Embed Size (px)
DESCRIPTION
The Royal Society of Chemistry has an archive of hundreds of thousands of published articles containing various types of chemistry related data – compounds, reactions, property data, spectral data etc. RSC has a vision of extracting as much of these data as possible and providing access via ChemSpider and its related projects. To this end we have applied a combination of text-mining extraction, image conversion and chemical validation and standardization approaches. The outcome of this project will result in new chemistry related data being added to our chemical and reaction databases and in the ability to more tightly couple web-based versions of the articles with these extracted data. The ability to search across the archive will be enhanced as a result. This presentation will report on our progress in this data extraction project and discuss how we will ultimately use similar approaches in our publishing pipeline to enhance article markup for new publications.
Citation preview

Data enhancing the Royal Society of Chemistry publication archive
Antony Williams, Colin Batchelor, Peter Corbett, Ken Karapetyan and Valery Tkachenko
ACS Dallas
March 2014

Data Enhancing the RSC Archive
• Publications summarise data acquisition, analysis and conclusions.• Much detail in the data• Improved navigation
includes data access• Reanalysis of data is
limited in PDFs


Text Mining
The N-(β-hydroxyethyl)-N-methyl-N'-(2-trifluoromethyl-1,3,4-thiadiazol-5-yl)urea prepared in Example 6 , thionyl chloride ( 5 ml ) and benzene ( 50 ml ) were charged into a glass reaction vessel equipped with a mechanical stirrer , thermometer and reflux condenser .
The reaction mixture was heated at reflux with stirring , for a period of about one-half hour .
After this time the benzene and unreacted thionyl chloride were stripped from the reaction mixture under reduced pressure to yield the desired product N-(β-chloroethyl)-N-methyl-N'-(2-trifluoromethyl-1,3,4-thiaidazol-5-yl)urea as a solid residue

How is DERA going? TEXT
• We have text-mined all 21st century articles… >100k articles from 2000-2013
• Mostly marked up with XML, more structured, easier to handle. Markup mostly published onto the HTML forms of the articles
• Required multiple iterations based on dictionaries, markup, OSCAR extraction
• New visualization approaches in development
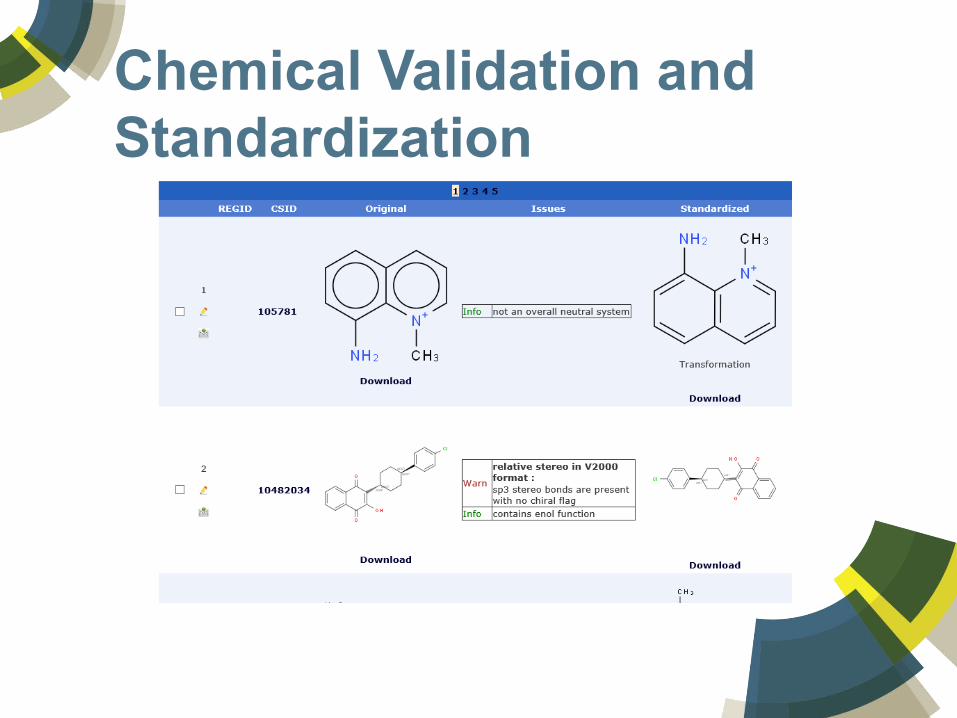
Chemical Validation and Standardization

The RSC Data Repository
Deposition Gateway
Staging databases
Compounds
Reactions
Spectra
Materials
Articles / CSSP
Compounds Module
Spectra Module
Reactions Module
Materials Module
TextminingModule
Module
Web UI for unified depositions
DropBox, Google Drive, SkyDrive, etc
LabTrove and other templated data
Documents
API, FTP, etc
Raw data Validated dataStaging
databases
All databases are sliced by data sources/data
collections and have simple
security model where each data
slice/source is private, public or
embargoed

