Embed Size (px)
DESCRIPTION
Petar Petrovski, Volha Bryl, Christian Bizer Linked Data for Information Extraction Workshop @ ISWC 2014, Riva del Garda, Italy, October 20, 2014
Citation preview

Learning Regular Expressions for the Extraction of Product Attributes
from E-commerce Microdata
School of Business Informatics and Mathematics
Petar Petrovski, Volha Bryl, Christian Bizer
Data and Web Science Research GroupUniversity of Mannheim, Germany
LD4IE @ ISWC'2014, October 20, 2014, Riva del Garda, Italy

Outline
1. HTML-embedded Data on the Web
2. Data Integration Pipeline
3. Learning regular expression
4. Evaluation
– Extraction of product attributes
– Identity resolution for products
5. Conclusions
2Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer

HTML-embedded Data
More and more Websites semantically markup the content of their HTML pages.
Microformats
Microdata
RDFa
3Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer

Schema.org
• ask site owners to embed data to enrich search results.
• 200+ Classes: Product, Review, LocalBusiness, Person, Place, Event, …
• Encoding: Microdata or RDFa
4Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer

Usage of Schema.org Data @ Google
Data snippets
within
search results
Data snippets
within
info boxes
5Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer

Websites Containing Structured Data (November 2013)
1.7 million websites (PLDs) out of 12.8 million provide Microformat, Microdata or RDFa data (13%)
585 million of the 2.2 billion pages contain Microformat, Microdata or RDFa data (26%).
http://webdatacommons.org/structureddata/
Google, October 2013: 15% of all websites provide structured data.
6Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer
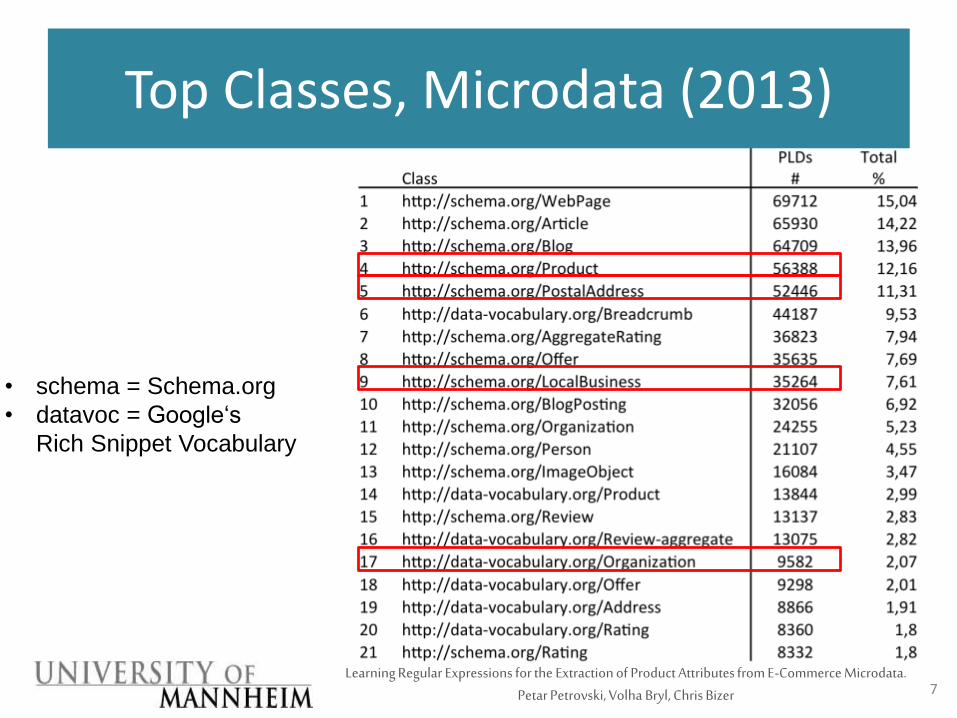
Top Classes, Microdata (2013)
• schema = Schema.org
• datavoc = Google‘s
Rich Snippet Vocabulary
7Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer

