Embed Size (px)
Citation preview

Making Linked Data SPARQL with theInterMine Biological Data Warehouse
9th International SWAT4LS Conference
5-8 December 2016 Amsterdam
Justin Clark-Casey, Software Engineer @InterMineDaniela Butano, Software Engineer @InterMine

Today’s Talk
● InterMine
● MOLD (Model Organism Linked Database)
● Providing RDF and SPARQL from all Mines: The challenges ahead

What is InterMine?
● A biological data warehouse.● Initially for Drosophilia.● But with a flexible and extensible data model.● Now used as infrastructure by many model organism
(MOD) and other life sciences projects.● Open-source, continuous development for over 15 years.● 7 software engineers, 1 biologist, 1 PI.




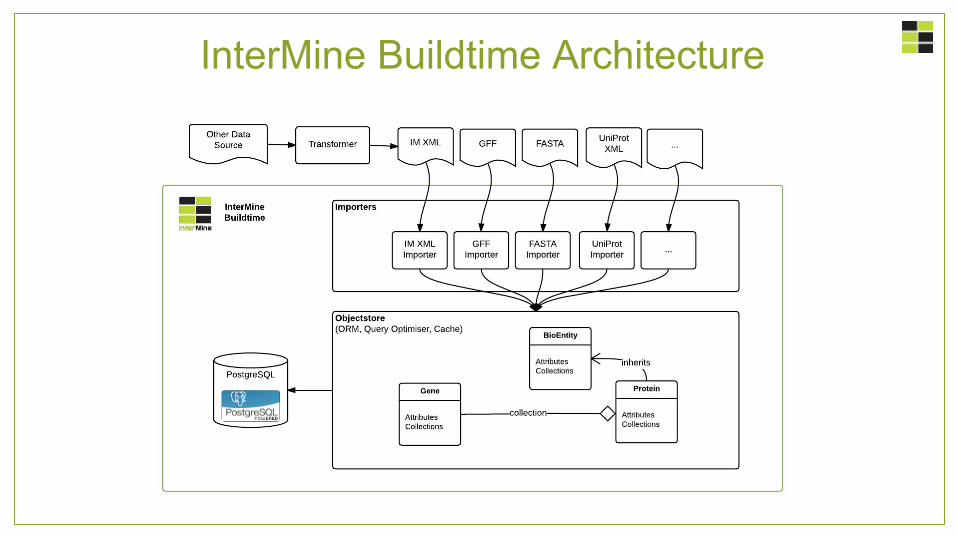
InterMine Buildtime Architecture

InterMine Runtime Architecture

Extracting DataGetting data via a script (Python example)
from intermine.webservice import Serviceservice = Service("http://www.flymine.org/flymine/service")query = service.new_query("Gene")query.add_view("name", "proteins.uniprotName")query.add_constraint("name", "=", "zerknullt", code = "A")
for row in query.rows(): print row["name"], row["proteins.uniprotName"]
Resultszerknullt ZEN1_DROMEzerknullt B4LZ31_DROVI

Great, but...These export mechanisms have served us well and continue to do so.But...
● Query requires use of a bespoke language (InterMine PathQuery).● Exported data may require transformation.● Whole biological objects only have a human view.
A core aim of InterMine is to make its data provision FAIR, we are always looking for ways to facilitate this...

