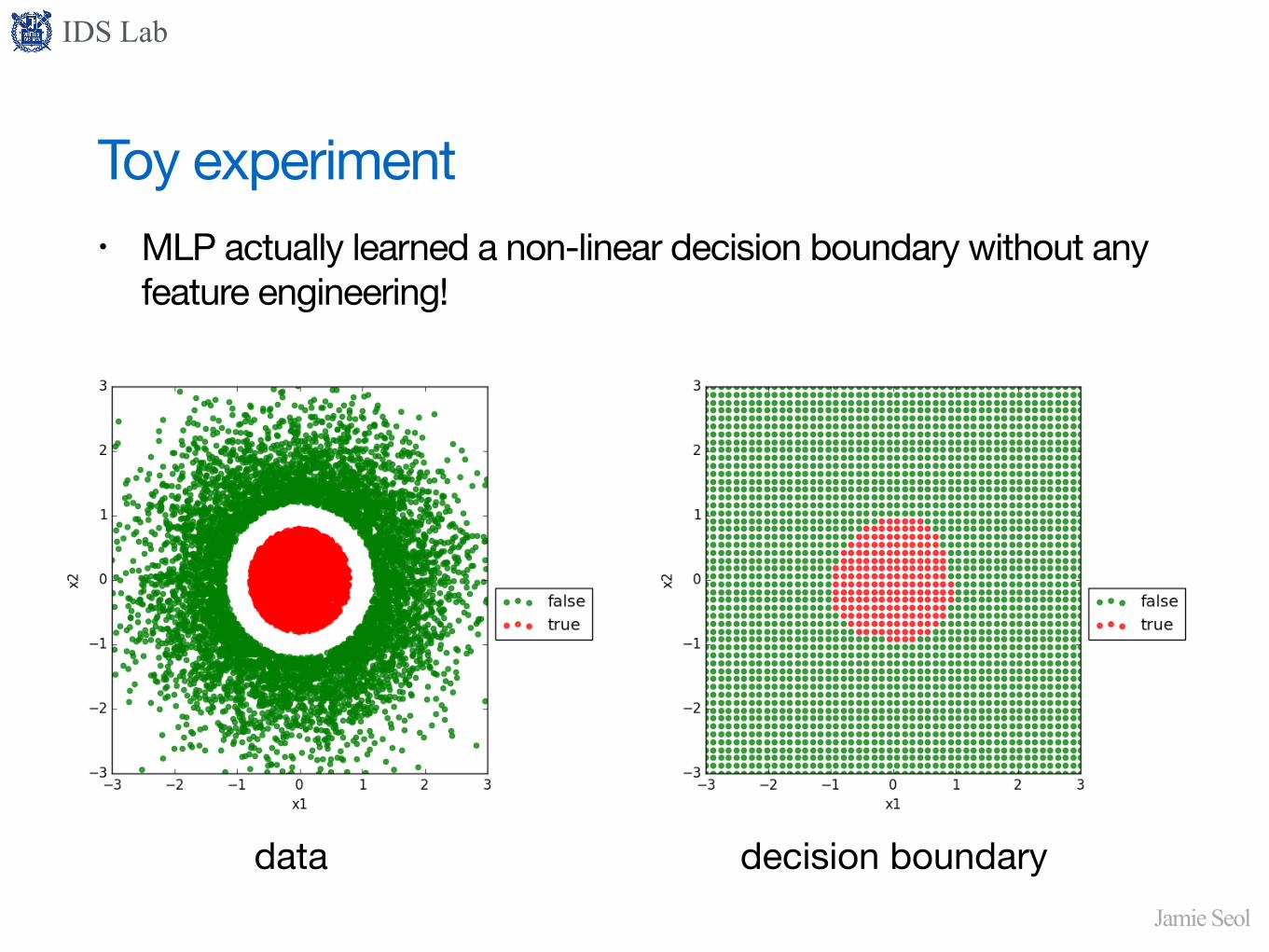
Toy experiment• MLP actually learned a non-linear decision boundary without any
feature engineering!
data decision boundary