Outline
1. HTML-embedded Data on the Web
2. Data Integration Pipeline
3. Learning regular expression
4. Evaluation
– Extraction of product attributes
– Identity resolution for products
5. Conclusions
8Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer
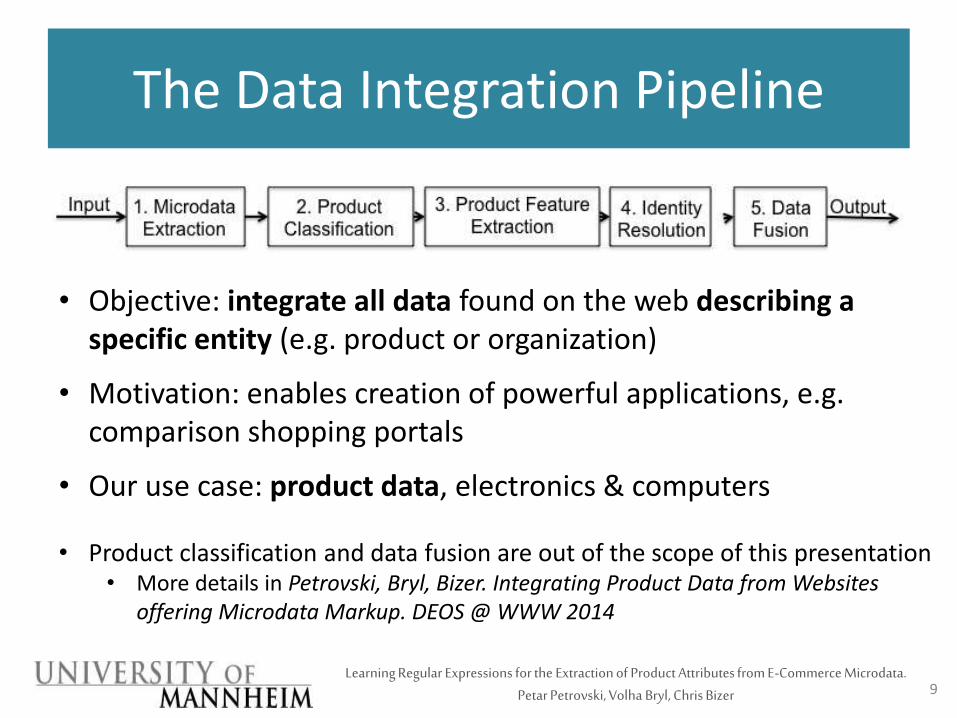
The Data Integration Pipeline
• Objective: integrate all data found on the web describing a specific entity (e.g. product or organization)
• Motivation: enables creation of powerful applications, e.g. comparison shopping portals
• Our use case: product data, electronics & computers
• Product classification and data fusion are out of the scope of this presentation• More details in Petrovski, Bryl, Bizer. Integrating Product Data from Websites
offering Microdata Markup. DEOS @ WWW 2014
9Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer

Web Data Commons Dataset
• Web Data Commons project: extracts structured data from the Common Crawl corpora– http://webdatacommons.org/– http://commoncrawl.org/
• Our evaluation dataset is extracted from Common Crawl 2012– 3 billion HTML pages, 40.6 million websites– 7.3 billion statements describing 1.15 billion things– 9.4 million product offers from 9240 e-shops
• 1.9 million products with English descriptions with length grater than 20 words
Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.Petar Petrovski, Volha Bryl, Chris Bizer

Problem: Product Matching by Titles and Descriptions
Title
Description
AppleMacBook Air MC968/A 11.6-Inch Laptop
Faster Flash Storage with 64 GB Solid State Drive and USB 3.0. 720p FaceTime HD Camera. The new 1.6 GHz Intel Core i5 Processor with Intel HD Graphics 3000 enabling beautiful rendering and 4GB DDR3 RAM. 11.6” LED display with the best resolution…
Title
DescriptionThe MacBook Air MC 968/A powered by Intel Core i5(1.6GHz, 3MB L3). 64 GB SSD and 4096 MB of DDR3 RAM. 29.464cm (11.6”) TFT 1366x768, Intel HD Graphics, IEEE 802.11a/b/g, Bluetooth 4.0, FaceTme camera, OS X LIon
Apple MacBook Air 11-in, Intel Core i5 1.60GHz, 4 GB, 64 GB, Mac OS X Lion 10.7
Various abbreviations can be found describing same features Often imprecise values due to
rounding in numeric values can be found Different descriptions follow
different levels of detail
Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.Petar Petrovski, Volha Bryl, Chris Bizer
Most common attributes:Title : 89%Description : 67%Others: scarce