Text-Mining

ChemSpider Reactions

Reactions
• We will put reactions from our databases into the Reactions Repository
• We will use “Reaction Validation” procedures to clean up Daniel Lowe’s USPTO patent set of over a million extracted reactions
• We will move ChemSpider SyntheticPages content to the Reactions Repository
• We will use the RXNO Ontology to classify the reactions

Reaction Deposition/Validation

ESI – Text Spectra

Lots of “Textual Spectra”
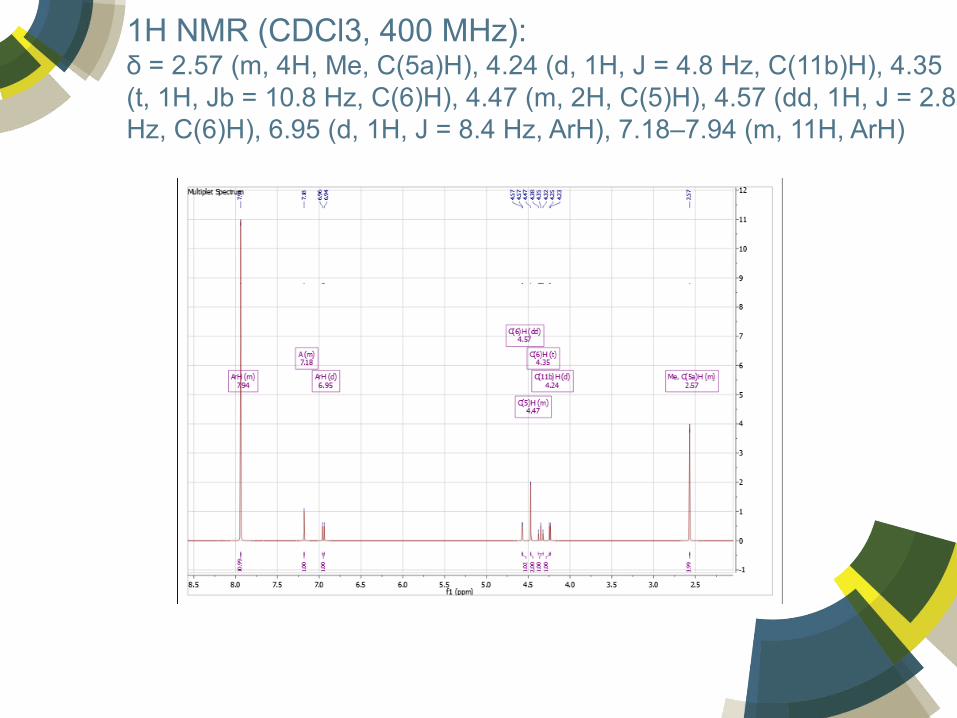
1H NMR (CDCl3, 400 MHz): δ = 2.57 (m, 4H, Me, C(5a)H), 4.24 (d, 1H, J = 4.8 Hz, C(11b)H), 4.35 (t, 1H, Jb = 10.8 Hz, C(6)H), 4.47 (m, 2H, C(5)H), 4.57 (dd, 1H, J = 2.8 Hz, C(6)H), 6.95 (d, 1H, J = 8.4 Hz, ArH), 7.18–7.94 (m, 11H, ArH)

13C NMR (CDCl3, 100 MHz): δ = 14.12 (CH3), 30.11 (CH, benzylic methane), 30.77 (CH, benzylic methane), 66.12 (CH2), 68.49 (CH2), 117.72, 118.19, 120.29, 122.67, 123.37, 125.69, 125.84, 129.03, 130.00, 130.53 (ArCH), 99.42, 123.60, 134.69, 139.23, 147.21, 147.61, 149.41, 152.62, 154.88 (ArC)

How is DERA going? Text Spectra
• Overall progress is good• Improved algorithms for extraction of spectra• Extraction of associated compound name
with spectrum – name to structure conversion now
• MestreLabs have provided us with batch conversion tool
• Work in progress – manual and automated validation. In theory auto-assignment also

Visualization of Spectra
• For spectra associated with compounds we would like to view “interactive spectra”

Javascript viewer with JMol

Figure Spectra into “Real Spectra”?
• We are turning text into structures• We are turning text into spectra• And we are turning figures into spectra