IDS Lab
Jamie Seol
Universal Approximation Theorem• The theorem states that, long story short, MLP can represent ANY given (nice) function• Formally proved by G. Cybenko in 1989 with sigmoidal activation
function• K. Hornik proved any activation function works too• therefore, theoretically, MLP can learn ANYTHING
• “it’s not working in practice” ← it will, if you have zillion neurons with zillion layers, and infinite data
• now we can say a deep learning is an universal learning algorithm
• then why do we need things like CNN and RNN? because we don’t have infinite data

IDS Lab
Jamie Seol
Universal Approximation Theorem• We’ll prove this theorem• We can’t skip maths forever!
• let’s use Times New Roman font

IDS Lab
Jamie Seol
Analysis 101• In Euclidean space ℝn, we call the following set open ball
• B(x, ε) = {y ∈ ℝn | d(x, y) < ε} • for given x ∈ ℝn and ε ∈ ℝ+
• function d can be any metric, but usually we use • d(x, y) = l2(x - y) = ||x - y||2 • also known as Euclidean distance
• We call a set A ⊂ ℝn is open if for ∀x ∈ A, ∃ε ∈ ℝ+ such that B(x, ε) ⊂ A • We generalize this concept of open set by open set itself, which we call a
topology

IDS Lab
Jamie Seol
Analysis 101
open ball open set
open ball when d(x, y) = l1(x - y)

IDS Lab
Jamie Seol
Topology 101• For some set X, we say 𝒯 is a topology on X if:
• 𝒯 is a family of subsets of X • that is, 𝒯 ⊂ 𝒫(X)
• ∅, X ∈ 𝒯 • any union of elements of 𝒯 is an element of 𝒯 • any intersection of finite elements of 𝒯 is an element of 𝒯
• Members of 𝒯 are often called open sets • for example, with X = ℝn, we can give topology 𝒯 by collecting all
open sets defined in previous slide • note that this is a typical non-contructive definition!
• we can’t specify all members of 𝒯, though we just know that they do exist well

IDS Lab
Jamie Seol
Topology 101• Note that topology is motivated by generalization of open set!
• for example, in analysis, we say a sequence {an} converges to a if for ∀ε > 0, ∃N s.t. for ∀n > N, |an - a| < ε holds
• in topology, we say a sequence {an} converges to a if for any open set O ∈ 𝒯 containing a, ∃N s.t. for n > N, an ∈ O holds
• x ∈ X is called a limit point of A (for some given A ⊂ X) if for any open set O ∈ 𝒯 containing x, O∩A ≠ ∅ holds
• we denote A’ to be a set of limit points of A • Ā is called a closure of A, defined by Ā = A∪A’ • we say A is dense in X if Ā = X
• THIS is the true meaning of dense! • dense dance ~

IDS Lab
Jamie Seol
Fourier Analysis 101• Easy example: any irrational number is a limit point of ℚ (why?), so
closure of ℚ is equal to ℝ, or, ℚ is dense in ℝ • One of the most useful application of the concept dense is Fourier series/
transform: • trigonometric polynomials (a.k.a. Fourier series) are dense in L2
• this is non-trivial when support is not compact • how about Lp?
• Fourier transform can be defined in Lp • this is also non-trivial • can be proved by following step:
• show that Swarts class is dense in Lp • extend domain by completion to Lp

IDS Lab
Jamie Seol
Topology 101• We say a topological space X is compact if every open covers has a finite
subcover • open covers are just
• Actually, talking about compactness requires a lot of time • For Euclidean space, we can think compact as bounded and closed
• this is not trivial: see Heine-Borel theorem • bounded means that the set can be contained in some big open ball • closed is just opposite of open; A is closed set when X\A is open

IDS Lab
Jamie Seol
Linear Algebra 101• For a vector space V over field F, we call || • || → ℝ a norm of a vector if
• for all a ∈ F and all u, v ∈ V, • ||av|| = |a| ||v|| • ||u + v|| ≤ ||u|| + ||v|| • ||u|| = 0 then u = 0
• Examples • lp-norm: lp(x) =
• Lp-norm: Lp(f) = • Note that set of real valued-functions are vector space! functions are
vector! • (3f + g) is a function(vector) defined by (3f + g)(x) = 3f(x) + g(x)

IDS Lab
Jamie Seol
Linear Algebra 101• For a vector space V over field F, we call <•, •> → F a inner product of
two vectors if • for all a ∈ F and all x, y, z ∈ V,
• Note that we can induce canonical(trivial) norm from inner product by
• Example: inner product of two function