Product Feature Extraction
12Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer
• Low precision (69%) for identity resolution without product feature extraction, reason – lack of structure

Product Feature Extraction
• Low precision (69%) for identity resolution without product feature extraction, reason – lack of structure
• We developed the Free Text Preprocessor– Makes the data more structured by extracting new property-value
pairs from free-text properties– https://www.assembla.com/spaces/silk/wiki/Silk_Free_Text_Preprocessor
• With pre-processing precision goes up to 85%
We used Silk framework for identity resolution: http://wifo5-03.informatik.uni-mannheim.de/bizer/silk/
13Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer

Free Text Preprocessor by Example
<http://wdc.org/resource/2> <http://schema.org/Product/title> "Apple iPod nano (8 GB, 6th generation, Graphite)" .
<http://wdc.org/resource/2> <http://schema.org/Product/description>
"Memory size: 8GB. Colour: Graphite Generation: 6th generation. Memory type: Integrated. Weight: 21.1g. Radio: With Radio. Audio/Video formats: AAC, AIFF, Audible, MP3, WAV, VBR Display: 1.5-inch" .
14Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer

Free Text Preprocessor by Example
<http://wdc.org/resource/2> <http://schema.org/Product/title> "Apple iPod nano (8 GB, 6th generation, Graphite)" .
<http://wdc.org/resource/2> <http://schema.org/Product/description>
"Memory size: 8GB. Colour: Graphite Generation: 6th generation. Memory type: Integrated. Weight: 21.1g. Radio: With Radio. Audio/Video formats: AAC, AIFF, Audible, MP3, WAV, VBR Display: 1.5-inch" .
<http://wdc.org/resource/2> <http://schema.org/Product/Brand> "Apple" .
<http://wdc.org/resource/2> <http://schema.org/Product/Model> "iPod nano" .
<http://wdc.org/resource/2> <http://schema.org/Product/Storage> "8GB" .
<http://wdc.org/resource/2> <http://schema.org/Product/Display> "1.5-inch" .
15Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer

Free Text Preprocessor by Example
<http://wdc.org/resource/2> <http://schema.org/Product/title> "Apple iPod nano (8 GB, 6th generation, Graphite)" .
<http://wdc.org/resource/2> <http://schema.org/Product/description>
"Memory size: 8GB. Colour: Graphite Generation: 6th generation. Memory type: Integrated. Weight: 21.1g. Radio: With Radio. Audio/Video formats: AAC, AIFF, Audible, MP3, WAV, VBR Display: 1.5-inch" .
<http://wdc.org/resource/2> <http://schema.org/Product/Brand> "Apple" .
<http://wdc.org/resource/2> <http://schema.org/Product/Model> "iPod nano" .
<http://wdc.org/resource/2> <http://schema.org/Product/Storage> "8GB" .
<http://wdc.org/resource/2> <http://schema.org/Product/Display> "1.5-inch" .
16Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer
Preprocessor worked efficiently when regular expressions for extraction certain attributes were configured manually.

Outline
1. HTML-embedded Data on the Web
2. Data Integration Pipeline
3. Learning regular expression
4. Evaluation
– Extraction of product attributes
– Identity resolution for products
5. Conclusions
17Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer

Solution: Learning Regular Expressions
• No more manual configuration– Familiarity with regex syntax and deep understanding of
the data is no longer required from the user
• Approach: Genetic Programming
• Based on– Li et al. Regular expressions learning for information extraction.
EMNLP’08.– Langdon et al. Creating regular expressions as mRNA motfis with
GP to predict human exon splitting. GECCO’09.– Bartoli et al. Automatic generation of regular expressions from
examples with genetic programming. GECCO’12.
Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.Petar Petrovski, Volha Bryl, Chris Bizer