Turn “Figures” Into Data
EXTRACTED DATA
FIGURE

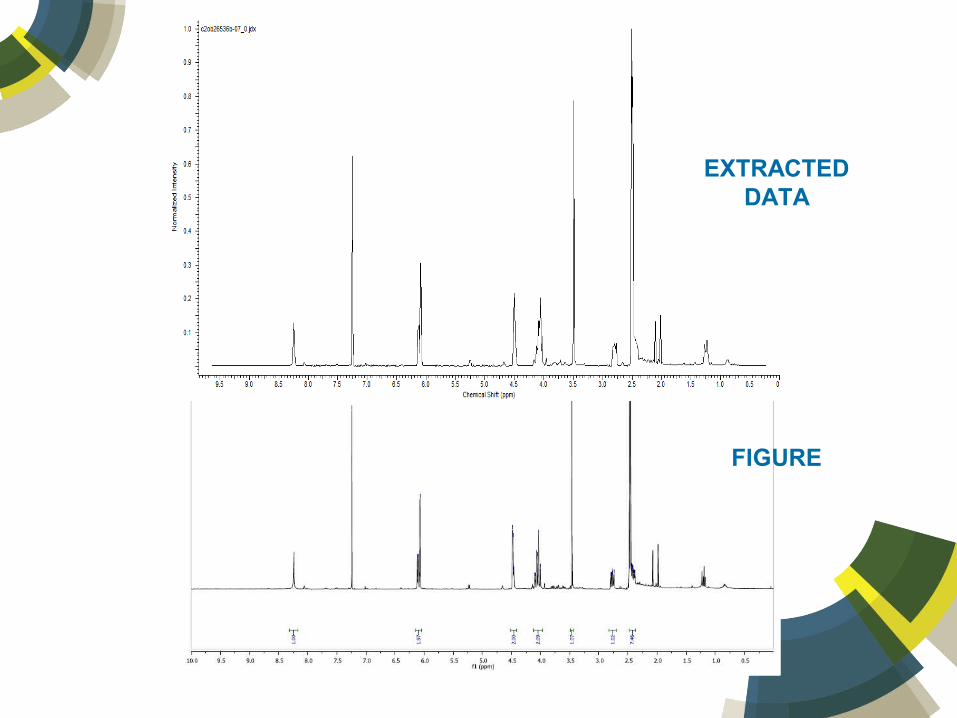
EXTRACTED DATA
FIGURE

How is DERA going? Figures
• Validation tests performed with William Brouwer. Good enough to proceed with larger test set
• Ready to run process across larger collection• Focus on 21st century articles only for now

Early Test Experiments
Input : 74 supplementary data documents/ 3444 pages Output : p2t extracted content in 1069 page instances
− 578 molecules ~ 10% false positives eg., classifies Bruker logo as
chemical object ~ 20% false negatives eg., missing some symbols
from structure− 1151 spectra
> 80% of peaks extracted to within 1-2 decimal places (ppm)

Validating Spectra
• How will we check data consistency?• How do we know the structure and the
spectra match? Comparing image to spectrum is NOT enough!!!
• Predict spectra, use spectral verification, use algorithmic checking.
• Flag “dodgy data” and use crowdsourcing for data checking
• MULTIPLE prediction technologies now available – VERIFICATION is tougher

What are we extracting?
• Compounds from compound names• Reactions from the text• Spectral extraction – from figures and text
• Extraction of data from “tables” – not only CSV files but literal tables in the publication – specifically data from MedChemComm as proof of concept

Building out the technology
• We are presently Open-Sourcing a chemical registration system developed for OpenPHACTS
• We will then Open Source the Chemical Validation and Standardization Platform
• We are working with Bob Hanson and Bob Lancashire on Jmol/JSpecView Open Source
• We will deliver a set of Open Source widgets for structure handling/visualization

Javascript viewer NMR, MS, IR

Grand Target
• Fingers crossed to get 21st century spectra converted
• Spectra associated with compounds will go into ChemSpider
• Spectra converted from Figures but without compound association will be captured with Figures into the Data Repository
• Focus on IR, Raman, UV-Vis & 1D NMR

DERA is FINE for an archiveThe WRONG WAY otherwise!
• We should NOT be mining data out of future publications
• Structures should be submitted “correctly” • Spectra should be digital spectral formats,
not images• ESI should be RICH and interactive• Data should be open, available, with meta
data and provenance

We can solve for Authors hereWill it be used though???

Advanced ESI

Conclusions
• Great progress in mining the archive and 21st century articles are being enhanced on the publishing platform iteratively
• Spectral Data is the next focus – directly connected to our work on the data repository
• Reaction extraction, processing and validation from articles is progressing more slowly
• Results are content, software components and and Open Source Contributions

Acknowledgments
• Bill Brouwer – Plot2Txt Development• Carlos Cobas and Santi Dominguez• Bob Hanson and Bob Lancashire for
Jmol/JSpecView Javascript version• Leah McEwan and Will Dichtel• ACD/Labs – Provider of spectroscopy tools

Thank you
Email: [email protected]: 0000-0002-2668-4821 Twitter: @ChemConnectorPersonal Blog: www.chemconnector.com SLIDES: www.slideshare.net/AntonyWilliams





