IDS Lab
Jamie Seol
Linear Algebra 101• Function space - just a vector space
• which means, its elements, or vectors, are functions • mostly we’ll deal with continuous and real-valued function
• Typical example of function spaces are: • linear functional (dual space) • Swartz class • Banach space, Hilbert space
• Reproducing Kernel Hilbert Space (RKHS) • this is really really really important concept! mandatory for
understanding regularization and transfer learning • we’ll cover it someday…
• Domain of functions(vectors) are often called support

IDS Lab
Jamie Seol
Analysis 101• A set M is called a metric space if metric d is given, holding
• d: M × M → ℝ, and for all x, y, z in M, • d(x, y) ≥ 0 • d(x, y) = 0 then x = y • d(x, y) = d(y, x) • d(x, z) ≤ d(x, y) + d(y, z)
• Obviously, if some vector space is norm space, then it has canonical(trivial) metric d induced by d(x, y) = ||x - y||
• Another obvious: metric space has canonical(trivial) topology induced from open balls
• For example, Kullback-Leibler divergence is not a metric

IDS Lab
Jamie Seol
Analysis 101• A sequence {an} in metric space M is said to be a cauchy if for ∀ε > 0, ∃N s.t. for ∀n, m > N, d(an, am) < ε holds
• A metric space M is said to be complete if every cauchy sequence converges • very, very typical complete space: ℝ
• but this is not trivial • for example, rational sequence {an} satisfying an ∈ [π - 1/n, π + 1/n] is
cauchy, but it never converges!

IDS Lab
Jamie Seol
Analysis 101• In function space with functions having a metric codomain, we say a
sequence {fn} converges uniformly to f if for ∀ε > 0, ∃N s.t. for ∀n > N, d(fn(x), f(x)) < ε holds all x in support • why uniform? because, N was determined independently by x
• which means, N is a function of ε • if N was determined by both ε and x, then we call it point-wise
convergence

IDS Lab
Jamie Seol
Real Analysis 101• We say a function is measurable if f−1(A) is measurable for any open set A
• maybe we should stop here… • if someone meets non-measurable function by chance, it’ll be one of
the most unlucky day ever • one old mathematician said, “If someone built an airplane using
non-measurable function, then I’ll not ride the plane” • Anyway, a measure is something that measures area of a set
• for example, µ([a, b]) = b - a will hold as intuitively in ℝ with Lebesgue measure µ
• we say some property p holds almost everywhere in A if the measure of {x ∈ A | ¬p(x)} is 0
• note that the probability, is measure of an event!

IDS Lab
Jamie Seol
All together• Want to show: “set of MLP is uniformly dense in measurable normed
function space on every compact support” • at last! now we can read this statement
• Let’s prove this theorem

IDS Lab
Jamie Seol
Notations• For some natural number r, let Ar be set of all affine functions from ℝr to ℝ, where affine function means in form of A(x) = wTx + b
• For any measurable function G from ℝ to ℝ, let ∑r(G) be the class of functions {f: ℝr → ℝ, f(x) = ∑𝛽jG(Aj(x)), x ∈ ℝ, 𝛽j ∈ ℝ, Aj ∈Ar, finite sum} • note that ∑r(G) is family of single hidden layer feedforward neural
network with one output, having G as activation function • actually, we’re talking about Borel measurable, not just any measure
• For any measurable function G from ℝ to ℝ, let ∑∏r(G) be the class of functions {f: ℝr → ℝ, f(x) = ∑𝛽j∏G(Ajk(x)), x ∈ ℝ, 𝛽j ∈ ℝ, Ajk ∈Ar, finite sum and finite product} • somewhat complex but more general form of MLP

IDS Lab
Jamie Seol
Notations• A function 𝛹: ℝ → [0, 1] is a squashing function if
• non-decreasing • limit to +∞ gives 1, -∞ gives 0 • examples: positive indicator function, standard sigmoid function
• Cr = set of continuous function from ℝr to ℝ • if G is continuous, both ∑r(G) and ∑∏r(G) belongs to Cr
• Mr = set of measurable function from ℝr to ℝ • if G is measurable, both ∑r(G) and ∑∏r(G) belongs to Mr • note that Cr is subset of Mr