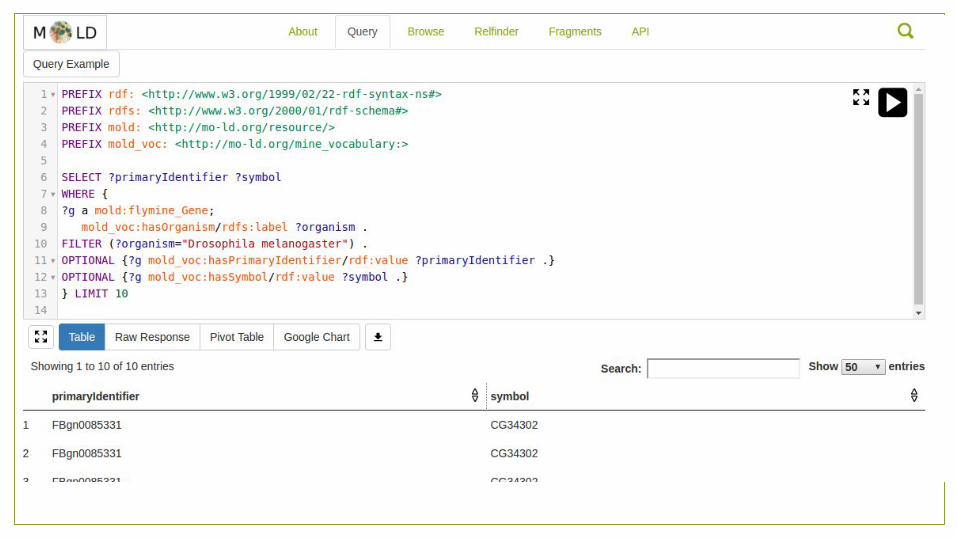
MOLD
● Created by the Dumontier Lab in Stanford.● Model Organism Linked Database● Create a LOD of model organism data.
○ With links to ontologies and other LOD (e.g. Bio2RDF).
● Publish tools to access and explore the data.

InterMine RDFization Process

Example of Generated RDF



What next?
● Incorporate and extend MOLD components to allow any mine operator to○ Generate and publish RDF dumps.○ Make biological objects available as RDF resources.○ Provide a SPARQL endpoint.○ Explore emerging approaches such as Triple Pattern Fragments.
● Mine operators may not be software engineers○ Software and processes need to be consumable.

Data Challenge : Stable URIs
● Navigation InterMine URIs do not have a stable ID○ http://www.flymine.org/flymine/report.do?id=1007741
● InterMine ‘shareable’ URIs are better but still have issues○ http://www.flymine.org/flymine/portal.do?class=Gene&externalids=FBgn00
04053
● Persistence in the face of○ Name changes○ Scientific changes

Data Challenge : Ontologies● As of now, InterMine has a data model with no attached ontologies.
○ Sequence Ontology is a partial exception.
● InterMine-RDFizer generates a vocabulary automatically for the data model.● But we want to emit RDF that uses existing ontologies
○ Gene Ontology○ FALDO○ etc.
● Issues○ Need a mechanism to attach arbitrary ontologies to the core data model and any extensions.○ Which ontologies?○ How do we facilitate user selection?

Tech Challenge : Performance● Other projects (e.g. MODs) rely on us.● Questions around SPARQL performance.● Proposed Solution: Adapt MOLD’s Dockerization approach with a separate
triplestore for data.○ Pros:
■ Easier deployment.■ Performance issues can be contained.■ Decoupled iteration.
○ Cons:■ Multiple systems.■ Maturity of Docker?

Maxime Déraspe Department of Molecular Medicine, Université Laval, Québec, CA
Stanford Center for Biomedical Informatics Research, Stanford University, Stanford, US
Gail Binkley Department of Genetics, Stanford University, Stanford, US
Daniela Butano Department of Genetics and Cambridge Systems Biology Centre, University of Cambridge, Cambridge, UK
Justin Clark-Casey Department of Genetics and Cambridge Systems Biology Centre, University of Cambridge, Cambridge, UK
Kalpana Karra Department of Genetics, Stanford University, Stanford, US
Julie Sullivan Department of Genetics and Cambridge Systems Biology Centre, University of Cambridge, Cambridge, UK
J. Michael Cherry Department of Genetics, Stanford University, Stanford, US
Jacques Corbeil Department of Molecular Medicine, Université Laval, Québec, CA
Gos Micklem Department of Genetics and Cambridge Systems Biology Centre, University of Cambridge, Cambridge, UK
Michel Dumontier Stanford Center for Biomedical Informatics Research, Stanford University, Stanford, US

THANKYOU!Justin [email protected]@justincc
Daniela [email protected]
MOLDhttp://mo-ld.org/
InterMinehttp://intermine.org@intermineorg
Presentation licensed under Creative Commons 4.0 Attribution International
goo.gl/IsjPzh





























![Distributed Join Approaches for W3C-Conform SPARQL Endpoints · data into it, but can use these SPARQL endpoints for data access. The RDF query language SPARQL [45] in its cur-rent](https://img.pdfslide.us/doc/110x75/5fd7cb2c66afe53aec1093fc/distributed-join-approaches-for-w3c-conform-sparql-endpoints-data-into-it-but-can.jpg)