Learning Regular Expressions
• Every individual is a tree representing a valid regex• Possible nodes
– Concatenate node ||– Possessive quantifiers
• *+, ++, ?+, {m,n}+
– Group operator ()– Character class node []
• Terminal nodes– Constants (d, 5, abc)– Ranges (a-z, 0-9)– Character classes (\w or \d)– Wildcards (.)– Whitespaces (\s)
Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.Petar Petrovski, Volha Bryl, Chris Bizer

Training Data and Initial Population
• Input set T: pairs of strings (t,s)– t is a text string– s is a substring of t that must be detected as a regular expression– if s is empty the pair is considered as a negative example
• Generating initial population– Population size = 2 * |T|– Half generated from examples
• Each digit is replaced by \d• Each character sequence is replaced by \w
– Half generated randomly by the ramped half-and-half method• Half full/bushy trees• Half diverse trees
Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.Petar Petrovski, Volha Bryl, Chris Bizer

Operators: Crossover
• Two point crossover
• Individuals for crossover are selected with tournament selection method
Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.Petar Petrovski, Volha Bryl, Chris Bizer

Operators: Mutation
Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.Petar Petrovski, Volha Bryl, Chris Bizer
• Two step mutation process1. Selecting the crossover operator
2. Executing headless chicken crossover
• cross an individual from the population with a randomly generated individual

Fitness Function
• Matthews correlation coefficient
Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.Petar Petrovski, Volha Bryl, Chris Bizer

Outline
1. HTML-embedded Data on the Web
2. Data Integration Pipeline
3. Learning regular expression
4. Evaluation
– Extraction of product attributes
– Identity resolution for products
5. Conclusions
24Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer

Attribute Extraction: Experimental Setting
• 5,000 products from the WDC dataset
• Training set
– 500 product specification from Amazon catalogue
– Positive examples: from the property to be extracted
– Negative examples: from other properties at random or random text
• 5 attributes
– Model, Storage, Display, Processor, Dimension
Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.Petar Petrovski, Volha Bryl, Chris Bizer

Attribute Extraction: Evaluation
• Learned regular expressions– Model: (?:[^\d]+\s[a-z0-9]+)*+– Storage: (?:\d+[^B]+[B]+)++– Display: \d+.[^nc]*+nc[^o]*+– Processor: \d+\s?[^z]++z – Dimension: \d[^.]x?[\d]++
• F-measure– 89.4% for numeric or simple combination of numbers and
letters (Display, Storage, Processor, Dimension)– 94.2% for Dimension (best)– 77.2% for Model (worst)
Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.Petar Petrovski, Volha Bryl, Chris Bizer

F-Measure: Model Property
27Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer

F-Measure: Dimension Property
28Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer

Identity Resolution: Experimental Setting
• Input• 5,000 products with extracted product attributes
• Matching against 20 electronics products from the Amazon product catalogue
• Gold standard• 5,000 links manually annotated, 2,500 positive/2,500 negative
• Baseline• Pairwise matching of just title and description
• Jaccarad similarity measure, extracting patterns with regex
• Tool: Silk Link Discovery Framework
29Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer

Identity Resolution: Evaluation
Precision % Recall % F-Measure %
Baseline 69 90 78.1
Manualconfiguration *
85 80 82.4
Learned Regular Expressions
80 84 81.9
30Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer
* See Petrovski, Bryl, Bizer. Integrating Product Data from Websites offering Microdata Markup. DEOS @ WWW 2014

Conclusions
• By using Microdata, thousands of websites help us to understand their content
• We have presented the 5-step data integration pipeline– From Microdata markup to an integrated dataset
• Pre-processing (attribute extraction) step is crucial for the precision of data integration – In cases the input data is not structured enough
• Learning regular expression allows us to achieve similar matching quality to that of manually configured pre-processing
31Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer

Conclusions
• Future work– Change the “select first match” strategy in attribute extraction
• Rank all available matches and then use this information during extraction
– Look at elitist strategy
• Keep top 1% when it comes to breeding
– Apply the approach to other domains
• Local businesses, job announcements, addresses, …
32Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer

Questions?
33Learning Regular Expressions for the Extraction of Product Attributes from E-Commerce Microdata.
Petar Petrovski, Volha Bryl, Chris Bizer





