IDS Lab
Jamie Seol
Notations• Subset S in Cr is said to be uniformly dense on compacta in Cr if for
every compact subset K ⊂ ℝr, S is dK-dense in Cr • dK(f, g) = supx∈K |f(x) - g(x)| • uniform convergence should hold
• Given a measure µ on (ℝr, Br), we define metric • dµ(f, g) = inf{ε > 0: µ{x: |f(x) - g(x)| > ε} < ε}
• so dµ(f, g) = 0 if and only if f and g agrees almost everywhere • Br is Borel 𝜎-field of ℝr (we omit detail explanation) • note that this measure µ is some kind of input space environment (think
as a probability of an event)

IDS Lab
Jamie Seol
Stone-Weierstrass Theorem• A family A of real functions defined on E is an algebra if A is closed
under addition, multiplication, and scalar multiplication • A family A separates points on E if for every x, y in E that x ≠ y, ∃f ∈ A s.
t. f(x) ≠ f(y) • A family A vanishes at no point of E if for each x in E, ∃f ∈ A s. t. f(x) ≠ 0 • statement if A is an continuous algebra on compact metric space K and
separates points on K and vanished at no point of K, then A is dK-dense on C(K)
• proof too long to prove in here • see the reference for full proof

IDS Lab
Jamie Seol
Sketch of the proof1. Apply Stone-Weierstrass theorem to ∑∏r(G) 2. Extend uniformly dense on compacta to dense in sense of measure 3. For squashing functions, approximate it to continuous squashing function 4. For continuous squashing function, approximate it to Fourier series 5. Remove ∏ by cosine rule

IDS Lab
Jamie Seol
Theorem 1• statement let G be any continuous non-constant function from ℝ to ℝ,
then ∑∏r(G) is uniformly dense on compacta in Cr • proof let K ⊂ ℝr be any compact set, then for any G, ∑∏r(G) is obviously
an algebra on K which separates points and vanished at no point, since we collected affine functions in form of A(x) = wTx + b, so we can use Stone-Weierstrass theorem

IDS Lab
Jamie Seol
Lemma 1• statement if {fn} is a sequence of functions in Mr that converges
uniformly on compacta to the function f, then dµ(fn, f) → 0 • by this lemma, extending Mr from Cr becomes really easy! • note that our activation functions are not always continous
• but surely measurable, because we don’t want to build any non-measurable MLP - it would be a terror!
• proof pick a big compact set (so that measure of the set becomes almost large as the whole), find large N from uniform convergence, then apply Chebyshev’s inequality • fn will be similar to f in the compact set, and the rest part of support is
small, so the integral on Chebyshev’s inequality becomes tiny • we’re working on ℝr, which is a locally compact metric space with
regular measure, so many problems are relatively simple

IDS Lab
Jamie Seol
Theorem 2• statement let G be any continuous non-constant function from ℝ to ℝ,
then ∑∏r(G) is dµ-dense in Mr for any finite measure µ • proof immediately follows from Theorem 1 and Lemma 1 if we know
that for any finite measure µ, Cr is dµ-dense in Mr
• this can be proved by similar way that we did in Lemma 1 • So the activation function don’t really have to be continuous! we can use
positive indicator function as activation function

IDS Lab
Jamie Seol
Theorem 3• statement let 𝛹 be any squashing function, then ∑∏r(𝛹) is uniformly
dense on compacta in Cr and dµ-dense in Mr for any probability measure µ • proof show that ∑∏r(𝛹) is uniformly dense on compacta in ∑∏r(F),
where F is continuous squashing function • any continuous squashing function F can be uniformly approximated
by some element H of ∑l(𝛹), in sense of supx∈ℝ |F(x) - H(x)| < ε for ∀ε > 0
• if ∏l(F) can be uniformly approximated by members of ∑∏r(𝛹), then we’re done
• these proof can be done by analytic (rather dirty) works • the rest part will be completed by Lemma 1 and Theorem 2

IDS Lab
Jamie Seol
Theorem 4• statement let 𝛹 be any squashing function, then ∑r(𝛹) is uniformly
dense on compacta in Cr and dµ-dense in Mr for any probability measure µ • proof using the fact that continous squashing function can be uniformly
approximated by Fourier series in each compact support and note that cosAcosB = cos(A+B) - cos(A-B) • wow! that’s really all! • we removed the ∏ part by uniformly approximating 𝛹 to some
continuous squashing function (using Theorem 3), which also can uniformly approximated to its Fourier series in each compact set (for more details, see the reference book), and some cosine rules

IDS Lab
Jamie Seol
Corollaries• The rest part is just some natural corollaries like
• it can be extended to general Lp space • it can be extended to multi-output MLP • it can be extended to multi-layer MLP
• hmm? actually, Theorem 4 claims that 1-layer NN is enough universal approximator

IDS Lab
Jamie Seol
Conclusion• We now know that MLP actually works theoretically! • MLPs are universal approximators
• Taylor series and Fourier series are also good universal approximators but those two requires detailed information of the original function (or computable oracle), while MLP can be learned by only using the train data
• me? • Jamie Seol • email - [email protected] • twitter - @theeluwin • website - theeluwin.kr • blog - blog.theeluwin.kr

IDS Lab
Jamie Seol
References• Hornik, Kurt, Maxwell Stinchcombe, and Halbert White. "Multilayer
feedforward networks are universal approximators." Neural networks 2.5 (1989): 359-366.
• Cybenko, George. "Approximation by superpositions of a sigmoidal function." Mathematics of control, signals and systems 2.4 (1989): 303-314.
• Rudin, Walter. Principles of mathematical analysis. Vol. 3. New York: McGraw-Hill, 1964.
• Rudin, Walter. Real and complex analysis. Tata McGraw-Hill Education, 1987.
• Munkres, James R. Topology. Prentice Hall, 2000. • Gockenbach, Mark S. Finite-dimensional linear algebra. CRC Press, 2011. • Young, Matt. "The Stone-Weierstrass Theorem." (2006). • Stein, Elias M., and Rami Shakarchi. "Fourier Analysis, Princeton Lectures
in Analysis I." (2003).






![Complexity bounds for approximations with deep ReLU neural … › fileadmin › i26_fg-kutyniok › ... · 2019-04-08 · The universal approximation theorem [15, 33] establishes](https://img.pdfslide.us/doc/110x75/5f1876f9ba58b252143d055d/complexity-bounds-for-approximations-with-deep-relu-neural-a-fileadmin-a-i26fg-kutyniok.jpg)

![Deep Belief Networks are Compact Universal Approximators · Universal approximation theorem [Cybe89] Let ’() be a non constant, bounded, and monotonically-increasing continuous](https://img.pdfslide.us/doc/110x75/5f18775625025331252c43a6/deep-belief-networks-are-compact-universal-universal-approximation-theorem-cybe89.jpg)
![A UniversalApproximationTheoremof DeepNeuralNetworksfor … · 2020. 4. 23. · Y. Lu and J. Lu/Universal Approximation Theorem of DNNs for Distributions 2 works [12, 18, 25, 6] on](https://img.pdfslide.us/doc/110x75/606f027a0f81fc4736168f77/a-universalapproximationtheoremof-deepneuralnetworksfor-2020-4-23-y-lu-and.jpg)


![David M. Blei arXiv:1511.06499v4 [stat.ML] 17 Apr 2016arXiv:1511.06499v4 [stat.ML] 17 Apr 2016 Published as a conference paper at ICLR 2016 1.We prove a universal approximation theorem:](https://img.pdfslide.us/doc/110x75/5ff663a310fc592c1d464c7f/david-m-blei-arxiv151106499v4-statml-17-apr-2016-arxiv151106499v4-statml.jpg)









![Universal approximations of invariant maps by neural networks · in the sense of the universal approximation theorem for neural networks Pinkus [1999]. Designing invariant and equivariant](https://img.pdfslide.us/doc/110x75/5f18775525025331252c439e/universal-approximations-of-invariant-maps-by-neural-networks-in-the-sense-of-the.jpg)






![algebraic topologyamathew/ATnotes.pdf · 2015-09-03 · the theorem 55 Lecture 17 [Section] 10/4 ... approximation theorem 58 x4 Lefschetz xed point theorem 59 Lecture 19 10/8 x1](https://img.pdfslide.us/doc/110x75/5ea492f5a0779303944d67a4/algebraic-topology-amathewatnotespdf-2015-09-03-the-theorem-55-lecture-17.jpg)